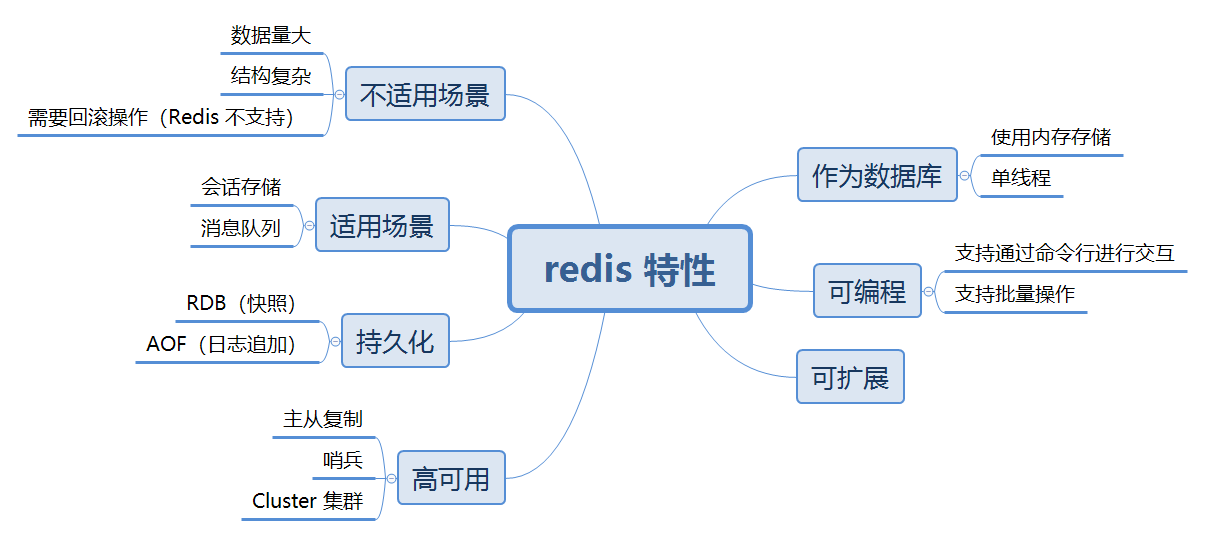
1. Redis 作为内存数据库(核心特性)
(1)为什么内存存储快?
- 内存 vs 硬盘 :
- 内存的访问速度是 纳秒级(ns) ,而 SSD 是 微秒级(μs) ,HDD 是 毫秒级(ms)。
- 举例 :Redis 读取 1KB 数据约 0.1ms ,MySQL(硬盘存储)约 1~10ms。
- 优化手段 :
- ziplist(压缩列表) :对小数据(如
Hash、List)进行压缩存储,减少内存占用。 - intset(整数集合) :如果
Set只包含整数,Redis 会用更紧凑的方式存储。
- ziplist(压缩列表) :对小数据(如
(2)单线程模型为什么高效?
- 核心原因 :
- 无锁竞争:单线程避免了多线程的锁开销,减少上下文切换。
- I/O 多路复用(epoll):一个线程管理多个连接,适用于高并发场景。
- 6.0 之后的多线程 :
- 仅用于网络 I/O(解析请求、发送响应),核心数据操作仍是单线程。
2. 可编程性(Lua 脚本 & 批处理)
(1)Lua 脚本的原子性
-
示例 :用 Lua 实现 分布式锁 + 自动续期
Lua-- KEYS[1] = 锁名称, ARGV[1] = 超时时间, ARGV[2] = 线程ID if redis.call("EXISTS", KEYS[1]) == 0 then redis.call("SET", KEYS[1], ARGV[2], "PX", ARGV[1]) return 1 -- 加锁成功 elseif redis.call("GET", KEYS[1]) == ARGV[2] then redis.call("EXPIRE", KEYS[1], ARGV[1]) -- 续期 return 1 else return 0 -- 锁被占用 end -
限制 :
- 脚本执行时间过长会阻塞 Redis(默认 5 秒超时)。
(2)批处理(Pipeline)
-
适用场景:需要执行大量命令(如批量写入 10 万条数据)。
-
示例 (Python):
pythonpipe = redis.pipeline() for i in range(100000): pipe.set(f"key_{i}", f"value_{i}") pipe.execute() # 一次性发送所有命令 -
对比事务(MULTI/EXEC) :
- Pipeline 只是减少网络往返,不保证原子性。
- 事务保证原子性,但失败不会回滚(继续执行)。
3. 持久化(RDB & AOF)
(1)RDB(快照)
- 触发方式 :
- 手动执行
SAVE(阻塞)或BGSAVE(后台异步)。 - 配置文件
save 60 10000(60 秒内 10000 次修改触发)。
- 手动执行
- 优点 :
- 恢复速度快(直接加载二进制文件)。
- 缺点 :
- 可能丢失最后一次快照后的数据。
(2)AOF(日志追加)
- 写策略 :
appendfsync always(每条命令刷盘,最安全但最慢)。appendfsync everysec(折中方案,默认推荐)。
- AOF 重写 :
- 避免日志过大,Redis 会生成新的 AOF 文件(只保留最终状态)。
