目录
设计思路
本模块就是设计一个HttpServer模块,提供便携的搭建http协议的服务器的方法。那么这个模块需要如何设计呢? 这还需要从Http请求说起。
首先从http请求的请求行开始分析,请求行里面有个方法。分为静态资源请求 和功能性请求的。
静态资源请求顾名思义就是用来获取服务器中的某些路径下的实体资源,比如文件的内容等,这一类请求中,url 中的资源路径必须是服务器中的一个有效的存在的文件路径。比如:
- HTML/CSS/JavaScript文件
- 图片(JPG、PNG、GIF等)
- 视频和音频文件
- PDF、文档等静态文件
- 字体文件
而如果提取出来的资源路径并不是一个实体文件的路径,那么他大概率是一个功能性请求,这时候就有用户来决定如何处理这个请求了,也就是我们前面说过的 请求路径 和 处理方法的路由表。
功能性请求如下
- 用户登录/注册
- 商品搜索结果
- 个人资料页面
- 订单处理
- API接口调用
- 数据统计和报表生成
但是还有一种特殊的情况就是资源路径是一个目录,比如 / ,这时候有可能是一个访问网站首页的请求,所以我们需要判断在这个路径后面加上 index.html(也可以是其他的文件名,取决于你的网站的首页的文件名) ,如果加上之后,路径有效且存在实体文件,那么就是一个静态资源请求,如果还是无效,那么就是一个功能性请求。
而功能性请求如何处理呢?这是由使用或者说搭建服务器的人来决定的。 用户未来想要提供某些功能,可以让他和某个虚拟的目录或者说特定的路径绑定起来。 比如提供一个登录功能,那么用户可以规定 /login 这个路径就代表登录的功能,未来如果收到了一个请求资源路径是 /login ,那么就不是请求实体资源,而是调用网站搭建者提供的登录的方法进行验证等操作。 一般来说这些虚拟路径不会和实体资源路径冲突。
同时,对于这种功能性请求对应的路径,他并不是说一个路径只能有一个功能,不同的请求方法,同一个路径,最终执行的方法也可以是不同的,这具体还是要看使用者的设定。
所以为了维护这样的功能性路径和需要执行的方法之间的映射关系,我们需要为每一种请求方法都维护一张路由表,路由表中其实就是保存了路径和所需要执行的方法之间的映射关系。
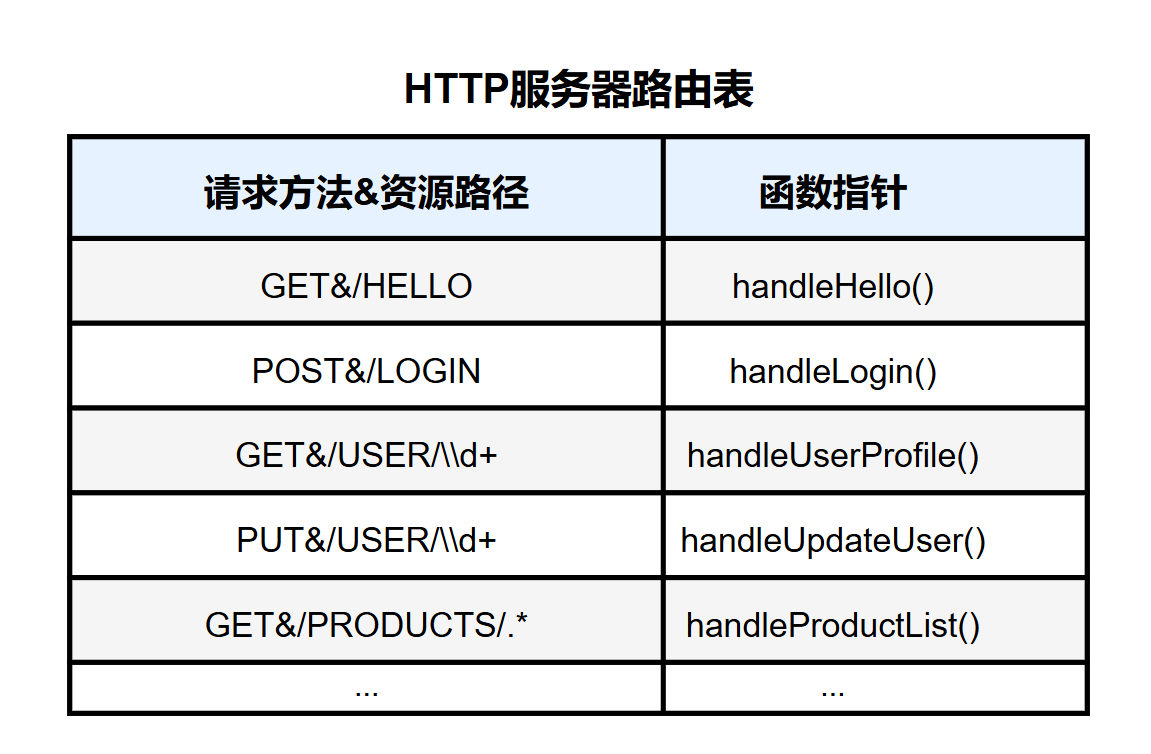
在我们这里,就只考虑常用的五种方法,get,post,delete,head,put,其他的暂时就不提供支持了
cpp
//五张路由表
using Handler = std::function<void(const HttpRequest&,HttpResponse*)>;
using HandlerTable = std::unordered_map<std::string,Handler>;
HandlerTable _get_route;
HandlerTable _post_route;
HandlerTable _head_route;
HandlerTable _put_route;
HandlerTable _delete_route;这是交给用户进行设置的,我们也会提供五个接口给用户用来添加处理方法。
