一、 背景
某业务Clickhouse库月数据增长超过2.5T,云上Clickhouse容量并不是无限的,单节点有32T上限,而业务已使用一半以上,依此速度,半年内就将达到上限。
与业务讨论,大致有以下几种解决思路:
- 按时间清理数据,但因为业务特点,能清理的数据不多
- 改造为分片模式,但涉及业务改动量较大
- 利用阿里云Clickhouse自带的冷热数据分层存储功能,从文档来看,操作简单、业务改动量也最小,于是业务进行调研与测试
二、 冷热数据分层存储
1. 背景知识
-
热数据:访问频次较高的数据,存储在热数据盘(即创建集群时所选的ESSD云盘或高效云盘)中,满足高性能访问的需求
-
冷数据:访问频次较低的数据,存储在较低价的冷数据盘(OSS)中,满足高性价比的需求
2. 两种存储策略
- 默认存储策略(按空间):新写入的数据存储在热数据盘中,当热数据存储量达到业务指定阈值时,自动将当前热数据盘中占用空间最大的part数据文件移动到冷数据盘存储,从而释放热数据盘存储空间。
- TTL存储策略(按时间):在默认存储策略基础上,添加TTL语句,实现将间隔时间之前的所有数据自动转移到冷数据盘中。
三、 注意事项
容易踩到和已经踩到的一些坑
1. 版本问题
默认阿里云界面现在已经建不了20.8版本以下的Clickhouse,对于新实例问题不大。
- 云数据库ClickHouse集群为社区兼容版且版本为20.8及以上版本
- 云数据库ClickHouse企业版基于缓存及共享存储,自动进行冷热分层,不依赖冷热数据存储规则
2. 关闭备份
这个有点坑,使用冷热分层后就不支持备份恢复了。但好在ClickHouse一般是数仓和报表业务用,本身有源数据,即使误删还能从上游拉回来,业务评估风险可以接受。
3. 重启生效
开通该功能后集群会立即进行重启,需要提前预约变更窗口
4. 只开不关
冷热数据分层存储功能开通后,暂不支持关闭
5. meta节点inode使用率暴增
这个是文档中完全没有提及的部分,可以看到,在不到两个小时,inode使用率从接近0快速涨到100%,且meta节点无法在界面扩容,后联系阿里云紧急在后台为meta节点扩容才恢复。
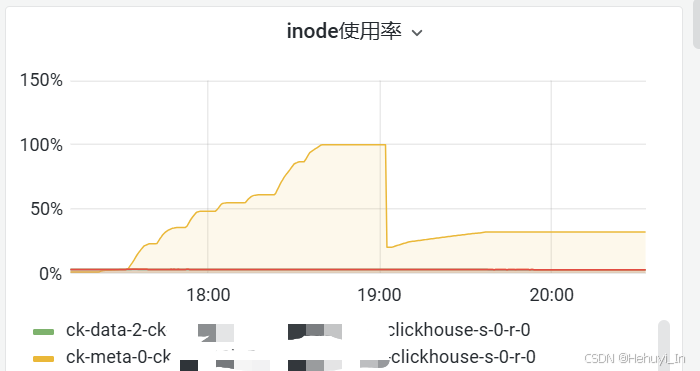
阿里云的解释是迁移到oss中的数据,每个part会映射到Clickhouse的meta节点上,占用一个inode。当表part数过多,而又没有设置合并,就可能触发这个问题。
对此的建议:
