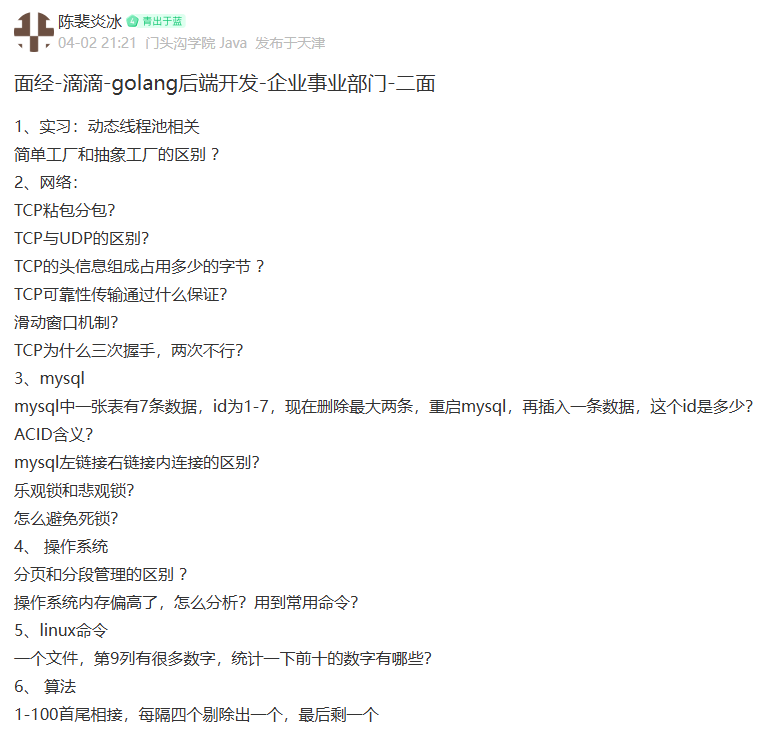
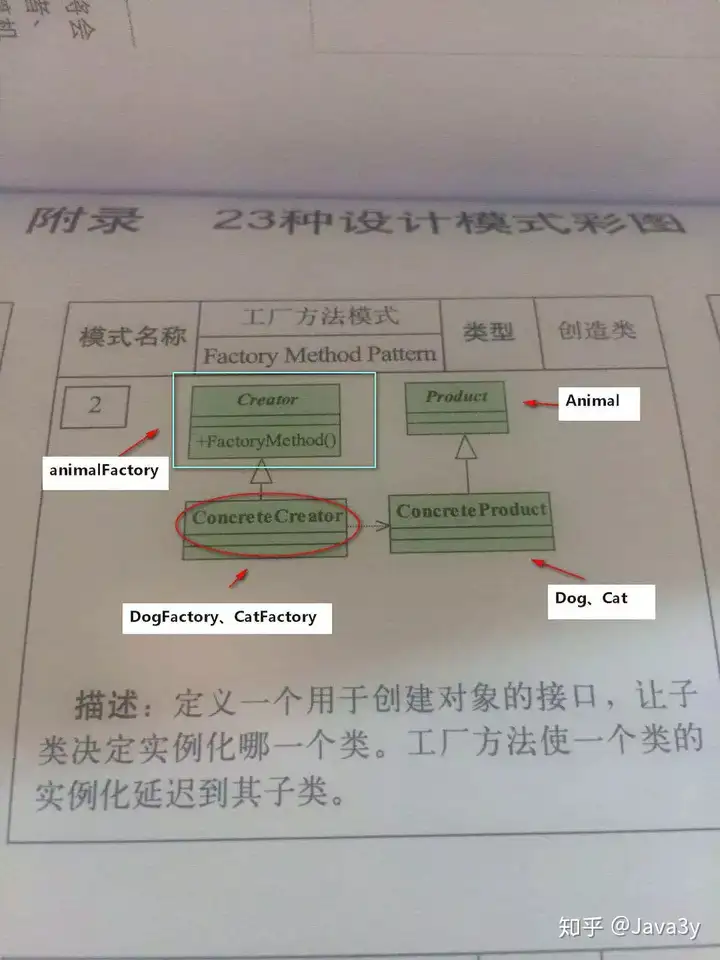
简单工厂和抽象工厂的区别 ?
参考:https://www.zhihu.com/question/27125796

工厂方法模式

简单/静态工厂模式

抽象工厂模式

TCP粘包分包?


TCP与UDP的区别?

TCP的头信息组成占用多少的字节 ?
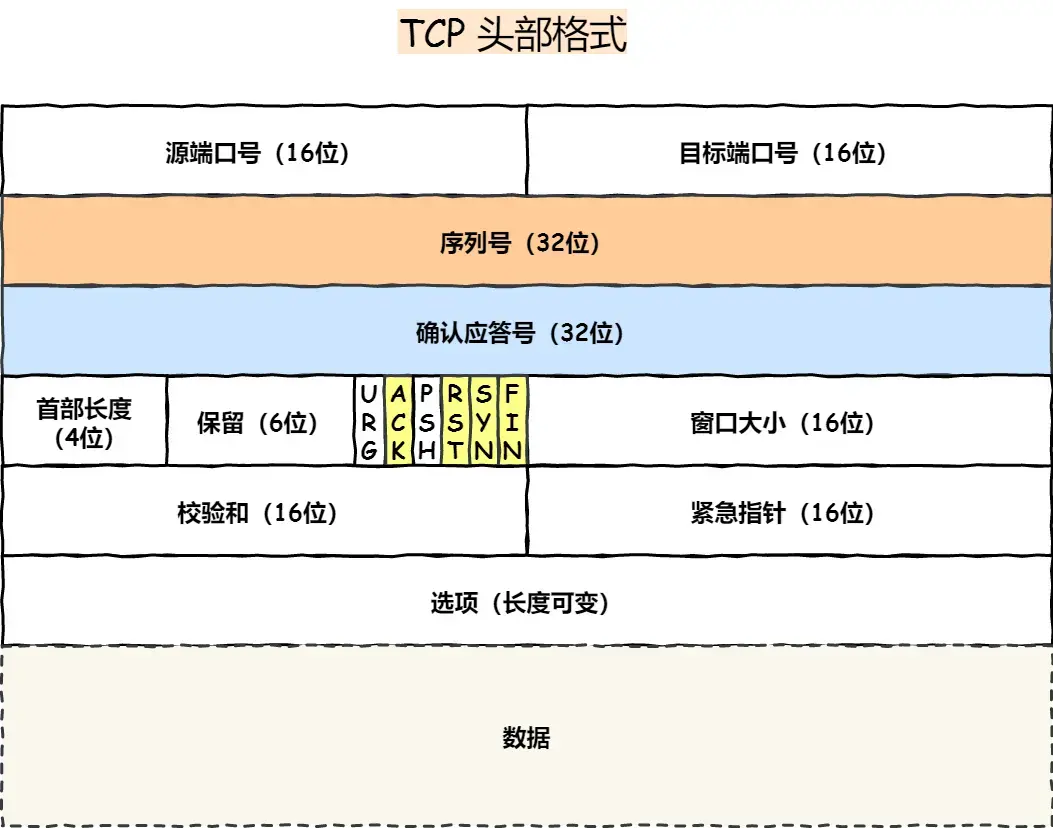
TCP 头信息(Header)的标准长度是 20 字节 ,但如果包含可选的选项字段(Options),最大可以扩展到 60 字节。以下是 TCP 头信息的详细组成:
TCP 头信息结构(固定部分:20 字节)
| 字段 | 占用字节数 | 说明 |
|---|---|---|
| 源端口(Source Port) | 2 字节 | 发送方的端口号(范围:0~65535)。 |
| 目的端口(Destination Port) | 2 字节 | 接收方的端口号(范围:0~65535)。 |
| 序列号(Sequence Number) | 4 字节 | 当前报文段数据部分的第一个字节的编号。 |
| 确认号(Acknowledgment Number) | 4 字节 | 期望接收的下一个报文段的序列号(仅在 ACK 标志为 1 时有效)。 |
| 数据偏移(Data Offset) | 4 位(0.5 字节) | 表示 TCP 头部的长度(单位:4 字节),用于定位数据的起始位置。 |
| 保留(Reserved) | 6 位(0.75 字节) | 保留字段,必须设为 0。 |
| 控制标志(Flags) | 6 位(0.75 字节) | 包含 6 个标志位:URG、ACK、PSH、RST、SYN、FIN(各占 1 位)。 |
| 窗口大小(Window Size) | 2 字节 | 接收方的接收窗口大小(流量控制)。 |
| 校验和(Checksum) | 2 字节 | 用于检测头部和数据的错误。 |
| 紧急指针(Urgent Pointer) | 2 字节 | 标识紧急数据的末尾位置(仅在 URG 标志为 1 时有效)。 |
| 选项(Options,可选) | 0~40 字节 | 可选字段(如 MSS、窗口缩放因子、时间戳等),长度可变,需按 4 字节对齐填充。 |
| 填充(Padding) | 可变 | 确保选项字段按 4 字节对齐的填充位(全 0)。 |
关键说明
-
固定部分
- 前 20 字节是 TCP 头的固定部分,所有 TCP 报文必须包含。
- 数据偏移字段 (4 位)的取值范围为
5~15(单位:4 字节),因此 TCP 头的总长度为(5~15) × 4 = 20~60 字节。
-
选项字段
- 常见的选项包括:
- MSS(Maximum Segment Size):协商最大报文段长度(4 字节)。
- Window Scale:窗口缩放因子(3 字节)。
- Timestamp:时间戳(10 字节)。
- 选项总长度必须为 4 字节的整数倍,不足时用填充(Padding)补齐。
- 常见的选项包括:
示例
- 无选项的 TCP 头:20 字节(固定部分)。
- 带 MSS 和 Window Scale 选项的 TCP 头 :
- 固定部分:20 字节。
- 选项:MSS(4 字节) + Window Scale(3 字节) + 填充(1 字节)= 8 字节。
- 总长度:20 + 8 = 28 字节。
总结
- 最小长度:20 字节(无选项)。
- 最大长度:60 字节(选项占满 40 字节)。
- 选项字段的实际长度取决于具体协议需求(如握手阶段的 SYN 报文通常携带 MSS 等选项)。
TCP可靠性传输通过什么保证?

