一.stack和queue的基本使用
stack和queue就是我们之前所学的栈和队列,这两个和之前学的vector,list不太一样:


这是vector和list的,注意第一行中写的containers,代表这两个都是容器,但是:


stack和queue不是容器,而是容器适配器,也是STL六大件之一,可能有人有疑惑:两者区别是什么?
容器:容器是用于存储和管理数据的类模板。常见的容器包括vector 、list 、deque 、set 和map 等。容器分为两大类:序列式容器 和关联式容器。序列式容器按元素加入的顺序存储数据,而关联式容器按关键字存储和访问数据。
适配器:适配器用于修饰容器、仿函数或迭代器的接口,使其行为类似于另一种事物。例如,queue 和stack 是容器适配器,它们底层依赖于deque 。
适配器不止有容器适配器,还有其他的适配器。
容器适配器简而言之就是借助容器的一种接口转变为另一种接口。
所以这两个的实现和之前的有所不同。

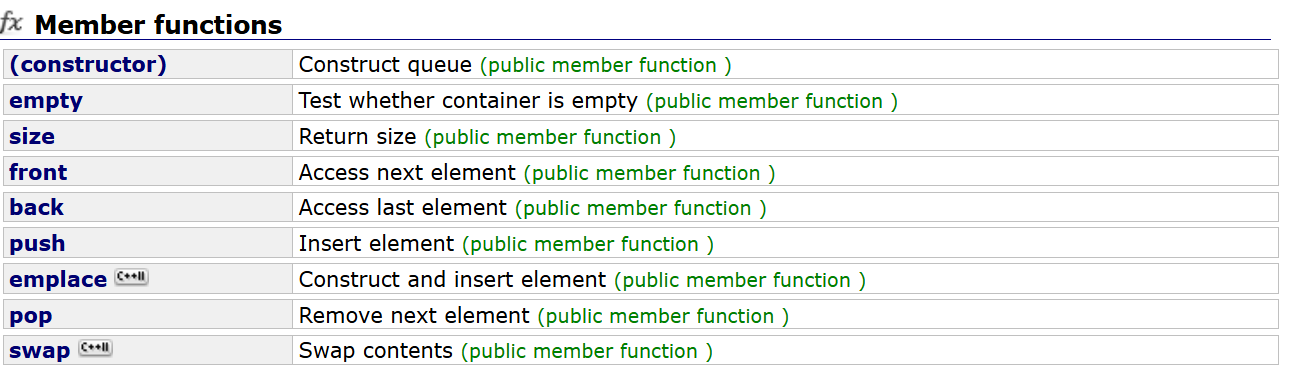
这两者的接口也和之前我们学栈和队列时所实现的一样,相信大家看到名字就知道如何使用,这里
对emplace提一嘴。
emplace和push的功能一样,但是其中涉及到目前未接触的知识,所以目前知道它怎么用即可,后面学到相关的知识会讲解。
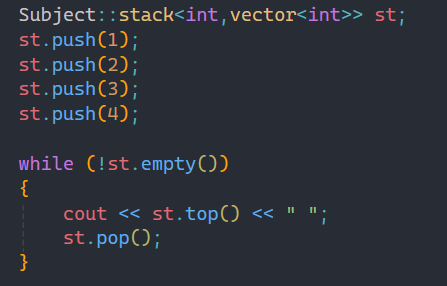
下面演示一下stack和queue的基本使用:
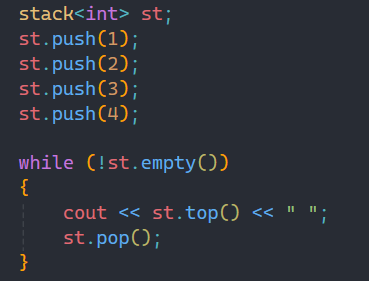
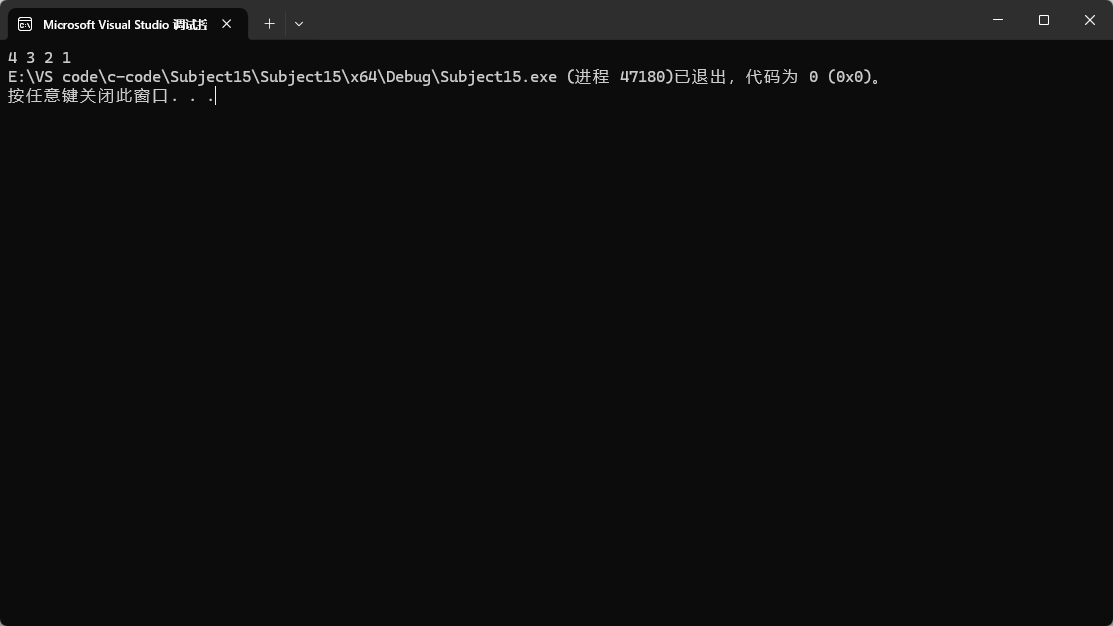
这是stack的基本使用,和之前学过的一样,遵循后进先出的原则,将其栈顶元素打印出来。当然,出栈顺序不是唯一的。
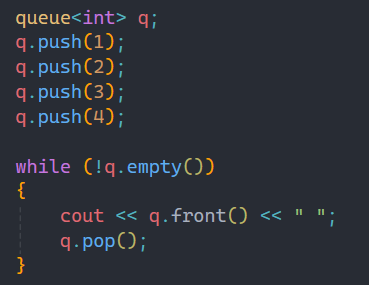

这是queue的基本应用,和之前学过的一样,遵循先进先出的原则,打印出队列中队头的数据。和栈不同的是,队列出队顺序是唯一的,即使中间插入删除,也是如此,原因也就是先进先出。
二.stack和queue的实现
2.1stack

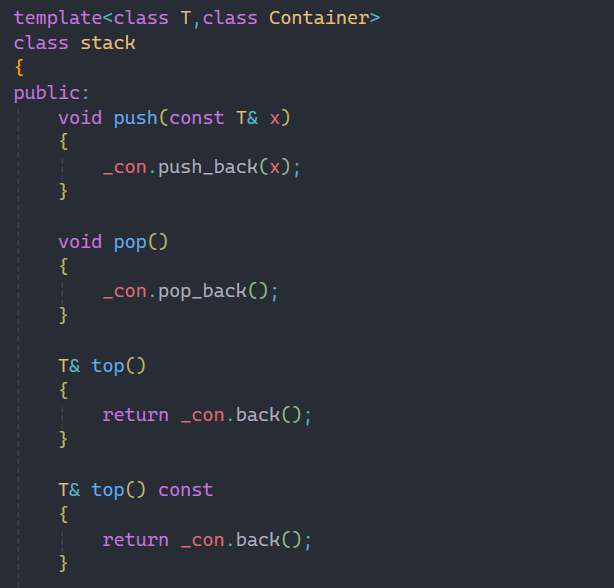
当我们实现stack或queue时就会发现比起容器的底层实现来说要简单许多,stack和queue都可以借助容器来实现。
在模板参数中我多写了一个类型Container,想必大家看见这个单词就知道它是什么作用,没错,就是用来接收不同的容器。
因为我们知道不管是stack还是queue,都可以用vector或者list来实现,所以为了满足这个需求多写一个类型。
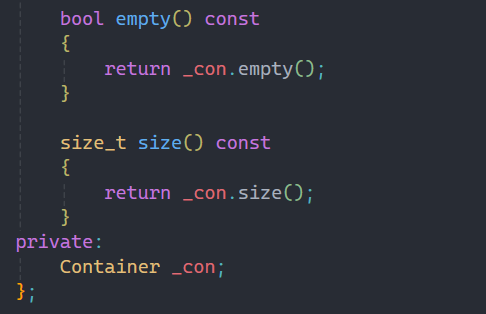
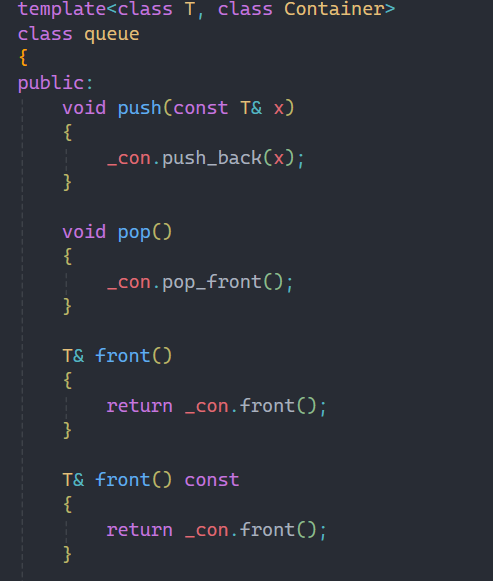
所以唯一的一个成员变量就是由不同的容器所创建的对象,剩下stack中的接口就都可以借助容器来实现,这里实现都比较简单所以我就不过多赘述了。
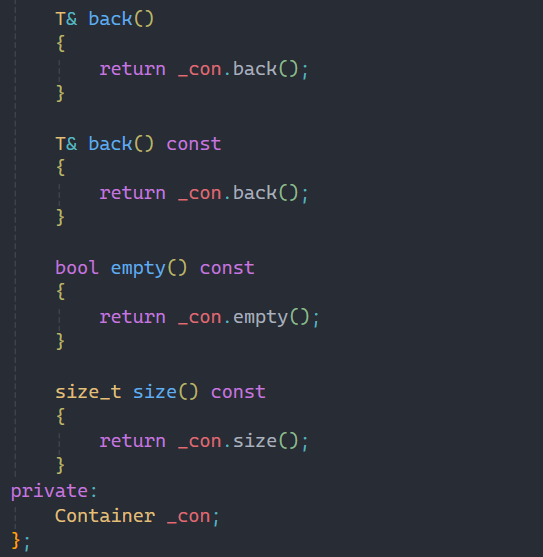
唯一要说明的就是back接口是之前没有讲到的,不过看这个名字就知道返回的是最后一个数据,与之相反的是front,返回的是第一个数据。
2.2queue
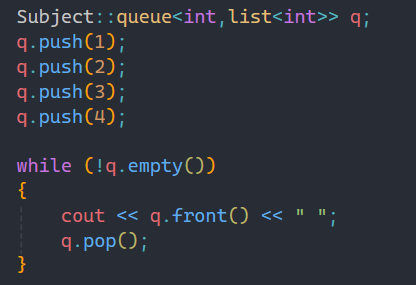
和stack一样,queue借助容器的接口也可以实现。
不过要注意的是如果在使用queue时,传的容器是vector,是不能调用pop_front的,因为vector底层没有实现这个接口:

所以如果要用vector来实现queue,可以借助erase接口来实现。
stack和queue是都没有迭代器的,只有容器才会有迭代器。
三.deque


而在实际应用中,第二个类型Container是有默认容器的,这个容器就是deque。
有人会疑惑为什么默认容器既不是vector或者list,而是deque呢?
