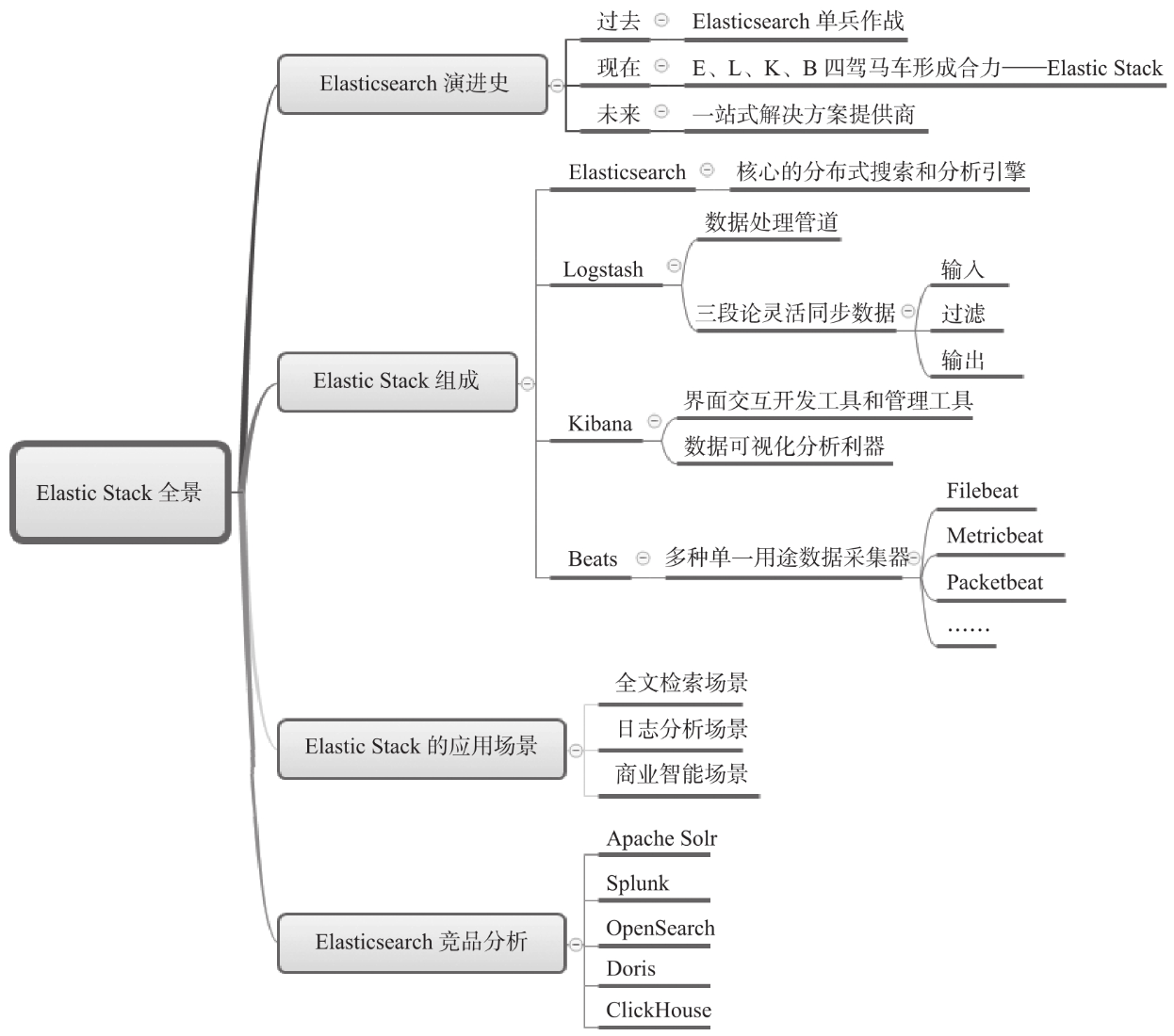
一、Elastic Stack的发展
- 过去和现在:
Elastic数据平台在搜索 、地理位置 、内部日志 、数据指标 、安全监控 和APM应用性能管理等场景中的应用颇具亮点。
APM(Application Performance Management,应用性能管理)是一种用于监控和管理软件应用程序性能与可用性的技术框架,旨在帮助企业确保应用程序高效运行、快速定位性能瓶颈,并优化用户体验。
- 将来:
Elastic公司经过两年精心研发,推出了一个全新特性ESRE(Elasticsearch Relevance Engine,最早发布于Elasticsearch 8.8版本)。它是一款基于AI的搜索引擎,实现开箱即用的卓越语义搜索。ESRE的出现,使强大的AI功能与Elasticsearch杰出的多模态搜索能力结合,开创了新的可能。
ESRE 是 Elasticsearch 8.8 版本推出的基于 AI 的搜索引擎,通过自然语言处理、集成第三方模型(如 GPT-3/4)和 Langchain 工具,结合稀疏与密集检索的混合排名方法,实现开箱即用的无训练语义搜索,提升多模态搜索相关性与准确性,助力构建生成式 AI 应用。
二、Elasticsearch的特点
1. Elasticsearch的特点
- 使用简单的RESTful API,天然兼容多语言开发。
- 支持水平横向扩展节点,通过增加节点来实现负载均衡及增强集群可靠性。
- 面向文档,不使用"表"来存储数据,而使用"文档"来存储数据。
- 无模式,无须定义好字段类型、长度等,可以直接导入文档数据。
- 近实时存储,使每个字段都被索引且可用于搜索。
- 响应快,海量数据下能实现秒级响应速度。
- 易扩展,支持处理PB级的结构化或非结构化数据。
- 多租户,支持多个业务共用Elasticsearch服务,并且确保各业务间数据的隔离性。
- 支持多种编程语言,包含但不限于Java、Python、C#、PHP、Python、Ruby等。
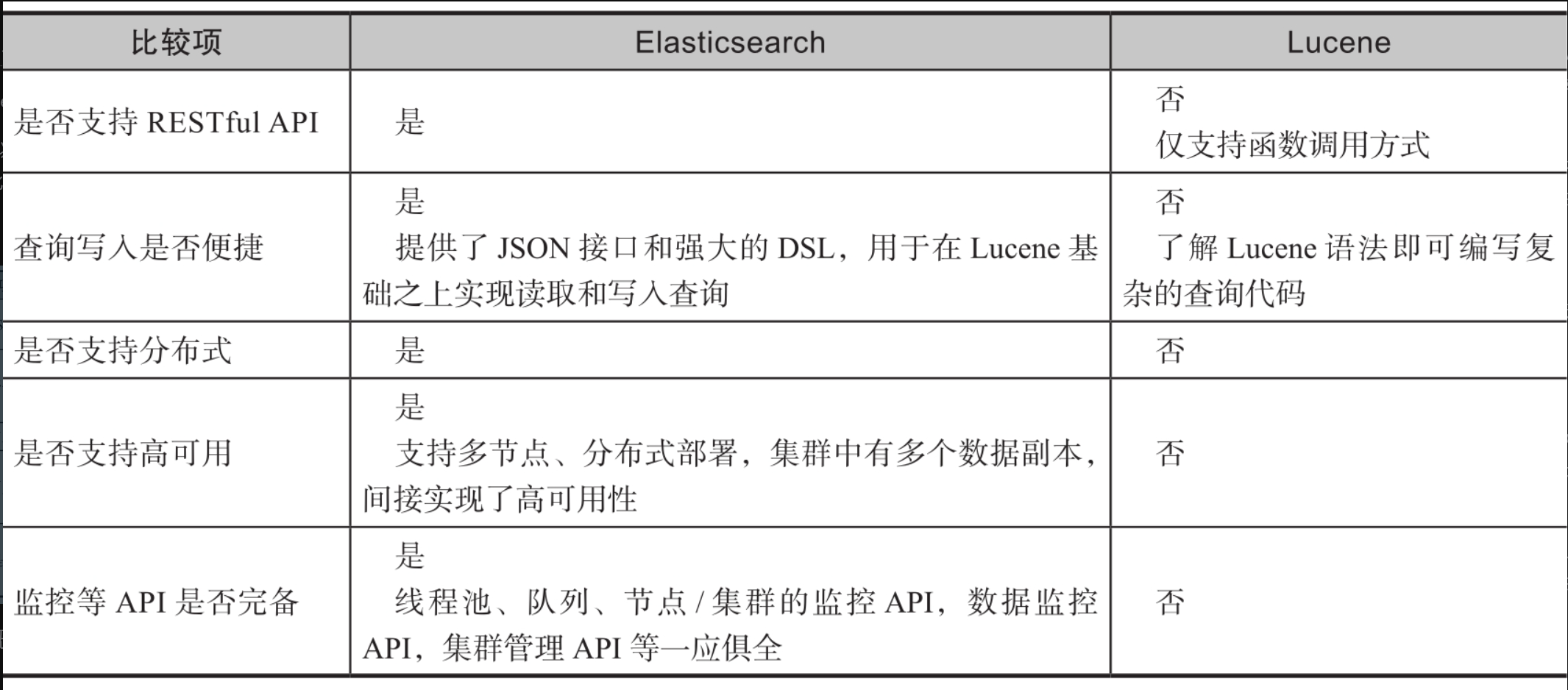
2. Elasticsearch和Lucene的对比
Lucene的工作模式类似于"自己亲手种植蔬菜",开发者使用它可以获得更多的控制权,但带来的问题是开发人员要花费更多的精力去维护。相比之下,Elasticsearch的工作模式则类似于"去超市购买蔬菜",明显效率会更高。
