面:
数据结构:String、hash、set、zset、list
什么是RDB?RDB和AOF的区别:
一、Redis概述
Redis就是缓存,Redis基于内存,将大量访问的数据放到缓存,而不是数据库,这样不会访问数据库,如果都放到内存,内存是jvm中的,无法保证多线程共享同一份内存,所以使用Redis。
数据存在内存中,但是可以对其进行持久化,这样内存宕机之后,数据也不会丢失。
Redis是开源的(BSD许可),数据结构存储于内存中,被用来作为数据库,缓存和消息代理。 它支持多种数据结构,例如:字符串(string),哈希(hash),列表(list),集合(set), 带范围查询的排序集合(zset),位图(bitmap),hyperloglog,带有半径查询和流的地理 空间索引(geospatial)。 Redis具有内置的复制,Lua脚本,事务和不同级别的磁盘持久性, 并通过Redis Sentinel(负责主从情况下选主)和Redis Cluster自动分区提供高可用性。
安装Redis
- 启动redis服务端:src/redis-server --daemonize yes
- 开启redis客户端:src/redis-cli
Redis Sentinel
二、Redis类型及编码
5种基本数据类型:String、hash、set、zset、list
Redis是key-value键值对,key肯定是string类型的,value是RedisObject类型的,包括多种类型。
- OBJECT encoding key:可以查看key对应的value的encoding类型。
三、Redis对象的编码
|---------------------------|------------------|
| encoding常量 | 编码所对应的底层数据结构 |
| REDIS_ENCODING_INT | long类型的整数 |
| REDIS_ENCODING_EMBSTR | embstr编码的简单动态字符串 |
| REDIS ENCODING_RAW | 简单动态字符串 |
| REDIS_ENCODING_HT | 字典 |
| REDIS_ENCODING_LINKEDLIST | 双向链表 |
| REDIS_ENCODING_ZIPLIST | 压缩列表 |
| REDIS_ENCODING_INTSET | 整数集合 |
| REDIS_ENCODING_SKIPLIST | 跳表和字典 |
跳表的概念重要:因为可以快速查询,比树结构好维护,查询效率也不会差多少
1. 类型&编码的对应关系
|----------------|---------------------------|
| 对象类型(type) | 对象编码(encoding) |
| REDIS_STRING | REDIS_ENCODING_INT |
| | REDIS_ENCODING_EMBSTR |
| | REDIS_ENCODING_RAW |
| REDIS_LIST | REDIS_ENCODING_ZIPLIST |
| | REDIS_ENCODING_LINKEDLIST |
| REDIS_SET | REDIS_ENCODING_INTSET |
| | REDIS_ENCODING_HT |
| REDIS_ZSET | REDIS_ENCODING_ZIPLIST |
| | REDIS_ENCODING_SKIPLIST |
| REDIS_HASH | REDIS_ENCODING_ZIPLIST |
| | REDIS_ENCODING_HT |
(能记住最好)
2. string类型常用命令
|----------------------------------|-----------------------|
| 命令行 | 含义 |
| set key value | 赋值key的值为value |
| get key / del key | 获取key的value值 / 删除key |
| expire key seconds | 设置key在seconds秒后过期 |
| setex key seconds value | SET + EXPIRE的组合指令 |
| ttl key | 查看key还有多久过期 |
| setnx key value | 如果key不存在,才新增key和value |
| strlen key | 计算指定key的值的长度 |
| incr key value | 值加1 |
| incrby key numbers | 指定增加值,numbers可以是负值 |
| mset key1 value1 key2 value2 ... | 批量添加 |
| mget key1 key2 key3 ... | 批量获取 |
用JSON的形式将对象存到value中,扩容规则:当value<=1M时翻倍扩容,当>1M时,每次扩容1M。字符串的长度不能超过512M
setex key time value :在设置key-value对象的同时设置了过期时间,
string类型的三种编码:
|-----------------------|
| REDIS_ENCODING_INT |
| REDIS_ENCODING_EMBSTR |
| REDIS_ENCODING_RAW |
int:long长度范围内的纯数字,超过long长度范围的话就是embstr
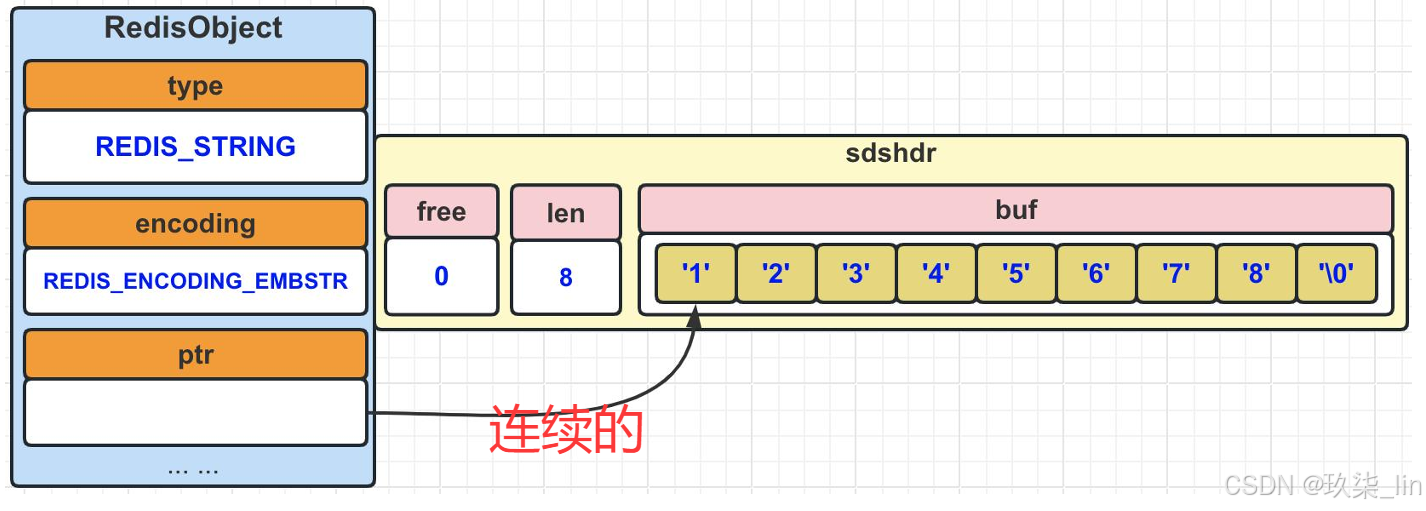
embstr:长度小于40位的数字+字符。一次内存分配,RedisObject和sdshdr是连续的。
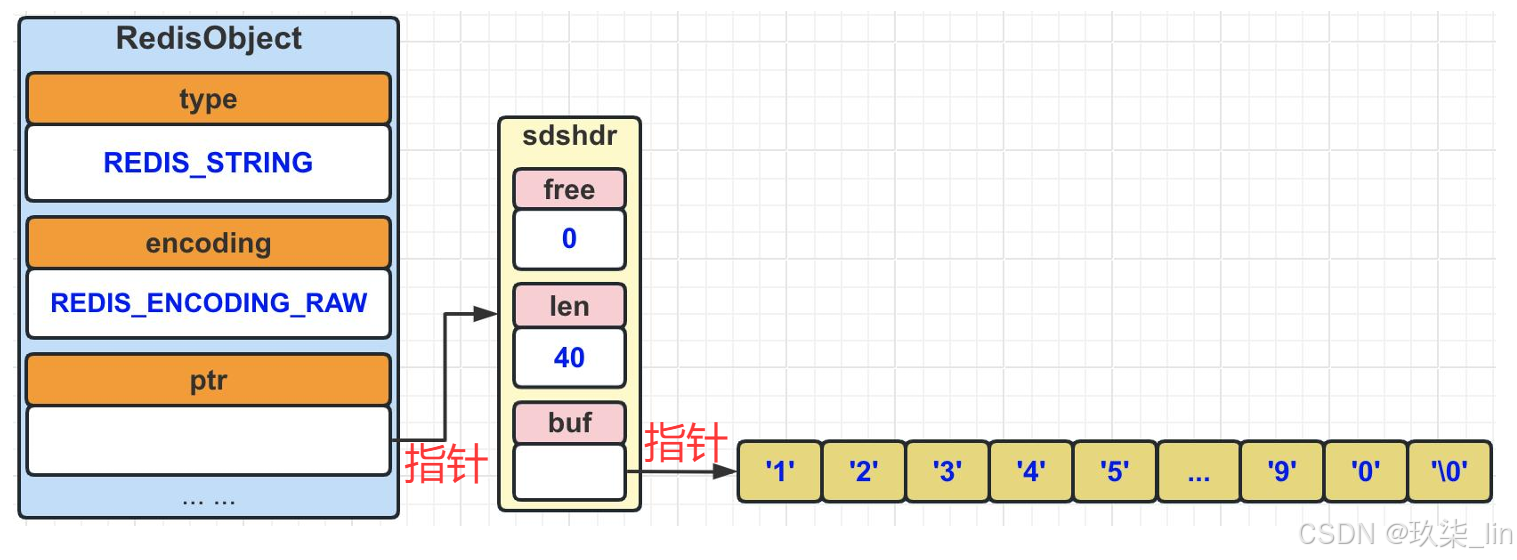
raw:>=40位的数字加字符。两次内存分配,靠指针连接RedisObject和sdshdr。访问速度比embstr慢,但是因为不连续使得内存要求不高。
(1)string类型内部实现------int编码
如果保存的value值,可以用long类型表示(-9223372036854775808 ~ 9223372036854775807),那么encoding就是int编码,如果超过了long类型的长度,则会转换为embstr编码。
(2)string类型内部实现------embstr编码
value值的长度如果小于40 ,则使用embstr,它可以保存数字类型和字符类型的值。embstr编码是专门用于保存短字符串的一种优化编码方式。
Redis没有为embstr编码的字符串对象提供修改功能,所以embstr是只读 的。如果我们对其进行修改,其实是先转换成raw,再执行修改命令。所以,修改后embstr就会变为raw编码的字符串对象了。
(3)string类型内部实现------raw编码
当value值的长度如果大于等于40时,则使用raw编码。
如果将原本保存的整数转换为字符串,那么字符串对象的编码也将从int变为raw。
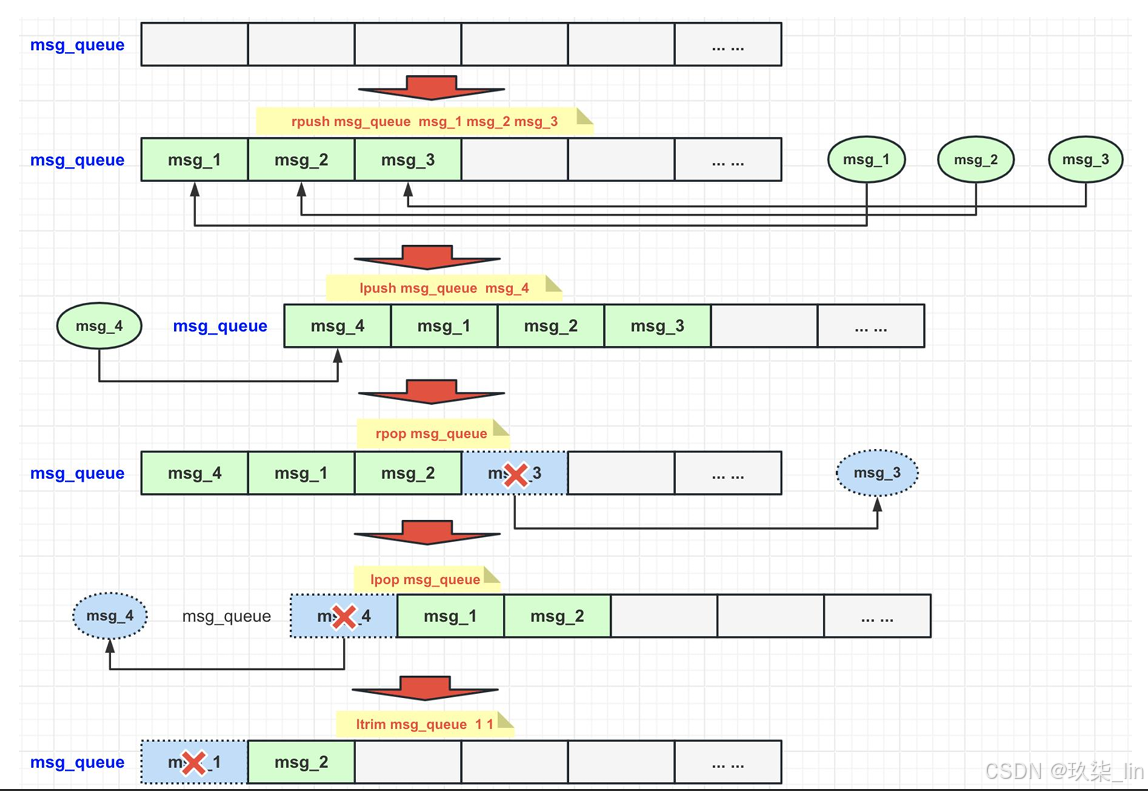
3. list类型常用命令
|--------------------------------|------------------------|
| 命令行 | 含义 |
| lpush key value1 value2 | 左侧插入value |
| rpush key value1 value2 | 右侧插入value |
| lpop key | 左侧弹出value |
| rpop key | 右侧弹出value |
| llen key | 查看key的长度 |
| lindex key index | 查看列表中某个index对应的value值 |
| lrange key startIndex endIndex | 查看指定元素,下标从0开始,-1为倒数第一个 |
| ltrm key startIndex endIndex | 仅保留某区间的列表,其余元素全被删除 |
ltrm key start end中是去掉start之前和end之后的,保留start到end的闭区间的。ltrm key 1 0是删除所有元素。
(1)列表常用操作
list类型的两种编码:
|---------------------------|
| REDIS_ENCODING_ZIPLIST |
| REDIS_ENCODING_LINKEDLIST |
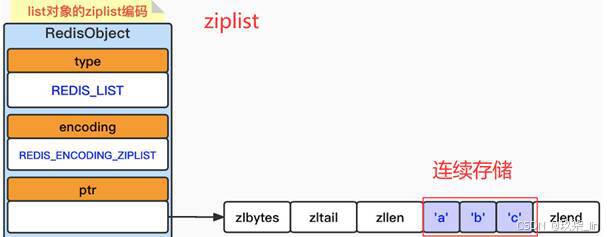
(2)list类型内部实现------ziplist编码
ziplist编码列表对象,采用压缩列表实现。每个列表节点保存一个列表中的元素。当我们执行RPUSH testlist a b c之后,其数据结构如下:
(3)list类型内部实现------linkedlist编码
linkedlist编码列表对象,采用双向链表作为底层实现,每个节点保存一个元素。数据结构如下:
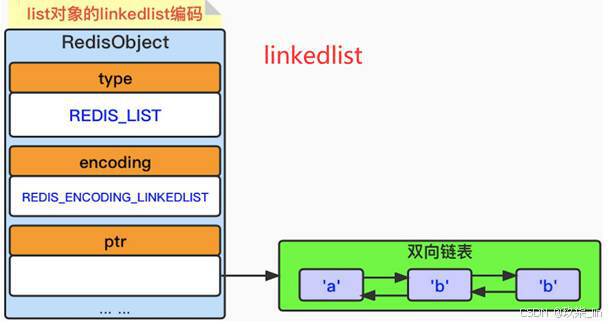
如果满足所有元素长度小于65字节 并且 列表中元素的个数小于512个 是ziplist 类型,否则是linkedlist类型;连续存储,内存连续时访问速度是最快的
4. set类型常用命令
Set类型:主要目的是去重
|------------------------|---------------|
| 命令行 | 含义 |
| sadd key value1 value2 | 添加元素到集合中 |
| smembers key | 查看集合中的所有元素 |
| sismember key value | 查看value是否在集合中 |
| scard key | 查询集合的长度 |
| spop key | 取出集合中的一个元素 |
| del key | 删除集合 |
set类型的两种编码:
|-----------------------|
| REDIS_ENCODING_INTSET |
| REDIS_ENCODING_HT |
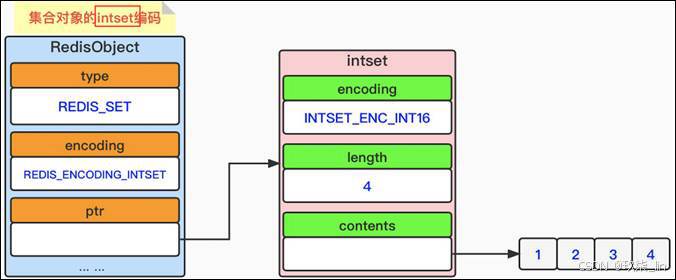
(1)set类型内部实现------intset编码
intset编码集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数 集合里面。数据结构如下所示:
(2)set类型内部实现------hashtable编码
当使用字典作为底层实现,每个键都是一个字符串对象,每个字符串对象包含了一个集合 元素,而字典的值则全部被设置为NULL。数据结构如下所示:
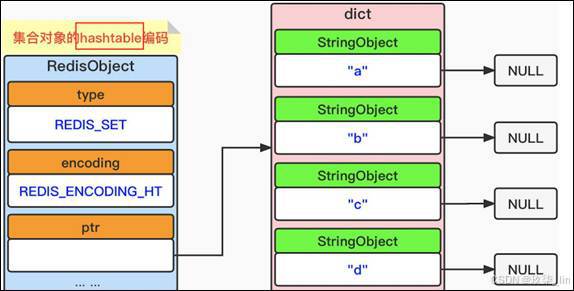
如果填加的是字符类型的,输出的就是乱序的。如果填加的是纯数字类型的话,输出就是升序的。
当集合对象同时满足以下 两个条件时,使用intset 编码,否则使用 hashtable编码:
- ① 集合对象保存的所有元 素都是整数值。
- ② 集合对象保存的元素数 量不超过512个。
Intset --> hashtable:
-
- 存入几个数字是intset,再存入字符类型的变成hashtable;
-
- 存入了512个数字是intset,再存入一个数字也会变成hashtable。
5. zset类型常用命令
|------------------------------------------|-----------------------------------------------------|
| 命令行 | 含义 |
| zadd key score1 value1 value2 score2 | 添加元素到有序集合中 |
| zscore key value | 查看key的score值,输出score>=负无穷, score<=正无穷的所有元素 |
| zrange key 0 -1 | 正序输出 |
| zrangebyscore key -inf +inf | 正序输出 |
| zrevrange key 0 -1 | 倒序输出 |
| zcard key | 查看key中的元素个数 |
| zrangebyscore key indexStart endStart | 获得key中score>=indexStart 且 score<=endStart的元素,正序排列 |
| zrevrangebyscore key indexStart endStart | 同上,倒序排列 |
| zrem key value | 删除key中的元素value |
|---------------------------------------|-----------------------------------------------------|
| zrangebyscore key indexStart endStart | 获得key中score>=indexStart 且 score<=endStart的元素,正序排列 |
相当于闭区间,如果想要开区间,则zrangebyscore key (indexStart endStart.
