kafka简介
Kafka就是一个分布式的用于消息存储的消息队列。
kafka角色
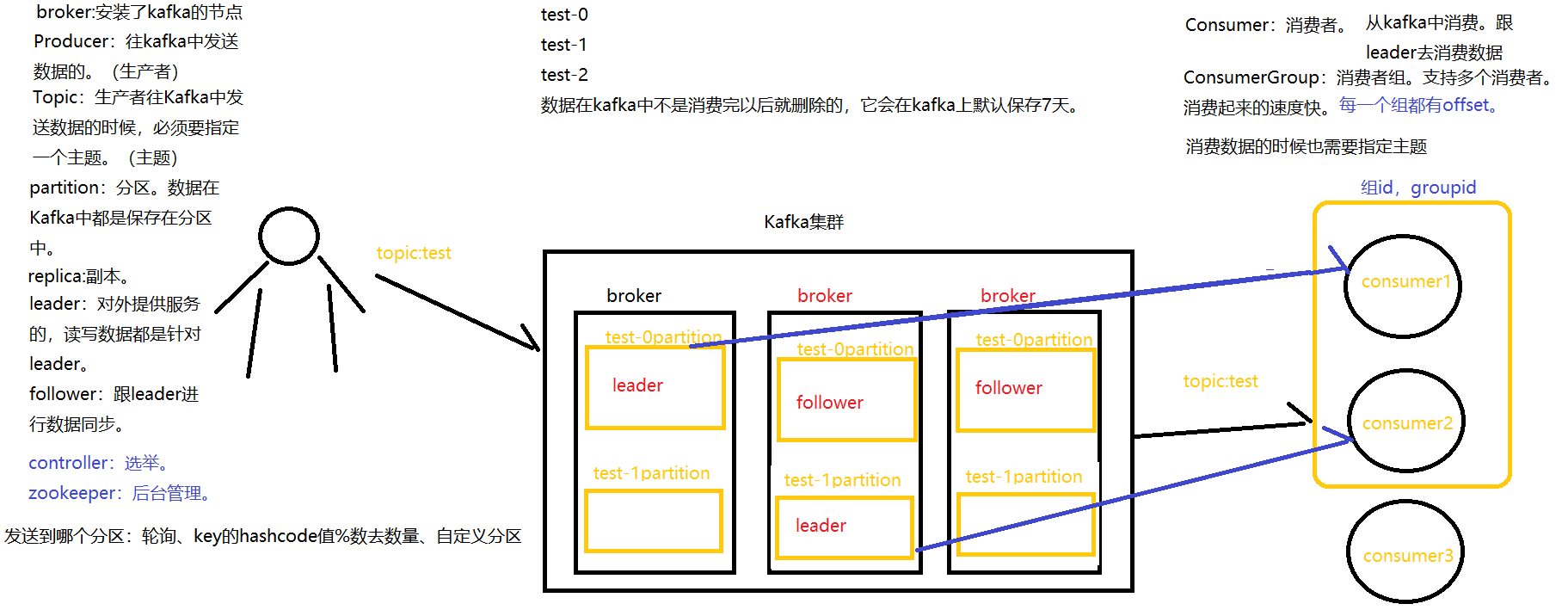
Kafka中存储的消息,被消费后不会被删除,可以被重复消费,消息会保留多长,由kafka自己去配置。默认7天删除。背后的管理工作由zookeeper来管理。
kafka安装
版本匹配
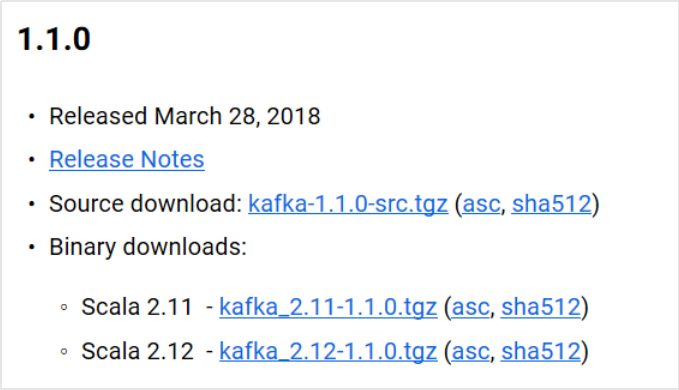
(以下操作均在虚拟机中运行)
首先进入到 /opt/software 中,将kafka的安装包传入,进行解压并重命名
cd /opt/software
rz (选择压缩包进行传入)
tar -zxvf 压缩包 (进行解压)
mv 文件名 kafka
然后ll查看就可以展现出所解压并且已经成功重命名的文件
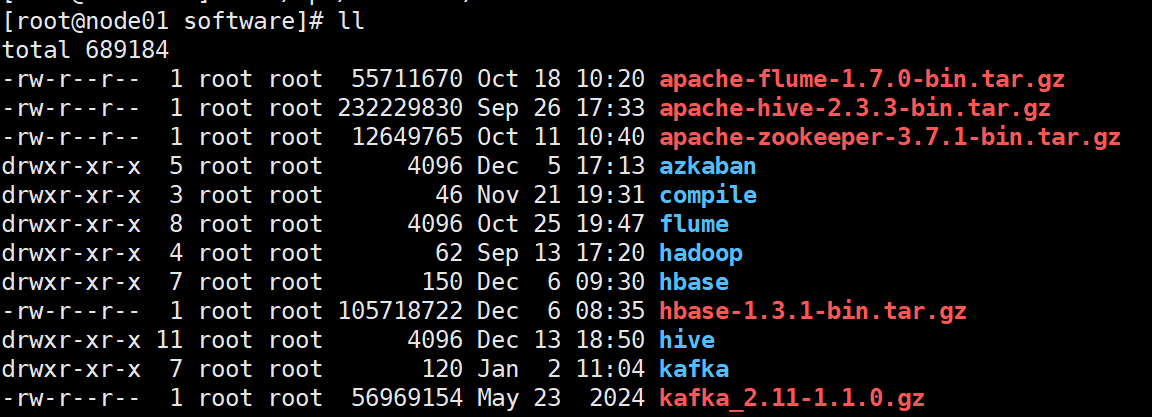
将文件传输到node02、node03中,并且修改配置
cd config
v i server.properties
0: node01
1: node02
2: node03
分发kafka的安装包,到其他的节点中:
|-----------------------------------------------------------------------------------------------------------------------------|