但是,这样的表真的好吗?
在实际的应用中,比如有以下的功能性请求的请求路径 , /login1213 , /login12124 , /login1213626 , /login12152 , /login1295 , /login1275,对于这样的一类路径,他们其实需要执行的是同一个方法,而并不需要为每一个类似的路径设置一个方法,而路径后半部分的数字其实后续可以当成参数来用。
那么综上所述,我们的路由表中作为 key 值的并不是 std::string ,而是只需要满足某一种匹配要求的路径,都可以执行某一方法,那么作为 key 值的其实是正则表达式。
cpp
using HandlerTable = std::unordered_map<std::regex,Handler>;但是如果我们编译一下就会发现,正则表达式是不能作为哈希的 key 值的,或者说不匹配默认的哈希函数。
我们可以思考一下,我们用正则表达式作为 key 了,那么后面不管使用何种数据结构来存储正则表达式和操作方法的映射关系,我们都是要遍历整个路由表的,需要遍历表中的所有的正则表达式,然后拿着我们的路径来进行正则匹配,匹配上了就说明这是我们要找的方法,如果匹配不上就说明不是,不管怎么样,都是要进行遍历,那么其实我们直接用数组来存储也是一样的。
所以最终我们使用 vector 来存储用户方法。
cpp
using HandlerTable = std::vector<std::pair<std::regex,Handler>>;而HttpServer模块中除了五张路由表,还需要一个TcpServer对象,这是毋庸置疑的。 同时还需要保存一个网页根目录,这个根目录是要交给用户设置的,由使用者决定。
cpp
//支持Http协议的服务器
class HttpServer
{
private:
TcpServer _server;
std::string _base_path; //网页根目录
//五张路由表
using Handler = std::function<void(const HttpRequest&,HttpResponse*)>;
using HandlerTable = std::vector<std::pair<std::regex,Handler>>;
HandlerTable _get_route;
HandlerTable _post_route;
HandlerTable _head_route;
HandlerTable _put_route;
HandlerTable _delete_route;
public:
};类的设计
那么需要哪些接口呢?
首先需要提供给用户的五个设置功能方法的接口,以及设置网页根目录和服务器线程数的接口。
还需要提供给用户是否开启超时释放,以及启动服务器的接口。
提供给用户的接口就这么多,其实都很简单,难的是私有的一些接口:
首先,未来拿到一个完整请求之后,我们需要能够判断这个请求是静态资源请求还是功能性请求。
- 如果是资源性请求我们需要怎么做?
- 如果是功能性请求我们有需要怎么做?
