Kafka数据源
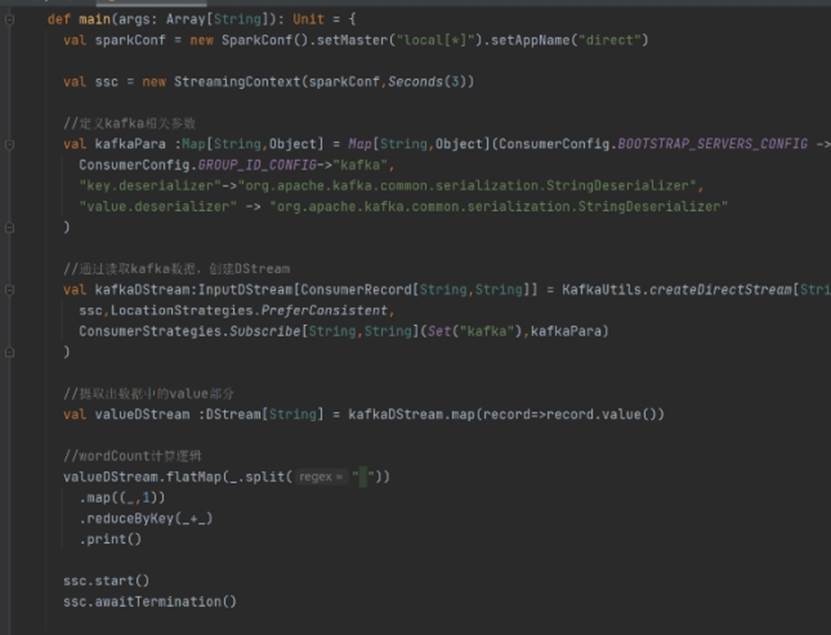
需求:通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台
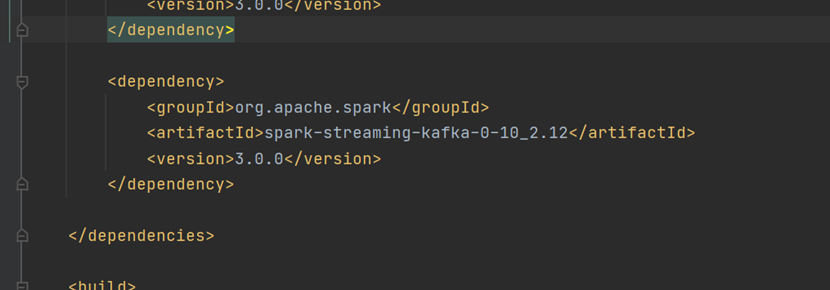
导入依赖
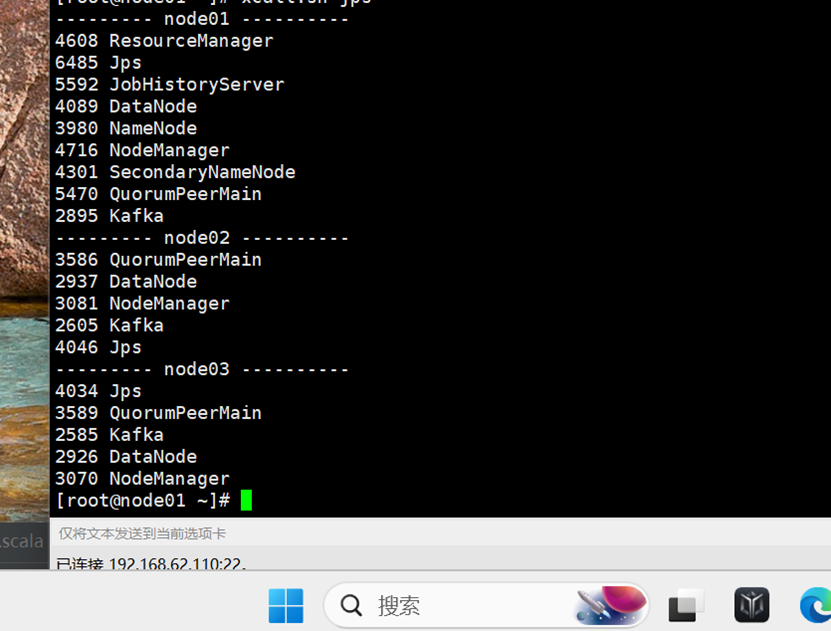
5.开启Kafka集群
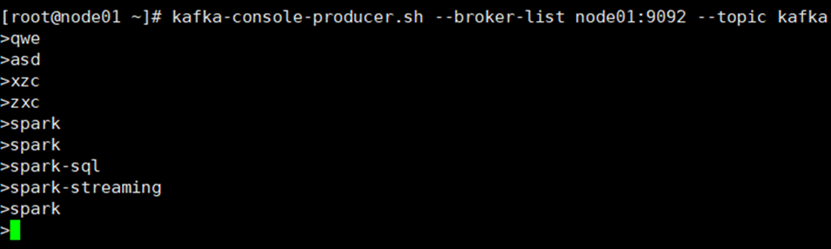
6.开启Kafka生产者,产生数据