zset类型的两种编码:
|-------------------------|
| REDIS_ENCODING_ZIPLIST |
| REDIS_ENCODING_SKIPLIST |
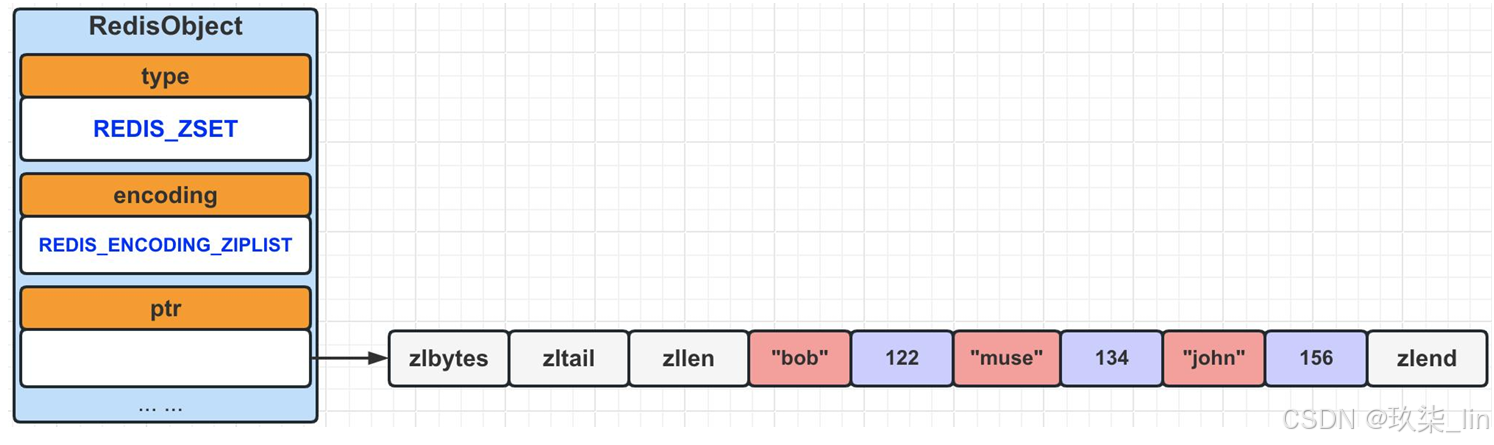
(1)zset类型内部实现------ziplist编码
ziplist使用压缩列表 作为底层实现,每个集合元素使用两个紧挨在一起 的压缩列表节点来保 存,第一个节点保存元素的成员 (member),而第二个节点则保存元素的分值 (score)。 压缩列表内的集合元素按分值(score)从小到大进行排序。
当有序集合对象可以同时满足以下两个条件时,使用ziplist编码,否则使用skiplist编码:
- ① 有序集合保存的元素数量小于等于128个。
- ② 有序集合保存的所有元素长度都小于64字节。
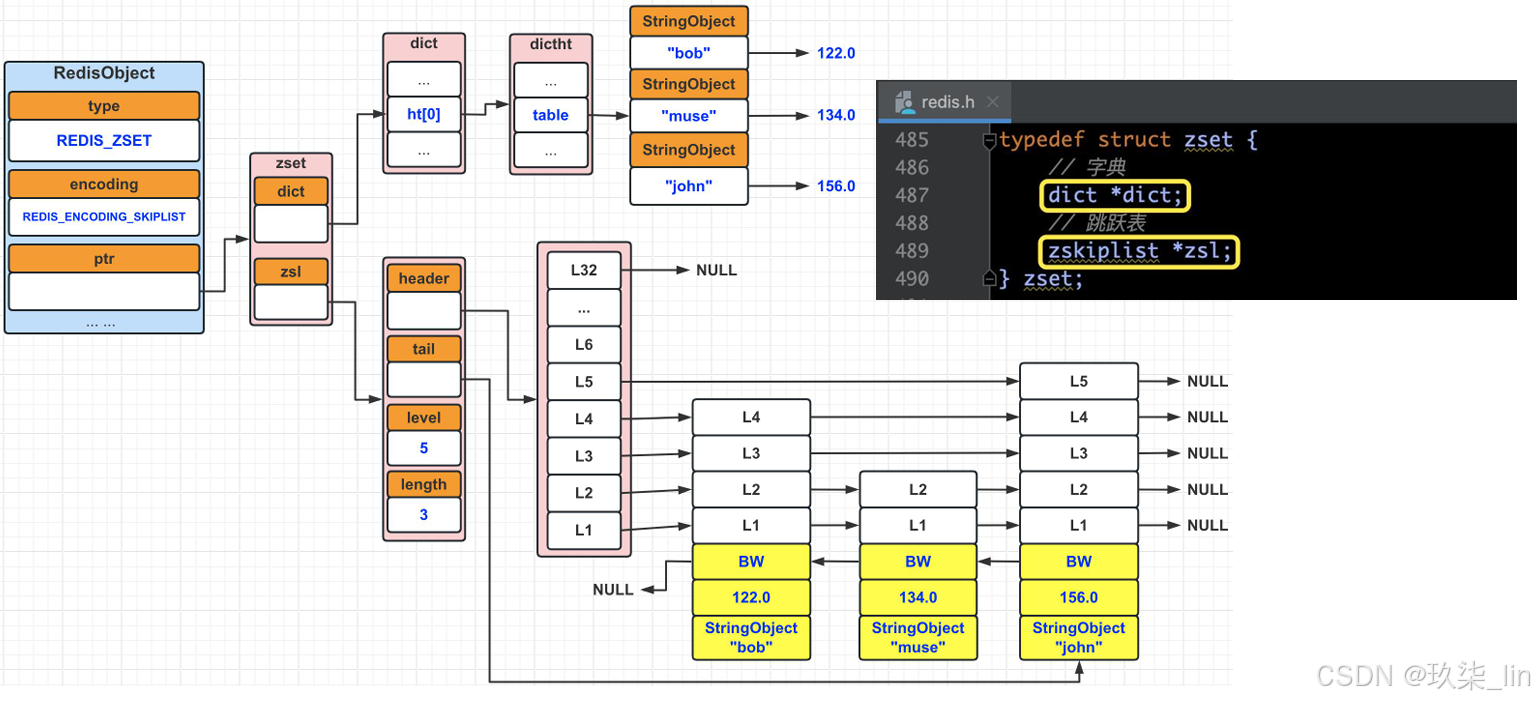
(2)zset类型内部实现------skiplist编码
skiplist编码的有序集合采用zset 结构作为底层实现,一个zset同时包含一个字典dict 和一个跳跃表zskiplist。
6. hash类型常用命令
|-------------------------------------|-----------------------|
| 命令行 | 含义 |
| hset key name value | 添加属性元素name和value到key中 |
| hget key name | 查看key的name值 |
| hmset key name1 value1 name2 value2 | 批量添加key的属性元素 |
| hmget key name1 name2 | 批量获取key的属性元素 |
| hlen key | 获得key的属性元素个数 |
| hgetall key | 查询key中的所有元素 |
hash类型的两种编码:
|------------------------|
| REDIS_ENCODING_ZIPLIST |
| REDIS_ENCODING_HT |
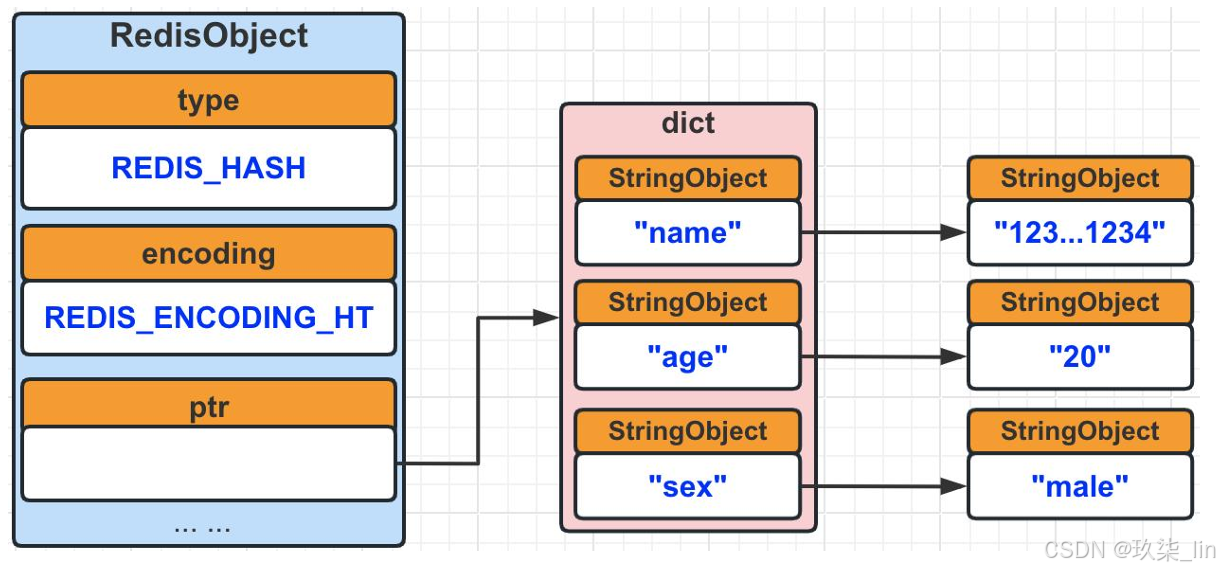
(1)hash类型内部实现------ziplist编码
ziplist编码底层使用压缩列表 实现,当有新的键值对要加入到哈希对象时,会先将key值从 队尾推入 压缩列表中,再将这个key对应的value值从队尾推入 压缩列表中;所以,同一键 值对的两个节点总是紧挨在一起的------key在前,value在后。

(2)hash类型内部实现------hashtable编码
同时满足两个条件时是ziplist编码类型,否则为hashtable编码类型
- ① 哈希对象中所有键值对中,key和value的长度均小于等于64字节。
- ② 哈希对象中键值对的个数小于512个。
四、Redis数据结构
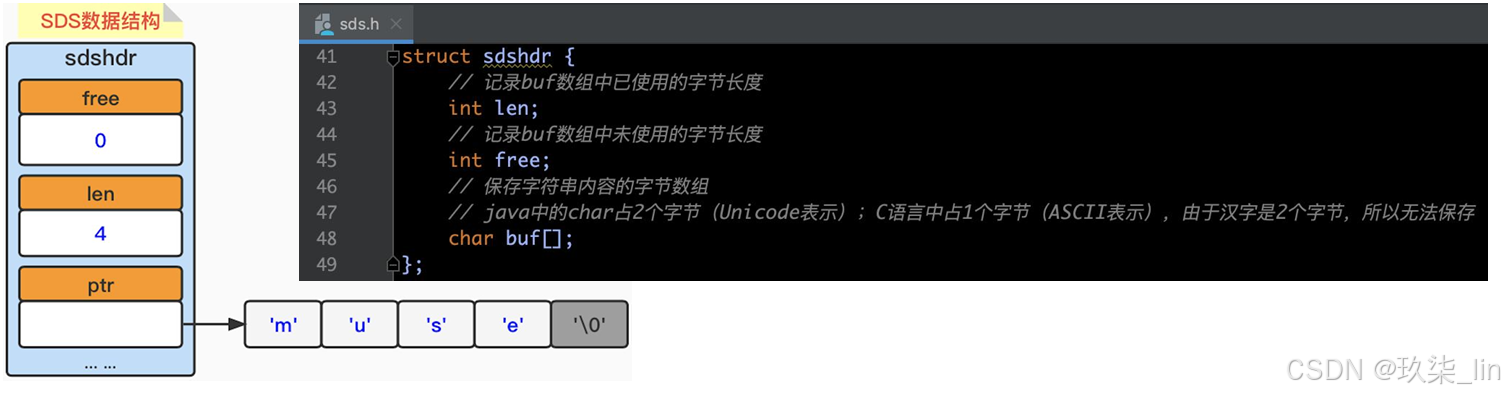
1. SDS简单动态字符串
SDS(simple dynamic string),简单动态字符串。是由Redis自己创建的一种表示字符串 的抽象类型。与C语言不同的是,C语言字符串是不可被修改的。但是SDS是动态可以被修 改的。
最后一位遵循C字符串的空字符('\0')结尾的规则,目的是可以直接使用C字符串的函数。 其中:len计数不包含'\0'。
2. 为什么Redis使用SDS而不是C字符串?
