操作步骤
1.下载,启动 LLamaFactory 工具
访问 github.com/hiyouga/LLa... 仓库地址
根据仓库的说明来安装 LLamaFactory 工具
bash
# github地址
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
# 码云地址
https://gitee.com/hiyouga/LLaMA-Factory.git
# 切换到项目目录下,安装两个python 工具
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
# 启动Web页面
llamafactory-cli webui注:如果使用GPU训练的话 torch工具需要安装GPU版本
2.安装GPU版 PyTorch
perl
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121原仓库的torch 下载比较慢,可以去阿里云镜像仓库中下载镜像文件
mirrors.aliyun.com/pytorch-whe...
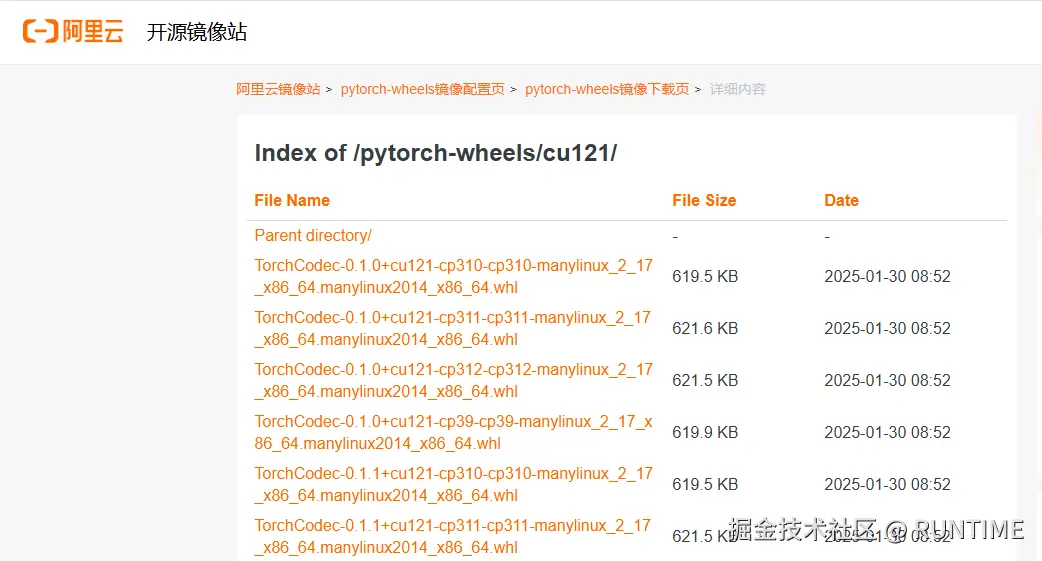
cu121 是cuda版本 我这边用的是 12.1
cp310 是python 版本我这边 用的3.10
bash
# 查看CUDA版本的命令
nvcc --version
# 查看python 版本的命令
python --version以上两个命令如果没能正确返回版本号,则需要检查是否正确安装(这两个环境必须得有)
根据自己的电脑环境下载这三个文件到自己本地,通过以下命令进行安装
bash
pip install torch-2.5.1+cu121-cp310-cp310-win_amd64.whl #安装pytorch
pip install torchaudio-2.5.1+cu121-cp310-cp310-win_amd64.whl
pip install torchvision-0.20.1+cu121-cp310-cp310-win_amd64.whl安装完成以后,新建一个py 文件,将下面内容拷贝进去。然后执行这个py文件,如果能正常打印不报错,则说明没啥问题。
