目录
[4. 滑动窗口](#4. 滑动窗口)
[情况一:数据报已经抵达,ACK 被丢了编辑](#情况一:数据报已经抵达,ACK 被丢了编辑)
[5. 流量控制](#5. 流量控制)
4. 滑动窗口
这个滑动窗口是 TCP 中非常有特点的机制。
我们知道,TCP 是通过确认应答,超时重传,连接管理 ==》 实现了可靠传输~
根据我们前面的介绍,为了实现可靠传输,也是付出了代价的,单位时间,能传输的数据量变少了(传输效率降低了!)
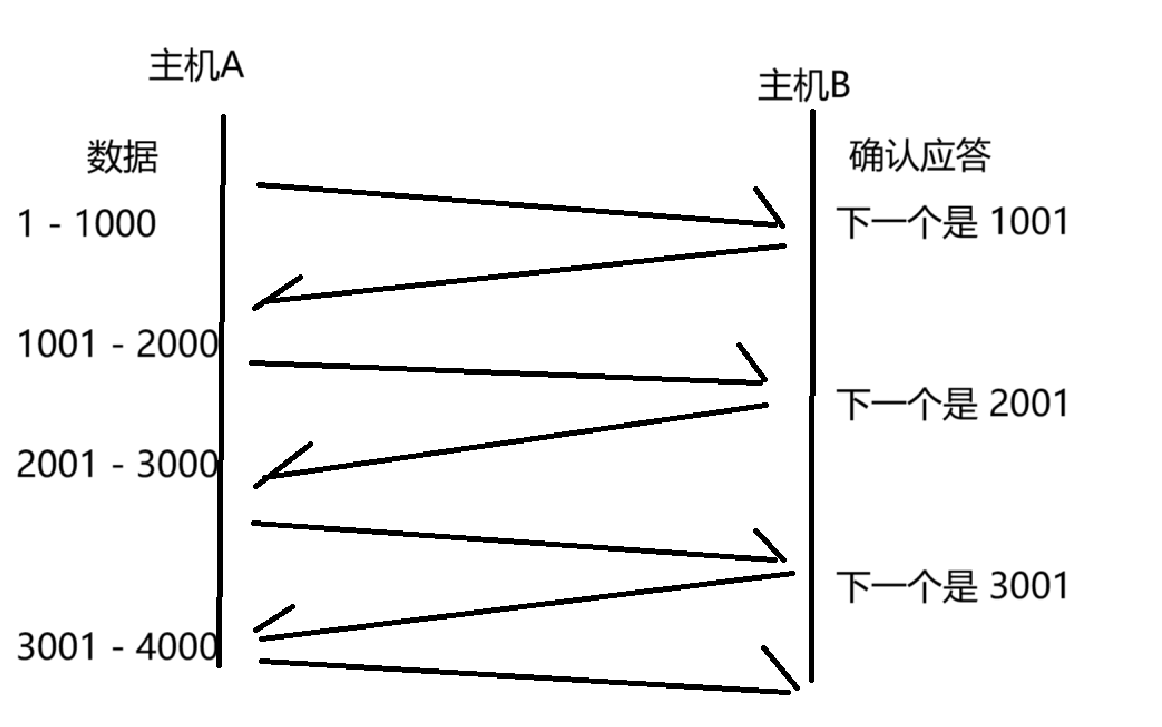
在确认应答机制之下,每次发送方收到一个 ack 才会发送下一个数据,导致会有大量的时间都消耗在等待 ack 上了,此处等待消耗的时间成本是非常多的~我们希望的是,在保证可靠传输的前提下,尽可能的让效率高一些,让消耗的时间成本少一些
滑动窗口这个机制,就是为了解决上述问题的。滑动窗口就可以在保证可靠传输的基础上,提高效率(这里的提高效率其实是降低了时间的损耗,而不是增加了传输速度)