第1点:C语言没有字符串的类型,关于字符串长度的计算。C字符串没有记录字符个数,每次都需要遍历,所以复杂度为 O(n)。SDS的len记录了当前字符串的长度,所以获取字符串长度的复杂度为O(1)。(C语言没有字符串的类型,只能用数组表示。只能存储数据,没有数据计算的能力。Sdshdr中存储了字符串的长度,当需要查询长度的时候直接从sdshdr中获取即可,时间复杂度O(1),而如果是C语言数组的话要去计算每个字符串的长度,时间复杂度是O(N) )
第2点:关于缓冲区溢出。C字符串无法杜绝缓冲区溢出。比如执行strcat函数时,如果 没有指定足够的内存,那么拼接后会造成缓冲区溢出。SDS在进行修改时,会先查看空 间是否足够,如果不够了,那么它的API会自动的进行空间扩展。用name1的muse去拼接John的时候,之前的bob就会被冲掉。具体情况如下所示:
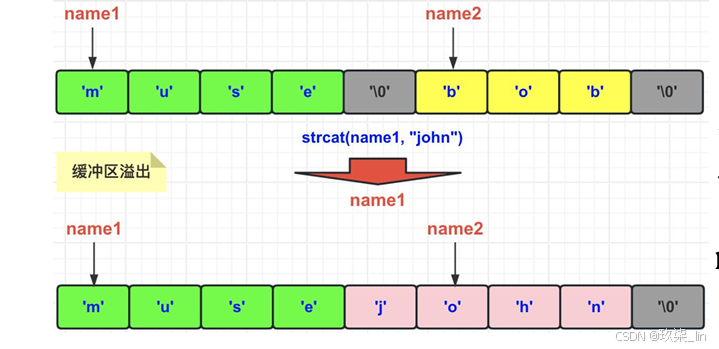
比如:之前name1是muse,name2是bob, 然后忘记在执行strcat操作之前为s1分配足够 空间了,name1变成了musejohn,那么, name2的内容就被修改了。
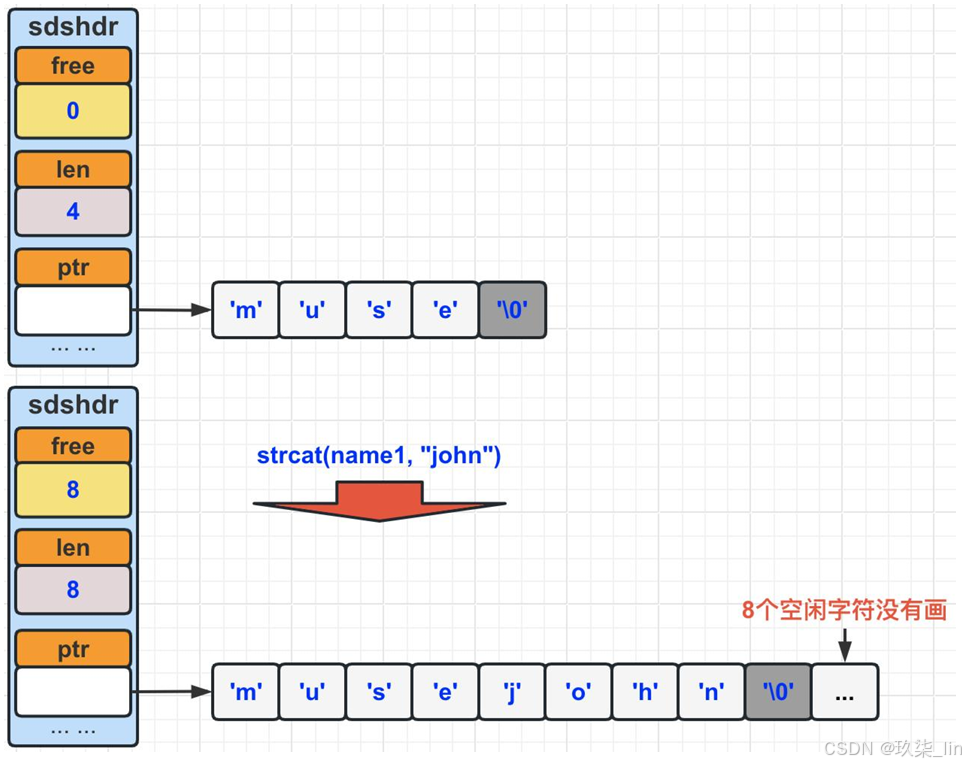
第3点:SDS采用了空间预分配 &惰性空间释放来减少性能消耗。空间预分配:SDS会提前多申请一些空间(如下图)。惰性空间释放:当删除了一些字符,空出来一些空间,这些空间不会被释放,无需跟操作系统交流。而是在sdshdr中更改free记录的空余空间数,当有新的字符串需要这些空间时,直接使用空余的空间,不需要重新请求空间。
(1)SDS空间预分配
如果对SDS进行修改后,SDS的 长度(len的长度)小于1MB的 时候,那么程序分配和len属性同样大小的未使用空间 (free) 。如果大于1MB,那么程序会分配1MB的未使用空 间(free)。
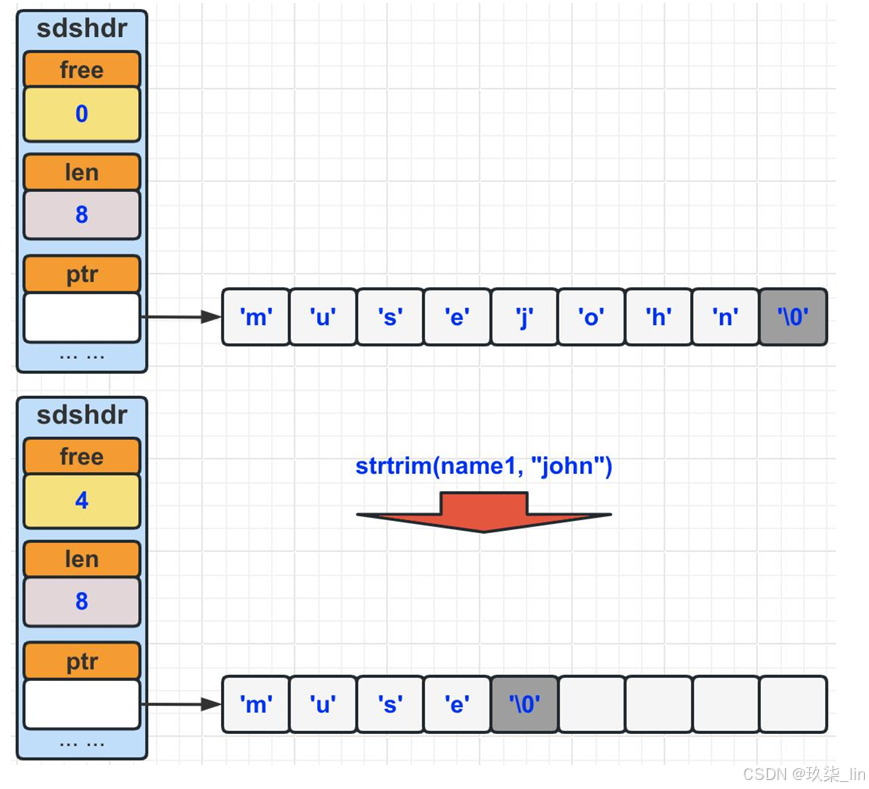
(2)SDS惰性空间释放
当有缩短SDS字符串操作时,程序并不立即把空闲出来的字节释放掉,而是使用free属性将这个空闲的字节记录起 来,等待将来使用。如右图所示:
3. list双向链表
(1)list双向链表源码部分
链表的特点是高效的删除 和新增节点来灵活的调整链表中的元素顺序。
由于C语言没有内置链表,所以Redis自己构建 了链表的实现。
Redis基本数据结构中的REDIS_LIST,底层的实 现之一就采用的链表。即:当包含了很多元素, 或者元素中有比较长的字符串时,就会采用链 表作为REDIS_LIST的底层实现。
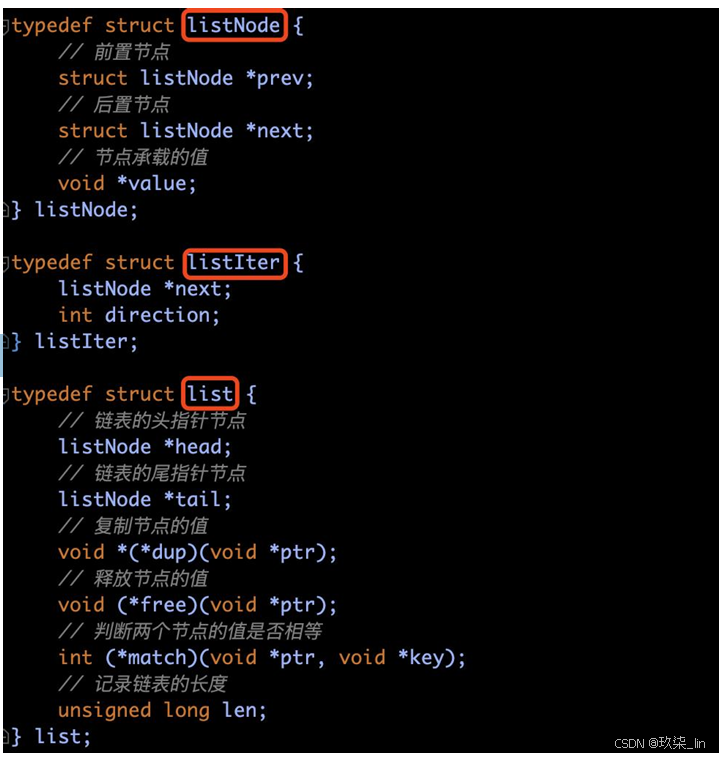
(2)list双向链表数据结构及特点
双端:具有prev和next指针,获取某个节点的前置/后置节点的复杂度为O(1)。
无环:头节点的prev=NULL,尾节点的next=NULL,对链表的访问以NULL为终点。
带表头/表尾指针:list结构中包含head指针和tail指针,所以获得链表头节点/尾节点的复杂 度为O(1)。
多态性:可以通过设置dup、free、match这三个不同类型特定函数,保存各种不同类型的 节点值。
List双向链表数据结构:
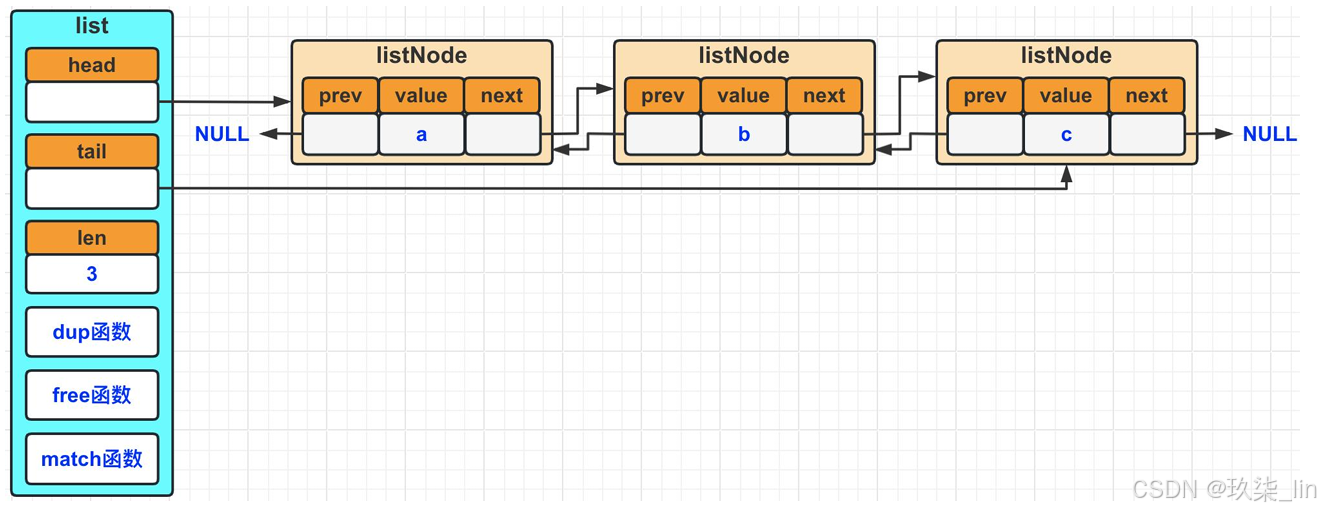
Head指向链表头,tail指向链表尾,len记录了链表的长度,当链表中新增或删除节点后,len记录的值会相应变化。如果想要获得链表的长度时,直接返回len记录的值即可,无需每次都去计算链表的长度。
4. 哈希表
(1)哈希表源码部分
字典又被称为符号表、关联数组、 映射(map)。是一种用于保存 键值对的抽象数据结构。
C语音并没有内置这种数据结构, 因为Redis构建了自己的字典实 现。
字典是哈希键的底层实现之一, 当一个哈希键包含的键值对比较 多,又或者键值对中的元素都是 比较长的字符串时,Redis就会 使用字典作为哈希键的底层实现。
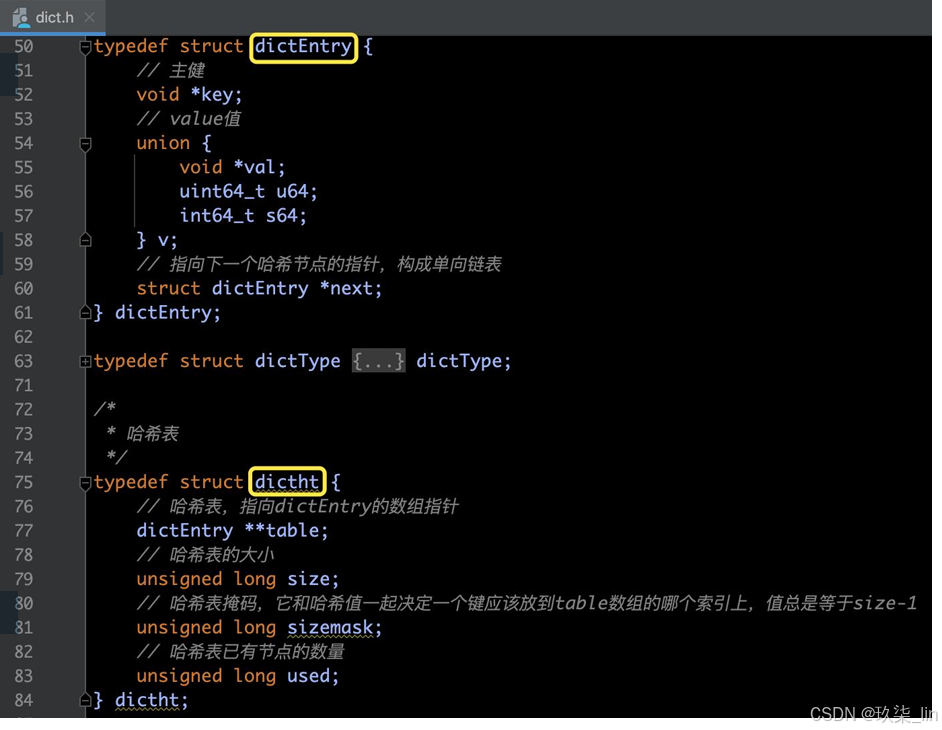
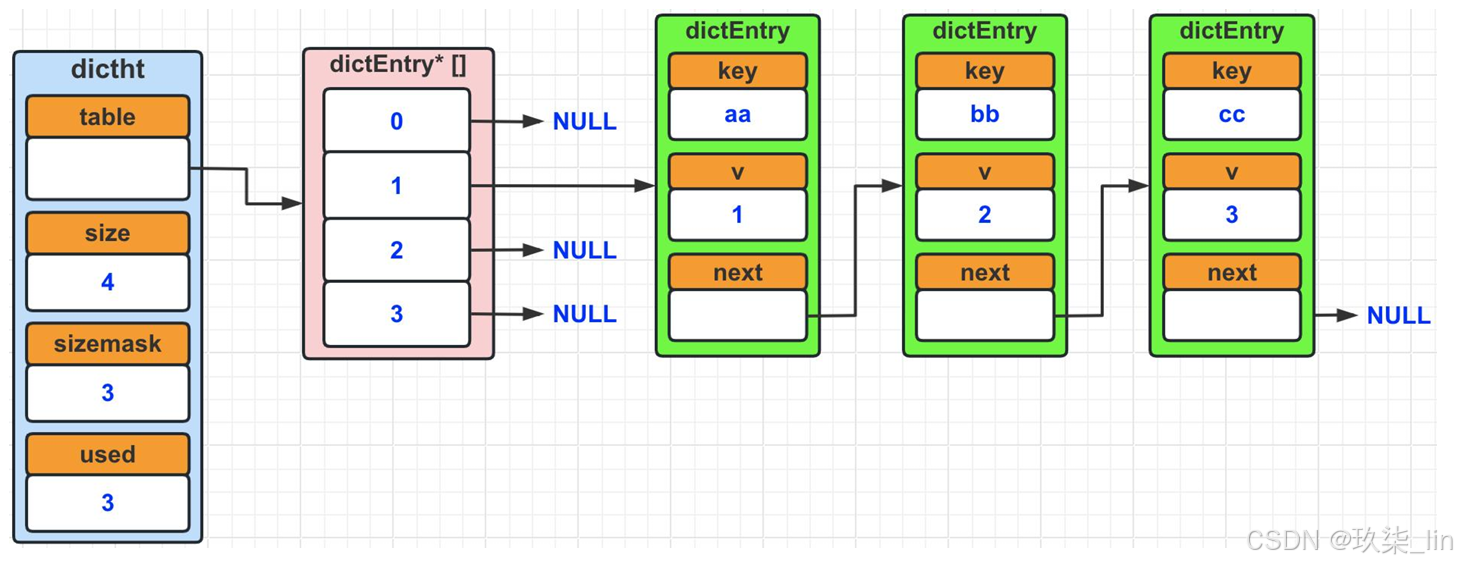
(2)哈希表数据结构
类似于hashtable,数组+链表的形式。
5. dict字典
(1)dict字典源码部分
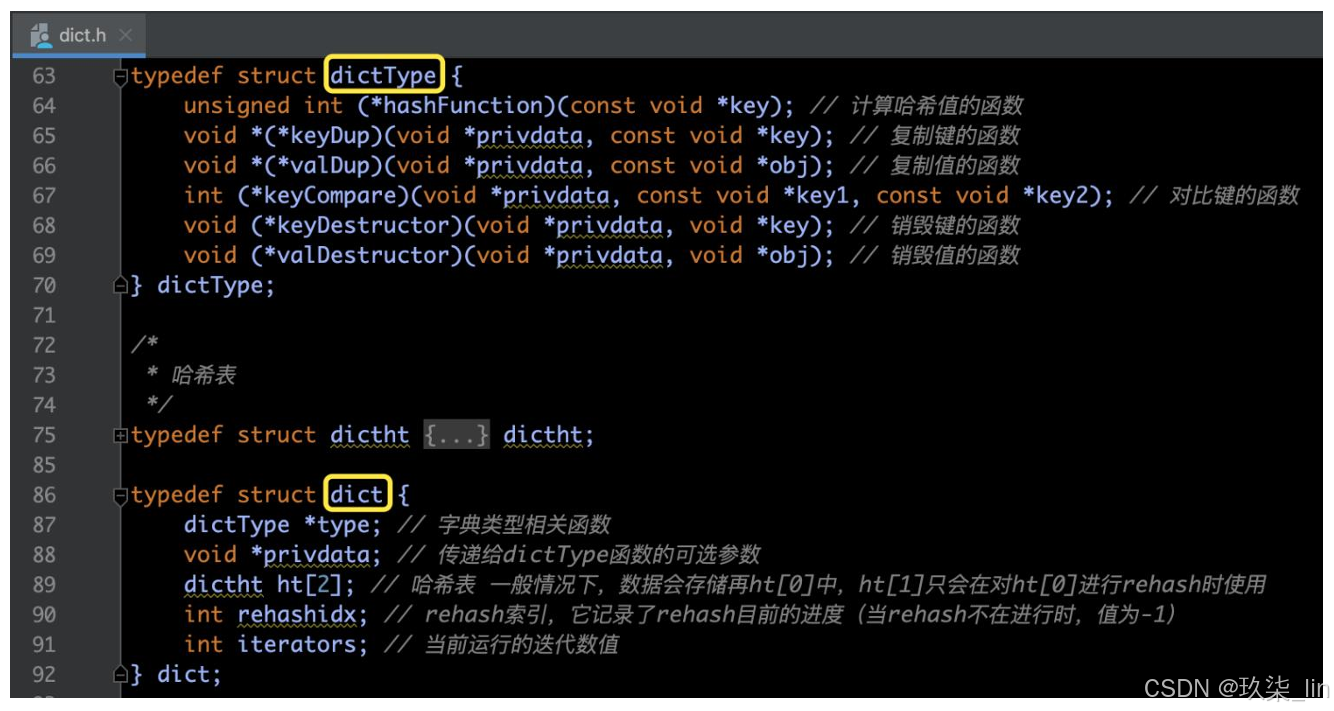
(2)Dict字典数据结构
更复杂的hashtable
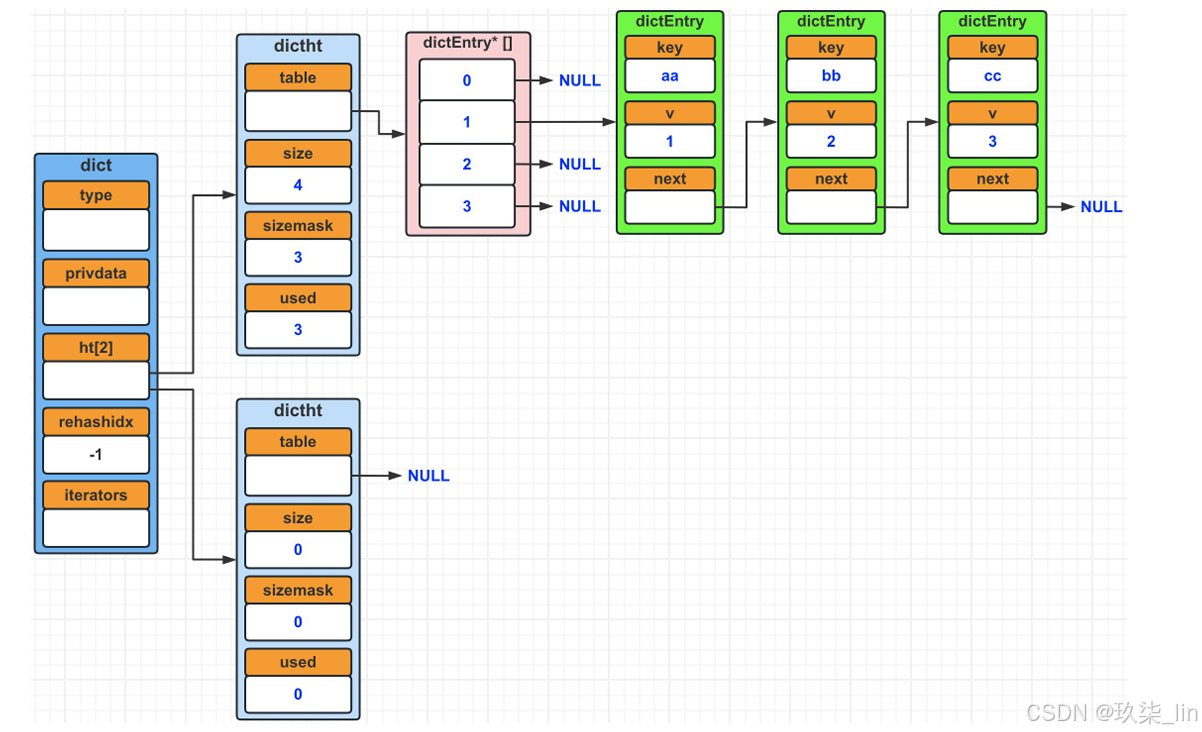
6. skiplist跳跃表
(1)skiplist跳跃表源码部分
跳跃表是一种有序数据结构。
Redis使用跳跃表作为有序集合键的底层实 现之一,如果一个有序集合包含的元素数 量比较多,或者有序集合中元素的成员是 比较长的字符串时,Redis就会使用跳表来 作为有序集合的底层实现。
Redis只在两个地方用到了跳跃表: ① 实现有序集合键。 ② 在集群节点中用作内部数据结构。
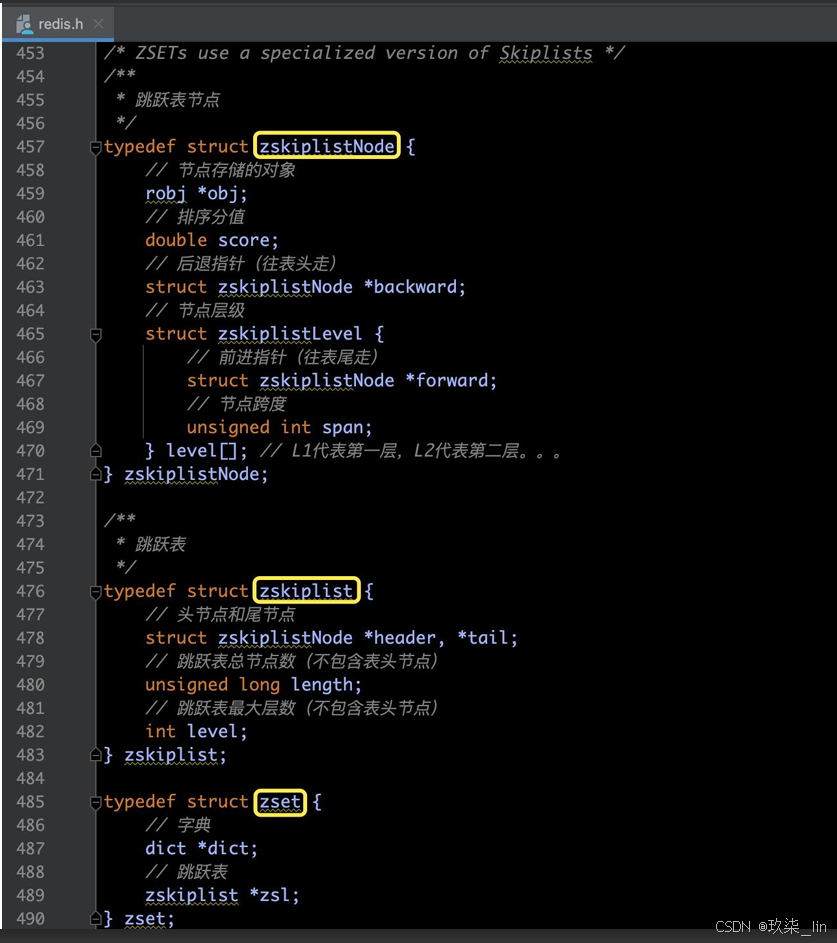
(2)跳表的数据结构
空间换时间的解决方案。层数越多,查询效率越高,类似于查字典。默认有32层。查找的时候是同层查找,span是跨度,也就是同层跨越几个节点。Forward是向后查找,如果找不到,要backward去一一查找
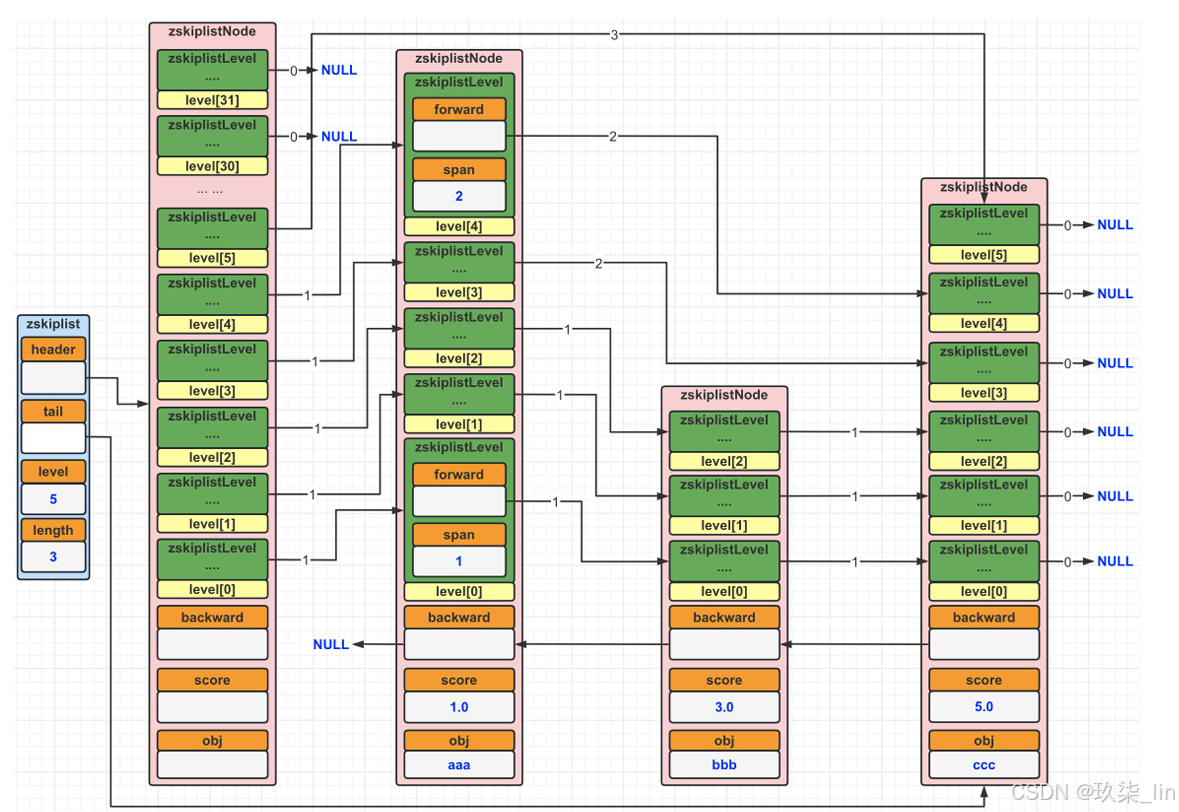
表结构包含了层级信息和节点信息
(3)skiplist跳跃表的使用
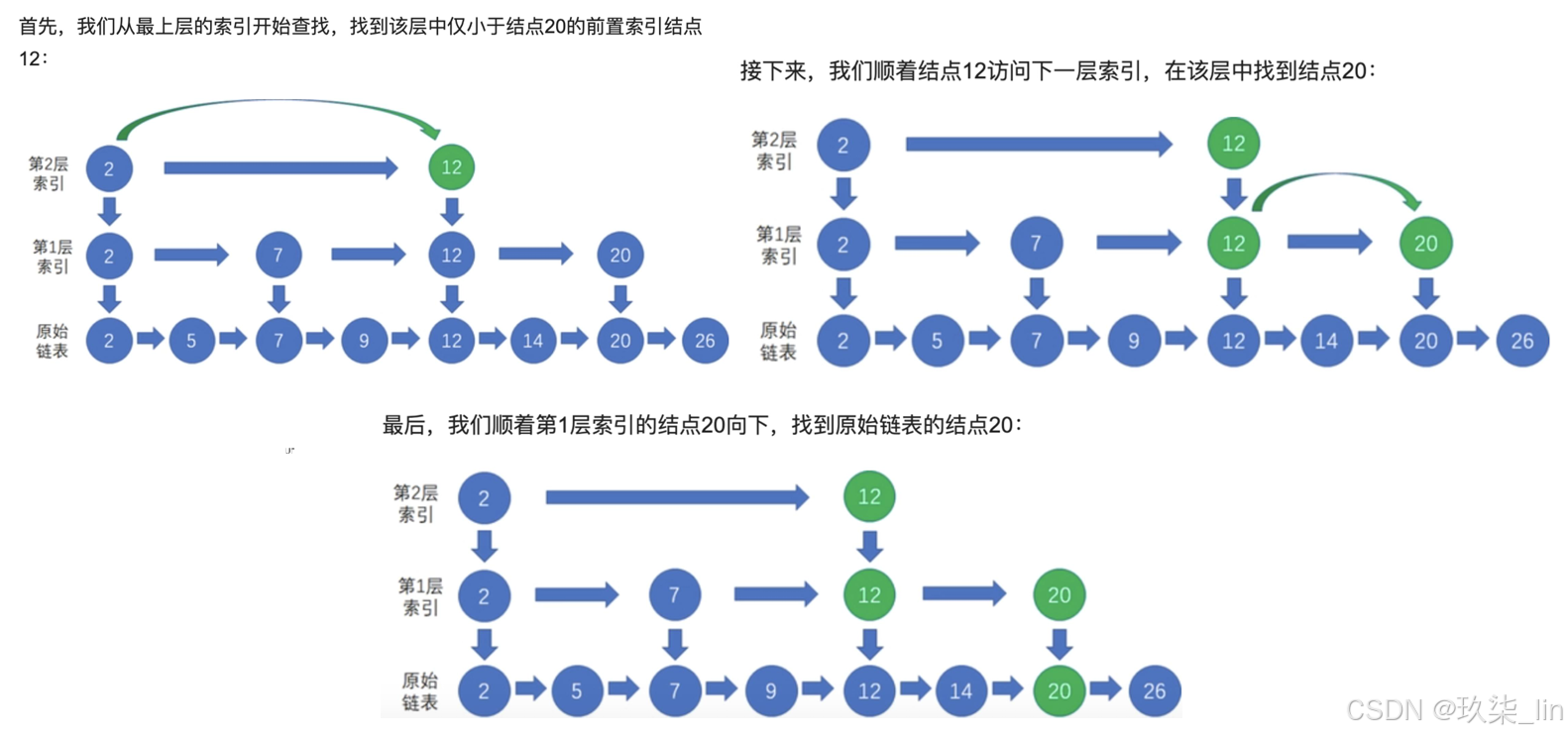
五、Redis 持久化
1. RDB概述