最后还需要将相应组织成一个tcp报文进行回复。
同时还需要提供未来设置给TcpServer的连接建立和新数据到来的回调方法,这两个方法是必需的,因为在连接建立时我们必须要设置上下文 ,在新数据到来时必须要有逻辑来决定怎么处理。
cpp
class HttpServer {
public:
//构造函数
HttpServer();
// 配置设置类方法
void SetBaseDir(); // 设置静态资源路径的根目录
void SetThreadCount(); // 设置线程数量
void Listen(); //开始监听
// 路由设置方法
void Get(); // 设置GET方法
void Post(); // 设置Post方法
void Put(); // 设置Put方法
void Delete(); // 设置Delete方法
void Head(); // 设置Head方法
private:
// 连接和消息处理回调
void OnConnected(); // 设置一个上下文
void OnMessage(); // 把请求报文从应用层缓冲区提取出来
// 请求处理和路由
bool IsFileHandler(); // 判断是否是静态资源请求
void Route(); // 通过请求类型分别进行处理
void Dispatcher(); // 功能性请求处理
void FileHandler(); // 静态资源请求处理
void ErrorHandler(); // 错误信息填充
void WriteResponse(); //把响应对象转换成响应报文并发送
};模块的实现
下面我将详细的讲解,这些模块都是干嘛的,让各位能有个更清晰的思路
公有接口
首先是设置静态资源路径根目录,这个是为了开发者设定的,因为用户在访问的时候,很大概率是不会加上根目录的,就好比你要在图片网站上找一个苹果的图片,对于网站来说他这个苹果肯定是分类在水果目录下面的,你在输入的时候大概率是直接apple.png,如果不进行设置默认根目录的话,那么肯定是找不到的,当你设置了根目录之后,你再输入apple.png的时候,它就会默认的变成fruit/apple.png了。
而开发者在进行设置的情况下,可能会出现粗心,比如说这个目录名字我少写了一个字母,所以这个函数需要先去寻找是否存在这个目录,要是不存在那就是开发者写错了,我要反馈给开发者,要是没写错我就设置传入的dir为根目录
cpp
void SetBasedir(const string &dir)
{
assert(Util::IsDirectory(dir) == true);
_basedir = dir;
}接着就是开发者设置下线程的数量了,直接就是传入要设置的count就行
cpp
void SetThreadPoolCount(int count)
{
_server.SetThreadCount(count);
}然后就是开始监听的接口了
cpp
void Listen() // 开始监听
{
_server.Start();
}接下来就是路由表的使用了,对不同的方法的路由表都设置相应的正则表达式模式字符串和对应的回调函数,当用户输入了对应的请求方法的时候就去对应的路由表里查找。至于如何定义,那就是开发者来自定义了
cpp
void Get(const string &pattern, const Handler &handler)
{
_get_route.push_back({regex(pattern), handler});
}
void Post(const string &pattern, const Handler &handler)
{
_post_route.push_back({regex(pattern), handler});
}
void Put(const string &pattern, const Handler &handler)
{
_put_route.push_back({regex(pattern), handler});
}
void Delete(const string &pattern, const Handler &handler)
{
_delete_route.push_back({regex(pattern), handler});
}最后就是构造函数的实现了,需要传入一个端口号来对我们内部的TcpServer对象进行初始化,然后包括三个内容,启动非活跃连接销毁,设置当连接来到的时候的回调函数用来设置上下文,以及把消息从缓冲区获取的回调函数
cpp
HttpServer(int port, int timeout = DEFAULT_TIMEOUT)
: _server(port)
{
// 启用非活跃连接释放
_server.EnableInactiveRelease(timeout);
// 设置连接回调函数
_server.SetConnectedCallback(
bind(&HttpServer::OnConnected, this, placeholders::_1)
);
// 设置消息回调函数
_server.SetMessageCallback(
bind(&HttpServer::OnMessage, this, placeholders::_1, placeholders::_2)
);
}私有接口
这些私有接口是由开发者去调用的,来设置一些信息,让使用者去更好的使用
首先是设置给新连接设置一个上下文,用于当连接被切换的时候保存其中的数据,当下次再切换回来的时候,能接着当前的数据继续进行操作,所以需要的参数就是一个新连接的引用,因为连接是会被放在TCP的全连接队列中的
cpp
