- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
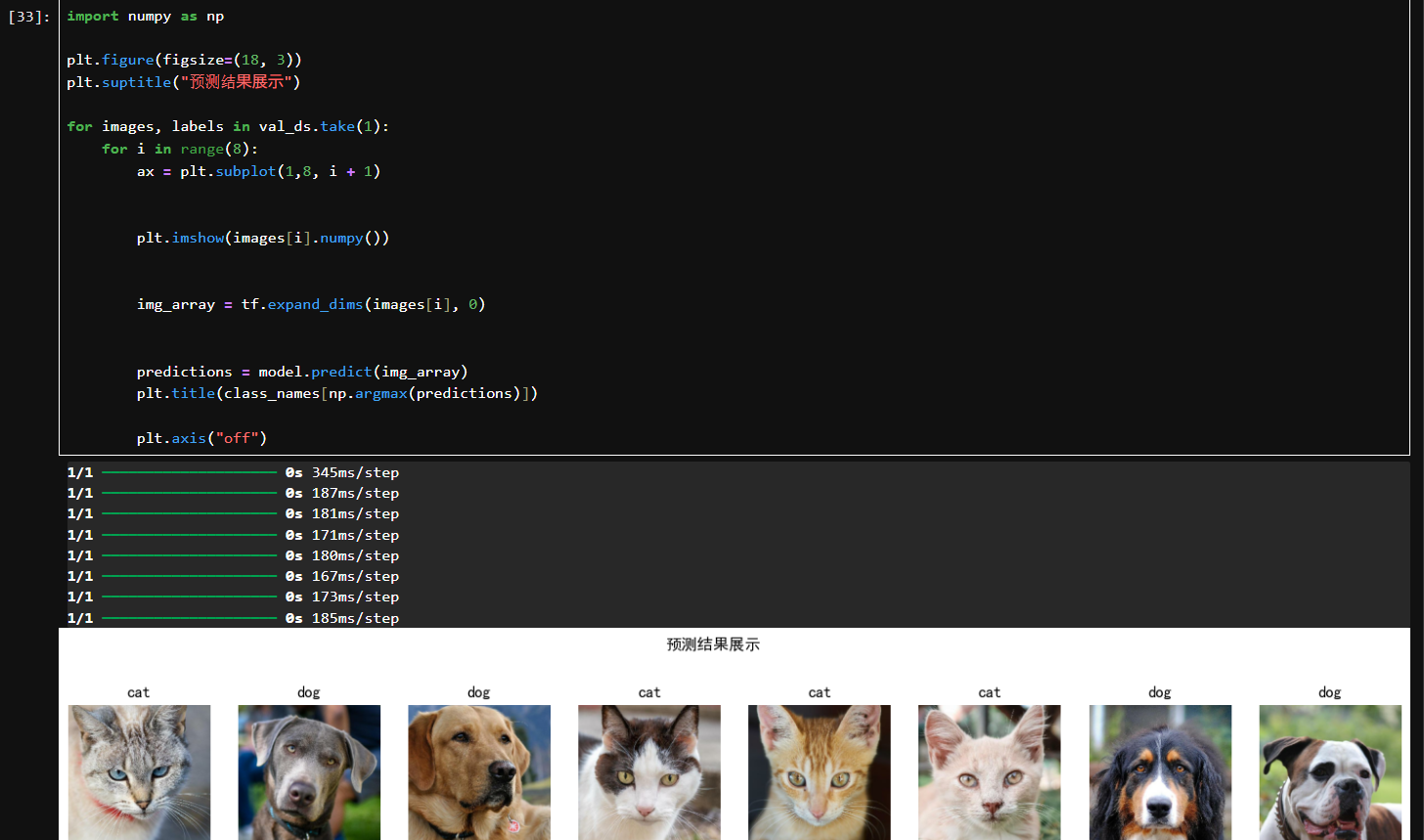
第T9周:猫狗识别2
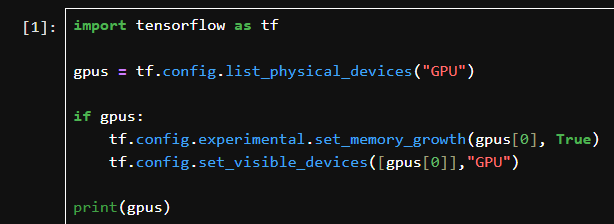
tf.config.list_physical_devices("GPU"),用于检测当前系统是否有可用的 GPU,并将结果存入 gpus 变量。如果系统检测到 GPU,代码会选择第一块 GPU(gpu0 = gpus0),然后调用tf.config.experimental.set_memory_growth(gpu0, True) 来启用 GPU。
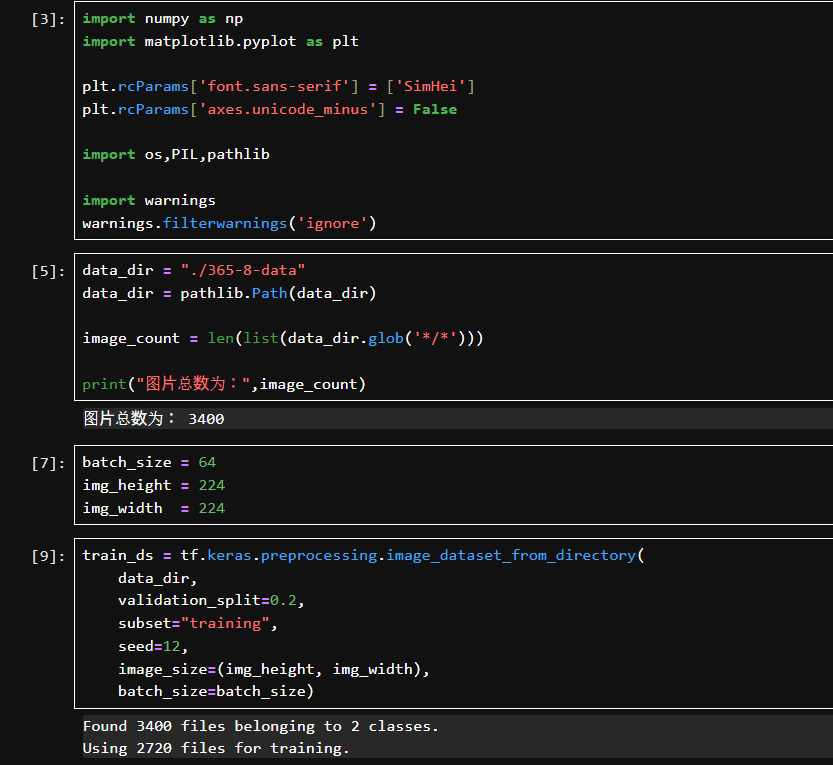
设定 batch_size=64,即每次训练时取 64 张图片进行计算。
设定图像大小 224x224,这样所有加载的图片都会被调整到该尺寸,以确保模型输入维度一致。
seed=12:固定随机种子,确保数据划分不会因多次运行而变化。image_size=(img_height, img_width):调整所有图片大小为 224x224。batch_size=batch_size:每批次加载 64 张图片。
数据集中共有3400 张图片,分别属于2个类别。其中,2720张作为训练集,680张作为验证集。
