素数筛
给定n, 求2~n内的所有素数
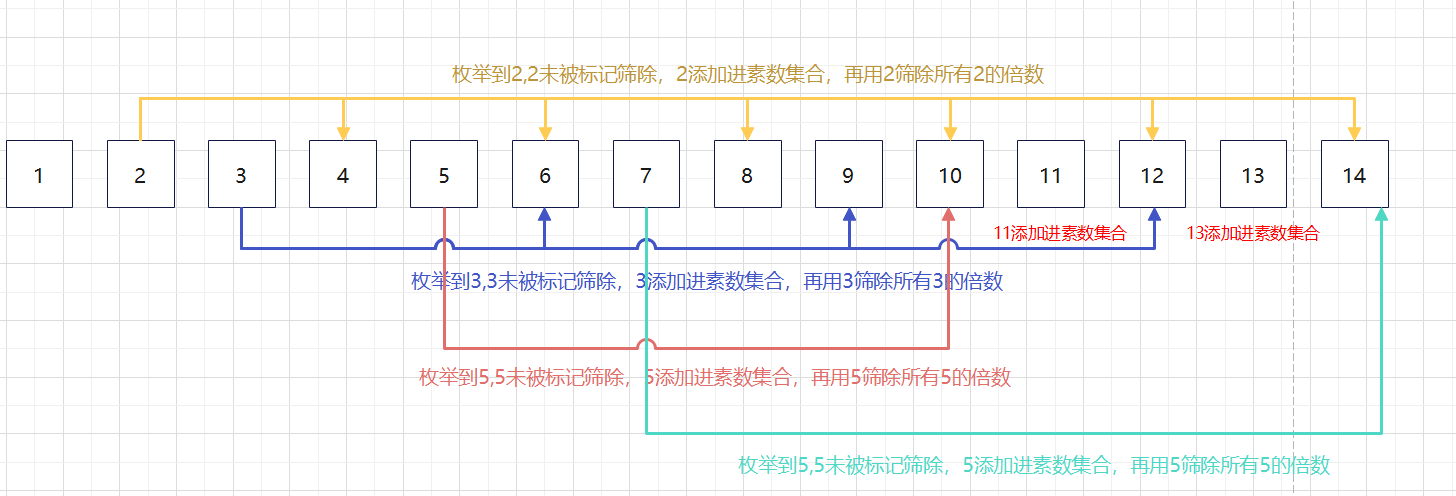
埃氏筛
利用素数的定义,
- 输出素数2,然后筛掉2的倍数,得 {2,3,5,7,9,11,13,...}
- 输出素数3,然后筛掉3的倍数,得 {2,3,5,7,11,13,...}
继续上述步骤,直到队列为空。
cpp
int E_sieve(int n) {
vector<bool>fat(n+1,false);
vector<int>tr(n);
int s=0;
for(int i=2;i<=sqrt(n);i++){ //筛选非负数
if(!fat[i])
for(int j=i*i;j<=n;j+=i) fat[j]=true; //标记为非素数
}
for(int i=2;i<=n;i++)
if(!fat[i]) tr[s++]=i;
return s;
}以【1,14】为例:
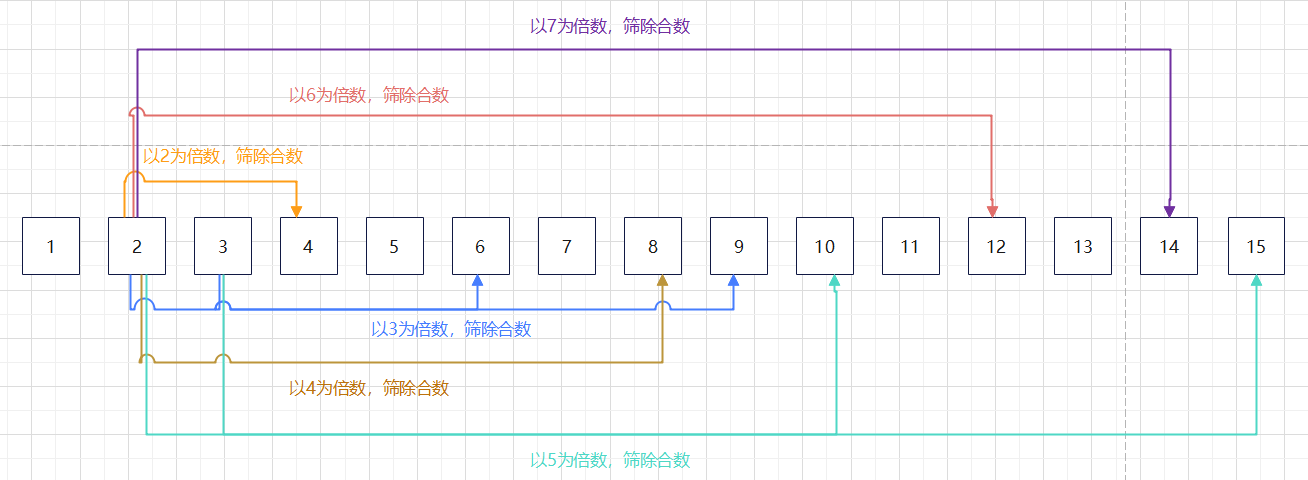
欧拉筛
欧拉筛是一种线性筛,是对埃氏筛的改进。
**原理:**一个合数肯定有一个最小质因数;让每个合数只被它的最小质因数筛选一次。
- 逐次检查2~n的所有数。第一个检查的是2,他是第一个素数。
- 当检查到第i个数时,利用求得的素数筛掉对应的合数x,而且是用x的最小质因数筛。
cpp
int prime[N];
int euler_sieve(int n){
int cnt=0; //此时得到的素数数量
bool vis[N];
memset(vis,0,sizeof(vis));
for(int i=2;i<=n;i++){ //i既在遍历时判断是否为素数,也充当筛选合数时的倍数。
if(!vis[i]) prime[cnt++]=i;
for(int j=0;j<cnt;j++){
if(i*prime[j]>n) break; //只筛小于等于n的数
vis[i*prime[j]]=1; //标记为筛除 循环中最少筛选1次,因为2是最小质数,合数的最小质因数>=2;
if(i%prime[j]==0) break;//关键,此时下一个合数的最小质因数不是prime[j] 退出循环。
