任务:爬取我的钢铁网的钢材价格指数数据,需要输入时间和钢材类型
网站:钢铁价格指数_今日钢铁价格指数实时行情走势_我的钢铁指数
目录
1.环境搭建
先把selenium的环境配置好
python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
import pandas as pd
import time
# 设置Edge浏览器选项
edge_options = Options()
edge_options.add_argument("--headless") # 无头模式,不显示浏览器窗口
edge_options.add_argument("--disable-gpu")
edge_options.add_argument("--window-size=1920,1080")
# 指定Edge驱动路径(需要先下载对应版本的Edge驱动)
# 下载地址:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
edge_service = Service('D:\桌面文件\edgedriver_win64\msedgedriver.exe') # 替换为你的Edge驱动路径
# 启动Edge浏览器
driver = webdriver.Edge(service=edge_service, options=edge_options)
url = "https://www.example.com"
driver.get(url)
# 获取网页标题
print(driver.title)
2.打开网站
实战演练都只能自己梳理流程,没有一样的,
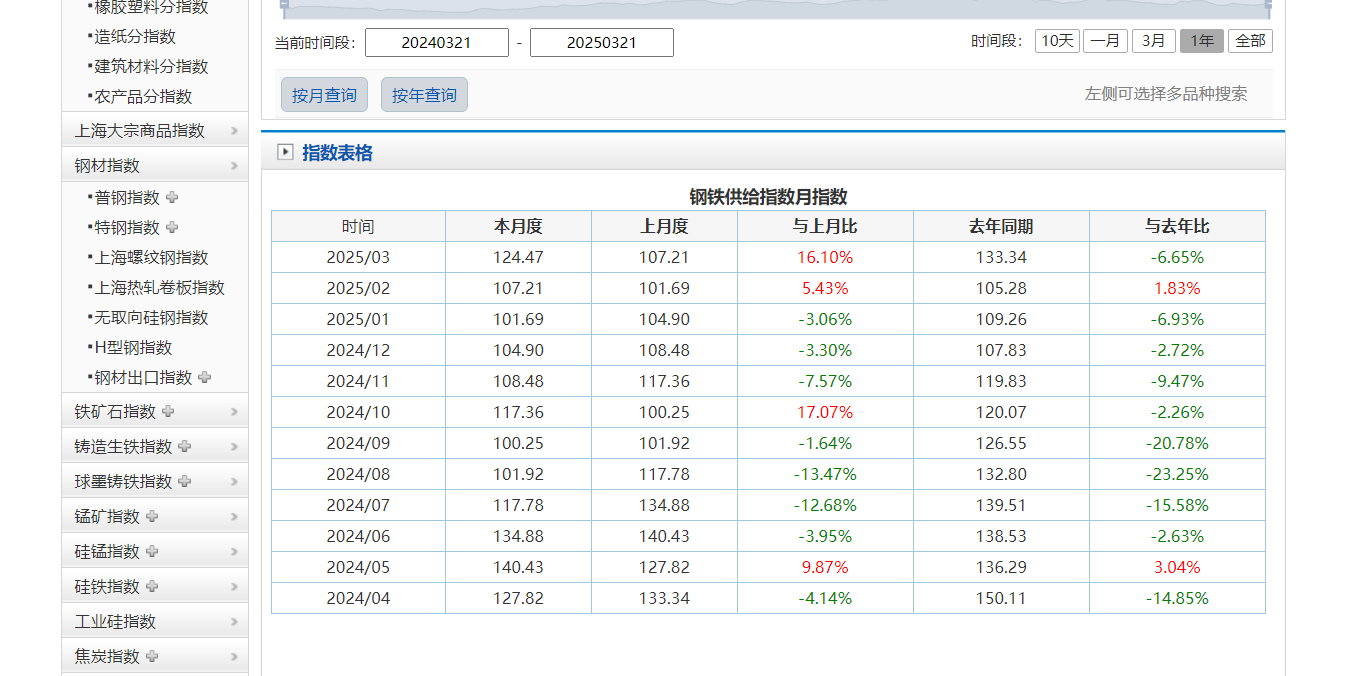
我这边的任务是爬取钢铁价格指数,按日查询,需要手动输入规定时间范围
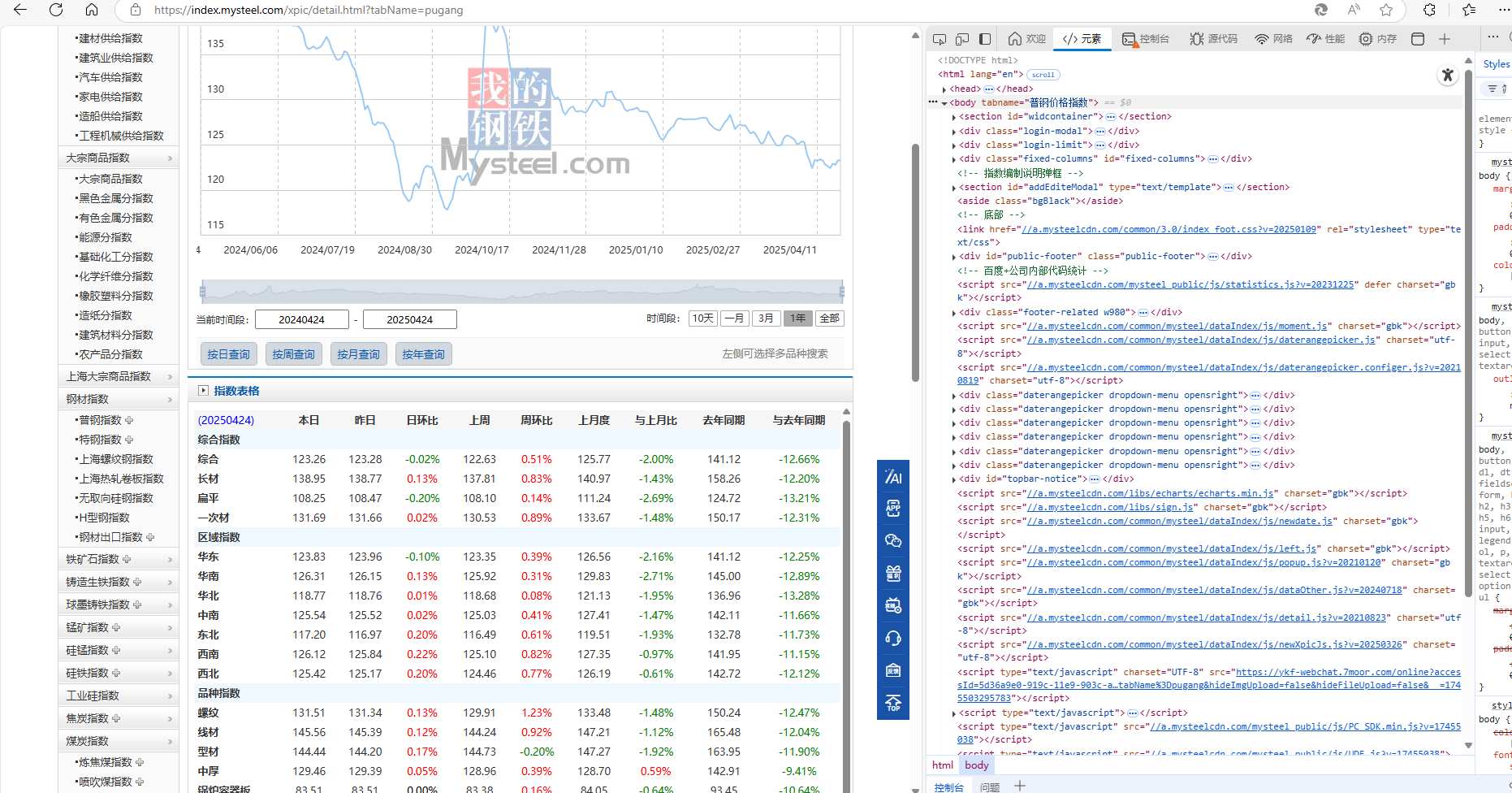
python
url = "https://index.mysteel.com/xpic/detail.html?tabName=pugang"
driver.get(url)