虽然通过滑动窗口这个机制,一定程度上的提高了效率,但还是不可能高于 UDP 这种不需要可靠性的协议~ 有点提高,总比什么都不做强~~
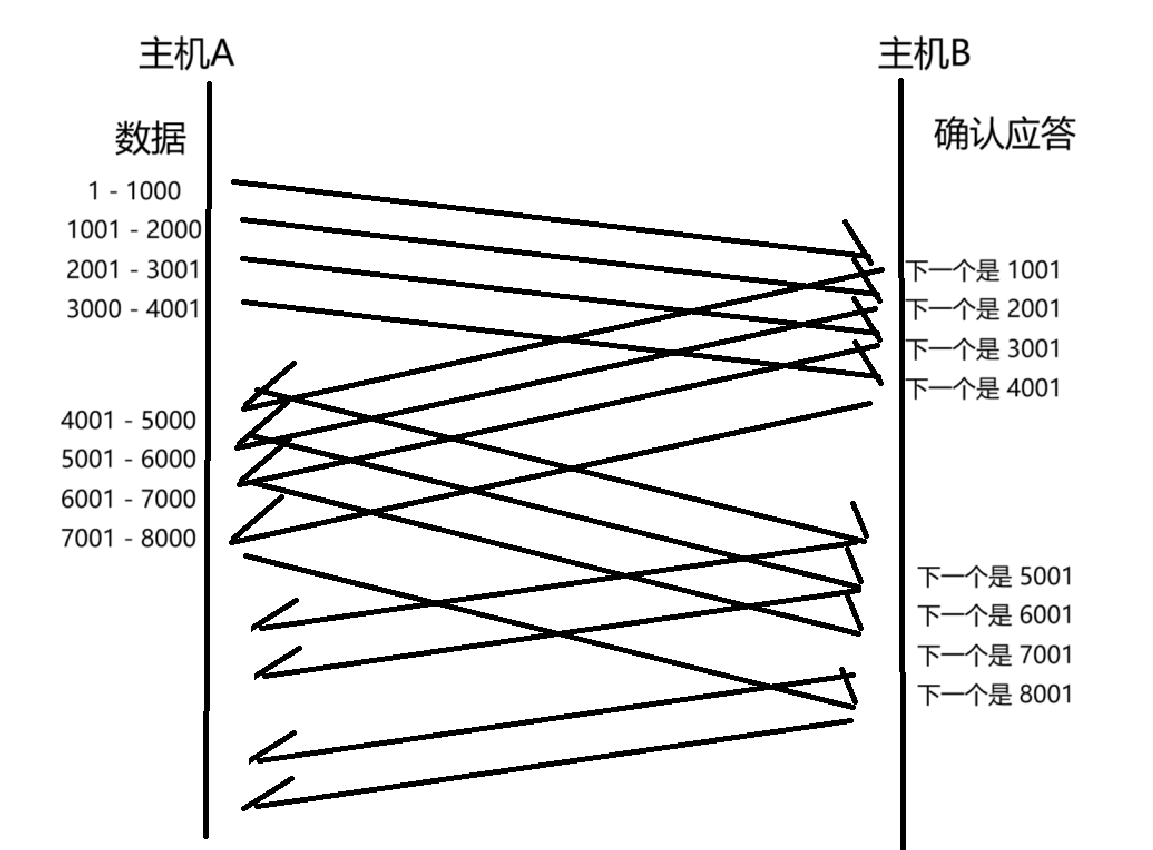
引入了滑动窗口,就可以实现 == 》批量传输。
之前是发送一个数据,等待 ack,再发送下一条数据。
现在是先发送一个数据,不等 ack,再发下一个,继续往下发数据~
连续发送了一定数据之后,统一等一波 ack ==》 把多次请求的等待时间,使用同一份时间来进行等待,减少了总的等待时间。
滑动窗口这个词是怎么来的呢?? ==》 其实这是一个很形象的比喻~~~
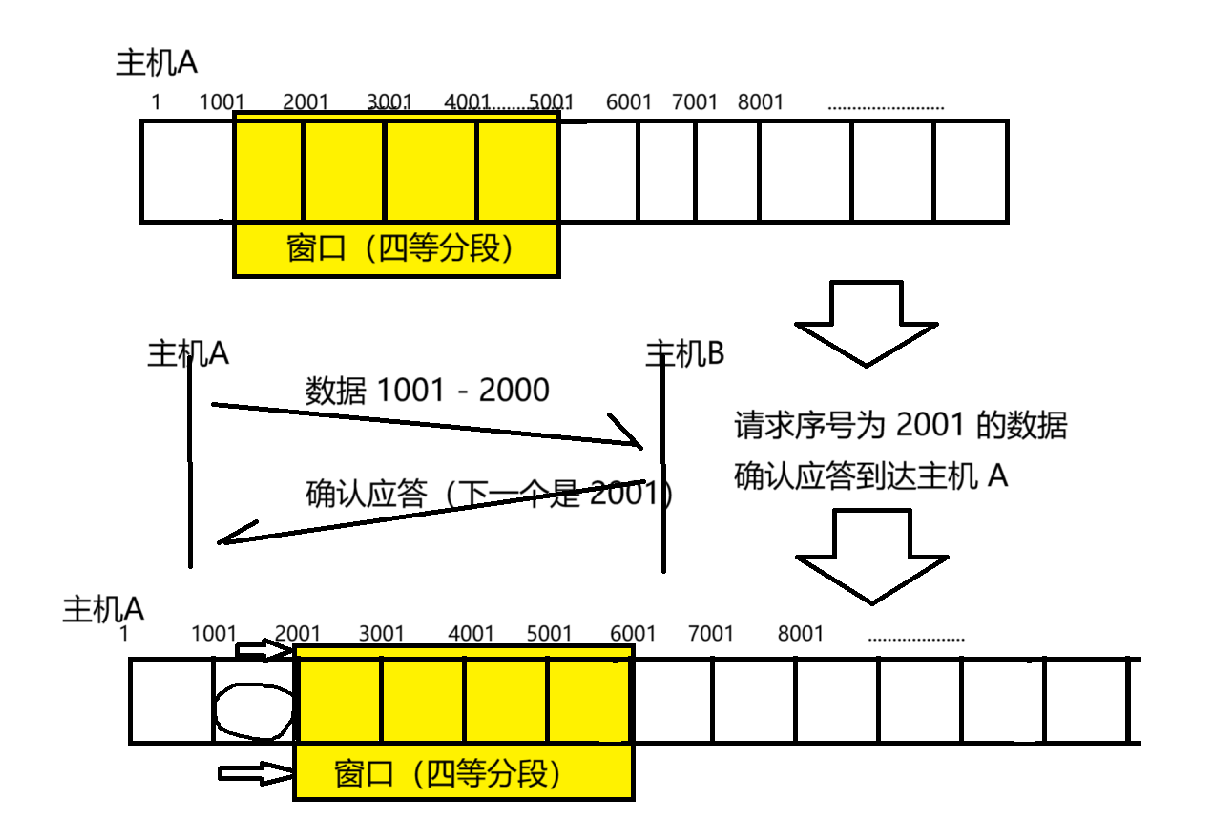
在这幅图的上面,黄色区域中的四份数据已经批量传输出去了~~传输出这四份数据之后,就等待 ack,暂时先不传输数据了~~~我们就把黄色区域(不等待 ack,能够批量传输的数据量)称为"窗口大小"
