Spark SQL 数组函数合集
官网:
https://spark.apache.org/docs/latest/api/sql/index.html#array

函数分类 & 用途一览表:
| 函数名 | 类型 | 用途 |
|---|---|---|
array_agg |
聚合 | 收集字段为数组 |
array_contains |
检查 | 判断数组是否包含某个值 |
array_size |
查询 | 获取数组长度 |
array_sort |
排序 | 对数组排序 |
array_distinct |
去重 | 去除数组中的重复元素 |
array_remove |
修改 | 删除数组中某个值 |
array_append / array_prepend |
修改 | 在数组尾部/头部添加元素 |
array_union / array_intersect / array_except |
集合操作 | 并集、交集、差集 |
array_join |
转换 | 把数组转成字符串 |
array_max / array_min |
查询 | 获取数组中的最大/最小值 |
array_position |
查询 | 获取某个值在数组中的位置 |
arrays_overlap |
检查 | 两个数组是否有交集 |
arrays_zip |
合并 | 合并多个数组为结构数组 |
array_compact |
清洗 | 删除数组中的 NULL 值 |
array_repeat |
构造 | 重复构造数组 |
array_insert |
修改 | 在指定位置插入元素 |
Demo with 龙珠🤣🤣🤣
底表:
1. array_contains
https://spark.apache.org/docs/latest/api/sql/index.html#array_contains

- 判断是否拥有某个技能
sql
SELECT name, array_contains(skills, '龟派气功') AS has_kamehameha
FROM dragon_ball_skills;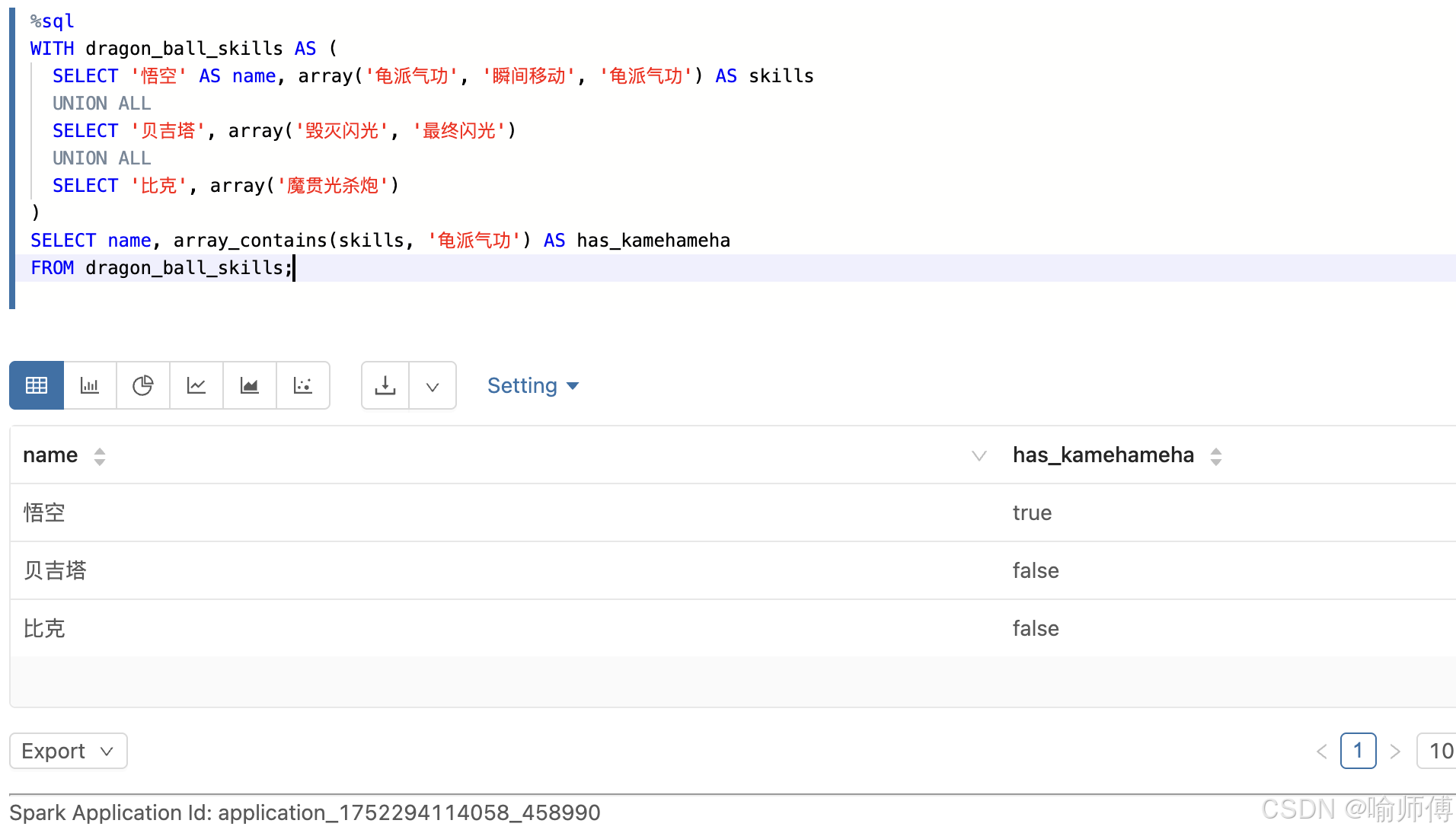
- 不可传null

org.apache.spark.sql.AnalysisException: cannot resolve 'array_contains(dragon_ball_skills.skills, NULL)' due to data type mismatch:
Null typed values cannot be used as arguments;
2. array_size
https://spark.apache.org/docs/latest/api/sql/index.html#array_size