# element = driver.find_element(By.CLASS_NAME, "mRightBox")
# print(element.text)3.点击右侧按钮展开
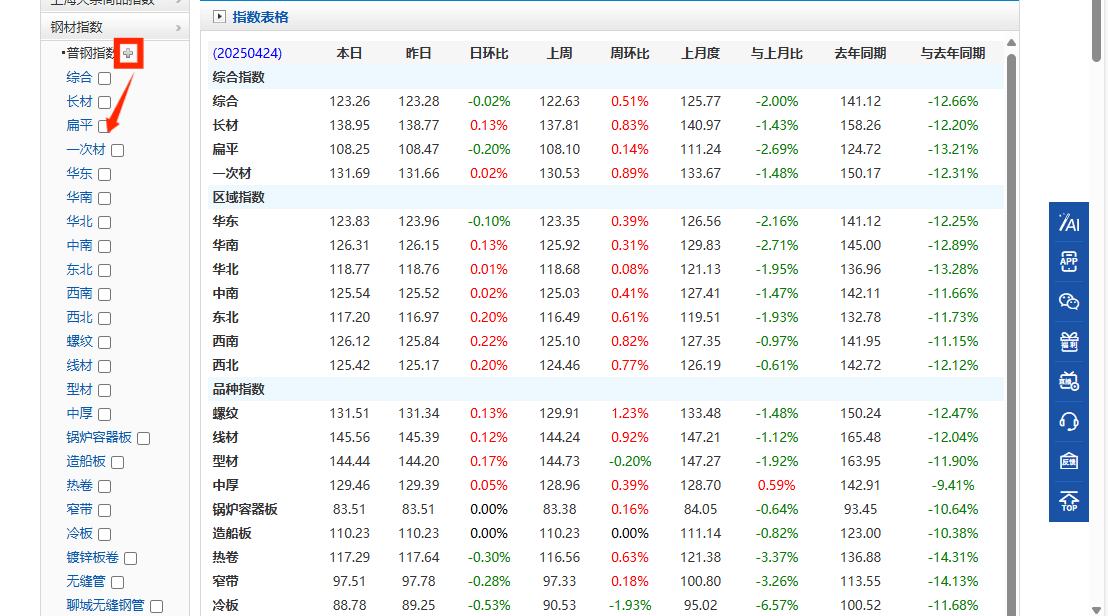
获取控件名称 :
<img class="addBtn" src="//a.mysteelcdn.com/common/mysteel/dataIndex/images/icon.png" alt="">
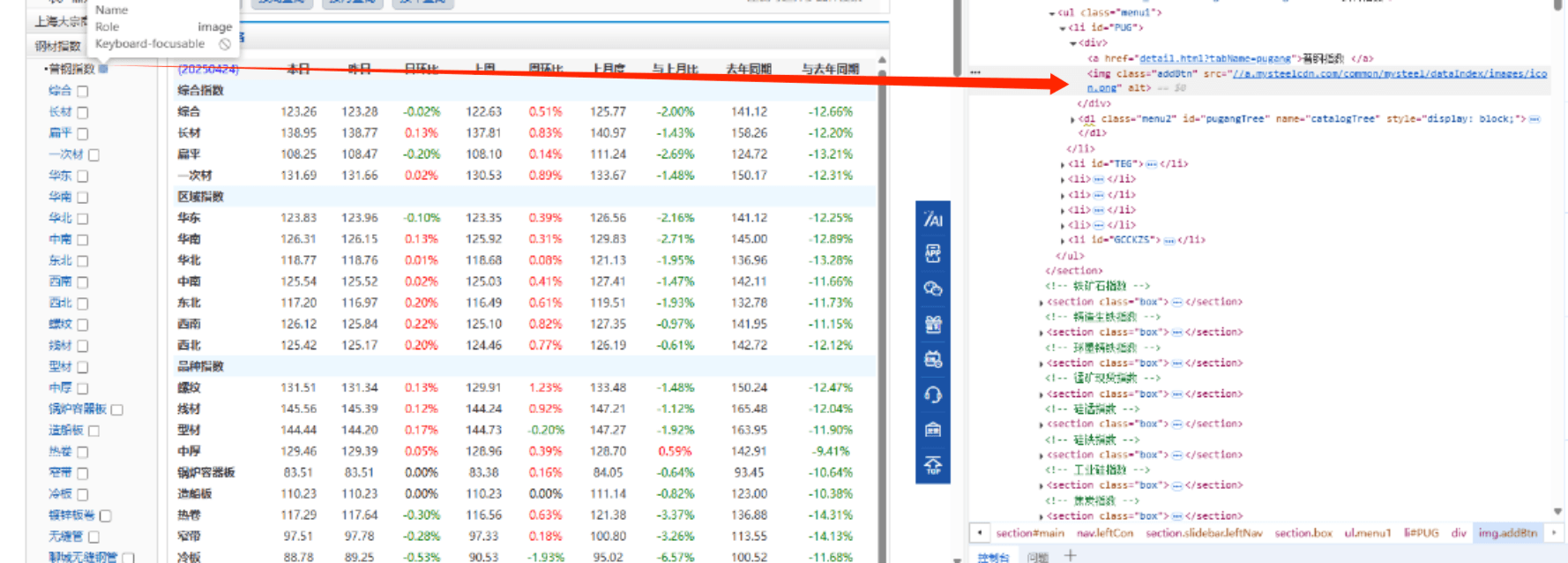
python
driver.find_element(By.CSS_SELECTOR, "img.addBtn[src*='icon.png']").click()4.点击需要的钢材数据
<a id="LUOWEN" name="螺纹" href="javascript:void(0);" class="blue">螺纹</a>
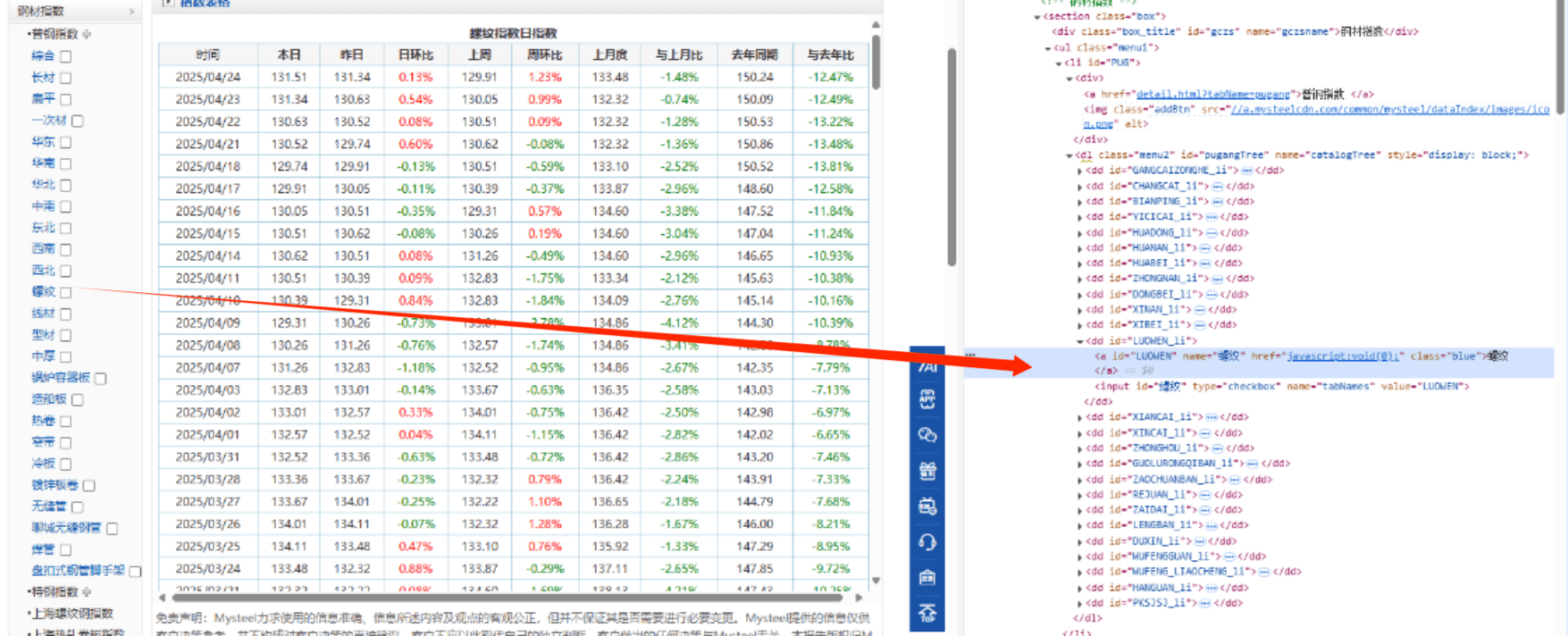
python
#点击综合
key1=driver.find_element(By.ID, "LUOWEN")
key1.click()5.点击"按日查询"
<a href="javascript:void(0);">按日查询</a>
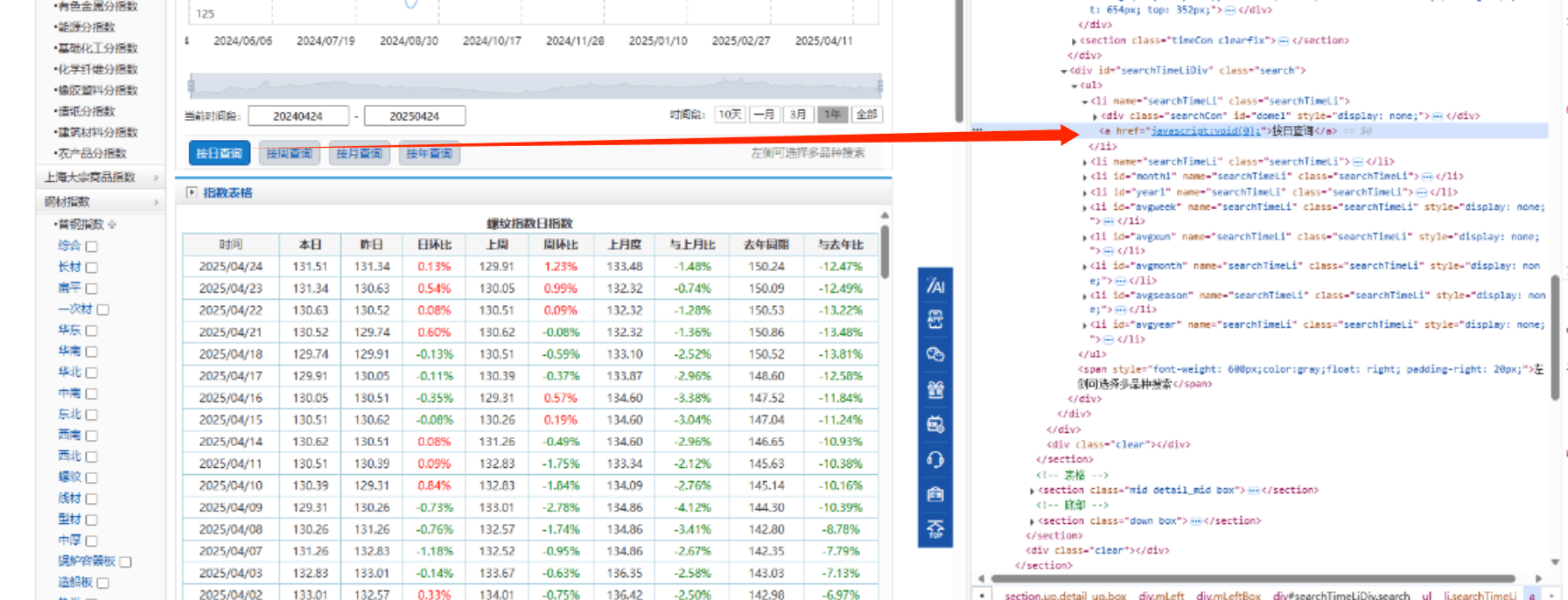
有一些控件的属性和id都不好筛选,我感觉最直接办法就是获取:XPATH
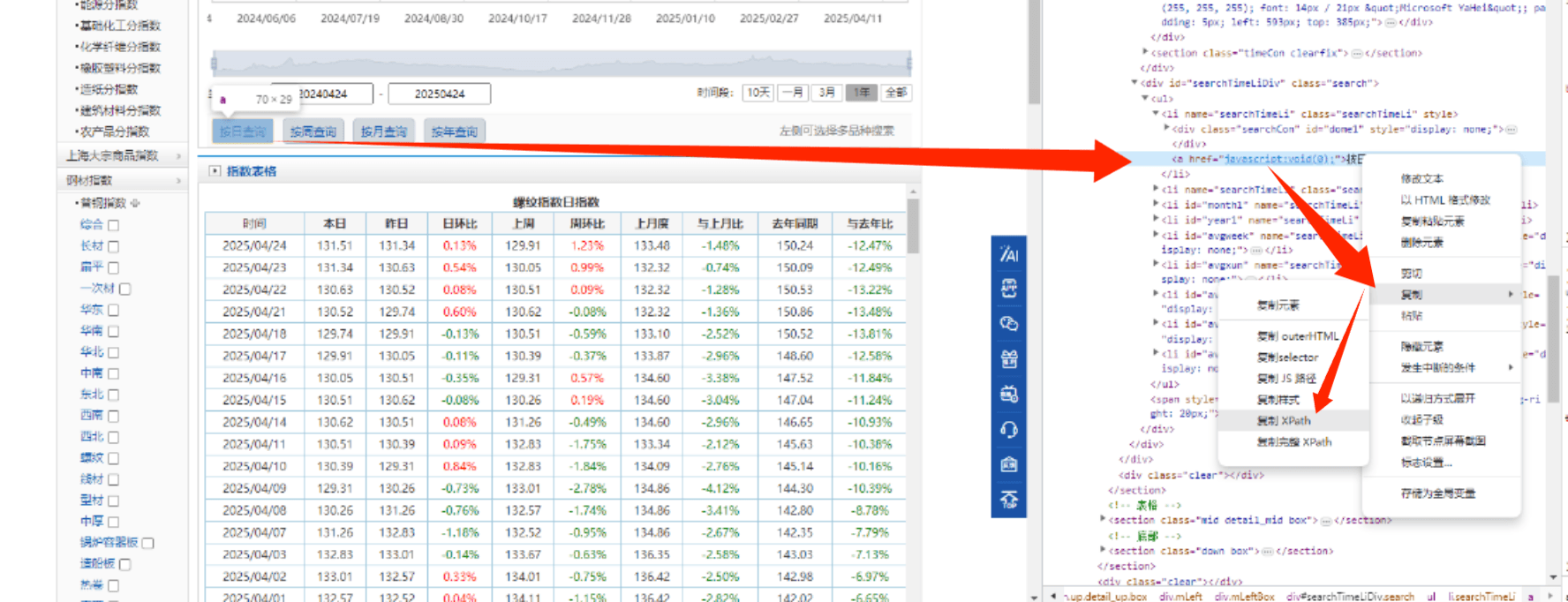
python
key2=driver.find_element(By.XPATH, '//*[@id="searchTimeLiDiv"]/ul/li[1]/a')
key2.click()6.输入日查询起始

点击完"按日查询"之后,会出现下面的起始和终止,然后点击空空框,弹出日历表:
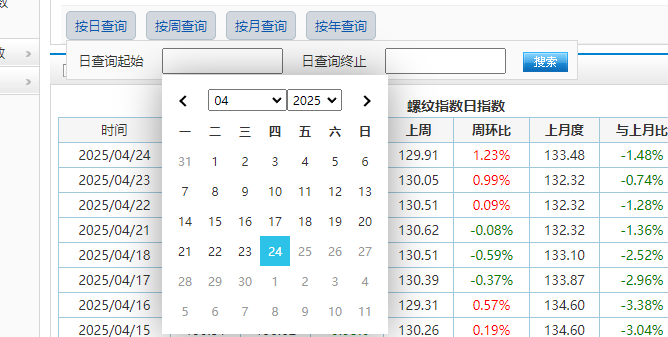
获取控件:
<input type="text" readonly="readonly" size="15" id="startDay" class="calendarBtn">