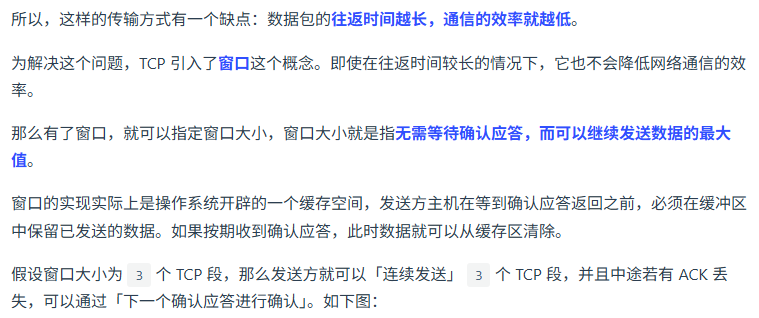
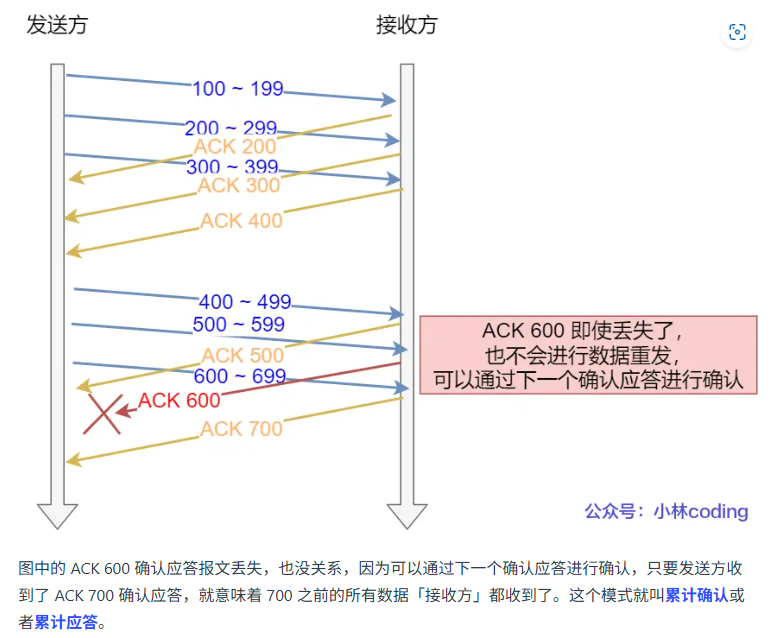
滑动窗口机制?
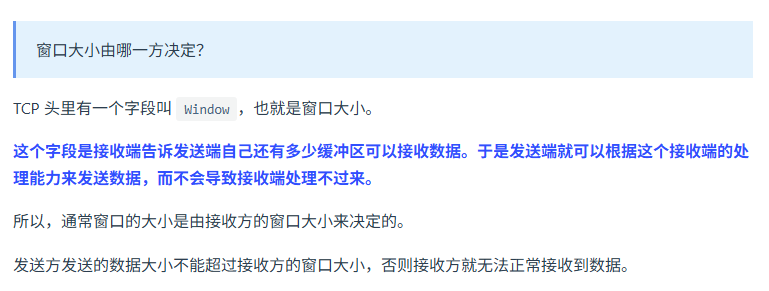
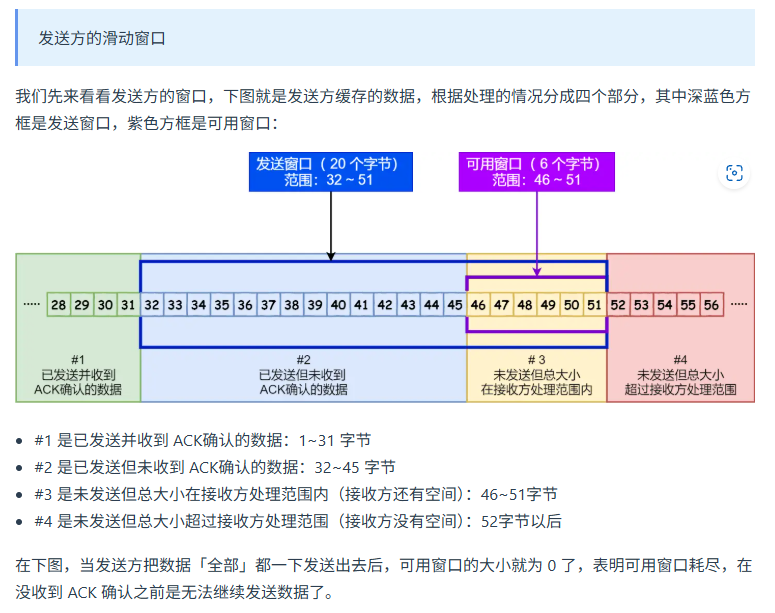
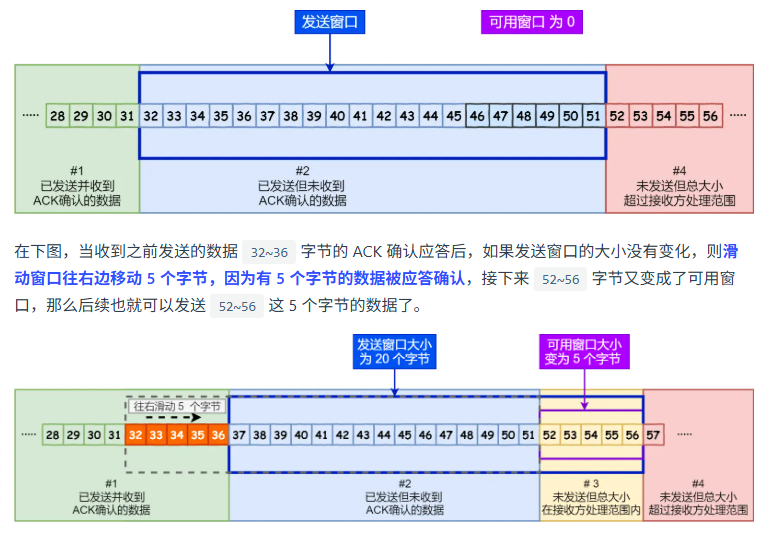
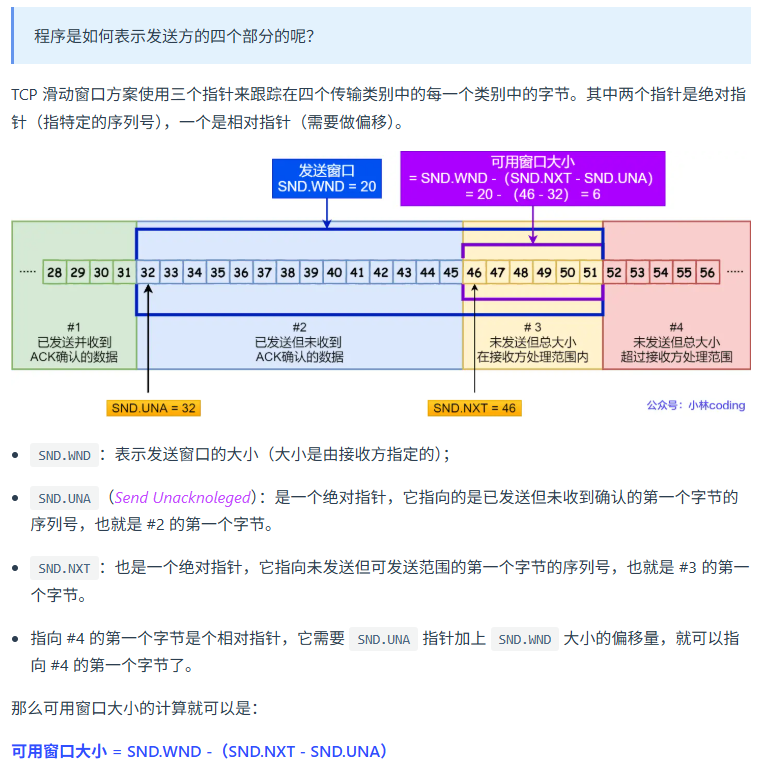
TCP为什么三次握手,两次不行?

