以【5 Stage pipeline CPU】搜索图片,选取5幅有代表性的图列举如下,并结合Chisel代码进行理解和点评。
图1:原文链接如下
https://acsweb.ucsd.edu/~dol031/posts/update/2023/04/10/5stage-cpu-pipeline.html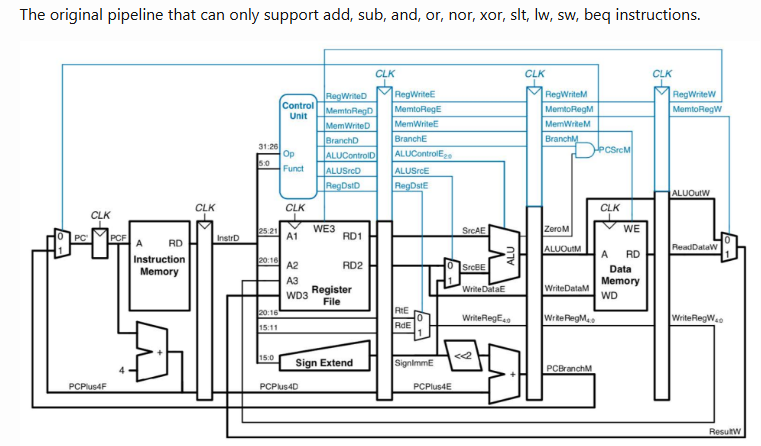
点评:黑色的部分是"数据通路"。蓝色的部分是"控制通路"。这个图的新颖之处就在于数据通路和控制通路在一张图中呈现并且通过颜色明显区分!在搜索引擎列出的一大堆图中很快关注到这个图,并以此作为"标杆",关注数据通路+控制通路 都有的"全景图",而不是只有数据通路的"裁剪图"。
图2:原文链接如下:
https://github.com/shivpvtel/Five-Stage-Pipelined-CPU-Verilog
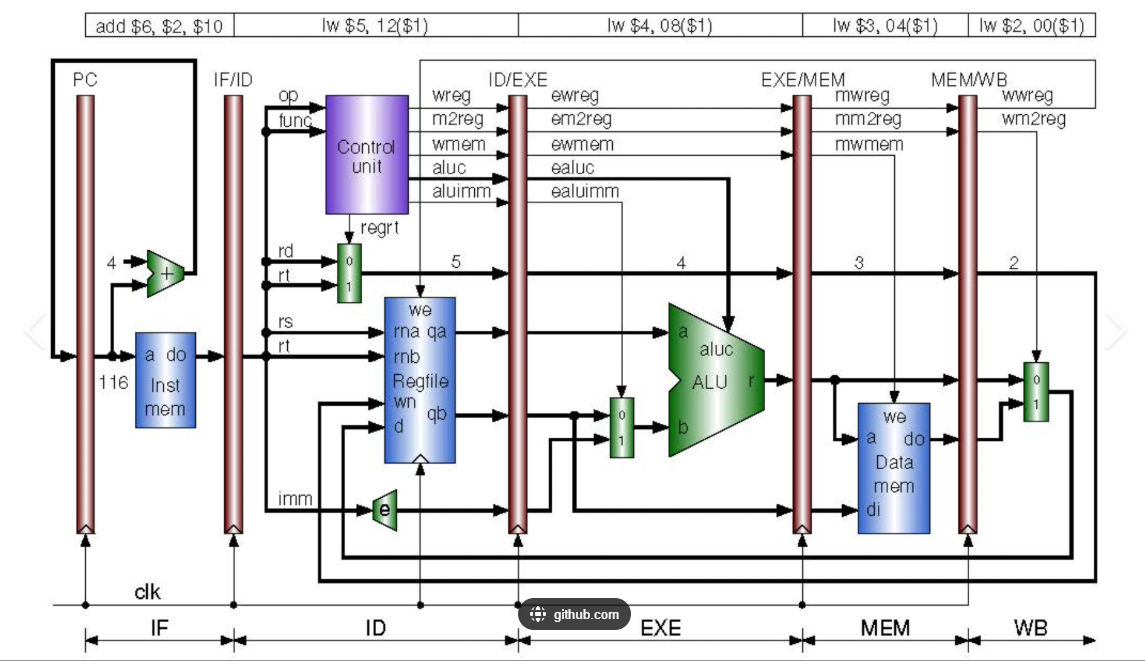
