MapReduce是一个分布式运算程序的编程框架,是用户开发"基于Hadoop的数据分析应用"的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序(例如:jar包),并发运行在一个Hadoop集群上。
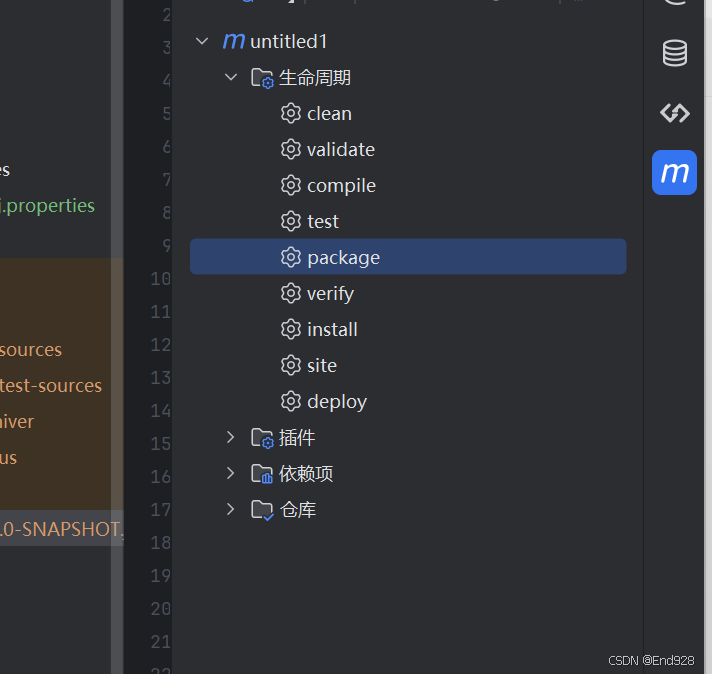
双击package,此时package可以自动打包并生成文件如下:
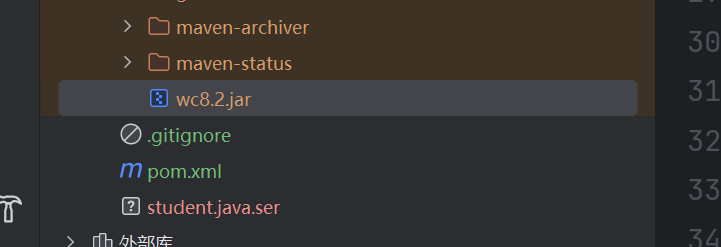
这个是我自己改过名的,可以自定义,可以右键打开资源管理器,找到打包的文件。
MapReduce是一个分布式运算程序的编程框架,是用户开发"基于Hadoop的数据分析应用"的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序(例如:jar包),并发运行在一个Hadoop集群上。
双击package,此时package可以自动打包并生成文件如下:
这个是我自己改过名的,可以自定义,可以右键打开资源管理器,找到打包的文件。