本案例仅供学习和参考
逆向参数:__jsluid_s、__jsl_clearance_s
注意:__jsluid_s由服务器下发,而__jsl_clearance_s需通过客户端执行JS代码生成
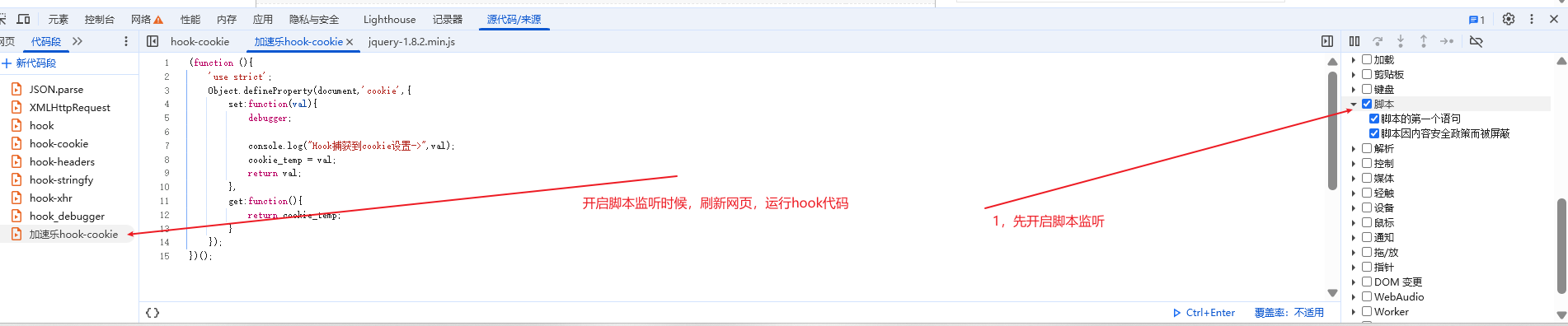
1,在应用这里将cookie清空
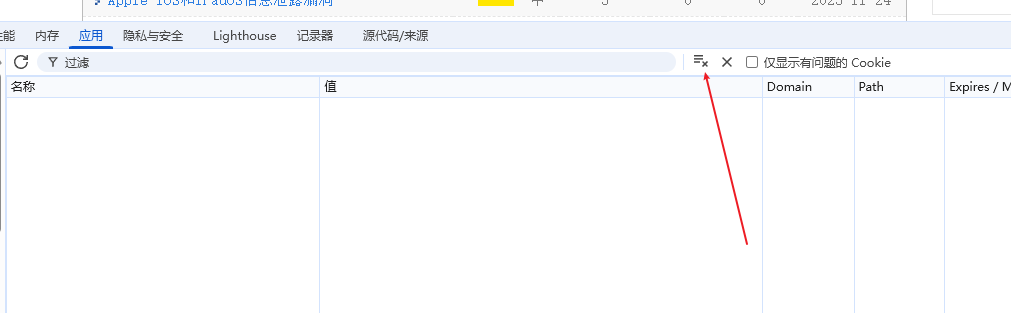
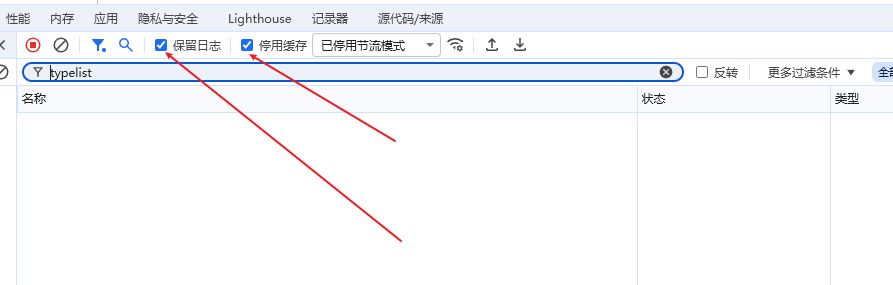
2,在网络这里打开保留日志,停用缓存