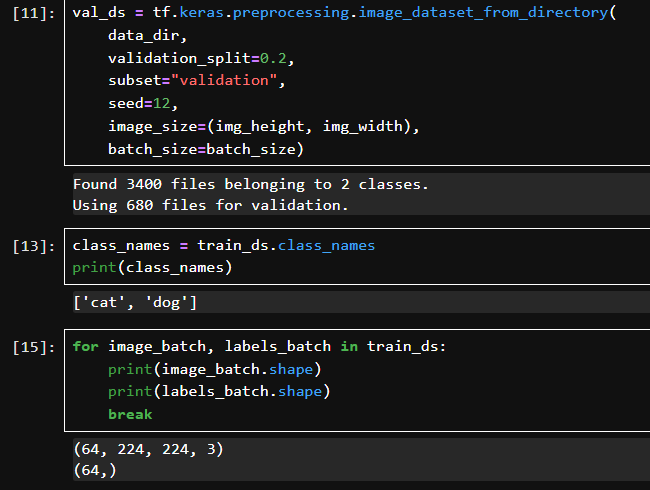
这个批次包含 64张图片(因为 batch_size=64),每张图片的尺寸是 224x224。 图片有 3 个通道。
Label_batch是形状(64,)的张量,这些标签对应64张图片
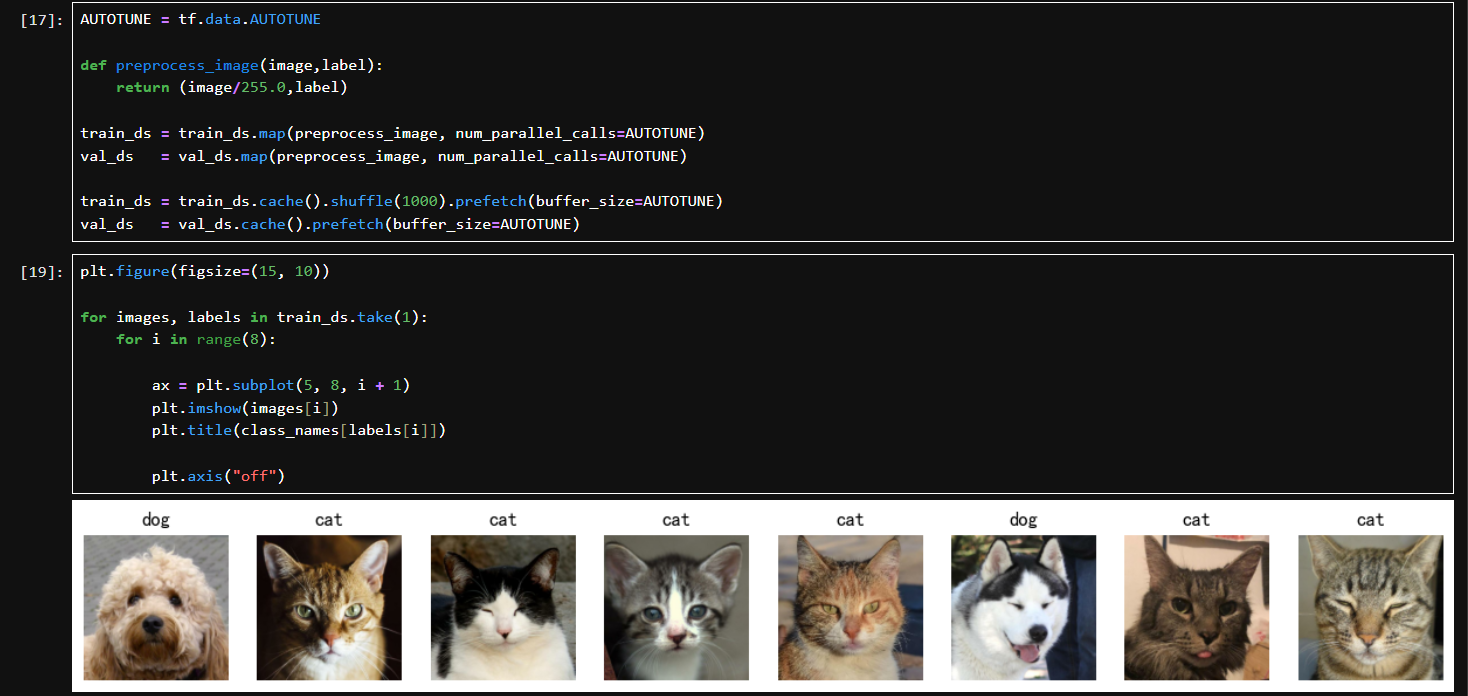
cache(),将数据缓存在内存中,提高训练速度
shuffle(1000):打乱训练数据,缓冲区大小是 1000
prefetch(buffer_size=AUTOTUNE):异步加载数据,加速训练过程(AUTOTUNE 会自动选择合适的预取大小)