//设i=prime[j]*t i*prime[j+1]=prime[j]*t*prime[j+1]
//说明下一个i*prime[j]的最小质因数不是prime[j];
}
}
}以【1,15】为例:
双子数
问题描述
若一个正整数能表示成(p2*q2)的形式(p,q为质数且互不相等)这称这个数为双子数,
求在2333,2333333333333范围内有多少个双子数?
代码
cpp
#include<bits/stdc++.h>
#define ll long long
using namespace std;
vector<ll>dt;
void selve(ll n){ //欧拉筛,筛出所有平方*4小于23333333333333的质数
unordered_set<ll>st; //记录被筛除的数据
int cnt=0;
for(ll i=2;i<=n;i++){
if(!st.count(i)) {
dt.push_back(i);
cnt++;
}
for(int j=0;j<cnt;j++){
if(dt[j]*i>n) break;
st.insert(dt[j]*i);
if(i%dt[j]==0) break;
}
}
}
int main()
{
// 请在此输入您的代码
ll ans=0;
ll t=sqrt(23333333333333/4);
selve(t); //筛选出小于t的所有素数
int i=0,j=dt.size()-1;
while(i<=j){
int k=i+1;
while(dt[i]*dt[i]*dt[k]*dt[k]<2333) k++; //找下限
while(dt[i]*dt[i]*dt[j]*dt[j]>23333333333333) j--; //找上限
if(j>=k) ans+=(j-k+1); //dt[i]*dt[i]*dt[p]*dt[p]都满足范围约束,p属于[k,j]; k,j为i固定下的最小值与最大值
i++;
}
cout<<ans;
return 0;
}质数拆分
问题描述
将2019拆分成若干个两两不同的质数的和,共有多少种不同的方案数?