- 表分批迁移,优先迁移表大而part相对较少的,收益较大
- 设置prefer_not_to_merge参数为false,对冷数据中的part也进行合并(对性能有明显影响)
- 提前估算迁移part数与inode使用率,必要时联系阿里云提前扩meta节点
- 社区新版本对此功能有计划优化,但何时上线还不明确,且还需业务进行升级
四、 启用及设置
1. 功能启用
非常简单,点击开通即可
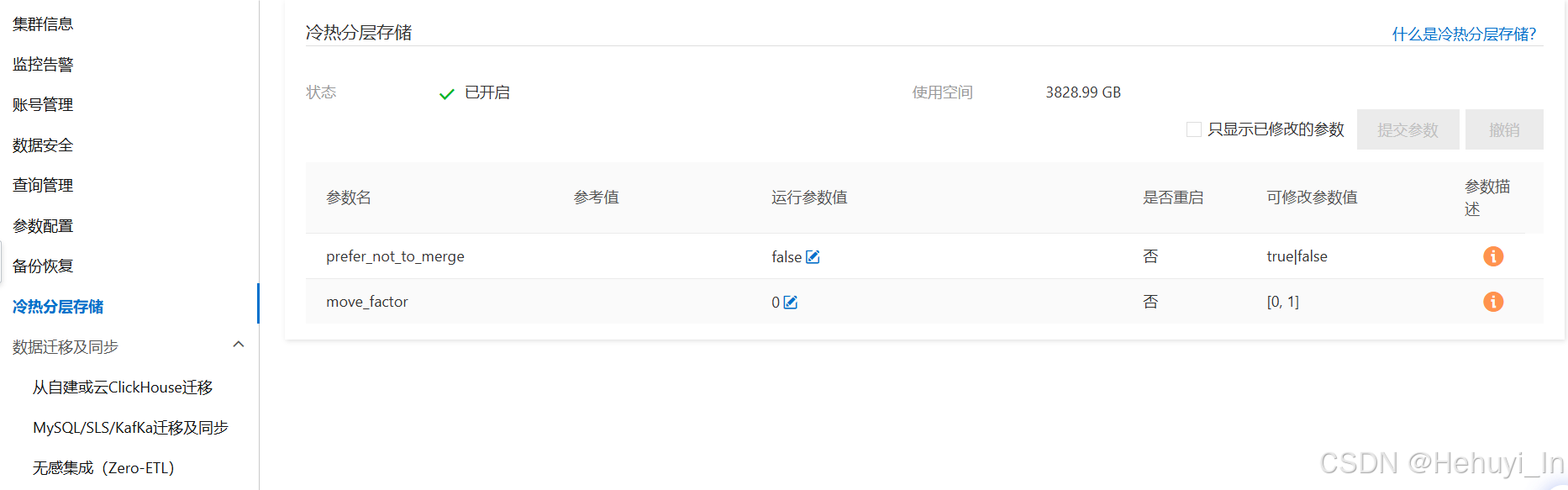
2. 默认存储策略设置
两个核心参数
|-------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 参数 | 说明 |
| move_factor | 当热数据盘中的可用存储空间所占比例小于该参数时,自动将当前热数据盘中占用空间最大的part数据文件移动到冷数据盘存储。 取值范围为[0,1]。取值为0时,代表关闭基于磁盘存储容量的冷热数据分层存储。默认值为0.1,代表可用存储空间所占比例小于10%时,将自动进行数据移动。 一般来说生产表业务逻辑不太会允许根据空间大小挪数据,建议设为0 |
| prefer_not_to_merge | 冷数据盘中的数据是否进行合并。 * true:不合并,默认值。对性能影响小,但part数可能非常多,出现前面的inode问题 * false:合并。part可以合并,占用inode较少,但合并时性能影响较大,遇到过打满CPU的情况。 |
3. TTL设置
- 创建时设置
sql
-- 以date列为依据,将90天之前的所有数据移动到冷数据盘。
CREATE TABLE ttl_test_tbl
(
`f1` String,
`f2` String,
`f3` Int64,
`f4` Float64,
`date` Date
)
ENGINE = MergeTree()
PARTITION BY date
ORDER BY f1
TTL date + INTERVAL 90 DAY TO DISK 'cold_disk'
SETTINGS storage_policy = 'hot_to_cold';- 创建后修改
sql
ALTER TABLE <table_name> ON CLUSTER default MODIFY TTL <time_column> + INTERVAL <number> TO DISK 'cold_disk';
