一、Kafka整合flume
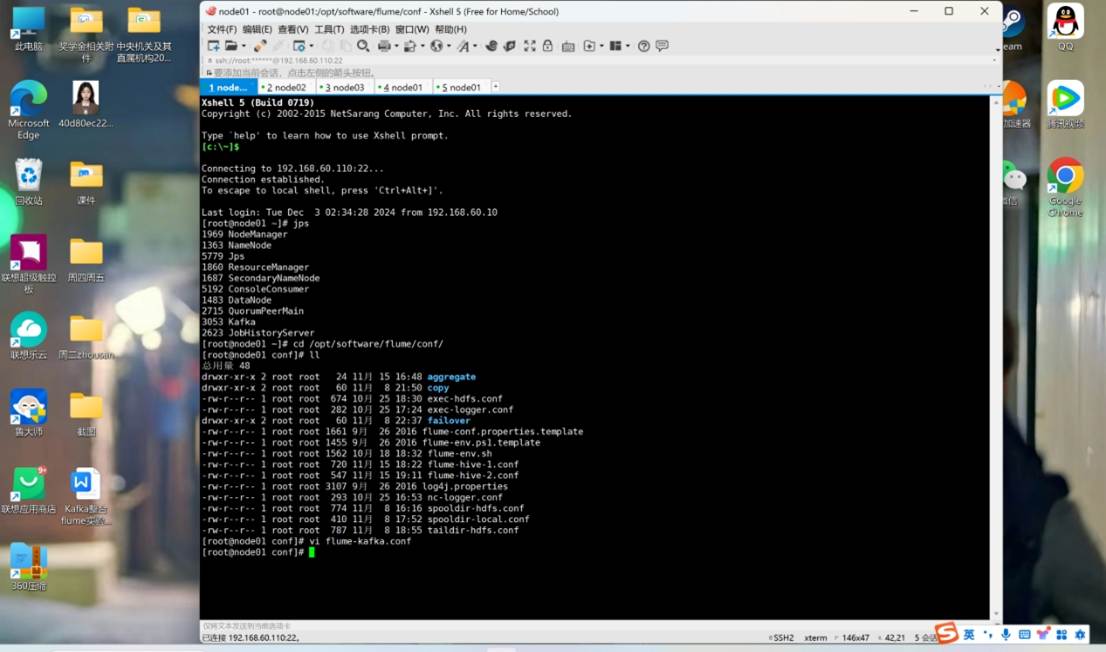
cd /opt/software/flume/conf/
vi flume-kafka.conf
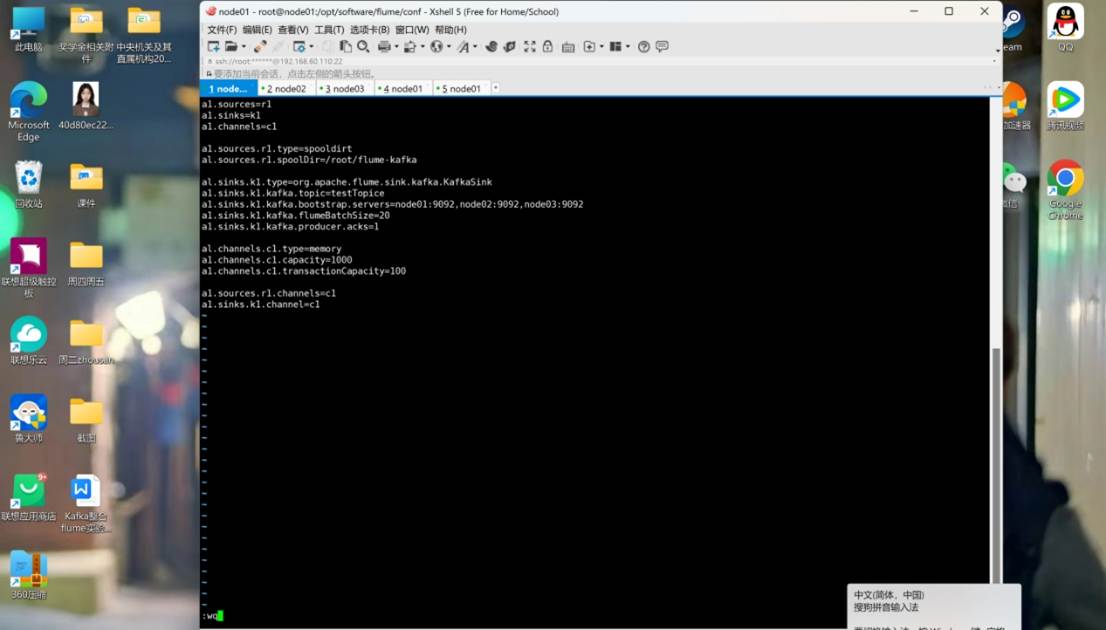
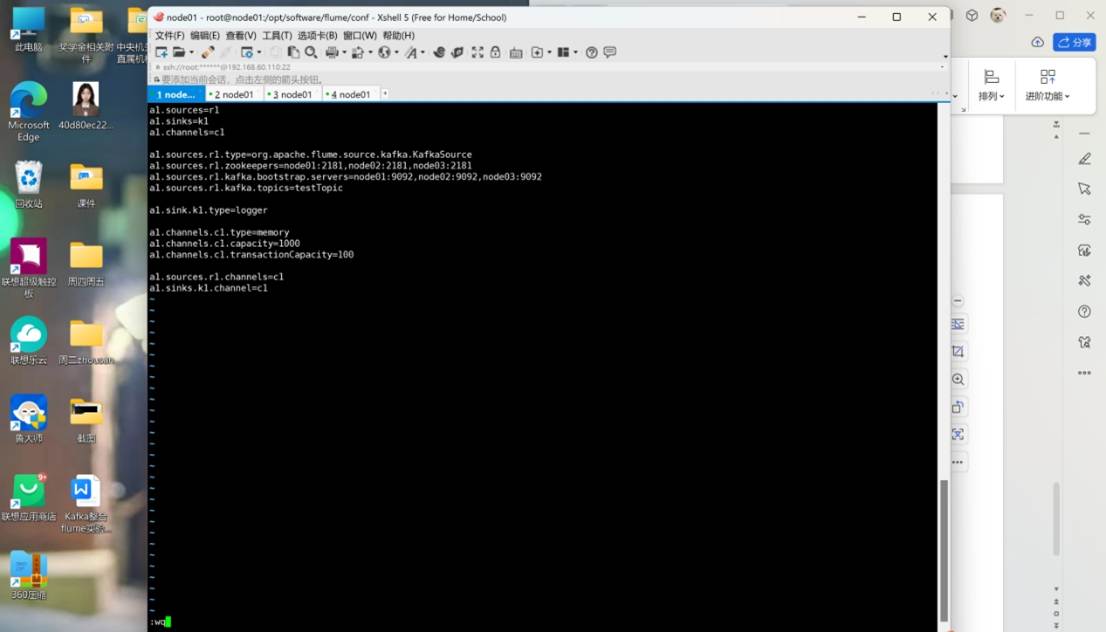
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=spooldirt
a1.sources.r1.spoolDir=/root/flume-kafka
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic=testTopice
a1.sinks.k1.kafka.bootstrap.servers=node01:9092,node02:9092,node03:9092
a1.sinks.k1.kafka.flumeBatchSize=20
a1.sinks.k1.kafka.producer.acks=1
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
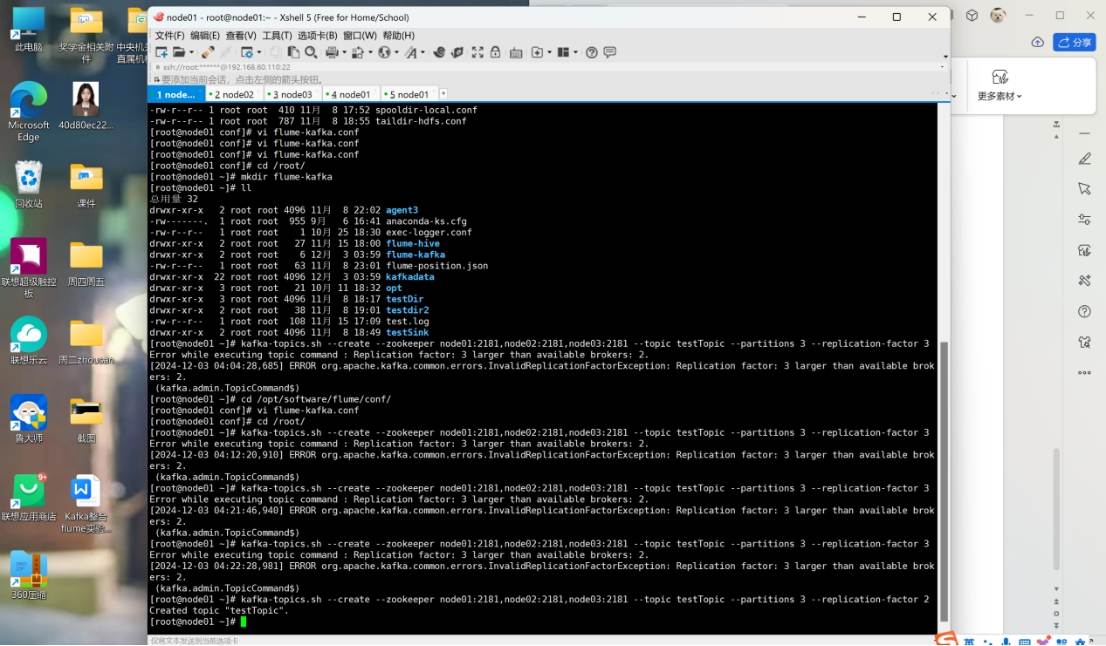
cd /root/
mkdir flume-kafka
ll
drwxr-xr-x 2 root root 4096 11月 8 22:02 agent3
-rw-------. 1 root root 955 9月 6 16:41 anaconda-ks.cfg
-rw-r--r-- 1 root root 1 10月 25 18:30 exec-logger.conf
drwxr-xr-x 2 root root 27 11月 15 18:00 flume-hive
drwxr-xr-x 2 root root 6 12月 3 03:59 flume-kafka
-rw-r--r-- 1 root root 63 11月 8 23:01 flume-position.json
drwxr-xr-x 22 root root 4096 12月 3 03:59 kafkadata
drwxr-xr-x 3 root root 21 10月 11 18:32 opt
drwxr-xr-x 3 root root 4096 11月 8 18:17 testDir
drwxr-xr-x 2 root root 38 11月 8 19:01 testdir2
-rw-r--r-- 1 root root 108 11月 15 17:09 test.log
drwxr-xr-x 2 root root 4096 11月 8 18:49 testSink
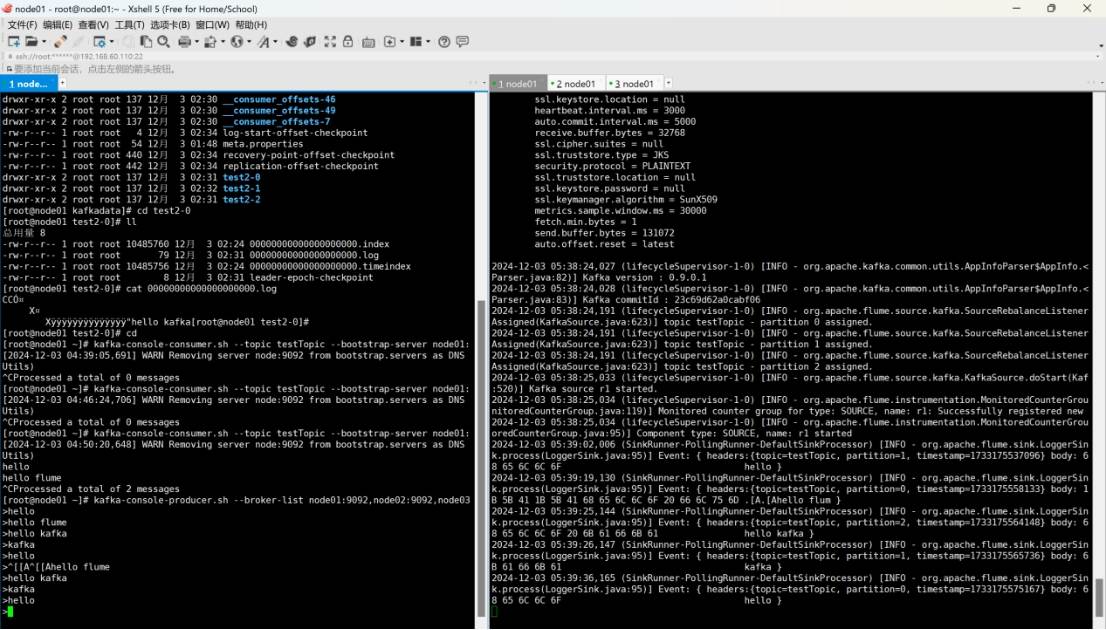
kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --topic testTopic --partitions 3 --replication-factor 2
flume-ng agent -c /opt/software/flume/conf/ -f /opt/software/flume/conf/flume-kafka.conf -n a1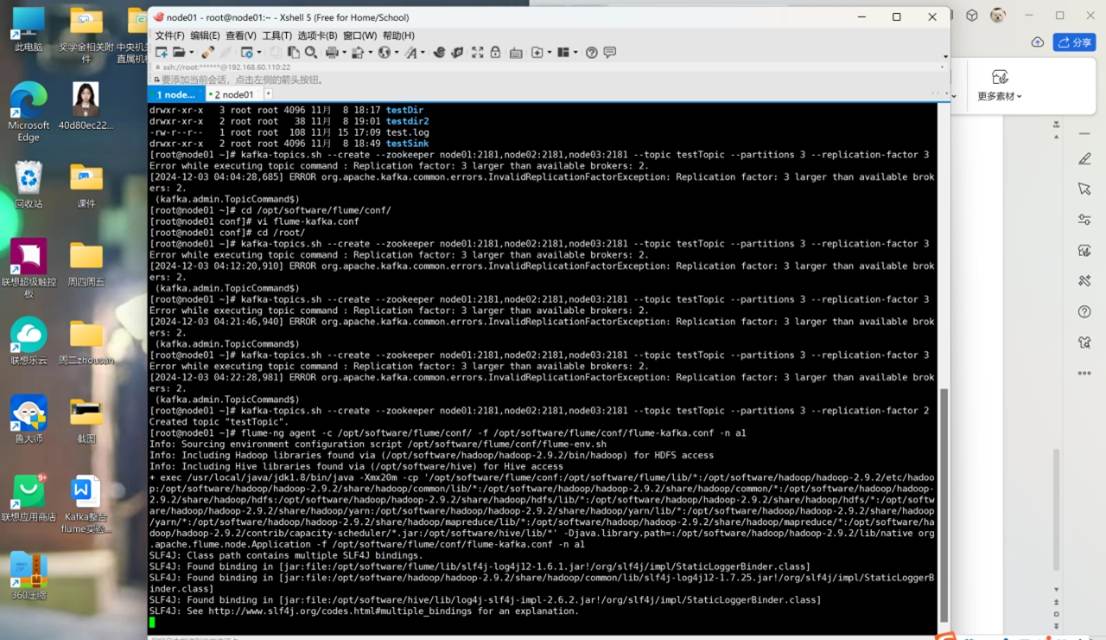
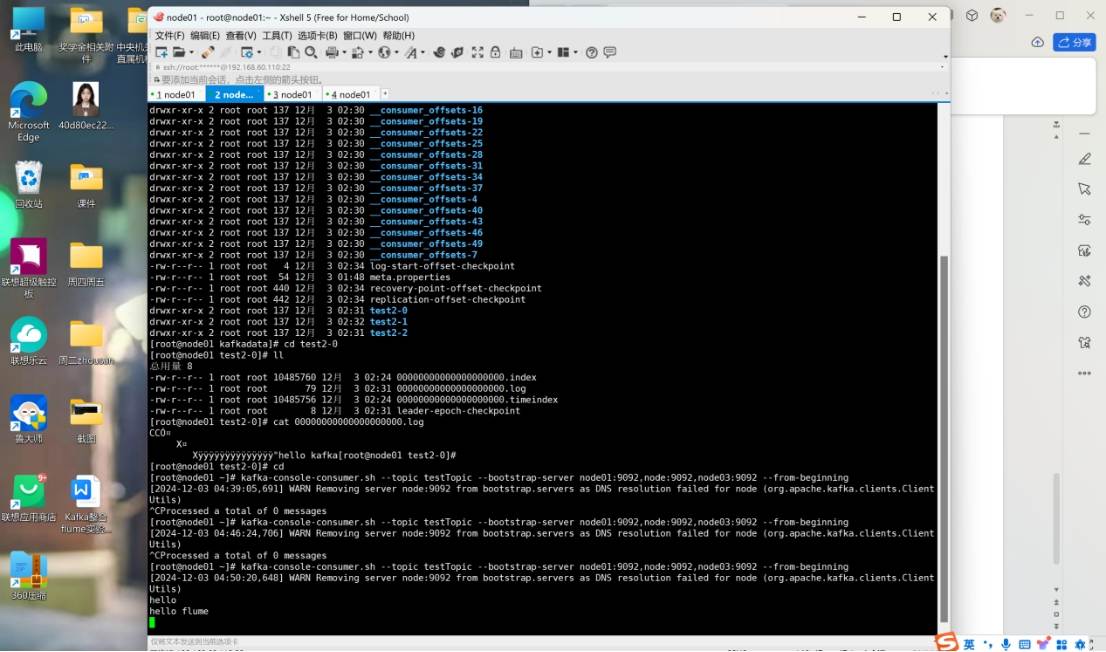
kafka-console-consumer.sh --topic testTopic --bootstrap-server node01:9092,node:9092,node03:9092 --from-beginning
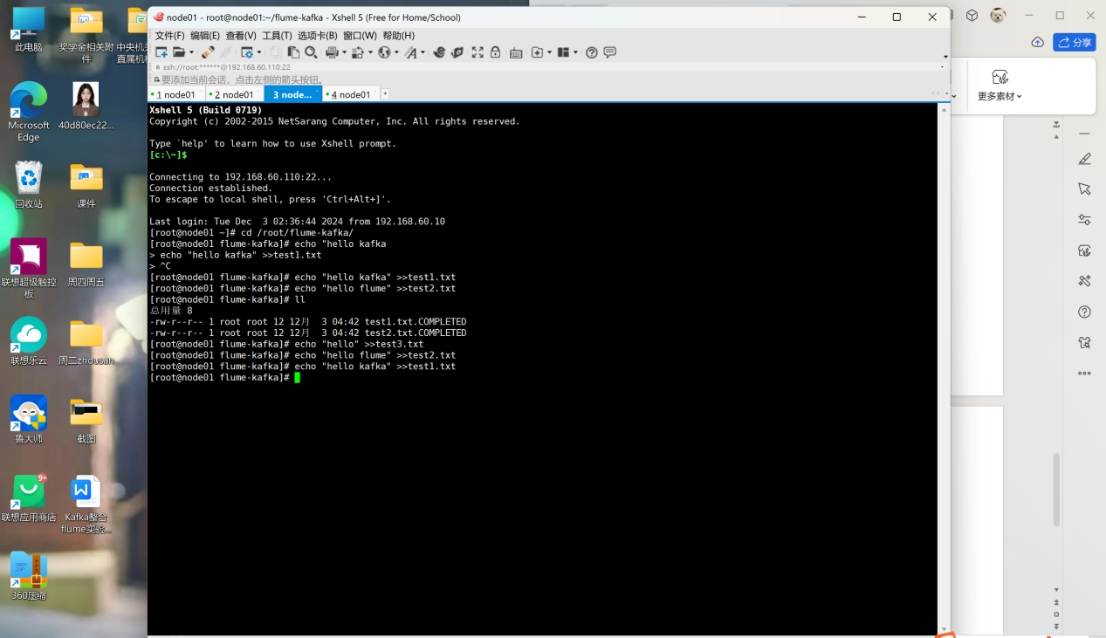
cd /root/flume-kafka/
echo "hello" >>test3.txt
echo "hello flume" >>test2.txt
cd /opt/software/flume/conf/
vi kafka-flume.conf
kafka-console-consumer.sh --topic testTopic --bootstrap-server node01:9092,node:9092,node03:9092 --from-beginning
Hello
hello kafka
hello flume
flume-ng agent -c conf/ -f conf/kafka-flume.conf -n a1 -Dflume.root.logger=INFO,console