3,刷新网页,可以看到有三个请求,第三个是基于前面两个生成出来的
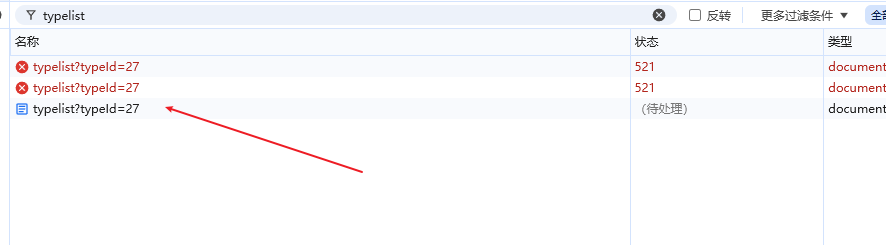
4,说明我们的代码需要获取两次cookie,第三次才能拿到我们的页面数据
第一次

第二次

第三次
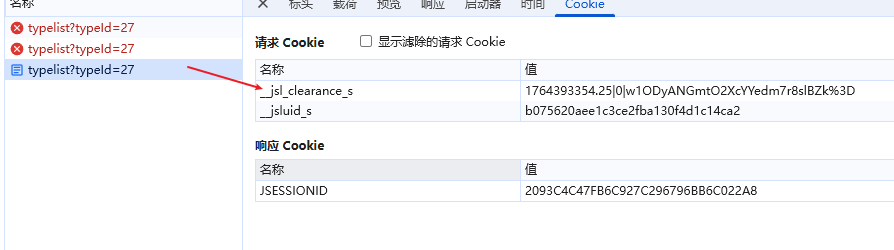
5,来到网络源代码里面具体分析一下
第一次



第二次
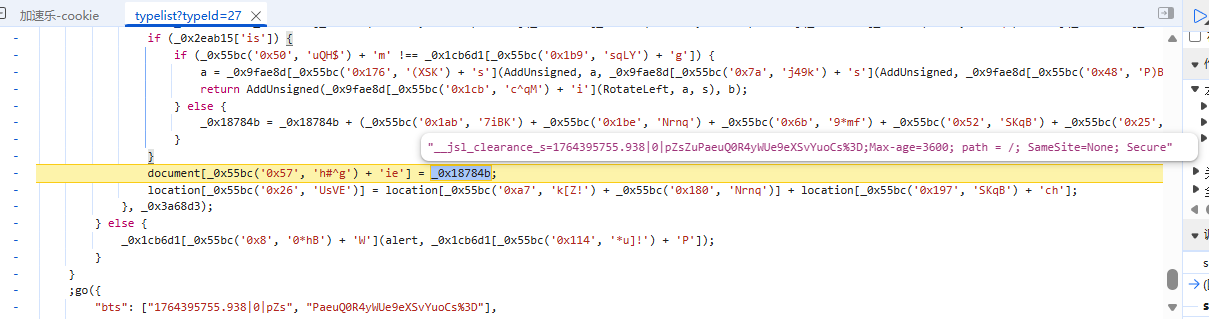

所以在py代码里面可以这样写
第一次的
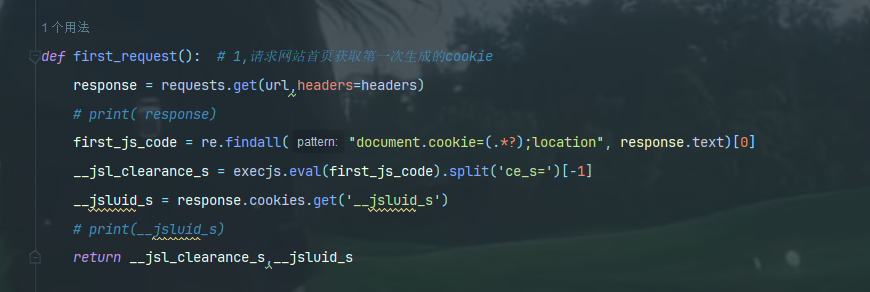
