使用selenium爬虫的时候,如果不加入代理IP,很容易会被网站识别,容易封号;
最近去了解了一下买代理ip,但是还是有一些不太懂的东西。
例如有了代理ip以后,怎么用在爬虫上,requests 和selenium的方法各自是怎么样的?怎么能确定我爬取的时候,用的是代理的ip,还是我自己的ip?
下面就是一些我整理的内容:
1. requests使用代理ip的方法:
简单版:
python
import requests
proxies = {
'http': 'http://your-proxy-address:port',
'https': 'http://your-proxy-address:port'
}
response = requests.get('http://httpbin.org/headers', proxies=proxies)
print(response.json()) # 查看返回的headers信息严谨版:
python
import requests
import time
url='https://www.baidu.com/'
proxyaddr = "代理IP地址" #代理IP地址
proxyport = 57114 #代理IP端口 ,类似
proxyusernm = "代理帐号" #代理帐号
proxypasswd = "代理密码" #代理密码
#name = input();
proxyurl="http://"+proxyusernm+":"+proxypasswd+"@"+proxyaddr+":"+"%d"%proxyport
t1 = time.time()
r = requests.get(url,proxies={'http':proxyurl,'https':proxyurl},headers={
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cache-Control":"max-age=0",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"})
r.encoding='gb2312'
t2 = time.time()
print(r.text)
print("时间差:" , (t2 - t1));2. selenium使用代理ip的方法:
python
from selenium import webdriver
from urllib import request
#from selenium.webdriver.support import expected_conditions (时间超载的请求)
# 代理服务器
url='https://www.baidu.com/'
proxyaddr = "代理IP地址" #代理IP地址
proxyport = 57114 #代理IP端口 ,类似
proxyusernm = "代理帐号" #代理帐号
proxypasswd = "代理密码" #代理密码
#name = input();
proxyurl="http://"+proxyusernm+":"+proxypasswd+"@"+proxyaddr+":"+"%d"%proxyport
proxy_handler = request.ProxyHandler({
"http" : proxyMeta,
"https" : proxyMeta,
})
print(proxyMeta)
opener = request.build_opener(proxy_handler)
request.install_opener(opener)
option = webdriver.ChromeOptions() #打开
option.add_experimental_option('excludeSwitches', ['enable-automation']) # webdriver防检测
# option.add_argument('--headless')
option.add_argument("--disable-blink-features=AutomationControlled")
option.add_argument("--no-sandbox")
option.add_argument("--disable-dev-usage")
#option.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
chromedriver_path = r"D:\\XXX\\chromedriver.exe" #路径要是自己的,还有下面的字段
