在大数据领域,Spark以其卓越的并行处理能力著称。但面对小数据集的极致并行需求时,默认优化策略往往成为瓶颈。本文将深入剖析如何通过精准控制分区策略,将仅170条数据的表拆分成170个独立Task并行执行,实现100%的并行度,并详细解释背后的分布式计算原理。
1.问题场景与技术挑战
原始业务需求
-
输入数据:170条地理坐标记录(约10MB)
-
处理逻辑:对每条记录应用geohash UDTF(用户定义表函数),每个围栏要用udf 去炸geohash8,一个围栏要变成千万行
-
核心目标:最大化并行度,每条数据在独立Task中处理
CREATE TABLE result AS
SELECT
mall_id,
substr(geohash8, 1, 7) AS geohash7
FROM
source_table LATERAL VIEW geohash(wl_min60) t AS geohash8默认Spark行为的痛点
-
小数据集优化倾向:Spark倾向于将整个数据集放入单个分区处理,无法充分利用集群资源
-
单点执行瓶颈:所有geohash UDTF调用在单个Task中顺序执行,形成明显的性能瓶颈
-
资源浪费:集群计算资源处于闲置状态,无法实现并行加速
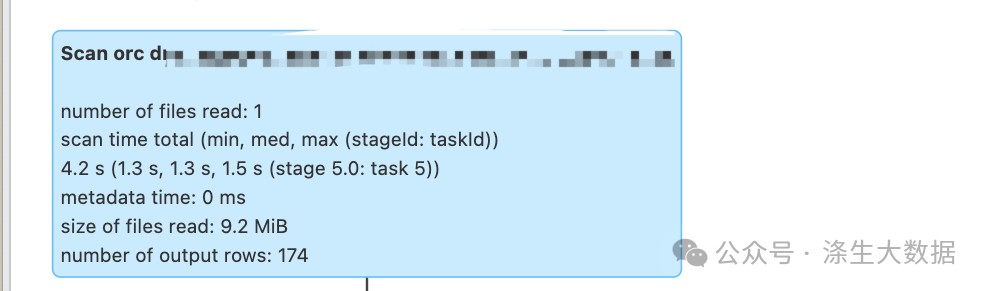
下图为用单条数据测试时间

技术挑战本质
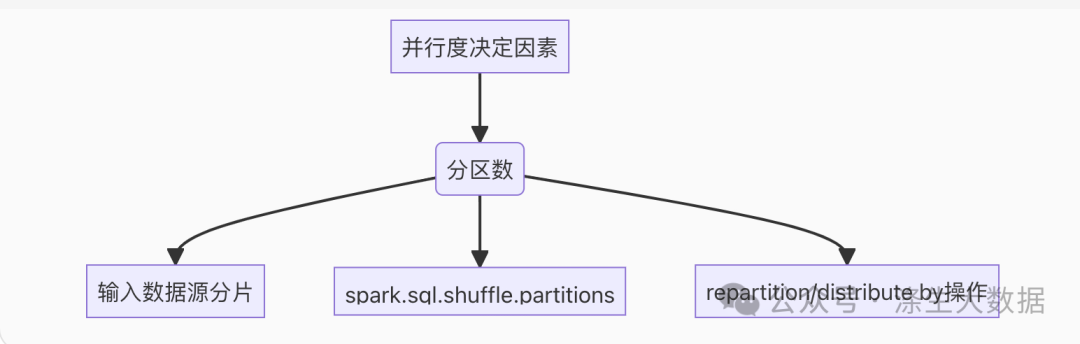
实现极致并行的核心挑战在于Spark的并行度控制机制:
-
分区决定并行度:Spark的并行度由数据分区数直接决定,而分区策略受多重因素影响
-
关键影响因素:
-
输入数据源的分片数(如HDFS块大小)
-
Shuffle操作的spark.sql.shuffle.partitions配置
-
显式的repartition/distribute by操作
-
2.分布式计算核心原理剖析
Spark执行模型四层架构
Application → Job → Stage → Task → Partition
-
Task:最小执行单元,处理单个分区数据
-
Partition:数据逻辑分片,与Task一一对应
-
关键公式:并行度 = min(分区数, 可用计算核心数)
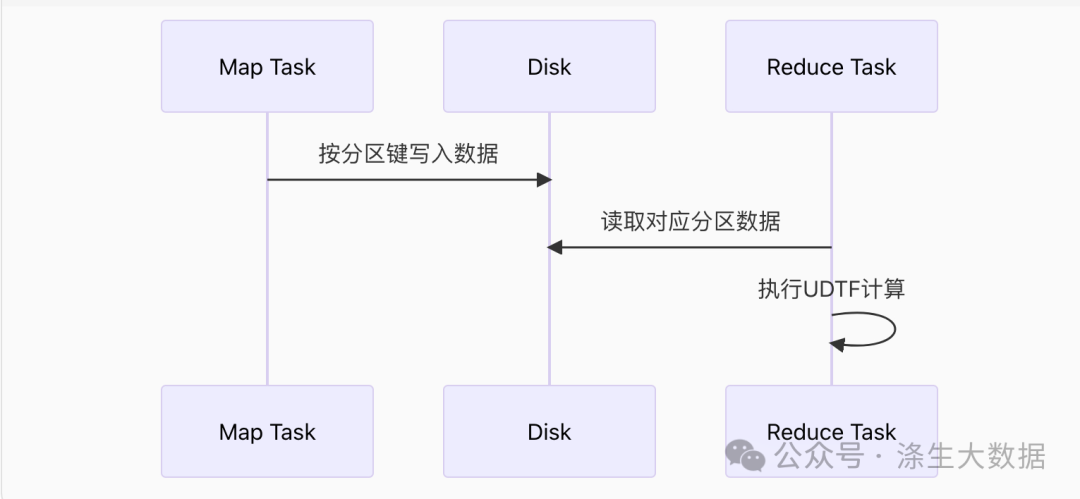
Shuffle机制深度解析
实现并行优化的核心在于Shuffle操作,其工作原理:
-
Map阶段:每个Task生成分区键的<Key, Value>对
-
Shuffle Write:按分区键将数据写入磁盘
-
Shuffle Read:下游Task读取对应分区数据
-
Reduce阶段:处理分配到的数据
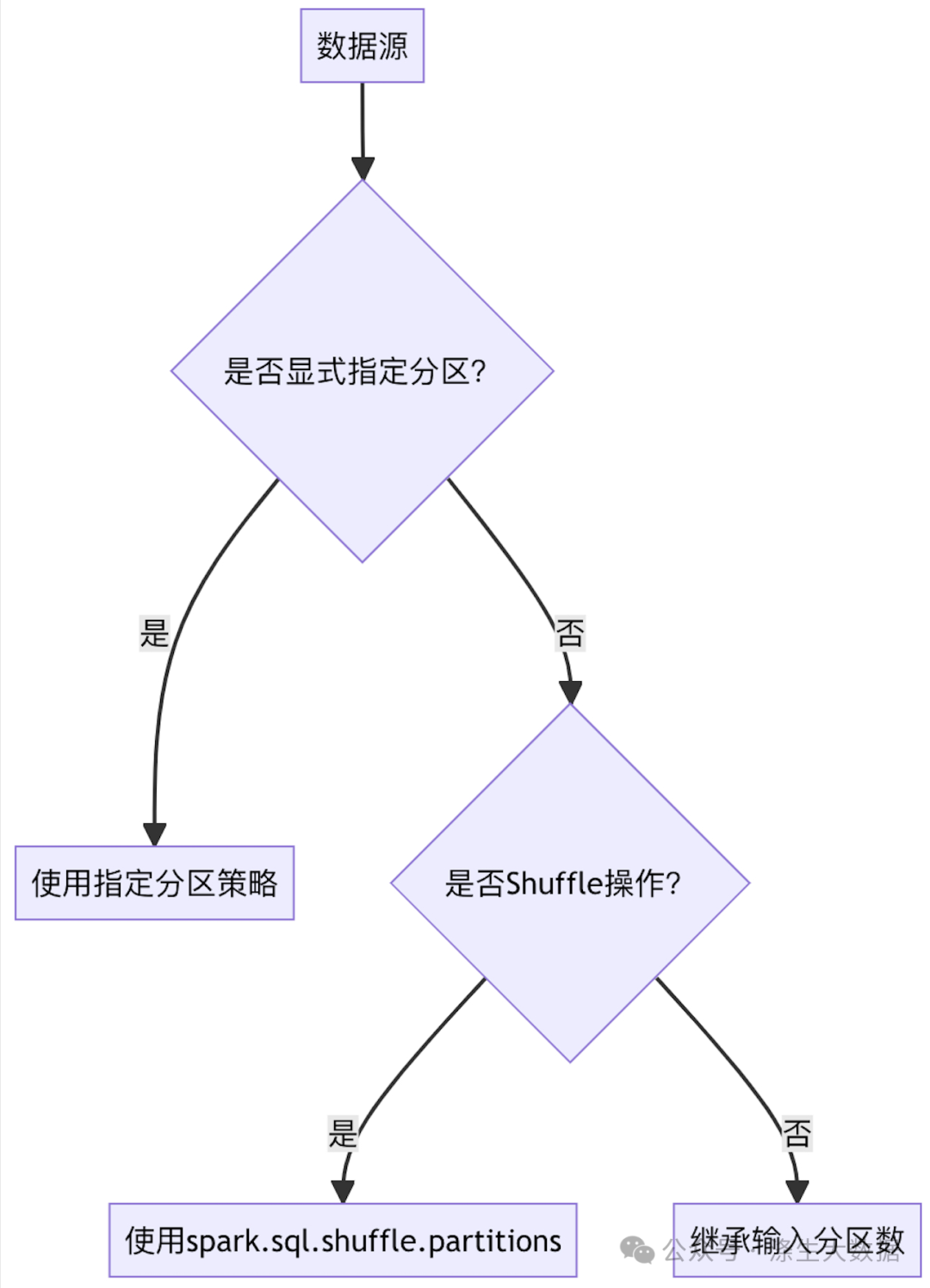
分区策略引擎
Spark的分区决策流程:
3.极致并行优化方案实现

关键实现代码
-- 关闭自适应优化避免动态调整
SET spark.sql.adaptive.enabled=false;
-- 设置Shuffle分区数=数据量
SET spark.sql.shuffle.partitions=170;
CREATE TABLE result AS WITH numbered_data AS (
SELECT
mall_id,
wl_min60,
ROW_NUMBER() OVER (
ORDER BY
rand()
) AS row_id -- 行号生成:创建唯一分区键
FROM
source_table
),
distributed_data AS (
SELECT
mall_id,
wl_min60,
row_id
FROM
numbered_data DISTRIBUTE BY row_id
)
SELECT
mall_id,
substr(geohash8, 1, 7) AS geohash7
FROM
distributed_data LATERAL VIEW geohash(wl_min60) t AS geohash8;-- UDTF将在每个分区独立执行总结:
-
第一步:在numbered_data中,我们使用ROW_NUMBER生成行号,这一步需要全局排序,数据被收集到一个Task中(如果只有一个分区的话)。
-
第二步:通过DISTRIBUTE BY row_id将数据重新分区,每个row_id一个分区(共170个分区)。
-
第三步:在每个分区上,执行LATERAL VIEW geohash(wl_min60),这样每个Task处理一条记录,并行执行。
因此,geohash函数的计算是并行执行的。
4.性能对比与优化效果
优化前:
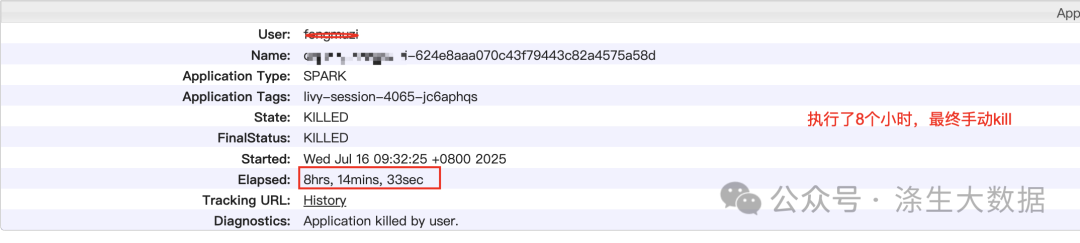
优化后:

5.技术总结与延伸思考
通过本案例,我们实现了:
-
精准分区控制 - 使用DISTRIBUTE BY+ROW_NUMBER()
-
UDTF极致并行 - 确保每条数据独立处理
-
资源最大化利用 - 完全利用集群计算资源
关键优化公式:极致并行度 = 为每条数据创建唯一分区键 + 匹配的分区数设置
本方案可抽象为小数据大并行(SDP)处理范式:
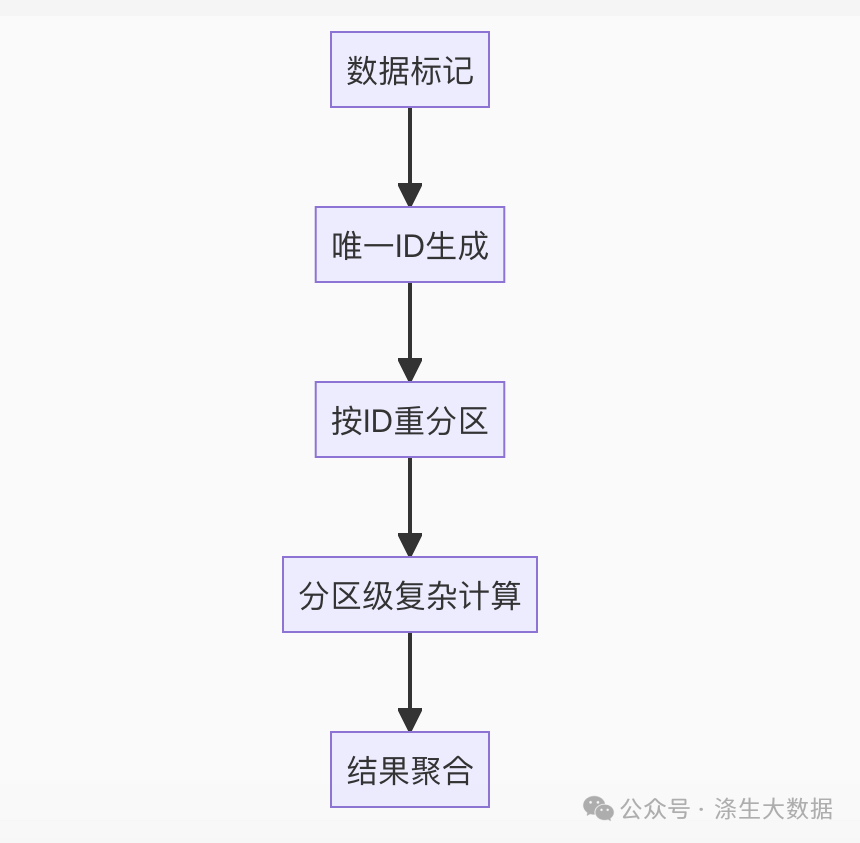
通过这种"小数据大并行"的创新思路,我们充分发挥了Spark分布式计算的优势,解决了小数据集场景下的性能瓶颈问题。这种优化思路已在多个实际生产环境中得到验证,为地理围栏分析、基因序列处理等场景带来几十倍以上的性能提升。