一、魔塔社区免费服务器如何使用webui微调?
一上来我就得先记录一下,使用魔塔社区的免费服务器的时候,因为没有提供ssh而导致无法看到webui的遗憾如何解决的问题?
 执行命令
执行命令
如果点这个链接无法弹出微调的webui,则可以在启动webui的命令之前设置了一些环境变量。
bash
CUDA_VISIBLE_DEVICES=0 GRADIO_SHARE=1 GRADIO_SERVER_PORT=7860 llamafactory-cli webui- 通过
CUDA_VISIBLE_DEVICES=0,确保程序只使用编号为0的 GPU,避免占用其他 GPU 资源。 - 使用
llamafactory-cli webui启动一个基于 Gradio 框架的 Web 用户界面。 - 通过
GRADIO_SHARE=1,生成一个公共 URL,允许其他人通过互联网访问你的 WebUI。 - 通过
GRADIO_SERVER_PORT=7860,将 WebUI 的服务端口固定为7860。
二、llamafactory工程文件目录里面都有是些什么?
 目录结构
目录结构
"LLaMA-Factory"的项目目录结构。以下是对各个文件夹和文件的简要说明:
| 文件夹/文件 | 简要说明 |
|---|---|
| assets | 通常用于存放项目的静态资源,如图片、样式表等。 |
| data | 用于存放数据集或模型训练所需的数据。 |
| docker | 包含与Docker相关的配置文件和脚本,用于容器化部署。 |
| evaluation | 可能包含评估模型性能的脚本和工具。 |
| examples | 示例代码或使用案例,帮助用户了解如何使用该项目。 |
| scripts | 脚本文件,自动化任务或辅助工具。 |
| src | 源代码文件夹,存放项目的主程序代码。 |
| tests | 测试文件夹,存放单元测试和其他测试脚本。 |
| CITATION.cff | 引用格式文件,指导如何正确引用此项目。 |
| LICENSE | 许可证文件,说明项目的使用许可条款。 |
| Makefile | 构建文件,定义了编译和构建项目的规则。 |
| MANIFEST.in | Python打包工具(如setuptools)使用的文件,指定哪些文件应该被包含在发布包中。 |
| pyproject.toml | Python项目配置文件,用于管理项目依赖和构建设置。 |
| README.md | 项目的英文README文件,提供项目介绍和使用指南。 |
| README_zh.md | 项目的中文README文件,提供项目介绍和使用指南。 |
| requirements.txt | 列出项目运行所需的Python包及其版本。 |
| setup.py | Python项目的安装脚本,用于打包和安装项目。 |
三、webui里面的微调参数的都是什么意思?
虽然把界面设置成中文,基本都能读懂,但还是有必要对一些参数做点说明:
|-----------------------|---------------------------------------------------------|----------------------------------------------------|