第二次的因为这些go里面的参数会变所以需要替换代码
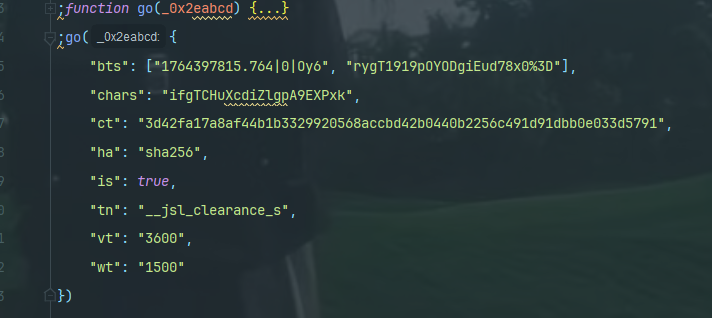
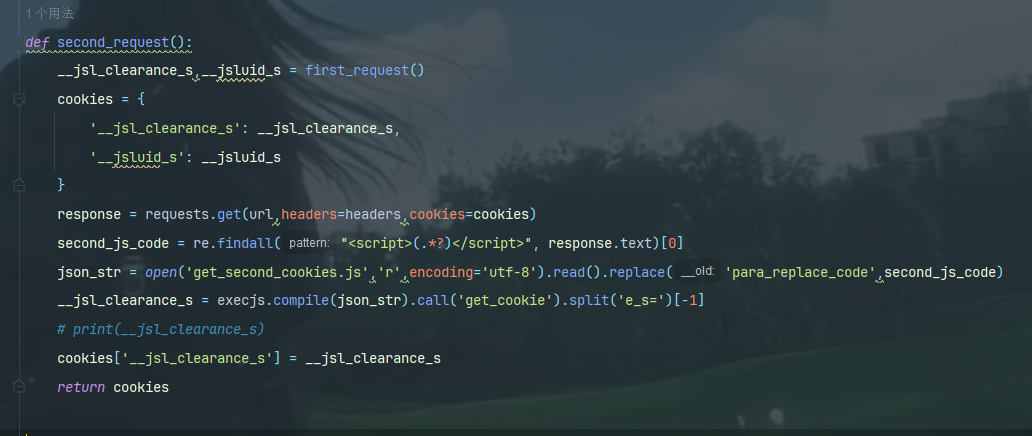
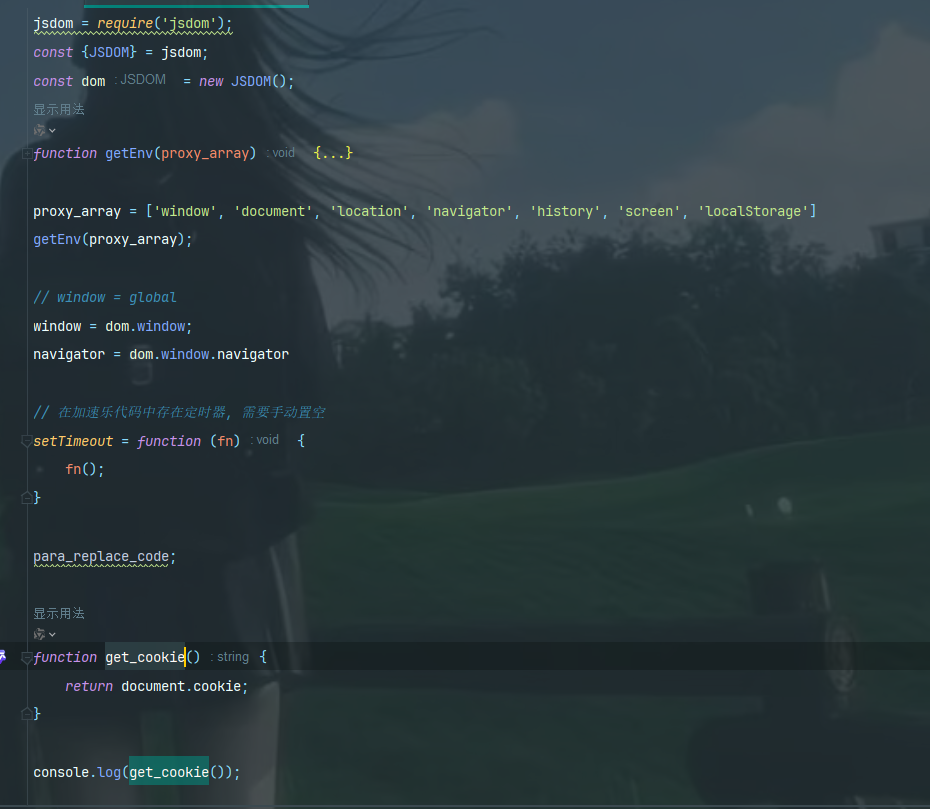
第三次
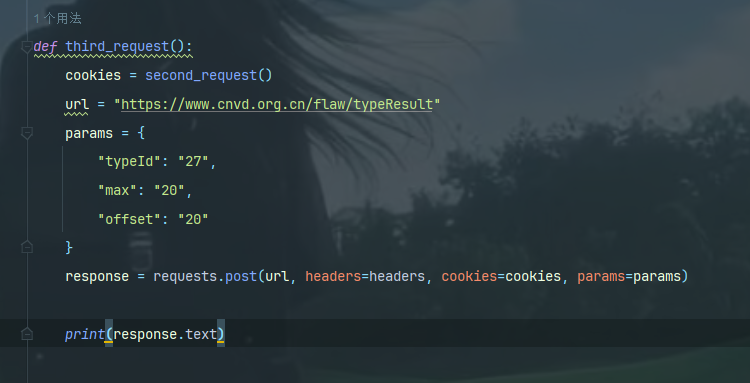
经过三次的请求就可以批量拿数据了
总结:这个案例非常锻炼人的思维逻辑,很有意思的,很适合正在学习爬虫的小伙伴们练习cookies的反爬