啥时候能继续发下一个数据(5001 - 6000)呢,是等到所有 ack 都回来了,再往后批量发四组数据,还是等回来一个 ack 就往后发一组呢??
等回来一个 ack 就往下发下一组,这样的效率会比较高~~
上述的发送 / 返回 ack 的过程都很快,窗口快速的向后面移动,也就形成了一个"滑动"的效果了~~~ ==》 因此也就把上述的过程,称为滑动窗口了~~
滑动窗口出现丢包
滑动窗口是我们为了提升传输效率的一个机制,但 TCP 安身立命之本的可靠性还是大前提的。如果出现丢包,滑动窗口会怎么解决呢???
这里可以分两种情况讨论:
情况一:数据报已经抵达,ACK 被丢了
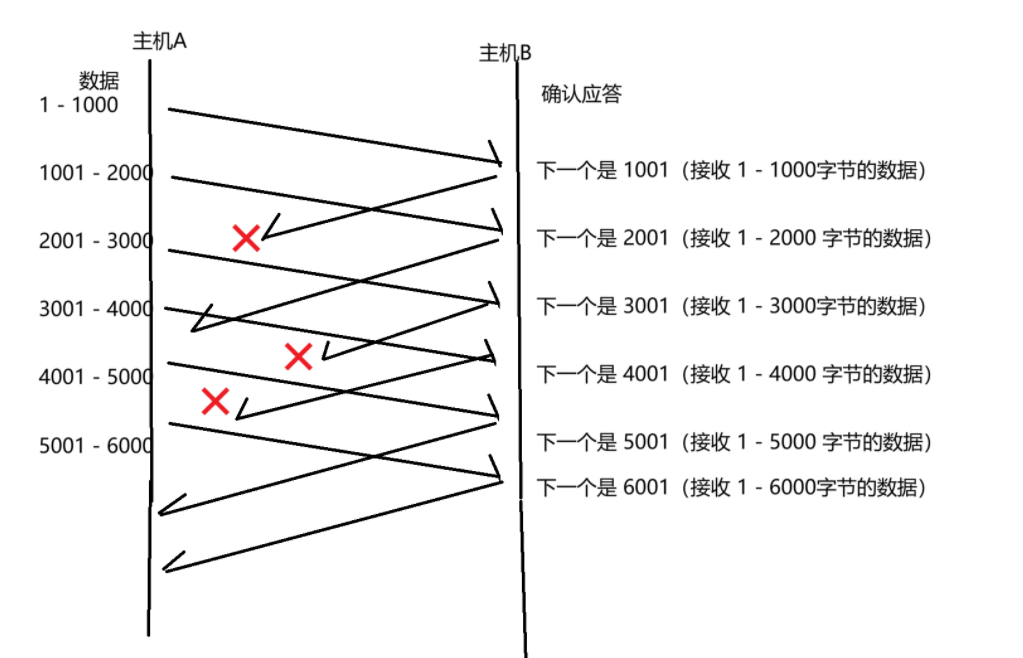
如上图,主机 A 的数据,都是完好的传入到了主机 B,但是主机 B 的一些 ack 出现丢包了,这种情况,其实并不会对我们的数据传输造成影响,我们无需进行任何处理~~
