SparkSQL 子查询 IN/NOT IN 对 NULL 值的处理
官网:https://spark.apache.org/docs/4.0.0/sql-ref-functions.html
https://spark.apache.org/docs/4.0.0/sql-ref-null-semantics.html#innot-in-subquery
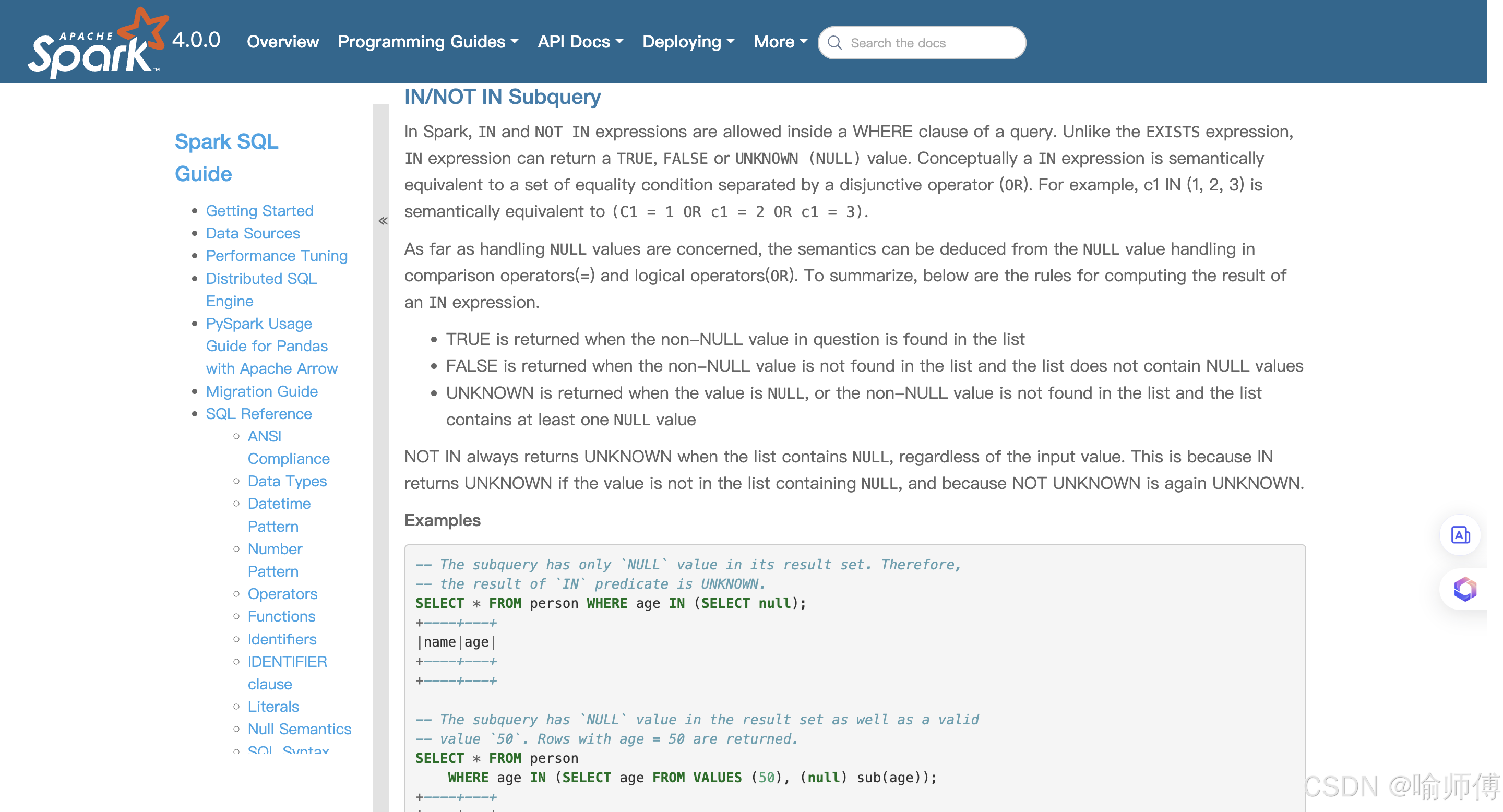
Unlike the
EXISTSexpression,INexpression can return aTRUE,FALSEorUNKNOWN (NULL)value.与
EXISTS不同,IN表达式可能返回三种布尔状态:
TRUE:当前值在集合中;FALSE:当前值不在集合中;UNKNOWN(即NULL):当表达式中涉及了NULL值时,无法确定真假。
Conceptually a
INexpression is semantically equivalent to a set of equality condition separated by a disjunctive operator (OR).For example,c1 IN (1, 2, 3)is semantically equivalent to(c1 = 1 OR c1 = 2 OR c1 = 3).