python
import torch
print("CUDA 是否可用:", torch.cuda.is_available()) # 应为 True
print("PyTorch CUDA 版本:", torch.version.cuda) # 应与本地 CUDA Toolkit 版本一致
print("当前 GPU 名称:", torch.cuda.get_device_name(0))3.LLamaFactory webUi的使用
命令行切换到项目的目录下执行: llamafactory-cli webui
浏览器会自动打开webUi 地址:http://localhost:7860/
然后按照下面两张图片标的步骤进行相关设置
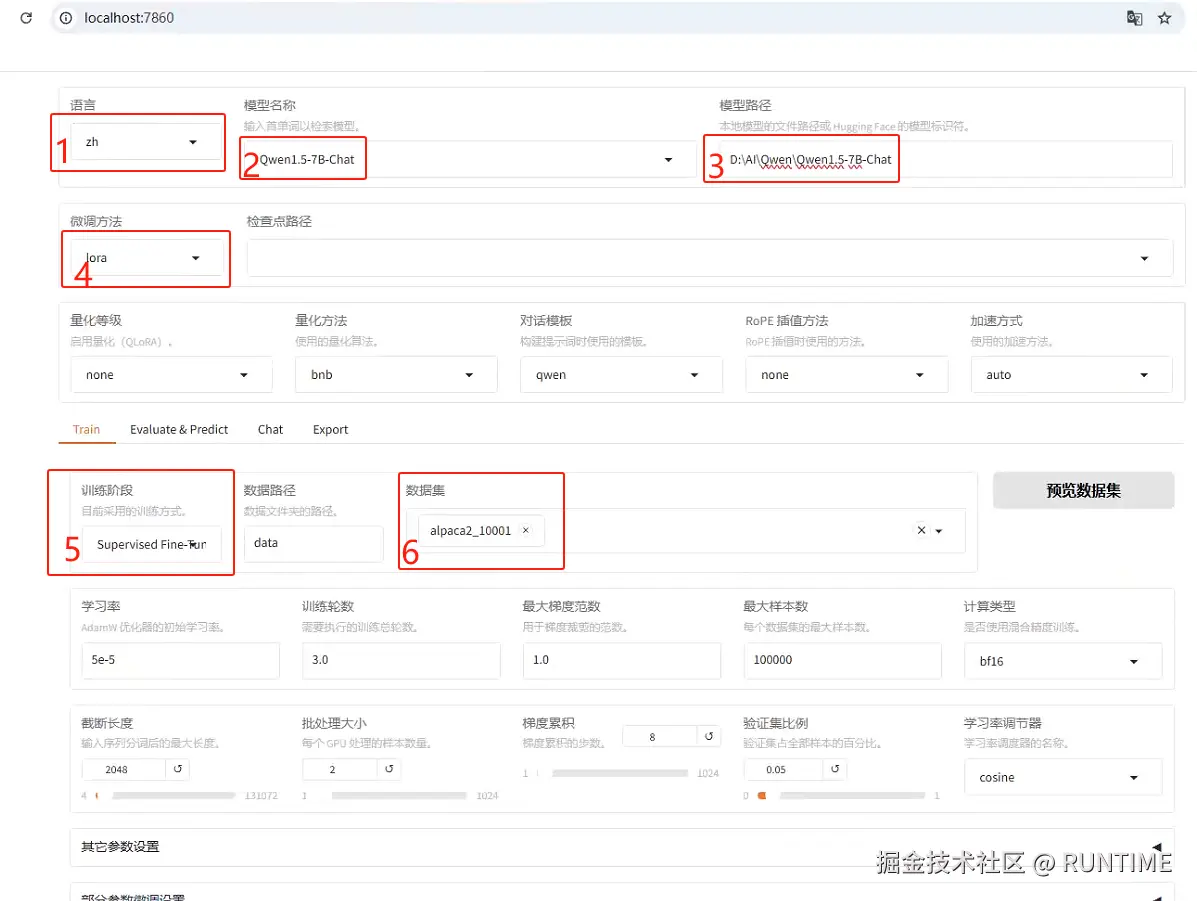
- 默认为英文,选择语言为中文
- 选择需要微调的模型名称
- 选择模型时会自动带出来huggingface 的模型地址,国内可能无法正常使用,可以自行下载模型,然后填写模型的本地目录地址即可。可以参考下面的从魔塔社区下载模型
