安装Spark的过程就是下载和解压的过程。接下来的操作,我们把它上传到集群中的节点,并解压运行。
1.启动虚拟机
2.通过finalshell连接虚拟机,并上传安装文件到 /opt/software下
3.解压spark安装文件到/opt/module下
tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/
4.重命名,把解压后的文件夹改成spark-local。因为后续我们还会使用其他的配置方式,所以这里先重命名一次。mv是linux的命令,
mv spark-3.3.1-bin-hadoop3 spark-local
配置环境变量
1.打开etc/profile.d/my_env.sh文件中,补充设置spark的环境变量。
省略其他...
添加spark 环境变量
export SPARK_HOME=/opt/module/spark-local
export PATH=PATH:SPARK_HOME/bin:$SPARK_HOME/sbin
2.使用 source /etc/profile 命令让环境变量生效
单机模式 运行第一个Spark程序
这里使用单机模式快运行第一个Spark程序,让大家有个基本的印象。在安装Spark时,它就提供了一些示例程序,我们可以直接来调用。进入到spark-local,运行命令spark-submit命令。
spark-submit --class org.apache.spark.examples.SparkPi --master local2 /opt/module/spark-local/examples/jars/spark-examples_2.12-3.1.1.jar 10
或者写成
cd /opt/module/spark-local bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local2 \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10
这里的 \ 是换行输入的意思,整体的代码就只有一句,只不过太长了,我们把它拆开成几个部分来输入,其中\ 的意思就是这里写不下,写在下一行。
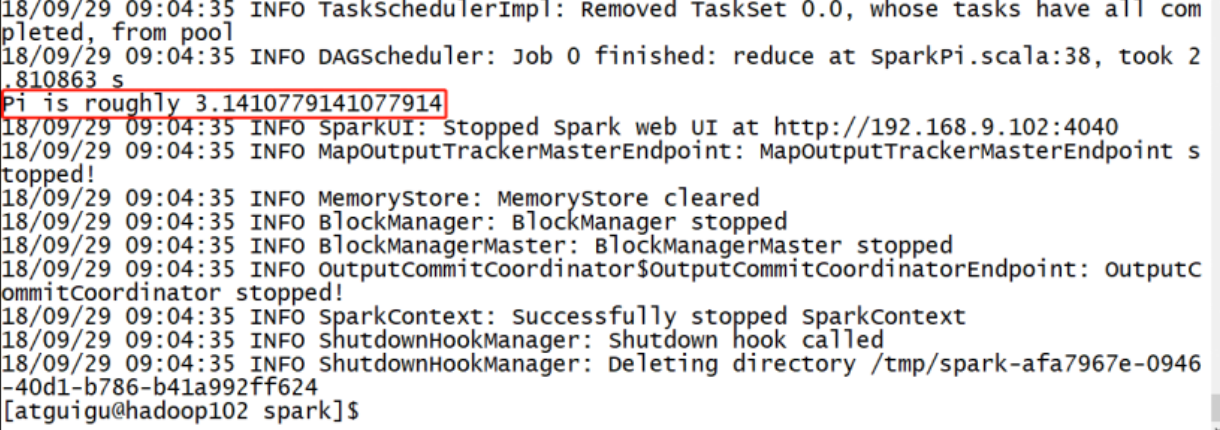
结果展示
该算法是利用蒙特·卡罗算法求PI的值,具体运行效果如下。请注意,它并不会产生新的文件,而是直接在控制台输出结果。