三、Elastic Stack组成
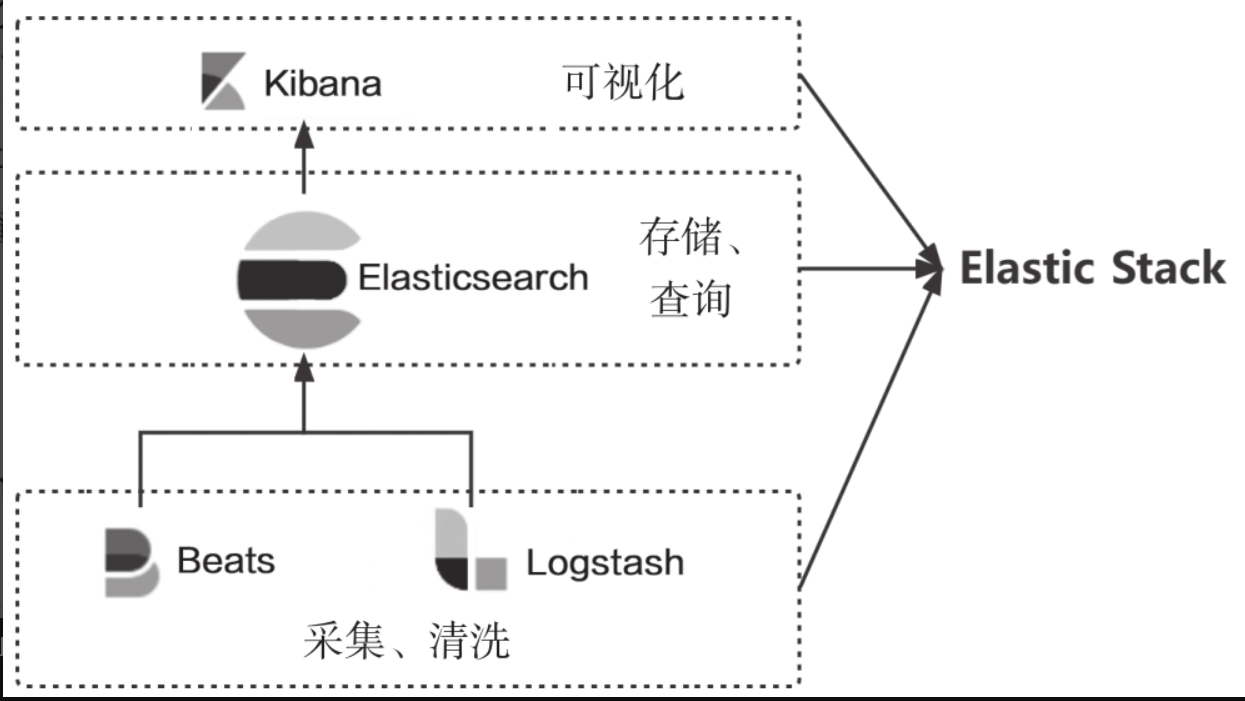
1. Logstash概览
Logstash与Beats作为底层核心引擎,共同构建了数据摄取平台,实现数据标准化处理,为后续分析奠定基础。其中:
- Logstash的定位与功能:提供免费开源的服务器端数据处理管道(pipeline),支持从多源数据源采集数据,通过过滤(filter)组件按自定义规则解析事件、提取字段并转换为通用格式,最终将标准化数据输出至Elasticsearch等"存储库"。
- 灵活的输出能力:依托可插拔框架,Logstash支持将数据输出至MySQL、Kafka、Redis等多样化目标,满足业务场景的差异化存储与处理需求。
- 插件生态与配置模式:内置超200个插件(如logstash_input_jdbc、logstash_output_elasticsearch等),通过"输入-过滤-输出"三段式模板灵活配置,适配不同类型数据的处理流程,提升数据集成效率。
2. Kibana概览
Kibana是一款免费开源的工具,作为Elastic Stack的核心用户界面,主要功能体现在数据可视化分析、开发运维辅助及集群监控三大领域:
- 数据可视化分析:支持将Elasticsearch中的数据转化为折线图、仪表盘、地理地图等多样化可视化图表,用户可通过简单拖拽操作自定义多维度数据报表,快速洞察数据趋势与关联。
- 开发与运维支持:集成界面交互开发工具与管理工具,辅助技术人员完成查询调试、索引管理、权限配置等操作,简化开发流程并提升运维效率。
- 集群监控与异常检测 :
- 作为可视化安全监控平台,实时展示Elasticsearch集群的CPU、内存、索引状态等关键运维指标,提供实时运行状态看板与历史趋势曲线,帮助用户提前发现潜在风险。
- 借助内置机器学习功能,自动检测数据中的异常模式(如指标突变、异常流量),并追溯异常来源,实现智能化故障预警与根因分析。
3. Beats概览
Beats是免费开源的轻量级数据采集平台,通过集成多种单一功能的数据采集器,实现海量机器与系统的数据向Logstash或Elasticsearch的高效传输,具体特点如下:
- 核心功能与采集器类型 :
- 作为数据采集层核心组件,支持从数百/数千台设备实时采集数据;
- 包含多款轻量级采集器:
- Filebeat:专注日志文件采集,资源占用低,适合大规模日志场景;
- Metricbeat:实时监控服务器CPU、内存、磁盘等性能指标;
- Packetbeat:捕获网络流量数据,解析协议字段以分析网络性能与安全。
- 技术优势 :
- 可扩展框架:支持自定义采集器扩展,适配多样化数据源;
- 高效采集:预置采集器经过优化,降低数据采集对系统资源的消耗,提升采集效率。
- 与Elastic Stack的协同价值 :
Beats与Elasticsearch、Logstash、Kibana共同构成Elastic数据平台四大核心产品,实现:- 实时性:秒级数据采集与传输,满足实时分析需求;
- 相关性:通过数据标准化与关联分析,挖掘数据间深层联系;
- 扩展性 :支持PB级数据规模,灵活应对业务增长。
该平台通过全链路数据处理能力,彻底解决企业大数据实时采集、分析与可视化难题,成为数据驱动决策的核心基础设施。
四、Elastic Stack的应用
Elastic Stack在全文检索、产品检索、JSON文档存储、数据聚合、坐标与地理位置检索、指标统计和分析、自动补全、自动推荐、安全分析等领域都有广泛的应用。我们将其划分为全文检索、日志分析、商业智能3类核心应用场景。
1. 全文检索场景
Elasticsearch在全文检索领域应用广泛:
- 覆盖多场景:支持电商(淘宝/京东)、应用市场(360手机助手)、文档平台(腾讯文档)等搜索需求。
- 技术优势:提供自定义打分/排序、高亮显示,通过跨机房容灾实现高可用、低延迟。
- 企业实践:阿里巴巴、腾讯、携程等头部企业将其作为核心技术,提升用户体验与业务效率。
2. 日志分析场景
Elasticsearch支持多类型日志处理:
- 日志类型:涵盖业务日志(用户行为)、状态日志(慢查询)、系统日志(多等级)。
- 技术优势:基于倒排索引实现秒级日志索引与检索,满足实时分析需求。
- 企业应用:58集团、唯品会、国投瑞银等用于日志分析、监控与故障排查。
3. 商业智能场景
电子商务、移动App开发、广告媒体等领域的企业面临大型业务数据收集与分析的巨大挑战。
Elasticsearch的核心能力:
- 具备结构化查询功能,可实现全文数据检索和聚合分析;
- 高效处理大数据,支持个性化分析,助力企业发现问题、辅助业务决策并挖掘商业价值。
典型商业智能应用场景: - 睿思BI、百度数据可视化Sugar BI、永洪BI等知名企业的商业智能系统,均借助Elasticsearch高效、实时的数据分析和可视化能力;
- 帮助企业理解市场趋势、优化决策过程,提升数据驱动的商业价值。
五、竞品分析
在大数据与搜索分析领域,ElasticSearch 凭借其卓越的性能与丰富功能占据重要地位,但市场中也存在诸多强劲竞品,各自具备独特优势与应用场景。以下对 ElasticSearch 与 Apache Solr、Splunk、OpenSearch、Doris、Clickhouse 进行对比分析。
1. Apache Solr
- 技术特点:
成熟的全文检索能力:基于 Lucene 构建,拥有强大的全文检索功能,支持复杂查询语法,如布尔查询、模糊查询等,在文本搜索方面与 ElasticSearch 旗鼓相当。
丰富的插件生态:具备大量插件,可用于扩展功能,像数据导入插件能方便地从数据库等数据源导入数据,还有支持多种语言的分析器插件。
分布式架构:支持分布式部署,通过分片和副本机制实现高可用性与负载均衡,不过在集群自动扩展与收缩的灵活性上,较 ElasticSearch 稍逊一筹。
- 适用场景:
企业搜索应用:常用于企业内部文档搜索、知识库检索等场景,例如大型企业的内部资料查询系统,借助其强大的文本处理能力,能高效定位相关文档。
电子商务搜索:在一些电商平台中,用于商品搜索,通过对商品描述、属性等文本的索引与检索,为用户提供商品查找服务。
- 与 ElasticSearch 对比:
生态活跃度:ElasticSearch 的生态更为活跃,拥有更广泛的社区支持与丰富的第三方工具集成,在云服务支持方面也更为领先。
实时性:对于实时数据的处理,ElasticSearch 通常能提供更短的索引延迟,在对数据实时性要求极高的场景中表现更佳。
2. Splunk(不开源)
- 技术特点:
专注日志分析:在日志管理与分析领域堪称佼佼者,能高效收集、索引和分析各类日志数据,具备强大的日志解析功能,可自动识别多种日志格式。
可视化与告警:提供丰富且直观的可视化界面,方便用户创建自定义仪表盘展示日志分析结果。同时,具备灵活的告警机制,能根据设定的阈值及时通知运维人员异常情况。
强大的数据处理能力:可以处理海量数据,通过分布式架构实现横向扩展,满足大型企业复杂的日志处理需求。
- 适用场景:
IT 运维监控:广泛应用于企业 IT 系统运维,通过分析系统日志、应用日志等,快速定位故障根源,保障系统稳定运行,如金融机构的核心业务系统运维监控。
安全信息与事件管理(SIEM):在安全领域,用于收集和分析安全相关日志,检测潜在的安全威胁,例如互联网企业的网络安全防护体系。
- 与 ElasticSearch 对比:
开源属性:ElasticSearch 开源免费,用户可自由使用、修改和分发,而 Splunk 为商业软件,使用需购买许可证,对于预算有限的企业,ElasticSearch 更具成本优势。
功能侧重:ElasticSearch 功能更为通用,除日志分析外,在搜索、数据分析等多领域均有出色表现;Splunk 则深度聚焦日志分析与安全监控,在该特定领域功能更为专业和深入。
3. OpenSearch
- 技术特点:
源于 ElasticSearch 的分支:继承了 ElasticSearch 的诸多特性,如分布式架构、全文搜索能力等,两者在基础功能上有较高相似度。
多租户支持:支持多租户功能,可在同一集群中为不同用户或业务部门创建隔离的环境,每个环境拥有独立的数据、用户权限和仪表盘等,这是其区别于 ElasticSearch 的显著特性。
SQL 查询支持:在 OpenSearch 及其仪表盘均支持 SQL 查询,用户可使用熟悉的 SQL 语法查询数据,并以图表、表格形式可视化结果,降低了对熟悉 SQL 的用户的使用门槛。
- 适用场景:
云服务提供商:适合云服务提供商为多个客户提供搜索与分析服务,通过多租户功能实现资源隔离与高效利用,例如一些中小型云服务平台基于 OpenSearch 搭建搜索服务。
企业多业务线:大型企业内部有多条业务线,希望在同一集群中管理不同业务数据,利用 OpenSearch 的多租户特性,可方便地为各业务线分配独立资源与权限。
- 与 ElasticSearch 对比:
功能差异:ElasticSearch 在机器学习、跨集群复制等功能上更为完善,例如其机器学习功能可用于异常检测、预测等多种场景;而 OpenSearch 在多租户和 SQL 查询支持方面具有优势。
性能表现:根据部分基准测试,在处理大规模数据时,OpenSearch 在扩展性上稍强,可支持更大的数据量,且在相同工作负载下,CPU 和内存消耗比 ElasticSearch 低约 50% 。
4. Doris
- 技术特点:
高效的 OLAP 引擎:专为在线分析处理(OLAP)场景设计,在海量数据的聚合查询方面性能卓越,采用向量化执行引擎和分布式架构,能快速处理复杂的查询请求。