在解决这个问题之前我们先思考一下vector和list的优缺点:
vector:
优点:下标随机访问效率高
缺点:
1.头部或者中间的插入删除效率低
2.扩容会造成一定的空间浪费。如:容量200,但只存入了100个甚至更少的数据
list:
优点:
1.头部或中间的插入删除效率高
2.不存在扩容,不会有空间浪费,按需申请结点或释放
缺点:不支持下标随机访问
其实看了两者的优缺点,vector和list其实是互补的。
而deque:

double-ended queue就是deque的名字,叫做双端队列,别看名字后面加了个队列,其实跟队列没有关系。
可以看出deque支持\[\]符号,并且支持头插,头删,尾插和尾删。其实,deque就是vector和list的整合,同时兼具vector和list的优点。
但是deque的结构要比我们之前学的所有容器要复杂,甚至复杂得多。
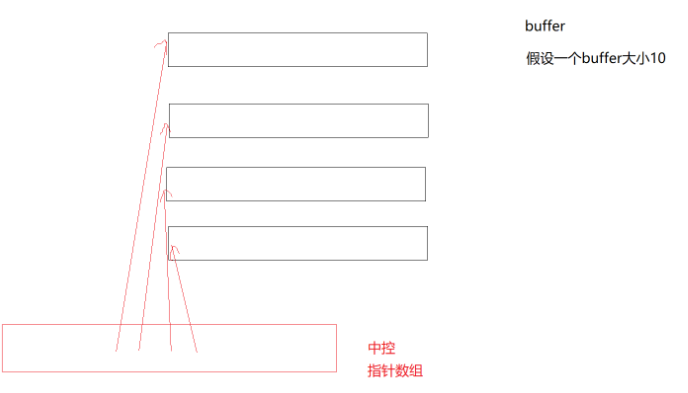
deque的结构大概就是这样,中控指针数组中保存的就是各个小数组的地址,而每一个地址都指向一个buffer数组,这个数组的大小一般都不大。
可以看出每个buffer数组之间并不连续的,但是再中控指针数组存的指针是连续的。
我们下来看deque的具体结构:
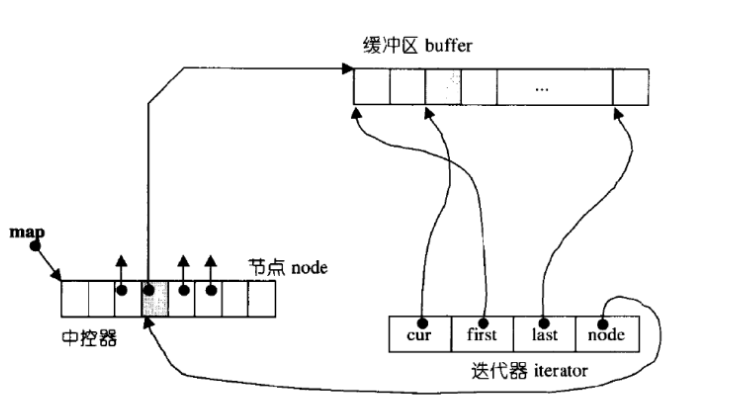
这就是deque的具体结构,可以看出是比之前的容器复杂多的,就一个迭代器就含有四个变量,cur是用来遍历deque的,first是每个buffer数组首元素地址,last指向每个buffer数组结尾,node是来寻找每一个buffer数组,因为要记录每个buffer数组的地址,所以node是二级指针,比如:node++就会找到下一个buffer数组。
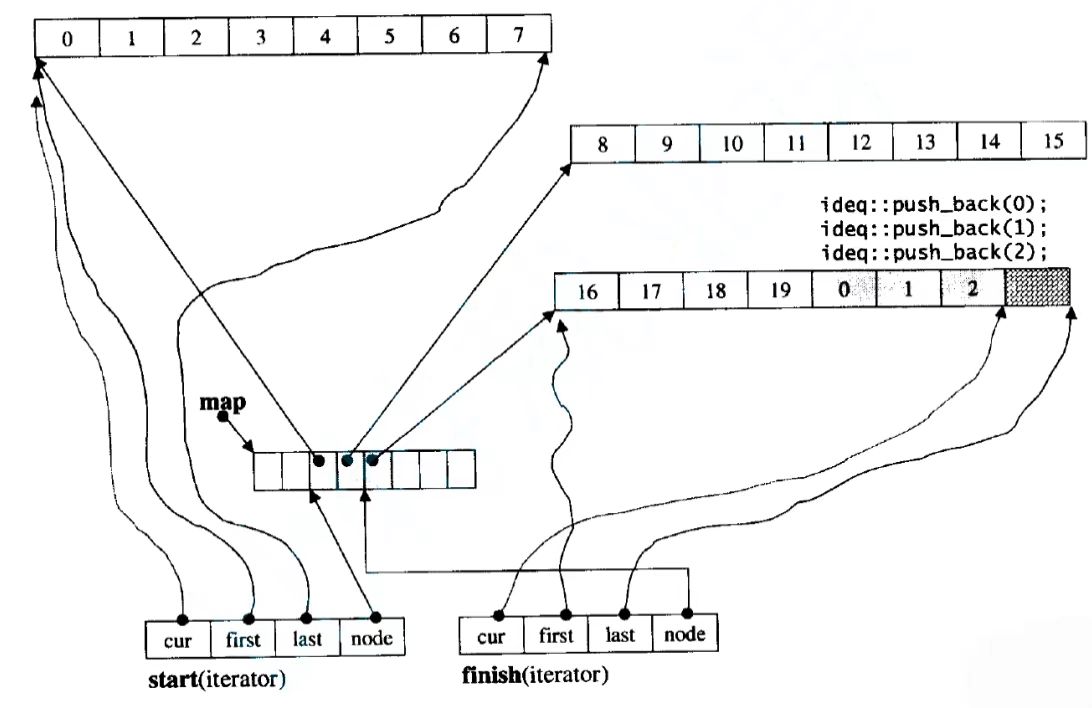
而deque为什么叫双端队列的原因也正是因为它的结构,从图中可以看出deque存数据是从中间开始存数据,如果要头插或者尾插,就会向两边延伸开辟新的buffer数组。
但是在实际应用中deque用的并不多,所以下面我只简单介绍一下deque某些接口的实现思路:

我们经常要用迭代器来遍历数组,在deque中cur就是这个作用,虽然迭代器含有四个变量,但其实比较的就是cur。
而遍历完一个buffer数组,就要走到下个buffer数组,所以也要对++符号重载进行一些变化,如上图所示,其中的N就是每个buffer数组的大小。

而如果要头插,注意是从最后一个位置开始插入数据,这样才符合deque的结构,不能从头插入数据,尾插就是直接按顺序插入数据即可。
头插和尾插同样也会造成一部分的空间浪费,但是浪费量相对较小,这取决于buffer数组的大小,最大就是浪费了buffer数组的大小-1个大小的空间。

而如果要找到某个位置的值,就要找到它是哪个buffer数组的,并且是这个buffer数组的哪个位置。
而找到是哪个数组就可以让输入的值 / buffer数组的大小,具体哪个位置就让输入值 % buffer数组的大小,图下方的例子就可以验证。
这时候我们思考一个问题:为什么deque同时兼顾了vector和list的优点,但是并没有替代vector和list呢?
解决这个问题就要先总结出deque的优缺点:
优点:
1.头部和尾部的插入删除效率高
2.下标随机访问效率也可以,但是不如vector
缺点:
中间的插入或删除效率不高,不如list
其实deque无法完全替代vector和list的原因就很明显了,虽然它同时兼具vector和list的优点,但是没有引起质变的功能,兼具的优点没有发挥到极致。
说白了就是什么都沾点,但是都不精,在下标随机访问方面不如vector,中间的插入删除不如list。
可能有人会问:那下标随机访问效率会差多少呢?
我直接说结论:大概差两倍左右的性能。举个例子:把deque中的数据拷贝到vector中进行sort排序,再把排好序的数据拷贝回deque的效率都比deque直接调用sort排序高,效率基本上还是差两倍。
那中间的插入删除效率会差多少呢?
这个问题相信大家都有数,就相当于vector的中间插入删除和list的中间插入删除效率相比较。
而为什么stack和queue的默认容器是deque的原因就是deque的第一个优点,因为stack和queue主要功能就是头部和尾部的插入和删除。
四.priority_queue
4.1priority_queue的基本使用

priority_queue就是优先级队列,这个就是特殊的队列,所以也是包含在queue头文件中的。
和stack,queue一样,priority_queue也是容器适配器,从第二个参数可知,priority_queue底层默认是用vector实现的。
第三个参数呢叫做仿函数,下面会讲,这里先讲如何使用。
为什么叫做优先级队列呢?