这里需要注意 ack 报文中确认序号的含义,比如我们传了 5001,代表的是 5001 之前的所有数据(1 - 5000 的数据都收到了)这里涵盖了 4001 之前的数据都收到了这样的信息~
情况二:数据报直接就丢了
数据丢了的情况,这个时候就一定要进行重传了~~~
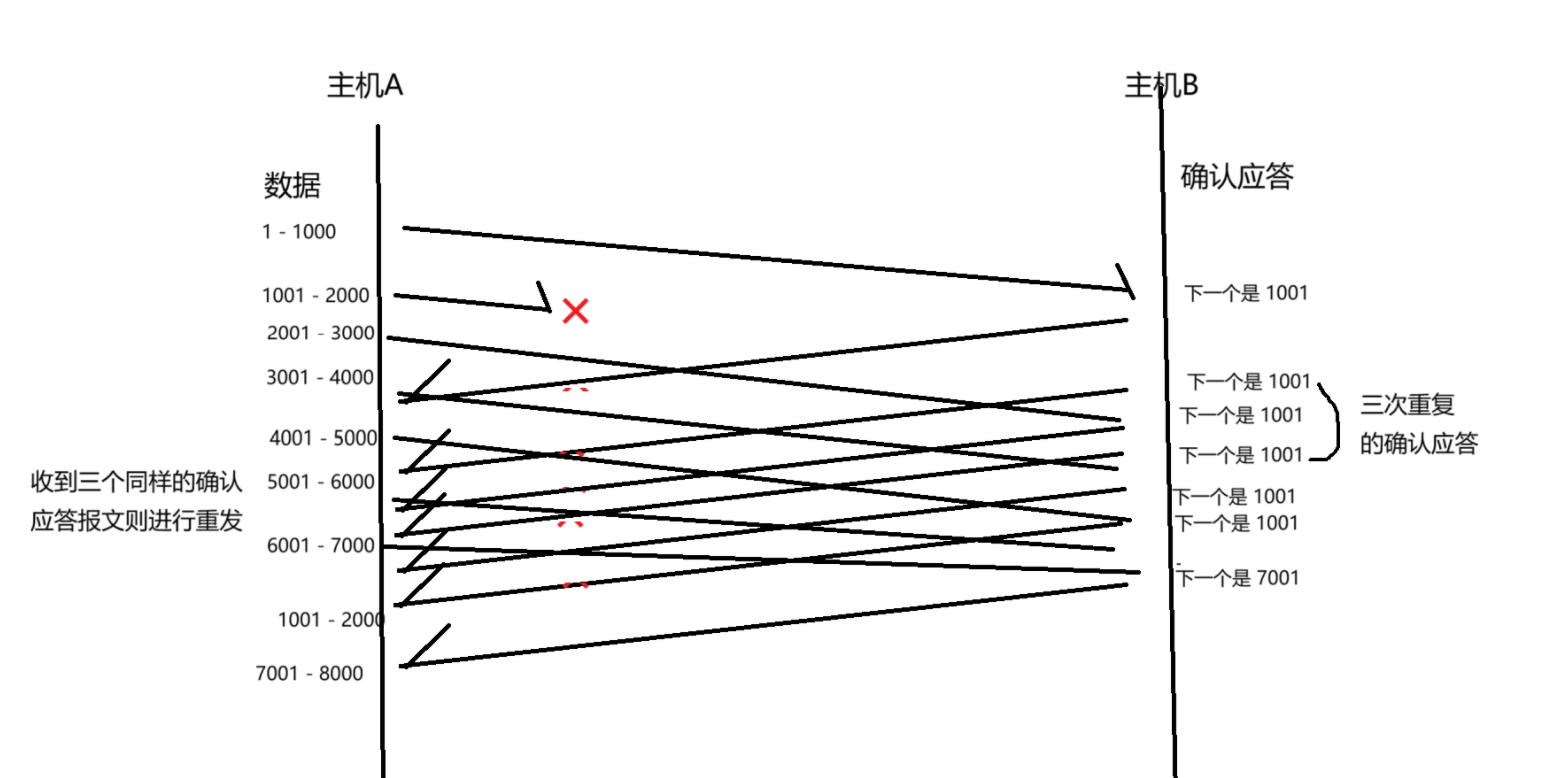
解决这个数据报丢了关键要点:是主机 B 的确认应答报文中,当没有收到 1001 - 2000 数据的时候,返回的应答报文中的确认序号是 1001,而不是 3001。如果是 3001,就是在告诉发送方,1001 - 2000也收到了实际上是,1001 - 2000 的数据报丢包了没收到~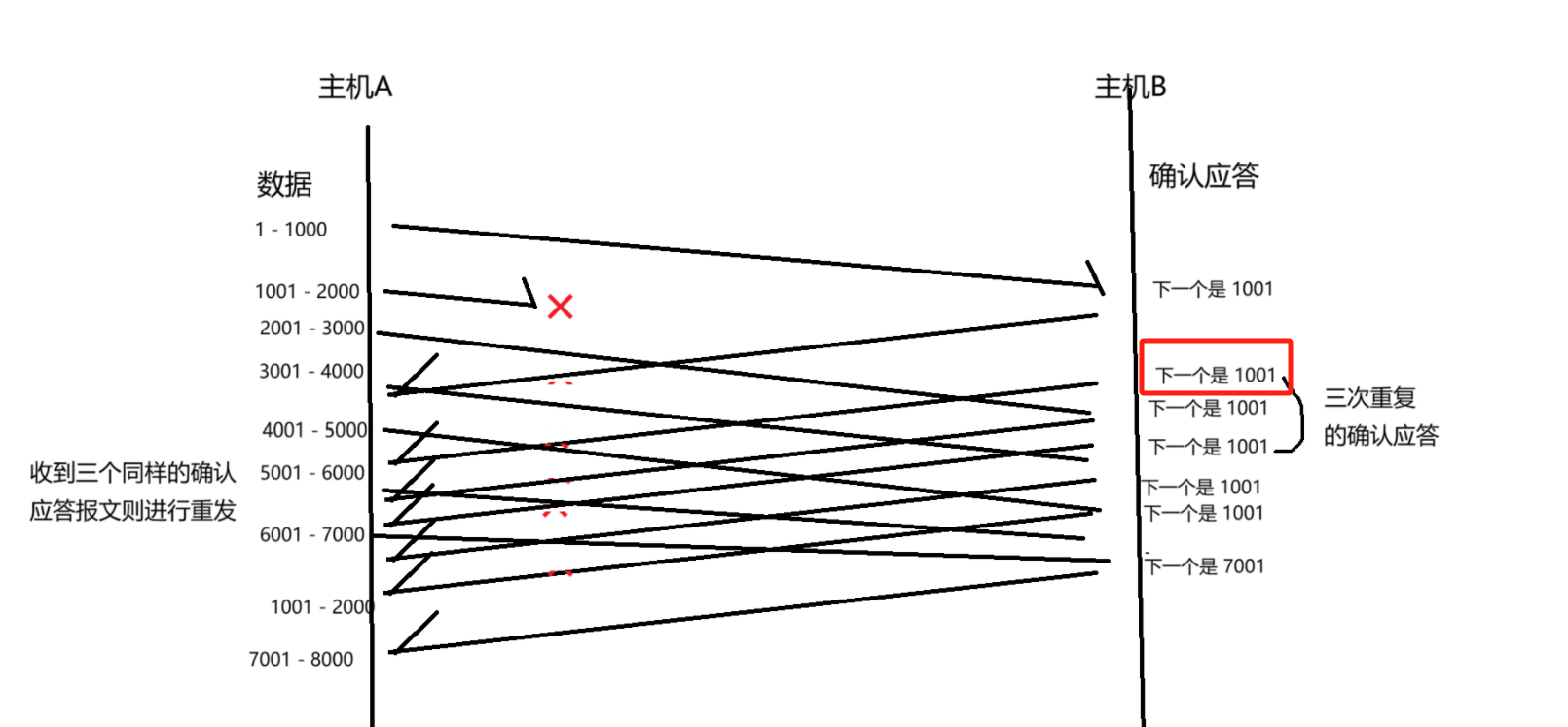
此处就明确告诉了对端,我想要的现在是 1001 这个数据,不仅是这一个应答报文,而是接下来的若干数据,确认序号都是 1001,反复的向对端索要 1001 这个数据。(发福索要,就是再给 1001 的到达留有等待时间,连续多次索要的时候,发现 1001 这个数据还没到达,应该就是丢包了,就相当于"超时时间"判定了)