void OnConnected(const PtrConnection &conn) // 设置一个上下文
{
conn->SetContext(HtppContext());
DBG_LOG("new connection %p", conn.get());
}接着是对于该新连接数据的提取,因为这些数据从TCP的接收缓冲区是先提取到用户态中的缓冲区的,但是因为TCP是面向字节流的,也就是在用户态的缓冲区存储的数据都是以字节的形式,但是我Http要的是报头,正文,请求行,这种类型的呀,所以肯定也是需要转换的也就是用到了context的模块,接着就是判断请求的状态码,如果是状态码大于400了,就说明错误了,此时就需要进行处理了,可能你开发者想这个时候给用户弹出一个错误网页,所以接下来就调用ErrorHandler函数,然后把这个错误响应回去,再重置下HTTP上下文,准备处理新的请求,然后把缓冲区更新下也就是清空缓冲区,接着就是关闭连接了。如果是正常的状态码就返回了
cpp
void OnMessage(const PtrConnection &conn, Buffer *buf) // 处理从客户端接收到的HTTP请求消息
{
while(buf->ReadAbleSize() > 0) // 只要缓冲区中还有可读数据就继续处理
{
HttpContext *context = conn->GetContext()->get<HttpContext>(); // 从连接上下文中获取HTTP上下文对象
context->RecvHttpRequest(buf); // 从缓冲区中解析HTTP请求数据
HttpRequest &req = context->GetRequest(); // 获取解析后的HTTP请求对象
HttpResponse rsp; // 创建HTTP响应对象
if(context->StatusCode() >=400) // 检查HTTP状态码,如果大于等于400表示出错
{
ErrorHandler(req,&rsp); // 调用错误处理函数生成错误响应
WriteResponse(conn,req,rsp); // 将错误响应写回客户端
context->Reset(); // 重置HTTP上下文,准备处理新的请求
buf->MoveReadIndex(buf->ReadAbleSize()); // 清空缓冲区中剩余的所有数据
conn->ShutDown(); // 关闭连接
}
return;
}
}可能会有同学问了,这里的context->Reset(); buf->MoveReadIndex(buf->ReadAbleSize()); 的是不是可以丢弃了,因为后面直接就是shutdown了
可以是可以但是这样是不规范的,释放链接是释放链接,在释放链接之前,我们正常去处理错误逻辑,将各个环节该置空的置空,该清理的清理,这是我们必须在代码中进行体现的,这才是一个好的代码习惯。并且来说,conn->shutdow还不是实际发送的逻辑,在后续还会进行一些判断的,所以上层该做的工作还是要做的
这个操作之后,我们也就解析了二进制的数据了,然后判断请求行的方法是什么类型的,是不是静态资源的请求。需要四步:首先需要判断有没有设置资源根目录。静态资源请求的方法必须是 GET 或者 HEAD ,因为其他的方法不是用来获取资源的。然后静态资源请求的路径必须是一个合法的路径。最后就需要判断请求的路径的资源是否存在。但是我们需要考虑路径是目录的时候,给它加上一个 index.html。最后就是判断文件是否存在
cpp
bool IsFileHandler(const HttpRequest &req)
{
// 1.查看设置了静态资源根目录
if(_basedir.empty())
return false;
// 2.请求方法必须是GET或HEAD
if(req._method != "GET" && req._method != "HEAD")
return false;
// 3.请求资源路径必须合法
if(Util::ValidPath(req._path) == false)
return false;
// 4.请求资源必须存在,且是一个普通文件
// 为防止修改路径,先复制一份
string req_path = _basedir + req._path;
// 先处理特殊情况:如果请求的是目录,就换成请求首页
if(req._path.back() == '/')
req_path += "index.html";
// 如果不是普通文件就错误
if(Util::IsRegular(req_path) == false)
return false;
return true;
}接下来我们举二个例子来更好的帮我们捋一捋思路
例子1: 正常的图片请求
- 用户访问
http://example.com/images/logo.png - 浏览器发送 GET 请求,路径为
/images/logo.png - 函数检查:
- 静态根目录已设置为
/var/www/html/ - 请求方法是 GET ✓
- 路径
/images/logo.png是合法的 ✓ - 文件
/var/www/html/images/logo.png存在且是普通文件 ✓
- 静态根目录已设置为
- 函数返回 true,服务器会提供这个图片文件
例子2: 请求目录
- 用户访问
http://example.com/blog/ - 浏览器发送 GET 请求,路径为
/blog/ - 函数检查:
- 静态根目录已设置 ✓
- 请求方法是 GET ✓
- 路径
/blog/是合法的 ✓ - 检测到路径以
/结尾,自动添加index.html - 检查