RDB持久化支持手工执行和服务器定期执行,RDB持久化产生的文件是一个经过压缩的二进 制文件,对应文件为dump.rdb,因为它保存在磁盘上,所以可以用它来还原数据库中的数 据。宕机重启后,通过读取二进制文件dump.rdb,将数据还原回来。
++保存手工执行RDB保存有两个命令:SAVE命令和BGSAVE命令。++
SAVE命令会阻塞Redis服务器进程,直到RDB文件生成完毕都会一直处于阻塞状态,不能处理任何的Redis命令请求;BGSAVE命令会fork一个子进程来生成RDB文件,Redis 服务器进程不受影响,可以继续处理命令请求。
当服务器启动的时候,RDB自动执行加载,没有专门的命令来加载RDB文件。只要Redis启 动时检测到RDB文件的存在,那么就会自动载入RDB文件。加载过程中,会一直处于阻塞状 态,直到加载完毕为止。由于AOF文件的更新频率一般比RDB文件的更新频率高,所以,如 果服务期开启了AOF持久化功能,那么就优先加载AOF文件,否则,加载RDB文件。
RDB(Redis database) & AOF(Append Only File):
Redis的数据存储在内存中,如果宕机了,不作持久化的话,数据就会丢失。
2. RDB的备份与恢复
BGSAVE执行条件检测器------serverCron
serverCron默认每100毫秒 执行一次条 件验证,如果符合保存条件,则执行 BGSAVE命令。
它会通过dirty 和lastsave(间隔时间= 当前时间-lastsave时间)这两个参数, 来判断是否执行BGSAVE命令。
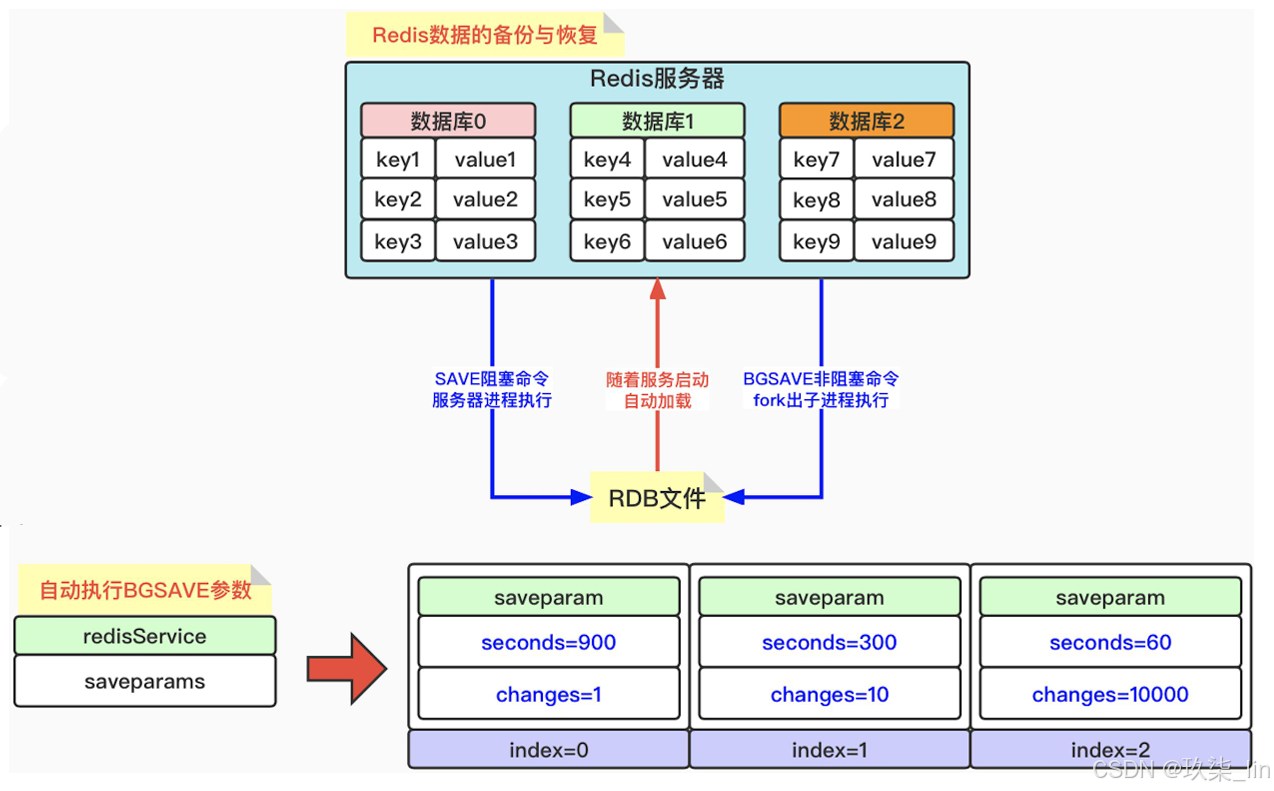
SAVE和BGSAVE生成RDB文件,随着服务启动自动加载进内存中(图片右上角)。
Cron表达式:定期去执行。
RDB和AOF的区别:
BGSAVE将数据保存到库里边,AOF是将对应的指令保存到文件里。
3. AOF概述
AOF(Append Only File)持久化,它是通过保存Redis执行命令来记录数据库数据变更。 持久化流程如下所示:

如何开启AOF和配置AOF路径------redis.conf文件:

AOF的持久化分为三步:命令追加------>文件写入------>文件同步 ,如果打开AOF后,每 次执行完一个写命令之后,都会把写命令以请求协议格式保存到aof_buf缓冲区的末尾。
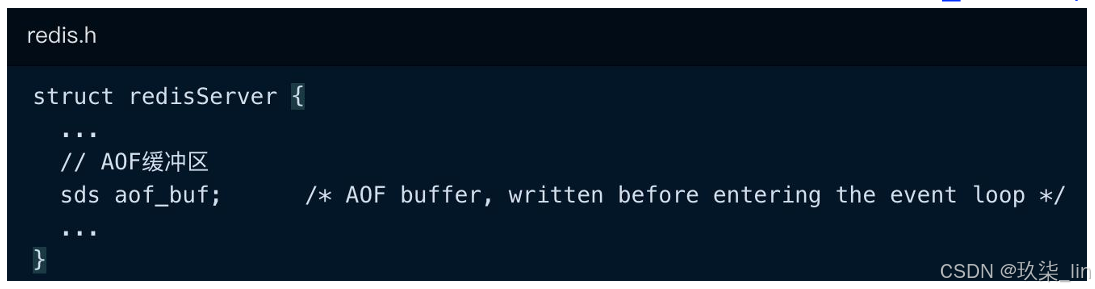
AOF是对指令进行备份,先将数据持久化到数据库,然后再将改变写入AOF文件中。
写入和同步都是OS级别的,调用write函数时,将数据放入操作系统的缓存中,在一定时间范围内,将缓存中的数据刷到磁盘上,写入 是写到缓存?缓冲中,同步是将缓存?缓冲中的数据刷到真正的磁盘上。
AOF怎么使用:在一个客户端输入操作命令,例如"set name muse",然后打开AOF文件:"BGREWRITEAOF",再打开另一个客户端,cd redis/src cat appendonly.aof,可以从.aof文件中看到前一个客户端中所做的Redis操作命令。在读取.aof文件时,将其中记录的指令再执行一次,达到恢复数据库操作的目的。
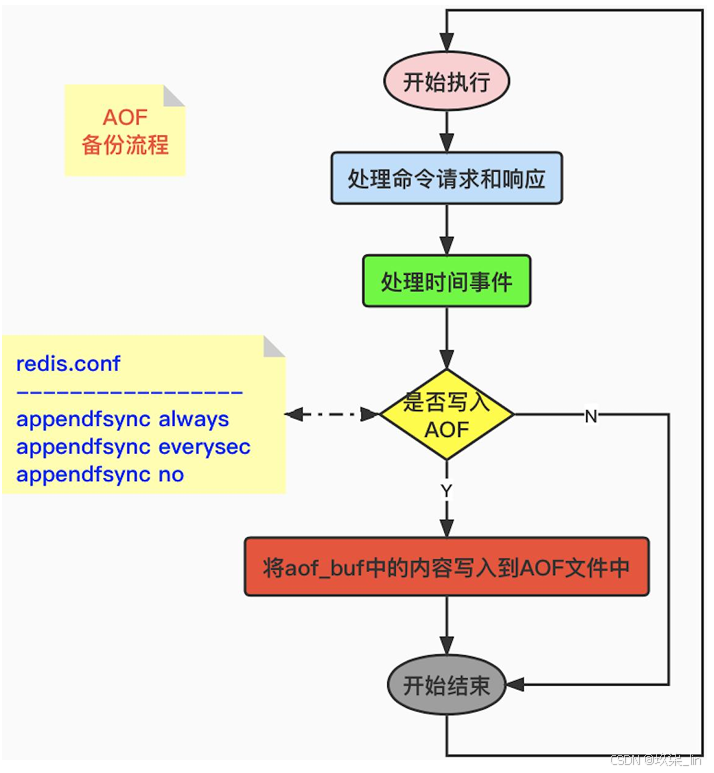
Redis的服务器进程就是一个事件循环,在这个循环中:
- 文件事件负责接收客户端的命令请求和发 送给客户端执行结果回复。
- 时间事件负责执行如serverCron这种需要 定时运行的函数。
- 当每次一个事件循环结束之前,都会调用 flushAppendOnlyFile函数,来判断是否需要 将aof_buf缓冲区中的内容写入和同步到 AOF文件中。
- 其中,flushAppendOnlyFile函数的行为由 appendfsync配置决定(redis.conf文件中)
4. appendfsync配置详解

5. 什么叫写入?什么叫同步?有什么区别呢?
为了提高文件的写入效率,在现代操作系统中,当用户调用write函数时,将一些数据写 入到文件的时候,操作系统通常会将写入数据暂时保存在一个内存缓冲区里面,等到缓冲 区的空间被填满、或者超过了指定的时限之后,才真正地将缓冲区中的数据写如到磁盘里 面。
这种做法虽然提高了效率,但也为写入数据带来了安全问题,因为如果计算机发生停机, 那么保存在内存缓冲区里面的写入数据将会丢失。
为此,操作系统提供了fsync和fdatasync两个同步函数,它们可以强制让操作系统立即将 缓冲区中的数据写入到磁盘里,从而确保写入数据的安全性。

6. AOF加载流程
当Redis服务启动并读取AOF,即可恢复关闭前的数据状态。加载流程如下:

Fack Client(伪客户端)的执行命令效果与带网络的效果完全一样。由于载入AOF时, 命令来源于AOF文件,而不是网络连接传递过来的命令,所以,建立了一个没有网络连接 的伪客户端。
Redis服务启动的时候,如果检测到了AOF,就会先加载AOF,如果AOF是关闭的或者检测不到,就以RDB为主。
伪客户端的作用:执行指令,恢复数据。执行完毕,自动关闭伪客户端。
7. AOF重写
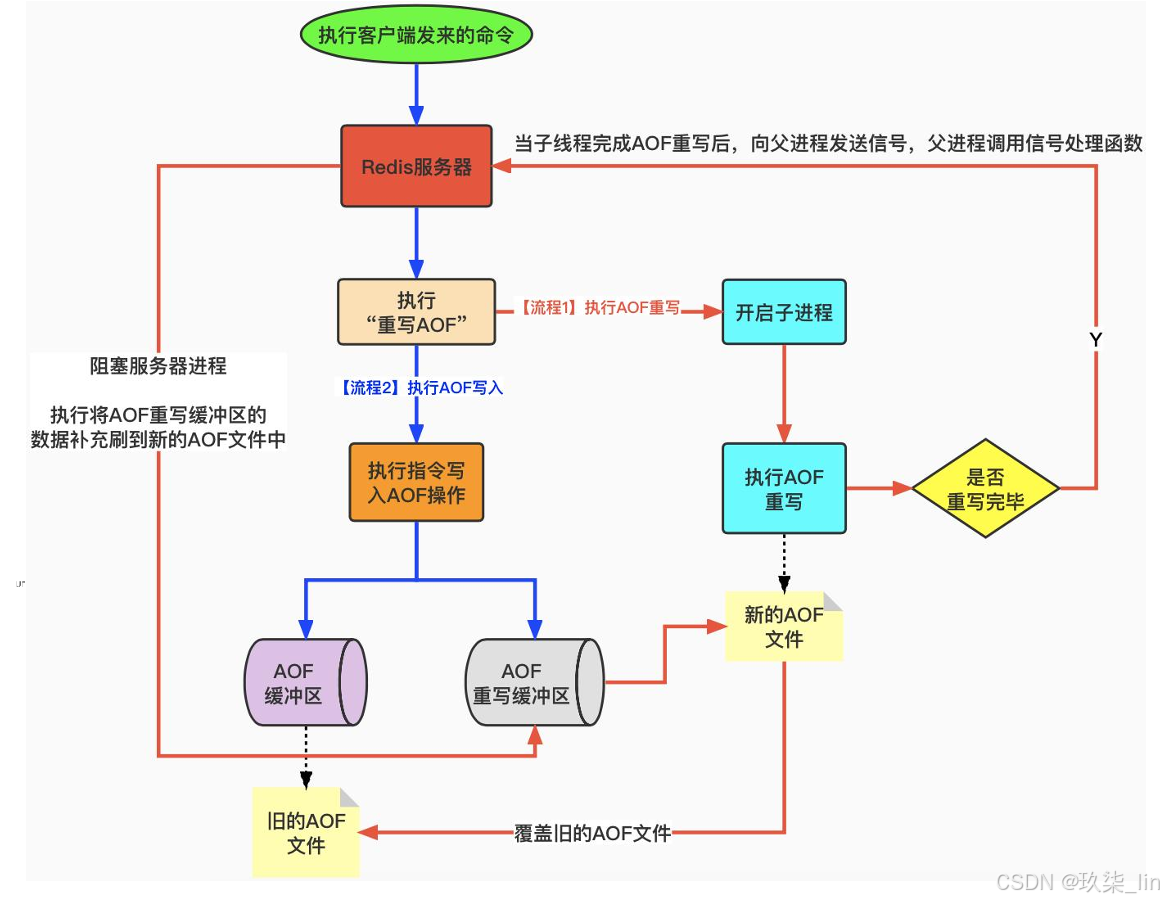
AOF重写:基于数据重新生成一份AOF,实现AOF瘦身(对指令进行备份)。当重写的时候,Redis不能再做别的操作,防止造成数据不一致的问题,但是当操作数据频繁时,AOF重写不方便,于是创建AOF的时候,开启一个子进程,在子进程中进行重写操作。
Redis.conf文件中:
Auto-aof-rewrite-percentage 100:比上一次重写的大小增多了100%时,会自动触发重写(体积)
Auto-aof-rewrite-min-size 64mb:AOF文件超过了64M的时候,触发一次重写。
流程图中:
【执行"重写AOF"】如果不满足(当不需要重写的时候),则执行【执行指令写入AOF操作】,然后进入【AOF缓冲区】步骤,当需要重写的时候(redis.conf文件中判断),执行【开启子进程】,重写是基于当前的数据快照写入的,如果在3:00到3:05分执行重写操作,那么在这5分钟的时间内对于数据库进行的新操作,会写进【AOF重写缓冲区】,该缓冲区与重写操作同步开启。在3:05重写完成后,精简后的操作步骤写入【新的AOF文件】,重写完成后【向父进程发送信号,父进程调用信号处理函数】,然后【阻塞服务器进程】,该位置的阻塞是为了将【AOF重写缓冲区】中的数据补充到【新的AOF文件】中,因为时间比较短,【AOF缓冲区】中的指令也不会很多,通过将redis停止掉,将额外的数据补充到【新的AOF文件】,这个过程速度很快,然后用【新的AOF文件】【覆盖旧的AOF文件】,覆盖完成后,再将进程放开,就可以正常地对外提供服务了。
六、三种特殊数据类型
1. geospatial地理位置
快递,外卖等使用场景
可以用于基于地理位置的业务场景。比如:查询两地之间的距离,方圆几里存在的地理 位置等等。经纬度查询https://jingweidu.bmcx.com。
(1)创建数据集:
GEOADD key(city) 经度 纬度 cityname
(2)查询两地之间的距离
GEODIST city beijing shanghai km
(3)GEOHASH:52位长度的编码,通过hash可以表示经度和纬度
GEOHASH city beijing shanghai haerbin (返回的是三个位置的hash编码)
(4)获得某个位置的经纬度:
GEOPOS city Beijing
(5)查看所有的city
ZRANGE city 0 -1
(6)雷达圈寻,查找指定坐标在某个半径范围内包含的所有位置
GEORADIUS city 116 40 1500 km WITHCOORD WITHDIST ASC
查询在以(116,40)为圆心,1500km为半径的圆圈范围内的所有地址,以升序返回【地址名称】【距离圆心的长度】【该位置的经度和纬度】
(7)雷达圈寻,查找指定city在某个半径范围内包含的所有位置
GEORADIUSBYMEMBER city beijing 1500 km WITHCOORD WITHDIST ASC
2. hyperloglog预估集合的基数
不精准但是快,适用于量大但是对具体数据要求不敏感的,例如对接口的访问量级,看柱状图的数据
hyperloglog常用的使用场景,一般是非精准性的统计计数。比如:统计访问网站的UV 数,商品评论数或点击量等等。
HyperLogLog 是一种用于计算唯一事物的概率数据结构(从技术上讲,这称为预估集合 的基数)
它占用的空间很小,只需要12KB的内存,可以存储2^64不同的元素数量。但是它的统 计是有小于1%的误差,所以并不适合精准统计使用场景。
(1) 新建数据集并向内新增元素
PFADD user muse bob tom tony muse
(2) 计数
PFCOUNT user
返回 4 。有去重的作用
(3) 两个数据集合并
PFADD vip james muse cartern (创建另一个数据集vip)
PFMERGE alluser user vip (合并user和vip数据集)
PFCOUNT alluser (去重计数)
返回6
3. bitmap位图
不占空间,效率较高。Hyperloglog和bitmap适用于大数据量,用来看统计结果,而不是明细的场景。
可以利用bitmap指定其二进制位是0或1,来实现类似"是"or"否"的相关操作。它的 特点也是占用内存空间特别的小。比如,我们要记录每个用户当天是否活跃(即:是否 登录过系统),那么如果我们要记录他一年的是否登录的记录,只需要365个bit即可存 储。
七、事务管理
半事务,保证语句的原子性,不能保证其他
事务管理:用于保证指令的原子性,功能没有很强大。
事务的本质,其实就是一组命令的集合。一个事务中的所有命令都会按照命令的顺序去 执行,而中间不会被其他命令加塞。
DISCARD:放弃事务的执行
EXEC:执行事务
MULTI:开启对应的事务
UNWATCH:解除监控
WATCH:监控
:
示例:同一IP和端口开启两个客户端用作测试
客户端1:set account 1000
客户端1和2:get account ,返回结果均为1000
客户端1:开启对应的事务: MULTI
客户端1:进行一系列的操作
set account 2000
set account 800
set account 500
以上三条指令将操作加入到队列,其实还没有真正执行。在客户端2查不到这三条指令所做的更改。如果要真正地执行,需要EXEC,这是依次执行以上三条指令,中间不能再插入其他指令(单进程执行)。
客户端1:EXEC
这时再get account返回的是500
客户端1:MULTI 开启事务
set account 2000
set account 800
客户端1:DISVARD 放弃执行事务
get account
返回的是500,设置为2000和800的两条指令不会操作。
事务监控功能:
客户端1:WATCH account
客户端1:MULTI
客户端1:set account 1000
客户端1:set account 1500
客户端1:set account 700
客户端2:get account 返回500
客户端2:set account 5000
客户端2:get account 返回5000
客户端1:EXEC
客户端1:get account 返回的不是700,而是5000.