| scp -r kafka node02:PWD scp -r kafka node03:PWD 使用下面的 scp -r kafka node02:/opy/software scp -r kafka node03:/opt/software |
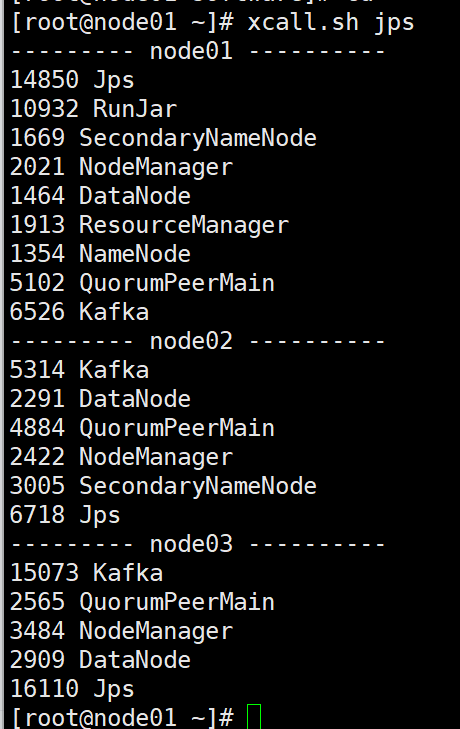
启动节点
先启动zookeeper集群
zkServer.sh start
启动脚本和停止脚本命令。
以后台守护进程启动:(前面启动不行 使用该命令)三个节点都启动
kafka-server-start.sh -daemon /opt/software/kafka/config/server.properties
注意: 在启动kafka之前,必须先启动zookeeper
spark安装
选择与kafka、scala版本相匹配的spark文件进行
(以下操作均在虚拟机中运行)
将文件传输到node01、node02、node03中,并解压重命名

修改spark的配置文件
vi /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/yarn-site.xm
添加如下两行
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
保存退出(esc+:+wq)
修改env文件,添加配置并保存刷新
可以测试是否安装成功