因为它是按优先级来出数据的,默认是按大的优先级高,这里可能有人感觉和之前学的某个东西有点像。
没错,就是堆,按优先级来出数据,不就是默认是大堆吗。所以这也是为什么默认容器是vector来实现。
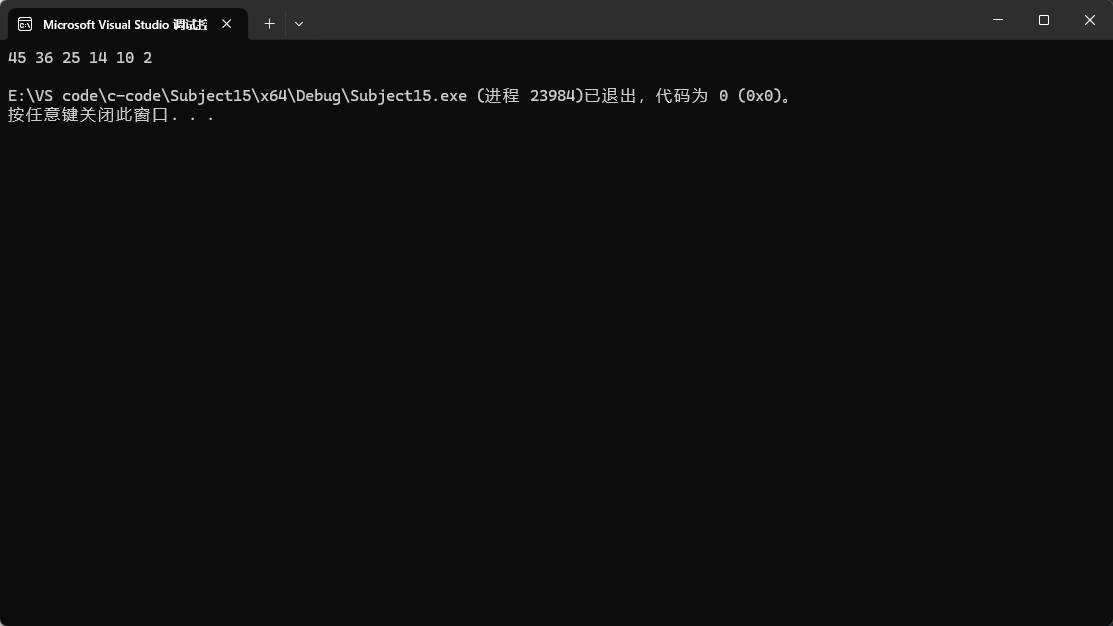
根据输出的结果,我们可以自己画个图来看输出顺序是否是大堆,那么如何用小堆来输出呢?
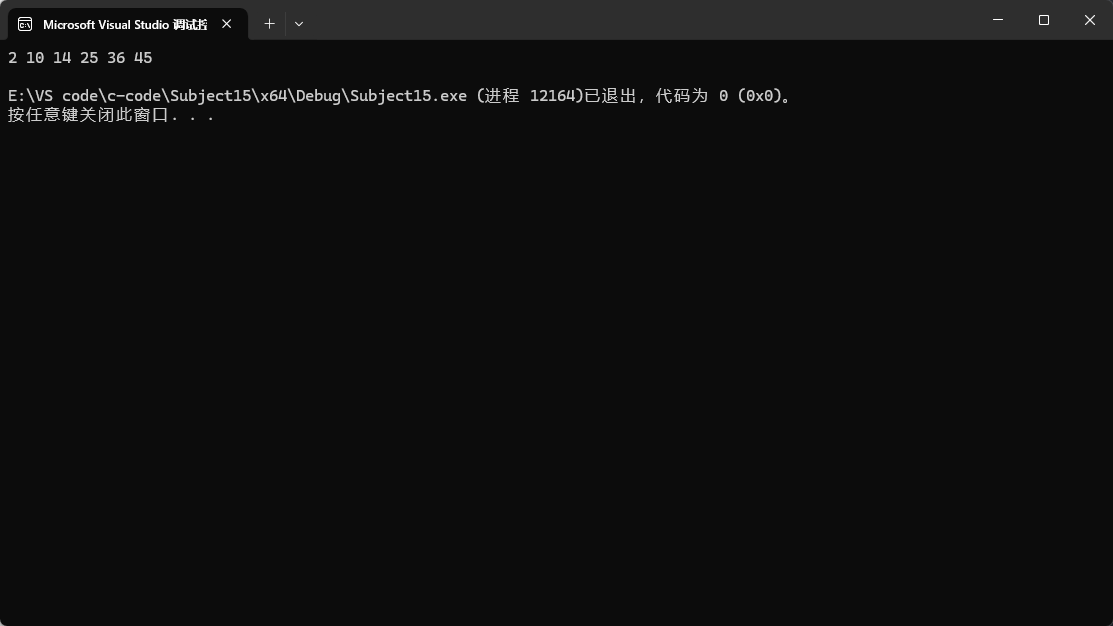
这时候就要用到仿函数,这里用到的仿函数是库里的greater。
这里提一嘴,正常来说,greater这个仿函数是从大到小排序,less仿函数才是从小到大,不过因为早期priority_queue设计的一些缺陷,导致两个仿函数在这里功能反过来了。
4.2priority_queue的底层实现
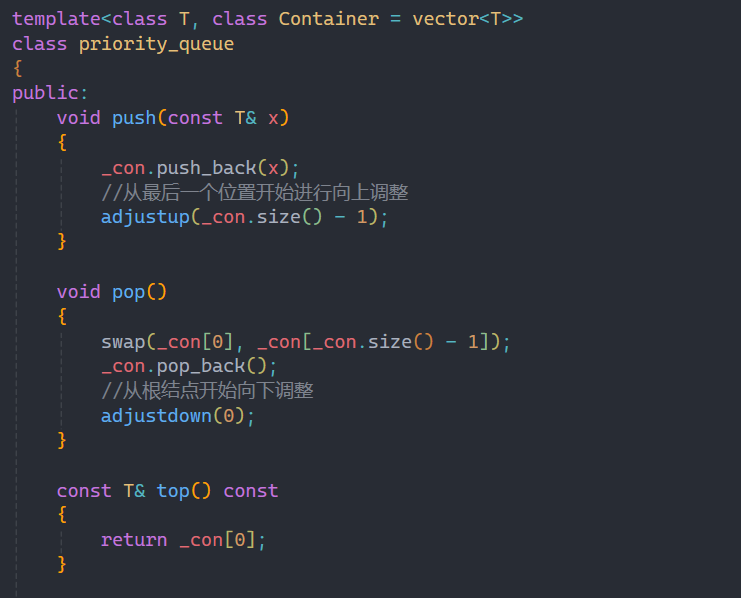