- 查看技能数量
sql
SELECT name, array_size(skills) AS skill_count
FROM dragon_ball_skills;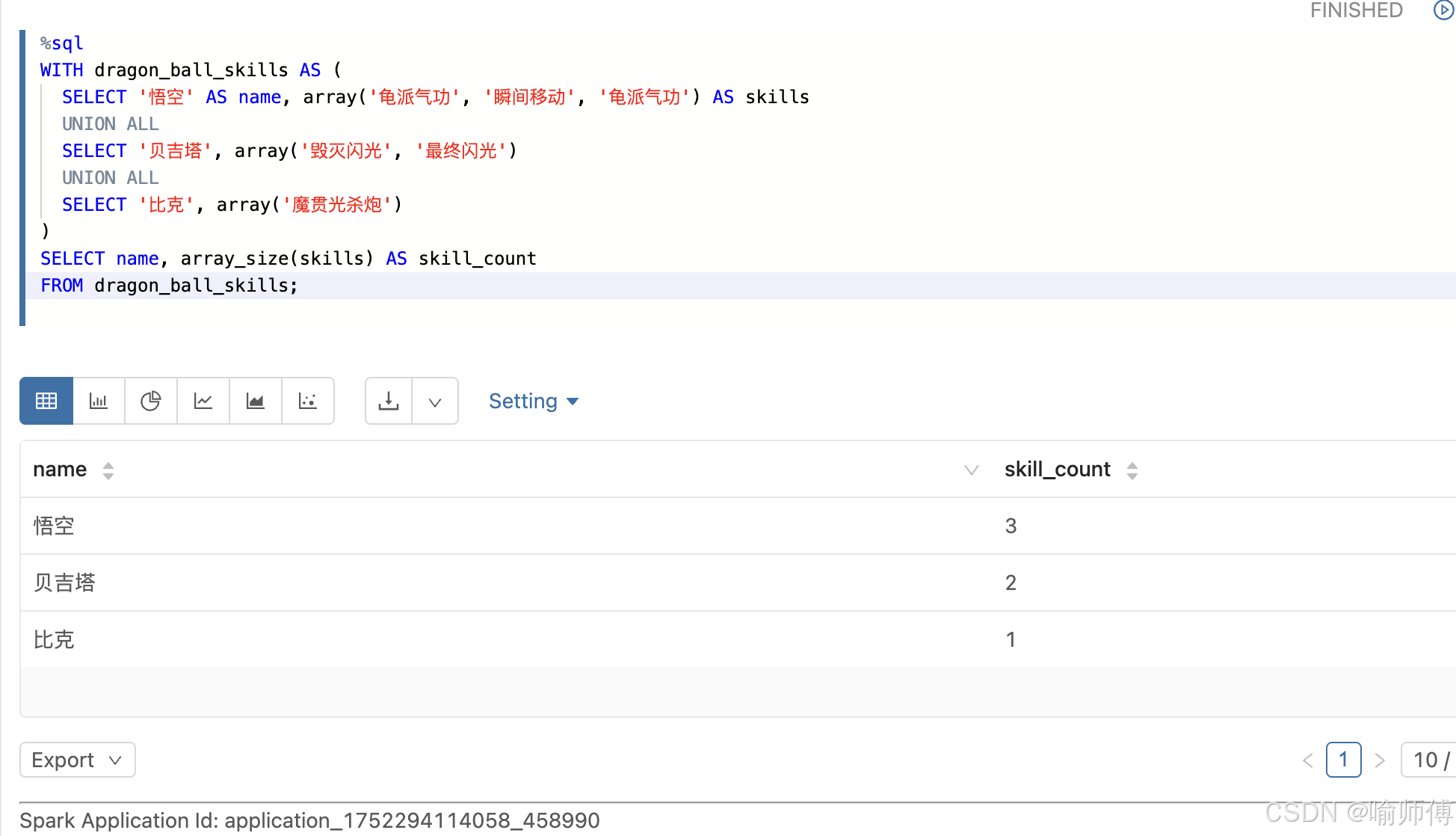
- 不可传null

3. array_distinct
https://spark.apache.org/docs/latest/api/sql/index.html#array_distinct

- 去重技能
sql
SELECT name, array_distinct(skills) AS unique_skills
FROM dragon_ball_skills;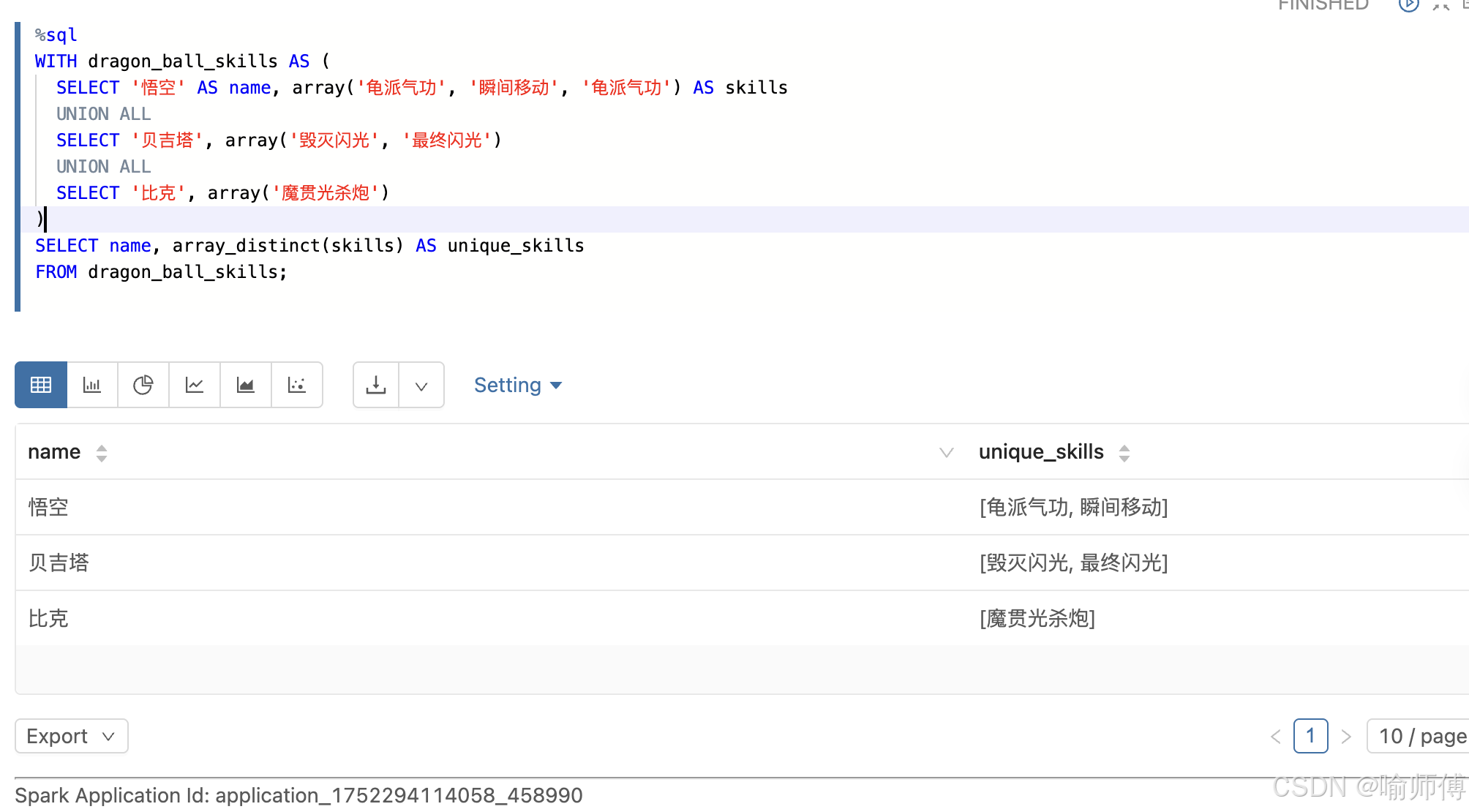
- 不可传null

4. array_sort
https://spark.apache.org/docs/latest/api/sql/index.html#array_sort
这个排序函数细节很多,博主会单独出一期讲解。可以在博主主页搜索哈。

- 按字母排序技能
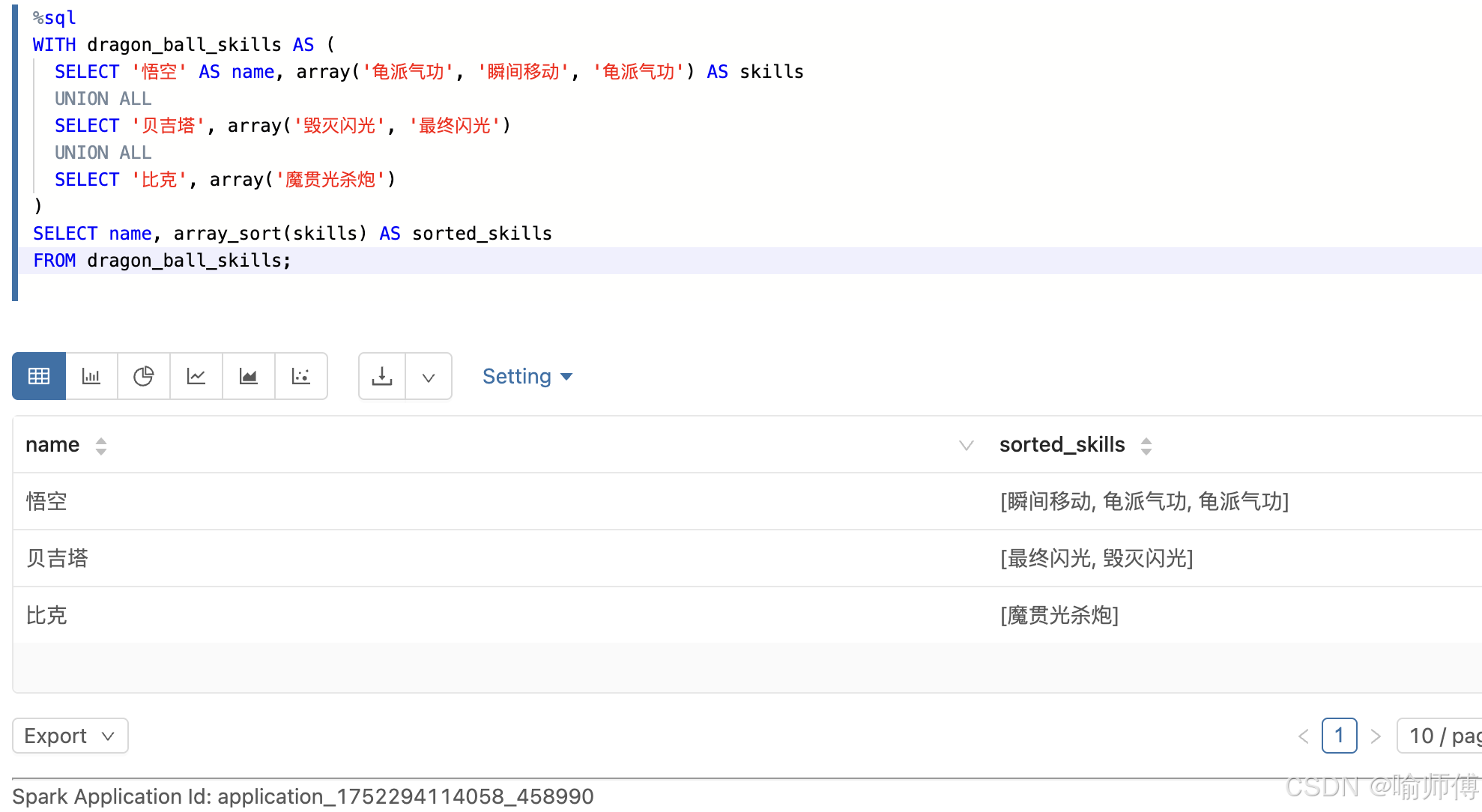
5. array_append / array_prepend
https://spark.apache.org/docs/latest/api/sql/index.html#array_append

https://spark.apache.org/docs/latest/api/sql/index.html#array_prepend

- 从数组前后加入数据 就不展开讲了
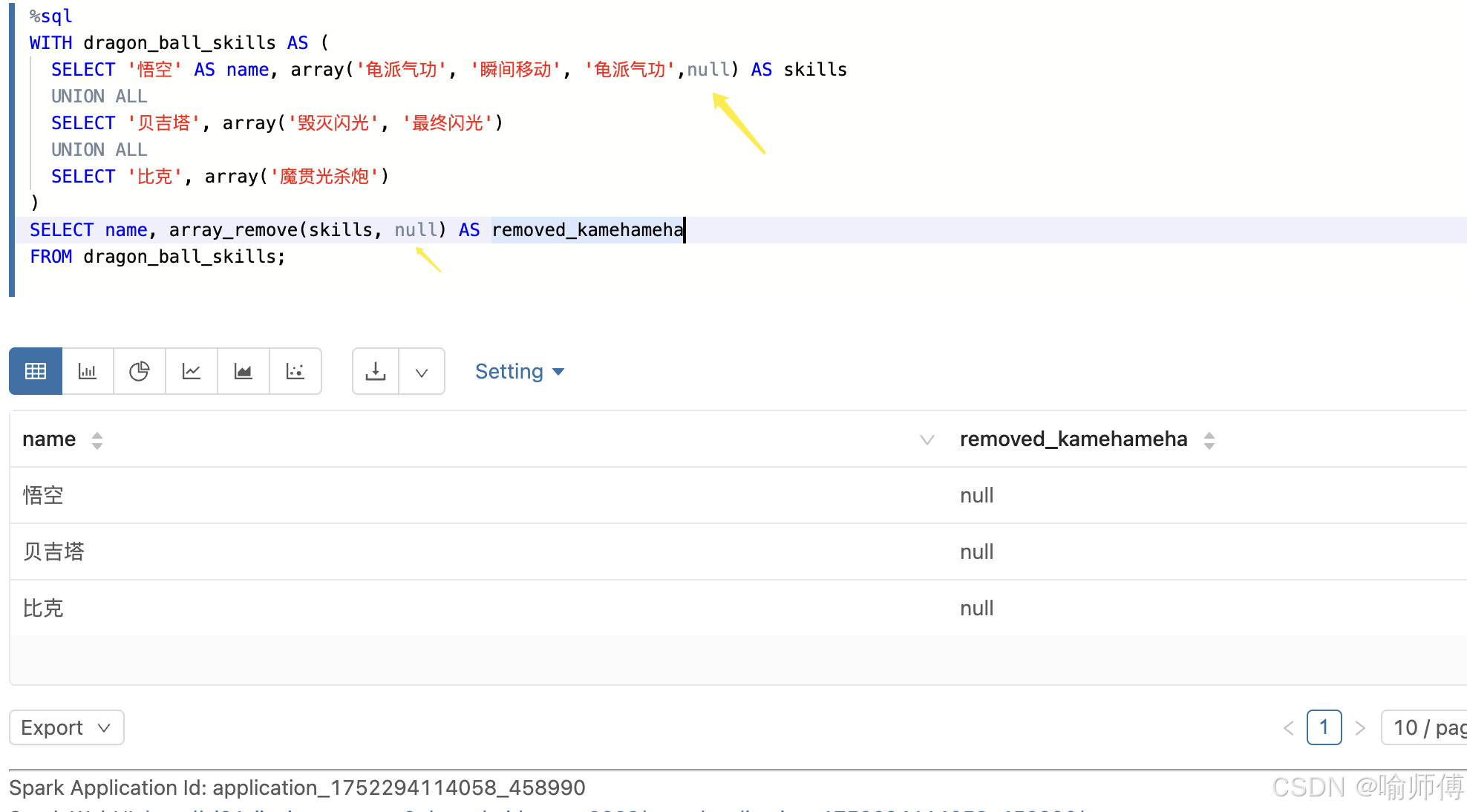
6. array_remove
https://spark.apache.org/docs/latest/api/sql/index.html#array_remove

- 删除某个技能
sql
SELECT name, array_remove(skills, '龟派气功') AS removed_kamehameha
FROM dragon_ball_skills;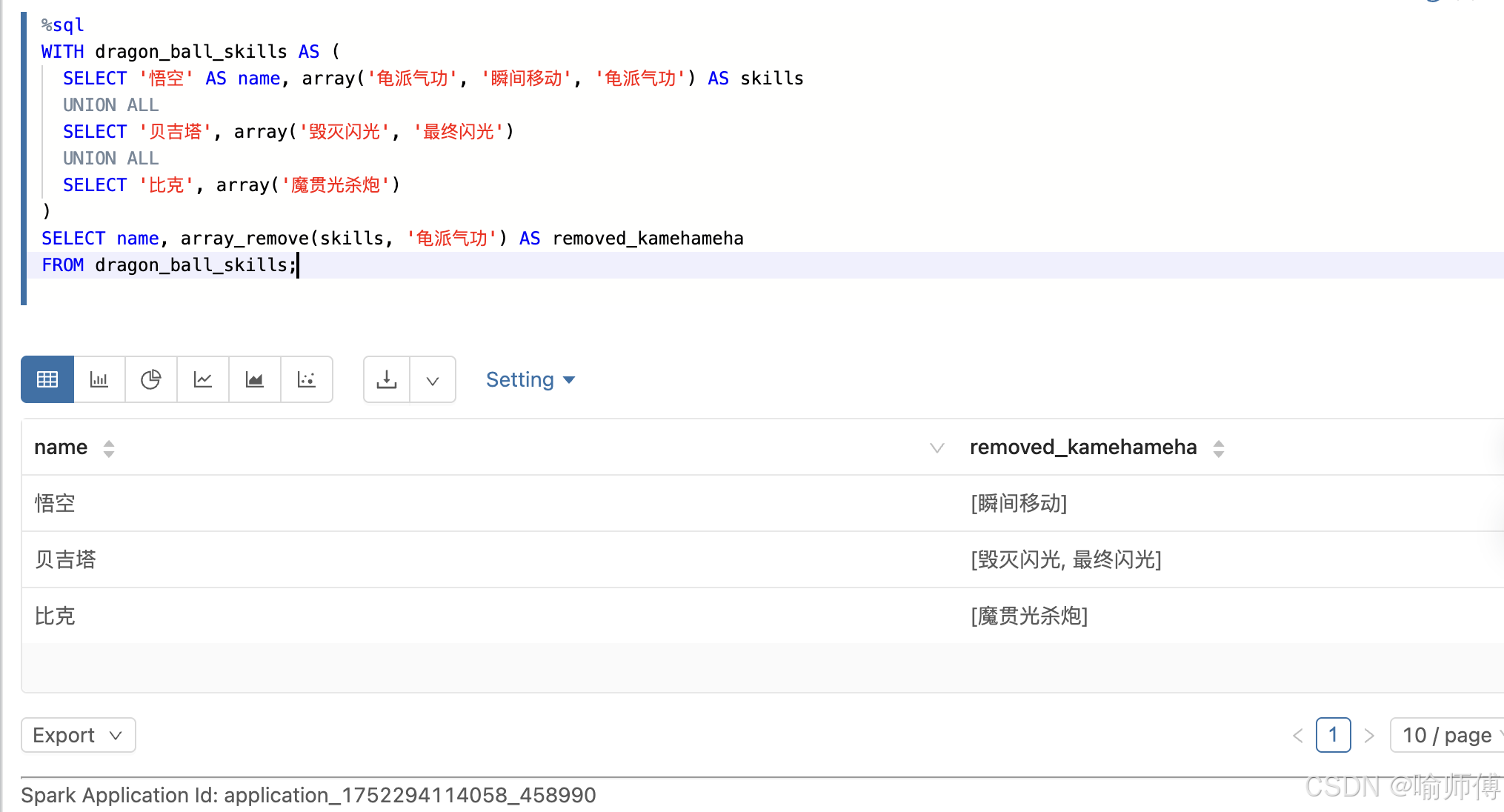
- 注意null值的处理
7. array_union
https://spark.apache.org/docs/latest/api/sql/index.html#array_union

- 合并两个技能数组
sql
SELECT array_union(array('龟派气功', '瞬间移动'), array('元气弹')) AS all_skills;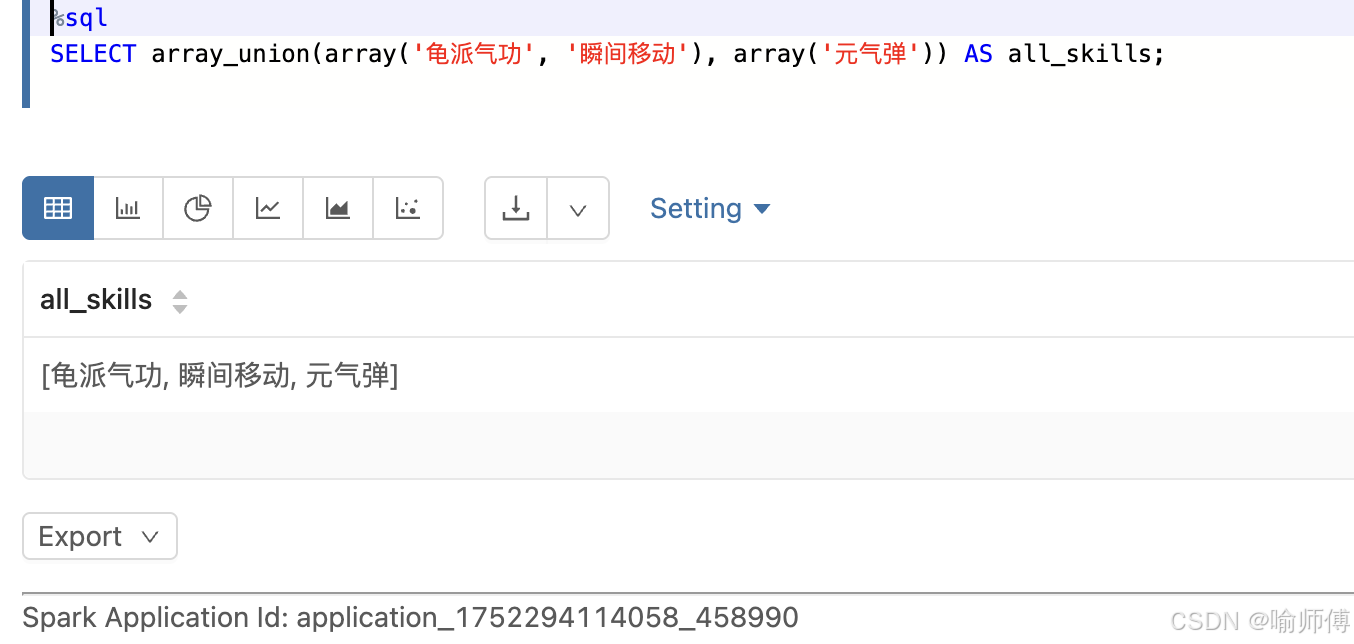
- 不可传null

org.apache.spark.sql.AnalysisException: cannot resolve 'array_union(array('龟派气功', '瞬间移动'), NULL)' due to data type mismatch:
input to function array_union should have been two arrays with same element type, but it's [array<string>, void];

org.apache.spark.sql.AnalysisException: cannot resolve 'array_union(NULL, NULL)' due to data type mismatch:
input to function array_union should have been two arrays with same element type, but it's [void, void];
8. array_intersect
https://spark.apache.org/docs/latest/api/sql/index.html#array_intersect

- 查找共同技能
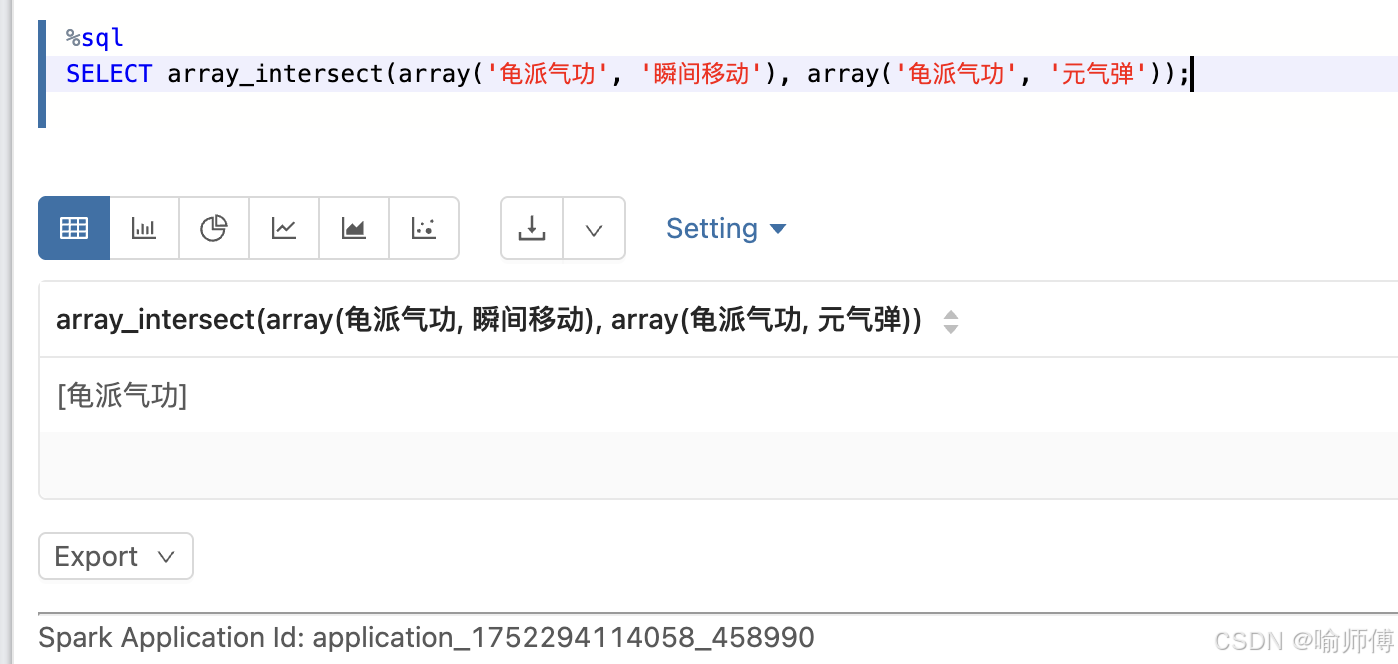
["龟派气功"]9. arrays_overlap
https://spark.apache.org/docs/latest/api/sql/index.html#arrays_overlap
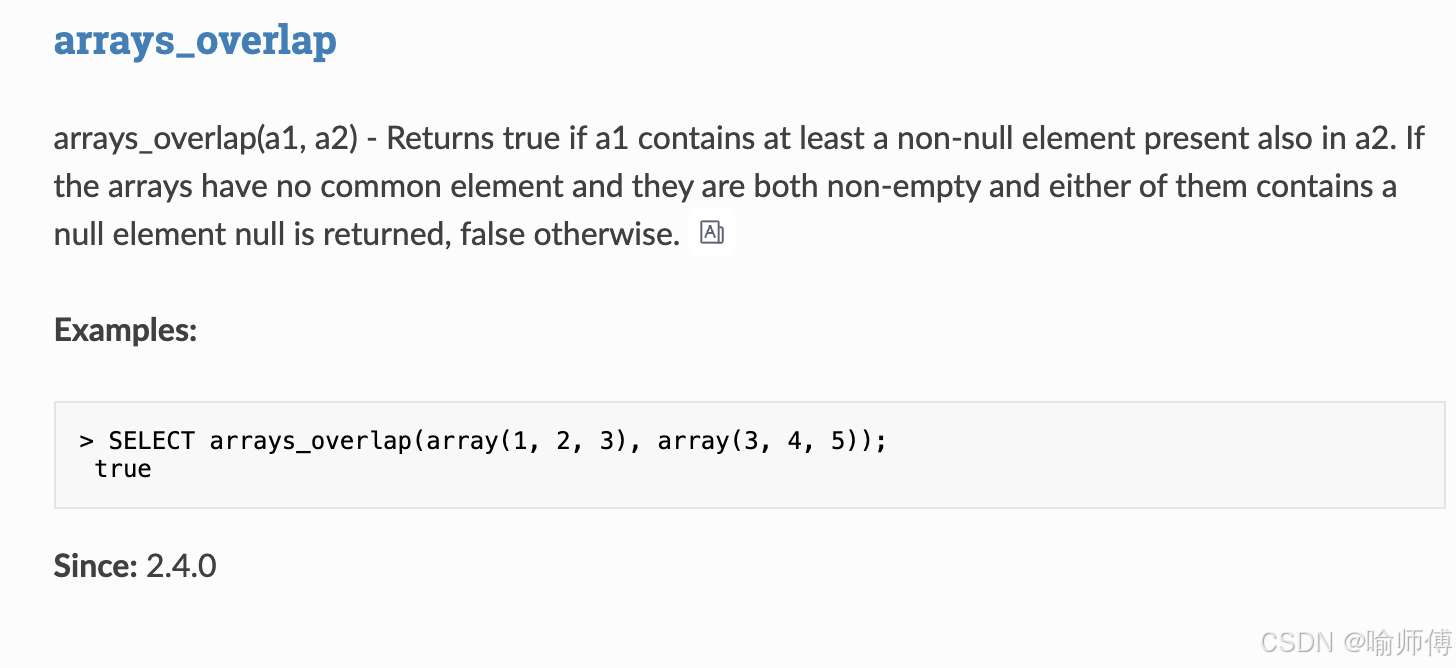
sql
arrays_overlap(a1, a2) 如果数组
a1和a2至少有一个非空元素相同 ,则返回true。
否则,分情况讨论:
- 如果两个数组 都没有共同元素 :
- 并且两个数组 都不是空数组 :
- 其中一个数组含有
NULL,则返回NULL
- 其中一个数组含有
- 否则返回
false
- 并且两个数组 都不是空数组 :
只要两个数组中有一个非空值相同 ,就返回
true;否则看有没有NULL,没有就返回false。
使用时要注意处理NULL` 的情况。
1:有共同元素(非空)
sql
SELECT arrays_overlap(array(1, 2, 3), array(3, 4, 5));
-- 输出: true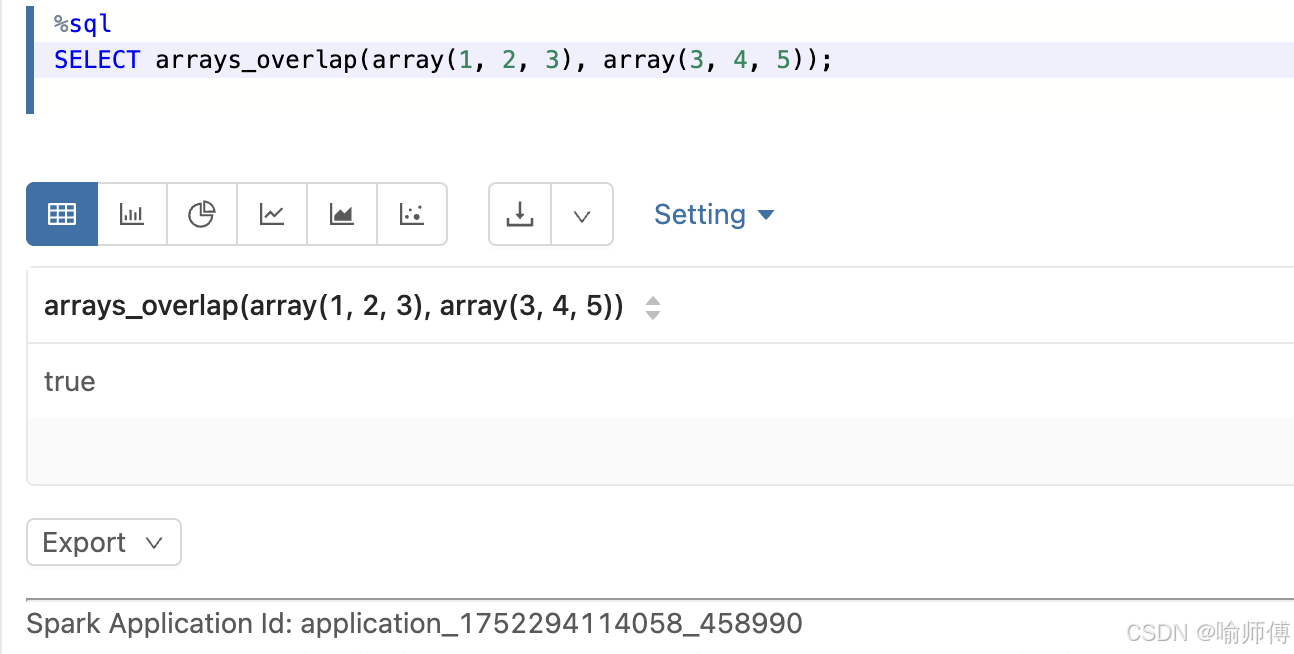
- 两个数组都有
3,所以返回true
2:没有共同元素,且都非空,但都没有 NULL
sql
SELECT arrays_overlap(array(1, 2), array(3, 4));
-- 输出: false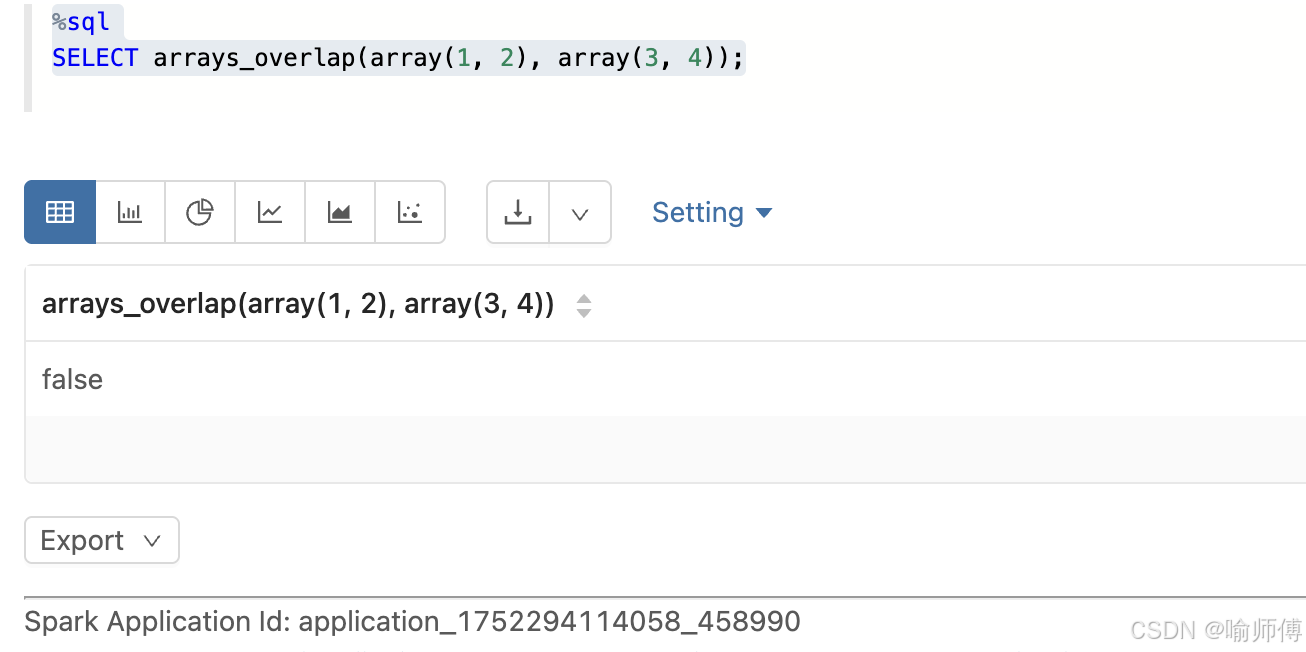
- 没有交集,也没有 NULL,返回
false
3:没有共同元素,但有一个数组含 NULL
sql