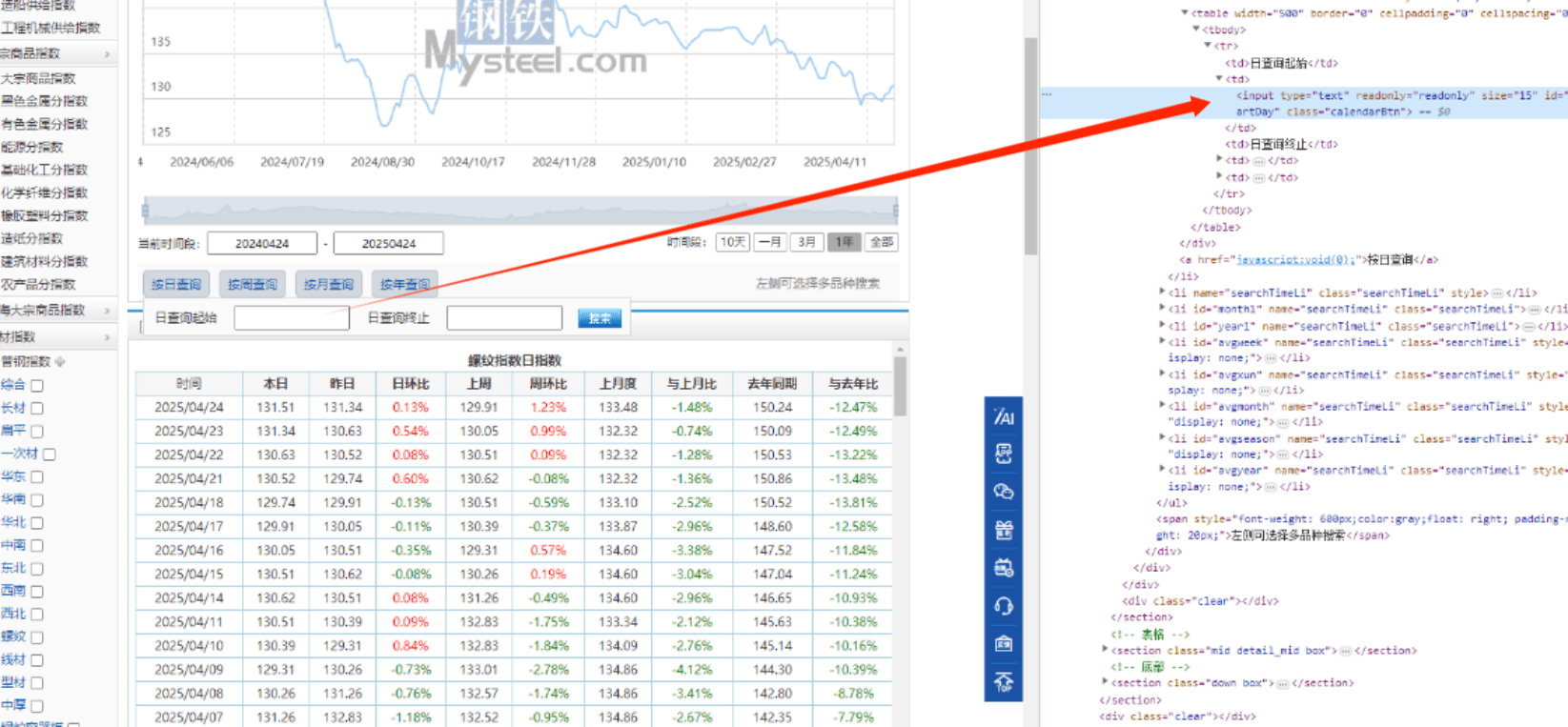
python
start_date=driver.find_element(By.XPATH, '//*[@id="startDay"]')
# start_date.clear()
start_date.click()年:Xpath:/html/body/div3/div2/div/table/thead/tr1/th2/select2
{kind=link}
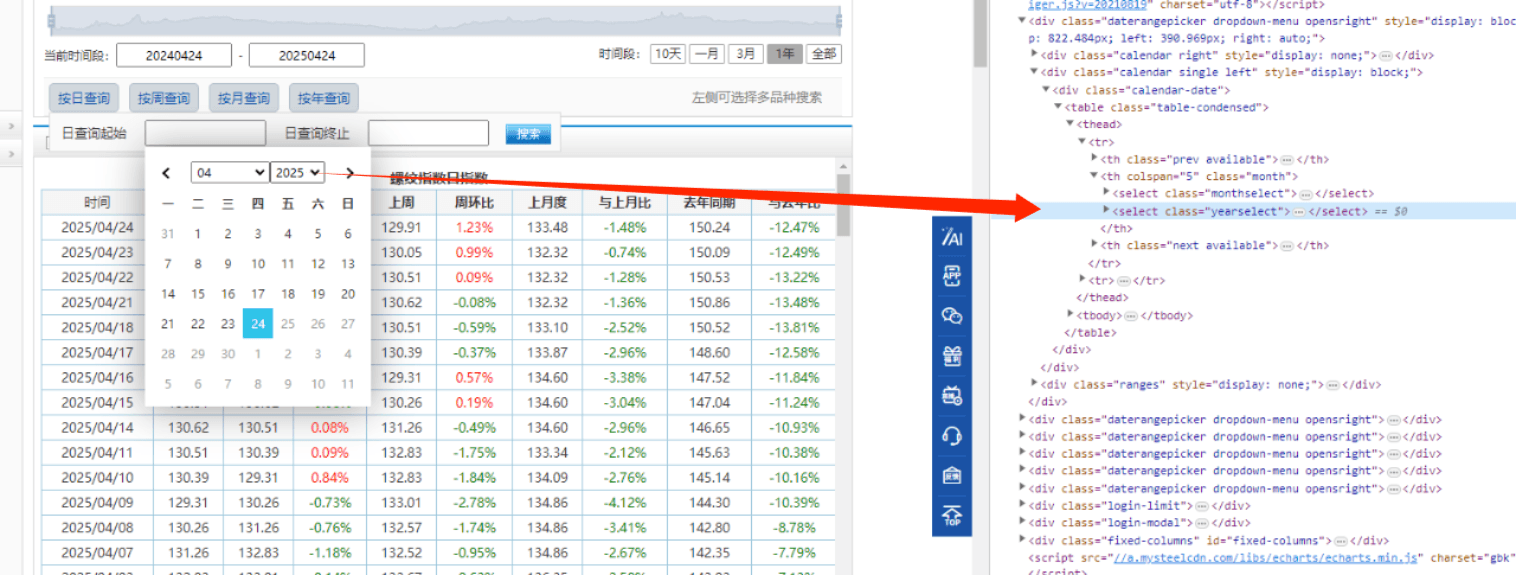
下拉框选择:2021
python
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
# 选择年份(如果页面有年份下拉框)
year_dropdown = driver.find_element(By.XPATH, "/html/body/div[3]/div[2]/div/table/thead/tr[1]/th[2]/select[2]")
year_dropdown.click()
print("选择年份下拉框")
# 选择年份<option value="1975">1975</option>
# year_dropdown.find_element(By.XPATH, f"//option[@value='{year}']").click()
# print(f"选择年份:{year}")
select = Select(year_dropdown)
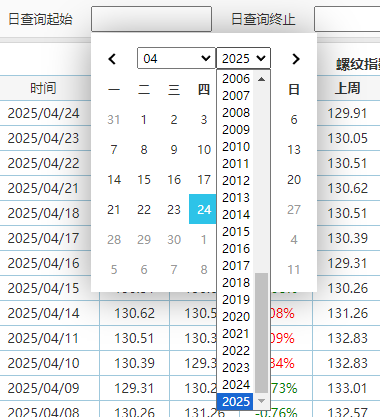
select.select_by_visible_text("2021") # 根据文本选择月份同理:01
python
#输出
#选择月份 /html/body/div[3]/div[2]/div/table/thead/tr[1]/th[2]/select[1]
month_dropdown = driver.find_element(By.XPATH, "/html/body/div[3]/div[2]/div/table/thead/tr[1]/th[2]/select[1]")
month_dropdown.click()