从语义上讲,IN 表达式等价于多个等于条件用 OR 连接起来。
c1 IN (1, 2, 3)相当于:
c1 = 1 OR c1 = 2 OR c1 = 3As far as handling
NULLvalues are concerned, the semantics can be deduced from theNULLvalue handling in comparison operators(=) and logical operators(OR).
对于 NULL 值的处理方式,可以基于比较运算符(如 =)和逻辑运算符(如 OR)的行为来推导。 也就是说,IN 的行为是建立在底层 SQL 对 NULL 处理规则之上的。
To summarize, below are the rules for computing the result of an
INexpression.
TRUEis returned when the non-NULL value in question is found in the listFALSEis returned when the non-NULL value is not found in the list and the list does not containNULLvaluesUNKNOWNis returned when the value isNULL, or the non-NULL value is not found in the list and the list contains at least oneNULLvalue
IN 表达式的计算规则如下:
| 情况 | 结果 |
|---|---|
| 当前值不为 NULL,并且存在于列表中 | TRUE |
| 当前值不为 NULL,但不在列表中,且列表中没有 NULL值 | FALSE |
| 当前值为 NULL,或者列表中有 NULL值但当前值不在其中 | UNKNOWN |
只要列表中包含 NULL,即使当前值不在列表中,也不能简单地返回 FALSE,而是返回 UNKNOWN。