| 名字 | 解释 | 补充 |
| 模型路径 | 一般是服务器中存放模型的绝对路径。也可以是huggingface上面的模型标识符。 | 建议自己下载到本地,然后用本地服务器的绝对路径。 |
| 微调方法 | 常用就2个,LoRA和QLoRA | |
| 检查点路径 | 训练过后保存模型权重的路径,方便你做增量训练 | |
| 量化等级 | 具体要损失多少精度,提升多少推理速度,常用有8bit、4bit量化等级 | |
| 量化方法 | 实现量化的具体技术,比如线性量化或非线性量化 | 一般使用bitstandbytes开源量化库 |
| 对话模板 | 构建提示词使用的模板,要和你想微调的模型保持一致 | |
| 日志间隔 | 默认是每5轮epoch保存一次日志 | |
| 保存间隔 | 默认是每100epoch保存一次模型权重 | 会在每次保存权重之前,去跑一次验证 |
| 输出路径 | 输出路径就是保存你训练好的LoRA模型参数的路径。 | 一般是在一个叫做save/模型名字/lora下面,用chekpoint来命名,LoR模型无法单独使用 |
| 配置路径 | 配置路径的意思就是webui设置好的参数,生产一个yaml文件,可以用这个文件去等效的用在命令行中做微调训练 | 将webui的配置保存成一个yaml |
| 验证集比例 | 在每一次保存权重之前做验证的时候用到 | |
| 量化数据集 | 用来衡量量化前后 | |
| LoRA秩 | LoRA训练中的秩大小,影响LoRa训练中自身数据对模型作用程度,秩越大作用越大,需要依据数据量选择合适的秩。 | 一般设置在32到128之间,默认是8 |
| LoRA缩放系数 | LoRa训练中的缩放系数,用于调整初始化训练权重,使其与预训练权重接近或保持一致。 | 一般是LoRA秩的两倍,一般设置个128、256 |
| 截断长度 | 单个训练数据样本的最大长度,超出配置长度将自动截断。 | |
| 批处理大小 | 批次大小代表模型训练过程中,模型更新模型参数的数据步长,模型每看多少数据即更新一次模型参数。 | 合适的batch size可以加速训练 |
| deepspeed stage | 选择分布式多卡训练的模式 | 有三种模式,一般用第二种 |
| deepspeed offload | 将一部分数据从显存放到内存中 | 会很耗时间 |
四、直接使用webchat来和指定模型对话
虽然可以在webui的chat中和指定的模型去对话。但llamafactory还单独给了一个命令,能够起一个webchat来加载模型进行对话。
bash
llamafactory-cli webchat --model_name_or_path MODEL_NAME_OR_PATH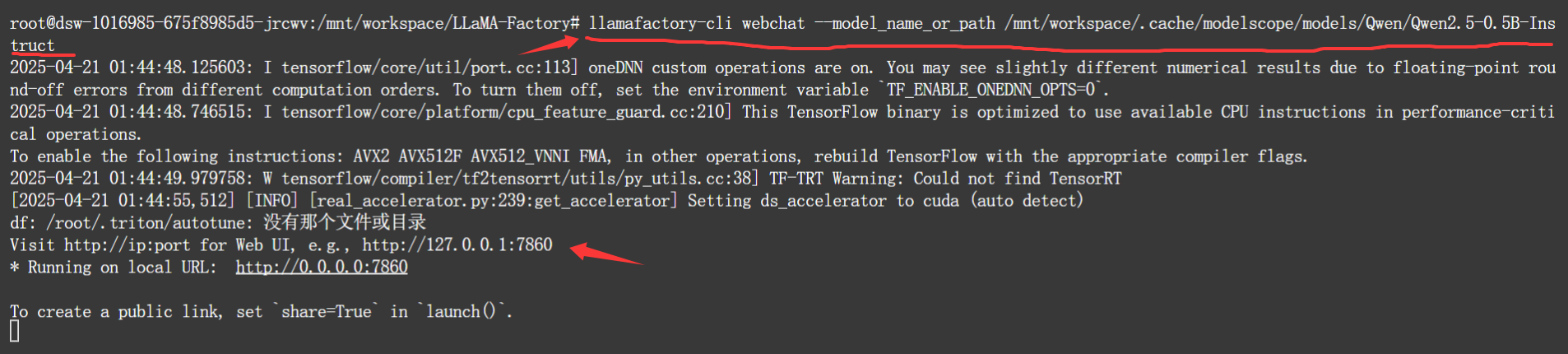 执行命令
执行命令
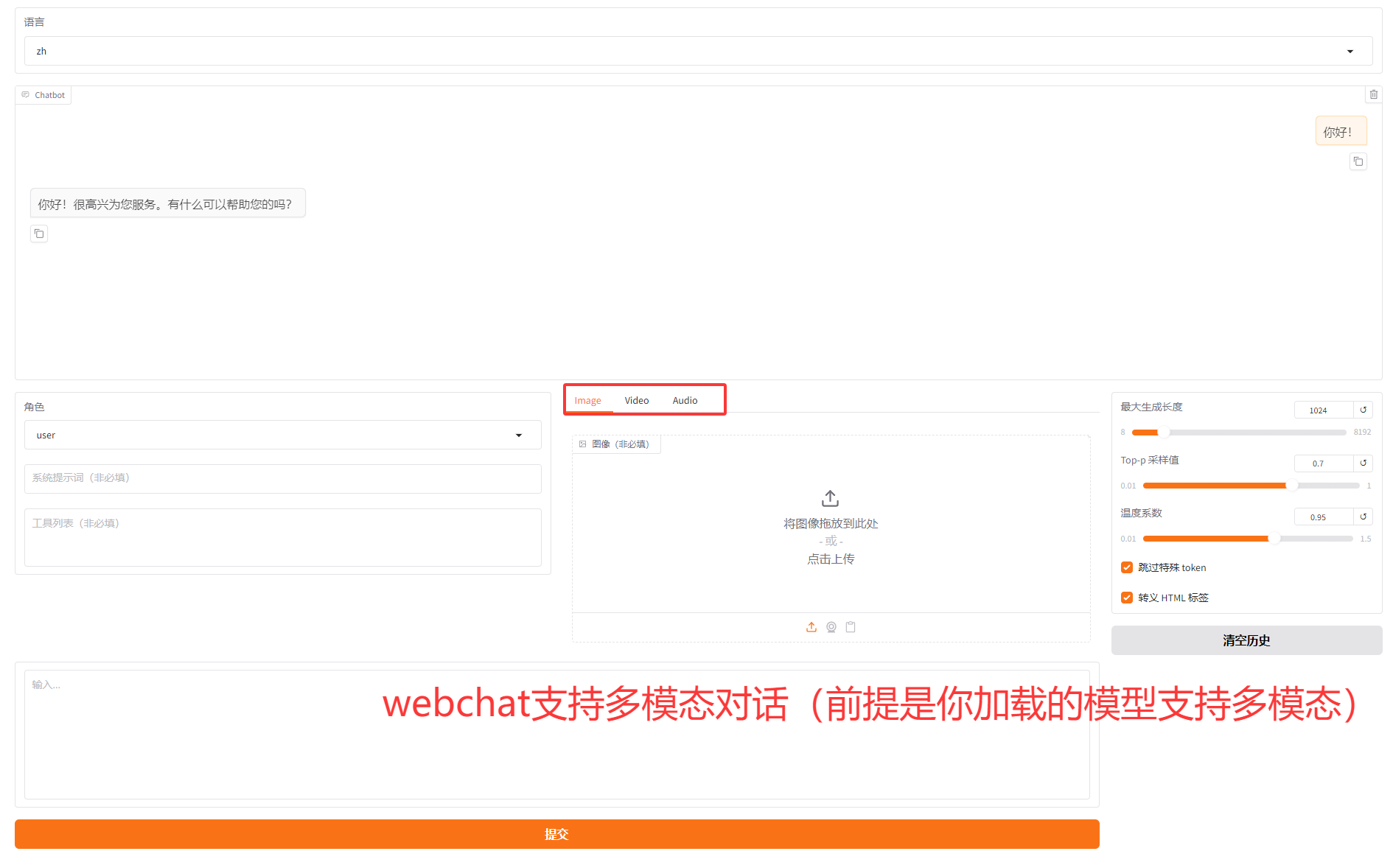 llamafactory自带的webchat
llamafactory自带的webchat
后续持续更新有关使用llamafactory过程中的我觉得值得记录的内容。