print("选择月份下拉框")
select1 = Select(month_dropdown)
select1.select_by_visible_text("01") # 根据文本选择
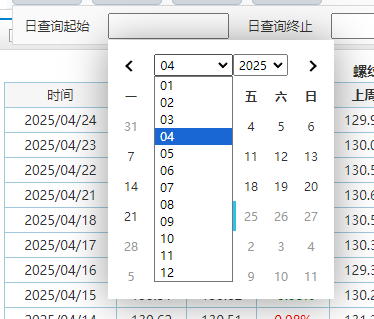
print("选择月份:09")日:
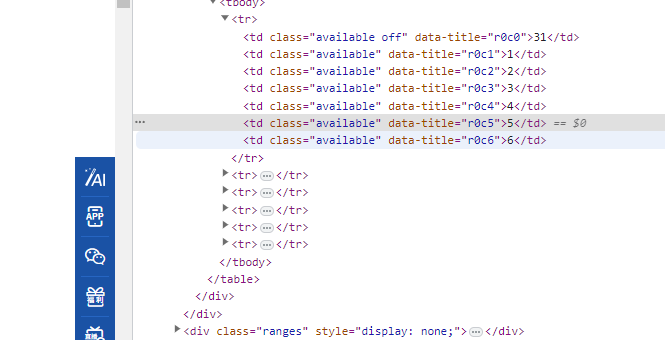
选择一号:
python
date_cell = driver.find_element(
By.XPATH, "//td[contains(@class, 'available') and text()='1']"
)
date_cell.click()完整代码:
python
try:
#点击综合
key1=driver.find_element(By.ID, "GANGCAIZONGHE")
key1.click()
# //*[@id="searchTimeLiDiv"]/ul/li[1]/a按日查询
key2=driver.find_element(By.XPATH, '//*[@id="searchTimeLiDiv"]/ul/li[1]/a')
key2.click()
#起始日期//*[@id="startDay"]
start_date=driver.find_element(By.XPATH, '//*[@id="startDay"]')
# start_date.clear()
start_date.click()
driver.maximize_window()
# 解析年月日
target_date = "2021-09-01"
year, month, day = target_date.split('-')
# # 等待日历面板加载
# WebDriverWait(driver, 10).until(
# EC.presence_of_element_located((By.CSS_SELECTOR, ".daterangepicker.dropdown-menu"))
# )
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