- 微调方式选lora
- 训练阶段选 SpervisedFine-Tuning(指令微调SFT)
- 数据集选中事先准备好的数据集,可以参考下面的 训练数据集
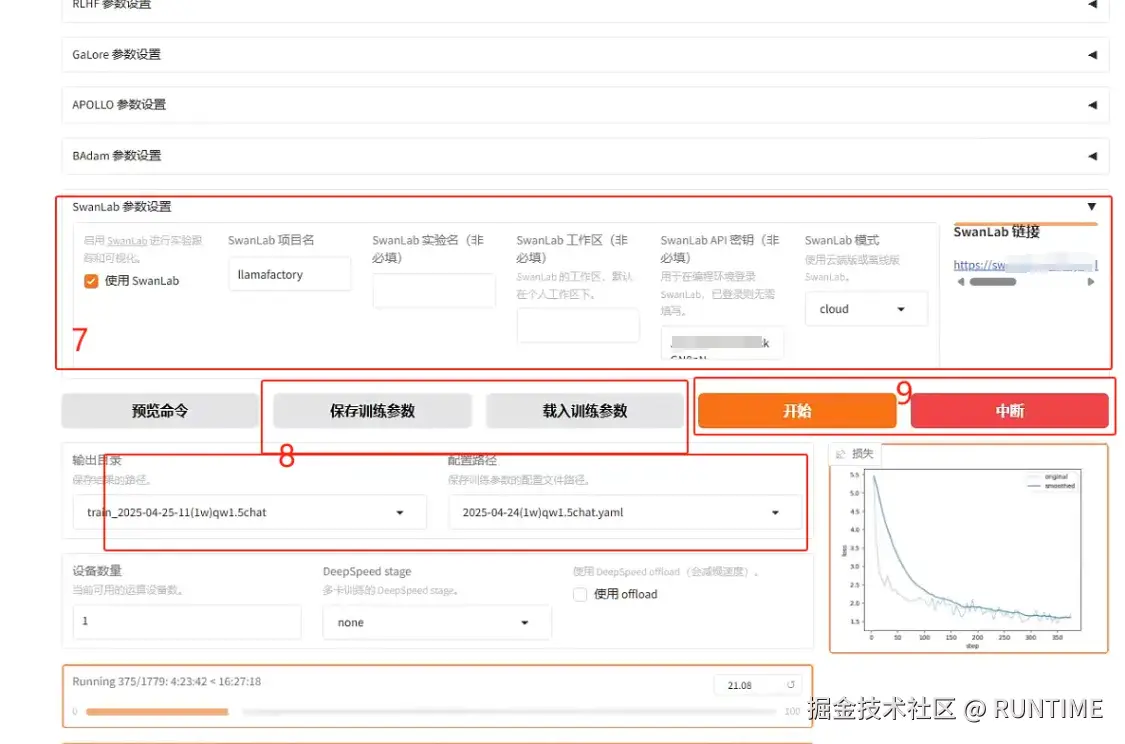
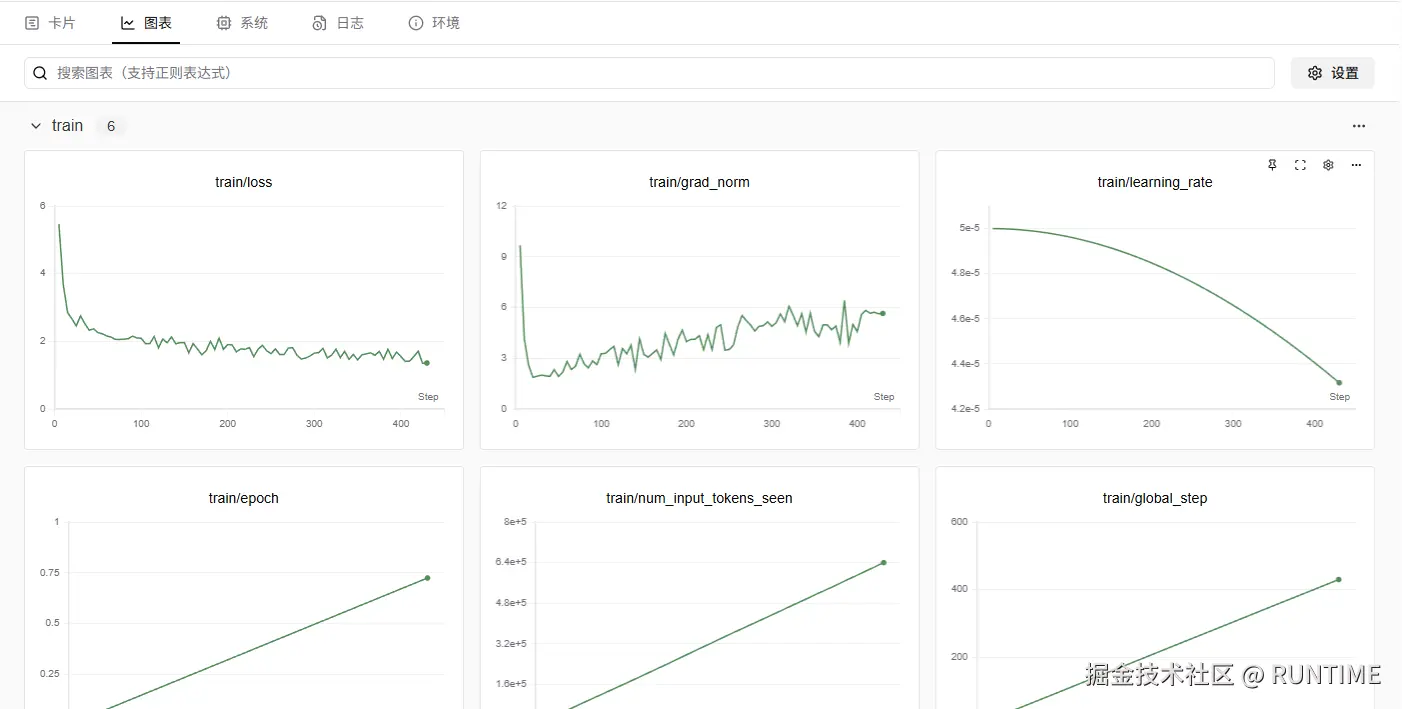
- 配置SwanLab 面板(非必选)需要在 swanlab.cn 注册一个账号,然后获取密钥,填入到配置中,等运行之后右上角会生成一个地址,打开地址就能看到训练情况的折线图以及训练环境的配置参数等
- 打开页面默认就会生成输出目录和配置路径,这个是可以手动修改的,点击 保存训练参数以后,下次可以通过载入训练参数还原之前保存的。
- 以上配置全部完成后,就可以点击开始 按钮进行训练,同时控制台也会打印相关的日志,显示当前训练进度等信息。如果训练到中途需要调整参数什么的,可以点中断训练,需要记好输出目录,下次选中先前的中断目录,可以继续上次的训练