IN Demo:
1:子查询结果只有 NULL
%sql
WITH person AS (
SELECT * FROM VALUES
('a', 25),
('b', 30),
('c', 35),
('d', 40),
('e', 50),
('d', 50)
AS person(name, age)
)
SELECT * FROM person
WHERE age IN (SELECT null);空表✅
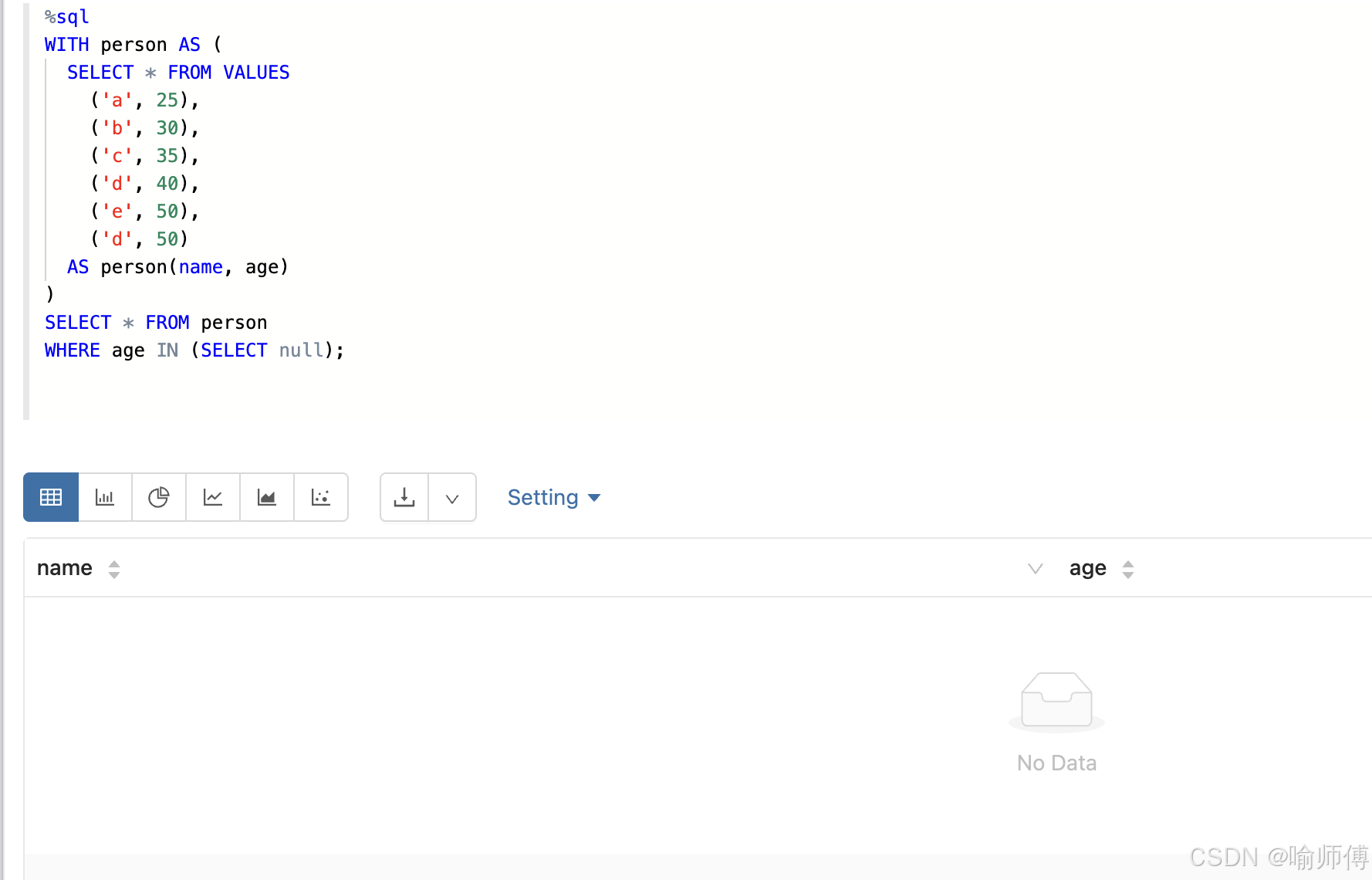
IN (NULL)返回的是UNKNOWN,不会匹配任何行。
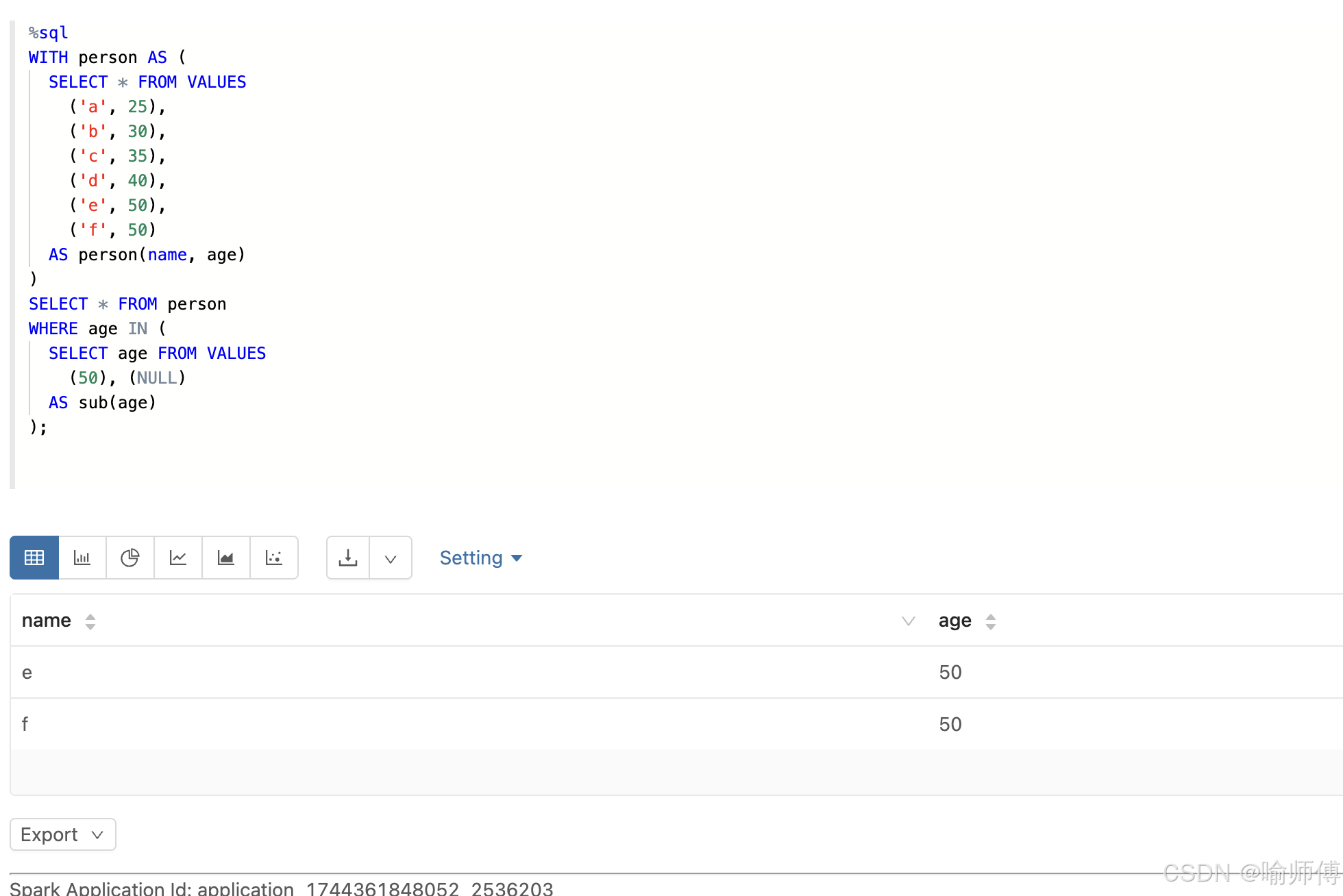
2:子查询包含 NULL 和有效值
%sql
WITH person AS (
SELECT * FROM VALUES
('a', 25),
('b', 30),
('c', 35),
('d', 40),
('e', 50),
('f', 50)
AS person(name, age)
)
SELECT * FROM person
WHERE age IN (
SELECT age FROM VALUES
(50), (NULL)
AS sub(age)
);
-- 虽然子查询里有 NULL,但只要匹配到具体值就会返回;只有 age = 50 的记录被选中。
3:子查询包含 NULL 和多个值
%sql
WITH person AS (
SELECT * FROM VALUES
('a', 25),
('b', 30),
('c', 35),
('d', 40),
('e', 50),
('f', 50)
AS person(name, age)
)
SELECT * FROM person
WHERE age IN (
SELECT age FROM VALUES
(25), (30), (NULL)
AS sub(age)
);
-- 虽然子查询里有 NULL,但只要匹配到具体值就会返回;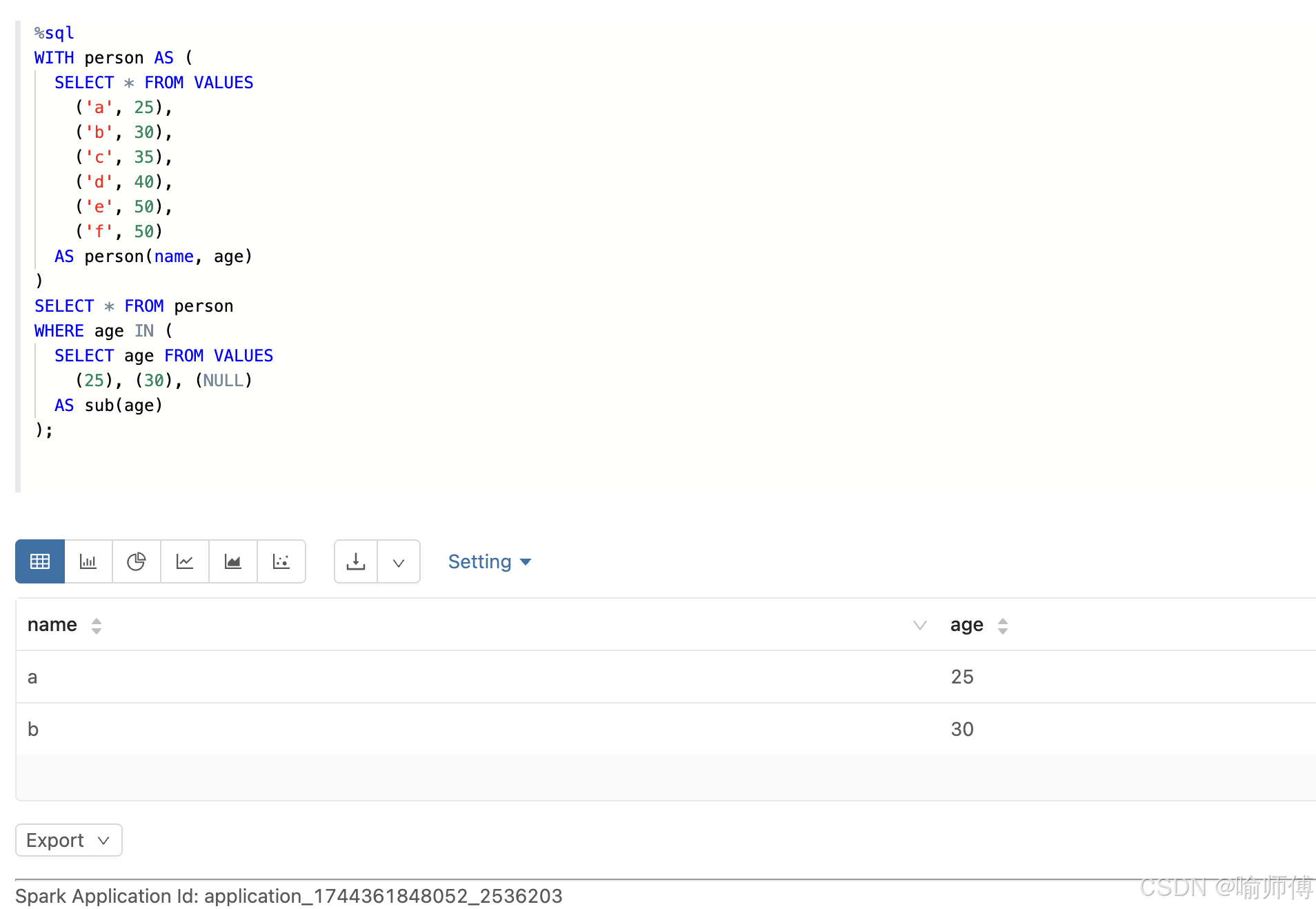
4: 主表中存在 NULL 值,同时子查询结果也包含 NULL
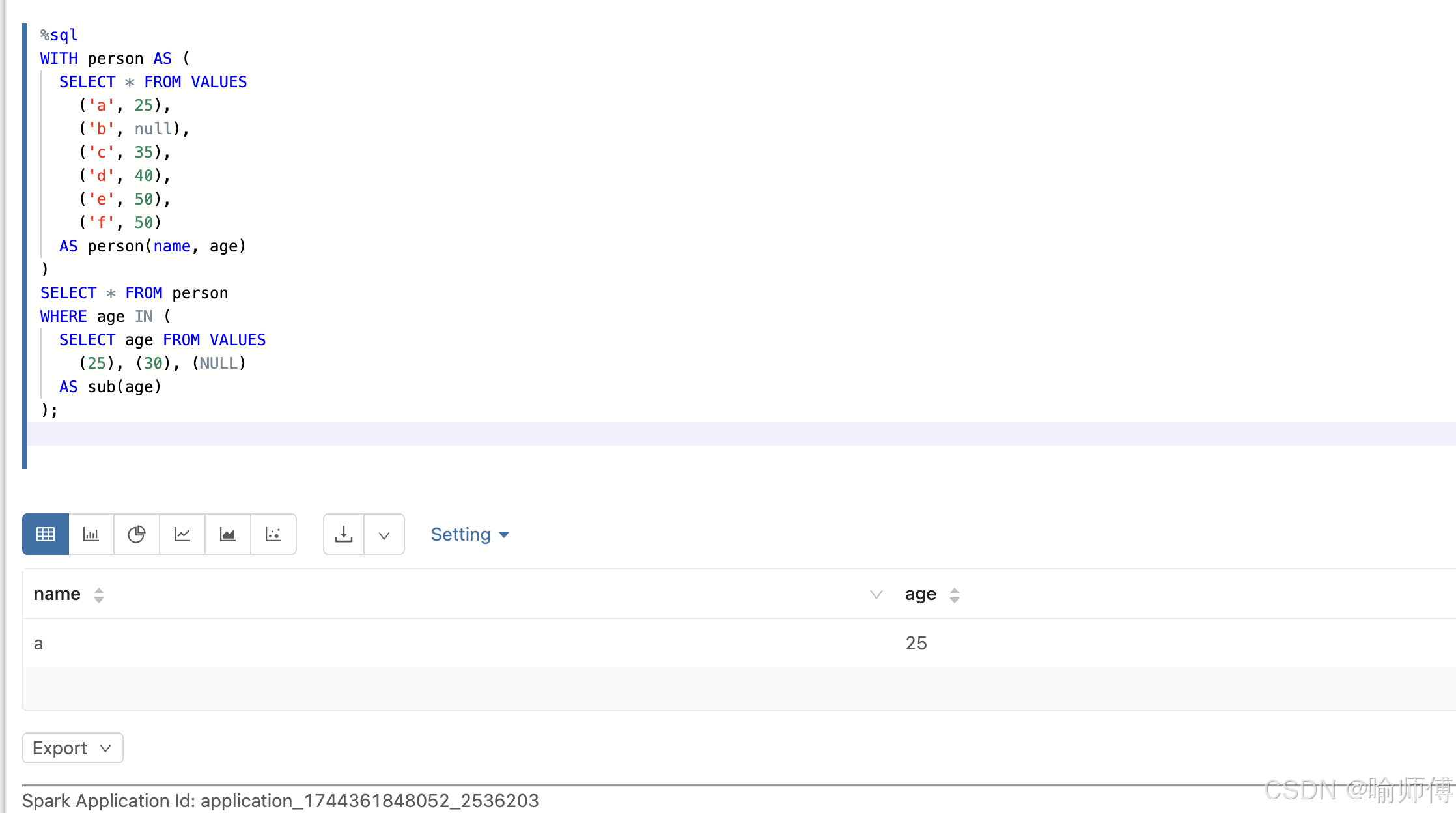
| 条件 | 是否被选中 | 原因 |
|---|---|---|
| age = 25 | ✅ 是 | 匹配列表中的值 |
| age = NULL | ❌ 否 | NULL IN (...) → UNKNOWN |
| age = 35/40/50 | ❌ 否 | 不匹配列表中的非 NULL 值,且列表中有 NULL → UNKNOWN |
NOT IN Demo:
只要 NOT IN 后面的子查询包含 NULL,整个条件就会变成 UNKNOWN, 没有任何行被返回。
避免这个问题,需要在子查询中加上 WHERE age IS NOT NULL。
1:子查询结果只有 NULL
-
NOT IN(只要有null)不返回任何结果%sql
WITH person AS (
SELECT * FROM VALUES
('a', 25),
('b', 30),
('c', 35),
('d', 40),
('e', 50),
('d', 50)
AS person(name, age)
)
SELECT * FROM person
WHERE age NOT IN (SELECT null);
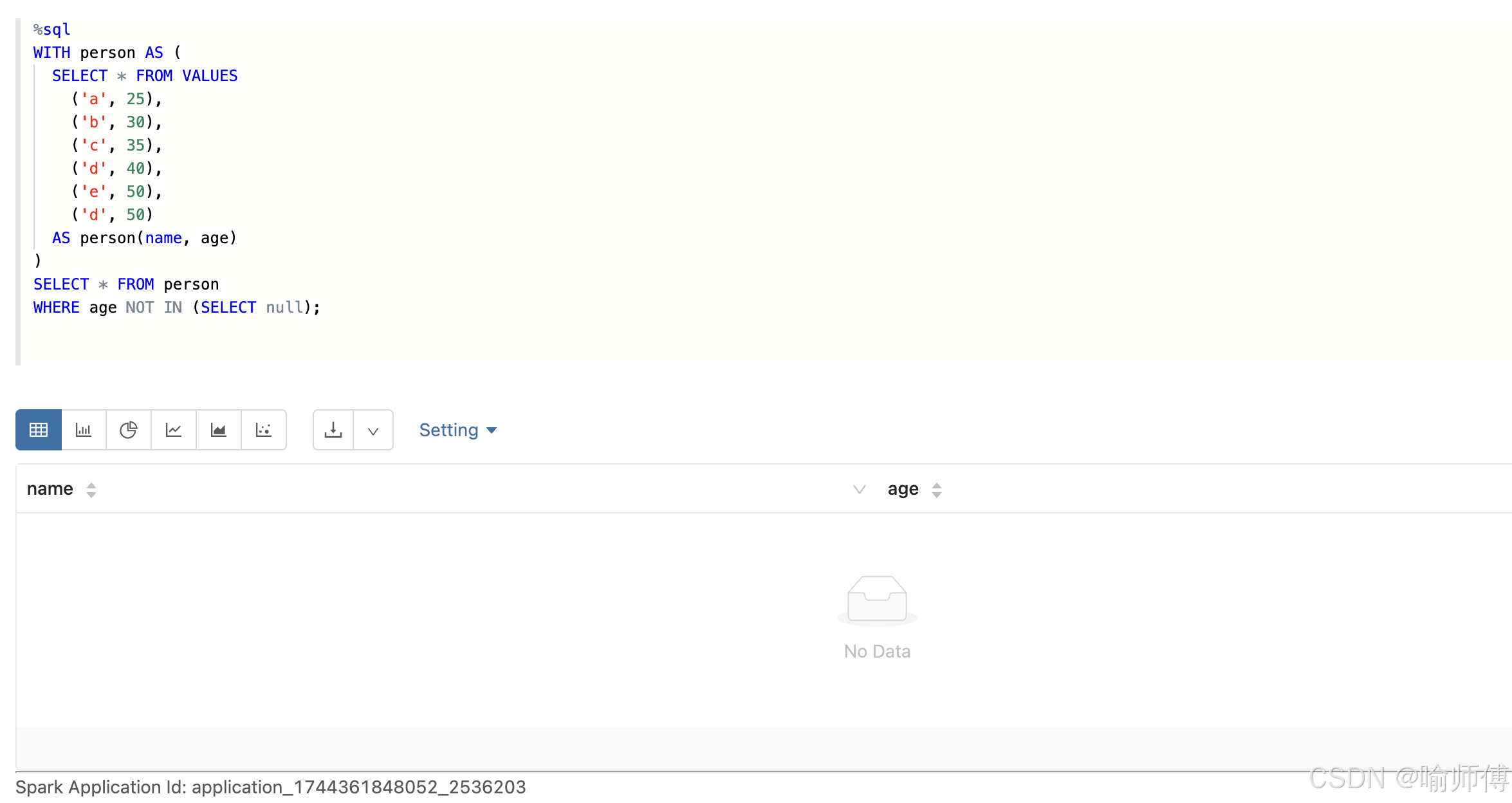
子查询中包含 NULL,NOT IN 整体返回 UNKNOWN,SQL 不会将其视为 TRUE,所以没有行满足条件。
2: 子查询包含 NULL 和有效值
-
NOT IN(只要有null)不返回任何结果%sql
WITH person AS (
SELECT * FROM VALUES
('a', 25),
('b', 30),
('c', 35),
('d', 40),
('e', 50),
('f', 50)
AS person(name, age)
)
SELECT * FROM person
WHERE age NOT IN (
SELECT age FROM VALUES
(50), (NULL)