点评:同样有那个Control Unit单元以及它所控制的信号链条,代表了控制通路!此图的亮点有两处:一是控制通路带了箭头更清晰地表达了控制的过程。二是和ChipCamp/riscv-chise-book的代码中所展示的5-Stage Pipeline的命名是一致的,都是IF-ID-EXE-MEM-WB这样5个Stage。其中,ID/EXE的右侧寄存器,都增加了一个e代表EXE。EXE/MEM的右侧寄存器,将e改为m代表MEM。ME/WB的右侧寄存器,将m改为w代表WB。命名也比较规范。
图3:原文链接如下:
https://nlitz88.github.io/projects/mipscpu/mipscpu/
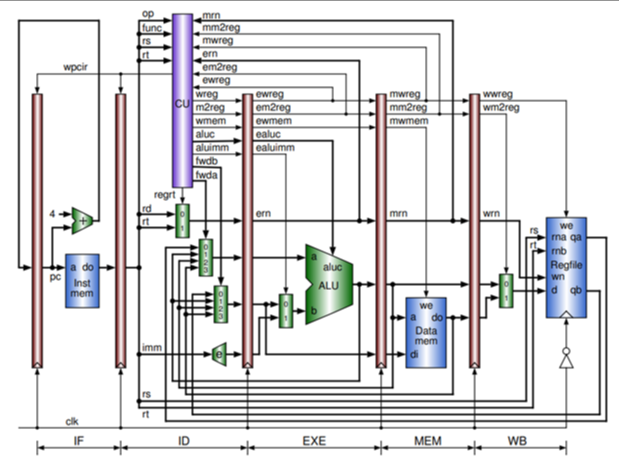
点评:这个图同样有一个控制单元CU以及它所控制的信号链条,代表了控制通路。此图相对于上图来说有更多的细节之处,在于清晰地标识了多个阶段的控制信号"反馈"到CU上!也就是mm, mm2reg等指向CU的箭头。CU对除了Regfile外的各个电路单元的直接控制信号也更加多一些,比如对ID阶段的多个Mux的控制,而对EXE阶段的ALU及MUX的控制则和上一幅图基本一样。
图4:原文链接如下:
https://github.com/shivpvtel/Five-Stage-Pipelined-CPU-Final-Project-Verilog
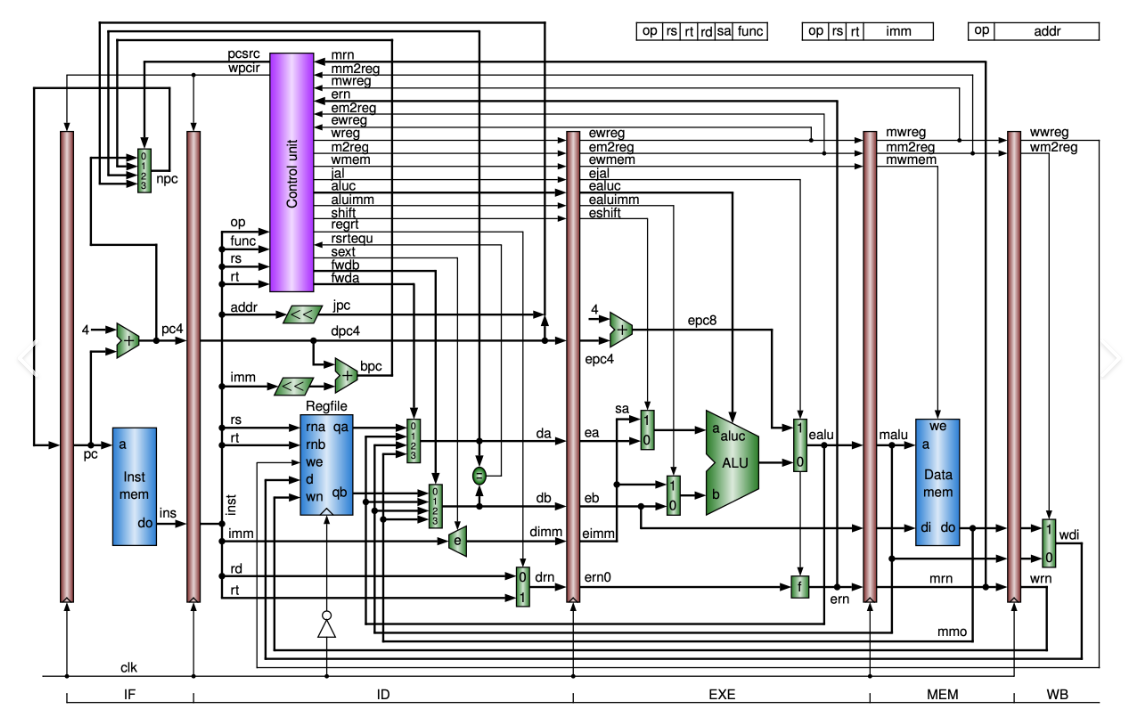
点评:这个图同样有一个控制单元CU以及它所控制的信号链条,代表了控制通路。此图相对于上图来说有更多的细节之处,在于反馈和正馈的控制信号都更多了。
图5:原文链接如下:
https://github.com/Ammarkhan561/RISCV-32I-5-Stage-Pipelined-Processor
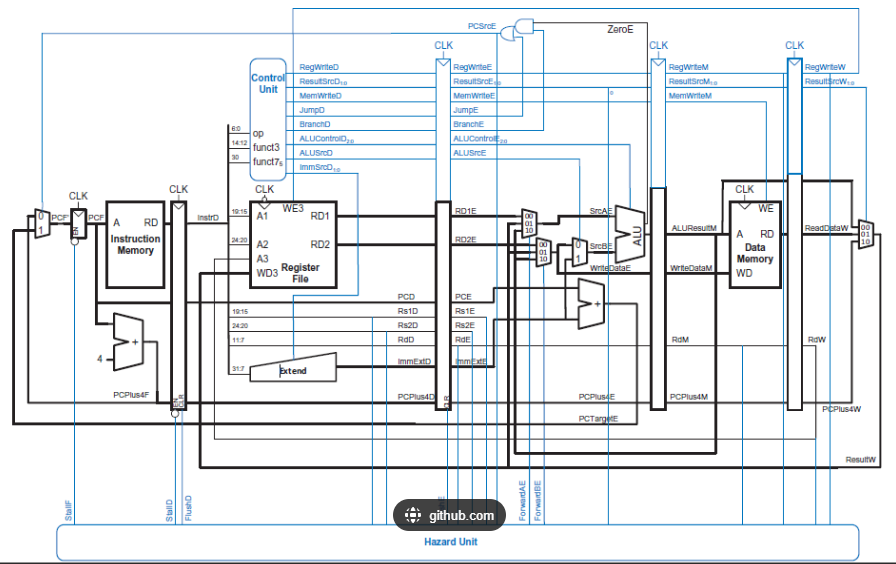
点评:这个图其实是和第一幅图比较接近,但增加了下面的Hazard Unit(冒险单元),和上面的Control Unit相对应。而且合格Hazard Unit直观一眼看到的"特征"就是全局控制----直接控制位于多个Stage内的电路。与此相对应的是,Control Unit单元是分级正向控制(正馈) + 直接获取多级反馈。这在前面的图3和图4中特别明显。正向的控制,通过多级模块之间的寄存器传输以及位于级内的控制模块响应这一侧的信号变化,时钟信号主要用于驱动寄多级模块之间的寄存器传输!
图6:原文链接如下(是图5文章的一个对照,5-Stage-pipeline-processor vs Single-cycle-processor,意外地收获到这样的"对比",太稀罕了):
https://github.com/Ammar-10xe/RISCV-32I-Single-Cycle-Processor
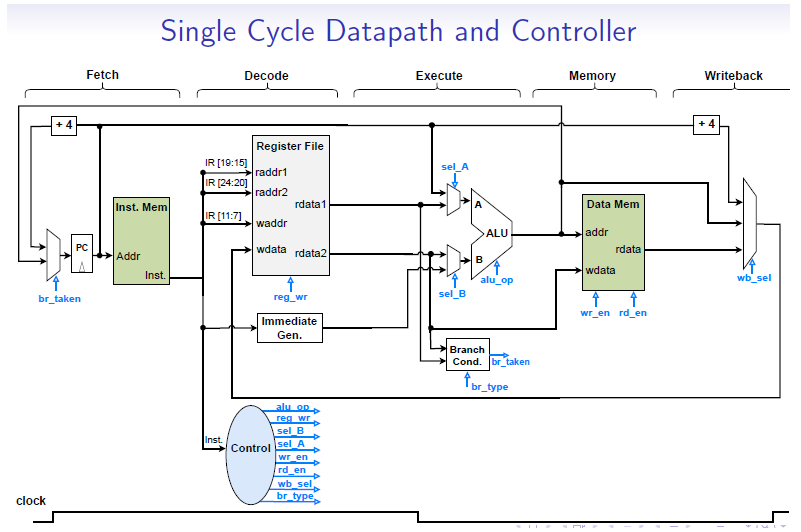
点评:这个单周期处理器(Single Cycle Processor)同样也有Control Unit。这个Control Unit有什么特点呢,在上面的图5的例子中Hazard Unit就是直接控制位于多个Stage内的电路模块,而本图中的Control Unit也是!这正是Single Cycle Processor的特点,即控制单元直接控制"全局"的众多信号。而与此对应,5-Stage Pipeline Processor则是通过多级Inter-Stage的Register来分域控制!Inter-Stage Register在Clock的控制下实现左侧->右侧的寄存器传输,每个Stage的组合电路则受本Stage的Register的变化而实现响应(组合电路响应)。
Control Unit单元是分级正向控制(正馈) + 直接获取多级反馈。这在前面的图3和图4中特别明显。那么代码中是怎么样的呢?
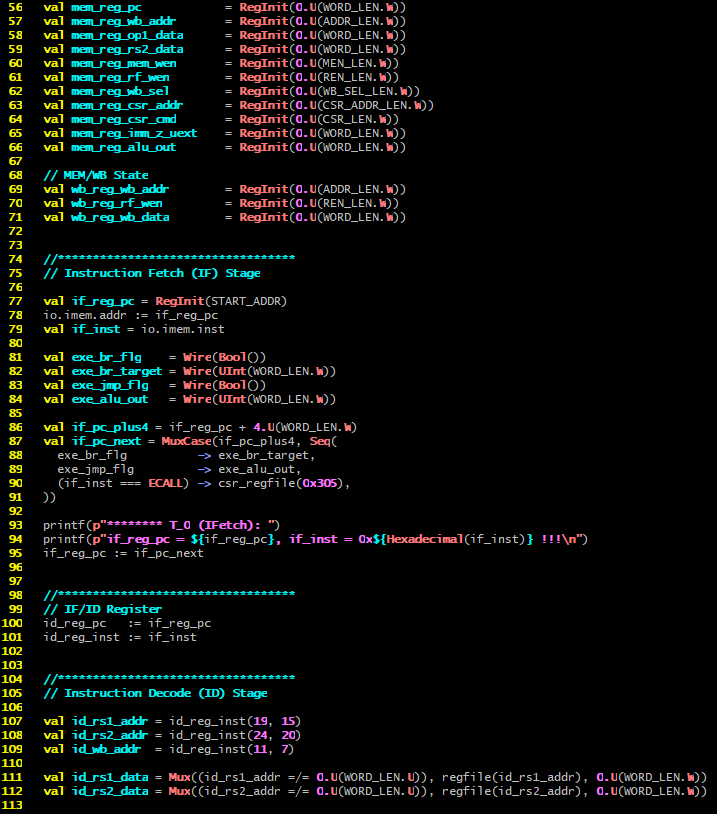
下面的例子是05_riscvtests/Core.scala文件的一部分,其中第87行,在设置if_pc_next的时候(也就是对IF Stage进行正向控制的时候),读取了exe_br_flg和exe_jmp_flg以及if_inst等变量,这些读取的变量位于EXE和IF等不同的阶段,说明了Control Unit是直接获取了多级电路模块的反馈的。事实上,所有这些多级模块的变量,在整个Control Unit中(也就是Core.scala文件的Core模块中),都是全局可访问的,可以直接读取。当然理论上也可以直接写入,但5-Stage Pipeline的"范式"就是不要直接写入,是保持架构原则的"不要"而非"不能"!