以上结果的原因是:客户端1开启事务之前开启了WATCH监控功能,此时可以发现在客户端2对account进行了修改,于是在客户端1队列中的事务操作就会放弃执行。
如果不开启WATCH监控功能:(现在账户是5000)
客户端1:MULTI 开启实物功能
客户端1:set account 1000
Set account 700
客户端2:set account 500
客户端2:get account 返回500
客户端1:EXEC 执行成功
客户端1:get account 返回700
因为没有开启WATCH监控功能,所以客户端2进行了更改之后,再去执行事务操作,依旧可以成功。
事务管理需要注意的两点:
- 每次需要监控,都要在开启事务之前开启监控功能
- 针对命令语法错误,会导致整个事务 执行被中断;针对执行中的运行操作错误(异常),只会导致该条指令的执行失败,不会影响事务中的其他指令。(示例如下)
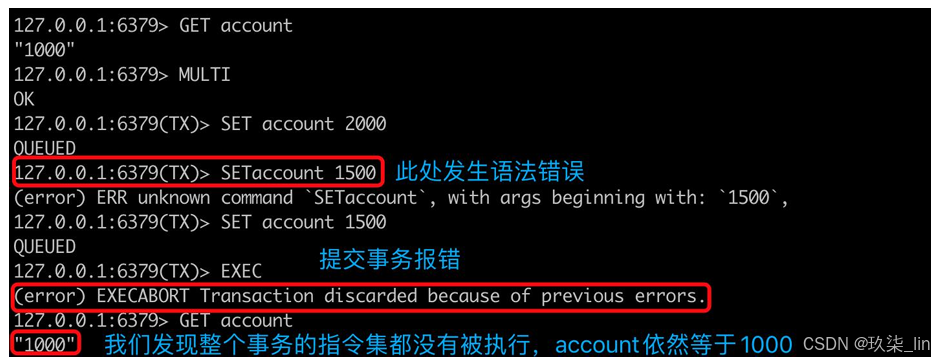
++针对命令语法错误++:
本来account中是700;
客户端1:MULTI
客户端1:set account 2000
客户端1:setaccount 1500 执行时会报错(语法错误)
客户端1:set account 1500
客户端1:EXEC 执行时报错
客户端1:get account 返回700,即事务中的指令都不会执行
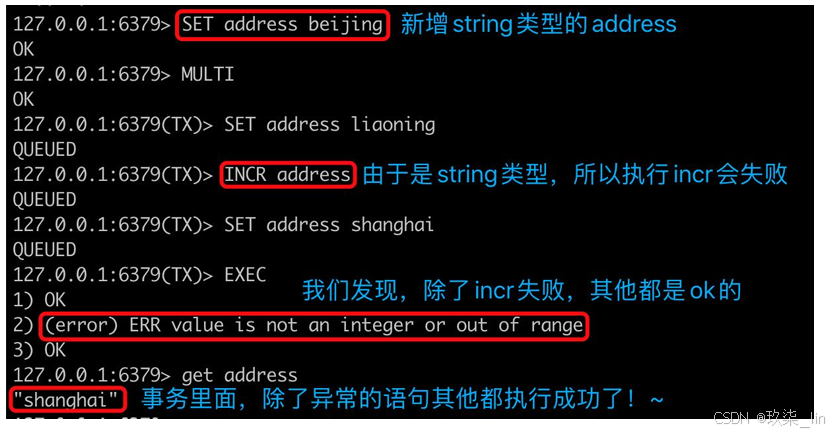
++针对执行中的运行异常++:
本来address中存的是beijing;
客户端1:MULTI 开启事务
客户端1:set address liaoning
客户端1:INCR address
客户端1:set address shanghai
客户端1:EXEC 此时回车显示语句1和3执行成功,语句2执行失败
客户端1:get address 返回"shanghai"
事务中异常的处理
命令语法错误:针对语法错误,会导致整个事务 执行被中断
运行操作错误:针对执行中的异常,只会导致该 条指令的执行失败,而不会影响事务 中其他的指令
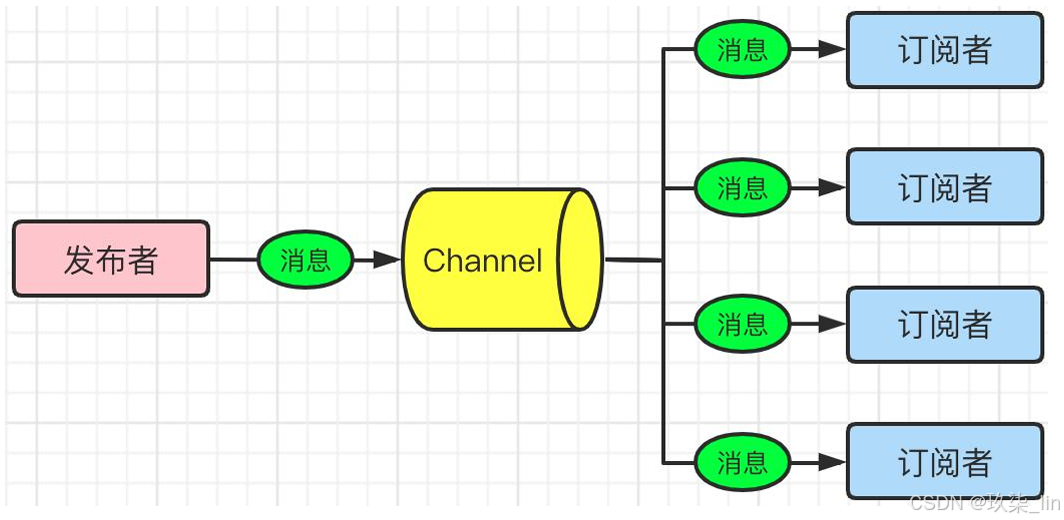
八、发布订阅
如果熟悉消息中间件,那么对发布订阅一定不陌生。发布者Publish一条消息,消息发送 到Channel通道中,然后所有订阅了这个通道的订阅者Subscriber都会接收到这条消息。 如下图所示:
1. Redis针对发布订阅相关指令
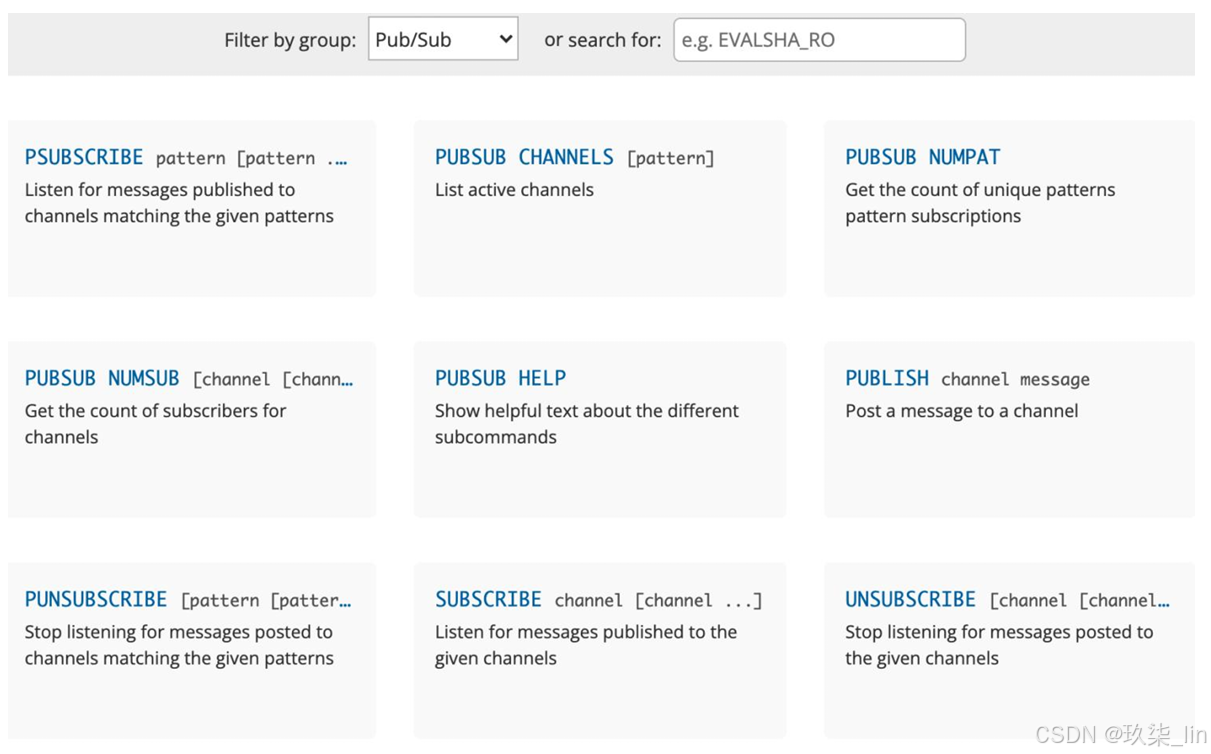
示例:
(1)基础
客户端1:SUBSCRIBE muse
客户端2:PUBLISH muse hello 此时客户端1的控制台会输出message:"hello"
(2)匹配模式pattern
客户端1:PSUBSCRIBE haello
客户端2:PUBLISH hallo 1111 客户端1可以接收到
客户端2:PUBLISH hello 1111 客户端1可以接收到
客户端2:PUBLISH hillo 1111 客户端1接收不到
(3)订阅通道PUBSUB,无法基于pattern
客户端1:SUBSCRIBE muse (这里如果设置的是PSUBSCRIBE m*se,下边第二条也不能订阅成功,因为不基于pattern)
客户端2:PUBSUB CHANNELS muse 客户端2可以订阅成功
客户端2:PUBSUB CHANNELS m1se 客户端2订阅不成功
(4)查看订阅数量 PUBSUB NUMPAT
客户端2:PUBSUB NUMPAT 返回订阅者的数量
客户端2:PUBSUB NUMSUB muse 返回非pattern模式订阅者的数量。
九、主从复制
主从复制,是指将一台Redis服务器的数据复制到其他的Redis服务器。前者称为主节点 (Master/Leader),后者称为从节点(Slave/Follower);数据是从主节点复制到从节 点的。其中,主节点负责写数据(当然有读的权限),从节点负责读数据(它没有写数 据的权限)。默认的配置下,每个Redis都是主节点。
一个主节点可以有多个从节点,但是一个从节点只能有一个主节点,即:主从节点是1 对N的关系。

1. 主从复制的用处
数据冗余:主从复制实现了数据的备份,实际上提供了数据冗余的实现方式。实现高可用性
故障恢复:当主节点出现异常时,可以由从节点提供服务,实现快速的故障恢复,实际上提供了服 务冗余的实现方式。主节点出现故障,从节点用来提供服务,这时主节点可以用来故障恢复。
负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务, 分担服务器的负载;在写少读多的业务场景下,通过多个从节点分担读负载,可以大大提高 Redis服务器是并发量。
高可用:哨兵配合主从复制,可以是实现Redis集群的高可用。
主机宕机之后,从节点依旧无法成为主节点,还是只能提供读操作。
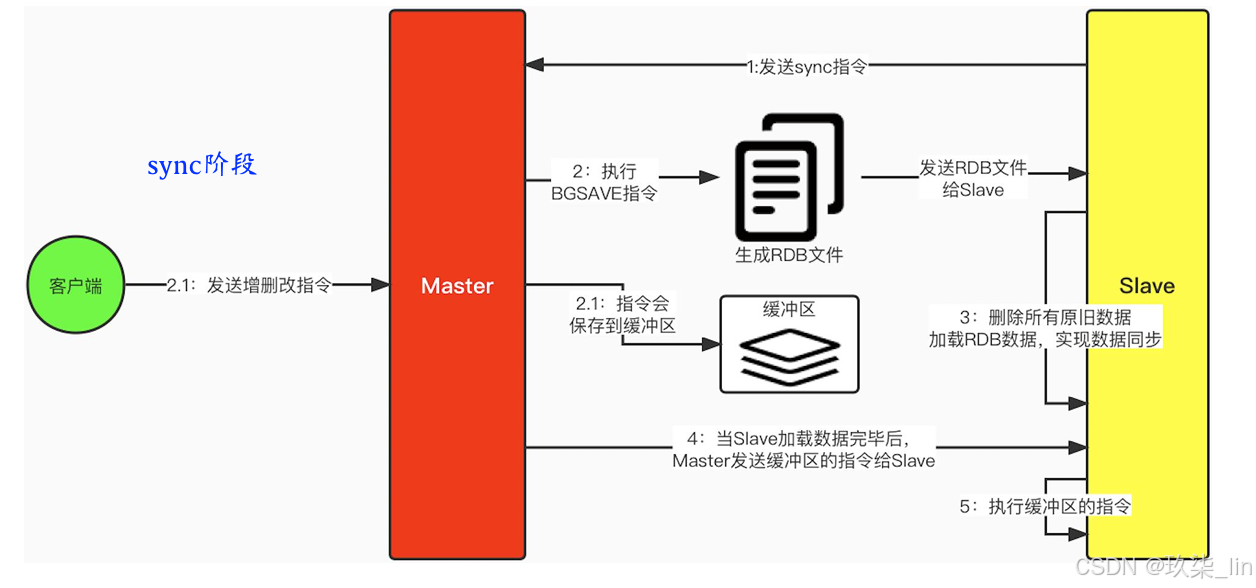
2. 主从复制实现原理
Redis的主从复制可以分为两个阶段:sync阶段和command propagate阶段。当从节点启 动后,会发送sync指令给主节点,要求全量同步数据,此为sync阶段;那么,如果后续 Master节点接收到新的增删改操作,也需要Slave节点接收同步的更新,这就是command propagate阶段;
- psync指令
当主从节点都正在运行的时候,出现了网络抖动,造成连接断开,那么当网络恢复,两个 节点再次建立起连接的时候。从节点发送sync指令后,主节点依然需要重新生成RDB,并 对从节点进行全量数据的同步造成。那么这中间的耗时是非常严重的,并且传输备份文件 也会对网络带宽造成很大的消耗。那么为了解决这个问题,从Redis 2.8开始,引入了 psync指令来代替sync指令。psync指令会根据不同的情况,来确定执行全量重同步还是部 分重同步。
++全量重同步++ :当从节点是第一次与主节点建立连接的时候,那么就会执行全量重同步,这个同步过程 与上面我们介绍的sync阶段+command propagate阶段一样。
++部分重同步++:从节点的复制偏移量无法在复制积压缓冲区中找相应待同步的数据 并且 主节点与从节 点不是第一次同步(根据Redis节点ID判断)
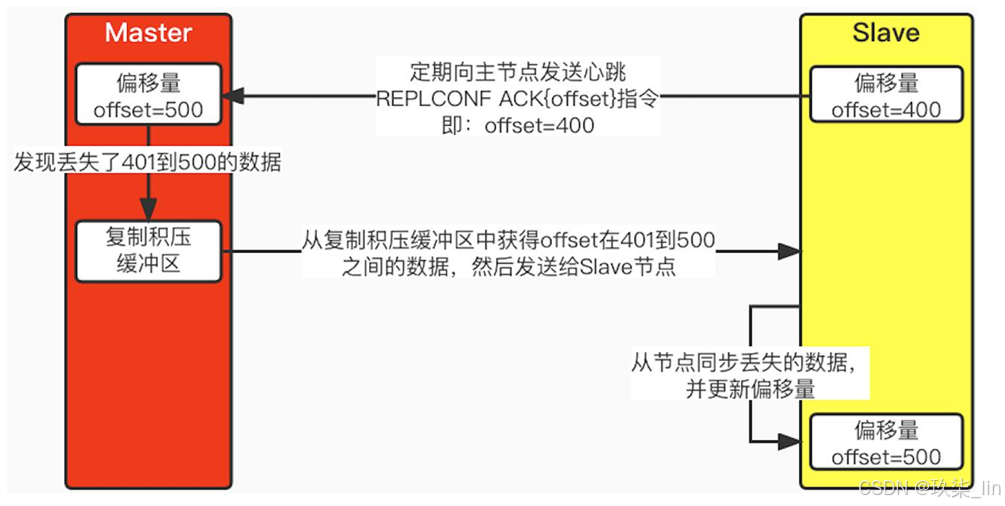
3. 复制偏移量
Master节点和Slave节点都保存着一份复制偏移量。当Master节点每次向Slave节点发送n 字节数据的时候,就会在Master节点偏移量加上n;而Slave节点每次接收到n个字节的 时候,也会在Slave节点偏移量上加n。在命令传播阶段,Slave节点会定期的发送心跳 REPLCONF ACK{offset}指令,这里的offset就是Slave节点的offset。当Master节点接 收到这个心跳指令后,会对比自己的offset和命令里的offset,如果发现有数据丢失,那 么Master节点就会推送丢失的那段数据给Slave节点。如下图所示:
4. 复制积压缓冲区&节点ID
什么是复制积压缓冲区?
复制积压缓冲区是由主节点维护的一个固定长度(默认1MB)的队列。它存储了每个字 节值与对应的复制偏移量。因为复制积压缓冲区的大小是固定的,所以它保存的是主节点近 期执行的写命令。当从节点将offset发送给主节点后,主节点便会根据offset与复制积压缓 冲区的大小来决定是否可以使用部分重同步。如果offset之后的数据仍然在复制积压缓冲区 内,则执行部分重同步;否则还是执行全量重同步。
节点ID:
Redis节点服务启动之后,就会产生一个用来唯一标识Redis节点的ID。当Master节点与 Salve节点进行第一次连接同步的时候,Master节点会将ID发送给Slave节点,Slave节点接收 到会对其进行保存。那么当主从服务之间发生了中断重连的时候,Slave服务器会将这个ID 发送给Master服务器,Master服务器会拿自己的ID进行对比,如果相同,则说明主从之前是 连接过的。否则,则说明是第一次建立的连接。那么,就需要全量去同步数据了。
十、Redis哨兵
我们介绍主从复制的时候发现,主节点挂掉从节点不会自动变为主节点,需要人工的去 配置主节点才可以。但是这种做法费时费力,怎样能让Redis在主节点挂掉的情况下,自 己从从节点中选择新的主节点呢?这时候,就需要使用Sentinel哨兵了。
哨兵本质就是一个Redis实例节点。哨兵模式是一种特殊的模式,它能够后台监控主机是 否故障,如果故障了,则根据投票数自动将Slave节点转换为新的Master节点。 首先 Redis提供了哨兵的命令,哨兵是一个独立的进程,会独立的运行。它的原理是:哨兵通 过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。如下图所示:
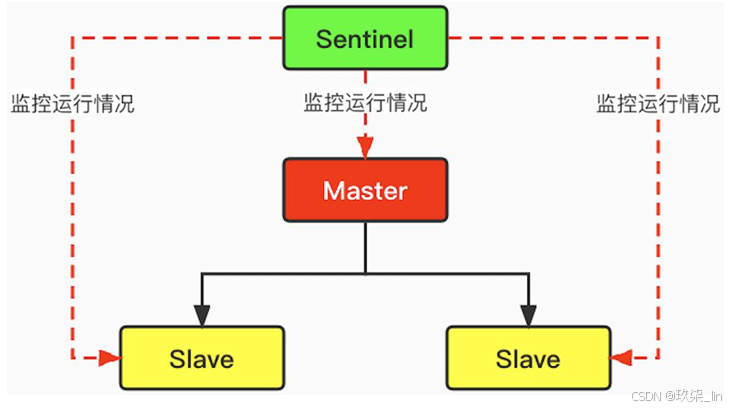
主节点宕机后,推选出新的主节点,这时当重启后,原来的主节点下沉为从节点。这个过程由Sentinel完成,不需要手动去做。是如何做点:重写redis.command文件,在该文件中可以指定主节点是哪一个,重启的时候根据配置文件中设置的主从节点的拓扑图。
多个Sentinel之间不存在主从的概念,是平行角色,会相互监控,多个Sentinel投票选择一个slave作为master。如果Sentinel只剩了一个,就没有了选主的能力。
1. 多哨兵模式
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题。因此,我们可以使用多哨 兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
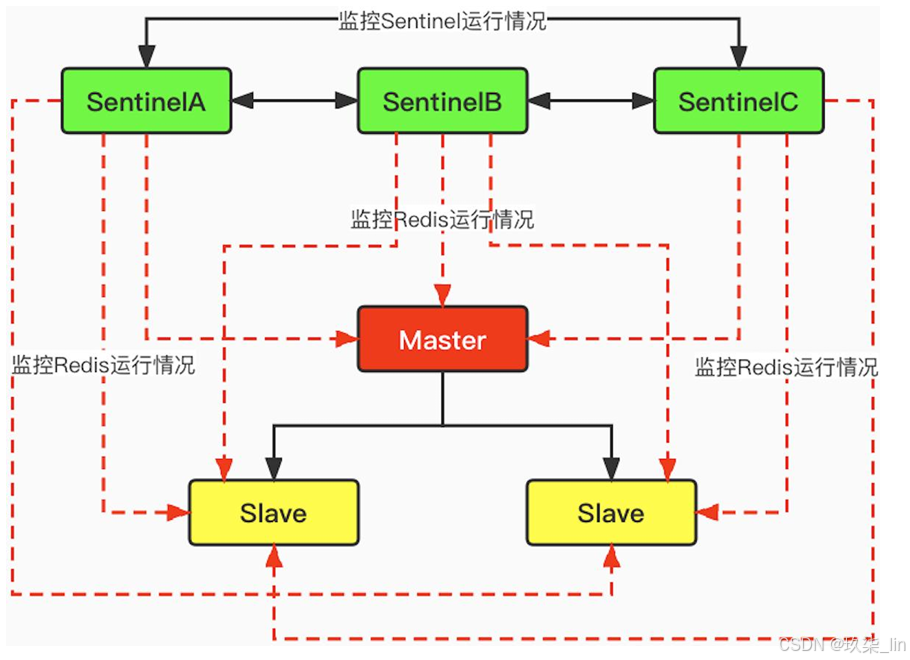
主观节点下线:SentinelA等待master的相应,在规定时间内没有响应,则为主观master下线。
客观节点下线:多个Sentinel对master节点进行的判断。半数以上认为下线则认为master下线。再去根据投票结果选择slave升级为master。
2. 环境搭建(3哨兵 1主2从)
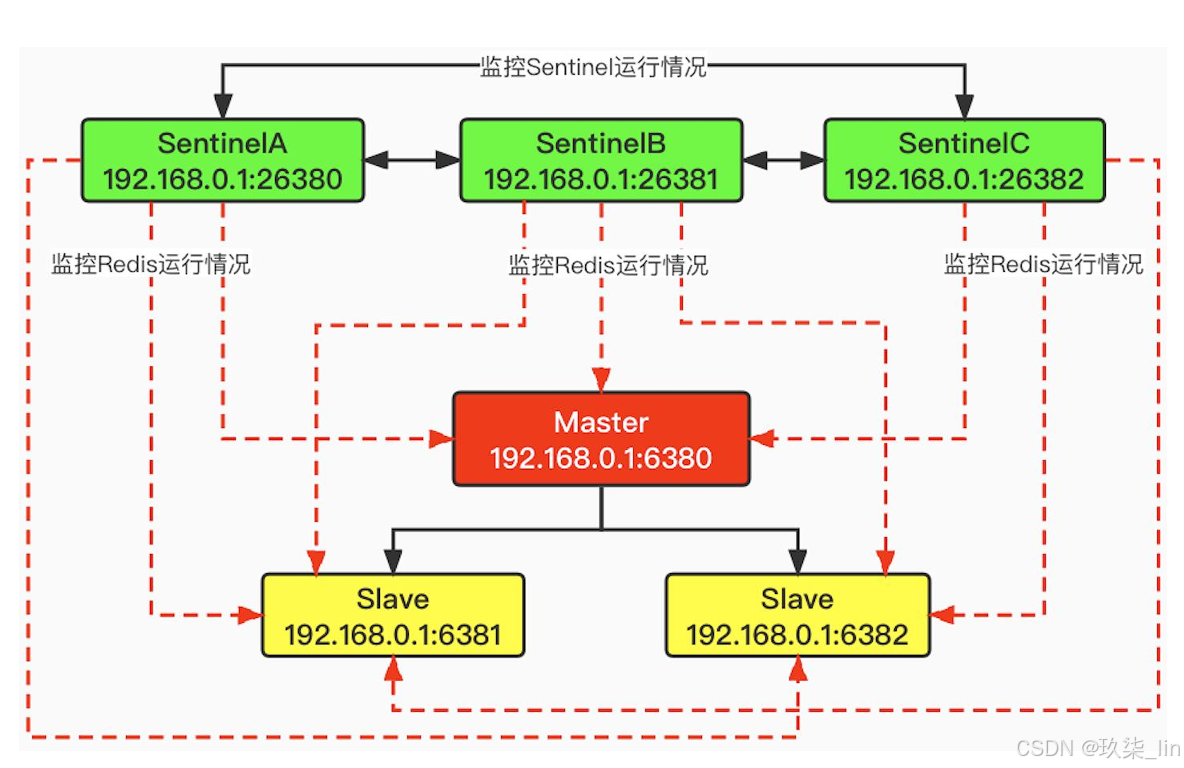
- 哨兵配置文件sentinel.conf
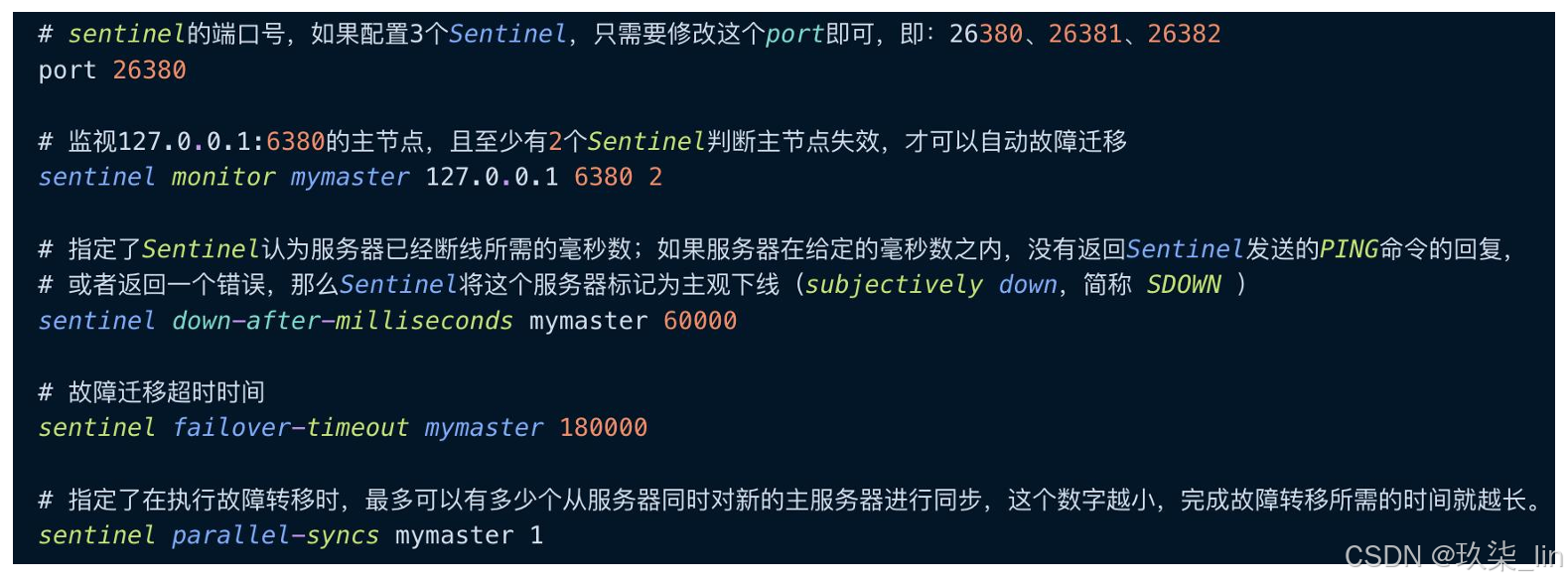 Sentinel是redis的一个进程。只剩一个Sentinel之后无法进行master选举了。
Sentinel是redis的一个进程。只剩一个Sentinel之后无法进行master选举了。
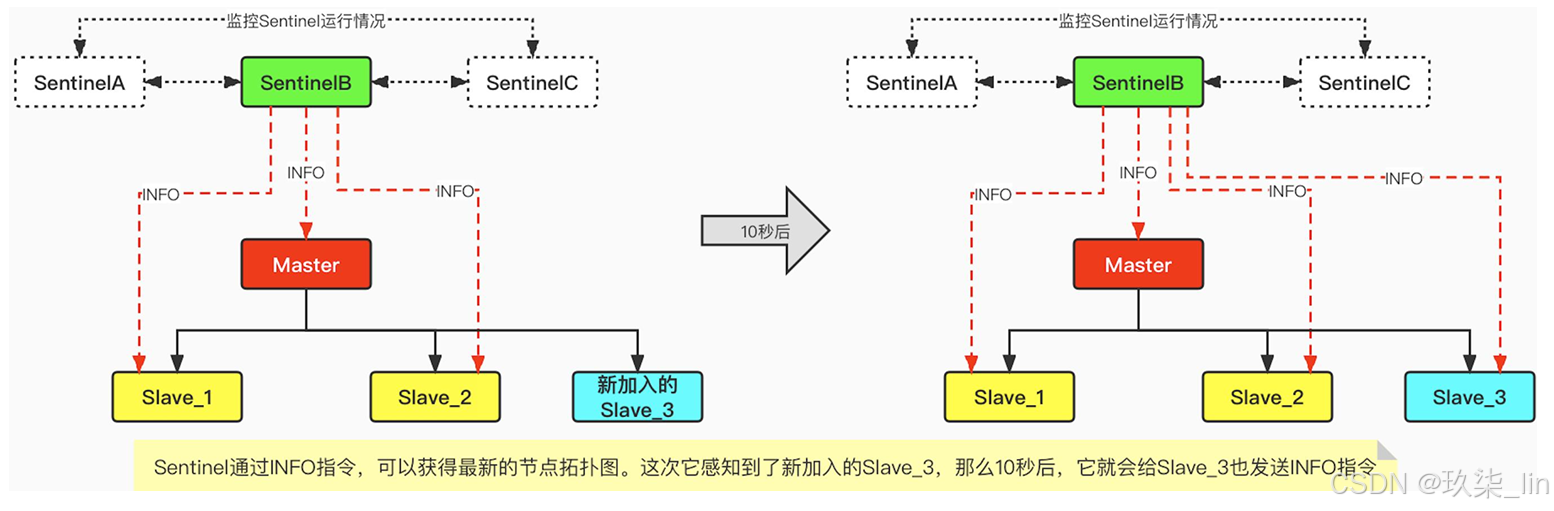
3. INFO指令获得最新节点拓扑图
每个Sentinel每隔10秒就会向主从节点中发送INFO指令,通过该指令可以获得整个redis的节 点拓扑图。那么这时候,如果有新的节点加入或者有节点退出集群,那么Sentinel就可以很 快的感知到拓扑图的变化。如下图所示:
4. 哨兵监测集群状态方法
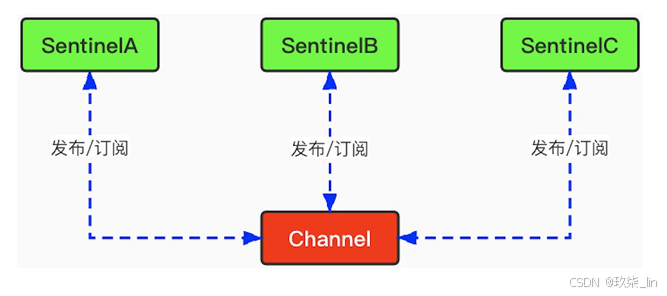
每个Sentinel每隔2秒会向指定频道上发布自己 对Master节点是否正常的判断以及当前 Sentinel节点的信息,并且通过订阅这个频道, 可以获得其他Sentinel节点的信息和对Master 节点是否存活的判断。如图所示:
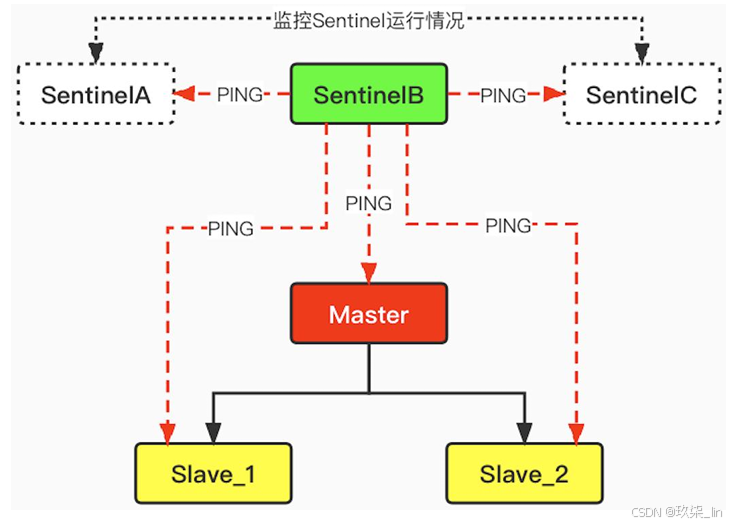
每个Sentinel每隔1秒会向所有节点 (Sentinel节点、Master节点、Slave节点) 发送PING指令来进行心跳检测。如图所示:
5. 选举流程
当一个Sentinel判断主节点不可用的时候,会首先进行"主观下线",此时,这个Sentinel 通过sentinel is-masterdown-by-addr指令获取其他哨兵节点对主节点的判断,如果当 前哨兵节点对主节点主观下线的票数超过了我们定义的quorum值,则主节点被判定为 "客观下线"。
Leader Sentinel 节点会从原主节点的从节点中选出一个新的主节点,选举流程如下:
- ① 首先,过滤掉所有主观下线的节点。
- ② 然后,选择slave-priority最高的节点,如果有则返回,没有就继续下面的流程。
- ③ 选择出复制偏移量offset最大的节点,如果有则返回,没有就继续下面的流程。
- ④ 选择run_id最小的节点,其中,run_id表示服务器运行 ID。
- ⑤ 在选择完毕后,Leader Sentinel节点会通过SLAVEOF NO ONE命令让选择出来的从节 点成为主节点,然后通过SLAVEOF命令让其他的节点成为该节点的从节点。
十一、Redis Cluster
Redis3.0开始引入了去中心化分片集群Redis Cluster。
传统的Redis集群是基于主从复制+哨兵的方式来实现的。但是集群中都只有一个主节点 提供写服务。
Redis Cluster则采用多主多从的方式,支持开启多个主节点,每个主节点上可以挂载多 个从节点。
Cluster会将数据进行分片,将数据分散到多个主节点上,而每个主节点都可以对外提供 读写服务。这种做法使得Redis突破了单机内存大小限制,扩展了集群的存储容量。并且 Redis Cluster也具备高可用性,因为每个主节点上都至少有一个从节点,当主节点挂掉 时,Redis Cluster 的故障转移机制会将某个从节点切换为主节点。