注:交换顺序为同一种方案,如:2017+2=2019,与2+2017=2019为同种方案。
代码
cpp
#include <iostream>
#include<vector>
#include<math.h>
#include<algorithm>
using namespace std;
int sum=0;
int cnt=0;
int main()
{
// 请在此输入您的代码
vector<int>data;
vector<bool>vis(2020);
vector<long long>dp(2020);
dp[0]=1;
for(int i=2;i<=2019;i++){
if(!vis[i]) {data.push_back(i);cnt++;}
for(int j=0;j<cnt;j++){
if(i*data[j]>2019) break;
vis[i*data[j]]=true;
if(i%data[j]==0) break;
}
}
/*dp[i]表示若干个data中的元素相加为i的组合数。
特殊地,dp[0]=1;*/
for(int i=0;i<cnt;i++){ //遍历i
for(int j=2019;j>=data[i];j--){ //每次以data[i]作为所选元素中最大值,确保不重复计算
dp[j]+=dp[j-data[i]]; //更新若干个data元素相加为i的组合数
}
}
cout<<dp[2019];
return 0;
}线性探测
求解前n个质数
前面的素数筛用于求解小于等于n的所有质数能在O(n)的时间复杂度内完成,那么求解前n个质数是否同样有高效率呢?
答案是没有,当求解前106个质数时,第106个质数大于10^7,复杂度约为O(10n),往后相差更大。此时用试除探测的方法会更好。
代码
cpp
vector<long long>d(1,2);
void sovle(int n){
long long i=3;
while(d.size()<n){
int k=0;
while(d[k]*d[k]<=i){
if(i%d[k]==0){ //i是合数
i+=2;
k=1; //因为i是奇数,不用d[0]=2来试除。
}
else k++;
}
d.push_back(i); //i是质数
i+=2; //偶数必定不是质数,每次加2,只探测奇数。
}
}分解因数
cpp
//质因数存储在pa[]中
void zs(int n)
{
for(int j=2;j<=n;j++)
while(n%j==0)
{
pa.push_back(j);
n/=j;
}
}分解质因数的一个应用是求整数的正因数个数。
因数个数定理:大于1的整数n的约数个数等于n的每个质因数的幂(指数)加一的累乘
对 n 进行质因数分解: n = p 1 a 1 ∗ p 2 a 2 ∗ p 3 a 3 ∗ . . . ∗ p s a s ( p s 为 n 的质因数 ) 对n进行质因数分解: n=p_1^{a_1}*p_2^{a_2}*p_3^{a_3}*...*p_s^{a_s}(ps为n的质因数) 对n进行质因数分解:n=p1a1∗p2a2∗p3a3∗...∗psas(ps为n的质因数)
n 的约数个数为 s u m = ∏ i = 1 s ( a i + 1 ) ; n的约数个数为 sum=\prod_{i=1}^{s}(a_i+1); n的约数个数为sum=i=1∏s(ai+1);
阶乘约数
蓝桥杯2020年国赛题
问题描述
求100!的约数个数。
思路分析
前置知识:约数个数定理
因为任何一个正整数n都可以唯一分解为有限个素数的乘积,所以100!=p(1)*p(2)*p(3)*...p(100) p(x)为质因数分解式。
所以100!的因数个数为p(1)*p(2)*p(3)*...p(100) 中质因数的个数(指数)+1的累乘。
统计每个p(i)中质因数的个数 最后在算总的即可。
代码
cpp
#include<bits/stdc++.h>
using namespace std;
int a[101]={0};//存储每个质数的个数 例a[2]=10 即质数2有10个(指数数为2)
void zs(int n)
{
for(int j=2;j<=n;j++)
while(n%j==0)
{
a[j]++;//若当前n中含有质数j,即将j存储到a数组中
n/=j;
}
}
int main()
{
long long num=1;//num的范围大
for(int i=1;i<=100;i++)//统计每个质因数个数
{
zs(i);//可得当前数i含有的每个质数的个数
}
for(int i=1;i<=100;i++)
{
if(a[i]!=0)
num=num*(a[i]+1);//约数个数:等于它的质因数分解式中每个质因数的个数(即指数)加1的连乘的积。
}
cout<<num<<endl;
return 0;
}乘积尾0
问题描述
给定一个正整数数组,求数组中所有数相乘的结果末尾0的个数.