driver = webdriver.Chrome(options=option,executable_path=chromedriver_path)
#driver = webdriver.Chrome(options=option)
driver.set_page_load_timeout(15)3. 检测 Selenium 是否成功使用代理的方法:
当你在 Selenium 中使用代理时,可以通过以下几种方法验证代理是否真正生效:
方法 1:通过 IP 检测网站+ 浏览器开发者工具验证
先安利一个查看自己的服务器的网站:(建议收藏)
这个网站使用了Cloudflare的服务,先是检测你是否为真人,

然后进去以后就可以看到页面的服务器IP是啥了,在红色框线那里。
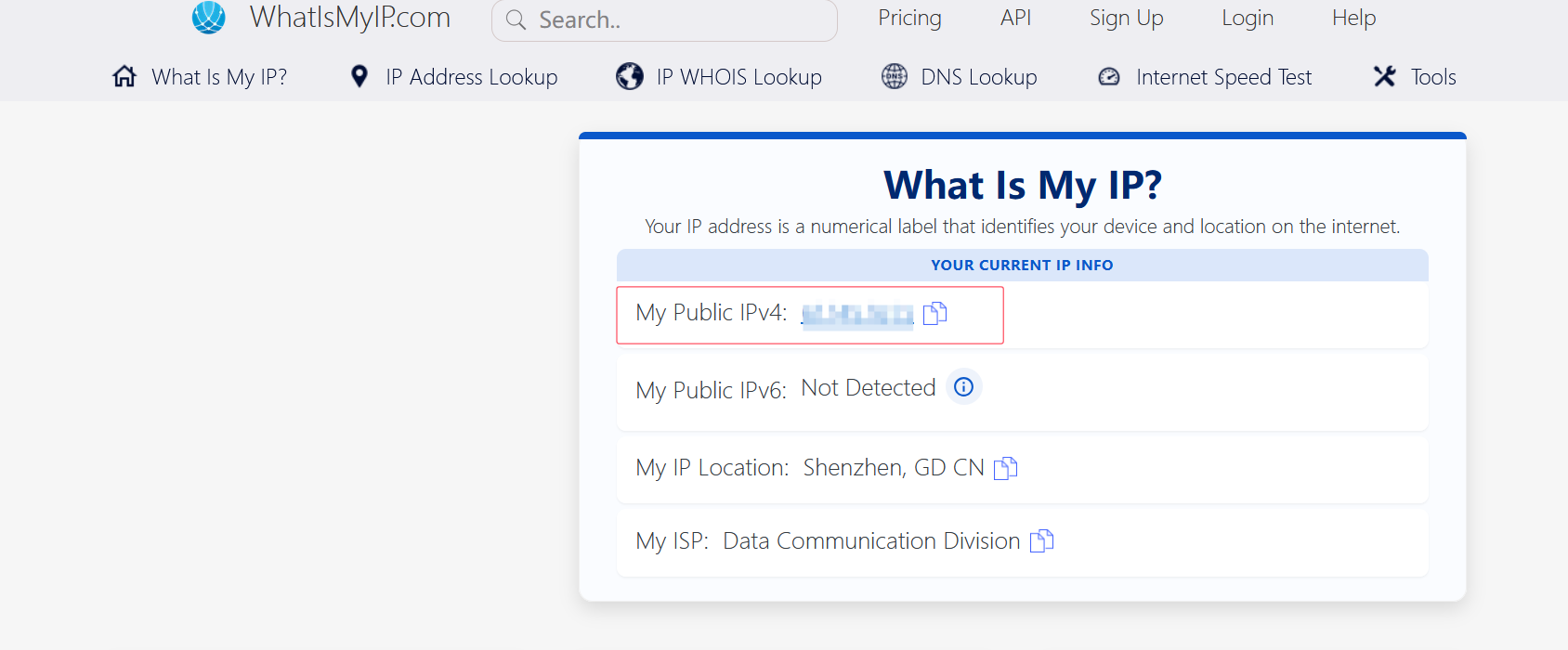
然后,使用浏览器开发者工具验证
- 在代码中添加暂停以便手动检查:
python
driver.get("https://www.baidu.com") #任意一个网站
input("按回车继续...") # 暂停程序,让你可以手动检查这个部分也可以自己收
- 在打开的浏览器中:
- 按 F12 打开开发者工具
- 转到 "Network" (网络) 选项卡
- 刷新页面
- 查看请求的 "Remote Address" (远程地址) 是否显示为你的代理IP
PS:可以对比自己住宅IP的地址,以及对比使用代理ip后打开的浏览器界面,对比网络选项卡上的远程地址,看看是否不同。
如果是不一样,说明确实用了代理,改变了响应的ip地址!
方法 2:使用代码监测
python
from selenium import webdriver
# 设置代理选项
proxy = "123.45.67.89:8080" # 替换为你的代理IP和端口
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument(f'--proxy-server={proxy}')
# 启动浏览器
driver = webdriver.Chrome(options=chrome_options)
# 访问IP检测网站
driver.get("https://www.whatismyip.com/")
# 或者使用 httpbin
# driver.get("http://httpbin.org/ip")
# 手动查看显示的IP是否与你的代理IP一致
# 或者使用下面的方法自动提取IP信息
# 保持浏览器打开以便查看
input("检查完毕后按回车键关闭浏览器...")
driver.quit()方法 3:验证代理请求头
python
driver.get("http://httpbin.org/headers")
headers_json = driver.find_element(By.TAG_NAME, "body").text
print(headers_json)
# 检查是否有代理相关的头部信息
if "X-Forwarded-For" in headers_json:
print("检测到代理头部信息")4. 其他的问题排查
-
如果遇到代理未生效的问题:
- 检查代理格式是否正确(IP:PORT)
- 验证代理是否需要用户名密码认证(需要额外配置)
- 测试代理服务器本身是否可用(用其他工具如curl测试)
-
需要认证的代理:
python
from selenium.webdriver.common.proxy import Proxy, ProxyType
proxy = Proxy({
'proxyType': ProxyType.MANUAL,
'httpProxy': '123.45.67.89:8080',
'sslProxy': '123.45.67.89:8080',
'noProxy': '' # 设置不需要代理的地址
})
# 如果有用户名密码
proxy.http_proxy = "username:password@123.45.67.89:8080"
proxy.ssl_proxy = "username:password@123.45.67.89:8080"
capabilities = webdriver.DesiredCapabilities.CHROME
proxy.add_to_capabilities(capabilities)
driver = webdriver.Chrome(desired_capabilities=capabilities)- 代理连接超时 :
- 增加页面加载超时时间
- 检查代理服务器是否正常运行
- 尝试不同的代理服务器
通过以上方法,你可以确认 Selenium 是否成功通过代理访问网站,以及代理是否按预期工作。

(码代码累了,看个美图欣赏一下吧~)