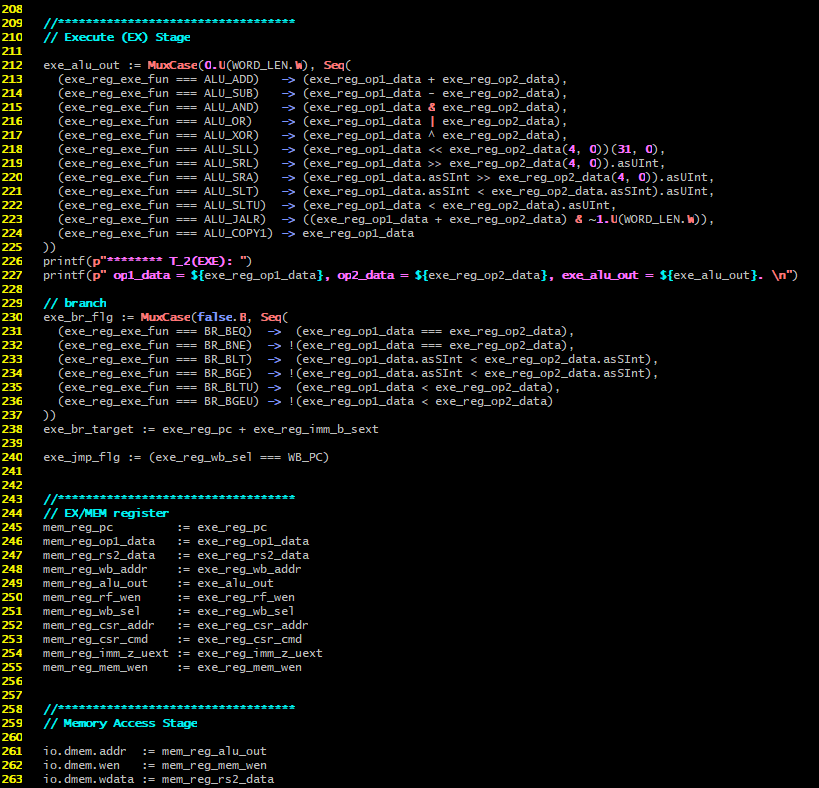
继续这一架构原则,看看Exe阶段的执行以及Mem阶段的执行,如下图所示。
Exe阶段,就是一个纯的组合逻辑电路,直接对exe_reg_exe_fun、exe_reg_op1_data等信号的变化进行响应、响应结果体现在exe_alu_out和exe_br_flag、exe_br_target、exe_jmp_flag中。前面的信号中的任何一个信号变化,都会导致响应结果的变化,这个响应是无条件的、立即的,不需要等待clock信号!只是在exe之前的阶段,由Inter-Stage Register(也就是ID/EXE Register),响应(等待)clock边缘信号到达时才会把exe_reg_exe_func、exe_reg_op1_data等通过赋值进行改变,进而【立即触发】Mem这个Stage上的组合逻辑电路的响应。
而Exe阶段的组合逻辑电路的响应,也仅仅只到达EX/MEM Register的左侧,不影响EX/MEM Register的右侧!EXE/Mem的右侧各值的变化,要等待clock边缘的到来!当clock边缘到来后,Ex/Mem Register右侧的mem_xxx值才会赋值上。注意注意注意:这里说的左侧右侧是对照此前的Pipeline示意图而说的因为示意图中的Pipeline都是从左边到右边(箭头方向)!下面代码中的245-255行里面的表达式的左侧对应示意图中的右侧,表达式的右侧则对应示意图的左侧!