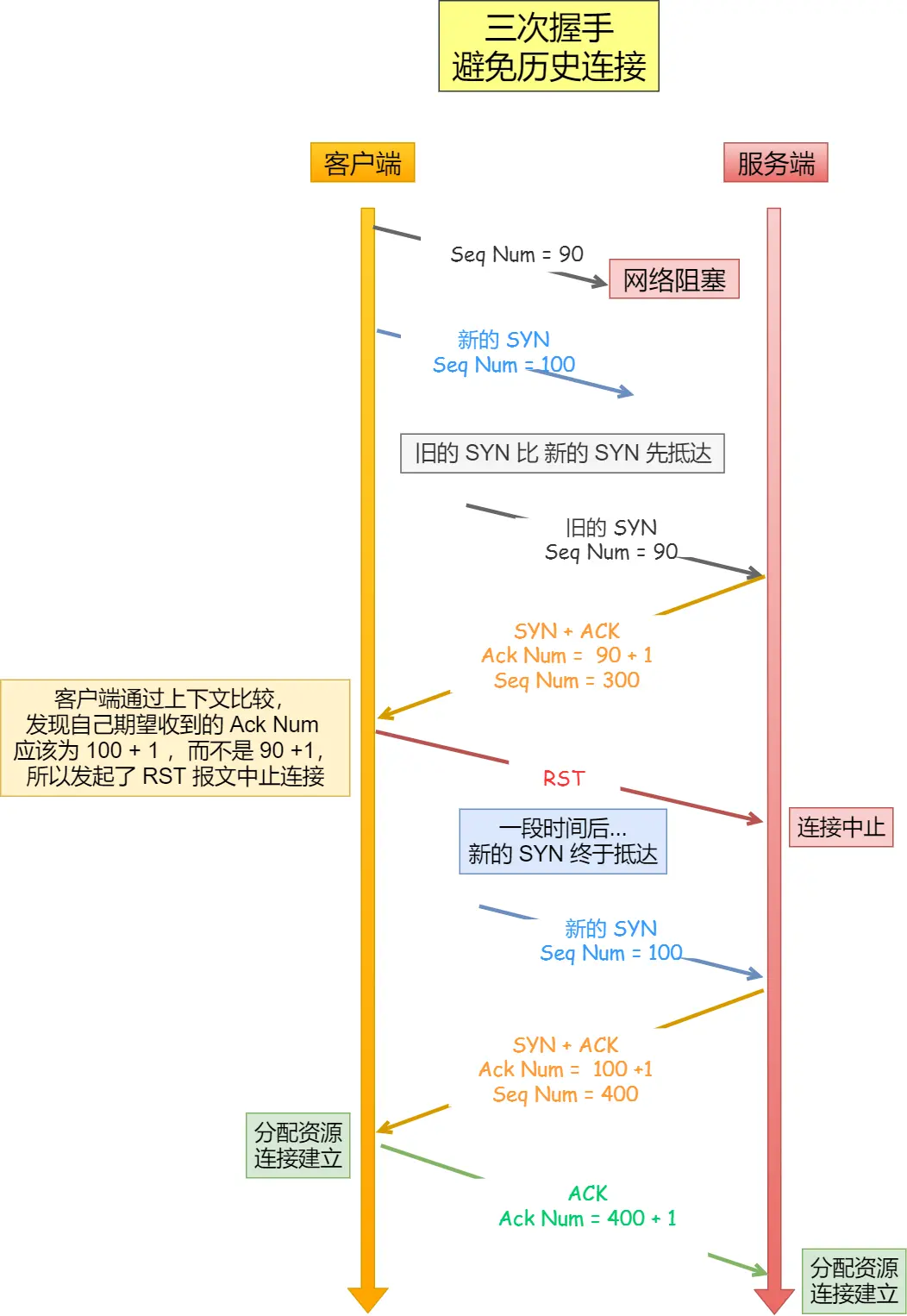


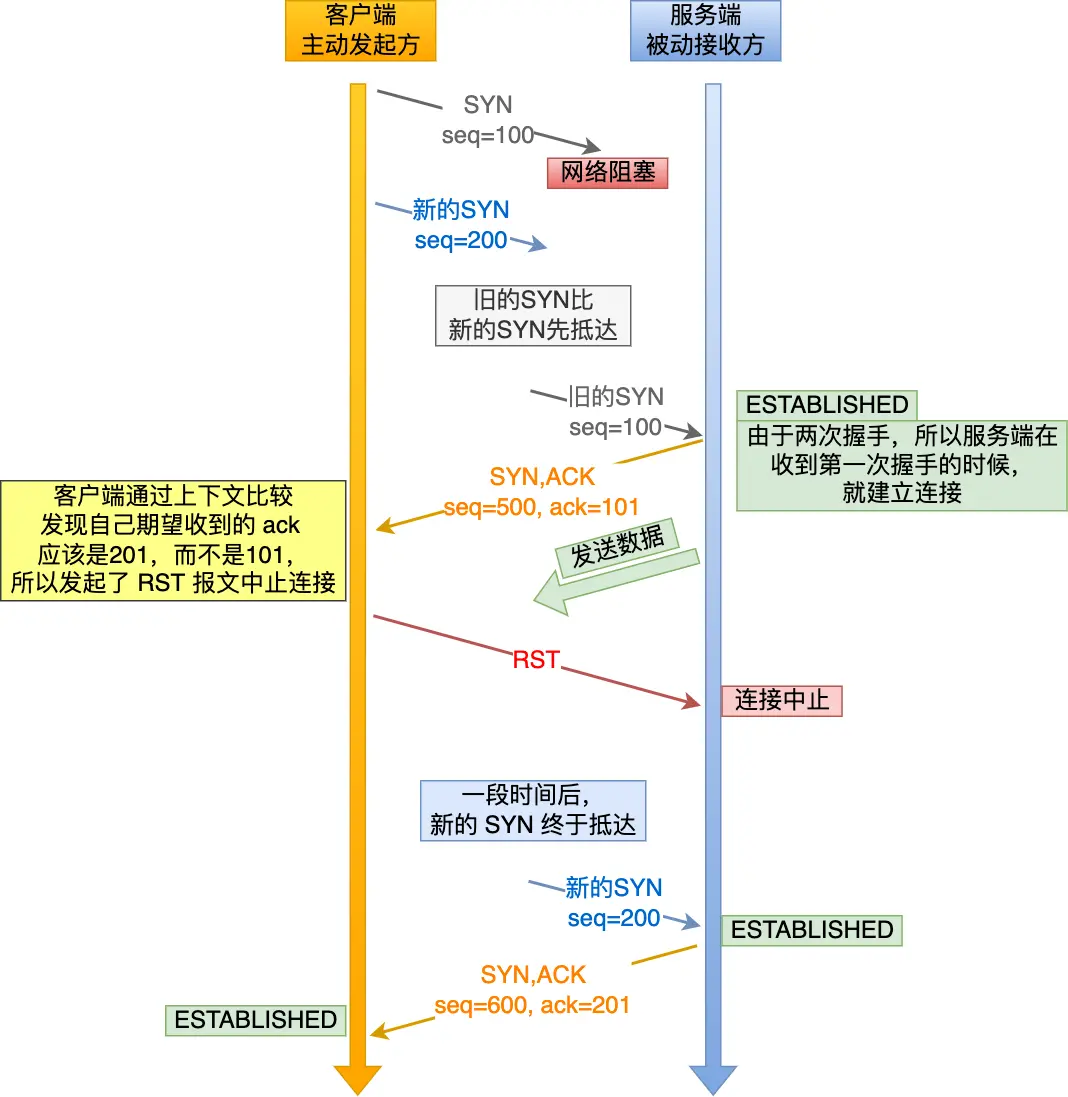



mysql中一张表有7条数据,id为1-7,现在删除最大两条,重启mysql,再插入一条数据,这个id是多少?
一张自增表里面总共有 7 条数据,删除了最后 2 条数据,重启 MySQL 数据库,又插入了一条数据,此时 id 是几?
一般情况下,我们创建的表的类型是InnoDB,如果新增一条记录(不重启mysql的情况下),这条记录的id是8;但是如果重启(文中提到的)MySQL的话,这条记录的ID是6。因为InnoDB表只把自增主键的最大ID记录到内存中,所以重启数据库或者对表OPTIMIZE操作,都会使最大ID丢失。
但是,如果我们使用表的类型是MylSAM,那么这条记录的ID就是8。因为MylSAM表会把自增主键的最大ID记录到数据文件里面,重启MYSQL后,自增主键的最大ID也不会丢失。
注:如果在这7条记录里面删除的是中间的几个记录(比如删除的是3,4两条记录),重启MySQL数据库后,insert一条记录后,ID都是8。因为内存或者数据库文件存储都是自增主键最大ID
ACID含义?