/var/www/html/blog/index.html是否存在 - 如果存在,返回 true;如果不存在,返回 false
接下来就是开发者对于路由表的规则的设置了,首先就是判断是什么类型的请求,如果是静态资源请求就调用静态资源的处理方法,如果是功能性的请求就匹配路由表中的方法,并且对不同方法设置不同的请求,如果两种请求都不是就说明是错的了
cpp
// 通过请求类型分别处理
void Route(HttpRequest &req, HttpResponse *rsp)
{
// 是静态资源请求就静态资源处理
if(IsFileHandler(req) == true)
return FileHandler(req, rsp);
// 动态性请求就动能性请求处理
if(req._method == "GET" || req._method == "HEAD")
return Dispatcher(req, rsp, _get_route);
else if(req._method == "POST")
return Dispatcher(req, rsp, _post_route);
else if(req._method == "PUT")
return Dispatcher(req, rsp, _put_route);
else if(req._method == "DELETE")
return Dispatcher(req, rsp, _delete_route);
// 两个都不是就返回405 METHOD NOT ALLOWED
rsp->_status = 405;
return;
}接下来就是对静态资源请求的处理,首先构造一个完整的文件路径,然后如果结尾是/就说明是访问的首页,然后把路径读响应到正文中,如果文件读取失败就说明错误了。然后用ExtMime把路径中的最后一部分给分离出来,然后填入到响应报头的Content-type中
cpp
// 静态资源请求处理
void FileHandler(const HttpRequest &req, HttpResponse *rsp) // 处理静态文件请求的函数
{
// 读取静态文件资源,放到rsp的body,并设置mime
// 判断里面没有修改资源路径,所以在这里要修改
string req_path = _basedir + req._path; // 构造完整的文件路径
if(req._path.back() == '/') // 如果请求路径以'/'结尾(请求的是目录)
req_path += "index.html"; // 自动添加index.html作为默认页面
bool ret = Util::ReadFile(req_path, &rsp->_body); // 读取文件内容到响应体
if(ret == false) // 如果文件读取失败
return; // 直接返回,不设置任何响应内容
string mime = Util::ExtMime(req_path); // 根据文件扩展名获取MIME类型
rsp->SetHeader("Content-type", mime); // 设置Content-type响应头
return; // 处理完成,返回
}接下来几个例子,帮助大家理解
假设用户通过浏览器访问你的网站,请求了以下几个不同的资源:
- HTML页面请求 :
- 用户访问
http://yourwebsite.com/about.html - 服务器找到
about.html文件 ExtMime函数确定这是HTML文件,返回text/html- 服务器在响应头中设置
Content-type: text/html - 浏览器收到响应后,看到这个MIME类型,知道应该将内容解析为HTML并渲染网页
- 用户访问
- 图片请求 :
- 当HTML页面中引用了图片
<img src="logo.png"> - 浏览器请求
http://yourwebsite.com/logo.png - 服务器找到
logo.png文件 ExtMime函数确定这是PNG图片,返回image/png- 服务器在响应头中设置
Content-type: image/png - 浏览器看到这个MIME类型,知道应该将内容解析为PNG图片并显示
- 当HTML页面中引用了图片
接着就是对动态请求的处理。先循环遍历路由表表里面正则表达式是否匹配请求对象的资源路径,以找到对应的处理函数填充响应对象,如果找不到就是404
cpp
// 功能性请求处理
void Dispatcher(HttpRequest &req, HttpResponse *rsp, Handlers &handlers) // 处理动态请求的分发器函数
{
// 循环遍历路由表表里面正则表达式是否匹配请求对象的资源路径,以找到对应的处理函数填充响应对象
for(auto &handler :handlers) // 遍历所有注册的处理器
{
const regex &e = handler.first; // 获取当前处理器的正则表达式
const Handler &func = handler.second; // 获取当前处理器的处理函数
bool ret = regex_match(req._path, req._matches, e); // 尝试匹配请求路径与正则表达式
if(ret == false) // 如果不匹配
continue; // 继续检查下一个处理器
return func(req, rsp); // 找到匹配的处理器,调用对应的处理函数并返回
}
// 找不到就是404
rsp->_status = 404; // 设置HTTP状态码为404(未找到)
