这几天,不论国内国外,人们都在关注 DeepSeek 发布的 V3.1 新模型。
它采用了全新的混合推理架构,让模型能在一个统一框架内支持「思考」与「非思考」两种模式。V3.1 通过训练后优化,在工具使用与编程、搜索等智能体任务上表现均获得了较大提升。
Deepseek V3.1 的很多基准测试结果已经陆续在 SWE-bench 等榜单上出现。此外,新模型在 Aider 多语言编程基准测试中得分超越了 Anthropic 的 Claude 4 Opus,同时还有显著的成本优势。
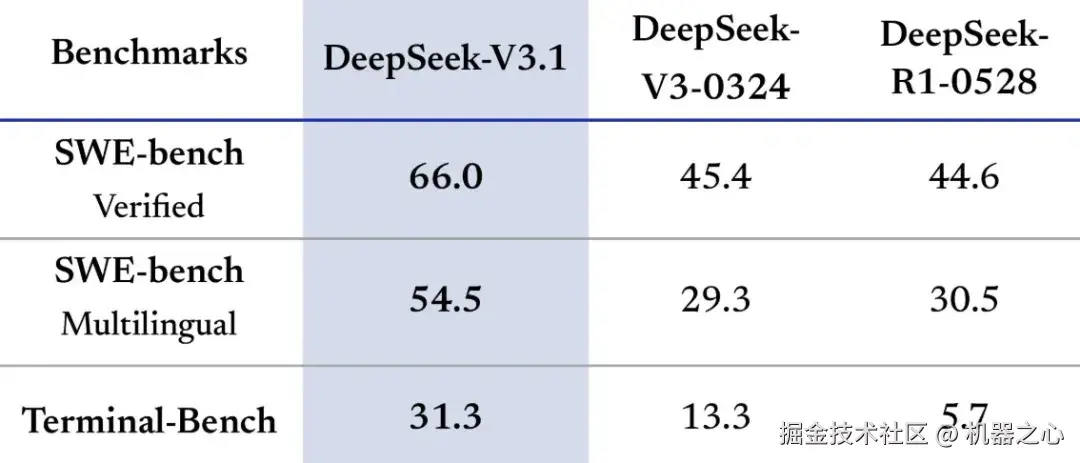
与 DeepSeek 自己此前的模型相比,V3.1 的性能提升显著,它解决问题需要更多步骤,但经过了思维链压缩训练,在任务表现持平的情况下,token 消耗量可以减少 20-50%,因此有效成本与 GPT-5 mini 相当。
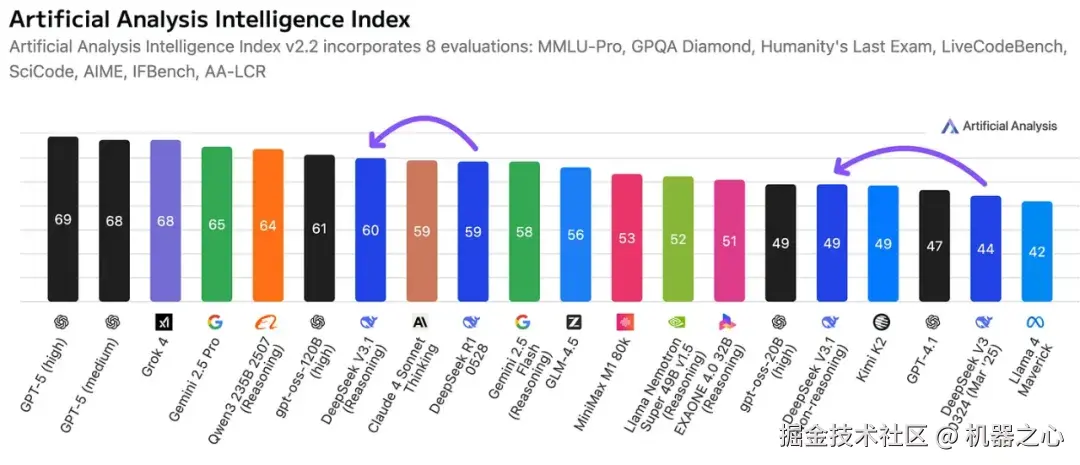
除了模型性能的提升之外,值得关注的是,DeepSeek 昨天在其微信公众号文章介绍 DeepSeek V3.1 的时候,特意回复指出,UE8M0 FP8 是针对即将发布的下一代国产芯片设计的机制。
这就引发了人们的很多猜想。

根据 Hugging Face 的介绍文档,DeepSeek V3.1 的模型参数量为 685B,其在训练过程中采用了 UE8M0 FP8 缩放浮点格式,以确保与微缩放浮点格式的兼容性。

其中,E 和 M 分别代表指数(Exponent)和尾数(Mantissa)的位数,U 表示无符号(Unsigned),可能针对激活值的非负特性优化。因此,UE8M0 可能是指新模型应用的特殊量化策略。
所谓 FP8,其全称为 8-bit floating point(8 位浮点数),是一种超低精度的数据表示格式,用于深度学习中的训练与推理。相较于 FP32(单精度)或 FP16(半精度)等传统浮点格式,FP8 的主要优势包括如下,因此可以在尽量保持数值稳定性和模型精度的前提下,进一步降低存储和计算开销:
-
显著节省显存,比如 FP32 占 4 字节,FP16 占 2 字节,而 FP8 仅占 1 字节。当推理规模达到百亿甚至千亿参数时,节省极为可观;
-
提升计算效率,FP8 可以在硬件上实现更高的并行度,比如 NVIDIA Hopper GPU 的 FP8 Tensor Core 吞吐量是 FP16 的两倍;
-
保持模型精度,FP8 通过缩放因子以及混合精度训练,在多数场景下能接近 FP16/FP32 的精度。
近年来,除了 NVIDIA 之外,Meta、英特尔、AMD 等也都开始研究 FP8 训练与推理,有成为业界「新黄金标准」的趋势,核心思路在于「两个格式配合使用」。此次,DeepSeek V3.1 此次采用 UE8M0 FP8,意味着其开始在 FP8 技术栈上做自主创新。
从传统浮点数的表示来看,UE8M0 没有符号位和尾数位,8bit 全部用在了指数位。
根据很多人的猜测,UE8M0 只能表示非负数,将覆盖非常大的正数范围或者零;8bit 全部用于指数,代表了极宽的范围,尤其适合处理梯度、激活值等跨数量级变化极大的数据;没有尾数,代表了数值精度极低(在某个指数范围内无法表达中间值),误差也可能非常大。
此外,根据前文提到的要兼容微缩放浮点格式,这种格式的思路是在小块数据中引入外部缩放因子来补偿精度。因此 UE8M0 也可能采用这种思路,从而在国产芯片中实现低比特宽度存储和快速计算。
而在国内,包括华为、寒武纪在内多家厂商的新一代 AI 芯片都可以支持 FP8 格式,这也让它们再次成为业界和资本圈关注的焦点。其中华为提出的 HiFloat8 (HiF8)方案通过「单一格式 + 锥形精度(tapered precision)」的思路,能够兼顾精度和范围,覆盖正向和反向传播。
最后,很多人可能依然好奇,DeepSeek V3.1 是使用国产芯片训练的吗?
毕竟 DeepSeek R2 越来越近了,前几天英国《金融时报》的报道刚刚「预热」过一波:
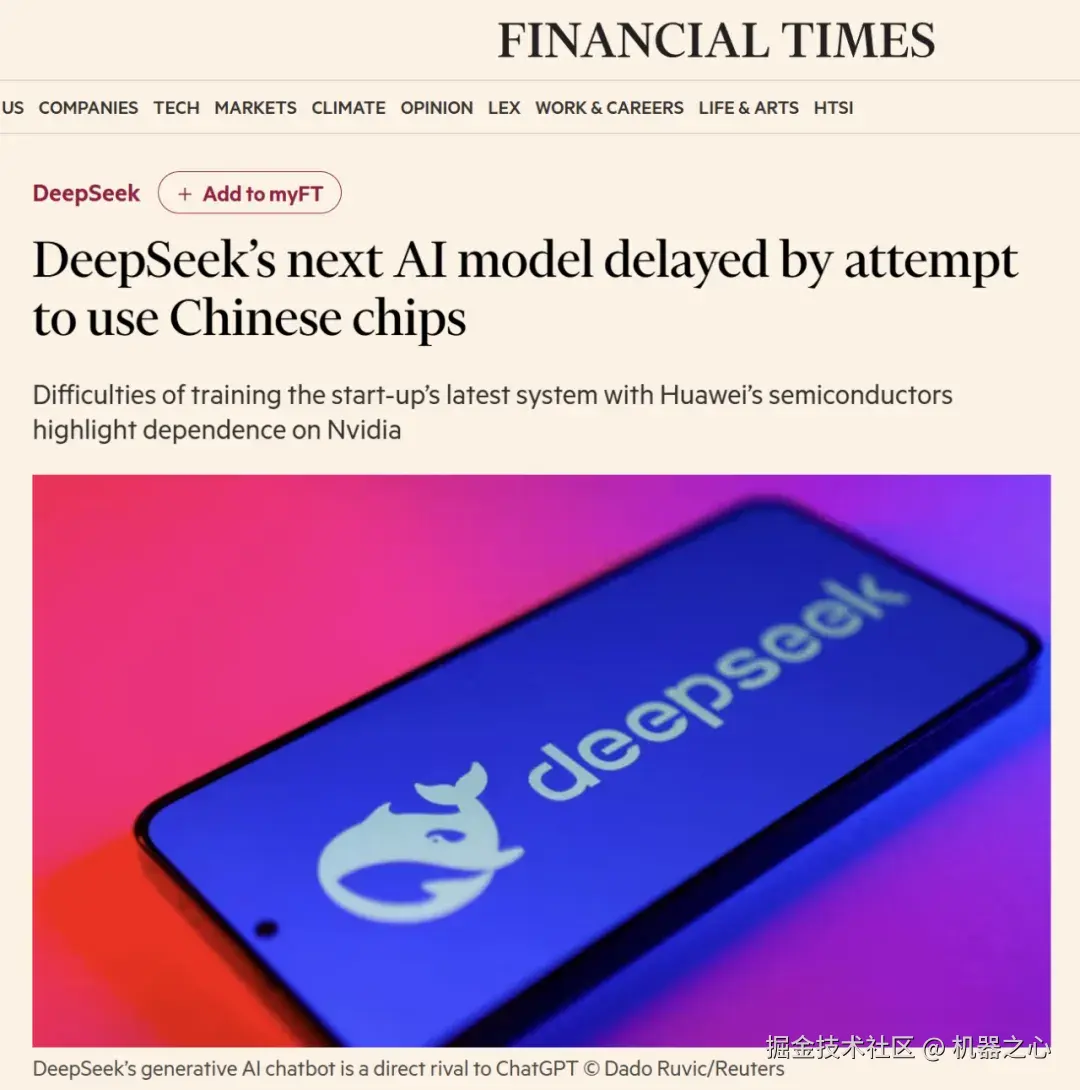
上周四,FT 说 DeepSeek R2 延迟是因为其使用了国产芯片进行训练,DeepSeek 随即否认。
目前看来,在 DeepSeek V3.1 上使用国产芯片训练的概率还比较小,UME8 M0 应该是为国产推理芯片优化所使用的机制。
不过既然 DeepSeek 这回已经明确指出了,我们可以期待未来国产开源大模型,针对华为昇腾、寒武纪等 AI 芯片实现专门优化,并大规模应用。
参考链接: