深度学习与机器学习的关系,如同摩天大楼与地基------前者是后者的高阶延伸,但能否绕过地基直接造楼?本文从技术本质、学习曲线、应用场景三个维度剖析这一关键问题。
一、技术血脉的承继关系
-
概念体系同源:
-
损失函数、梯度下降、过拟合等核心概念在两者中通用
-
交叉验证、ROC曲线等评估方法完全一致
-
典型案例:反向传播算法是深度学习的基础,但其数学原理继承自传统神经网络的优化思想
-
-
算法演进路径:
-
决策树 → 随机森林 → GBDT(机器学习主线)
-
感知机 → CNN → Transformer(深度学习主线)
-
关键差异:深度学习通过端到端学习自动提取特征,传统机器学习依赖人工特征工程
-
二、绕过机器学习的三大风险
-
黑箱操作陷阱:
-
仅调参不究理:无法解释Batch Normalization为何能加速收敛
-
遇到梯度消失时,不理解Xavier初始化的数学推导
-
-
场景误用危机:
-
在小样本场景强用BERT,不如逻辑回归+TF-IDF效果稳定
-
结构化数据场景中,XGBoost常比DNN更高效
-
-
职业发展瓶颈:
-
面试中被追问KL散度与交叉熵的区别时哑口无言
-
无法将胶囊网络的设计思想迁移到传统模型优化
-
三、高效学习的阶梯策略
1. 最小必要知识包(30小时):
-
掌握线性回归推导(理解损失函数与优化)
-
手推逻辑回归的交叉熵损失(激活函数的意义)
-
实践K-means聚类(无监督学习思维)
2. 深度学习直通路径:
-
第1周:用PyTorch实现MNIST分类(掌握张量操作与自动求导)
-
第2周:复现ResNet-18(理解残差连接与模型深度)
-
第3周:BERT文本分类实战(迁移学习与微调技巧)
3. 并行补强机制:
-
每学完一个深度学习模块,回溯对应的机器学习知识(如学完CNN后补SVM核方法)
-
在Kaggle比赛中交叉使用两种技术(如用XGBoost处理结构化数据,CNN处理图像数据)
四、分场景决策指南
-
CV/NLP方向:可快速切入深度学习,但需同步补足概率论与优化理论
-
量化金融/风控领域:必须精通随机森林、GBDT等传统算法
-
科研创新:需深入矩阵分解、概率图模型等数学密集型知识
关键结论:
-
时间充裕者:按机器学习→深度学习的顺序构建完整知识体系
-
项目驱动者:采用"需求倒逼学习"模式,在实战中查漏补缺
-
终极法则:用机器学习思维理解深度学习(如将LSTM视为特征提取器),用深度学习框架重构传统算法(如PyTorch实现K-means)
工业界真实案例:某电商团队新人直接使用LSTM预测销售额,因未考虑季节性因素导致效果不如ARIMA模型。这印证了工具再先进也需方法论指导------掌握机器学习的"第一性原理",才能在深度学习的浪潮中避免成为调参民工。
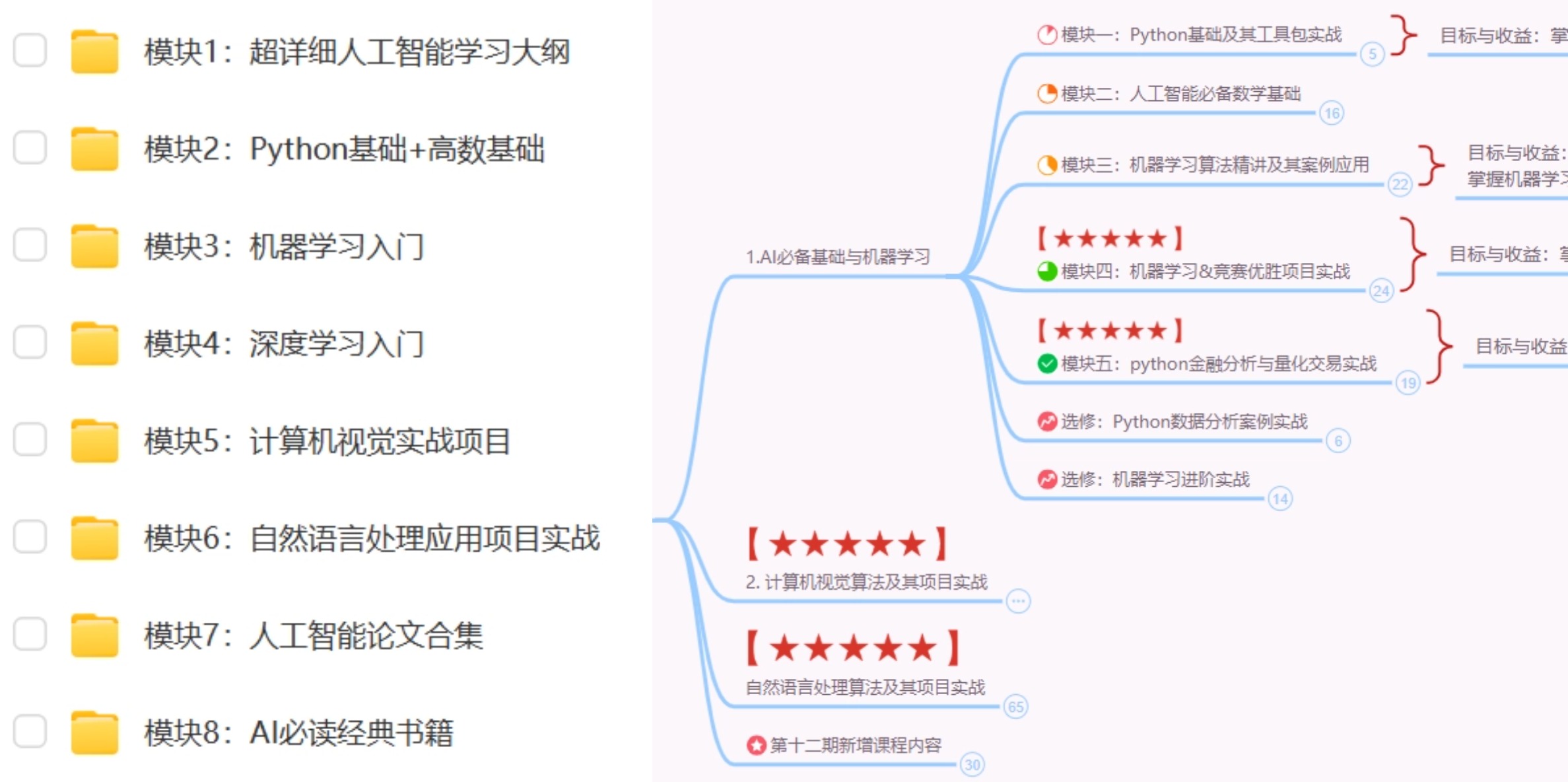 我这里有一份200G的人工智能资料合集:内含:990+可复现论文、写作发刊攻略,1v1论文辅导、AI学习路线图、视频教程等,扫描下方即可获取到!
我这里有一份200G的人工智能资料合集:内含:990+可复现论文、写作发刊攻略,1v1论文辅导、AI学习路线图、视频教程等,扫描下方即可获取到!