# 选择年份(如果页面有年份下拉框)
year_dropdown = driver.find_element(By.XPATH, "/html/body/div[3]/div[2]/div/table/thead/tr[1]/th[2]/select[2]")
year_dropdown.click()
print("选择年份下拉框")
# 选择年份<option value="1975">1975</option>
# year_dropdown.find_element(By.XPATH, f"//option[@value='{year}']").click()
# print(f"选择年份:{year}")
select = Select(year_dropdown)
select.select_by_visible_text("2021") # 根据文本选择
#输出
#选择月份 /html/body/div[3]/div[2]/div/table/thead/tr[1]/th[2]/select[1]
month_dropdown = driver.find_element(By.XPATH, "/html/body/div[3]/div[2]/div/table/thead/tr[1]/th[2]/select[1]")
month_dropdown.click()
print("选择月份下拉框")
select1 = Select(month_dropdown)
select1.select_by_visible_text("01") # 根据文本选择
print("选择月份:09")
# 选择日期
date_cell = driver.find_element(
By.XPATH, "//td[contains(@class, 'available') and text()='1']"
)
date_cell.click()
print(f"选择日期:{day}")
except Exception as e:
print(f"执行出错: {str(e)}")
driver.save_screenshot('error.png')7.输入日查询结束
和前前面差不多,唯一注意的地方就是,起始和结束的日历不是共享的一个,一个左一个右:
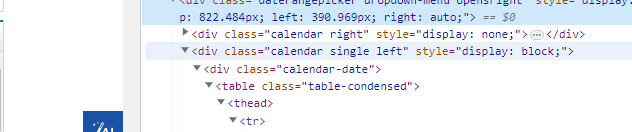
因为 刚开始左边在前可以直接选择:而右边需要定位到右侧日历:/html/body/div4/div2
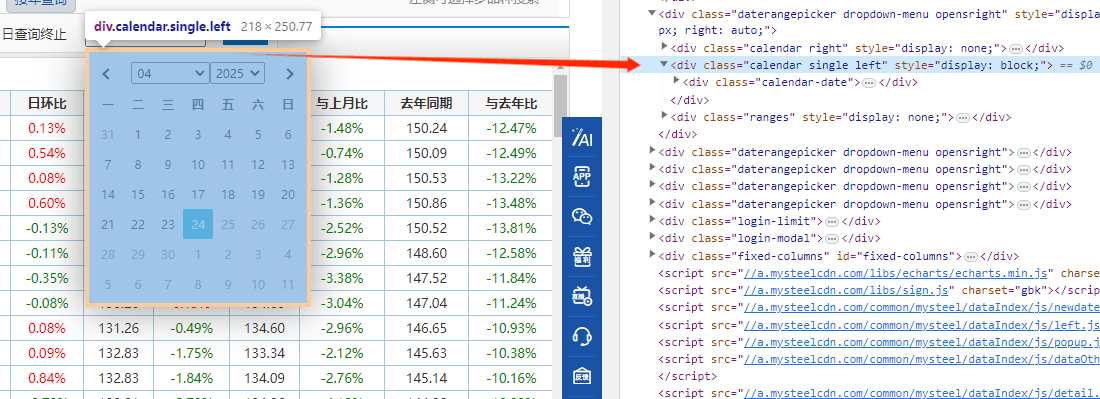
python
left_calendar = driver.find_element(
By.XPATH,
'/html/body/div[4]/div[2]'
)
# 选择日期
# left_calendar = driver.find_element(By.CLASS_SELECTOR, "calendar single left")
# driver.find_element(By.XPATH, "//td[contains(@class, 'available') and text()='2']")
date_end_cell = left_calendar.find_element(
By.XPATH,
'.//td[text()="1"]'
)完整代码:
python
try:
# //*[@id="searchTimeLiDiv"]/ul/li[1]/a按日查询
key2=driver.find_element(By.XPATH, '//*[@id="searchTimeLiDiv"]/ul/li[1]/a')
key2.click()
#终止日期//*[@id="endDay"]
end_date=driver.find_element(By.XPATH, '//*[@id="endDay"]')
# start_date.clear()
end_date.click()
driver.maximize_window()
# 解析年月日
target_date = "2021-09-01"
year, month, day = target_date.split('-')
# # 等待日历面板加载
# WebDriverWait(driver, 10).until(
# EC.presence_of_element_located((By.CSS_SELECTOR, ".daterangepicker.dropdown-menu"))
# )
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