思路分析
1.把每个数都拆成2的m次方乘以5的n次方再乘以一个常数的形式.该数的尾0数即为min(m,n)
2.所有拆分的数有a个2和b个5,那么会有min(a,b)个尾0.
统计所有数中的2的个数(指数)a 和5的个数(指数)b,最后结果就是min(a,b).
因为2和5互质,分解因数2不影响分解因数5.
代码
cpp
int Zerosum(vector<int>&arr){
int a=0,b=0;
for(int i=0;i<arr.size();i++){
int k=arr[i];
while(k%2==0){ //分解因数2
k/=2;
a++; //因数2的指数+1
}
while(k%5==0){ //分解因数5
k/=5;
b++; //因数5的指数+1
}
}
return min(a,b);
}阶乘尾零
将1*2*3*4*5*...*n当作一个整体看,只有5,10,15,20,25...含有因数5,定义这些乘数为因数5元子 且在整个阶乘式子中每个相邻的因数5元子中,都含有因数2元子与其配对。所以只需求因数5的个数即可。
具体实现
代码中 n/5求当前因数5元子的个数,再对n/=5(相当于对所有的因数5元子降幂一次),重新计算当前因数5元子的个数,这个过程可用递归进行。
目前最优
代码
cpp
int trailingZeroes(int n) {
return n==0?0:n/5+trailingZeroes(n/5);
}丑数||
问题描述
给你一个整数 n ,请你找出并返回第 n 个 丑数 。
丑数 就是质因子只包含 2、3 和 5 的正整数。
思路分析
任何一个数都能唯一进行质因数分解,一个丑数必能分解成(2 ^i * 3 ^ j * 5^k)的形式(i,j,k为自然数)。
每次将上一阶段的丑数乘2或3或5,实现丑数的逐级递增。
何时该乘2,何时乘3,何时乘5呢?
可以采用动态规划,每次将上一阶段求得的丑数储存起来 。当前阶段的丑数,为上一阶段的i,j,k指针对应的丑数分别乘2,3,5(分别记为num2,num3,num5)的最小值 ,同时让最小值对应的指针后移一位(保证下次求最小值时不是同一个数,实现丑数逐级递增)。
代码
cpp
int nthUglyNumber(int n) {
vector<int> dp(n + 1); //存储前面计算结果
dp[1] = 1;
int p2 = 1, p3 = 1, p5 = 1; //p指针对应的是dp的下标
for (int i = 2; i <= n; i++) {
int num2 = dp[p2] * 2, num3 = dp[p3] * 3, num5 = dp[p5] * 5;
dp[i] = min(min(num2, num3), num5); //取三者最小值
if (dp[i] == num2) p2++;
if (dp[i] == num3) p3++;
if (dp[i] == num5) p5++;
}
return dp[n];
}比特位计数
问题描述
给你一个整数 n ,对于 0 <= i <= n 中的每个 i ,计算其二进制表示中 1 的个数 ,返回一个长度为 n + 1 的数组 ans 作为答案。
思路分析
每个数不是是偶数就是奇数:
- 奇数,二进制表示中,奇数一定比前面那个偶数多一个最低位的 1。
- 二进制表示中,偶数中 1 的个数一定和右移一位之后的那个数一样多。因为最低位是 0,右移一位就是把那个 0 抹掉而已,所以 1 的个数是不变的。
定义一个数组res,res[i]存储了i的二进制表示的1的个数,从0到n枚举,
枚举到i是奇数res[i] = res[i >> 1] + 1;
枚举到i是偶数res[i] = res[i >> 1] 。
代码
cpp
vector<int> countBits(int n)
{
vector<int> res(n + 1, 0);
for (int i = 0; i <= n; i++)
{
res[i] = res[i >> 1] + (i & 1);
}
return res;
}分解质因数求单个欧拉函数
cpp
int euler(int n){
int ans=n;
for(int p=2;p*p<=n;p++){ //试除法
if(n%p==0){
ans=ans/p*(p-1); //欧拉公式的通解
while(n%p==0) n/=p; //去掉这个因数的幂,并使下一个p是质因数。
}
}
if(n!=1) ans=ans/n*(n-1); //情况1,n是一个质数,没有执行上面的分解
return ans;
}优质数对的总数
问题描述