layers.Rescaling(1./255):把像素值从 0, 255 缩放到 0.0, 1.0
从 val_ds 中取出一个 batch(默认是 (batch_size, height, width, 3))
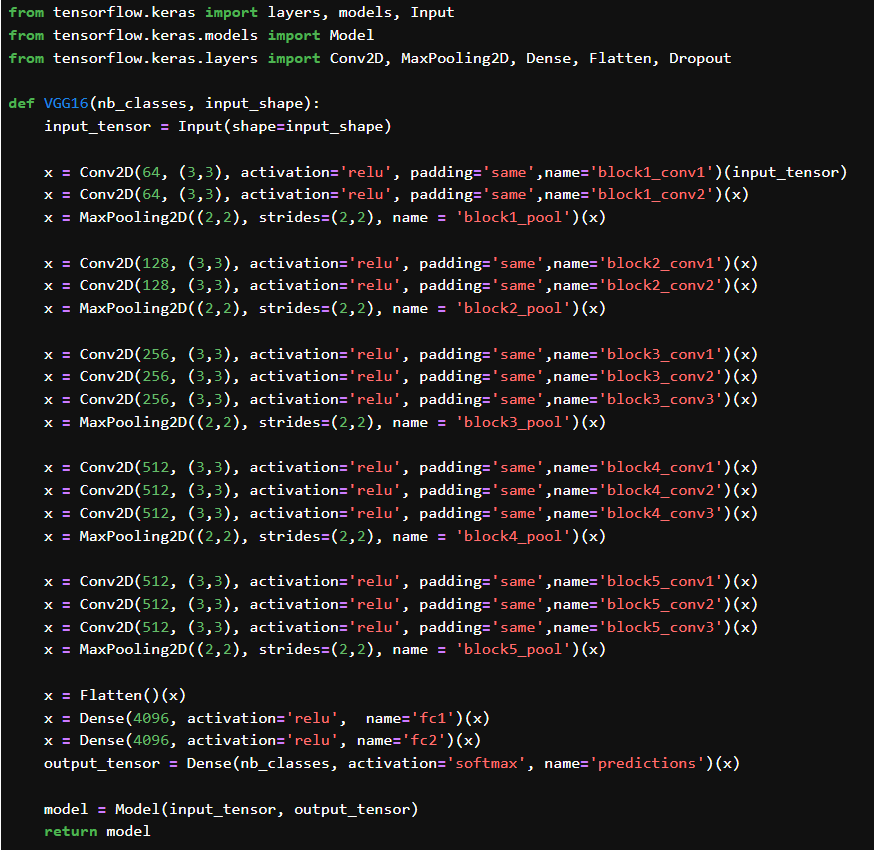
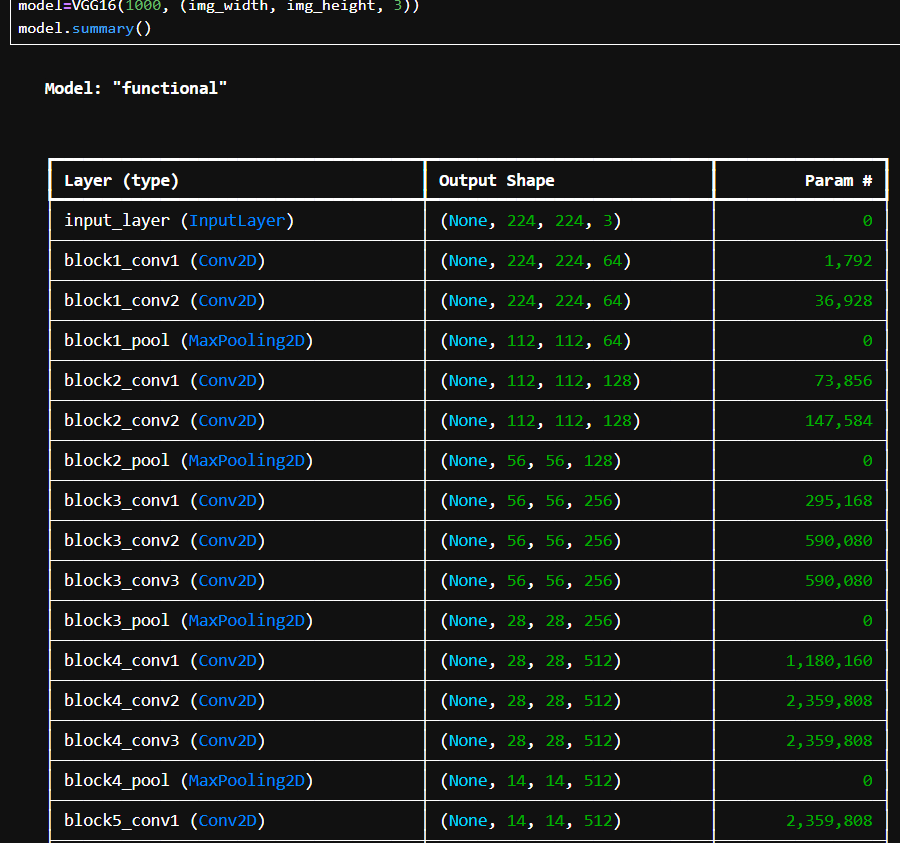
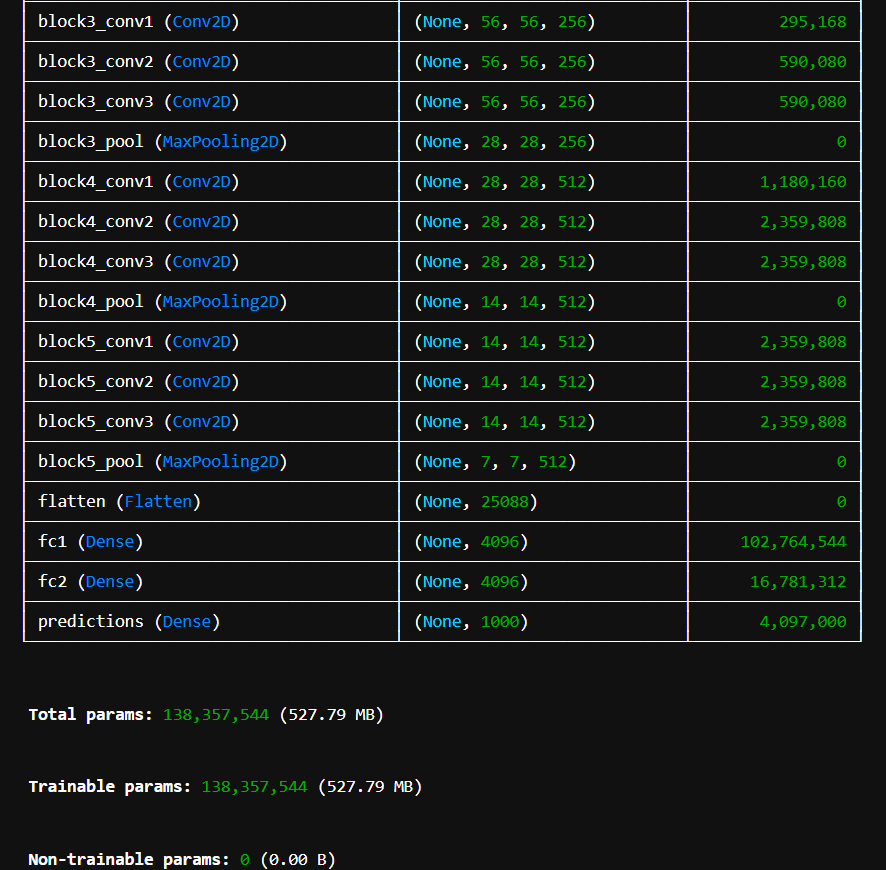
多分类任务的 VGG16 卷积神经网络,保留了 VGG16 的经典结构(13 个卷积层 + 3 个全连接层),输出为 nb_classes 类的 softmax 结果。