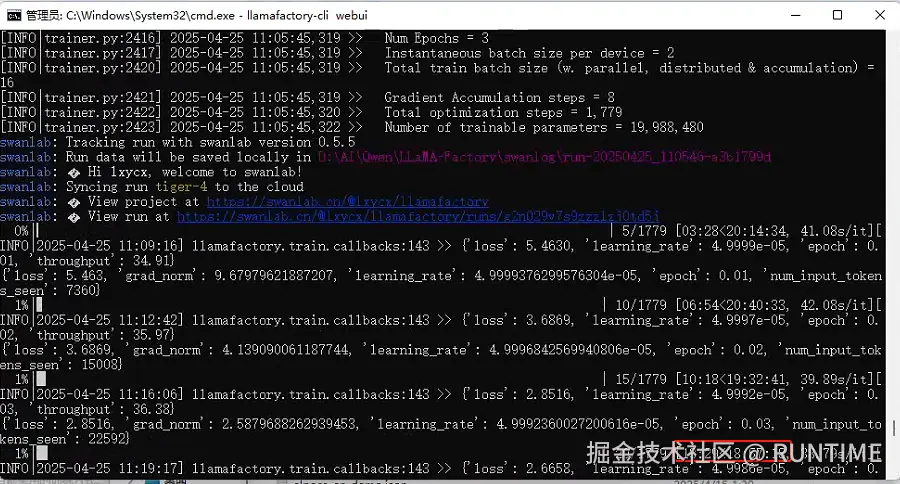
等待训练完成后,通过webUI 工具验证对话效果,和 导出模型
4.从魔塔社区下载模型
模型库地址:modelscope.cn/models
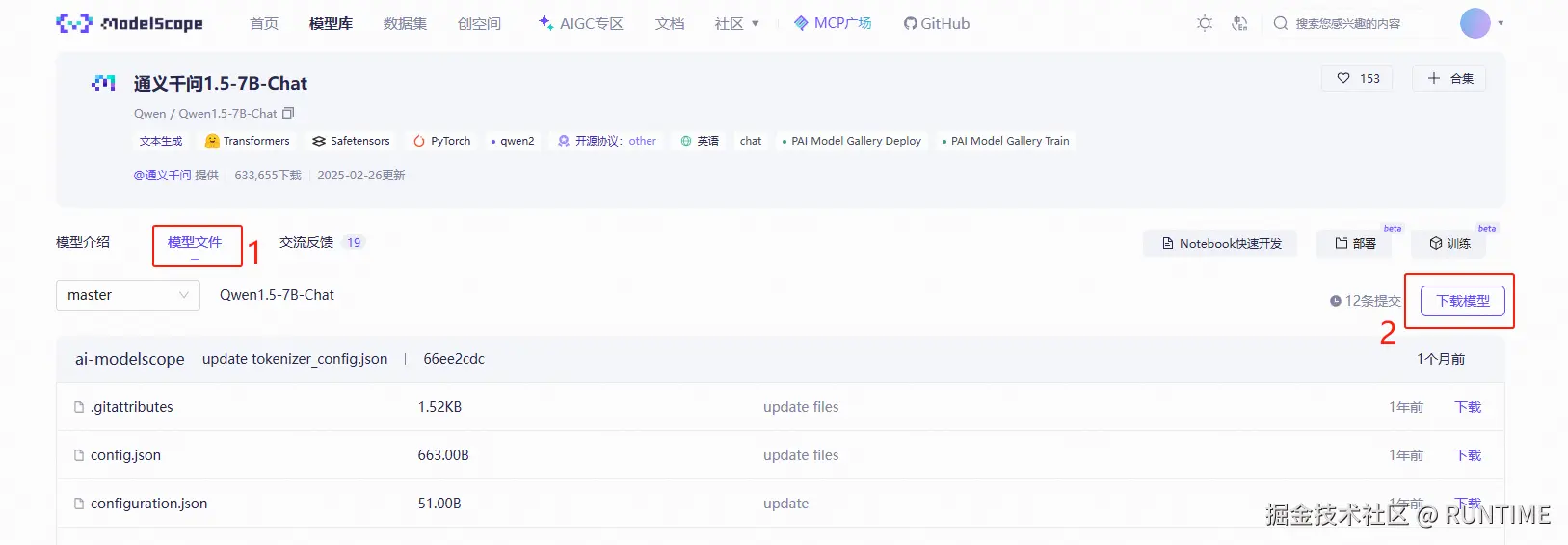
进入你需要的模型详情页,1.点击模型文件,2.再点击下载模型

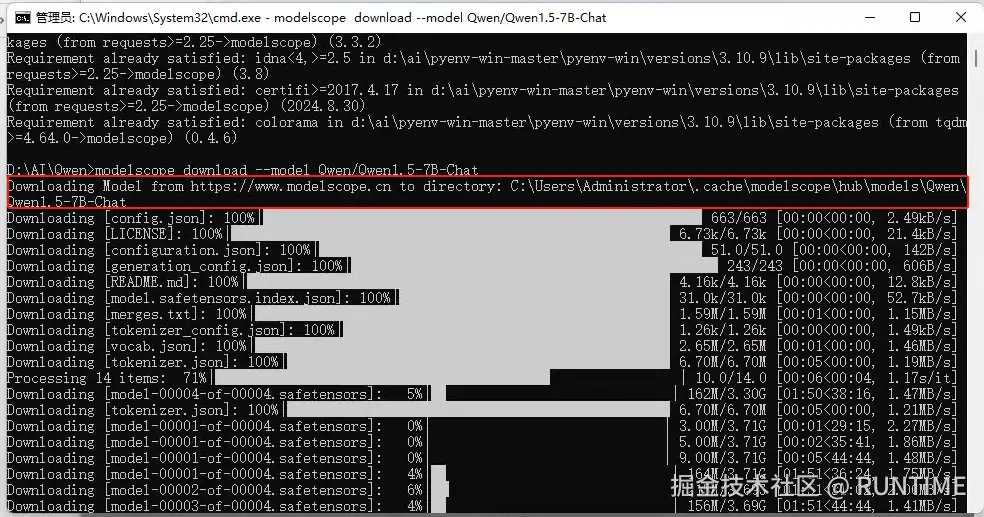
安装ModelScope: pip install modelscope
下载模型: modelscope download --model Qwen/Qwen1.5-7B-Chat
下载完成之后到这个目录去找模型文件
5.训练数据集
需要准备好alpaca 格式的数据集如下所示
swift
[
{
"instruction": "输入三支篮球队的名称并生成一个适当的口号。",
"input": "输入:俄克拉荷马城雷霆队,芝加哥公牛队,布鲁克林网队。",
"output": "输出: "雷霆,公牛和网队:各显神通,角逐群雄!""