Redis Cluster是一个去中心化的集群,每个节点都会与其他节点保持互连,使用gossip协 议来交换彼此的信息,以及探测新加入的节点信息。并且Redis Cluster无需任何代理, 客户端会直接与集群中的节点直连。
1. 分片方式
(面试 一致性哈希提问多)
(1)哈希取模
这种方式就类似我们使用HashMap时选址的方式,只要hash计算出来的值够散列,那么 每个key都可以均匀的分散到N个节点上。 但是它存在的问题就是,如果要扩容或缩容,会导致key重新计算存储位置,从而导致缓 存失效。
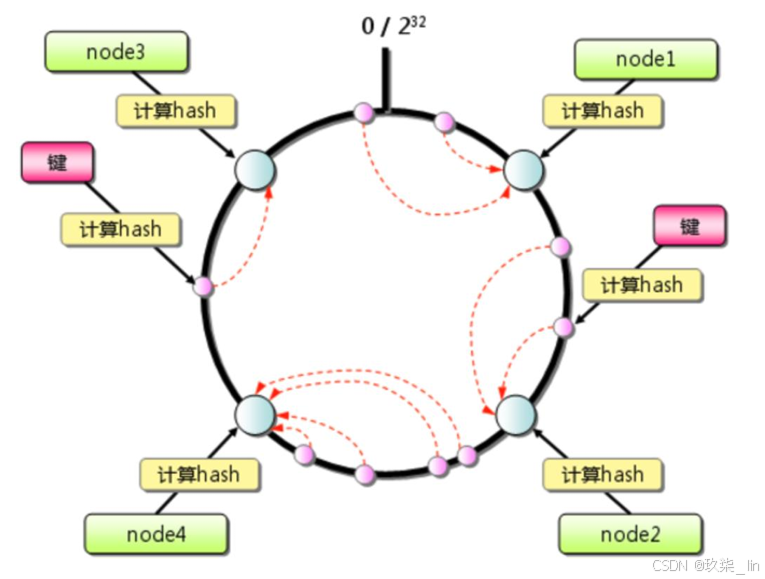
(2)一致性哈希
一致性哈希算法将整个哈希值空间组织 成一个虚拟的圆环,其范围为0 ~ 2^32-1, 如图所示。 我们会先对Key计算它的hash值,从而确 定它在环上的位置。然后从该位置沿着环顺 指针地走,找到的第一个节点,便是这个 Key应该存放的服务器节点的位置。
(3)虚拟节点 + 一致性哈希
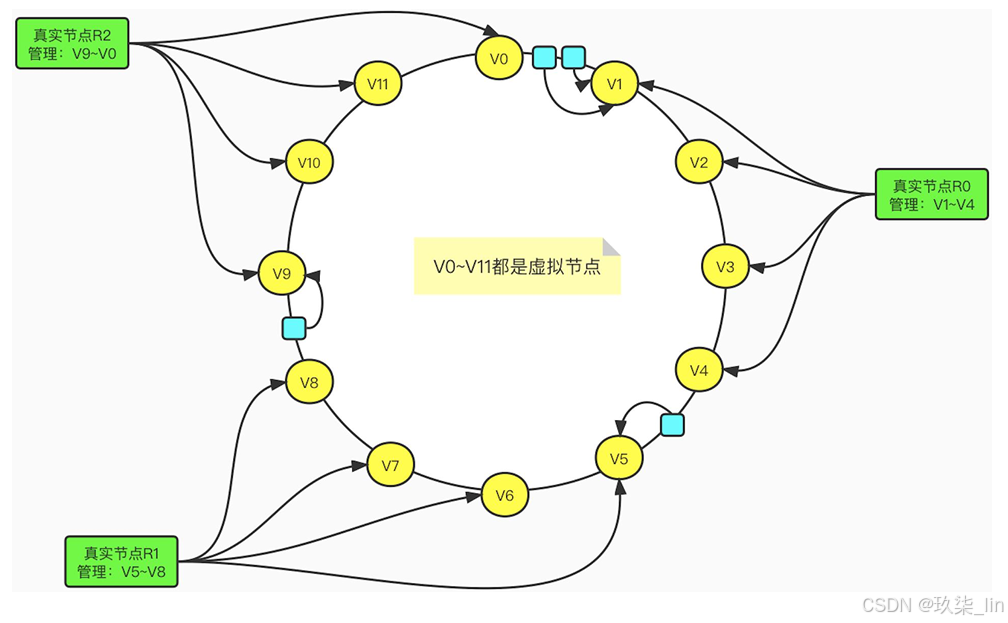
该方案在一致性哈希的基础上,引入了虚拟节点这一概念。原本是由实际节点来"抢占" 哈希环的位置,现在则是将虚拟节点分配给实际节点,然后由虚拟节点来抢占。如图所示:
在引入了虚拟节点这一概念后,数据 到实际节点的映射关系就变成了数据 到虚拟节点,再由虚拟节点到实际节 点了。Redis集群便是采用了这种方 案。一个集群包含16384个哈希槽 (hash slot)也就是16384个虚拟节 点。譬如,我们的集群有三个节点, 那么:
- Master1节点负责处理0~5460号 slot
- Master2节点负责处理5461~ 10922号slot
- Master3节点负责处理10923~ 16383号slot
2. 集群搭建
由于Redis Cluster要求必须要至少6个节点,所以我们就以配置3主3从为例。修改redis 6390.conf ~ redis-6395.conf配置文件
分配主从(--cluster-replicas 1:表示创建1主1从)
- ./redis-cli --cluster create 127.0.0.1:6390 127.0.0.1:6391 127.0.0.1:6392 127.0.0.1:6393 127.0.0.1:6394 127.0.0.1:6395 --cluster-replicas 1
配置完集群后,可能会报错------16384个槽位没有分配完。我们通过如下指令就可以进行检查和修复
- redis-cli --cluster check 172.17.0.2:6379
- redis-cli --cluster fix 172.17.0.2:6379 #官方修复功能
十二、面试
1. 缓存穿透(查不到数据)
当用户想要查询一个数据,发现Redis中不存在,也就是所谓的缓存没有命中,于是这个 数据请求就会打到数据库中。结果数据库中也不存在这条数据,那么结果就是什么都没 查询出来。那么当用户很多时候的查询,缓存中都没有数据,请求直接打到数据库中, 这样就会给数据库造成很大的压力,缓存的作用也就几近于失效了,那么这种情况就叫 做缓存穿透。
解决方案: ① 当数据库中也查询不到数据时,那么将返回 的空对象也缓存起来,同时设置一个过期时 间,之后再访问这个数据将会从缓存中获取, 从而起到保护数据库的作用。 ② 添加布隆过滤器。如图所示:
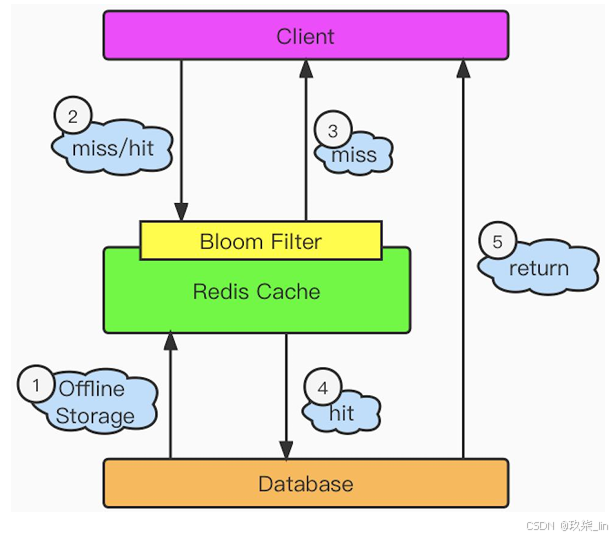
缓存穿透:查不到数据,穿透的是redis。因为redis缓存中没有数据,所以击穿redis访问数据库。
2. 缓存击穿(高并发查询某数据,且缓存过期)
指一个非常热点的key,在不停的高并发请求着,那么当这个key在缓存中失效的一瞬间, 持续对这个key的高并发就击穿了缓存,直接请求到了数据库,就像在一个屏障上早开了 一个洞。当热点key过期失效的一瞬间,高并发突然融入,会对数据库突然造成巨大的压 力,严重的情况甚至会造成数据库宕机。
解决方案:
① 方案一:设置热点数据永不过期 从缓存层面来看,没有设置过期时间,所以不会出现热点key过期后所产生的缓存击穿 问题。
② 方案二:加互斥锁 使用分布式锁,当缓存数据过期后,保证对每个热点key同时只有一个线程去查询后端 服务,并将热点数据添加到缓存。
3. 缓存雪崩(缓存大批量失效或Redis宕机)
指在某一个时间段,缓存集中过期失效,或Redis宕机,导致针对这批数据的查询都落到 了数据库上,对于数据库而言,就会产生周期性的压力波峰。于是所有的请求都会达到 存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。其实缓存集中过期,倒 不是最致命的,比较致命的是Redis发生节点宕机或断网。因为缓存集中过期后,数据库 压力增大,但是随着缓存的创建,压力也会逐渐变小。针对Redis服务节点宕机,对数据 库服务器造成的压力是不可预知的,很有可能是持续压力而最终造成数据库宕机。
解决方案 :
① 方案一:配置Redis集群
通过配置Redis集群,提升高可用性,那么即使挂掉几个Redis节点,集群内的其他Redis 节点依然可以继续对外提供服务。
② 方案二:限流降级
缓存失效后,通过加锁或队列来控制读取数据库且写入缓存的线程数量。
③ 方案三:数据预热分散过期时间
在正式部署之前,先把可能被高频访问的数据预先访问一遍,这样大部分热点数据就加 载到缓存中了,并且通过设置不同的过期时间,让缓存失效的时间尽量均匀,防止同一时刻 大批量缓存失效
4. 布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量 和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优 点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困 难。
布隆过滤器的特征是:它可以判断某个数据一定不存在,但是无法判断一定存在。(确 实有点拗口,但当我们介绍完它的原理,就很容易明白了)
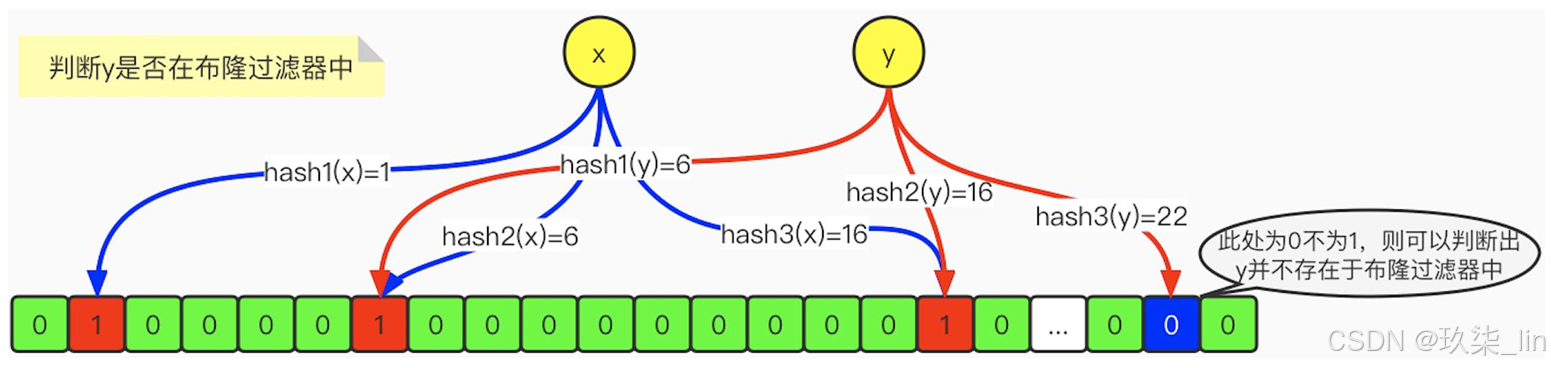
布隆过滤器:判断不存在则一定不存在,判断存在也不一定存在。
- 把数据库中的数据以离线的方式存到redis缓存中。
- Client发请求,首先布隆过滤器判断,如果不存在,则返回miss ③
- 如果布隆过滤器判断存在,则请求redis,再将数据返回给client
删除困难:不提供删除能力
数据一致性不能完全被解决。