Therefore, using floating-point precision for neural network inference is preferred in certain situations. However, the deployment of standard floating-point (IEEE-754) neural networks on FPGAs leads to a considerable resource overhead, resulting in inadequate arithmetic computation power and low execution efficiency. Unlike fixed-point precision, where addition and multiplication can be efficiently implemented using FPGA's internal DSP resources, floating-point operations require much more FPGA resources. Specifically, floating-point addition comprises of exponential alignment, sign judgment, fixed-point addition, and exponential normalization. Except for the fixed-point addition that can be implemented with DSP, all the other operations require FPGA fabric and wiring resources. Similarly, the floating-point multiplication operations include fixed-point multiplication, overflow judgment, and exponential normalization, where additional fabric and wiring resources are also required. Moreover, neural network computation usually involves the accumulation of enormous intermediate product results (i.e. the partial sums). However, for floating-point precision, all product results must be shifted before addition, making it impossible to utilize the DSP's cascading circuit for optimization. Moreover, the multi-cycle process of floating-point addition prevents back-to-back accumulation, which greatly affects the overall performance.
因此,在某些情况下,使用浮点精度进行神经网络推理是首选。然而,在 FPGA 上部署标准浮点(IEEE-754)神经网络会导致相当大的资源开销,从而导致算术计算能力不足和执行效率低下。与定点精度的加法和乘法可以利用 FPGA 内部的 DSP 资源高效实现不同,浮点运算需要更多的 FPGA 资源。具体而言,浮点加法包括指数对齐、符号判断、定点加法和指数归一化。除了定点加法可以用 DSP 实现外,其他所有运算都需要 FPGA 的架构和布线资源。同样,浮点乘法包括定点乘法、溢出判断和指数归一化,也需要额外的架构和布线资源。此外,神经网络计算通常涉及大量中间乘积结果(即部分和)的累积。然而,对于浮点精度,所有乘积结果都必须在加法之前进行移位,这使得无法利用 DSP 的级联电路进行优化。而且浮点加法的多循环过程会阻止连续累加,这极大地影响了整体性能。
Optimizing FPGA-Based DNN Accelerator With Shared Exponential Floating-Point Format
https://ieeexplore.ieee.org/document/10218392
本文提出了一种新的浮点格式 , 称为共享指数浮点 (SFP),旨在结合低精度和共享指数方案的优势。具体而言,SFP 能够利用共享指数实现较高的数据压缩率,同时在低精度格式下保持良好的 DNN 模型精度。此外,SFP 针对 FPGA 设计进行了优化。基于此格式,我们提出了一种基于 FPGA 的高效浮点神经网络加速器。实验表明,该加速器的资源消耗与 INT8 加速器相当,且能够实现较高的计算效率。此外,我们对多种神经网络进行了测试,结果表明,该格式可用于直接量化全精度模型,并且无需微调即可实现非常低的精度损失(±1%)。本文的主要贡献如下:
- 我们提出了一种用于面向 FPGA 的神经网络计算的新型浮点格式 SFP,与现有的低精度浮点格式相比,它具有更高的存储密度,更适合 FPGA 乘法累加电路实现。
- 我们提出了一种针对 FPGA 优化的新型 DNN 加速器,它同时支持 INT8 和我们提出的浮点格式 SFP。矩阵乘法累加单元经过高度优化,可以充分利用 FPGA 架构资源。
- 我们提出了一种硬件-软件协同调度方案来平衡神经网络计算和存储带宽,从而在有限的 DDR 带宽下最大限度地提高所提出的神经网络计算电路的效率。
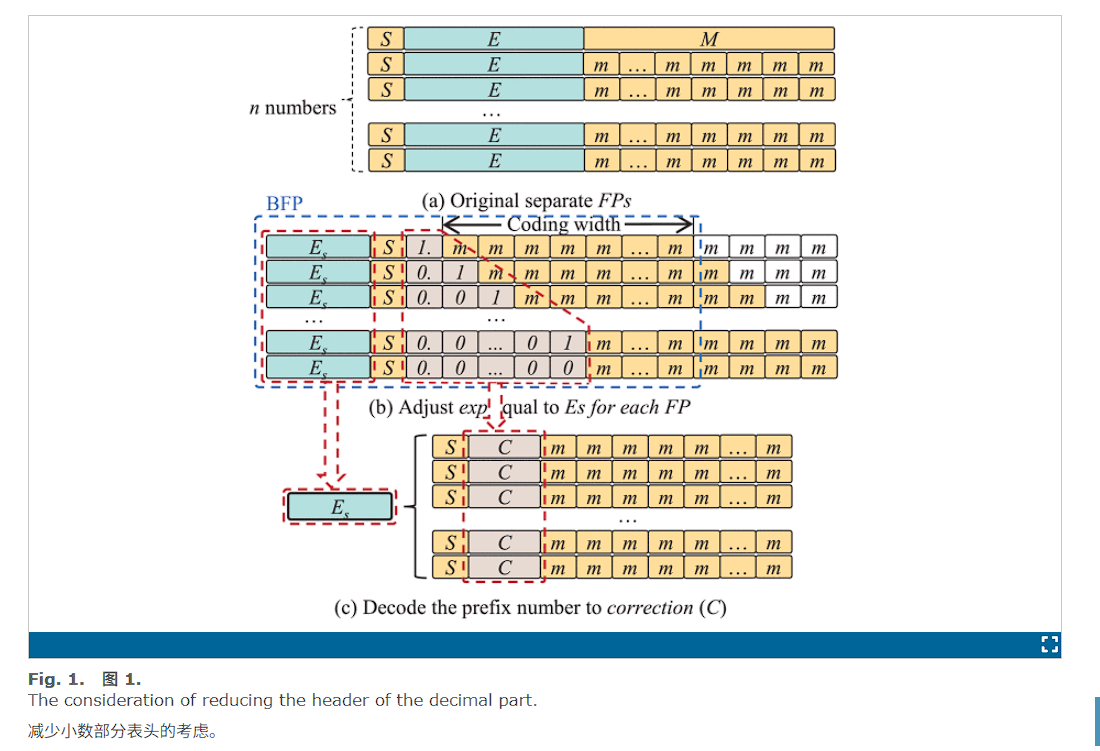
Fig. 1(a) and (b) 描述了 BFP 格式的定义。我们考虑编码 n 浮点数作为一个块,如 Fig. 1(a) 所示。块中的每个数据由 E ,年代 和 M ,分别表示指数、符号、尾数部分,其中 S 和 M 构成数字的小数部分,并且 E 是指数部分。通过在块内共享指数,我们可以有效地压缩浮点数据的大小。具体来说,我们选择块中的最大指数值作为共享指数 E s 。如 Fig. 1 (b) 所示,当一个数字调整其 E 到 E s ,其 M 必须根据 E 之间的差异向右移动 和 Es 。