二、kafka架构深入
分区策略:轮询(RoundRobin)、按 Key 哈希(Hash)、自定义分区。
数据可靠性:通过 ACK 机制(0、1、-1)和 ISR(同步副本集合)保证,acks=-1时需等待 Leader 和 Follower 全部落盘。
事务与幂等性:0.11 版本引入幂等性(enable.idompotence=true),结合 At Least Once 实现 Exactly Once 语义。
三、Spark-Streaming核心编程
1.DStream 转换
DStream 是 Spark-Streaming 处理实时数据的基本单位,可以理解为 "实时数据流"。
转换操作就是对这个数据流进行加工处理,比如过滤、拆分、统计等,就像工厂流水线对原材料进行加工一样。
操作分为两类:
无状态转换:只处理当前批次的数据,不关心历史数据(比如统计当前 3 秒内的单词数)。
有状态转换:会记住历史数据(比如统计从程序启动到现在的总单词数),文档里没详细讲,重点在无状态部分。
2.无状态转换的常见操作
无状态转换就像 "即处理即丢弃",每次只处理当前批次的数据,不保留之前的结果。
常见函数举例

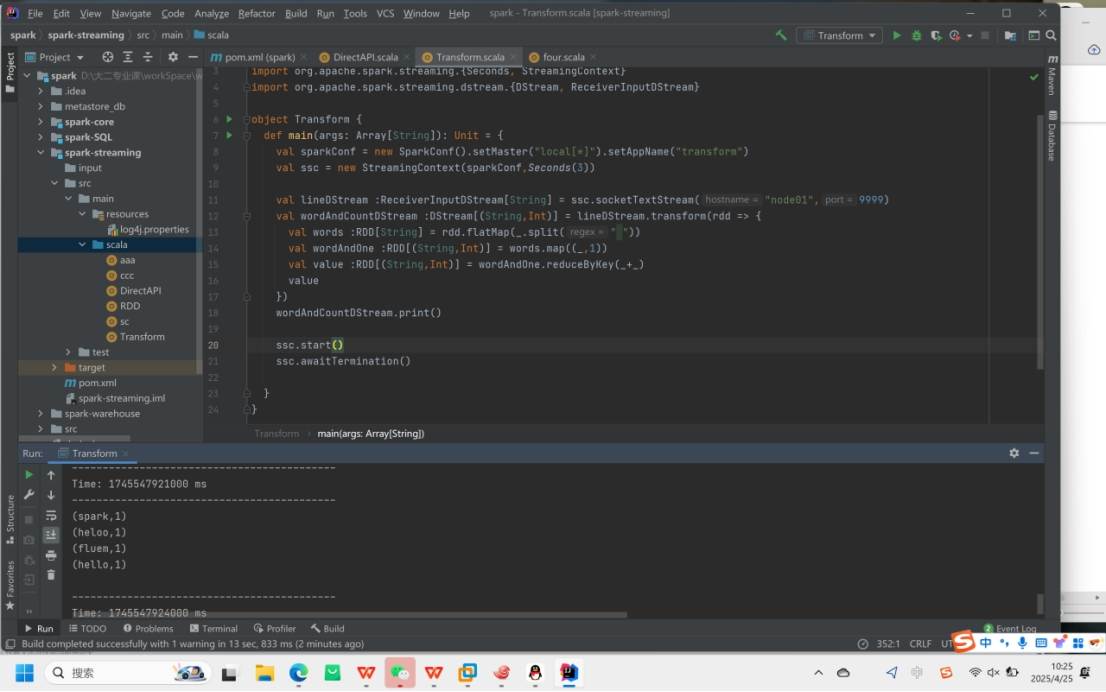
3.Transform转换
Transform是一个 "万能转换" 函数,可以对每个批次的 RDD(DStream 内部由多个 RDD 组成)执行任意自定义操作,甚至可以使用 Spark 原生的 RDD 函数(即使 DStream 没有直接提供)
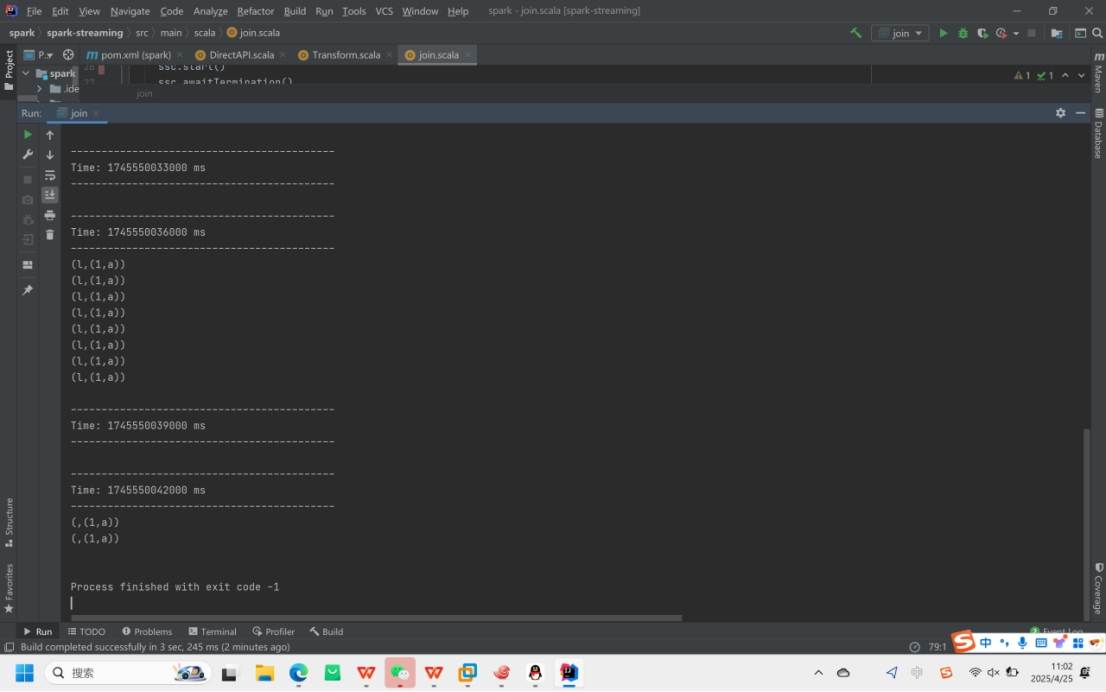
4.Join转换
join用于合并两个数据流中相同键的数据,就像拼拼图一样,只有键匹配的部分才能拼在一起。
适用于合并两个来源的单词数据
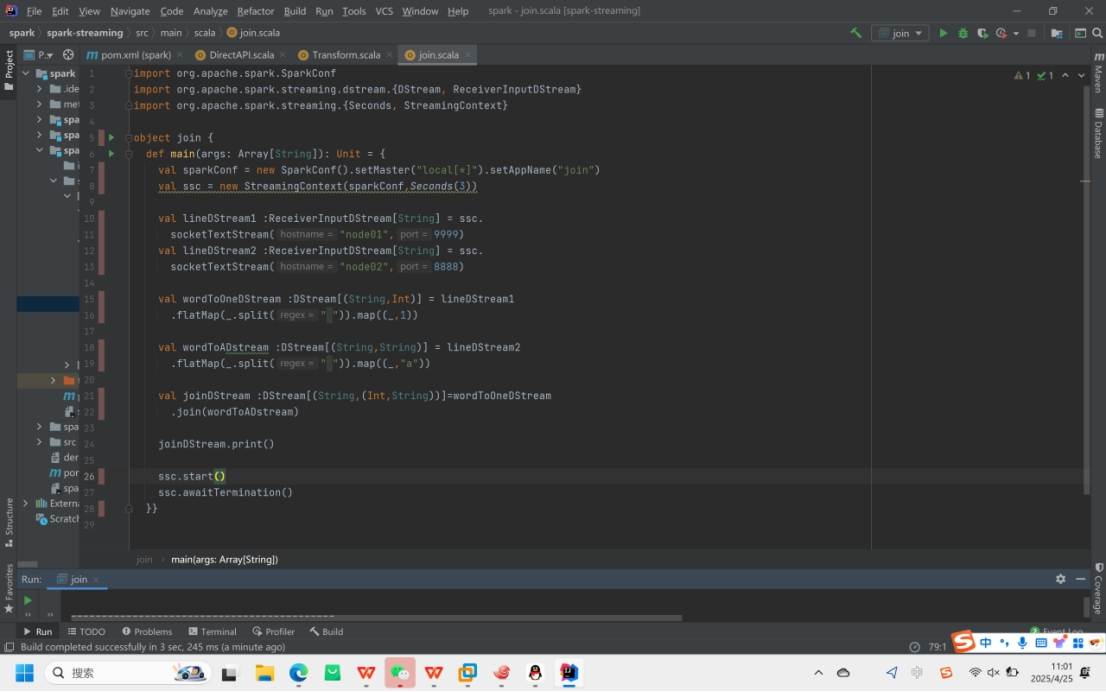
最后运行结果