原文笔记:
What:
在本文中,我们提出了一种受光流算法启发的CNN层,用于学习动作识别的运动表示,而无需计算光流。我们的表示流层是一个完全可微分的层,旨在捕获模型中任何表示通道的"流"。其迭代流量优化参数与其他模型参数一起学习,最大化动作识别表现。
Why:
借助光流的模型通过额外信息提高了模型效果,但也面临着其他问题:
1、光流本身的计算成本很高
2、使用光流的模型,参数量成倍上升,这会导致训练时间增加
3、使用光流进行训练本身就会造成训练时间增加
4、训练时难以做到端到端
5、即使在推理和过程中也需要计算每一帧的光流,并运行两个并行CNN,限制其实时应用。
Challenge:
最主要的挑战就是在保证使用光流的模型的效果的同时加快训练速度
How:
1、既然光流的计算成本很高,那就补计算光流改成计算特征流,这样仅需增加少量参数,就可以达到使用光流的效果,并且可以实现端到端的训练。
2、计算特征流时可能无法做到GPU的完全占用,会有效率瓶颈,作者采用卷积的方式来实现计算光流的方法从而来计算特征流,解决了该问题。
原文翻译:
Abstract
在本文中,我们提出了一种受光流算法启发的卷积层来学习运动表示。我们的表示流层是一个完全可微的层,旨在捕获卷积神经网络中任何特征通道的"流"以进行动作识别。它用于迭代流优化的参数以端到端的方式与其他 CNN 模型参数一起学习,最大化动作识别性能。此外,我们通过堆叠多个表示流层来新引入的学习"流流(flow of flow)"表示的概念。我们进行了广泛的实验评估,证实了它在计算速度和性能方面优于传统的光流的识别模型的优势。该代码是公开的。1
1. Introduction
活动识别是计算机视觉中的一个重要问题,具有许多社会应用,包括监控,机器人感知,智能环境/城市等。使用视频卷积神经网络(cnn)已经成为这项任务的标准方法,因为它们可以为问题学习更优的表示。双流网络20,采用RGB帧和光流作为输入,提供了最先进的结果,并且非常受欢迎。使用XYT卷积的三维时空CNN模型,如I3D3,也发现这种双流设计(RGB +光流)提高了模型的精度。同时提取外观信息和明确的运动流有利于识别。
然而,光流的计算成本很高。它通常需要每帧数百个优化迭代,并导致学习两个独立的 CNN 流(即 RGBstream 和 flow-stream)。这需要大量的计算成本和要学习的模型参数数量大幅增加。此外,这意味着模型即使在推理和过程中也需要计算每一帧的光流,并运行两个并行CNN,限制其实时应用。
以前的工作是在不使用光流作为输入的情况下学习捕获运动信息的表示,例如运动特征网络15和ActionFlowNet16。然而,尽管它们在模型参数和计算速度方面更有利,但与Kinetics13和HMDB14等公共数据集上的双流模型相比,它们的性能较差。我们假设光流方法执行的迭代优化产生了其他方法无法捕获的重要特征。
在本文中,我们提出了一种受光流算法启发的CNN层,用于学习动作识别的运动表示,而无需计算光流。我们的表示流层是一个完全可微分的层,旨在捕获模型中任何表示通道的"流"。其迭代流量优化参数与其他模型参数一起学习,最大化动作识别表现。这也可以在没有/训练多个网络流的情况下完成,从而减少模型中的参数数量。此外,我们通过堆叠多个表示流层来新提出学习"流的流"表示的概念。我们对光流计算的位置以及各种超参数、学习参数和融合技术进行了广泛的动作分类实验评估。
我们的贡献是引入了一种新的可区分的CNN层,该层展开了TV-L1光学流方法的迭代。这允许学习光流参数,应用于任何CNN特征图(例如中间表示),并在保持性能的同时降低计算成本。
2. Related Works
捕获运动和时间信息已被研究用于活动识别。早期,手工制作的方法,如密集轨迹24,通过跟踪时间点来捕获运动信息。许多计算光流的算法已经被开发出来,作为一种捕捉视频中运动的方法。其他的研究还探索了学习帧的顺序,以便在单个"动态图像"中总结视频,用于活动识别1。
卷积神经网络(cnn)已被应用于活动识别。最初的方法探索了基于池化或时间卷积的组合时间信息的方法12,17。其他作品探索了使用注意力来捕捉活动b18的子事件。双流网络已经非常流行:它们接受单个RGB帧(捕获外观信息)和一堆光流帧(捕获运动信息)的输入。通常,模型的两个网络流是分开训练的,最终的预测结果是平均的。还有其他双流CNN作品探索了不同的方式来"融合"或结合运动CNN和外观CNN7,6。还有大型3D XYT cnn学习时空模式26,3,这是由Kinetics13等大型视频数据集实现的。然而,这些方法仍然依赖于光流输入来最大化其精度。
虽然已知光流是一个重要的特征,但针对活动识别优化的流往往与真实光流19不同,这表明运动表示的端到端学习是有益的。最近,已经有一些工作使用卷积模型学习这种运动表示。Fan等人5利用深度学习库实现了TV-L1方法,提高了计算速度,并允许学习一些参数。结果被馈送到双流 CNN 进行识别。一些工作探索了学习CNN来预测光流,也可用于动作识别4,9,11,16,21。Lee等人15将特征从顺序帧转移到以非迭代的方式捕捉运动。Sun等人21通过计算表示和时间差异的梯度,提出了一种光流引导特征(OFF),但缺乏精确流量计算所需的迭代优化。此外,它需要采用 RGB、光流和RGB差异,以实现最先进的性能。
与之前的工作不同,我们提出的具有表示流层的模型仅依赖于 RGB 输入,学习参数要少得多,同时通过迭代优化正确表示运动。它比需要光流输入的视频 CNN 快得多,同时仍然保持与双流模型一样好甚至更好的性能。它在速度和准确性方面明显优于现有的运动表示方法,包括TVNet5和OFF21,我们通过实验证实了这一点。
3. Approach
我们的方法是一个受光流算法启发的完全可微卷积层。与传统的光流方法不同,我们的方法的所有参数都可以端到端学习,最大化动作识别性能。此外,我们的模型旨在计算任何表示通道的"流",而不是将其输入限制为传统的 RGB 帧。
3.1. Review of Optical Flow Methods
在描述我们的层之前,我们简要回顾了如何计算光流。光流方法是基于亮度一致性假设。也就是说,给定序列图像I1、I2、I1中的点x、y位于I2中的x+∆x、y+∆y,或者I1(x,y)=I2(x+∆x,y+∆y)。这些方法假设帧之间的运动很小,因此可以用泰勒级数近似:I2 = I1 + δI/δx∆x+ δI/δy∆y,其中u = ∆x,∆y。这些方程求解 u 以获得流,但由于两个未知数,只能近似。
近似光流的标准变分方法(如Brox2和TV-L127方法)以序列图像I1、I2为输入。变分光流方法使用迭代优化方法估计光流场u。张量 u ∈ R2×W ×H 是图像中每个位置的 x 和 y 方向的光流。以两个顺序图像作为输入I1, I2,该方法首先计算x和y方向上的梯度:∇I2。初始流量设置为0,u = 0。然后,可以计算基于当前流量估计u捕获两帧之间的运动残差的ρ。为了提高效率,预先计算 ρ的常数部分ρc:
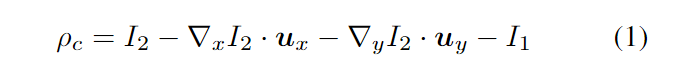
在之后进行迭代优化部分,每次更新u。
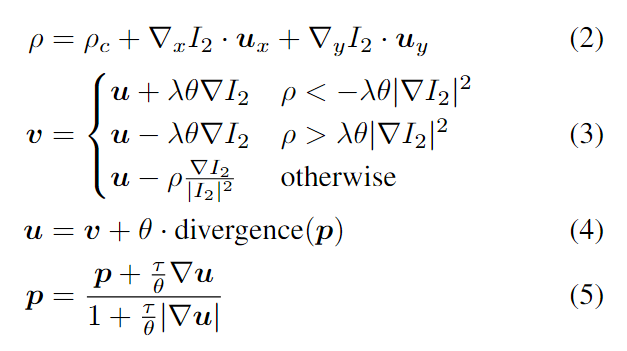
其中θ控制TV-L1正则化项的权值,λ控制输出的平滑度,τ控制时间步长。这些超参数是手动设置的。P是对偶向量场,用来使能量最小化。p的散度或后向差分计算为:
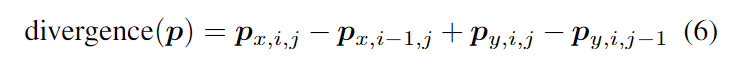
其中px为x方向,py为y方向,p包含图像中所有的空间位置。目标是最小化总变分能量:
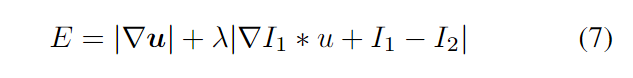
方法对从小到大的多个输入尺度进行迭代优化,并在更大的尺度上使用先前的流量估计u来扭曲I2,从而提供从粗到精的光流估计。这些标准方法需要多次缩放和翘曲才能获得良好的流量估计,需要数千次迭代。
3.2. Representation Flow Layer
受光流算法的启发,我们通过扩展上面概述的一般算法设计了一个完全可微的、可学习的卷积表示流层。主要区别在于 (i) 我们允许层捕获任何 CNN 特征图的流,并且 (ii) 我们学习了其参数,包括 θ、λ 和 τ 以及散度权重。我们还进行了一些关键更改以减少计算时间:(1)我们只使用单尺度,(2)我们不执行任何扭曲,以及(3)我们计算空间大小较小的 CNN 张量上的流。多尺度和翘曲的计算成本很高,每个尺度都需要多次迭代。通过学习流参数,我们可以消除对这些额外步骤的需求。我们的方法应用于低分辨率 CNN 特征图,而不是 RGB 输入,并以端到端的方式进行训练。这不仅有利于其速度,而且还允许模型学习针对活动识别优化的运动表示。
我们注意到亮度一致性假设同样可以应用于 CNN 特征图。我们不是捕获像素亮度,而是捕获特征值一致性。基于 CNN 的相同的假设被设计为空间不变的;即,它们在移动时为同一对象产生大致相同的特征值。
给定输入 F1、F2,来自顺序 CNN 特征图(或输入图像)的单个通道,我们通过将输入特征图与 Sobel 滤波器进行卷积来计算特征图梯度:
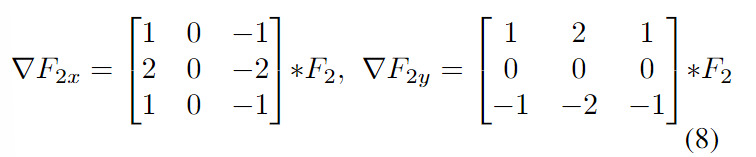
我们先设u = 0, p = 0,每个都有与输入相匹配的宽度和高度,然后我们可以计算出ρc = F2−F1。接下来,根据算法1,我们重复应用公式2-5中的操作进行固定次数的迭代,以实现迭代优化。为了计算散度,我们在第一列(x方向)或第一行(y方向)上用零填充p,然后将其与权重wx, wy进行卷积,以计算公式6:
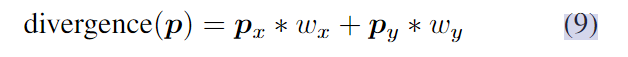
其中初始wx =−1 1,wy =−1 1^T。注意,这些参数也是可微的,可以通过反向传播来学习。我们计算∇u as
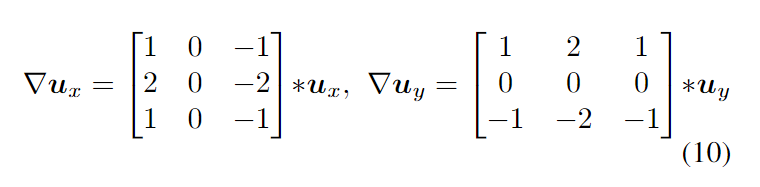
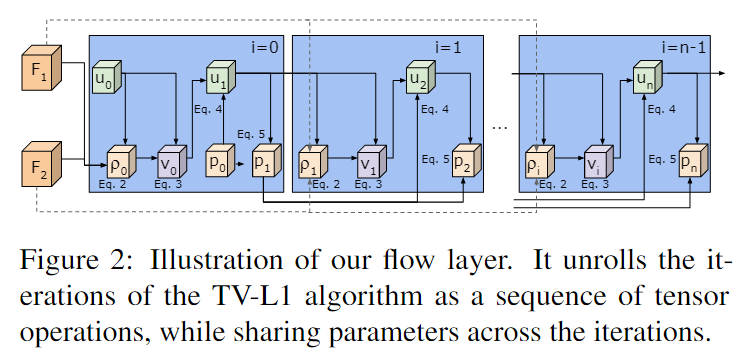
Representation Flow within a CNN 算法 1 和图 2 描述了我们的表示流层的过程。我们的多次迭代流层也可以解释为具有一系列卷积层共享参数(即图 2 中的每个蓝色框),每一层都的行为取决于其前一层的行为。由于这种公式,该层变得完全可微,并允许学习所有参数,包括 (τ, λ, θ) 和散度权重 (wx, wy )。这使得我们学习的表示流层能够针对其任务(即动作识别)进行优化。
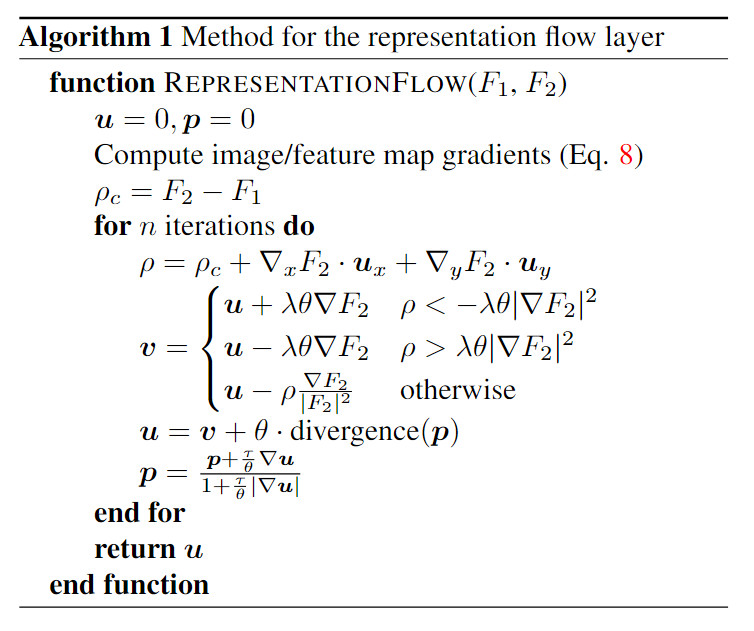
Computing Flow-of-Flow 标准光流算法计算两个序列图像的流。光流图像包含有关运动方向和大小的信息。直接在两个流图像上应用流算法意味着我们正在跟踪像素/位置,显示两个连续帧中的相似运动。在实践中,由于光流结果不一致和非刚性运动,这通常会导致性能下降。另一方面,我们的表示流层是从数据中"学习的",并且能够通过在流层之间具有多个规则的卷积层来抑制这种不一致和更好的抽象/表示运动。图 6 说明了这种设计,我们在实验部分确认了它的好处。通过堆叠多个表示流层,我们的模型能够捕获更长的时间间隔并考虑具有运动一致性的位置。
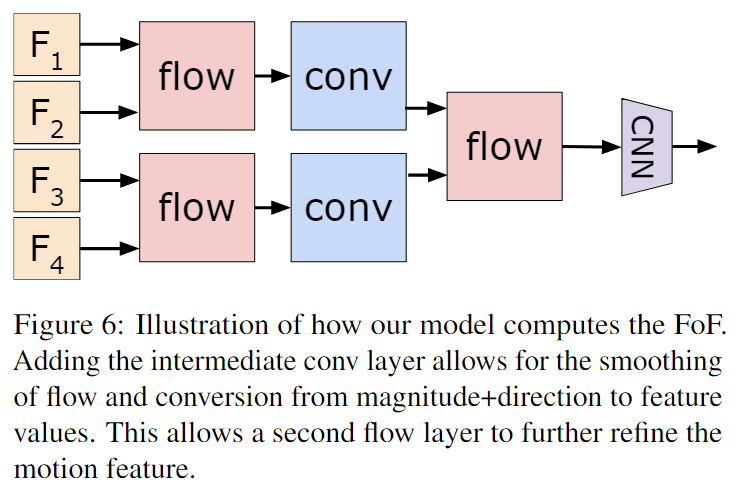
CNN特征图可能有数百或数千个通道,我们的表示流层计算每个通道的流,这可能需要大量的时间和内存。为了解决这个问题,我们应用卷积层在流层之前将通道数从 C 减少到 C'(请注意,C' 仍然比传统的光流算法显着,因为传统的光流算法仅适用于单通道、灰度图像)。对于数值稳定性,我们将此特征图归一化为 0, 255,匹配标准图像值。我们发现 CNN 特征平均相当小(< 0.5),TVL-1 算法默认超参数是为 0, 255 中的标准图像值设计的,因此我们发现这个归一化步骤很重要。使用归一化特征,我们计算流并堆叠 x 和 y 流,从而产生 2C' 通道。最后,我们应用另一个卷积层从 2C' 通道转换为 C 通道。结果被传递到剩余的 CNN 层进行预测。我们从许多帧平均预测来对每个视频进行分类,如图 3 所示。