mysql左链接右链接内连接的区别?
在 MySQL 中,左连接(LEFT JOIN)、右连接(RIGHT JOIN)和内连接(INNER JOIN) 是三种常见的表关联方式,它们的核心区别在于 匹配规则 和 结果集范围。以下是详细对比:
1. 内连接(INNER JOIN)
-
作用 :返回 两个表中匹配的行。
-
特点 :
- 只保留两个表中共有的数据。
- 不匹配的行会被丢弃。
-
语法 :
sqlSELECT * FROM 表A INNER JOIN 表B ON 表A.字段 = 表B.字段; -
示意图 :
| 表A ∩ 表B | → 结果集 -
示例 :
查询所有有订单的客户信息(客户表和订单表匹配的记录)。
2. 左连接(LEFT JOIN)
-
作用 :返回 左表所有行 + 右表匹配的行 (右表无匹配时填充
NULL)。 -
特点 :
- 左表数据全部保留。
- 右表无匹配时补充
NULL。
-
语法 :
sqlSELECT * FROM 表A LEFT JOIN 表B ON 表A.字段 = 表B.字段; -
示意图 :
| 表A | → 结果集(包含表A全部,表B匹配部分) -
示例 :
查询所有客户及其订单信息(包括没有订单的客户)。
3. 右连接(RIGHT JOIN)
-
作用 :返回 右表所有行 + 左表匹配的行 (左表无匹配时填充
NULL)。 -
特点 :
- 右表数据全部保留。
- 左表无匹配时补充
NULL。
-
语法 :
sqlSELECT * FROM 表A RIGHT JOIN 表B ON 表A.字段 = 表B.字段; -
示意图 :
| 表B | → 结果集(包含表B全部,表A匹配部分) -
示例 :
查询所有订单及其客户信息(包括未关联到客户的订单)。
三者的核心区别
| 连接类型 | 保留的数据范围 | 未匹配时的填充 | 常见用途 |
|---|---|---|---|
| INNER JOIN | 两表匹配的行 | 不保留 | 精确关联数据(如订单和客户) |
| LEFT JOIN | 左表全部 + 右表匹配的行 | 右表填充 NULL |
保留左表所有记录(如客户分析) |
| RIGHT JOIN | 右表全部 + 左表匹配的行 | 左表填充 NULL |
保留右表所有记录(较少使用) |
直观对比(示例场景)
假设有两张表:
-
表A(客户):
id name 1 Alice 2 Bob 3 Charlie -
表B(订单):
order_id customer_id amount 101 1 100 102 3 200
不同连接的结果:
-
INNER JOIN(匹配客户和订单):
| Alice | 101 | 100 | | Charlie| 102 | 200 | -
LEFT JOIN(所有客户 + 订单信息):
| Alice | 101 | 100 | | Bob | NULL| NULL| | Charlie | 102 | 200 | -
RIGHT JOIN(所有订单 + 客户信息):
| Alice | 101 | 100 | | Charlie | 102 | 200 |
使用建议
- 优先使用 LEFT JOIN :
右连接可以通过调换表顺序用左连接实现(A RIGHT JOIN B=B LEFT JOIN A)。 - 明确需求 :
- 需要保留主表数据 → 用左/右连接。
- 需要精准匹配 → 用内连接。
- 性能注意 :
外连接(左/右)通常比内连接更耗时,避免对大表无限制使用。
一句话总结
- INNER JOIN:只要匹配的行。
- LEFT JOIN:左表全要,右表匹配的才要。
- RIGHT JOIN:右表全要,左表匹配的才要。
乐观锁和悲观锁?


怎么避免死锁?


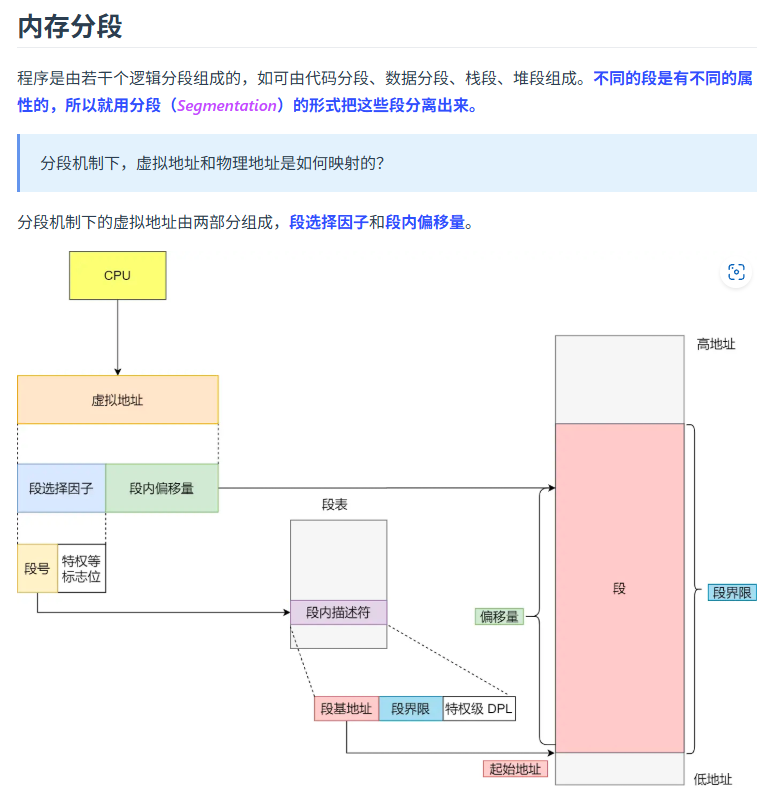
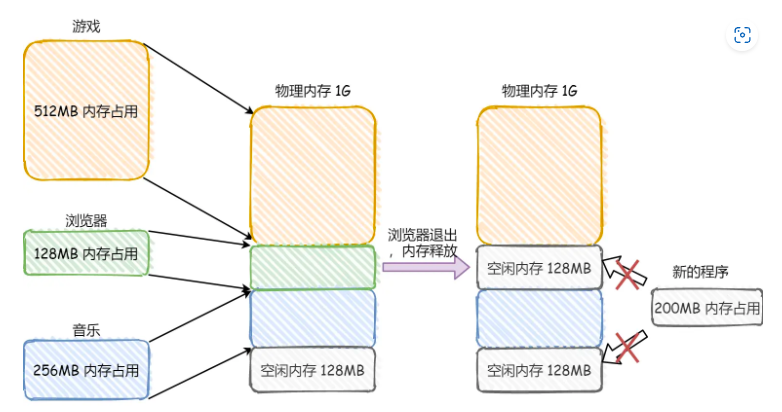
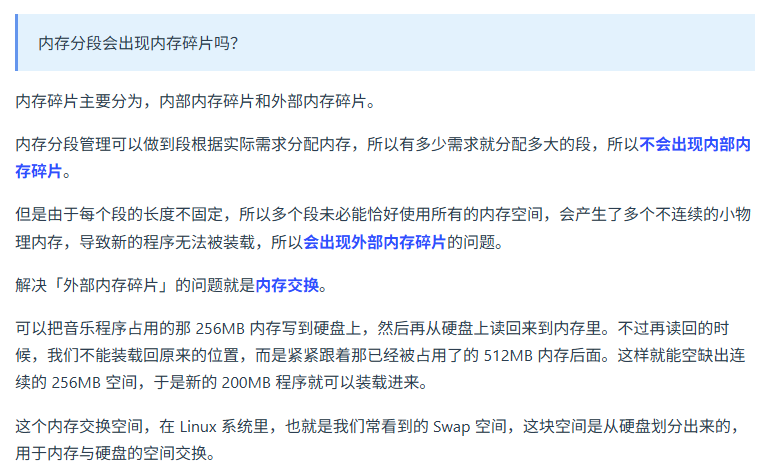
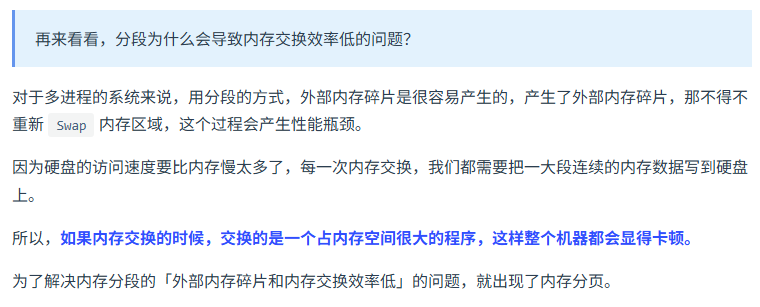
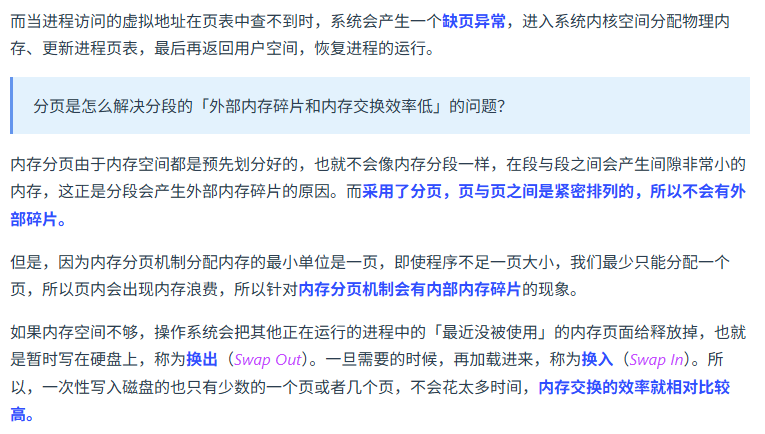
分页和分段管理的区别 ?
分段