输入图像的 shape 是 (img_width, img_height, 3),支持 RGB 彩图。
每个 block 都由若干个 3x3 卷积层(带 ReLU 激活),一个 2x2 最大池化层
每个卷积层都使用 'same' padding 保证输出尺寸一致,池化后尺寸减半。
Flatten(),把多维 feature map 展平成一维向量。
两个 Dense(4096) 层,经典的全连接层(重参数)。
Dense(nb_classes, activation='softmax'),输出最终的分类概率。
img_width, img_height 是图像的宽和高(为 224x224 默认的 VGG 输入尺寸)。
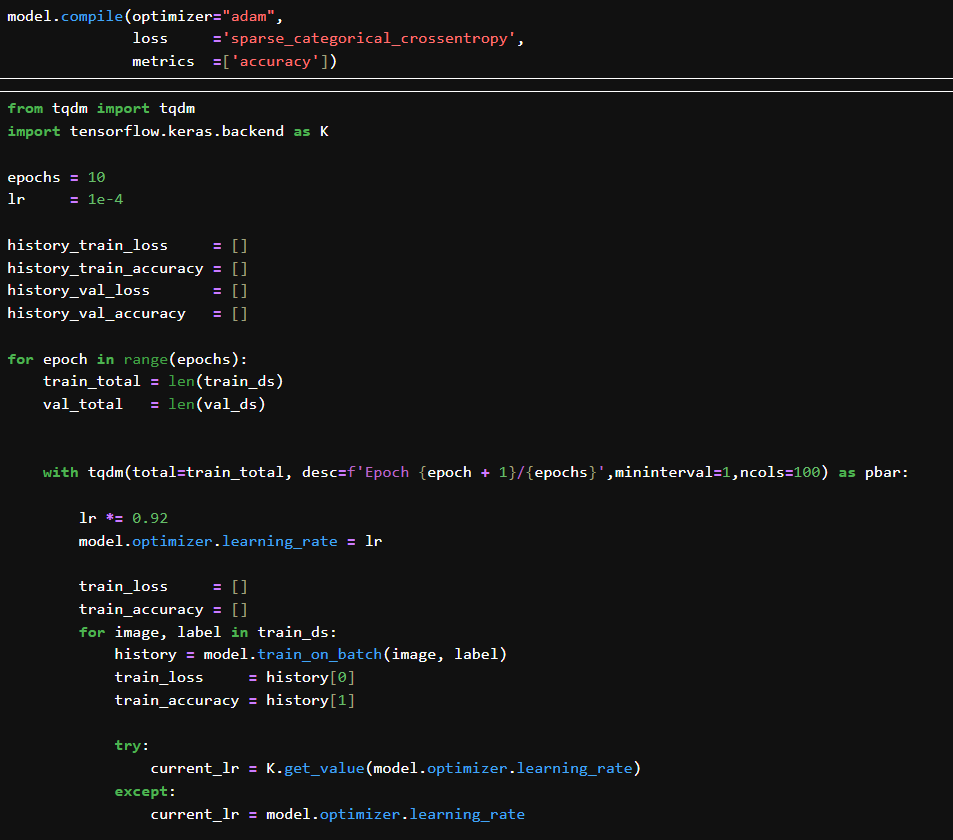
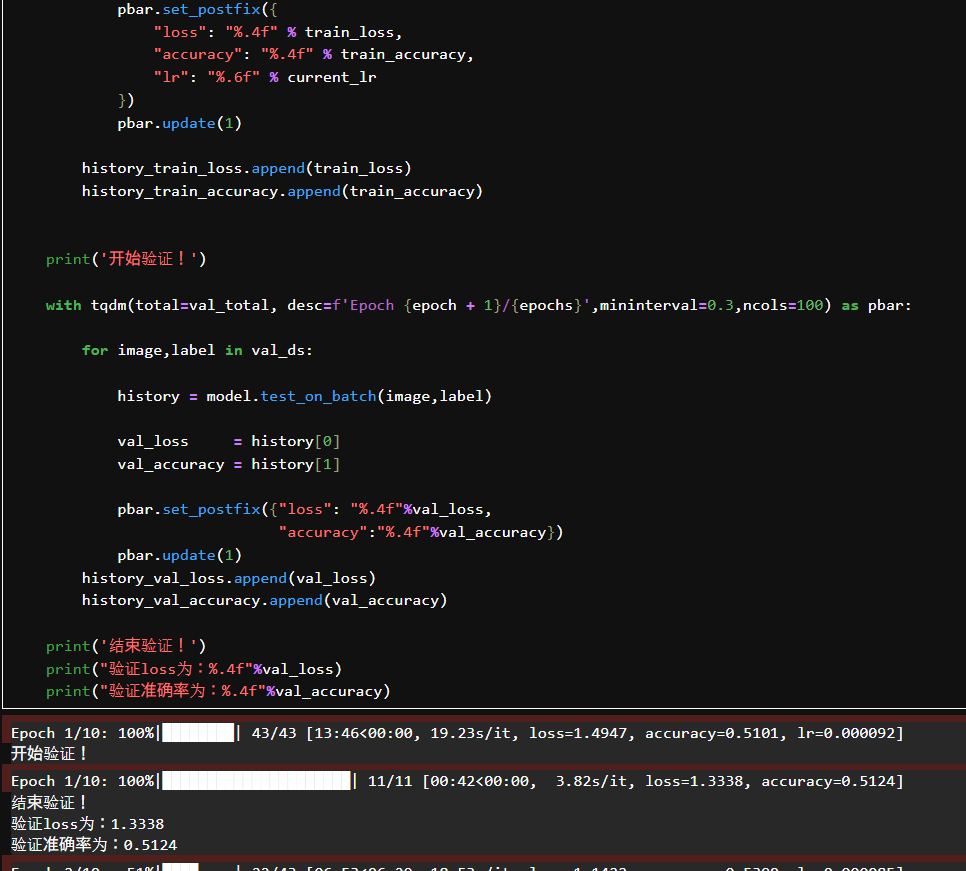
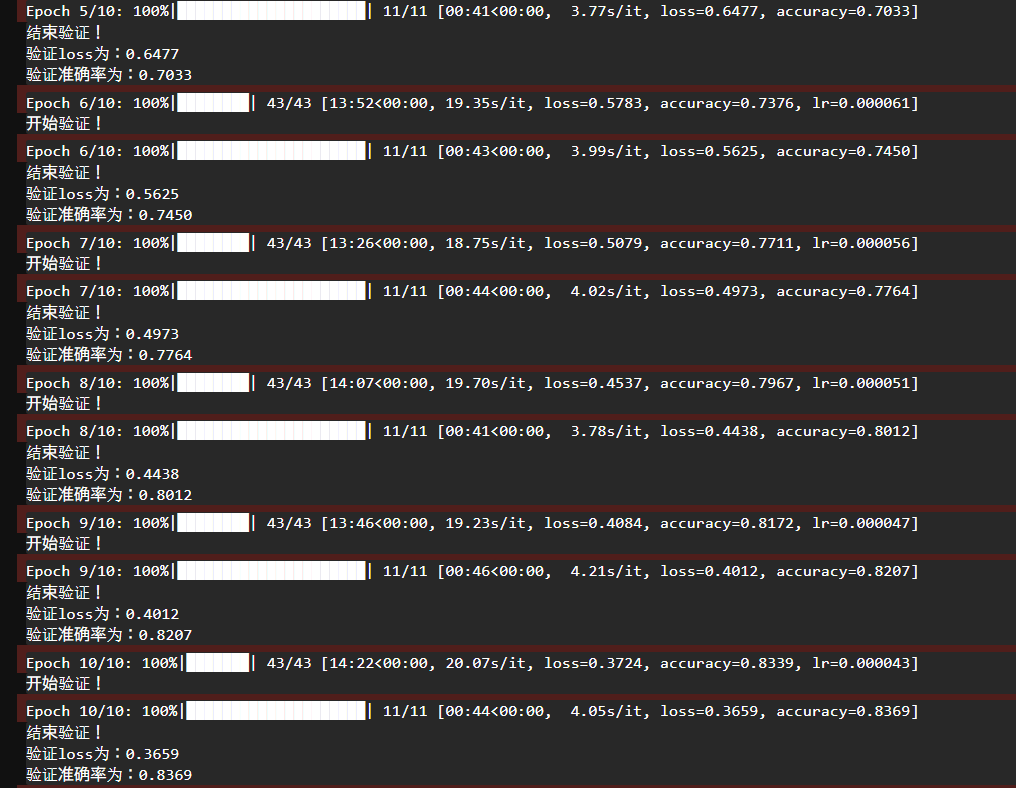
tqdm 是一个进度条库,显示每轮训练/验证的进度。
总共训练10 个 epochs,初始学习率设置为 0.0001。
每轮将学习率乘以 0.92,手动设置给模型的优化器。
遍历 train_ds,对每一个 batch 使用 model.train_on_batch() 进行训练。