一 在Spark 环境下使用 Hive 功能,创建表、加载数据、查询数据以及进行数据转换
1 先将需要用的movie.txt文件放到Spark-SQL/input目录下
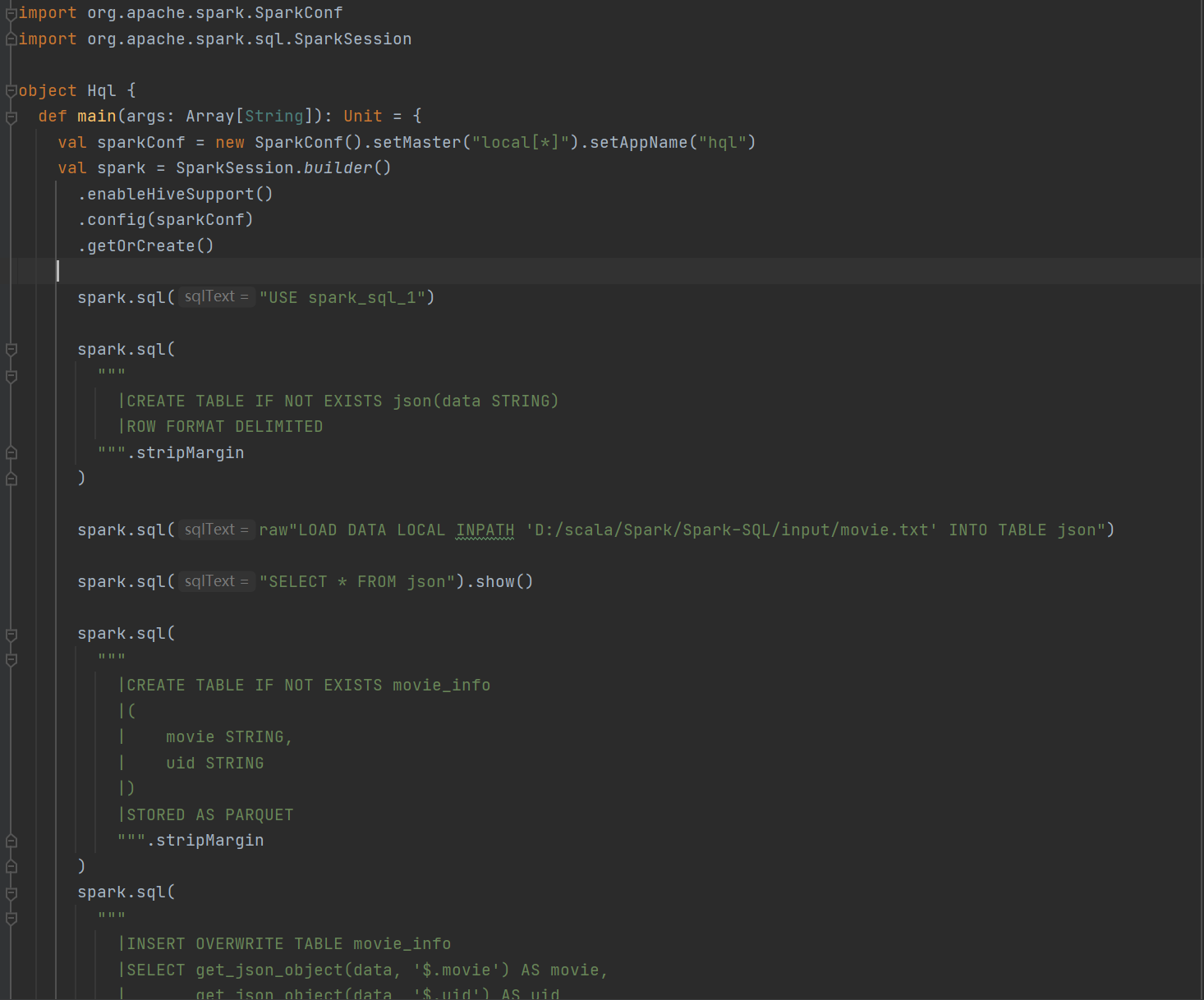
- 代码如图
1)进行数据转换,创建表、加载数据、查询数据进行数据转换
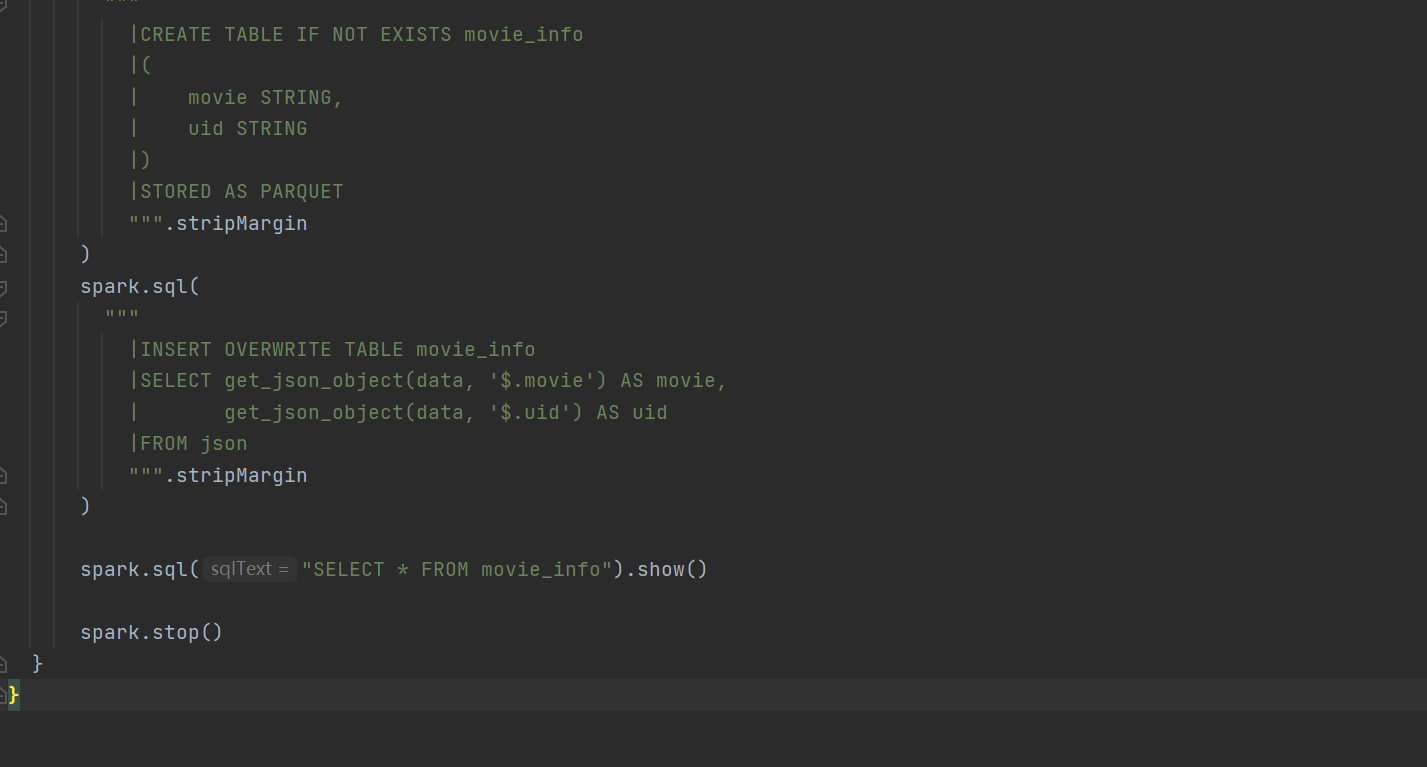
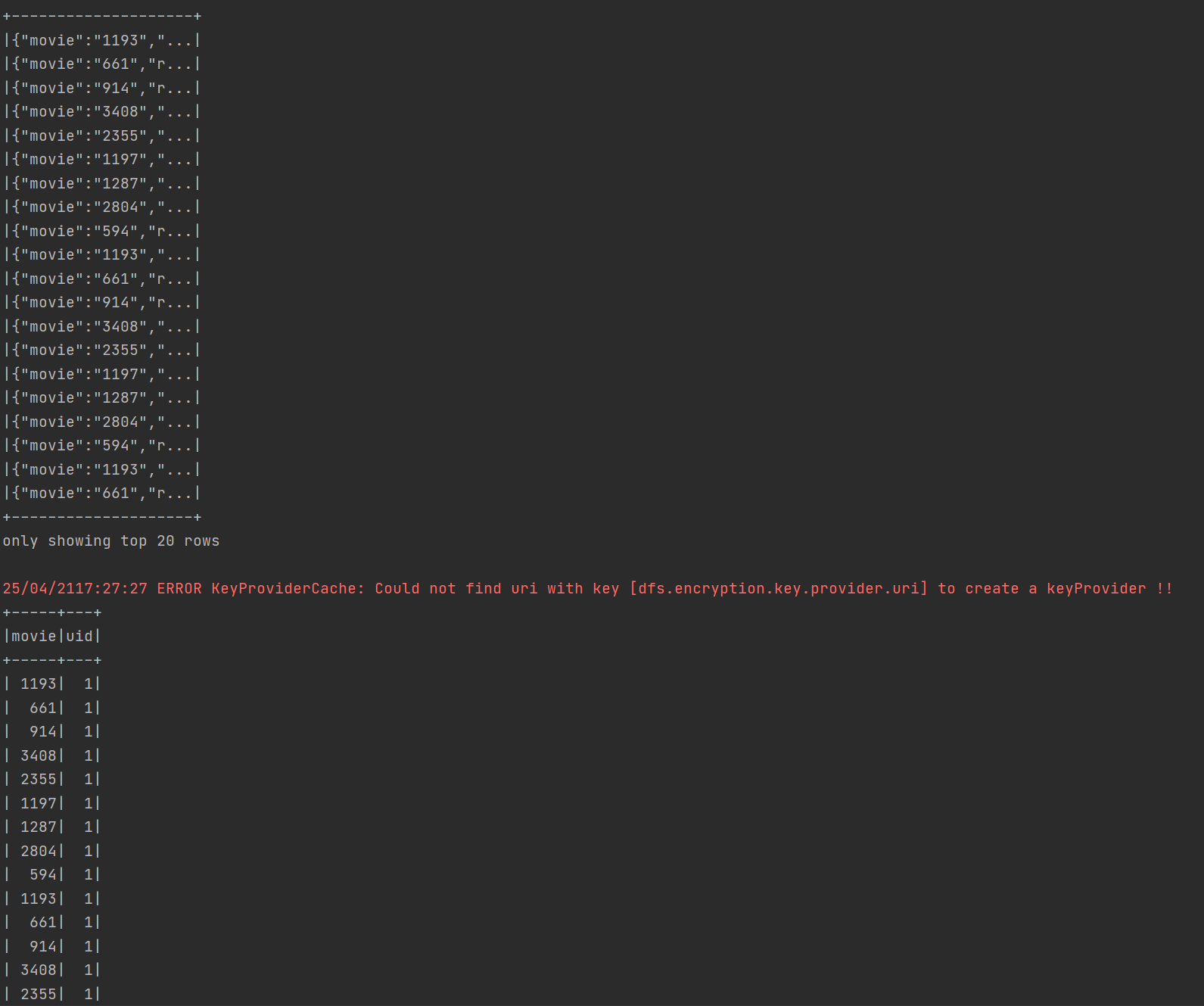
运行结果
二 spark-sql实验
实验内容:统计有效数据条数 及用户数量最多的前二十个地址。
实验过程:
1 先将需要用的user_login_info.json文件放到Spark-SQL/input目录下
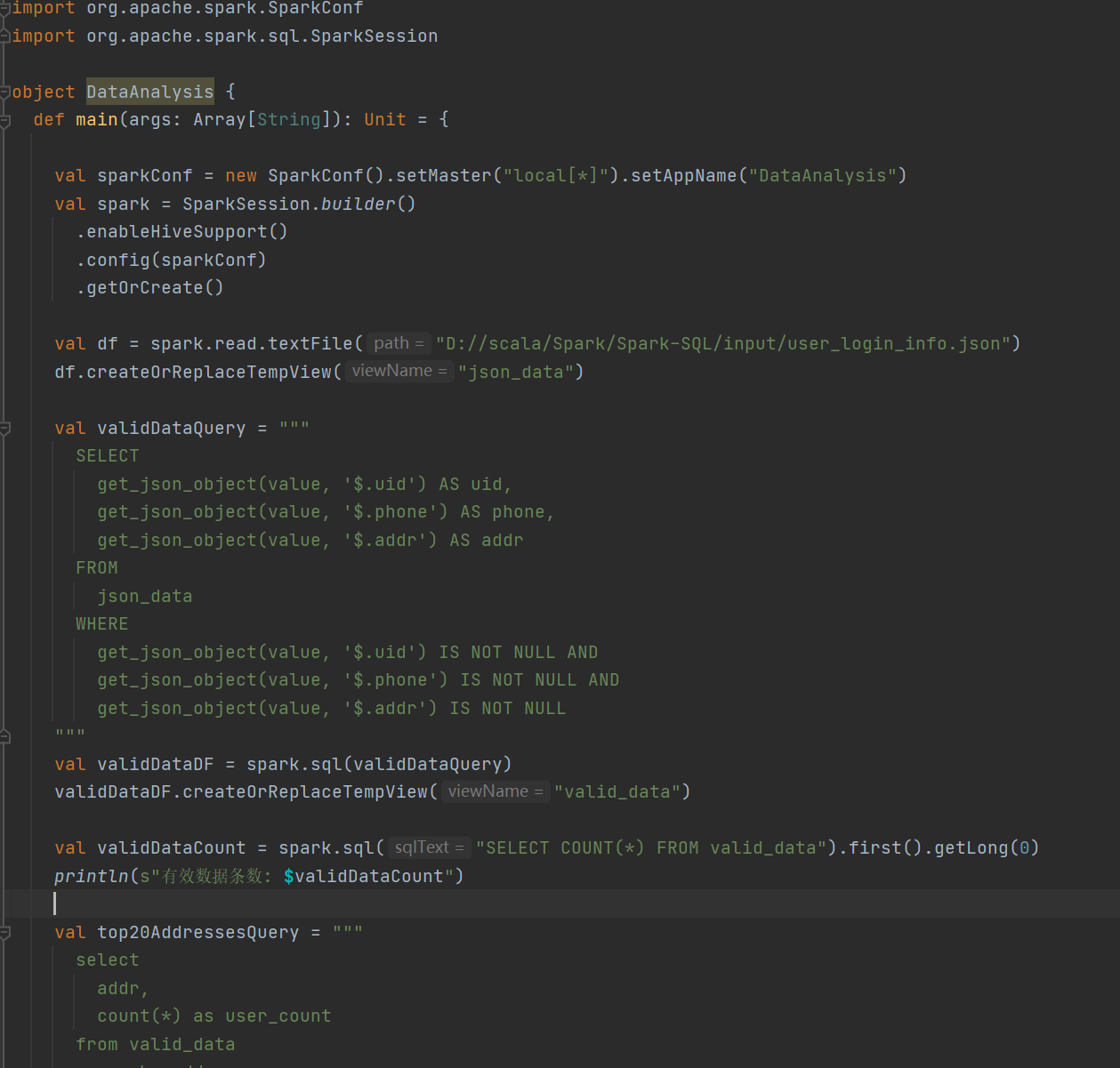
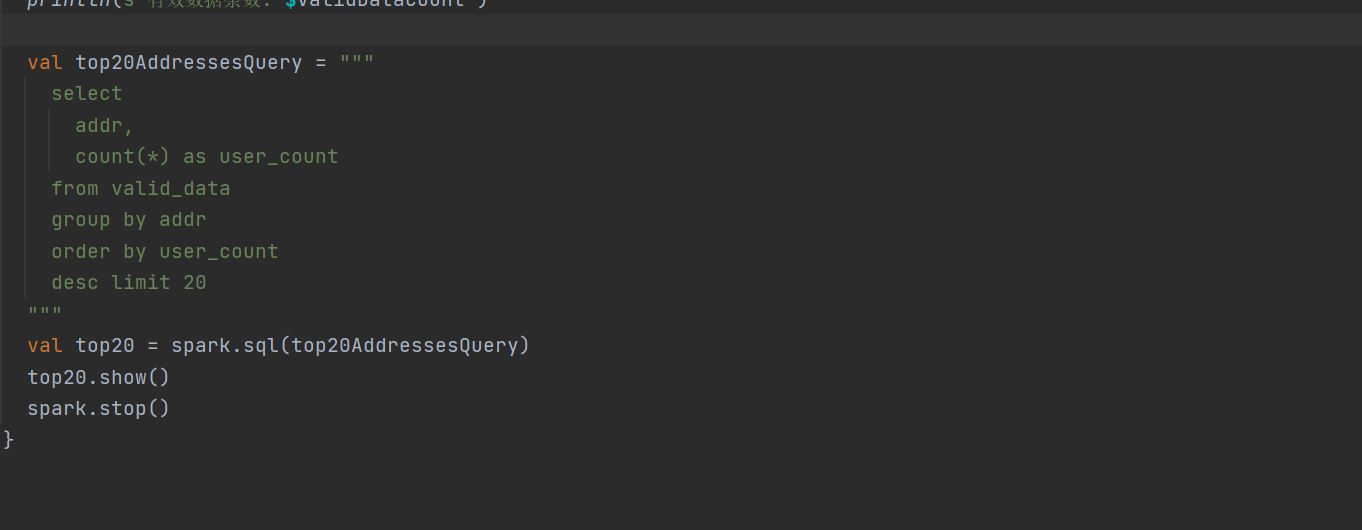
2 运行代码