},
{
"instruction": "比较以下两位著名人物,使用特征列表并以句子形式提供输出。",
"input": "人物1:阿尔伯特·爱因斯坦\n人物2:斯蒂芬·霍金\n特征:智力、教育、对世界的影响",
"output": "阿尔伯特·爱因斯坦和斯蒂芬·霍金都是拥有极其出色智力的人物。两人都取得过非常高的教育成就,他们推进了科学发展并在世界范围内产生了深远的影响。爱因斯坦以其相对论和质能关系公式而闻名,而霍金以其关于黑洞和宇宙的发现而著称。两位科学家都以其深厚的学识和非凡的贡献影响了世界。"
},
{
"instruction": "请根据以下文章构建一个需要回答的问题。",
"input": "",
"output": "我不好意思,您没有提供任何信息或文章来供我根据它构建问题。 请提供相应的文章或信息,以便我能够帮助您构建问题。"
}
]instruction:为用户的提示词或者问题(必填)
input:为问题关联上下文可以为空字符串
output:为输出内容
另外还有其他一些参数请搜索 alpaca 格式详解
保存成 alpaca_10001.json 文件(文件名随意自定义),然后将数据集保存到 LLaMA-Factory\data 目录下。
然后打开 data 目录下的dataset_info.json文件,增加相关配置(file_name 需要跟文件名对应)
json
"alpaca_10001":{
"file_name":"alpaca_10001.json",
"columns":{