AS sub(age)
);
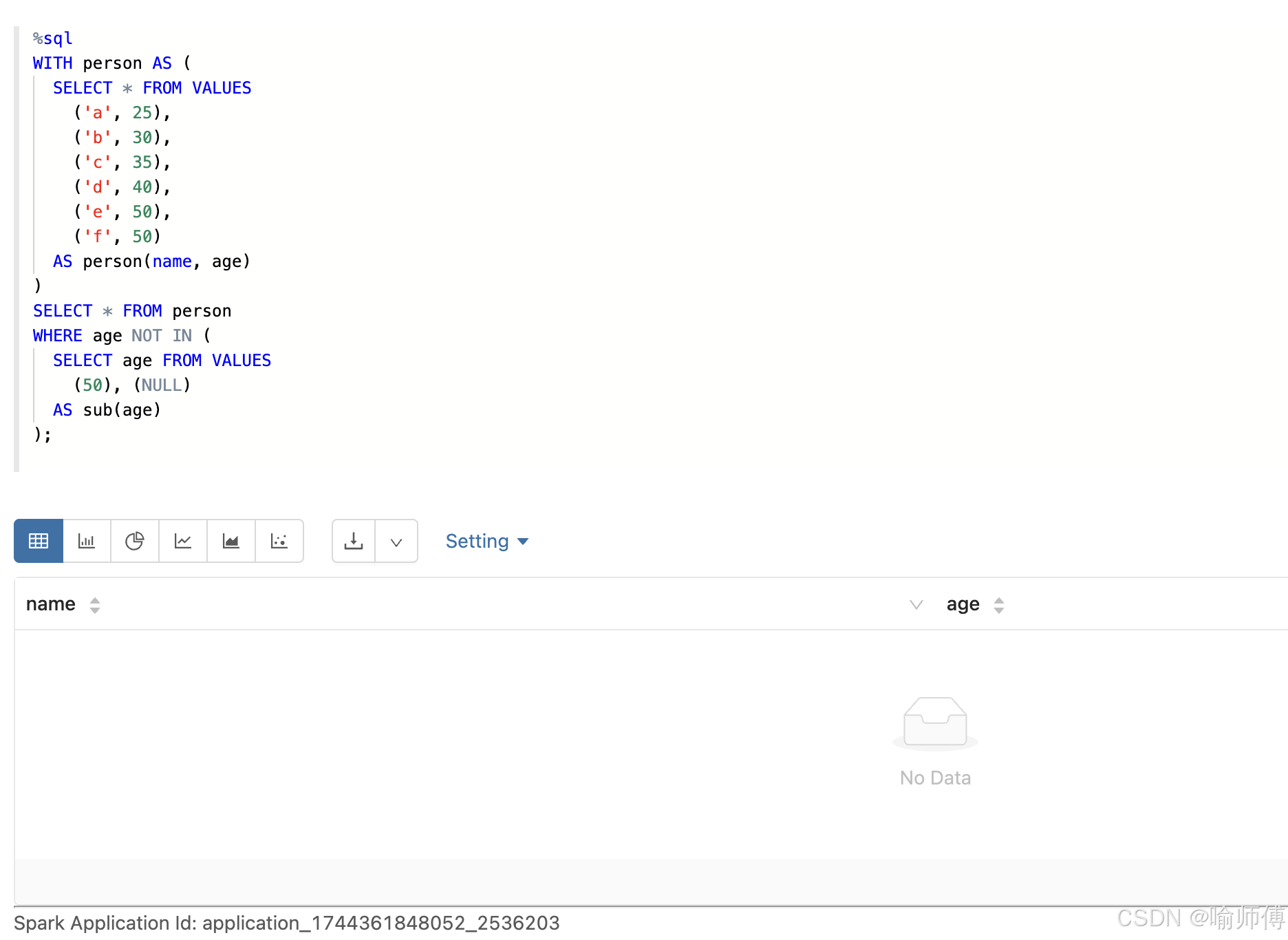
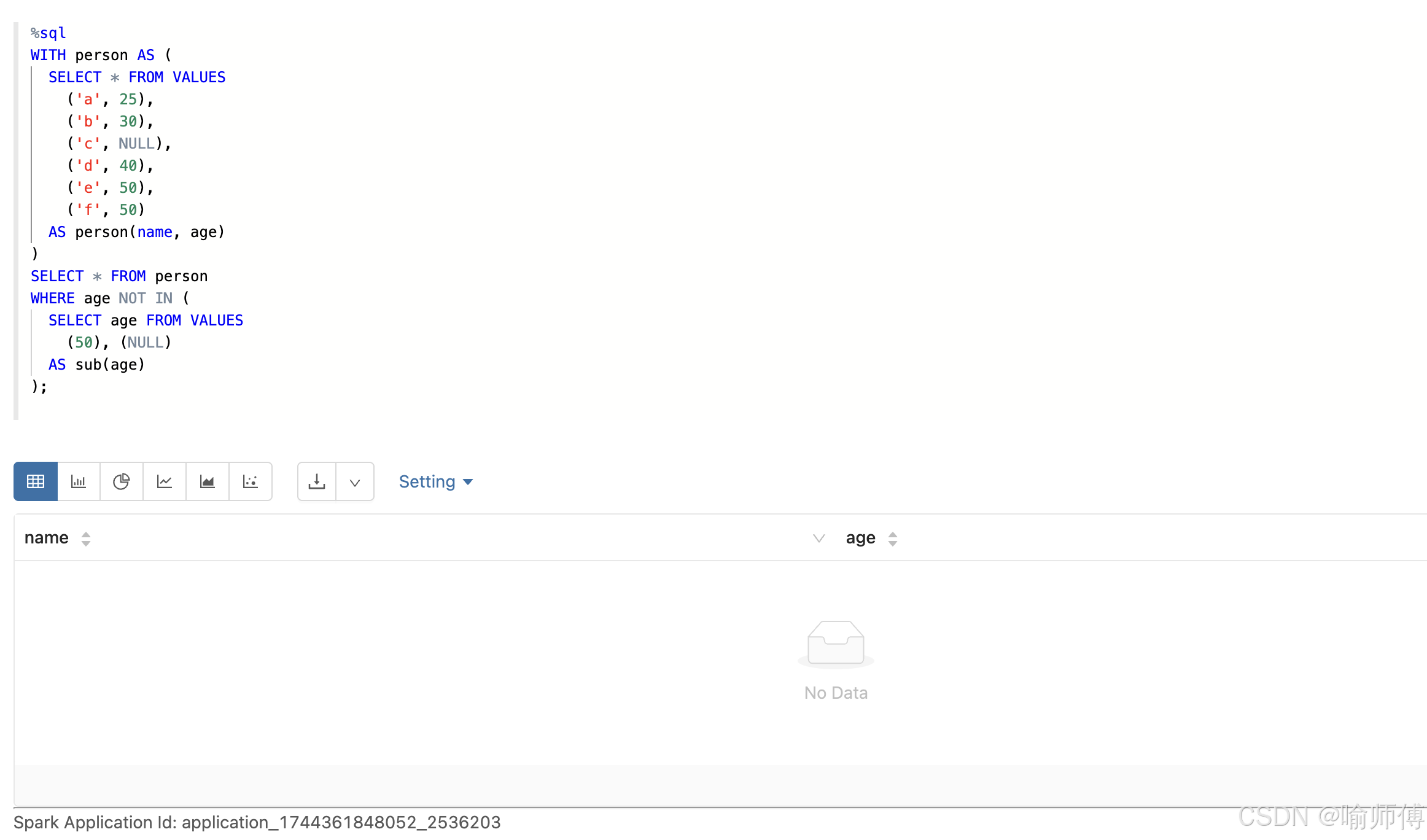
3: 主表中存在 NULL 值,同时子查询结果也包含 NULL
-
NOT IN(只要有null)不返回任何结果%sql
WITH person AS (
SELECT * FROM VALUES
('a', 25),
('b', 30),
('c', null),
('d', 40),
('e', 50),
('f', 50)
AS person(name, age)
)
SELECT * FROM person
WHERE age NOT IN (
SELECT age FROM VALUES
(50), (NULL)
AS sub(age)
);
Spark官方对于各种函数处理null值的说明:
https://spark.apache.org/docs/4.0.0/sql-ref-null-semantics.html