}接着就是把响应对象转换成响应报文并发送。思路就是先把报头完善一下,也就是进行判断是短链接就把字段的Connection设置为close,否则就设置成keep-alive,然后判断Content-Length有没有填,ContentType应该填什么。要是重定向的话,就更新Location字段为重定向的url,这些都是必要的条件。当完成了这些之后,就可以构建响应报文了完善响应行,响应报头,添加空行,添加响应正文,最后就是发送响应报文
cpp
// 把响应对象转化成响应报文并发送
void WriteResponse(const PtrConnection &conn, const HttpRequest &req, HttpResponse &rsp) // 将HTTP响应对象序列化为HTTP报文并发送
{
// 1.完善报头
if(req.Close() == true) // 如果请求要求关闭连接
rsp.SetHeader("Connection", "close"); // 设置Connection头为close
else
rsp.SetHeader("Connection", "keep-alive"); // 否则设置为keep-alive保持连接
if(rsp._body.empty() == false && rsp.HasHeader("Content-Length") == false) // 如果响应体不为空且没有设置Content-Length头
rsp.SetHeader("Content-Length", to_string(rsp._body.size())); // 设置Content-Length头为响应体大小
if(rsp._body.empty() == false && rsp.HasHeader("Content-Type") == false) // 如果响应体不为空且没有设置Content-Type头
rsp.SetHeader("Content-Type", "application/octet-stream"); // 设置默认的Content-Type为二进制流
if(rsp._redirect_flag = true) // 如果需要重定向
rsp.SetHeader("Location", rsp._redirect_url); // 设置Location头指向重定向URL
// 2.组织响应报文
stringstream rsp_str; // 创建字符串流用于构建HTTP响应
// 响应行
rsp_str << req._version << " " << to_string(rsp._status) << " " << Util::StatusDesc(rsp._status) << "\r\n"; // 构建状态行
// 响应报头
for(auto &head : rsp._headers) // 遍历所有响应头
{
rsp_str << head.first << ": " << head.second << "\r\n"; // 添加每个响应头到响应中
}
// 一个空行
rsp_str << "\r\n"; // 添加空行分隔响应头和响应体
// 响应正文
rsp_str << rsp._body; // 添加响应体
// 3.发送响应报文
conn->Send(rsp_str.str().c_str(), rsp_str.str().size()); // 发送完整的HTTP响应
}最后就是设置错误信息,如果这个路径是错误的,应该给用户返回什么
cpp
void ErrorHandler(const HttpRequest &req, HttpResponse *rsp) // 处理HTTP错误的函数
{
string body; // 创建一个字符串用于构建HTML错误页面
body += "<html>"; // HTML文档开始标签
body += "<head>"; // 头部开始标签
body += "<meta http-equiv='Content-Type' content='text/html;charset=utf-8'>"; // 设置页面元数据,指定内容类型和字符集
body += "</head>"; // 头部结束标签
body += "<body>"; // 正文开始标签
body += "<h1>"; // 一级标题开始标签
body += std::to_string(rsp->_status); // 添加HTTP状态码
body += " "; // 添加空格
body += Util::StatusDesc(rsp->_status); // 添加HTTP状态码的描述文本
body += "</h1>"; // 一级标题结束标签
body += "</body>"; // 正文结束标签
body += "</html>"; // HTML文档结束标签
// 响应正文类型是html
rsp->SetContent(body, "text/html"); // 设置响应内容为HTML并指定MIME类型
}疑问点
std::regex确实不能直接用作std::unordered_map的键

http不是管理的是协议的请求和响应吗 这个 void OnConnect(const PtrConnection& conn) 连接不是应该由tcp去处理吗?

"请求可能分多个TCP包到达,需要有地方存储部分解析的数据,这个地方就是上下文" 那这个数据不是存储在用户的缓冲区当中的吗?

HttpContext *context = conn->GetContext()->get<HttpContext>(); 这个代码不懂