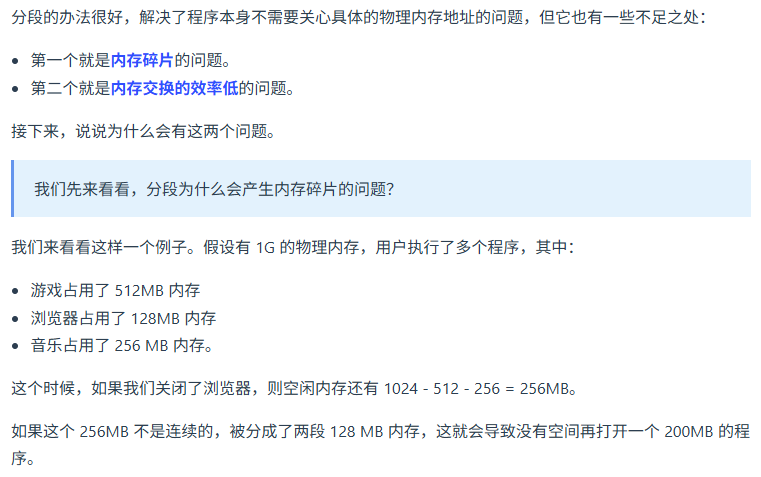
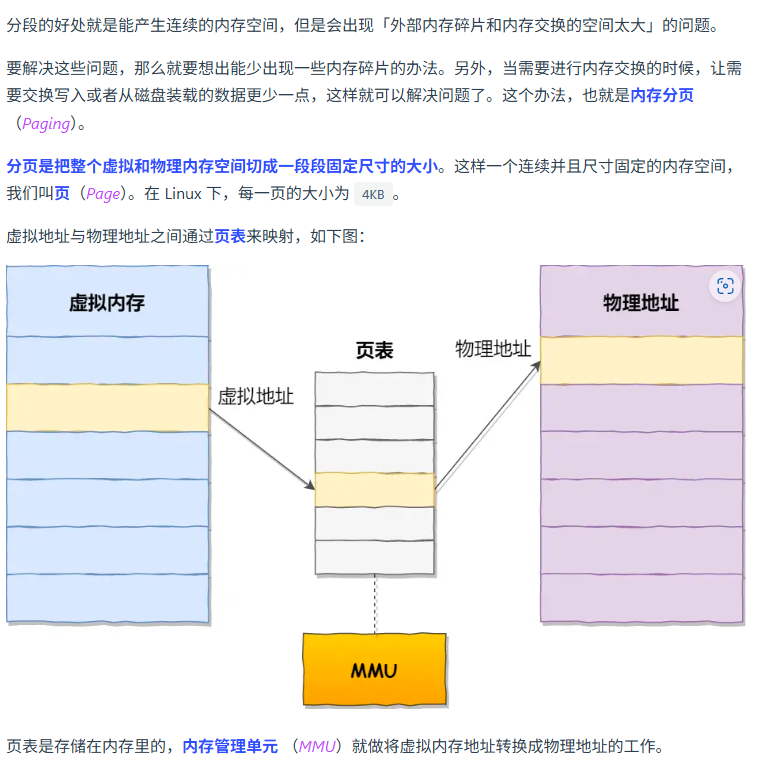
分页

操作系统内存偏高了,怎么分析?用到常用命令?
当操作系统内存使用偏高时,可以通过以下方法和常用命令进行分析:
1. 使用 top 命令
-
描述:实时查看系统的资源使用情况,包括 CPU 和内存使用。
-
命令 :
bashtop -
关注点 :
- 查看
%MEM列,了解各个进程的内存占用情况。 - 按
M可以按内存使用量排序。
- 查看
2. 使用 htop 命令
-
描述 :比
top更加友好的交互式进程查看工具。 -
命令 :
bashhtop -
关注点 :
- 可以直观地看到各个进程的内存使用情况。
- 支持进程的筛选和排序。
3. 使用 free 命令
-
描述:查看系统内存的使用情况。
-
命令 :
bashfree -h -
关注点 :
- 查看
total、used、free和available内存。 -h选项可以以人类可读的格式输出。
- 查看
4. 使用 vmstat 命令
-
描述:查看系统的内存、进程、IO 等状态。
-
命令 :
bashvmstat 1 -
关注点 :
- 每秒更新一次内存和进程状态。
- 查看
si和so列,了解交换内存的情况。
5. 使用 ps 命令
-
描述:查看当前运行的进程及其资源使用情况。
-
命令 :
bashps aux --sort=-%mem | head -
关注点 :
- 显示内存使用最多的前几个进程。
6. 使用 smem 命令
-
描述:查看每个进程的共享内存和独占内存使用情况。
-
命令 :
bashsmem -r -k -
关注点 :
- 计算出实际的内存使用情况,考虑了共享内存。
7. 使用 sar 命令
-
描述:收集和报告系统活动信息。
-
命令 :
bashsar -r 1 3 -
关注点 :
- 显示内存使用情况,提供历史数据。
8. 检查系统日志
-
描述:查看系统日志以获取内存使用异常的线索。
-
命令 :
bashdmesg | grep -i "memory" journalctl -xe
分析步骤
- 使用
top或htop确定高内存使用的进程。 - 使用
free和vmstat检查整体内存状态。 - 使用
ps和smem深入分析具体进程的内存使用情况。 - 查看系统日志以查找潜在的内存泄漏或错误。
通过这些工具和命令,可以有效地分析和诊断内存使用偏高的问题。
一个文件,第9列有很多数字,统计一下前十的数字有哪些?(linux命令)
参考:https://blog.csdn.net/weixin_48539059/article/details/131379880


shell
sed -n '8p' text.log | grep -o '[0-9]\+' | sort -n
1
1
1
2
2
2
2
3
4
5
9
34
sed -n '8p' text.log | grep -o '[0-9]\+' | sort -n | uniq -c | sort -k1
1 3
1 34
1 4
1 5
1 9
3 1
4 2
sed -n '8p' text.log | grep -o '[0-9]\+' | sort -n | uniq -c | sort -k1,1nr
4 2
3 1
1 3
1 34
1 4
1 5
1 91-100首尾相接,每隔四个剔除出一个,最后剩一个
https://leetcode.cn/problems/W7yuXW/
go
type ListNode1 struct{
val int
next *ListNode1
}
func Joseph_circle(people []int, k int) []int {
ans := []int{}
n := len(people)
if n==0{
return ans
}
idx := 0
// 构建初始列表
head := &ListNode1{val:people[0]}
q := head
for i:=1;i<n;i++{
q.next = &ListNode1{val:people[i]}
q = q.next
}
last := q
q.next = head
q = head
for len(ans)<n{
idx ++
if idx%k==0{
ans = append(ans, q.val)
last.next = q.next
}
last = q
q = q.next
}
return ans
}