至此,本文结合CPU的多级流水线的架构图、深入介绍了CPU的多级流水线的代码原理,并通过对比多级流水线处理器(5-Stage Pipeline Processor)和单周期处理器(Single Cycle Processor),理解它们在代码原理上的差异和原则。总结一下:
单周期处理器:控制单元全局直接控制整个芯片的众多端口。
多级流水线:每个流水线阶段的电路(组合逻辑电路)局部地响应Inter-Stage Register上的寄存器变量,而这些寄存器变量则是由Inter-Stage Register在Clock的驱动下从左到右传输。Inter-Stage Register不是一个哑的Register而是一个有左侧寄存器、右侧寄存器、寄存器传输控制的电路模块,这个电路模块的传输控制的输入信号可以来自多个阶段,而直接的输出信号则原则限定在单个Stage内。
PS:Inter-Stage Register的这种电路行为,十分匹配寄存器传输级Register Transfer Level的概念,对理解RTL的概念应该很有益处。
PS:Inter-Stage Register是本文使用的一个词,在业界似乎没有严格的定义,有叫pipeline register的,也有叫interface register的,但在芯片架构图中这个概念图却是高度一致的,都是从左到右的Stage之间过度的高宽比很大的长方形加一个以下边为边的三角形。这个图示非常好,只是业界并没有架构图的标准,因此本文把这个图示称作"Inter-Stage Register"并进行了解释(如上)。
PS:从分类学的角度,数字电路被分为组合逻辑电路和时序逻辑电路,这是一个"完备"的分类。高阶的思维方式下,(前人所做的)"完备"的分类可以帮助理解复杂事务如CPU。从目前为止的梳理(到5-Stage Pipeline CPU)来看,CPU的设计"套路"十分简单,就是:
1、一切都是组合逻辑电路、直到寄存器/锁存器打破组合逻辑电路的"直接响应"!
2、只有Inter-Stage Register实现了时序逻辑,这是通过寄存器传输实现的,理解RTL的概念。
3、注意寄存器和连接到寄存器上的导线/信号线/Wire/Signal的区分。Inter-Stage Register的左侧和右侧,连接的是导线/信号线。
4、Inter-Stage Register右侧的Register和这一侧的组合逻辑电路,可以看做是一体的(即同一个组合逻辑电路),因为这部分是以Register右侧的组合逻辑为主导,组合逻辑是"直接响应"的。
5、Inter-Stage Register左侧的Register 和 这一侧的组合逻辑电路,也可以看做一体的(即同一个组合逻辑电路),只不过这个是以Register左侧的组合逻辑为主导,什么时候写寄存器/锁存器,是由左侧电路决定的。但左侧电路却不决定左侧右侧Register之间的传输,而是确保在时钟边缘到达之前完成对寄存器/锁存器的写入。
6、Inter-Stage Register的左侧Register和右侧Register完全隔离并在控制电路的控制下进行寄存器之间的传输,是一个显著的分界线。单个寄存器/锁存器也可以通过"时序/时域"控制来实现时序电路(就像Single Cycle Processor所做的那样),但使用左侧Register和右侧Register的"空间域"划分的方式,更解耦更简单(当然也有代价就是寄存器资源消耗)!这大概是现有的数字电路"分类学"所没有谈到的----ChipCamp从代码和架构实践中总结出来的"设计模式"----寄存器复制&赋值。