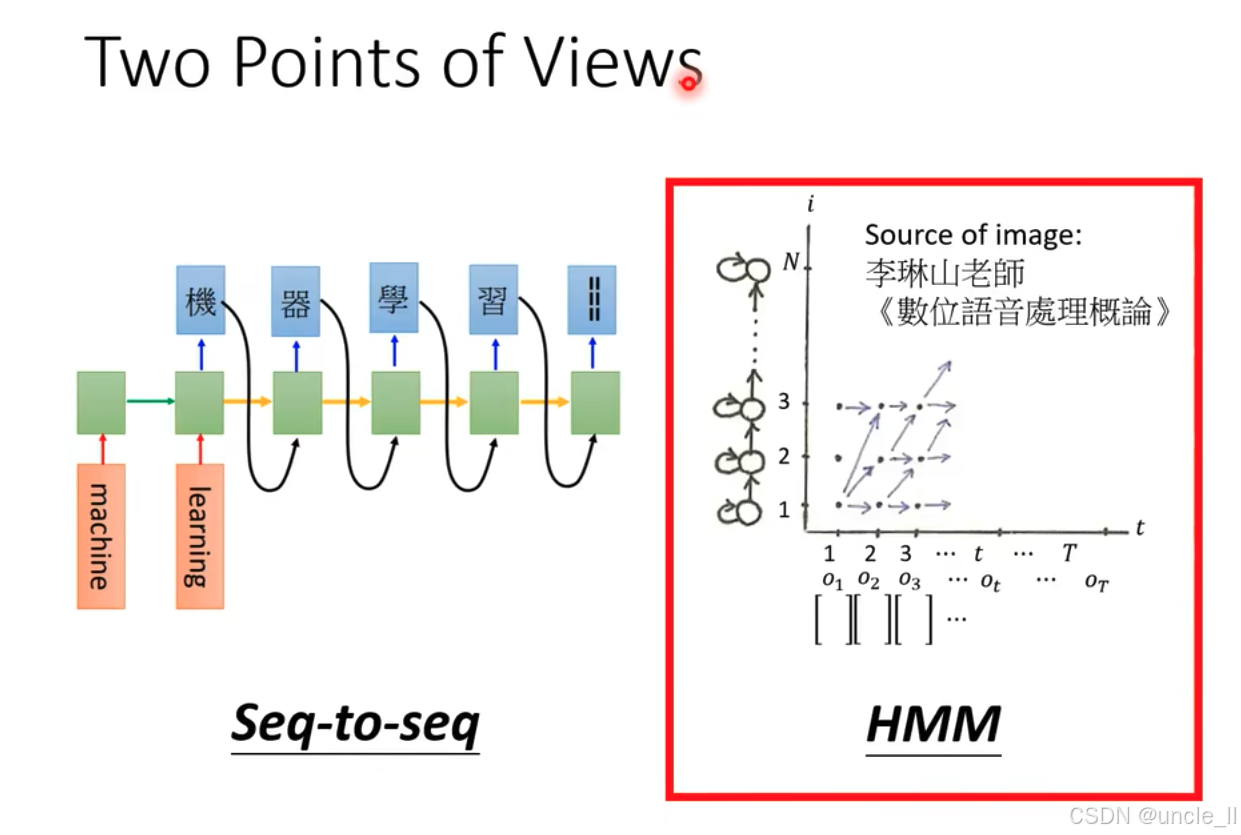
比较seq2seq和HMM
Hidden Markov Model(HMM)
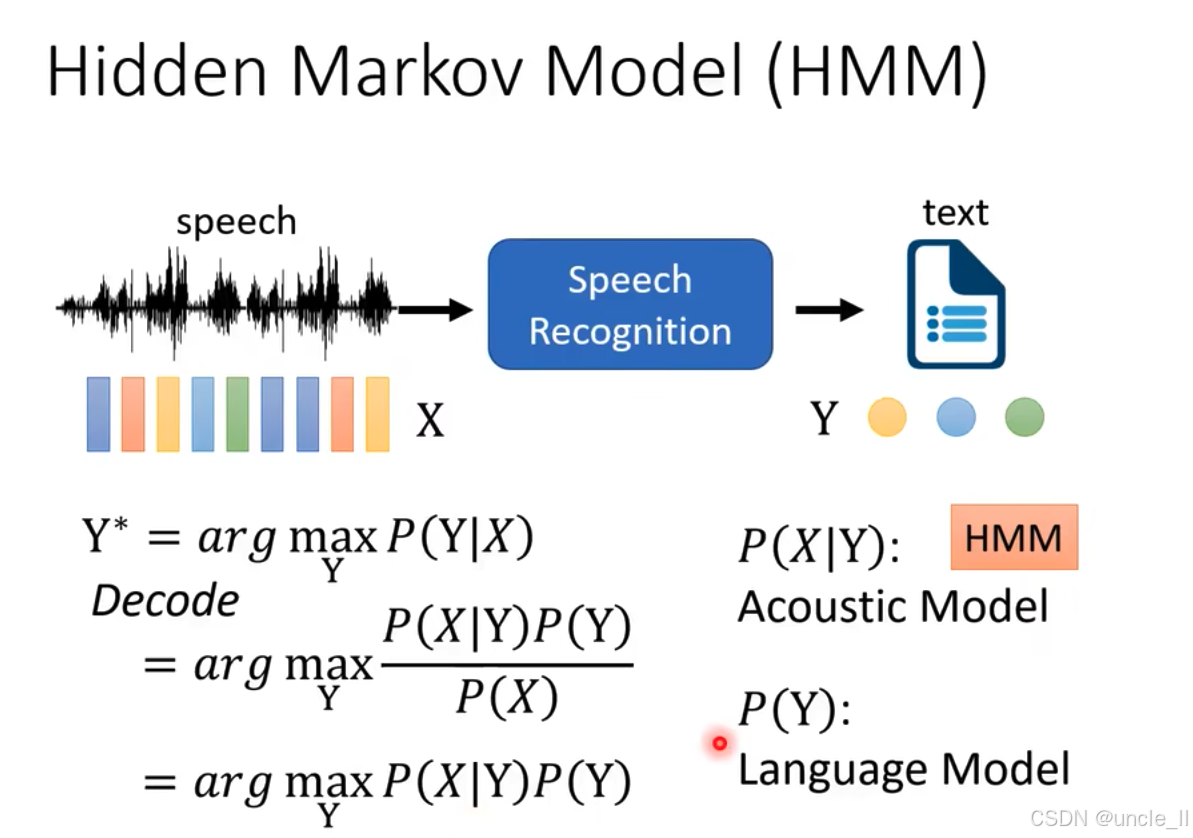
隐马尔可夫模型(HMM)在语音识别中的应用,具体内容如下:
-
整体流程:
- 左侧为语音信号(标记为 "speech"),其特征表示为 X X X。
- 中间蓝色模块 "Speech Recognition" 表示语音识别系统。
- 右侧为目标文本(标记为 "text"),其序列表示为 Y Y Y。
-
公式推导:
- 语音识别的目标是找到使 P ( Y ∣ X ) P(Y|X) P(Y∣X) 最大的文本序列 Y ∗ Y^* Y∗,即 Y ∗ = arg max Y P ( Y ∣ X ) Y^* = \arg\max_Y P(Y|X) Y∗=argmaxYP(Y∣X),这一过程称为解码(Decode)。
- 根据贝叶斯公式, P ( Y ∣ X ) = P ( X ∣ Y ) P ( Y ) P ( X ) P(Y|X) = \frac{P(X|Y)P(Y)}{P(X)} P(Y∣X)=P(X)P(X∣Y)P(Y)。由于 P ( X ) P(X) P(X)对所有 Y Y Y 是常数,可简化为 Y ∗ = arg max Y P ( X ∣ Y ) P ( Y ) Y^* = \arg\max_Y P(X|Y)P(Y) Y∗=argmaxYP(X∣Y)P(Y)。
- 其中, P ( X ∣ Y ) P(X|Y) P(X∣Y)由声学模型(Acoustic Model)建模,采用 HMM(图中橙色标注);P(Y) 由语言模型(Language Model)建模,反映文本序列的概率。
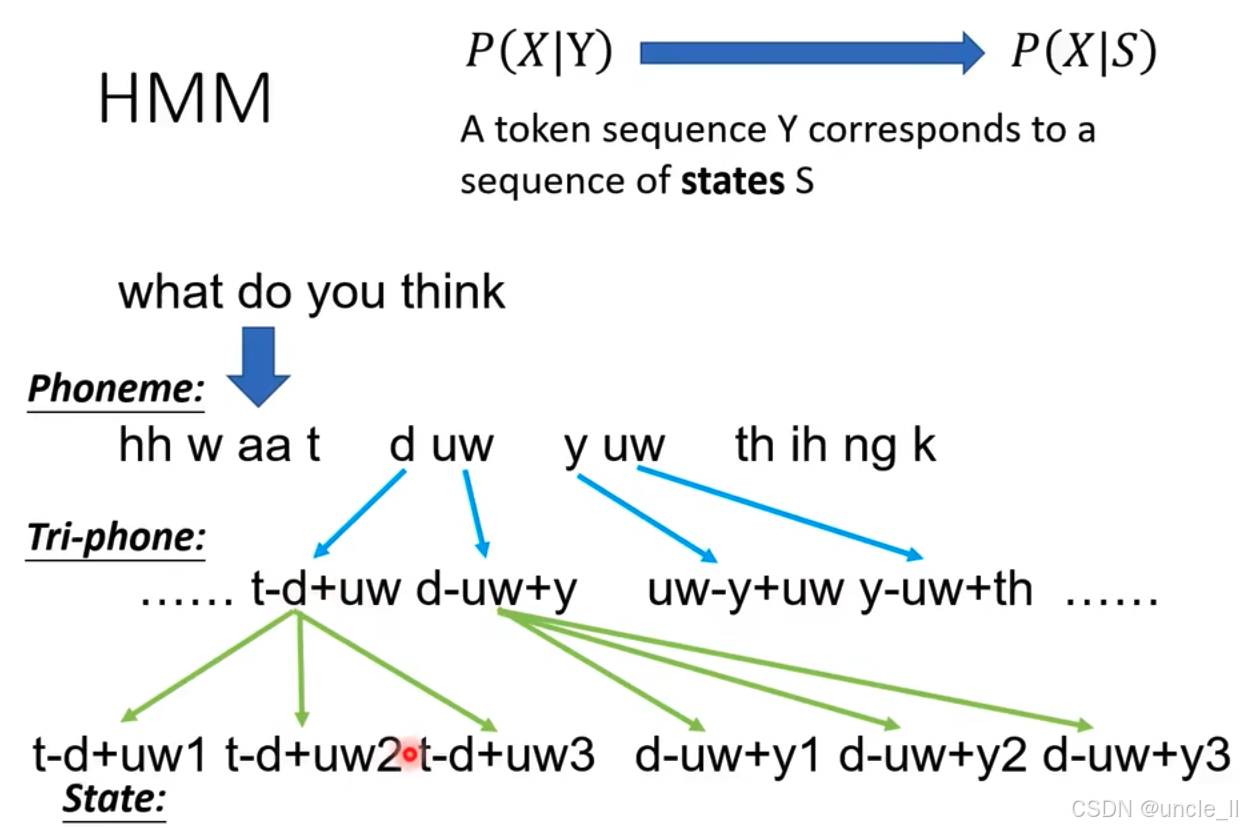
隐马尔可夫模型(HMM)在语音识别中对声学模型 P ( X ∣ Y ) P(X|Y) P(X∣Y) 的建模思路,通过引入状态序列 S S S简化建模过程,具体内容如下:
-
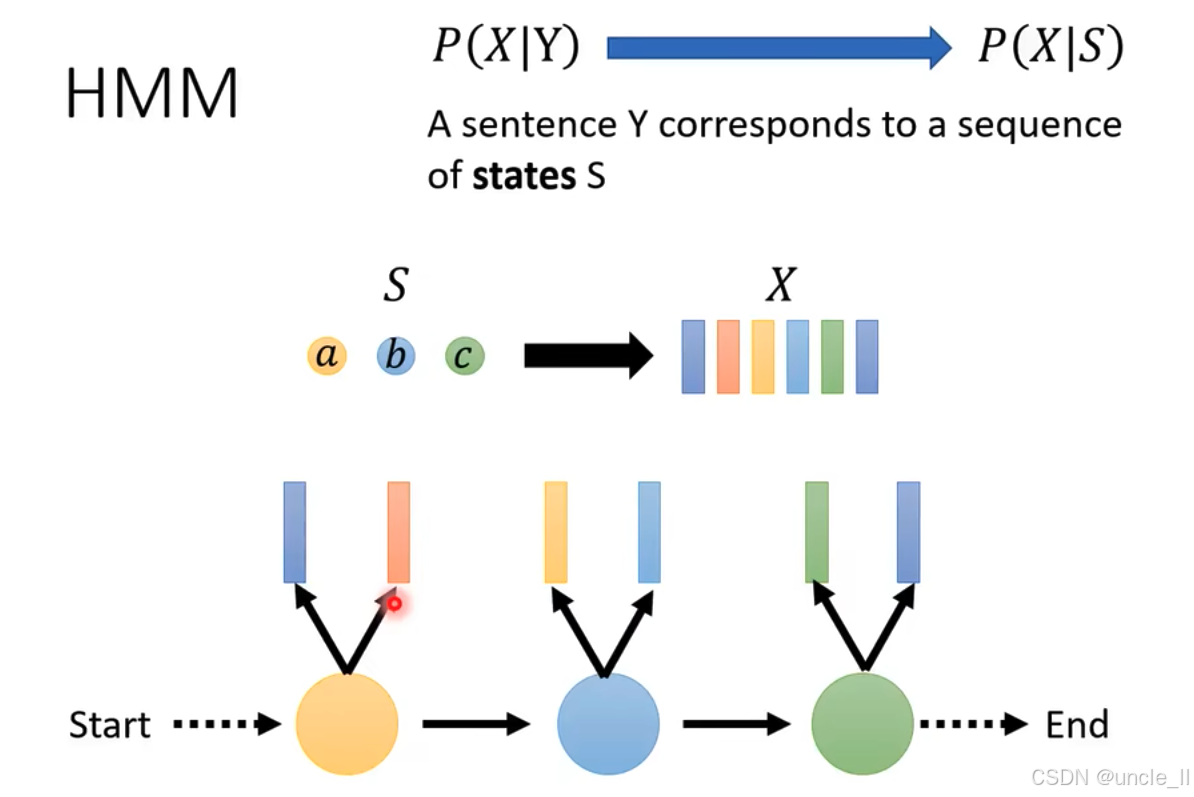
公式转换 :将 P ( X ∣ Y ) P(X|Y) P(X∣Y)(基于文本序列 Y Y Y 的声学概率)转换为 P ( X ∣ S ) P(X|S) P(X∣S)(基于状态序列 S S S 的声学概率),并说明一个文本序列 Y Y Y 对应一个状态序列 S S S。
-
语音分解示例:
- 音素(Phoneme) :句子 "what do you think" 被分解为音素序列: hh w aa t \text{hh w aa t} hh w aa t、 d uw \text{d uw} d uw、 y uw \text{y uw} y uw、 th ih ng k \text{th ih ng k} th ih ng k。
- 三音素(Tri - phone) :考虑音素的上下文关系,进一步形成三音素,如 t - d + uw \text{t - d + uw} t - d + uw、 d - uw + y \text{d - uw + y} d - uw + y、 uw - y + uw \text{uw - y + uw} uw - y + uw、 y - uw + th \text{y - uw + th} y - uw + th 等。
- 状态(State) :每个三音素再细分为不同的状态(如 t - d + uw1 \text{t - d + uw1} t - d + uw1、 t - d + uw2 \text{t - d + uw2} t - d + uw2、 d - uw + y1 \text{d - uw + y1} d - uw + y1 等),通过这些状态序列 S S S建模声学概率 P ( X ∣ S ) P(X|S) P(X∣S),更细致地描述语音特征与变化。
通过这种分层分解(文本 → 音素 → 三音素 → 状态),HMM 将复杂的语音信号 X X X与文本 Y Y Y的关系,转化为基于状态序列 S S S 的概率建模,从而有效解决语音识别中的声学建模问题。