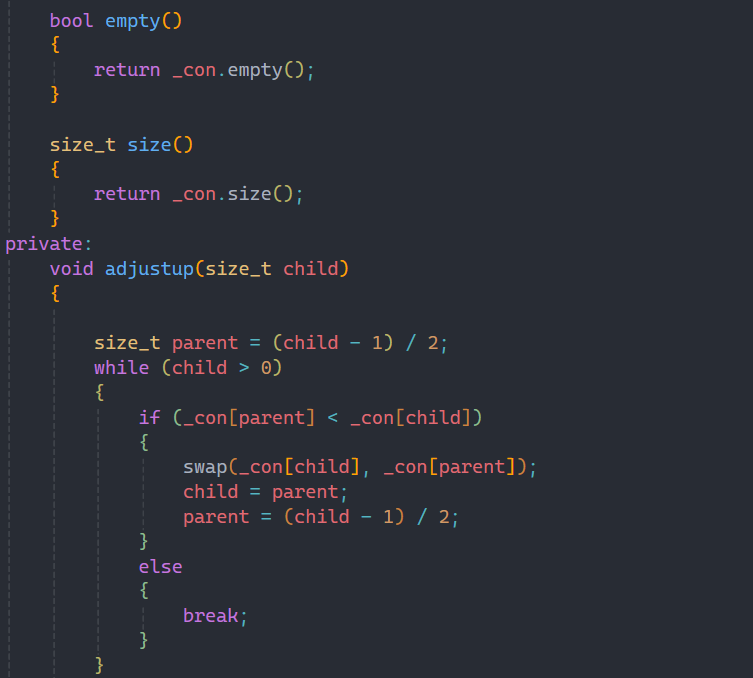
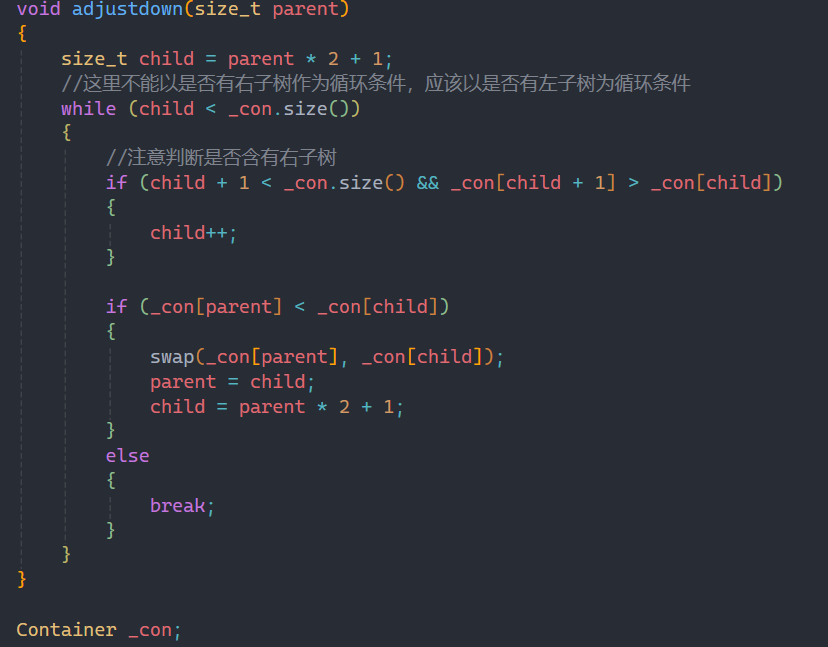
这里实现我先按照大堆来实现,后面讲仿函数时在进行优化。
根据priority_queue的接口,利用容器接口来进行实现,对priority_queue进行修改其实就是对堆进行修改,所以push和pop要利用之前学的堆的知识来解决问题。
向上调整算法和向下调整算法在堆的章节已经详细讲过,这里就不过多赘述。
需要注意的是就是pop时,要先交换堆顶和堆底的数据,如果直接删堆顶的数据,整个堆的结构就会被破坏。交换后,再利用向下调整算法就可以解决这个问题。
五.仿函数
仿函数(Functor),也被叫做函数对象(Function Object),它是一种行为类似于函数的对象。在编程里,函数是一段能够接收输入参数并返回结果的代码。而仿函数则是一个可以像函数那样被调用的对象。
一般仿函数是一个类或者结构体,这两个用哪个实现都一样,下面我们来简单实现以下上面所讲的less和greater:
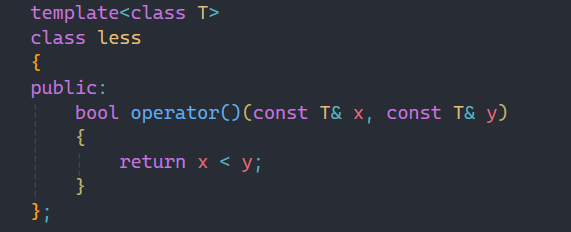
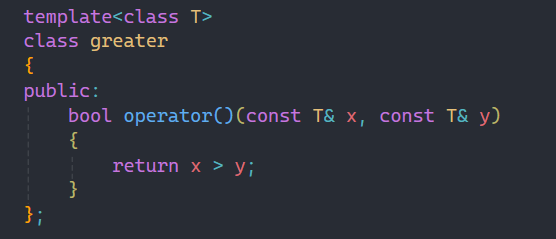
仿函数实现起来很简单,就是重载了()符号,使其比较逻辑发生改变。
其实仿函数的主要作用也就是改变比较逻辑,使其按照你想要的比较逻辑进行比较。
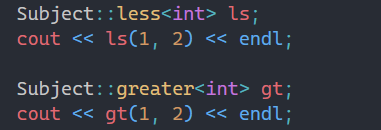
在使用时就能体现为什么叫实现函数的功能,设想一下,如果没有写Subject::less<int> ls和Subject::greater<int> gt,直接看输出那一行,是不是感觉就像两个函数传参一样。
通过实现仿函数,我们来对上面所写的push和pop接口进行优化:

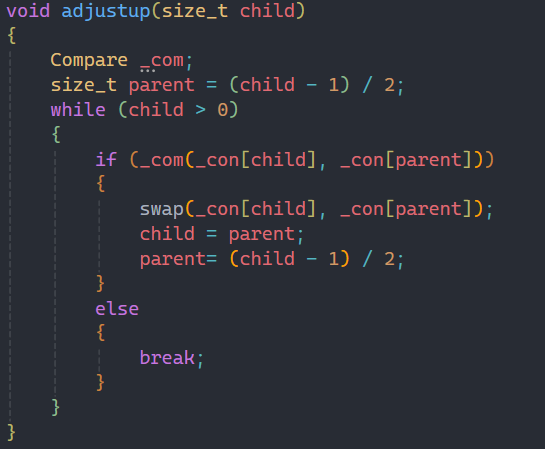
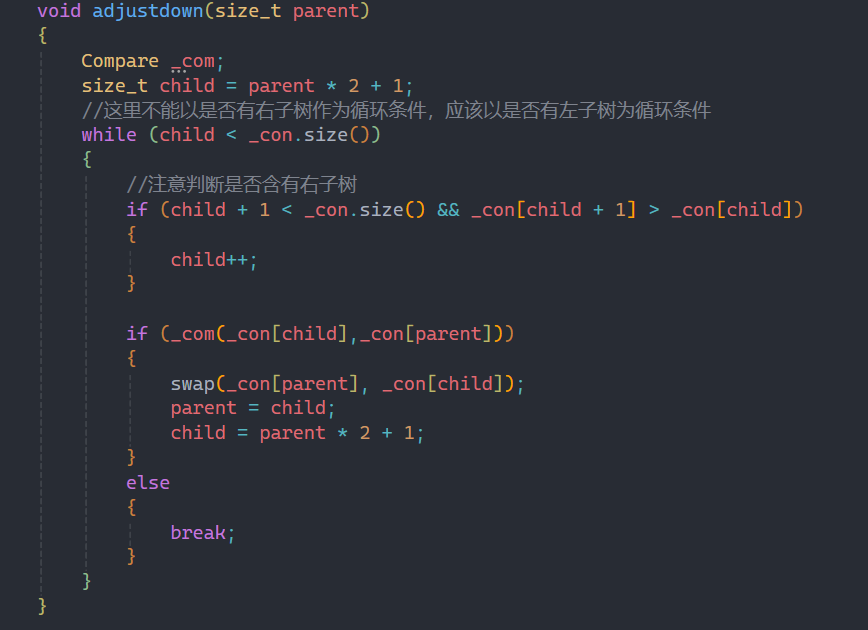