存量数据:默认情况下,存量数据将按照新策略进行存储,但需要时间异步处理,如需立即生效,您需更改TTL分层存储策略之后 ,还要执行
ALTER TABLE materialize TTL;语句。如果您不期望更改存量数据的TTL分层存储策略,需要在更改TTL分层存储策略之前 ,执行SET materialize_ttl_after_modify=0;语句。增量数据:默认情况下,增量数据也将按照新策略进行存储。
更改TTL分层存储策略后,已经进入冷数据盘中的数据不会自动移动到热数据盘。
4. 移动冷热数据盘的数据
- 热 -> 冷
sql
ALTER TABLE <table_name> ON CLUSTER default MOVE PARTITION <partition> TO DISK 'cold_disk';- 冷 -> 热
sql
ALTER TABLE <table_name> ON CLUSTER default MOVE PARTITION <partition> TO DISK 'default';5. 查看数据
- 查看热数据盘上的数据
sql
SELECT * FROM system.parts WHERE database = '<db_name>' AND TABLE = '<tbl_name>' AND disk_name ='default' AND active = 1;- 查看冷数据盘上的数据
sql
SELECT * FROM system.parts WHERE database = '<db_name>' AND TABLE = '<tbl_name>' AND disk_name ='cold_disk' AND active = 1;- 查看磁盘空间
sql
SELECT * FROM system.disks;- 移动上下限值
sql
SELECT move_ttl_info.min,move_ttl_info.max FROM system.parts WHERE database = '<db_name>'AND table = '<tb_name>'AND disk_name = 'default'五、 大致效果
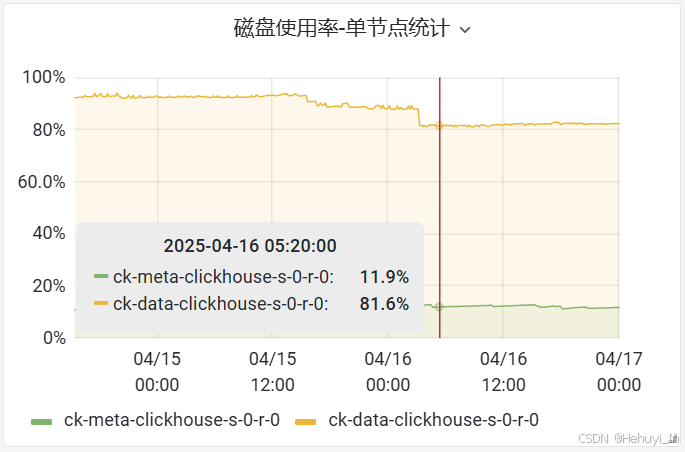
移动后可以看到冷数据空间逐渐增大
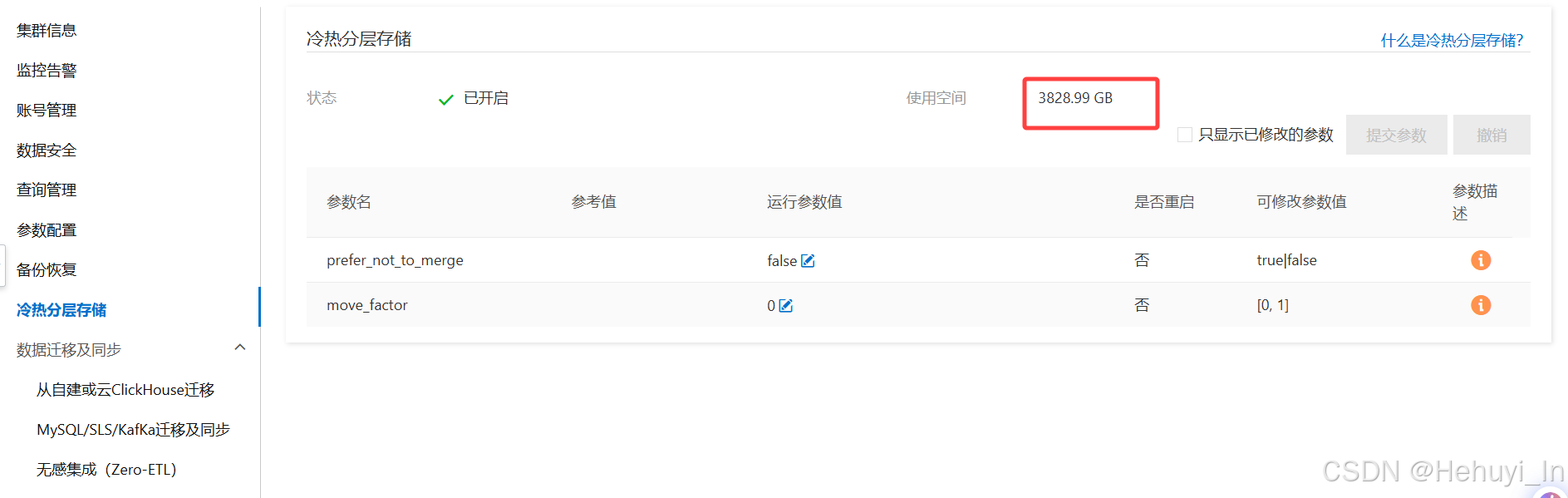
热数据存储使用率从93%左右降低至81%,大幅缓解空间压力
参考: