目录
[1 Hive数据模型全景图](#1 Hive数据模型全景图)
[2 Hive存储架构解析](#2 Hive存储架构解析)
[3 存储格式对比矩阵](#3 存储格式对比矩阵)
[4 存储格式选择决策树](#4 存储格式选择决策树)
[5 ORC文件结构剖析](#5 ORC文件结构剖析)
[6 Parquet与ORC技术对比](#6 Parquet与ORC技术对比)
[7 最佳实践指南](#7 最佳实践指南)
[7.1 建表示例模板](#7.1 建表示例模板)
[7.2 性能优化](#7.2 性能优化)
[8 总结](#8 总结)
1 Hive数据模型全景图
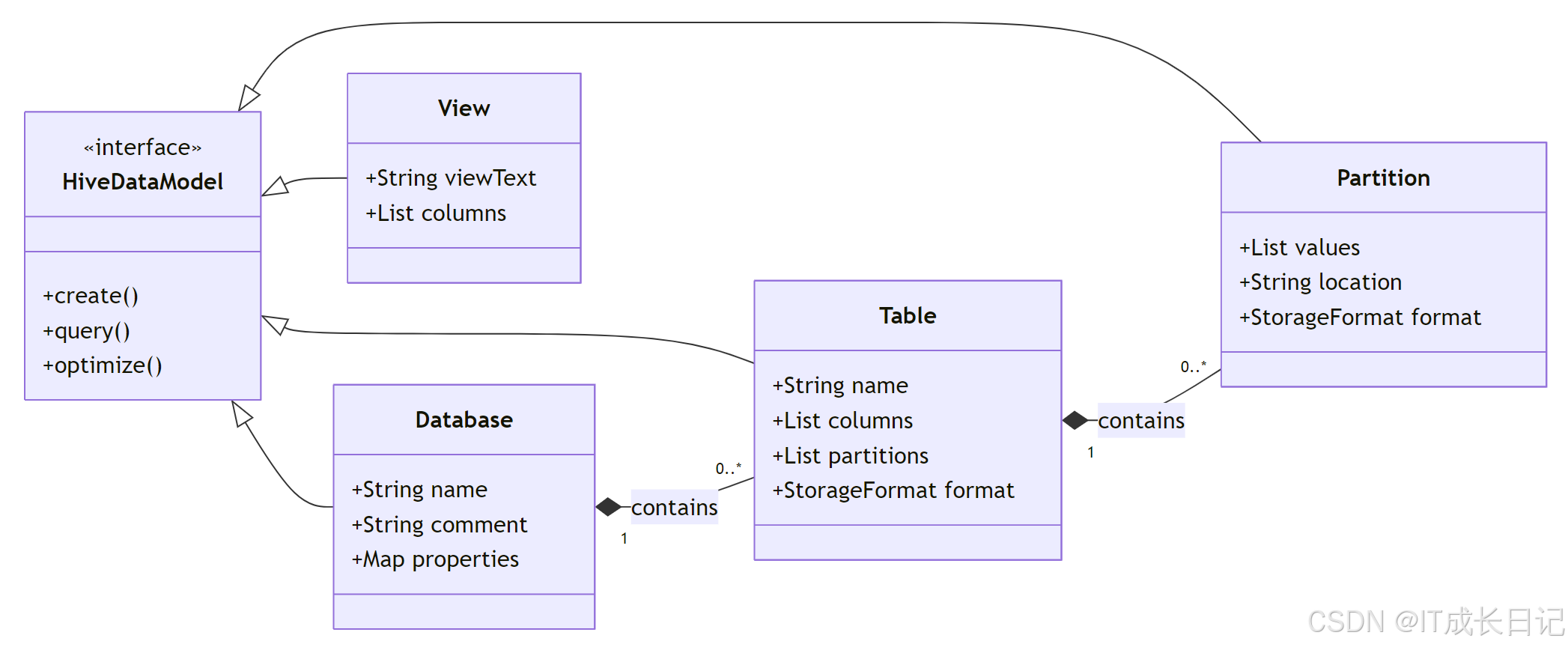
模型核心组件解析:
- Database:命名空间容器,相当于关系型数据库中的schema
- Table:结构化数据实体,包含:列定义(名称、类型、注释),分区信息(物理存储分离),存储格式配置
- Partition:基于列值的物理数据分片
- View:虚拟表,不存储实际数据
2 Hive存储架构解析
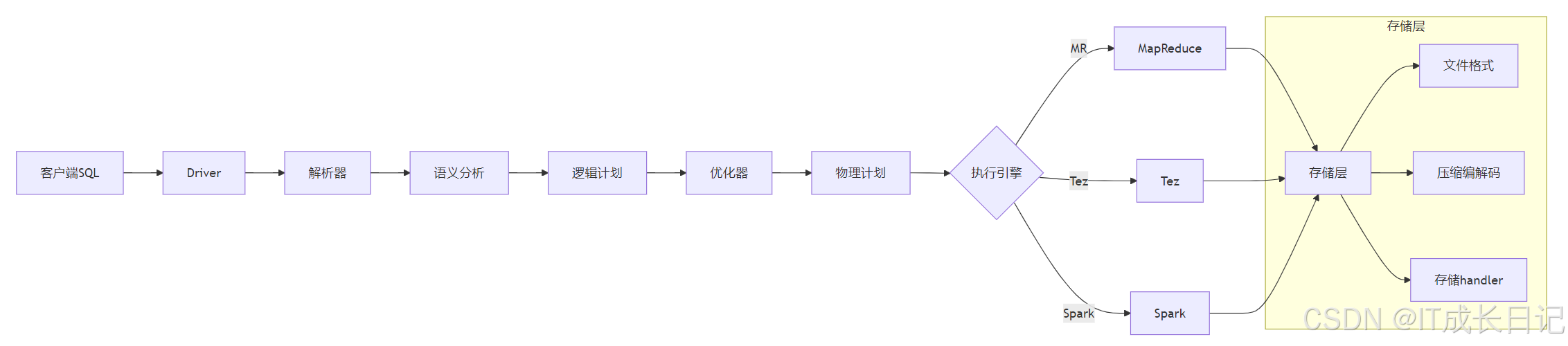
关键处理阶段:
- SQL解析:将HQL转换为抽象语法树
- 逻辑优化:谓词下推、列裁剪等优化
- 物理执行:根据配置选择执行引擎
- 存储交互:通过InputFormat/OutputFormat读写数据
3 存储格式对比矩阵
|--------------|-------------|----------------|--------------|
| 格式 | 结构特点 | 适用场景 | 压缩支持 |
| TextFile | 纯文本,按行存储 | 数据交换,临时存储 | Gzip, Bzip2 |
| SequenceFile | 二进制KV格式 | MapReduce中间结果 | Block压缩 |
| ORC | 列式存储,自带索引 | Hive高频查询 | ZLIB, Snappy |
| Parquet | 列式存储,嵌套结构支持 | Spark生态,复杂数据类型 | Gzip, LZO |
4 存储格式选择决策树
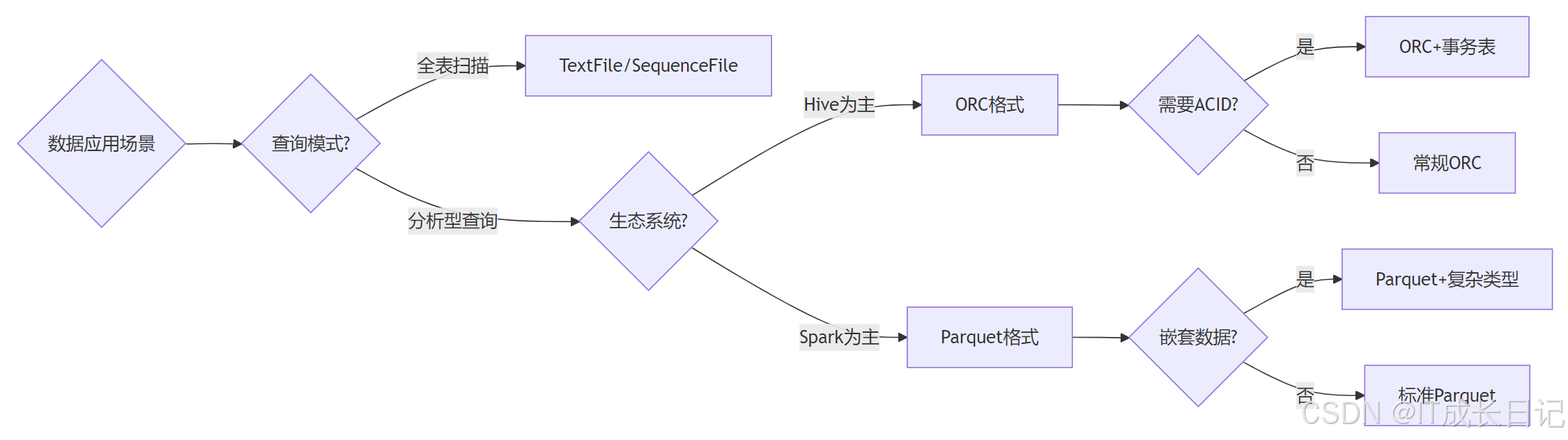
决策点说明:
- TextFile:适合作为数据接入层的原始存储
- ORC:Hive环境首选,支持:ACID事务(Hive 3.0+),轻量级索引(布隆过滤器)
- Parquet:跨平台首选,优势在于:完善的嵌套数据类型支持,Spark原生优化
5 ORC文件结构剖析
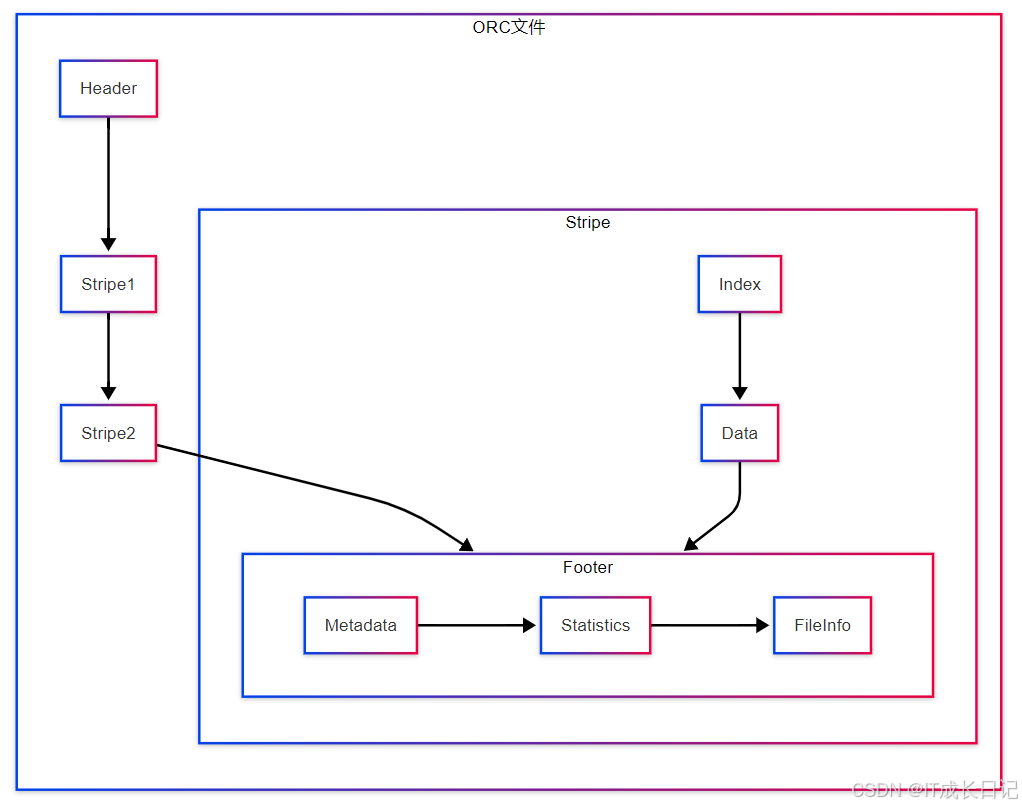
ORC核心结构:
- Stripe:数据分块(默认256MB),Index:存储min/max等统计信息;Data:列数据存储区