给你两个整数数组 nums1 和 nums2,长度分别为 n 和 m。同时给你一个正整数 k。
如果 nums1[i] 可以被 nums2[j] * k 整除,则称数对 (i, j) 为 优质数对 (0 <= i <= n - 1, 0 <= j <= m - 1)。
返回 优质数对 的总数。
思路
为方便描述,把 nums 1 和 nums 2 简记作 a 和 b。
a *i* 能被 b *j* ⋅k 整除,等价于 a *i* 是 k 的倍数且 ai/k 能被 b *j* 整除。
也就是说,ai/k 有一个因子 d 等于 b *j*。
- 遍历 a,枚举 ai/k的所有因子,统计到哈希表 cnt 中。比如遍历完后 cnt3=5,说明有 5 个 ai/k可以被 3 整除,等价于有 5 个 ai 可以被 3⋅k 整除。(因子为3的ai/k)有5个
- 遍历 b,把 cntb\[j] 加入答案。例如 bj=3,那么就找到了 cnt3 个优质数对。
代码
cpp
long long numberOfPairs(vector<int>& nums1, vector<int>& nums2, int k) {
unordered_map<int, int> cnt;
for (int x : nums1) {
if (x % k) {
continue;
}
x /= k;
for (int d = 1; d * d <= x; d++) { // 枚举因子
if (x % d) {
continue;
}
cnt[d]++; // 统计因子
if (d * d < x) {
cnt[x / d]++; // 因子总是成对出现
}
}
}
long long ans = 0;
for (int x : nums2) {
ans += cnt.contains(x) ? cnt[x] : 0;
}
return ans;
}
作者:灵茶山艾府时间复杂度:O(n sqrt(U/k)+m) ,其中 n 是 nums 1的长度,m 是 nums 2的长度,U=max(nums 1 )。
空间复杂度:O(U/k)。不同因子个数不会超过 U/k
将元素分配给组
问题描述
给你一个整数数组 groups,其中 groups[i] 表示第 i 组的大小。另给你一个整数数组 elements。
请你根据以下规则为每个组分配 一个 元素:
- 如果
groups[i]能被elements[j]整除,则元素j可以分配给组i。 - 如果有多个元素满足条件,则分配下标最小的元素
j。 - 如果没有元素满足条件,则分配 -1 。
返回一个整数数组 assigned,其中 assigned[i] 是分配给组 i 的元素的索引,若无合适的元素,则为 -1。
**注意:**一个元素可以分配给多个组。
思路分析
设 groups 中的最大值为 mx。我们直接预处理 1,2,3,...,mx 中的每个数能被哪个 elements[i] 整除。如果有多个相同的 elements[i],只考虑最左边的那个(i最小的那个)。
从左到右遍历 elements,设 x=elements[i]。枚举 x 的倍数 y(x,y都要小于mx),标记 y 可以被下标为 i 的元素整除,记作 target[y]=i。标记过的数字不再重复标记(保证获取的i为最小的)。
⚠注意:如果我们之前遍历过 x 的因子 d,那么不用枚举 x 的倍数,因为这些数必然已被 d 标记。
最后,回答询问,对于 groups[i]来说,答案为 target[groups[i]]。
初始 target所有元素都为−1。
代码
cpp
vector<int> assignElements(vector<int>& groups, vector<int>& elements) {
int mx = *max_element(groups.begin(),groups.end());
vector<int> target(mx + 1, -1);
for (int i = 0; i < elements.size(); i++) {
int x = elements[i];
if (x>mx||target[x] >= 0) { // x 及其倍数已被标记
continue;
}
for (int y = x; y <= mx; y += x) { // 枚举 x 的倍数 y
if (target[y] < 0) {
target[y] = i; // 标记 y 可以被 x 整除
}
}
}
// 回答询问
for (int& x : groups) {
x = target[x]; // 原地修改
}
return groups;
}