目录
[为什么需要 Cache?](#为什么需要 Cache?)
[🧱 Cache 的分层设计](#🧱 Cache 的分层设计)
[🔹 Level 1 Cache(L1 Cache)一级缓存](#🔹 Level 1 Cache(L1 Cache)一级缓存)
[🔹 Level 2 Cache(L2 Cache)二级缓存](#🔹 Level 2 Cache(L2 Cache)二级缓存)
[🔹 Level 3 Cache(L3 Cache)三级缓存](#🔹 Level 3 Cache(L3 Cache)三级缓存)
[Cache 的运行机制](#Cache 的运行机制)
[🔄 CPU 核心数量与 Cache 的关系](#🔄 CPU 核心数量与 Cache 的关系)
[🔎 Cache 相关术语(Cache-related Terms)](#🔎 Cache 相关术语(Cache-related Terms))
[🧠 引用的局部性( Locality of Reference)](#🧠 引用的局部性( Locality of Reference))
[1️⃣ 时间局部性(Temporal Locality)](#1️⃣ 时间局部性(Temporal Locality))
[2️⃣ 空间局部性(Spatial Locality)](#2️⃣ 空间局部性(Spatial Locality))
为什么需要 Cache?
想象你在玩一个 100GB 的大型 3D 开放世界游戏,比如《赛博朋克 2077》或《原神》。
这个游戏包含:
-
成千上万张地图贴图;
-
数百个角色模型;
你可能会想:
我们不能把所有代码都放在主存里吗?
从第一性原理看,这个问题非常自然。我们来分析一下背后的限制:
💡 为什么不能把整个游戏都放进主存?
原因一:主存容量有限
-
游戏是按需加载的,因为大部分内容你"当前并不会用到"。
-
比如你现在在城市区域,森林那部分地图用不到,加载了反而浪费空间。
原因二:主存速度不够快
-
CPU 执行速度以纳秒为单位,而主存(通常是 DRAM)访问延迟达几十甚至上百纳秒。
-
如果 CPU 每执行一条指令就等几十纳秒,那执行效率会非常低。
这就引出了我们今天的主角:
Cache(缓存) :一种高速小容量的临时存储区域,用于存放"最近正在用"或"即将用到"的数据,让 CPU 不用一直等主存。
🧱 Cache 的分层设计
💡从第一性原理出发:
我们知道,Cache 的设计目标是解决 CPU 和主存(DRAM)之间巨大的速度差。
| 元件 | 速度(延迟) |
|---|---|
| CPU(寄存器) | <1 ns |
| L1 Cache | 1--2 ns |
| L2 Cache | ~5 ns |
| L3 Cache | 10--20 ns |
| 主存 DRAM | 50--100 ns |
你可以看到,主存的访问时间是 L1 Cache 的几十倍。为了缩小这个"速度鸿沟",我们引入了多级缓存(Multilevel Cache Architecture):
🔹 Level 1 Cache(L1 Cache)一级缓存
-
位置:直接嵌入在 CPU 核心内部,与执行单元关系最紧密。
-
速度:最快,通常只有 1--2 个 CPU 时钟周期的延迟。
-
大小:非常小(一般为 16KB--64KB),分为:
-
L1I(指令缓存,Instruction Cache)
-
L1D(数据缓存,Data Cache)
-
为什么分为 I/D?
从第一性原理看:
CPU 在执行程序时,"取指"和"取数据"是两条并行路径,如果混在一起会互相干扰。
🔹 Level 2 Cache(L2 Cache)二级缓存
-
位置:仍在 CPU 核心附近,但通常不嵌入执行单元。
-
大小:较大(128KB--1MB),统一存储指令和数据。
-
速度:比 L1 慢,但比主存快,通常延迟在 5--15 个周期之间。
功能:
弥补 L1 空间不足的问题,把 L1 Cache Miss 的数据"接住"。
🔹 Level 3 Cache(L3 Cache)三级缓存
-
位置:多个核心之间共享的缓存,不再是每个核心私有。
-
大小:大(2MB--几十 MB)
-
速度:相对较慢,但比主存快得多。
设计目的:
为多个核心之间的数据共享提供"中转站"。
层级结构图示(逻辑上):
CPU Core
/ | \
L1I L1D -> L2
\______/
↓
L3 (共享)
↓
Main Memory| 层级 | 中文名 | 主要作用 | 特点 | 与 CPU 距离 |
|---|---|---|---|---|
| L1 Cache | 一级缓存 | 执行级加速,紧贴指令和数据 | 最小(16~64KB),最快(1ns) | 嵌在每个 CPU 核内部 |
| L2 Cache | 二级缓存 | 衔接 L1 和 L3,扩大命中率 | 中等大小(256KB~1MB),速度快 | 通常也是每核私有 |
| L3 Cache | 三级缓存 | 跨核心共享、减少主存访问 | 最大(2MB~64MB),最慢但仍比 RAM 快 | 多核之间共享 |
这套结构就像一个数据"梯子":
-
越靠近 CPU,越快,但越小;
-
越远,越大,但越慢。
🧠 从第一性原理讲:
越靠近 CPU 的缓存必须越小越快,以匹配 CPU 的指令节奏;而越远的缓存可以稍慢,但容量要大些,用于存放更多数据。
Cache 的运行机制
我们以 CPU 执行一条指令为例,看看 Cache 是怎么参与工作的:
**步骤一:**CPU 需要一个数据(比如变量 x)
CPU 发出一个"内存读取请求":我要取地址 0x1000 的值。
**步骤二:**先查 L1 Cache(一级缓存)
-
L1 是最小但最快的缓存(通常在 1ns 内响应)
-
CPU 立即在 L1 中查找这个地址。
如果找到了,就叫 Cache Hit(命中)
直接读取数据,立即返回!
如果没有找到,就叫 Cache Miss(未命中)
进入下一层:查 L2。
**步骤三:**L1 Miss → 查 L2 Cache(二级缓存)
-
L2 比 L1 稍远、稍大、稍慢(通常 5--15ns)。
-
如果在 L2 找到了 → 把数据送回 L1(便于下次快速访问)。
**步骤四:**L2 Miss → 查 L3 Cache(三级缓存)
-
L3 是多核共享的,容量最大,速度较慢(10--20ns 或更高)。
-
如果找到了 → 同样送回 L2 → 再写进 L1 → 最后给 CPU 用。
**步骤五:**L3 也 Miss → 去 Main Memory(主存)
-
如果三层都没命中,说明这块数据根本没在 Cache 中。
-
系统需要从主存(DRAM)加载数据(延迟可能高达 100ns)。
这就是最典型的 "缓存访问路径":
CPU → L1 → L2 → L3 → 主存🔄 CPU 核心数量与 Cache 的关系
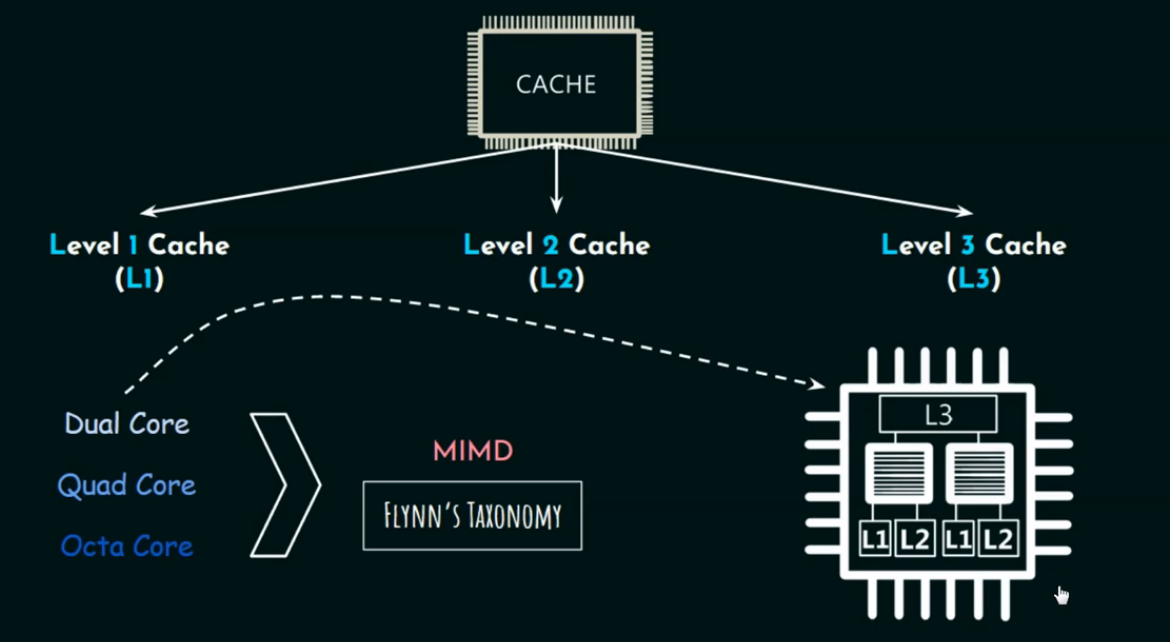
现代 CPU 通常不是单核,而是 多核结构(Multicore CPU)。
-
Dual-core(双核):2 个处理核心
-
Quad-core(四核):4 个处理核心
-
Octa-core(八核):8 个处理核心
这些术语表示CPU 中的处理核心数量。
那这些核心如何共享和配置 Cache 呢?我们来详细说说:
每个核心都拥有 自己的私有缓存(Private Cache)
| 缓存层级 | 分配方式 | 理由 |
|---|---|---|
| L1 Cache | 每个核心独立拥有 | 距离近、快速访问、不干扰其他核心 |
| L2 Cache | 大多数情况下也是私有 | 帮助每个核心缓存更多数据,防止竞争冲突 |
多个核心 共享 L3 Cache(Shared Cache)
L3 Cache 通常被设计为多核心共享的一层高速缓存。
原因:
-
可以减少重复缓存:比如多个线程访问同一个数据,不需要每个核心都复制一份。
-
提供跨核心通信的中转站。
结构示意(以四核为例):
[Core1]--L1--L2
[Core2]--L1--L2
[Core3]--L1--L2
[Core4]--L1--L2
\ | /
↘ L3 Cache ↙
↓
Main Memory这和 Cache 有什么关系?
每个核心通常有自己独立的 L1、L2 Cache,而多个核心之间会共享 L3 Cache,如下:
[Core1] --> L1/L2 --\
[Core2] --> L1/L2 ---|--> 共享 L3 Cache
[Core3] --> L1/L2 --/为什么这样设计?
从第一性原理看:
每个核心有自己的"工作空间",但也要能互相通信,所以共享 L3 是折中的办法。
这一套缓存层级 + 多核架构,最终的目标只有一个:
让 CPU 每时每刻都能有"足够快"的数据可用,最大化它的执行效率。
🔎 Cache 相关术语(Cache-related Terms)
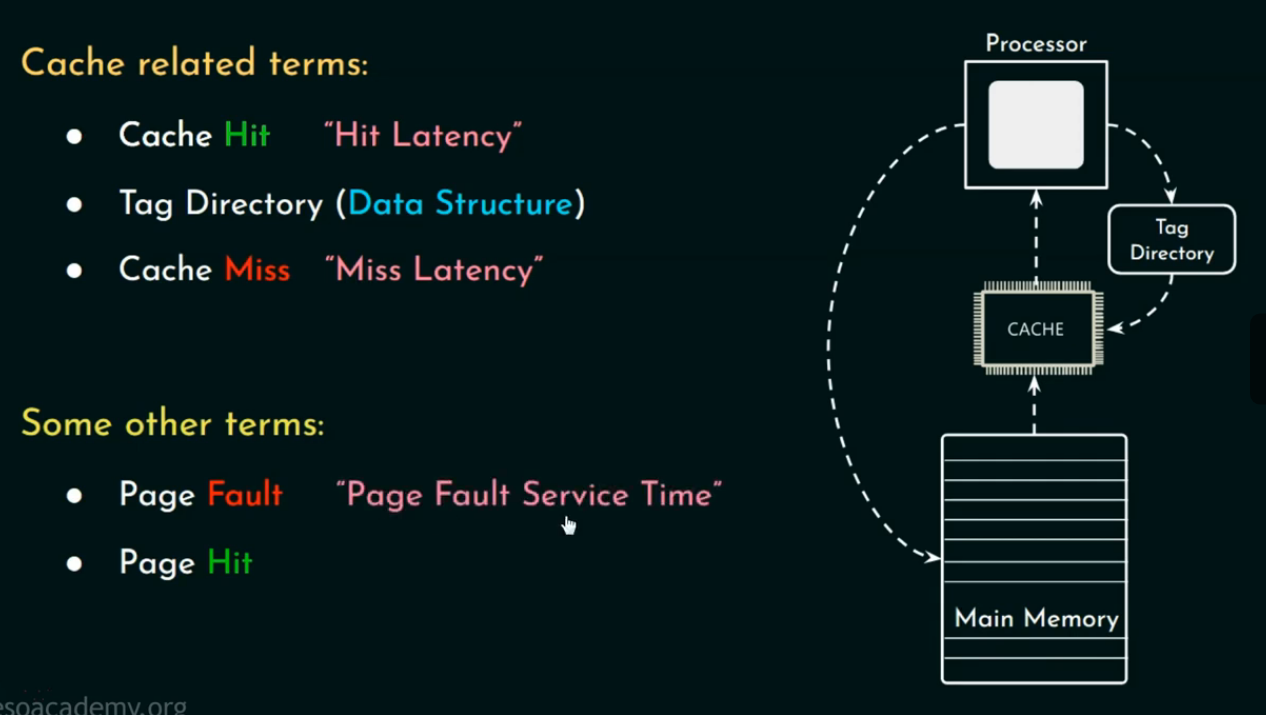
🏷️ 1. Cache Hit(缓存命中)
当 CPU 需要某个数据,而该数据已经在 Cache 中,就称为命中(Hit)。
🏷️ 2. Cache Miss(缓存未命中)
数据不在 Cache 中,CPU 需要从更下层(比如主存)去取。
Miss 会带来延迟,也叫 Miss Penalty(未命中惩罚)。
🏷️ 3. Tag Directory(标记目录)
每条 Cache 数据都会带一个"Tag",用于记录该数据来自内存的哪个位置。
Cache 查询时会通过比对 Tag 来判断是否命中。
🏷️ 4. 其他术语(补充说明):
🏷️ Page Fault(页错误)
-
当程序要访问的数据既不在 Cache,也不在主存,而是在磁盘(比如换页文件中),就会发生 Page Fault。
-
此时操作系统需要从磁盘中调入数据,成本极高。
🏷️Page Hit(页命中)
- 数据在内存页中已经存在,无需调入磁盘。
📌 注意:Page Fault / Page Hit 是虚拟内存管理里的概念,而不是 Cache 的,但它们也体现了内存的层级思想。
🧠 引用的局部性( Locality of Reference)
为什么 Cache 能提高性能?核心原理是:
程序访问数据时是有"规律"的,而不是随机的。
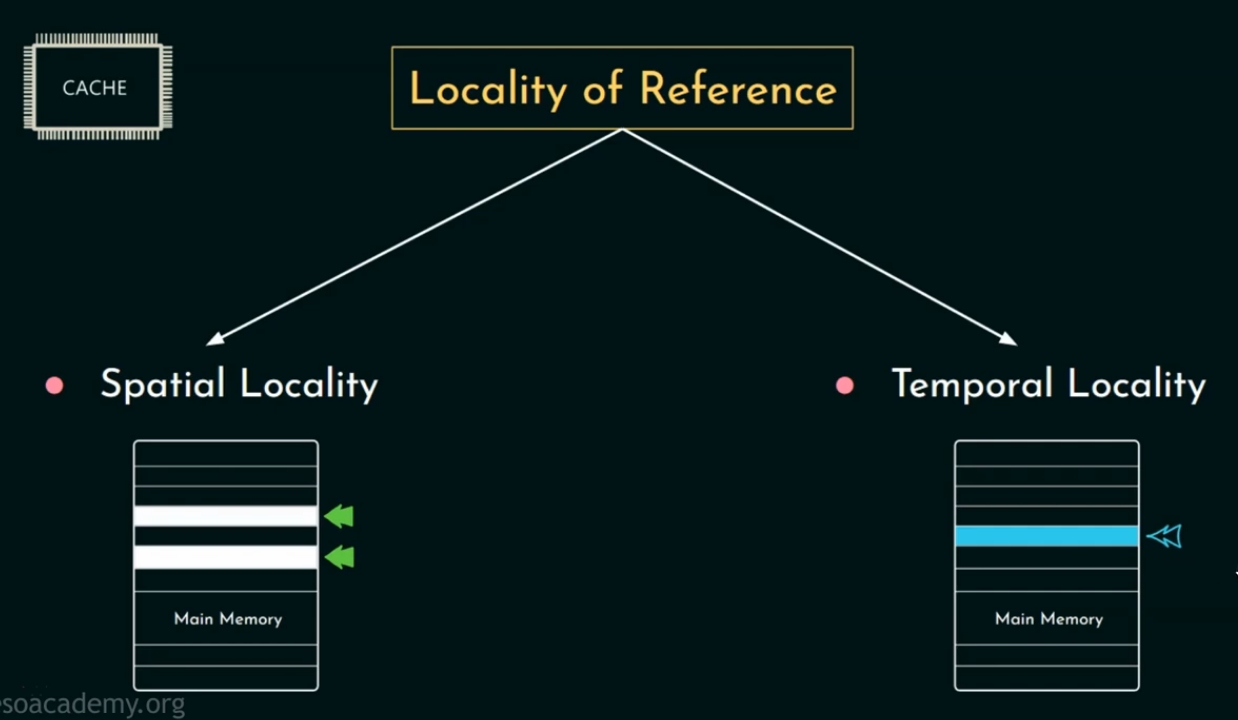
引用的局部性是指程序在访问内存时,有集中访问某些区域"的倾向。
就是说:程序不会随便乱跳着访问内存,它有"偏好":
要么访问同一块地方(空间局部性),要么短时间反复访问同样的内容(时间局部性)。
引用局部性分两种:
1️⃣ 时间局部性(Temporal Locality)
如果某个数据刚刚被访问过,很快还会再次被访问。
举例:
-
一个变量
x被频繁使用; -
一个循环不断用到数组第0项;
-
函数刚被调用,马上又调用一次。
2️⃣ 空间局部性(Spatial Locality)
如果访问了某个地址,很可能会接着访问它"附近"的地址。
举例:
-
遍历数组时会依次访问相邻的内存单元;
-
连续的结构体或局部变量通常排在栈上连续的空间。
计算机为了加快访问速度,就利用这个"局部性原理",把近期访问的数据(和它附近的数据)放到更快的缓存(Cache)里。
这样,下次再访问这些内容时就更快了。