统计有效数据条数及用户数量最多的前二十个地址。
运行结果
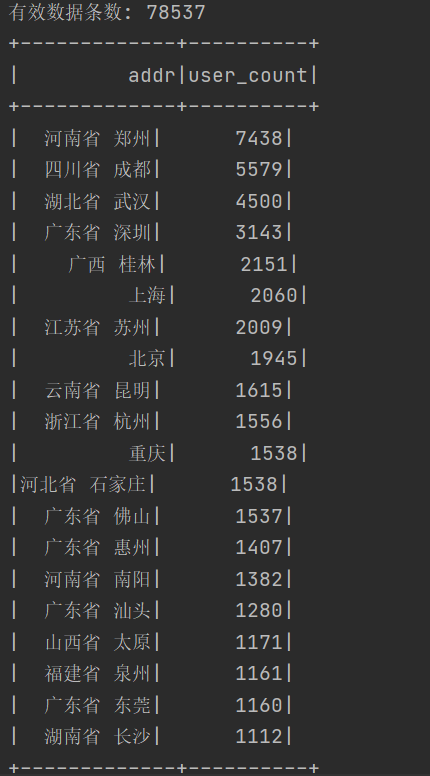
可以得到文件中有效的数据有78537条,以及用户数量最多的前二十个地址。