一 .Spark-SQL核心编程(六)
Spark-SQL连接Hive
Apache Hive 是 Hadoop 上的 SQL 引擎,Spark SQL 编译时可以包含 Hive 支持,也可以不包含。包含 Hive 支持的 Spark SQL 可以支持 Hive 表访问、UDF (用户自定义函数)、Hive 查询语言(HQL)等。需要强调的一点是,如果要在 Spark SQL 中包含Hive 的库,并不需要事先安装 Hive。一般来说,最好还是在编译 Spark SQL 时引入 Hive支持,这样就可以使用这些特性了。
使用方式分为内嵌Hive、外部Hive、Spark-SQL CLI、Spark beeline 以及代码操作。
1、内嵌的 HIVE
如果使用 Spark 内嵌的 Hive, 则什么都不用做, 直接使用即可。但是在实际生产活动当中,几乎没有人去使用内嵌Hive这一模式。
2、外部的 HIVE
在虚拟机中下载以下配置文件:

如果想在spark-shell中连接外部已经部署好的 Hive,需要通过以下几个步骤:
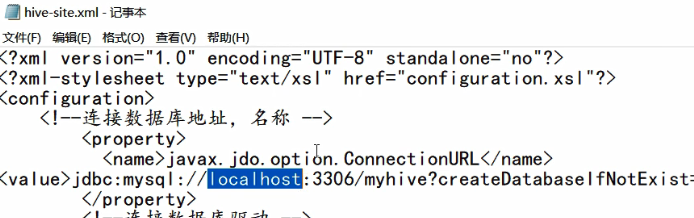
① Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下,并将url中的localhost改为node01

② 把 MySQL 的驱动 copy 到 jars/目录下

③ 把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
④ 重启 spark-shell
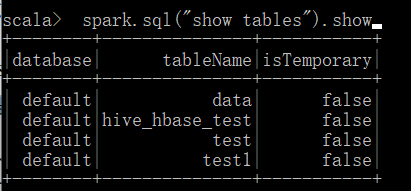
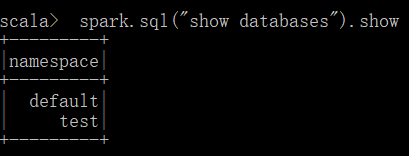
3、运行 Spark beeline(了解)
Spark Thrift Server 是 Spark 社区基于 HiveServer2 实现的一个 Thrift 服务。旨在无缝兼容HiveServer2。因为 Spark Thrift Server 的接口和协议都和 HiveServer2 完全一致,因此我们部署好 Spark Thrift Server 后,可以直接使用 hive 的 beeline 访问 Spark Thrift Server 执行相关语句。Spark Thrift Server 的目的也只是取代 HiveServer2,因此它依旧可以和 Hive Metastore进行交互,获取到 hive 的元数据。如果想连接 Thrift Server,需要通过以下几个步骤:
Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下
把 Mysql 的驱动 copy 到 jars/目录下
把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
启动 Thrift Server
使用 beeline 连接 Thrift Server
beeline -u jdbc:hive2://node01:10000 -n root
4、运行Spark-SQL CLI
Spark SQL CLI 可以很方便的在本地运行 Hive 元数据服务以及从命令行执行查询任务。在 Spark 目录下执行如下命令启动 Spark SQL CLI,直接执行 SQL 语句,类似于 Hive 窗口。
操作步骤:
将mysql的驱动放入jars/当中;
将hive-site.xml文件放入conf/当中;
运行bin/目录下的spark-sql.cmd 或者打开cmd,在
D:\spark\spark-3.0.0-bin-hadoop3.2\bin当中直接运行spark-sql