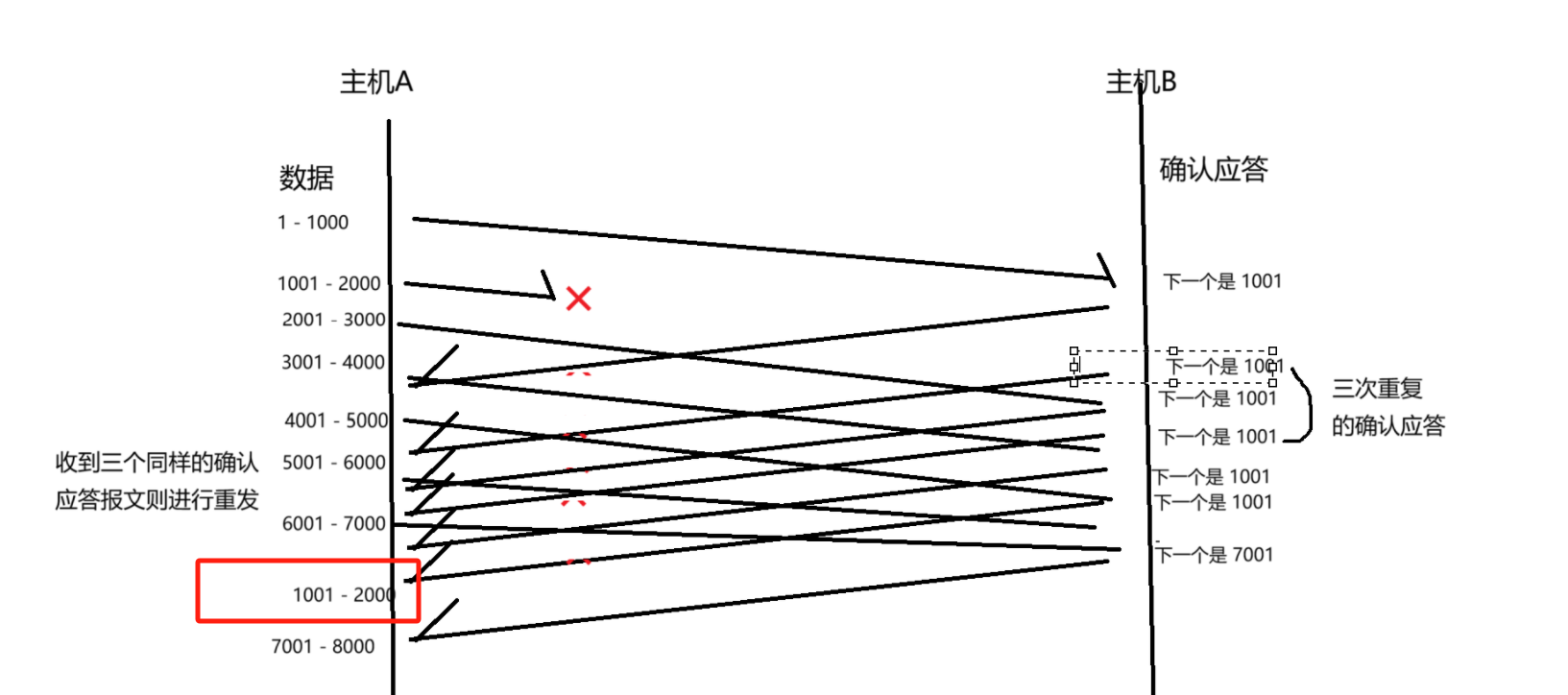
当发送方多次收到索要 1001 的 ack 确认报文之后,就反应过来,你连续的向我要 1001 这个数据,就会认为 1001 这个数据丢包了,就会重传 1001 这个数据。
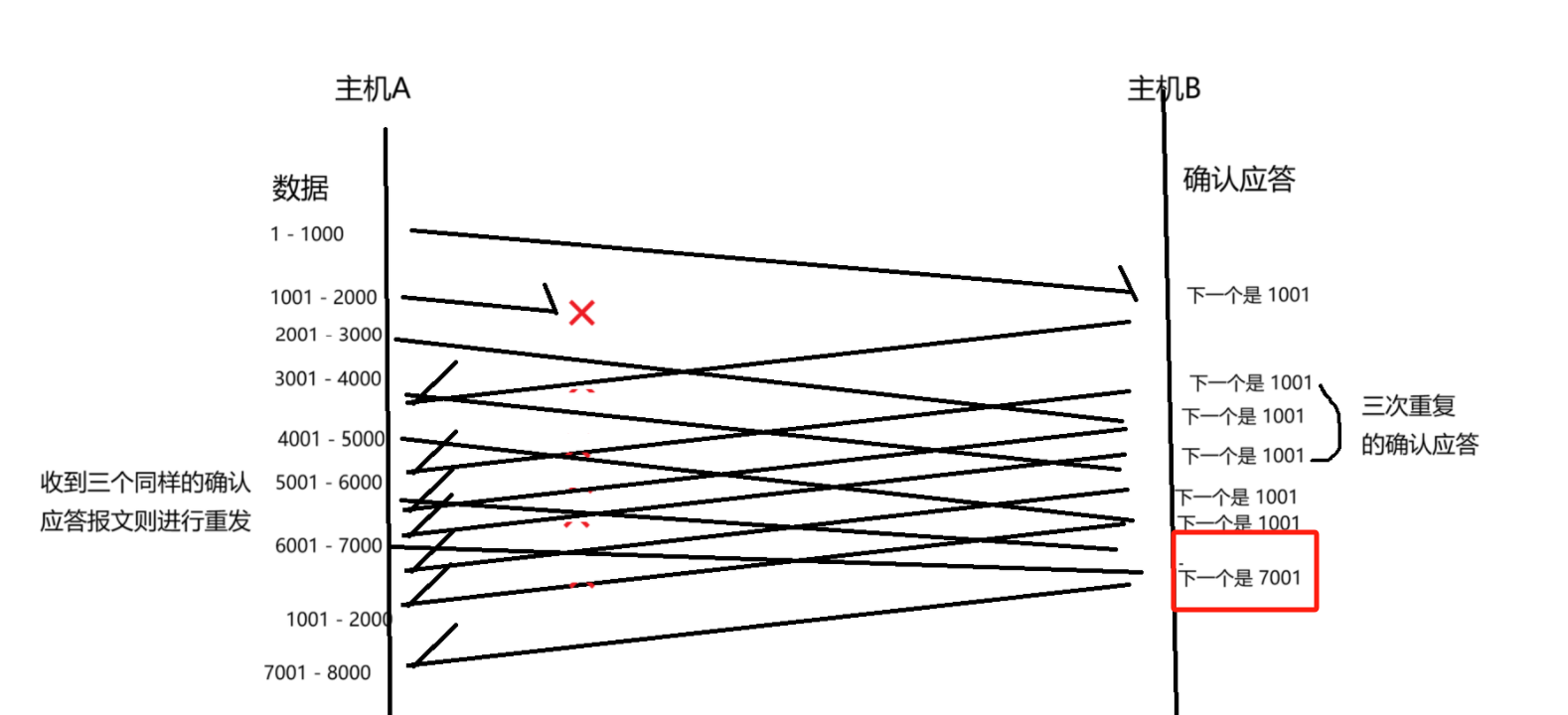
重传 1001 之后,此时的确认序号就是 7001 了,而不是再从 2001 开始,确认序号要表示的是,我接下来要向发送方索要那个数据~~ 当发送方重传 1001 这个数据之后,接收方的 7000 之前的数据就都收到了,接下来就要索要 7001 这个数据了~~~
在上述重传的过程中,整体的效率是非常高的,这里的重传就做到了"针对性"的重传。那个丢了重传那个,已经收到的数据,就不必要再重复发送了,整体的效率是没有额外的损失,我们就把这种重传称为"快速重传"。