(3)混合持久化(Redis 4.0+)
- 恢复流程 :
- 先加载 RDB 快照(快速恢复大部分数据)。
- 再重放 AOF 日志(恢复最新修改)。
4. 高可用(主从、哨兵、集群)
(1)主从复制
- 同步方式 :
- 全量同步(SYNC):从节点首次连接时,主节点发送完整数据。
- 增量同步(PSYNC):断线重连后,只同步缺失部分。
- 读写分离 :
- 主节点写,从节点读(通过
READONLY命令配置)。
- 主节点写,从节点读(通过
(2)哨兵(Sentinel)
- 功能 :
- 监控主节点健康状态。
- 自动故障转移(主节点宕机时,提升从节点为主)。
- 脑裂问题 :
- 解决方案:
min-slaves-to-write 1(至少 1 个从节点同步成功才接受写)。
- 解决方案:
(3)Cluster 集群
- 数据分片 :
- 16384 个哈希槽(
CRC16(key) % 16384计算槽位)。 - 每个节点负责一部分槽位。
- 16384 个哈希槽(
- 跨槽操作 :
- 使用
{hash_tag}确保相关 key 落在同一节点(如user:{123}:profile)。
- 使用
5. 适用场景 vs 不适用场景
(1)适用场景
| 场景 | 解决方案 | 示例 |
|---|---|---|
| 会话存储 | SETEX session:123 3600 "{user_data}" |
分布式登录态管理 |
| 实时排行榜 | ZADD leaderboard 100 "user1" |
游戏积分榜 |
| 消息队列 | LPUSH task_queue "data" + BRPOP task_queue 30 |
异步任务处理 |
会话存储
在 单机架构 中,用户的 Session 存储在当前服务器的内存里,请求携带的 SessionID 可以直接匹配,不会出现会话丢失问题。
但在 分布式架构 下:
- 用户请求先经过 负载均衡器(如 Nginx)。
- 负载均衡器采用 轮询策略,可能把请求分发到不同的服务器(Server 1、Server 2...)。
- 如果
Session只存储在 某台服务器内存 里,其他服务器无法读取,导致用户 "明明登录了,却找不到 Session"。
2. 解决方案
(1)会话绑定(Sticky Session)
- 原理 :让同一个用户的请求 始终访问同一台服务器(不采用轮询)。
- 实现方式 :
- 负载均衡器基于
SessionID或IP做 哈希路由。
- 负载均衡器基于
- 缺点 :
- 服务器宕机时,会话丢失(无高可用)。
- 扩容/缩容困难(哈希分布会变化)。
**2)集中式 Session 存储(Redis)(推荐)**
-
原理 :将会话数据统一存储在 Redis,所有服务器共享访问。
-
架构 :
用户 → 负载均衡器 → 任意应用服务器 → Redis(存储 Session) -
优点 :
- 高可用:即使某台服务器宕机,会话仍在 Redis 中。
- 可扩展:新增服务器无需迁移 Session。
- 自动过期 :Redis 支持
EXPIRE自动清理过期会话。
(2)不适用场景
- 海量数据存储(如 10TB):内存成本过高,建议用 MySQL + Redis 缓存。
- 复杂事务:Redis 事务不支持回滚,不适合金融级一致性要求。