"prompt":"instruction",
"query":"input",
"response":"output"
}
}配置完之后,在WebUi 中的数据集选项中,就能看到到这条数据集选项
6.模型验证
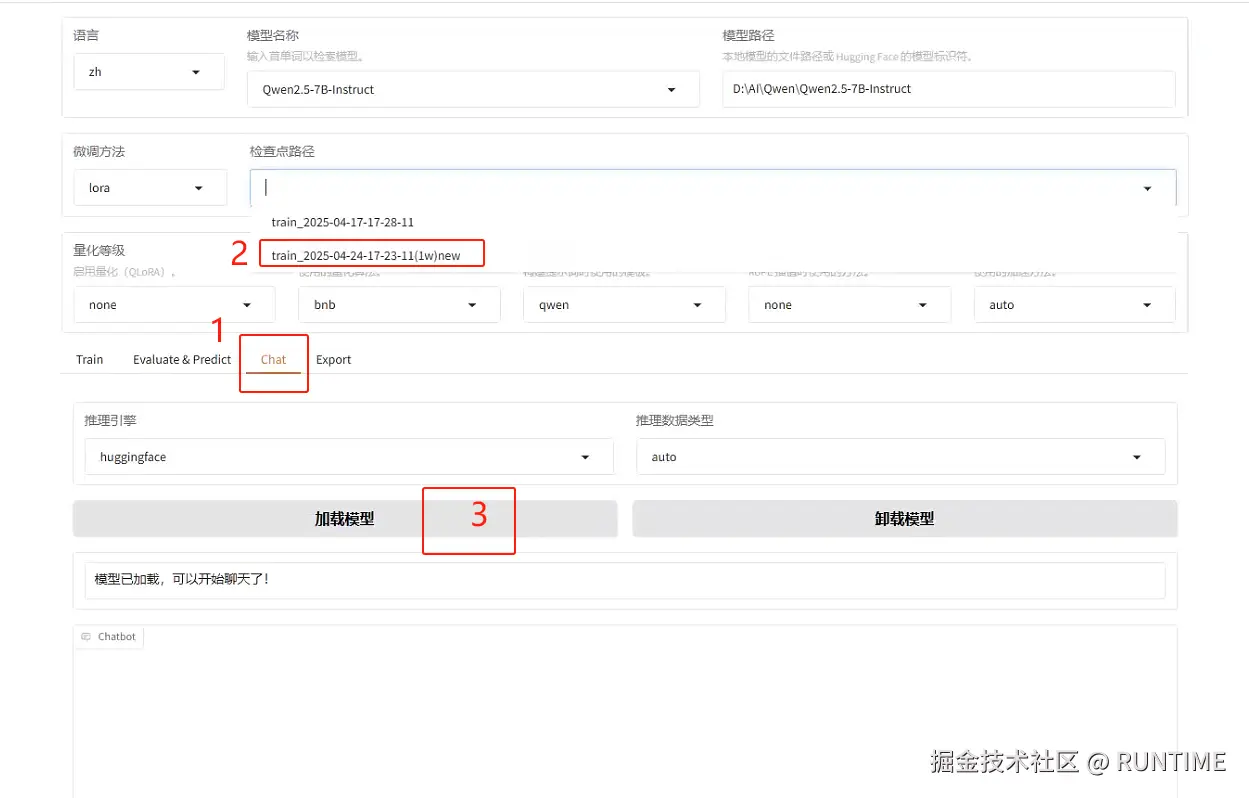
1.如图切换到Chat页签,下面会显示对话模块。
2.点击上面的检查点路径,下面会显示以及训练完的模型目录,然后选中你想要加载的模型
3.点击加载模型,然后下面就可以通过页面跟自己训练完成的模型进行对话了。
注意,检查点路径一定要选择,否则加载的是原本的模型。通过选择检查点路径选中的模型,响应可能比较慢,回复一次大概几分钟(打开目录发现它不是标准的模型文件)。 我们可以先通过导出功能给他导出成标准模型文件,然后再修改上面的模型路径重新加载新模型的目录,再重新加载,这个时候对话速度就正常了
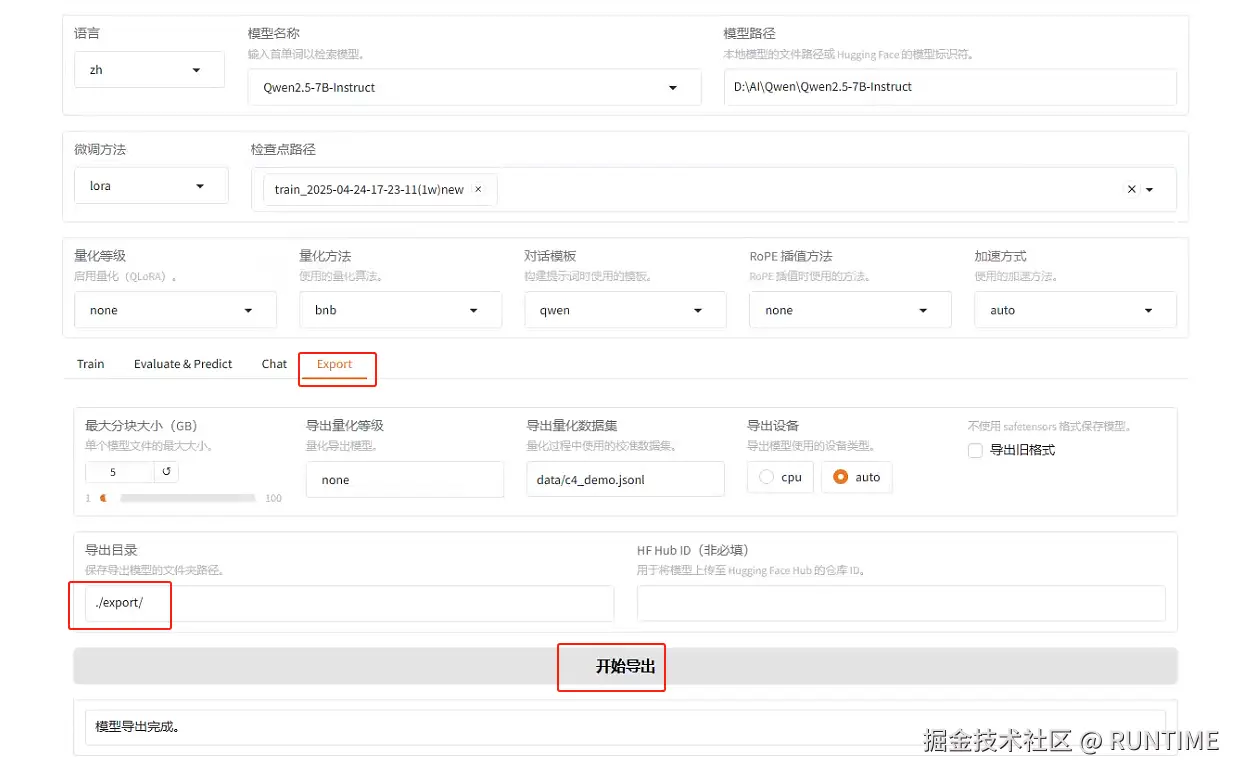
7.导出模型
将页签切换到Export,设置导出目录,最后点开始导出即可。(等导出完成,打开导出目录,里面的文件结构就和先前魔塔下载的原模型结构一样了)
工具地址
微调工具web
Qwen
qwen.readthedocs.io/zh-cn/lates...
SwanLab
参考文章
1.微调的大致流程步骤
阿里杀疯了,快来看!千问大模型部署、微调和评估指南_千问模型-CSDN博客
2.通过 LLaMA Factory 这个 web工具微调