把最后一个 batch 的 loss 和 accuracy 存进历史列表。保存最后一个 batch 的验证指标。
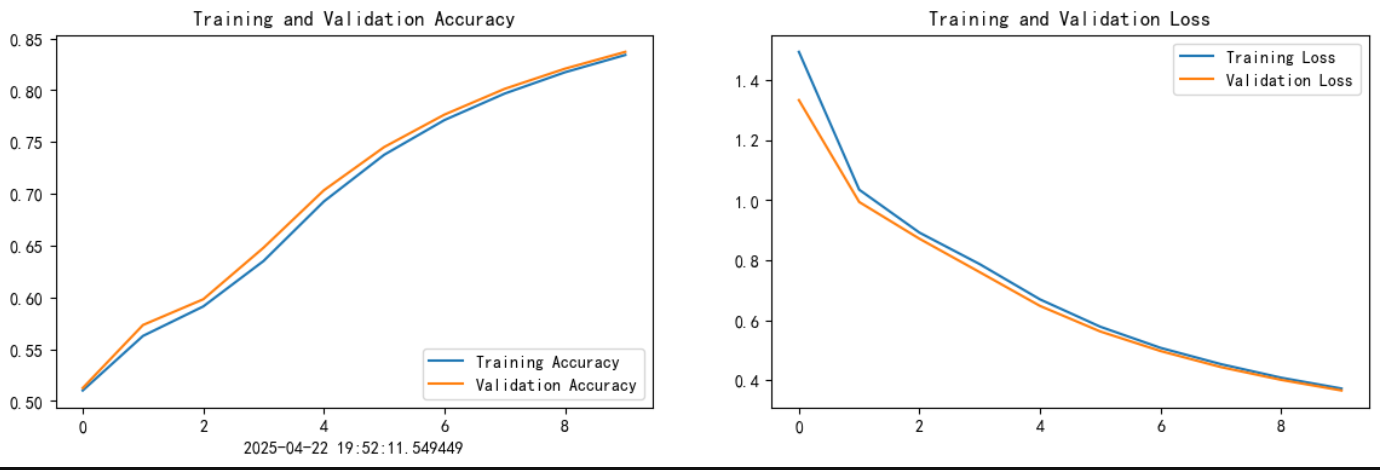
Training and Validation Accuracy
X轴:表示训练轮数(epochs),从0到9,10轮。
Y轴:表示准确率(accuracy),范围是从0.5到0.85。
蓝线(Training Accuracy):训练集上的准确率。
橙线(Validation Accuracy):验证集上的准确率。
准确率上升,从大约 0.51 提升到了 0.84。
训练集和验证集的准确率曲线接近,说明模型在训练过程中没有过拟合。验证准确率和训练准确率同步提升,模型的泛化能力较强。
Training and Validation Loss
X轴:同样是训练轮数。
Y轴:表示损失值(loss),从大约 1.5 降到 0.35 左右。
蓝线(Training Loss):训练集上的损失值。
橙线(Validation Loss):验证集上的损失值。
损失值持续下降,说明模型在逐步学习、拟合得越来越好。
训练和验证的损失曲线也几乎重合,验证损失略低于训练损失,数据未被过拟合,验证集代表性良好,模型有很好的泛化能力。
模型训练过程稳定,准确率上升,损失下降。验证集表现良好,未见过拟合或欠拟合。