# 选择年份(如果页面有年份下拉框)
year_end_dropdown = driver.find_element(By.XPATH, "/html/body/div[4]/div[2]/div/table/thead/tr[1]/th[2]/select[2]")
year_end_dropdown.click()
print("选择年份下拉框")
# 选择年份<option value="1975">1975</option>
# year_dropdown.find_element(By.XPATH, f"//option[@value='{year}']").click()
# print(f"选择年份:{year}")
select_year_end = Select(year_end_dropdown)
select_year_end.select_by_visible_text("2025") # 根据文本选择
#输出
#选择月份 /html/body/div[4]/div[2]/div/table/thead/tr[1]/th[2]/select[1]
month_end_dropdown = driver.find_element(By.XPATH, "/html/body/div[4]/div[2]/div/table/thead/tr[1]/th[2]/select[1]")
month_end_dropdown.click()
print("选择月份下拉框")
select_month_end = Select(month_end_dropdown)
select1_month_end = select_month_end.select_by_visible_text("01") # 根据文本选择
print("选择月份:04")
#/html/body/div[4]/div[2]
#找到右侧日历
left_calendar = driver.find_element(
By.XPATH,
'/html/body/div[4]/div[2]'
)
# 选择日期
# left_calendar = driver.find_element(By.CLASS_SELECTOR, "calendar single left")
# driver.find_element(By.XPATH, "//td[contains(@class, 'available') and text()='2']")
date_end_cell = left_calendar.find_element(
By.XPATH,
'.//td[text()="1"]'
)
date_end_cell.click()
driver.save_screenshot('C:\pythonProject\python爬虫\我的钢铁网\end_date.png')
print(f"选择日期:{day}")
except Exception as e:
print(f"执行出错: {str(e)}")
driver.save_screenshot('error.png')
8.获取数据
设置完时间之后,点击查询://*@id="dome1"/table/tbody/tr/td5/img
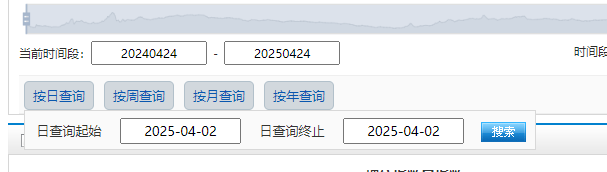
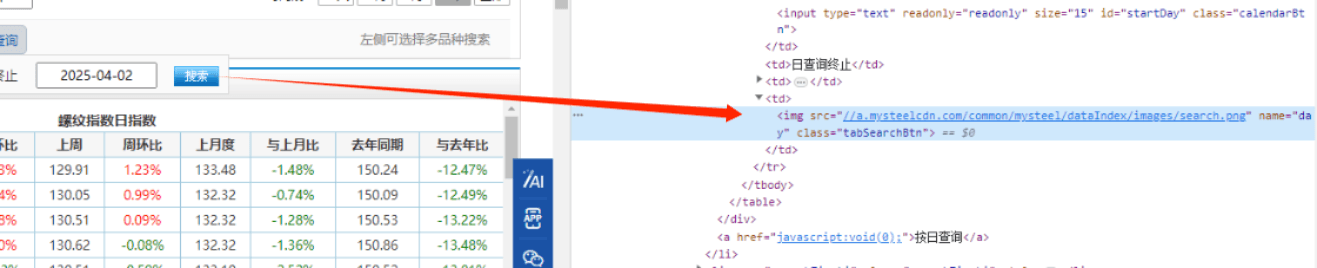
python
#点击搜索按钮
search_btn=driver.find_element(By.XPATH, '//*[@id="dome1"]/table/tbody/tr/td[5]/img')
search_btn.click()
driver.save_screenshot('C:\pythonProject\python爬虫\我的钢铁网\搜索之后.png')定位表格://*@id="main"/section/section2/section/div/table
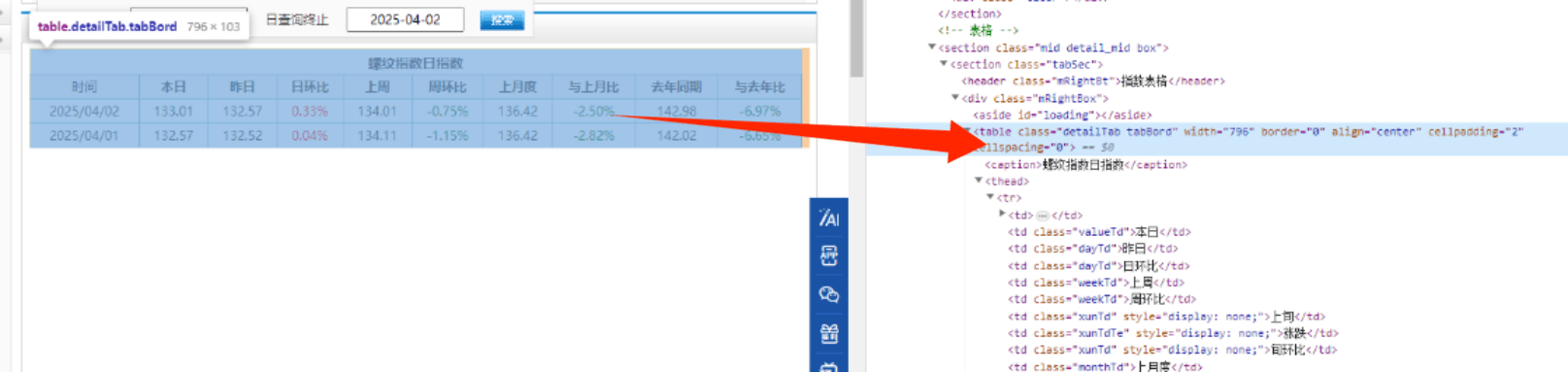
爬取实时数据:
python
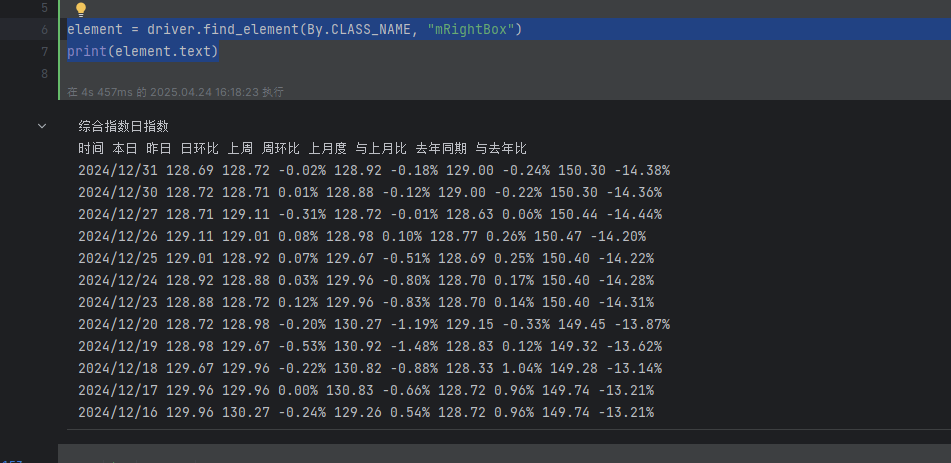
element = driver.find_element(By.CLASS_NAME, "mRightBox")
print(element.text)