- Footer:文件元数据,各列的聚合统计信息,文件Schema定义
- Postscript:压缩参数和版本信息
6 Parquet与ORC技术对比
- 编码效率
- ORC采用Run-Length Encoding
- Parquet使用Dictionary+Delta编码
- 索引机制
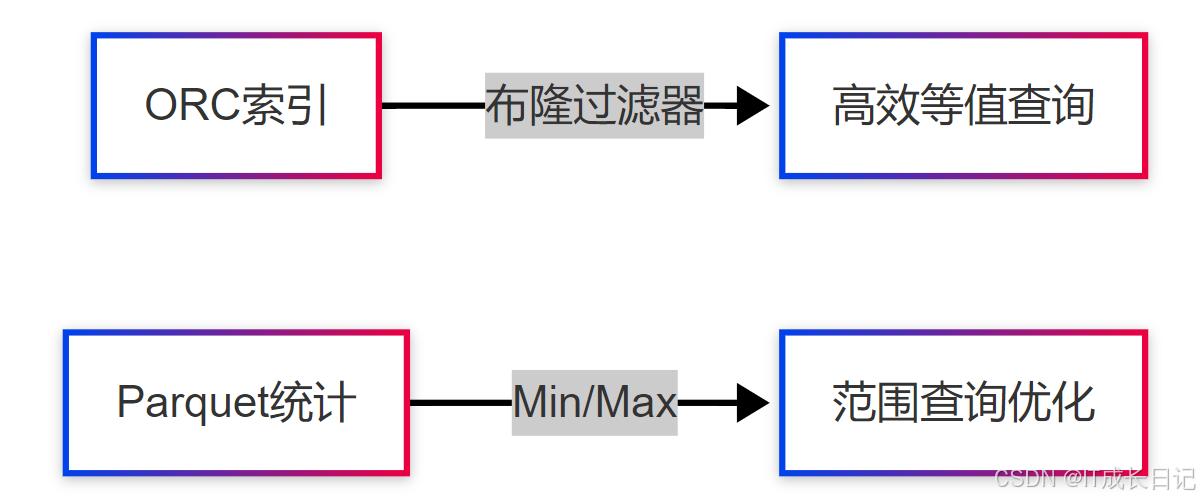
- 嵌套支持
- Parquet原生支持Map/List结构
- ORC需通过特殊格式实现
7 最佳实践指南
7.1 建表示例模板
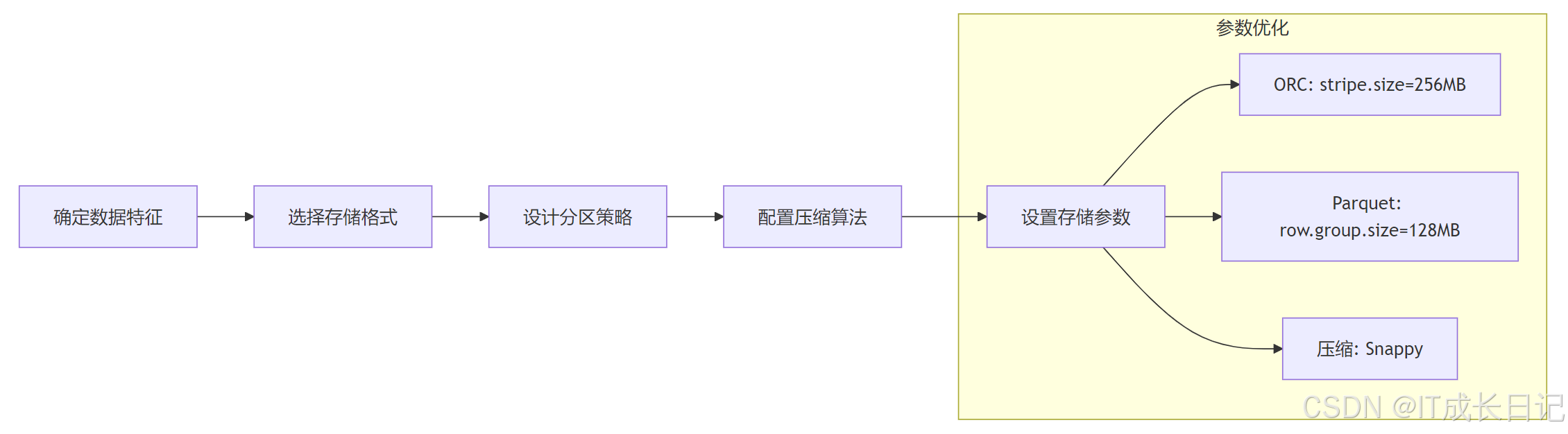
-
完整DDL示例
-- ORC事务表示例
CREATE TABLE user_test (
user_id BIGINT,
event_time TIMESTAMP,
event_name STRING
) PARTITIONED BY (dt STRING)
STORED AS ORC
TBLPROPERTIES (
'transactional'='true',
'orc.compress'='SNAPPY',
'orc.create.index'='true'
);
7.2 性能优化
优化技巧清单:
- 分区裁剪:WHERE dt='2025-04-20'
- 列裁剪:只SELECT必要列
- ORC索引:CREATE INDEX ON TABLE(col)
- 压缩选择:
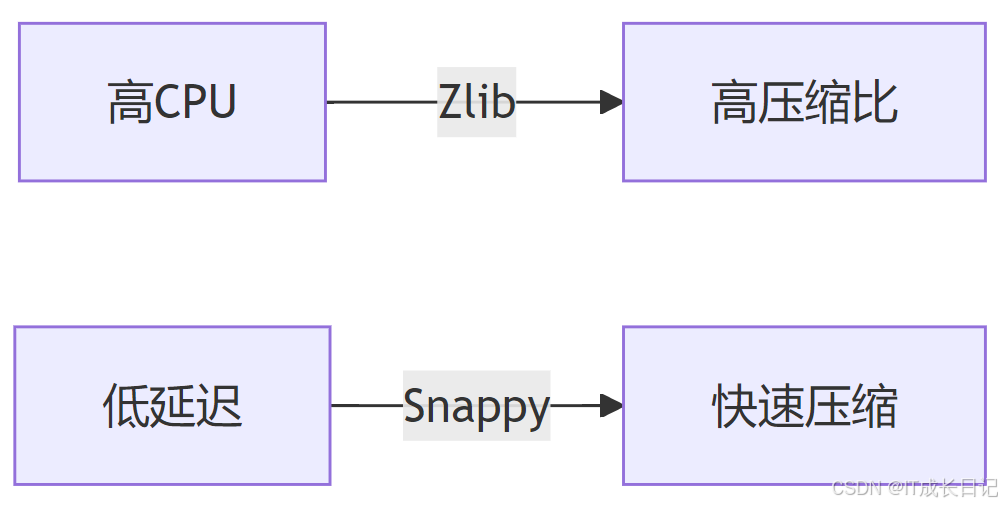
8 总结
通过本文的系统性解析,了解了Hive数据模型与存储格式的选择方法论。在实际应用中,建议通过 EXPLAIN分析执行计划,结合 ANALYZE TABLE收集统计信息,持续优化存储方案。对于PB级数据仓库,可采用分层存储策略:热数据用ORC/Parquet,冷数据转存为压缩率更高的格式。