注意,这里虽然 1001 丢包后,是在一段时间之后再又重传过来的,但因为我们已经给数据都编号了序号,而且在接收方是存在一个带有优先级的阻塞队列的(生产者消费者模型),发送方发送的数据,到了接收方,都是会先放到接收缓冲区里面进行排队的。一排队,咦,发现队伍里缺数据了,却谁,就再向发送方喊谁,等缺的人到了,队伍补齐了,就可以发车了~~~
补充:
我们讲的前面的几个机制,确认应答,超时重传,滑动窗口,快速重传,他们是并不冲突的,而且是同时存在的~~~
如果当前传输过程中,是按照滑动窗口(短时间内传输大量数据),就按照快速重传来保证可靠性,此时判定丢包的标准就是看是否接收方连续有多个 ack 索要同一个数据。
如果当前传输过程中,不是按照滑动窗口(没有很多数据需要传输),此时就仍然按照之前的超时重传来保证可靠性,此时判定丢包的标准就算达到超时时间还没有 ack 到达。
注意:滑动窗口中也有确认应答,只不过,把等待的策略稍作调整,转成批量的了,批量的前提是,发送方短时间发送了很多数据。(如果发的数据很少,此时窗口就滑动不起来,就退化成了确认应答~)
5. 流量控制
我们前面讲,通过滑动窗口,可以提高传输效率,窗口大小越大,更多的数据复用同一块时间等待,效率就更高~(批量传输不需要等待 ack 的数据量,就称为"窗口大小")
窗口大小肯定是不可能无限大的~~请记住,TCP 的安身立命之本是可靠传输,任何提升效率的行为,都不应该影响到可靠性~~~
发送的数据不能无限大,此时就需要考虑一些情况,来保证我们传输数据的可靠性。
比如说,发送方发的飞快,但是接收方处理不过来,此时也会出现丢包(接收方的接收缓冲区满了,发送方还在继续给他发,就会出现丢包情况)
这很像我们做数学应用题中的蓄水池问题:
很明显,如果接收方的接收缓冲区满了,发生丢包情况,这时候发送方就算重传也没用,反而还会浪费硬件资源~
与其等待接收方满了,发送方停止发送,还不如提前就感知到接收方接收缓冲区的情况,提前减慢速度~~
让发送方发送数据和接收方处理速度,可以做到步调一致~~~就算让接收方的处理数据的速度反过来影响发送方的速度 ==》 流量控制!!