简单易用:提供类 SQL 查询语言,语法简洁,易于上手,降低了数据分析人员的使用门槛。同时,数据导入方式丰富,支持多种数据源快速导入数据。
数据更新与实时查询:支持数据的实时更新与查询,在实时数仓等场景中,能快速将新数据摄入并提供查询服务,满足对数据时效性要求较高的业务需求。
- 适用场景:
数据仓库与商业智能:常用于构建企业的数据仓库,为报表生成、数据分析等提供支撑,如电商企业利用 Doris 进行销售数据的实时分析,辅助决策制定。
实时数据分析:在互联网广告、金融交易监控等需要实时分析大量数据的场景中表现出色,能够快速对实时产生的数据进行聚合分析,及时反馈业务状态。
- 与 ElasticSearch 对比:
功能定位:ElasticSearch 功能更为综合,涵盖搜索、日志分析、地理位置查询等多领域;Doris 则专注于 OLAP 分析,在数据聚合查询性能上优于 ElasticSearch,尤其适用于复杂分析查询场景。
数据模型:ElasticSearch 采用面向文档的数据模型,适合处理非结构化和半结构化数据;Doris 基于传统关系型数据库的数据模型,更适合处理结构化数据的分析查询。
5. Clickhouse
- 技术特点:
极致的查询性能:以其超高性能的查询速度闻名,特别擅长处理大规模数据集的复杂查询,采用列式存储、分布式架构和并行计算等技术,能在秒级甚至毫秒级返回查询结果。
灵活的数据模型:支持多种数据类型和复杂的数据结构,如数组、嵌套数据等,能够适应不同业务场景下的数据存储与查询需求。
类 SQL 查询语言:提供类 SQL 的查询语法,易于理解和使用,同时支持 SQL 函数和表达式,方便进行数据处理和分析。
- 适用场景:
大数据分析与报表生成:在互联网、金融等行业,用于生成复杂的业务报表,对海量数据进行多维分析,例如互联网公司对用户行为数据的深度分析,以优化产品策略。
实时数据监控与预警:适用于实时监控系统,对实时产生的数据进行快速查询与分析,及时发现异常情况并发出预警,如金融交易系统的实时风险监控。
- 与 ElasticSearch 对比:
查询性能:在大规模数据的复杂聚合查询方面,Clickhouse 性能更优;而 ElasticSearch 在全文搜索、地理位置查询等特定场景下表现出色,查询性能各有侧重。
数据处理类型:ElasticSearch 擅长处理文本等非结构化数据的搜索与分析;Clickhouse 则更适合结构化数据的高效查询与分析,数据处理类型上存在差异。