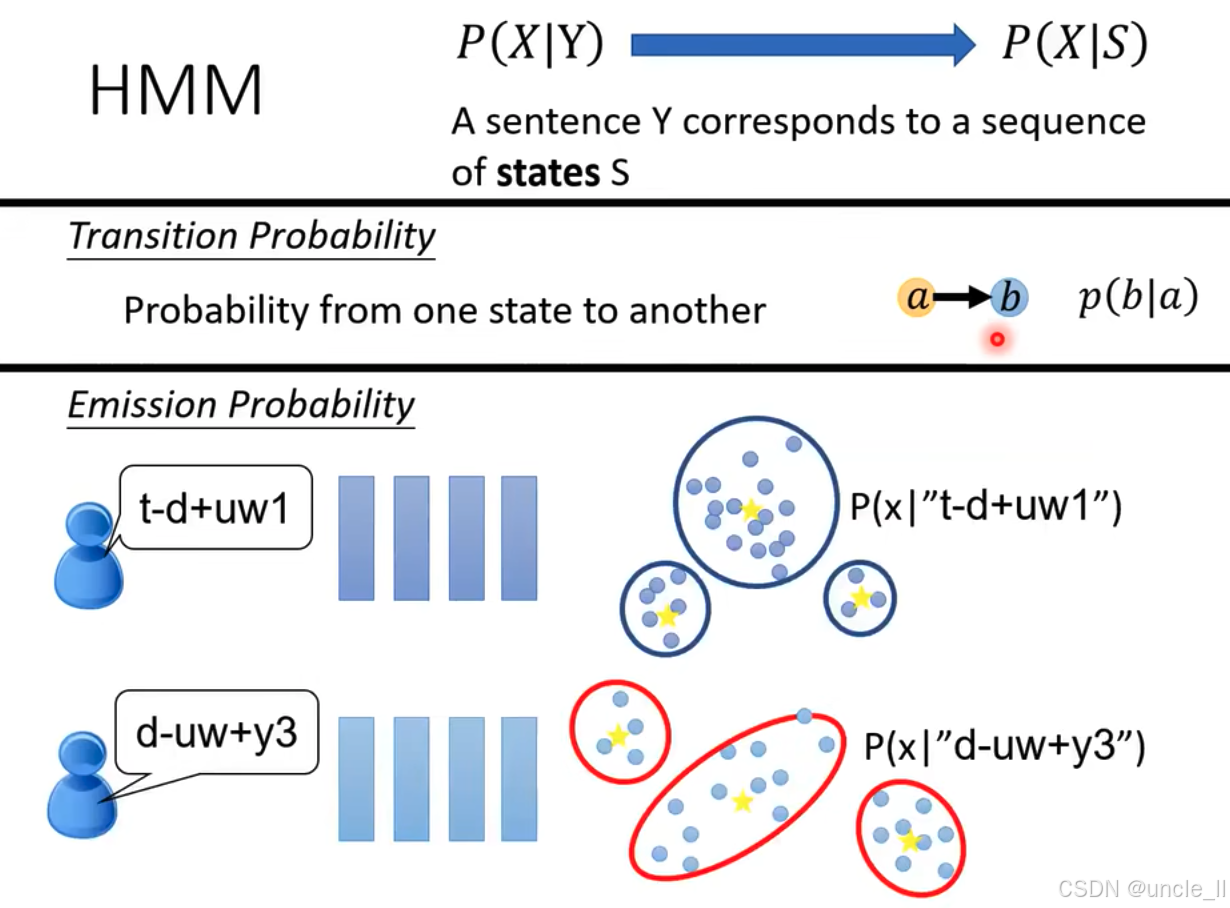 隐马尔可夫模型(HMM)中的两个关键概率:
隐马尔可夫模型(HMM)中的两个关键概率:
-
转移概率(Transition Probability):
- 定义为从一个状态转移到另一个状态的概率,图中以 a → b a \to b a→b 为例,标记为 p ( b ∣ a ) p(b|a) p(b∣a),体现了状态间的动态转移关系。
-
发射概率(Emission Probability):
- 表示某个状态生成特定观测值的概率。图中以状态 " t - d + u w 1 t\text{-}d\text{+}uw1 t-d+uw1" 和 " d - u w + y 3 d\text{-}uw\text{+}y3 d-uw+y3" 为例,右侧的蓝色竖条代表观测值,不同颜色的圈(如蓝色圈对应 " t - d + u w 1 t\text{-}d\text{+}uw1 t-d+uw1",红色圈对应 " d - u w + y 3 d\text{-}uw\text{+}y3 d-uw+y3")表示各状态下观测值的概率分布,标注 P ( x ∣ " t - d + u w 1 " ) P(x| "t\text{-}d\text{+}uw1") P(x∣"t-d+uw1")、 P ( x ∣ " d - u w + y 3 " ) P(x| "d\text{-}uw\text{+}y3") P(x∣"d-uw+y3"),体现了每个状态生成观测值的概率特性。 假设每个声音都有一个固定的发音。
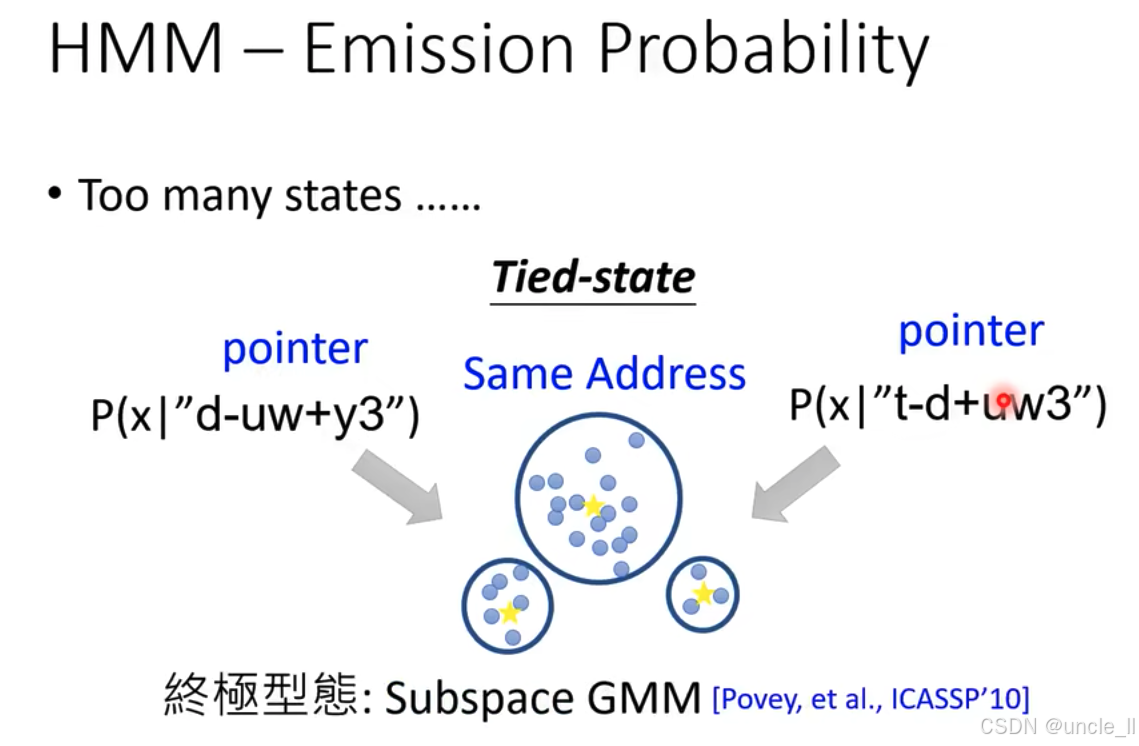 隐马尔可夫模型(HMM)中发射概率(Emission Probability)的相关内容,针对状态过多的问题提出了解决方案:
隐马尔可夫模型(HMM)中发射概率(Emission Probability)的相关内容,针对状态过多的问题提出了解决方案:
- 状态过多的挑战HMM 中状态数量可能极为庞大,直接计算每个状态的发射概率会导致参数过多、计算复杂。
- 状态绑定(Tied - state) :引入 "Tied - state" 概念,通过让不同状态共享相同的发射概率分布(图中显示不同指针指向 "Same Address"),减少参数数量,简化计算。例如,状态 " d - u w + y 3 d\text{-}uw\text{+}y3 d-uw+y3" 和 " t - d + u w 3 t\text{-}d\text{+}uw3 t-d+uw3" 共享同一发射概率分布。
- 子空间高斯混合模型(Subspace GMM):Subspace GMM Povey, et al., ICASSP'10",表明最终采用子空间 GMM 建模发射概率。高斯混合模型(GMM)通过混合多个高斯分布拟合观测数据分布,子空间 GMM 在此基础上利用子空间方法优化,进一步减少参数,提升模型效率与可管理性。
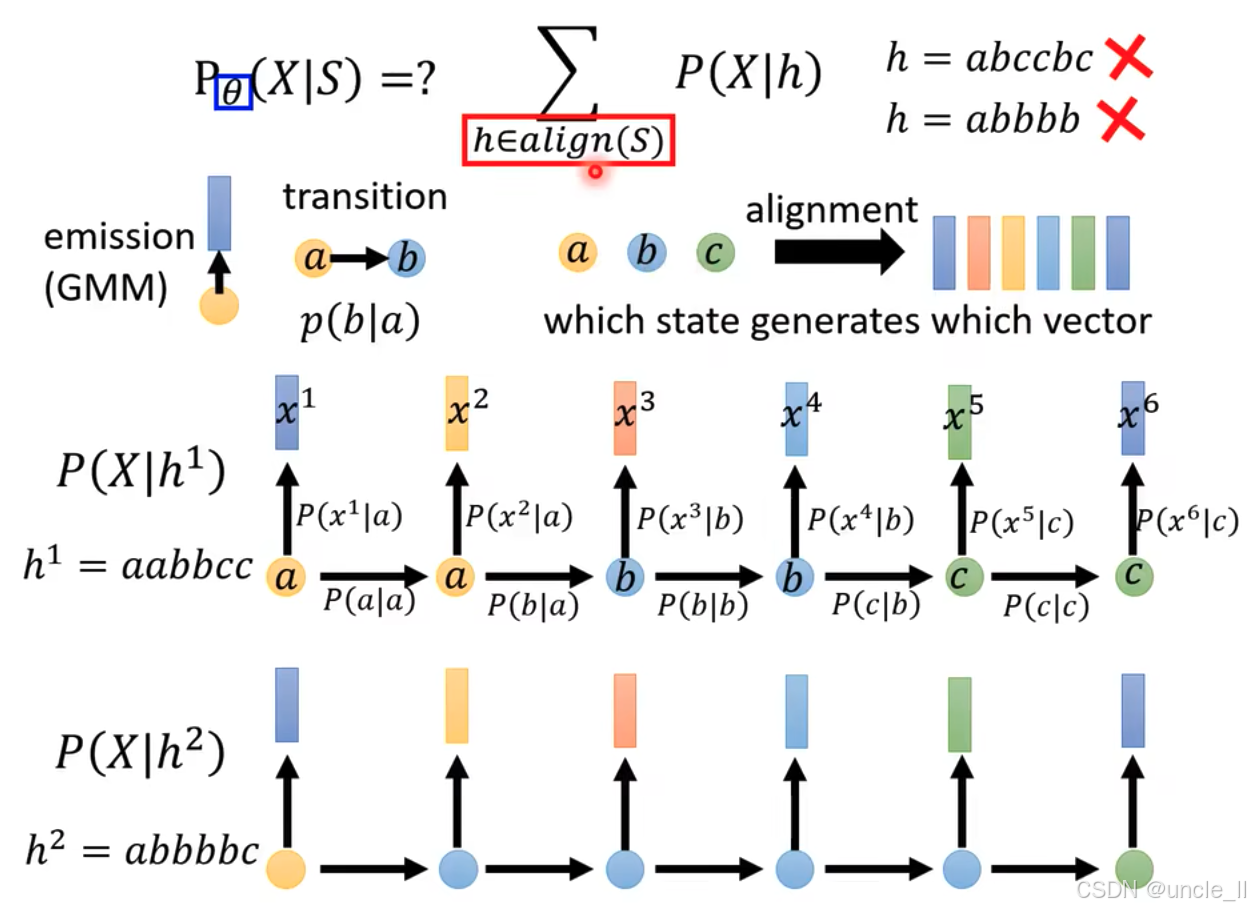
隐马尔可夫模型(HMM)中计算 P θ ( X ∣ S ) P_{\theta}(X|S) Pθ(X∣S)(给定状态序列 S S S 时观测序列 X X X的概率)的过程,核心是对所有有效对齐路径 h h h 求和,具体内容如下:
- 公式与对齐 :
- 公式 P θ ( X ∣ S ) = ∑ h ∈ a l i g n ( S ) P ( X ∣ h ) P_{\theta}(X|S) = \sum_{h \in align(S)} P(X|h) Pθ(X∣S)=∑h∈align(S)P(X∣h) 表示通过对状态序列 S S S 的所有有效对齐路径 h h h 求和来计算 P θ ( X ∣ S ) P_{\theta}(X|S) Pθ(X∣S)。图中 h = a b c c b c h = abccbc h=abccbc和 h = a b b b b b h = abbbbb h=abbbbb被叉除,表明这些对齐路径不符合要求。
- "alignment" 指状态与观测向量的对应关系,即 "which state generates which vector"(哪个状态生成哪个向量)。
- 发射与转移概率 :
- Emission (GMM) :发射概率使用高斯混合模型(GMM)建模,如 P ( x 1 ∣ a ) P(x^1|a) P(x1∣a) 表示状态 a a a 生成观测 x 1 x^1 x1 的概率。
- Transition :状态转移概率 p ( b ∣ a ) p(b|a) p(b∣a) 表示从状态 a a a 转移到状态 b b b的概率。
- 示例计算 :
- h 1 = a a b b c c h^1 = aabbcc h1=aabbcc:状态序列为 a → a → b → b → c → c a \to a \to b \to b \to c \to c a→a→b→b→c→c,计算 P ( X ∣ h 1 ) P(X|h^1) P(X∣h1) 时,需依次乘以各状态的发射概率 P ( x i ∣ 对应状态 ) P(x^i| \text{对应状态}) P(xi∣对应状态) 和状态转移概率 P ( 下一状态 ∣ 当前状态 ) P(\text{下一状态} | \text{当前状态}) P(下一状态∣当前状态),如 P ( a ∣ a ) × P ( x 1 ∣ a ) × P ( b ∣ a ) × P ( x 2 ∣ a ) × ⋯ P(a|a) \times P(x^1|a) \times P(b|a) \times P(x^2|a) \times \cdots P(a∣a)×P(x1∣a)×P(b∣a)×P(x2∣a)×⋯。
- h 2 = a b b b b b c h^2 = abbbbbc h2=abbbbbc:展示另一种对齐路径的概率计算方式,同样结合发射与转移概率。
DeepLearning方法
Tandem
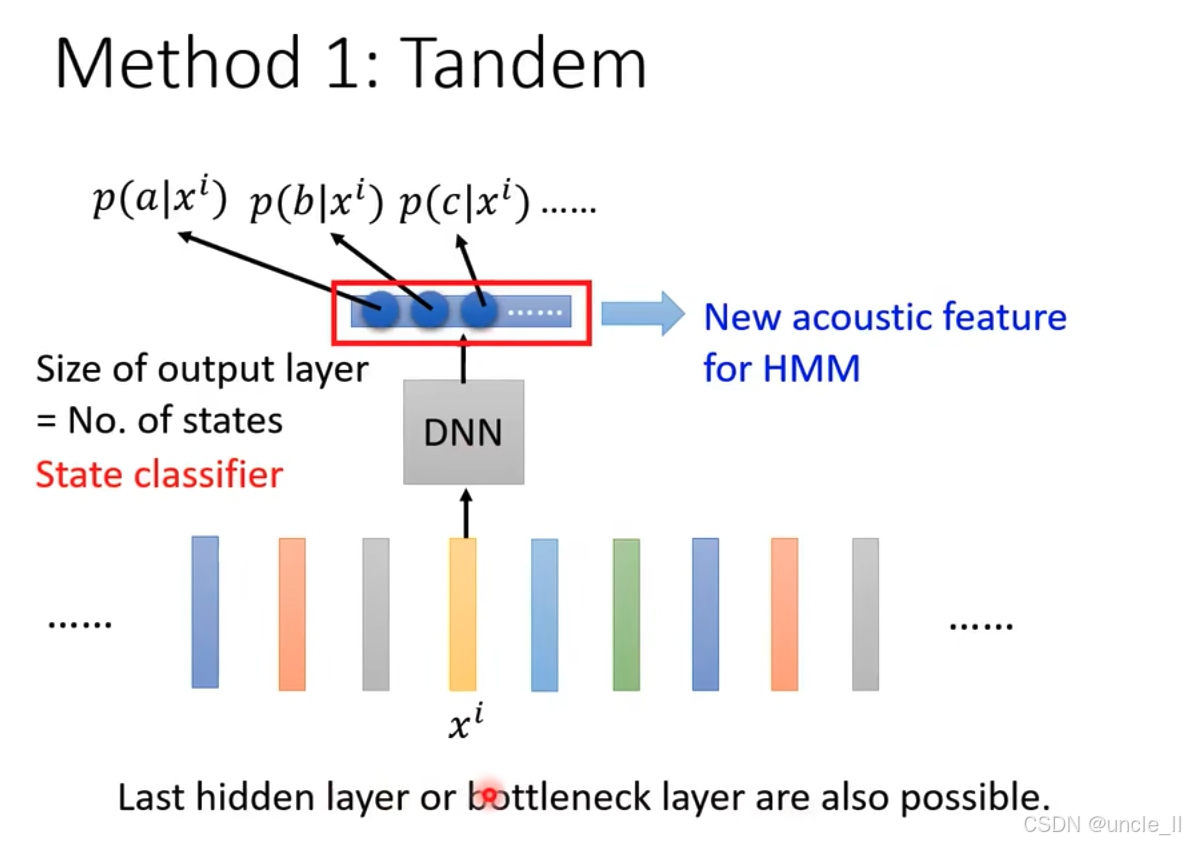 Tandem 方法,其核心是利用深度神经网络(DNN)为隐马尔可夫模型(HMM)生成新的声学特征,具体内容如下:
Tandem 方法,其核心是利用深度神经网络(DNN)为隐马尔可夫模型(HMM)生成新的声学特征,具体内容如下:
- DNN 作为状态分类器 :
- 输入特征 x i x^i xi被输入到 DNN 中。
- DNN 的输出层大小等于 HMM 中的状态数("Size of output layer = No. of states"),每个输出节点对应一个状态的后验概率(如 p ( a ∣ x i ) p(a|x^i) p(a∣xi)、 p ( b ∣ x i ) p(b|x^i) p(b∣xi)、 p ( c ∣ x i ) p(c|x^i) p(c∣xi)等),因此 DNN 充当 "State classifier"(状态分类器)。
- 生成新声学特征 :
- DNN 输出的状态后验概率被作为 "New acoustic feature for HMM"(HMM 的新声学特征),用于改进 HMM 的声学建模。
- 灵活的特征提取层 :
- 除了输出层,DNN 的最后隐藏层或瓶颈层的输出也可作为声学特征,增加了方法的灵活性。
DNN-HMM Hybrid
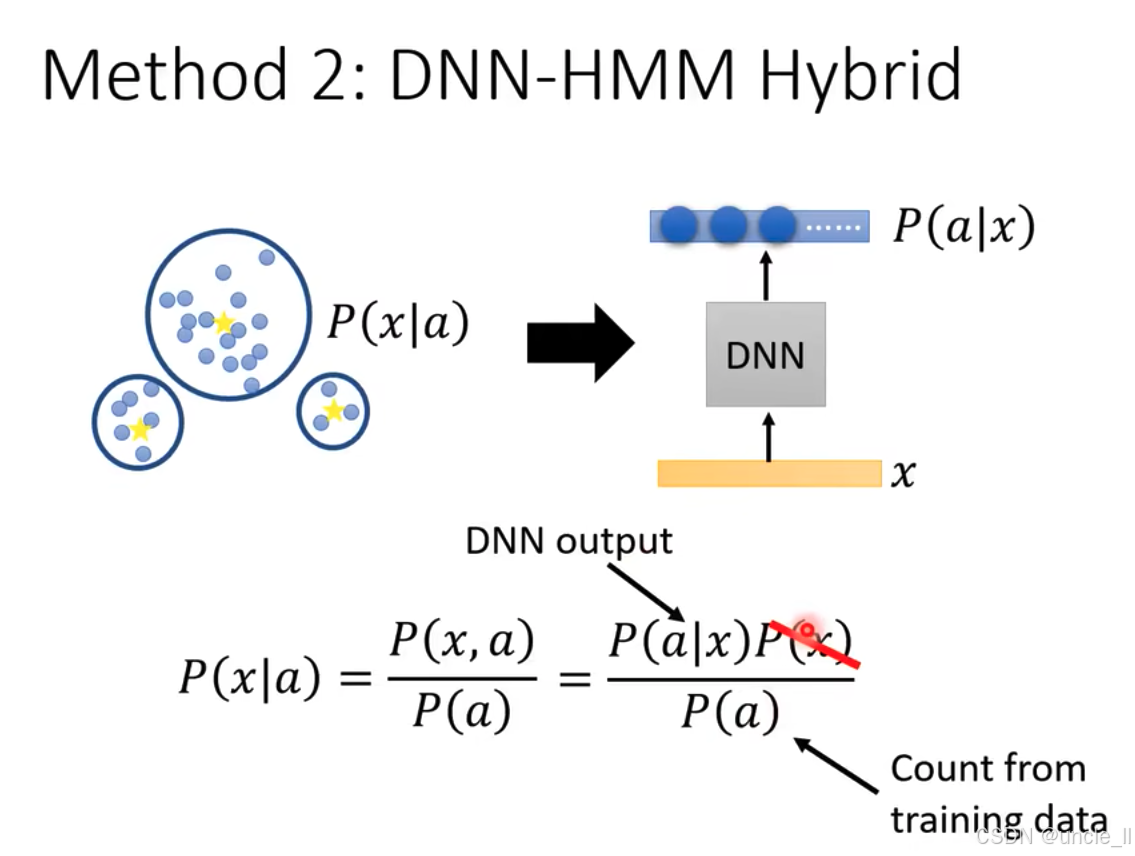 DNN - HMM Hybrid(深度神经网络 - 隐马尔可夫模型混合) 方法,核心是利用深度神经网络(DNN)改进隐马尔可夫模型(HMM)的发射概率 P ( x ∣ a ) P(x|a) P(x∣a),具体内容如下:
DNN - HMM Hybrid(深度神经网络 - 隐马尔可夫模型混合) 方法,核心是利用深度神经网络(DNN)改进隐马尔可夫模型(HMM)的发射概率 P ( x ∣ a ) P(x|a) P(x∣a),具体内容如下:
- 传统 HMM 的发射概率 :左侧用高斯混合模型(GMM)表示 P ( x ∣ a ) P(x|a) P(x∣a)(状态 a a a生成观测 x x x 的概率),通过多个高斯分布拟合数据。
- DNN 的作用 :右侧DNN 输入语音特征 x x x,输出状态后验概率 P ( a ∣ x ) P(a|x) P(a∣x)。
- 公式推导 :
- 根据概率公式 P ( x ∣ a ) = P ( x , a ) P ( a ) = P ( a ∣ x ) P ( x ) P ( a ) P(x|a) = \frac{P(x, a)}{P(a)} = \frac{P(a|x)P(x)}{P(a)} P(x∣a)=P(a)P(x,a)=P(a)P(a∣x)P(x)。由于 P ( x ) P(x) P(x)在比较不同状态 a a a 时是常数,可忽略,因此 P ( x ∣ a ) P(x|a) P(x∣a) 可通过 P ( a ∣ x ) P ( a ) \frac{P(a|x)}{P(a)} P(a)P(a∣x) 近似,其中 P ( a ) P(a) P(a)从训练数据中统计得到。
- 这种方法利用 DNN 直接预测 P ( a ∣ x ) P(a|x) P(a∣x),替代传统 GMM 对 P ( x ∣ a ) P(x|a) P(x∣a) 的建模,简化计算并提升声学建模能力。
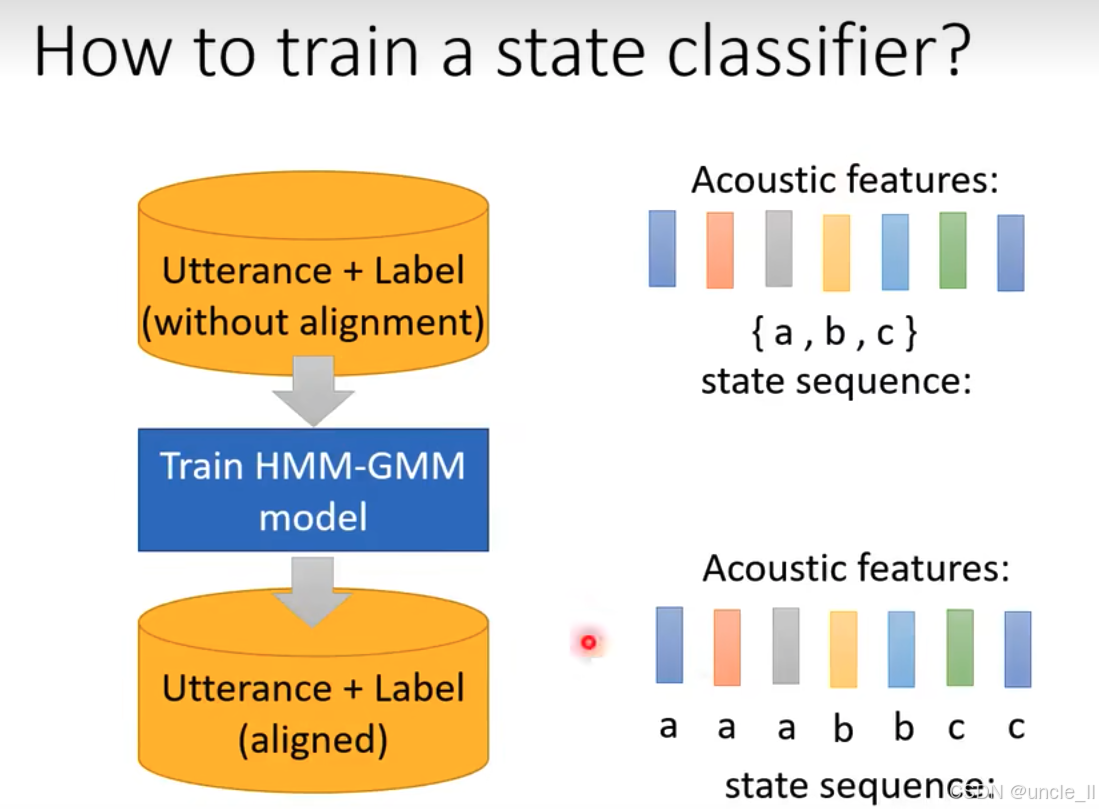
训练状态分类器的前期准备流程,具体如下:
- 输入未对齐数据:最上方的橙色圆柱表示输入 "Utterance + Label (without alignment)"(未对齐的话语和标签),即仅有语音特征(声学特征)和文本标签,但语音与标签未精确对齐。
- 训练 HMM - GMM 模型:通过蓝色模块 "Train HMM - GMM model" 训练隐马尔可夫 - 高斯混合模型。该模型利用无对齐的语音和标签数据,学习状态转移概率和发射概率(如通过 EM 算法),进而对语音进行对齐。
- 输出对齐数据 :下方橙色圆柱表示输出 "Utterance + Label (aligned)"(对齐后的话语和标签)。经过 HMM - GMM 模型处理后,每个声学特征都与具体状态(如 a , b , c a, b, c a,b,c)精确对齐(例如声学特征序列对应 a , a , a , b , b , c , c a, a, a, b, b, c, c a,a,a,b,b,c,c 的状态序列)。
该流程通过 HMM - GMM 模型将无对齐的语音和标签转化为对齐数据,为后续训练状态分类器(如 DNN)提供了带精确标注(状态标签)的训练数据,使分类器能根据声学特征准确预测对应状态。
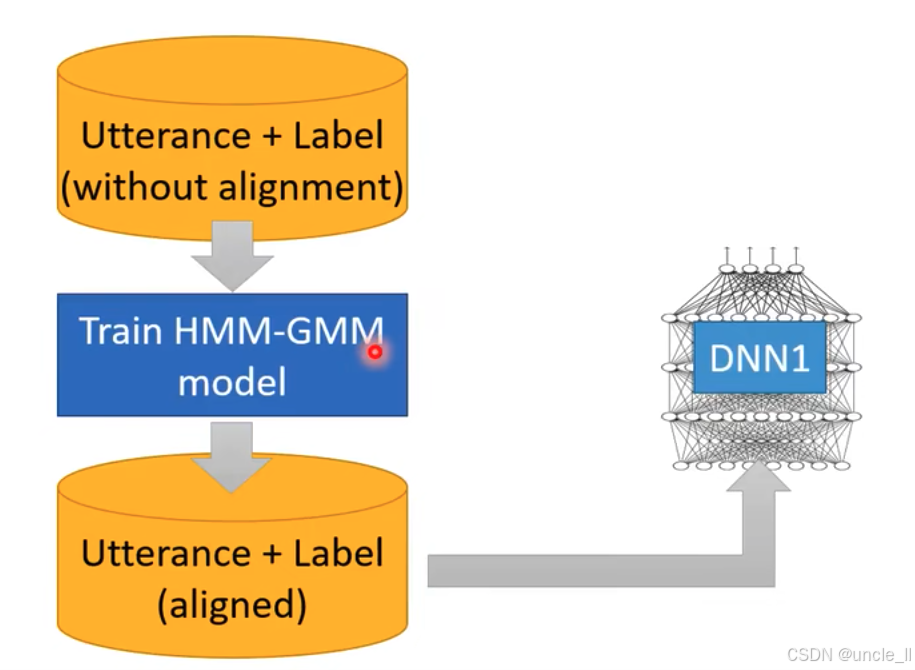
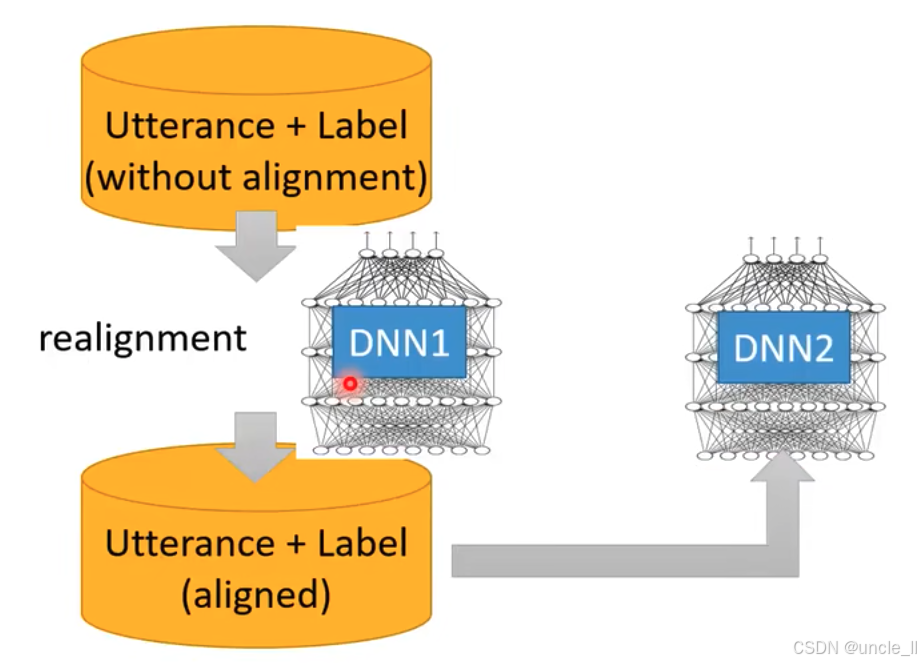
训练状态分类器的迭代优化流程,具体如下:
-
初始对齐阶段:
- 最上方的 "Utterance + Label (without alignment)" 表示输入未对齐的语音话语和标签。
- 通过 "Train HMM - GMM model" 模块训练隐马尔可夫 - 高斯混合模型(HMM - GMM),该模型对未对齐数据进行处理,输出 "Utterance + Label (aligned)",即语音与标签精确对齐的数据。
-
DNN 初步训练与重新对齐:
- 对齐后的数据输入到 DNN1 中,用于初步训练状态分类器。
- 利用 DNN1 的输出对数据进行 "realignment"(重新对齐),得到更优化的对齐数据。
-
DNN 迭代优化训练:
- 重新对齐后的数据输入到 DNN2 中,进一步训练状态分类器。这种迭代过程通过 HMM - GMM 与 DNN 的交互,逐步优化语音 - 标签对齐效果和状态分类器的性能,提升模型对声学特征与状态对应关系的学习能力。
该流程体现了利用传统 HMM - GMM 与深度神经网络(DNN)结合,通过迭代对齐和训练,优化状态分类器的过程,是语音识别中常见的模型训练策略。

通过上述方法达到人类水平!
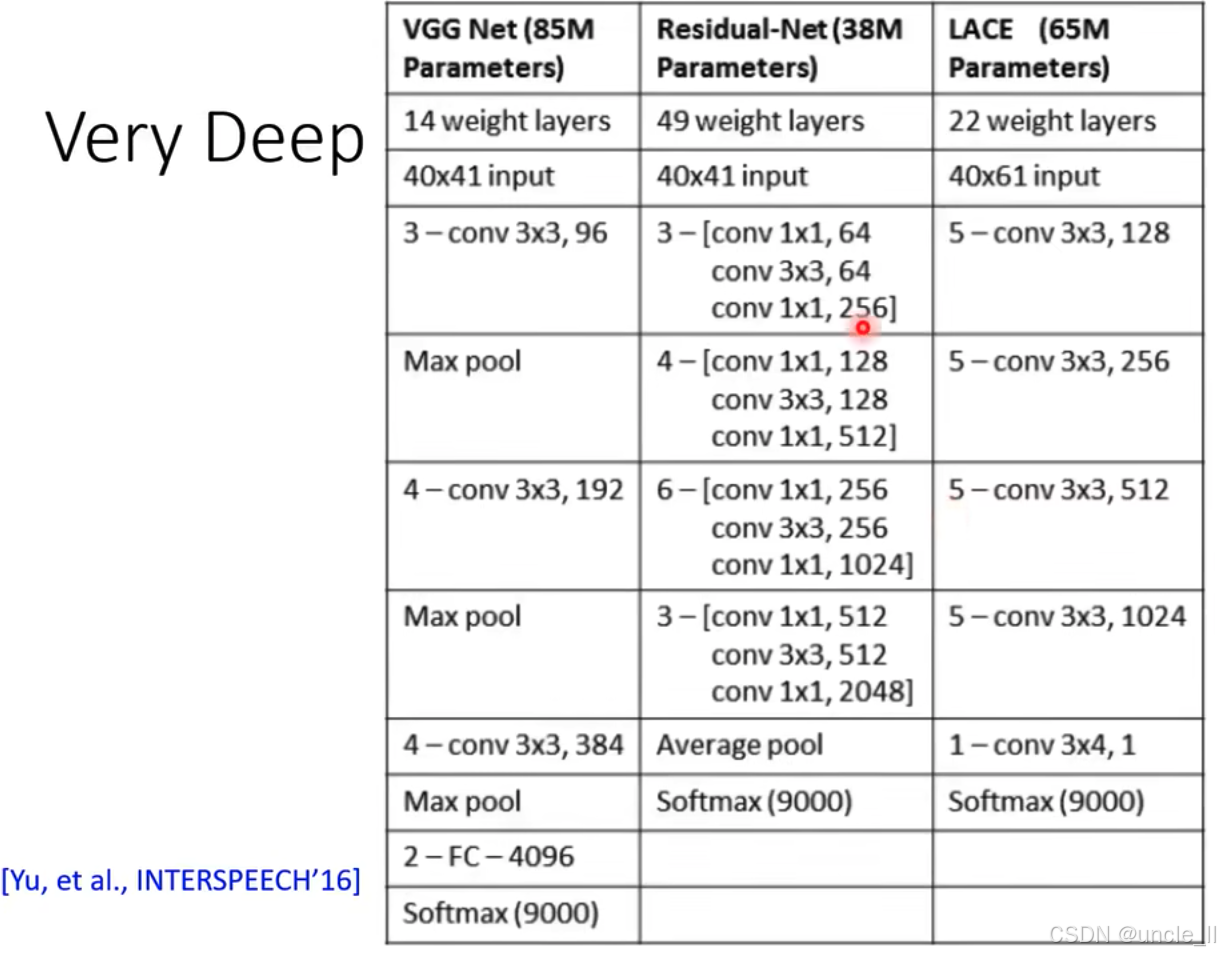
微软用了49层神经网络