我们在 TCP 报头讲解的时候,有一个 16 位窗口大小,就是用来做这个的~~
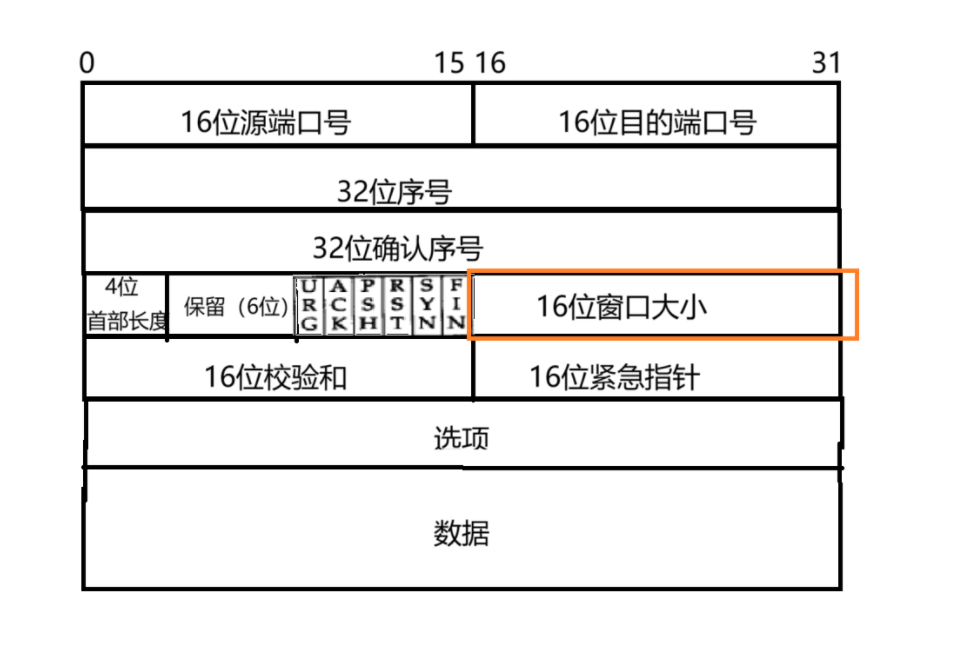
通过这个字段来给发送方反馈发送速度,这个字段在普通报文中是没有意义的,只有在 ack 报文中才有意义~~~
通过这个大小来反馈给发送方,接下来要发送的窗口大小设置成多少合适(接收方会按照自己接收缓冲区剩余空间的大小,作为 ack 报文中窗口大小的数值)~~~ 下一步发送方就会根据接收方 ack 中的窗口大小数值来调整自己的窗口大小。
补充:
我们这里 TCP 包头中,窗口大小是 16 位,但窗口大小并非就是 64 KB(2 的16次方是 65535,64KB = 64 * 1024 = 65535~~)~ 实际上,TCP 报头的选项中,还包含了一个参数,叫做窗口扩展因子,实际上真实要设置的窗口大小是:16 位窗口大小 * 2 ^ 窗口扩展因子
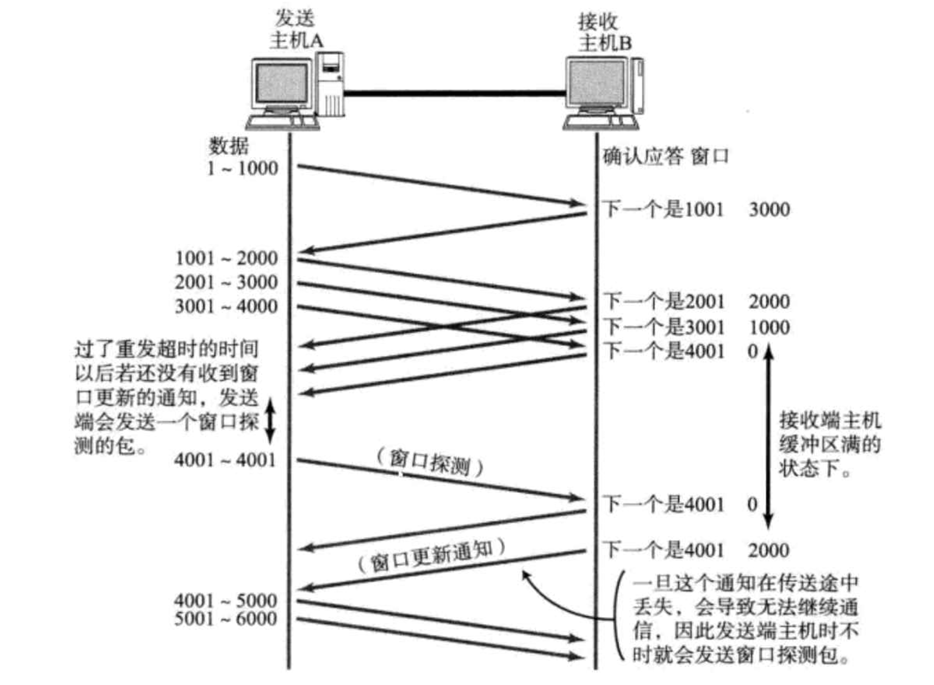
如上图,当接收方的接收缓冲区为 0 的时候,此时接收方就应该暂停发送,发送方什么时候恢复发送呢?? ==》发送方会周期性的发送一个"窗口探测包",这个窗口探测包,并不会携带任何载荷,这样的包对于业务并不产生影响,只是为了触发接收方的 ack,一旦查询出来的结果,是非 0 的时候,就代表缓冲区又行了!!!发送方就可以继续发送了!!!