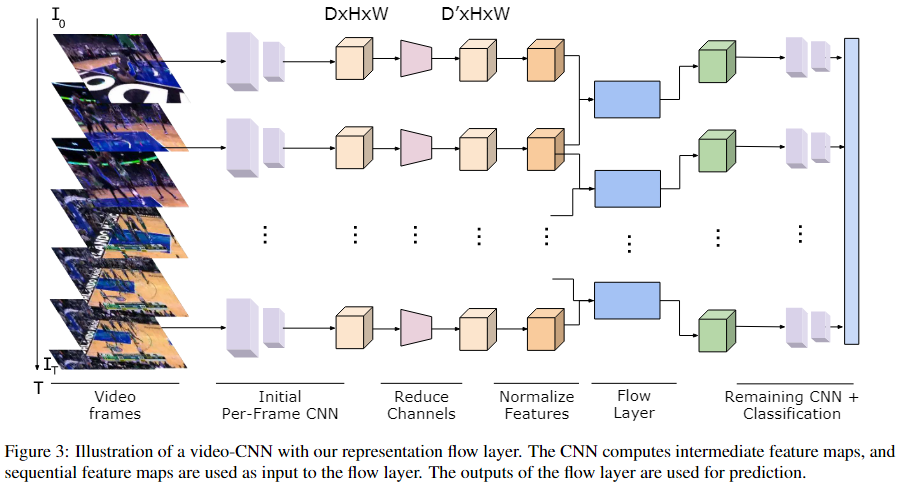
3.3. Activity Recognition Model
我们将表示流层放置在标准活动识别模型中,该模型将 T × C × W × H 张量作为 CNN 的输入。在这里,C 是 3,因为我们的模型使用直接 RGB 帧作为输入。T 是模型过程的帧数,W 和 H 是空间维度。CNN 输出每个时间步的预测,这些被时间平均以产生每个类的概率。该模型经过训练以最小化交叉熵:
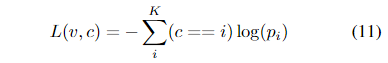
其中 p = M (v), v 是视频,函数 M 是分类 CNN,c 表示 v 属于K class中的哪个。也就是说,我们的流层中的参数与其他层一起训练,使其最大化最终的分类精度。
4. Experiments
Implementation details 我们在 PyTorch 中实现我们的表示流层,我们的代码和模型可用。由于在视频上训练 CNN 的计算成本很高,我们使用了 Kinetics 数据集 13 的一个子集,其中包含来自 150 个类别的 100k 视频:Tiny-Kinetics。这允许更快地测试许多模型,同时仍然有足够的数据来训练大型 CNN。对于大多数实验,我们使用大小为 16 × 112 × 112 的 ResNet-34 10(即 16 帧,空间大小为 112)。为了进一步减少许多研究的计算时间,我们使用了这个较小的输入,这降低了性能,但允许我们使用更大的批量大小并更快地运行许多实验。我们的最终模型在标准的 224 × 224 图像上进行了训练。检查特定训练细节的附录。
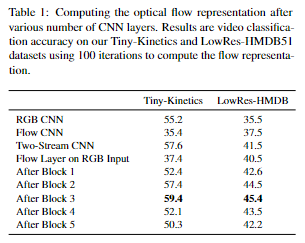
Where to compute flow? 为了确定网络中在哪里计算流,我们对比了 在原始RGB输入、在第一个卷积层后、在每五个残差块之后 上应用我们的流层。结果如表1所示。我们发现,计算输入上的流提供了较差的性能,类似于仅流网络的性能,但即使在1层之后也有很大的跳跃(表现变好),这表明计算特征的流动是有益的,同时捕获外观和运动信息。然而,在 4 层之后,随着空间信息过于抽象/压缩(由于池化和大空间感受野大小),性能开始下降,顺序特征变得非常相似,包含较少的运动信息。请注意,与最先进的方法相比,我们该表中的 HMDB 性能非常低,因为使用很少的帧和低空间分辨率(112 × 112)从头开始训练。对于以下实验,除非另有说明,否则我们在第三个残差块之后应用流层。在图 7 中,我们可视化了在块 3 之后计算的学习到的运动表示。

What to learn? 由于我们的方法是完全可微的,我们可以学习任何参数,例如用于计算图像梯度的核,用于散度计算的核,甚至τ, λ, θ。在表2中,我们比较了学习不同参数的效果。我们发现学习Sobel核值由于噪声梯度降低了性能,特别是当批大小有限时,但学习散度和τ, λ, θ是有益的。
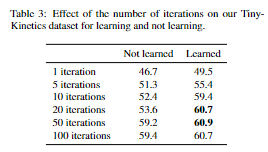
How many iterations for flow? 为了确认迭代是重要的,并确定我们需要多少次迭代,我们试验了不同数量的迭代。我们比较了学习(发散+τ, λ, θ)和不学习参数所需的迭代次数。流在3个剩余块之后进行计算。结果如表3所示。我们发现学习用更少的迭代提供了更好的性能(类似于5中的发现),迭代计算特征是很重要的。我们在剩下的实验中使用10或20次迭代,因为它们提供了良好的性能和速度。
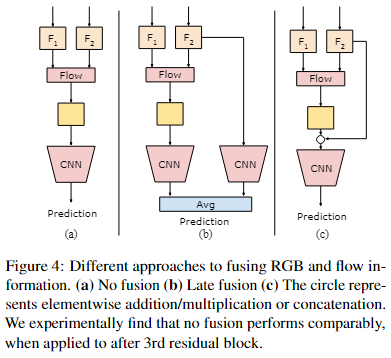
Two-stream fusion? 融合 RGB 和光流特征的双流 CNN 已被广泛研究 20, 7。基于这些工作,我们比较了融合RGB和我们的流表示的各种方法,如图4所示。我们比较了无融合、晚期融合(即单独的RGB和流CNN)和加法/乘法/级联融合。在表 4 中,我们比较了网络中不同位置的不同融合方法。我们发现融合 RGB 信息非常重要"当直接从 RGB 输入计算流时"。然而,当 CNN 已经抽象出了很多外观信息时,计算表示流并不那样有益。我们发现 RGB 和流特征的串联与其他特征相比表现不佳。我们不会在任何其他实验中使用双流融合,因为我们发现即使没有任何融合,在第 3 个残差块之后计算表示流也能提供足够的性能。
Flow-of-flow 我们可以多次堆叠我们的层,计算流的流 (FoF)。这的优点是将更多的时间信息组合成一个特征。结果如表5所示。应用TV-L1算法性能相对较差,因为光流特征并没有真正满足亮度一致性假设,因为它们捕获了运动的大小和方向(如图5所示)。应用我们的表示流层两次的性能明显优于 TV-L1 两次,但仍然比我们没有这样做的基线差。然而,我们可以在第一和第二流层之间添加一个卷积层,流卷积流(FcF),(图6),允许模型更好地学习长期流表示。我们发现这表现最好,因为这个中间层能够平滑流并为表示流层产生更好的输入。然而,我们发现添加第三个流层会降低性能,因为运动表示变得不可靠,因为空间感受野大小很大。在图7中,我们可视化了学习到的流流,这是一个更平滑的、类似加速度的特征,具有抽象运动模式。
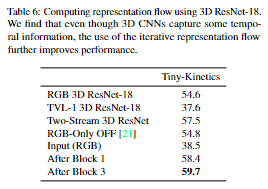
Flow of 3D CNN Feature 由于 3D 卷积捕获了一些时间信息,因此我们测试了从 3D CNN 特征计算的流表示。由于 3D CNN 的训练成本很高,我们遵循 I3D 3 的方法,将 ImageNet 上预训练的 ResNet-18 膨胀为视频 3D CNN。我们还与26中的空间 conv接着时间conv 的 (2+1)D 方法进行了比较。它产生了结合空间和时间信息的类似特征。我们发现即使 3D 和 (2+1)D CNN 已经捕获了一些时间信息,我们的流层也提高了性能:表 6 和表 7。这些实验使用了 10 次迭代并学习流参数。在这些实验中,没有使用 FcF。
我们还与使用 (2+1)D 和 3D CNN 的 OFF 21 进行了比较。我们观察到,使用捕获时间信息的 CNN,这种方法不会产生有意义的性能提升,而我们的方法确实如此。

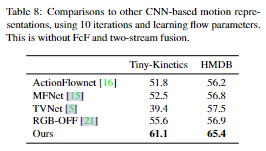
Comparison to other motion representations 与现有的基于 CNN 的运动表示方法进行比较,以确认我们的表示流的有用性。对于这些实验,当可用时,我们使用了作者提供的代码,否则我们自己实现了这些方法。为了更好地与现有工作进行比较,我们使用了 (16×)224 × 224 图像。表 8 显示了结果。MFNet 15 通过空间移动 CNN 特征图来捕获运动,然后对结果求和,TVNet 5 将卷积光流方法应用于 RGB 输入,ActionFlowNet 16 训练 CNN 联合预测光流和活动类。我们还仅使用 RGB 输入与 OFF 21 进行比较。请注意,21 中的 HMDB 性能是使用他们的三流模型(即 RGB + RGB-diff + 光流输入)报告的,这里我们仅使用 RGB 与版本进行比较。我们的方法在 CNN 特征图上应用迭代流计算的方法表现最好。
Computation time 我们在运行时间和参数数量方面将我们的表示流与最先进的双流方法进行了比较。所有的计时都是使用单个Pascal Titan X GPU测量的,对于一批大小为32 × 224 × 224的视频。流/双流cnn包括运行TV-L1算法(OpenCV GPU版本)来计算光流的时间。所有 CNN 都基于 ResNet-34 架构。如表 9 所示,我们的方法明显快于依赖于 TV-L1 或其他光流方法的双流模型,同时表现相似或更好。我们的模型的参数数量是其双流竞争对手的一半(例如,在 2D CNN 的情况下,21M 与 42M)。
Comparison to state-of-the-arts 我们还将我们的动作识别精度与Kinetics和HMDB的最新技术进行了比较。为此,我们使用32 × 224 × 224输入和完整的动力学数据集,使用8个v100来训练我们的模型。我们使用2D ResNet-50作为架构。在实验的基础上,我们将我们的表示流层应用于第3个残差块之后,学习了超参数和散度核,并进行了20次迭代。我们还比较了我们的流-流模型。在22之后,使用参数随时间的运行平均值执行评估。我们的结果如表9所示,证实了这种方法明显优于仅使用RGB输入的现有模型,并且与昂贵的双流网络具有竞争力。我们的模型在不使用光流输入的模型中表现最好(即,在每个视频仅采用~ 600ms的模型中)。需要光流的模型要慢10倍以上,包括双流版本的3,25,26
5. Conclusion
我们引入了一个受光流算法启发的可学习表示流层。我们通过实验比较了各种形式的层,证实了迭代优化和可学习参数的重要性。在标准数据集上,我们的模型在速度和准确性方面明显优于现有方法。我们还引入了"流的流"的概念来计算长期运动表示,并展示了它对性能的好处。