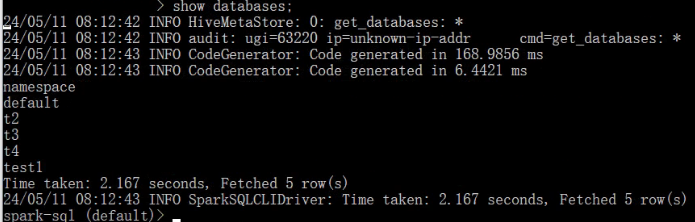
可以直接运行SQL语句,如下所示:
5、代码操作Hive
①、 导入依赖。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.3.3</version>
</dependency>
可能出现下载jar包的问题:
D:\maven\repository\org\pentaho\pentaho-aggdesigner-algorithm\5.1.5-jhyde
②、将hive-site.xml 文件拷贝到项目的 resources 目录中。
③、代码实现。
val sparkConf = new SparkConf().setMaster("local\*").setAppName("hive")
val spark:SparkSession = SparkSession.builder()
.enableHiveSupport()
.config(sparkConf)
.getOrCreate()
spark.sql("show databases").show()
spark.sql("create database spark_sql")
spark.sql("show databases").show()
注意:
如果在执行操作时,出现如下错误:
可以在代码最前面增加如下代码解决:
System.setProperty("HADOOP_USER_NAME", "node01")
此处的 node01 改为自己的 hadoop 用户名称
在开发工具中创建数据库默认是在本地仓库,通过参数修改数据库仓库的地址: config("spark.sql.warehouse.dir","hdfs://node01:9000/user/hive/warehouse")
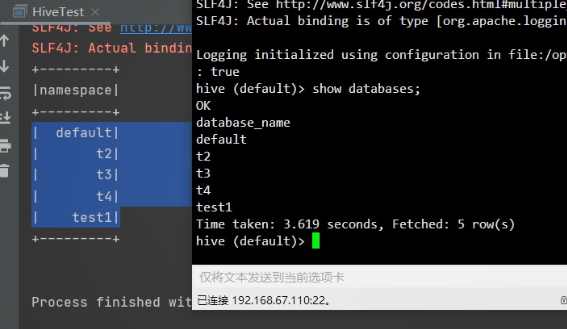
另
运行代码可以得出以下结果:
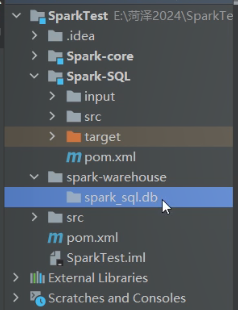
但其实数据库位置是在windows本地上面,如下所示:
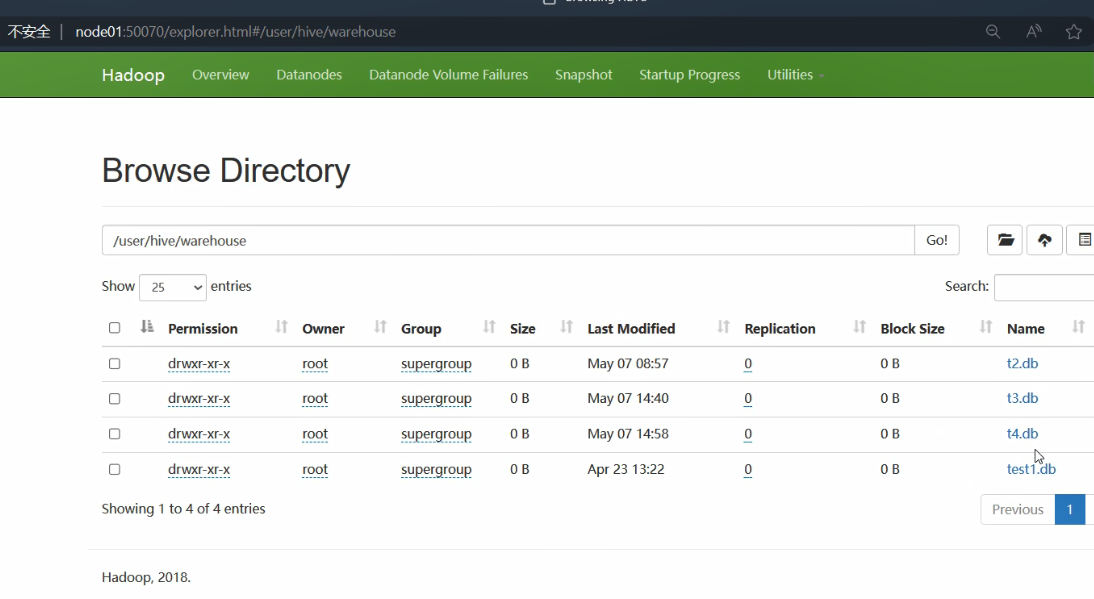
但是虚拟机里面只有四个数据库,如下图所示:
为了解决该问题,需要重新设置一下配置:
val spark = SparkSession.builder()
.enableHiveSupport()
.config("spark.sql.warehouse.dir","hdfs://node01:9000/user/hive/warehouse")
.config(sparkConf)
.getOrCreate()
之后再次创建数据库sqark_sql_1,就成功了
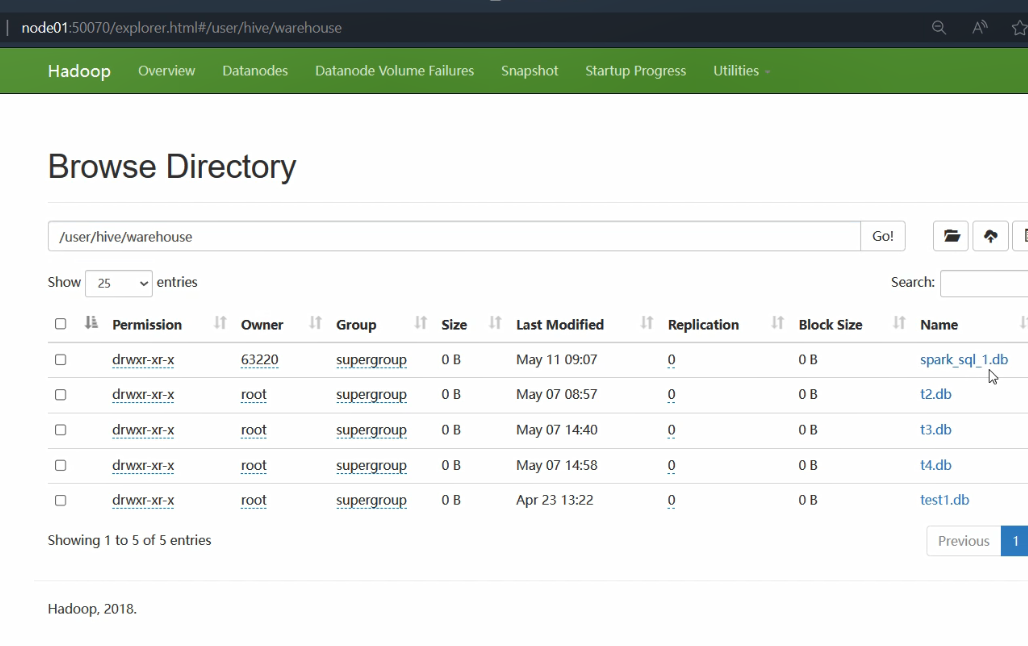
63220是本地的数据库名称,不是虚拟机的