这里我们就可以使用仿函数来对向上和向下调整算法进行优化,为了和库里面保持一致,这里同样默认是大堆,用greater来实现。
要用greater来实现的话,注意传参的顺序,两者不能颠倒,保证如果不使用仿函数,两者是>的比较。
仿函数在一些特殊场景也发挥着作用:
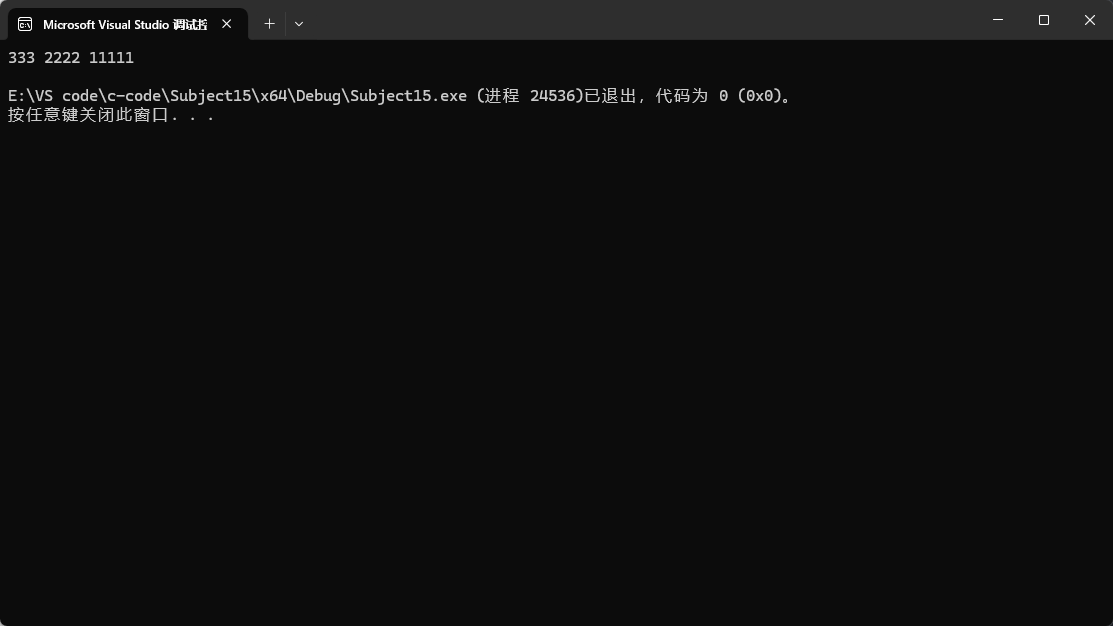
比如我们传的类型时string,string默认使用ASCII值来进行比较,但是我们如果不想用ASCII比较呢?比如想按照长度来比较:
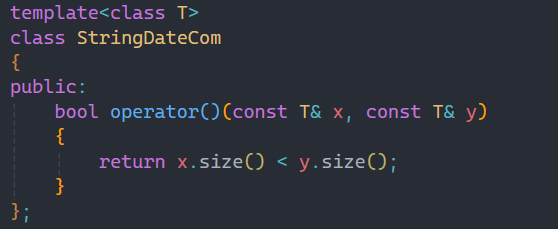
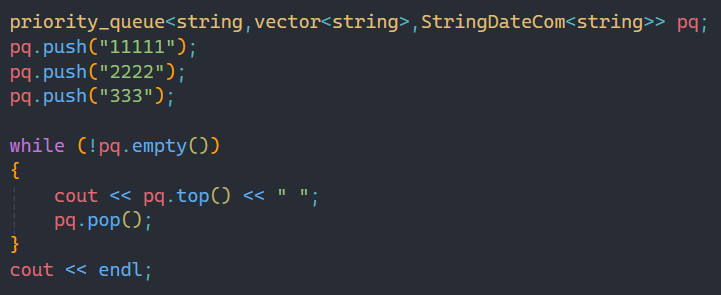
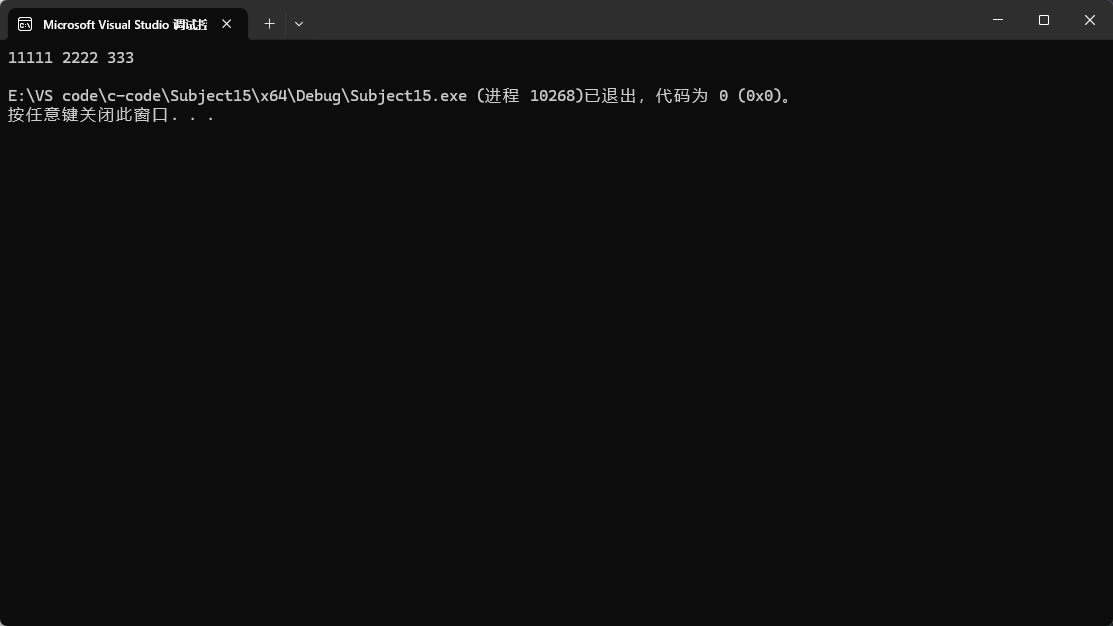
此时我们自己写一个仿函数,来选择比较的方式,就可以做到按照长度进行排序。
以上就是stck_queue的内容。