SELECT arrays_overlap(array(1, 2), array(3, NULL));
-- 输出: NULL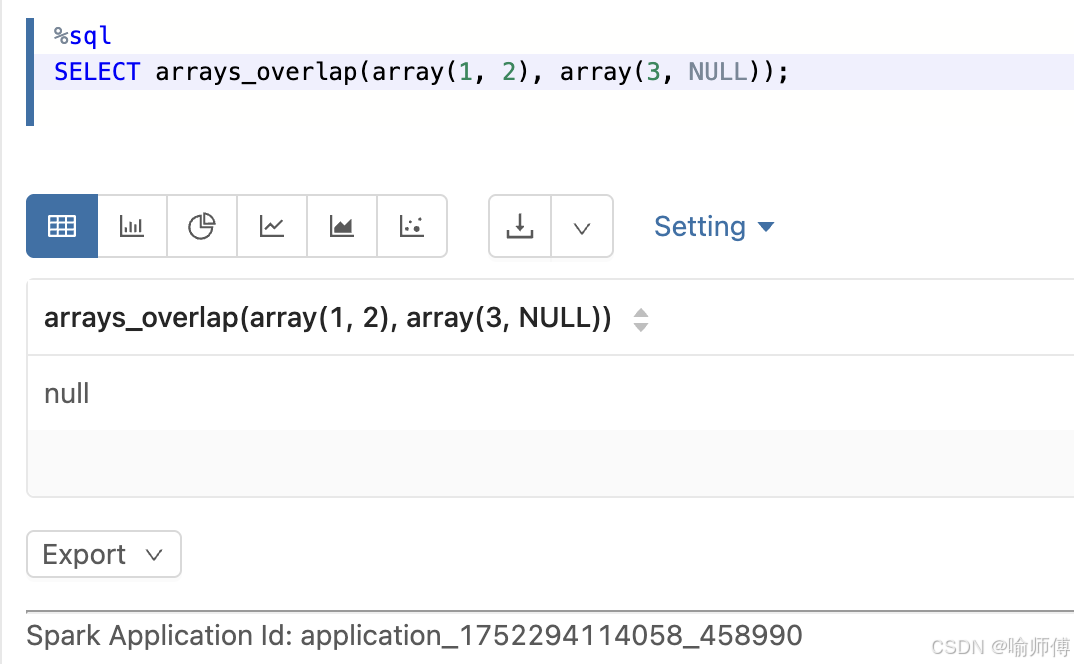
- 两个数组都不是空的,但没有共同元素,其中一个含有
NULL,所以返回NULL
4:两个数组都含有 NULL,但没有共同非空元素
sql
SELECT arrays_overlap(array(NULL, 1), array(NULL, 2));
-- 输出: NULL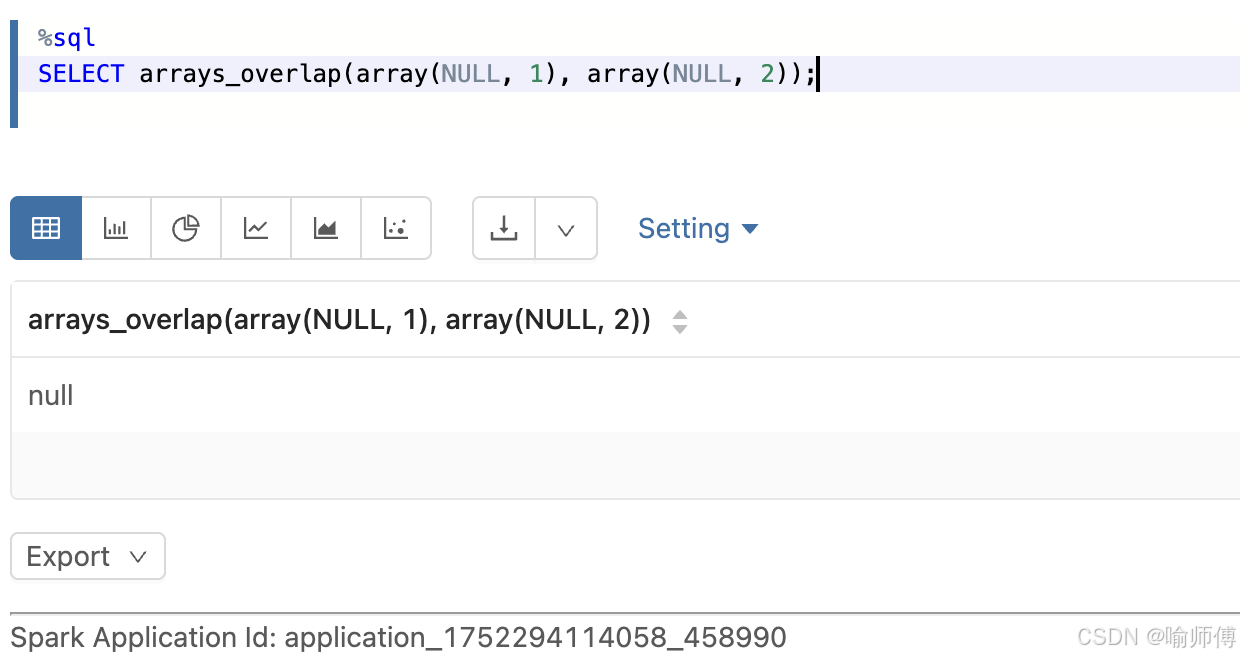
- 虽然都有
NULL,但没有共同的非空元素,所以返回NULL
5:一个数组为空,另一个有元素
sql
SELECT arrays_overlap(array(), array(1, 2));
-- 输出: false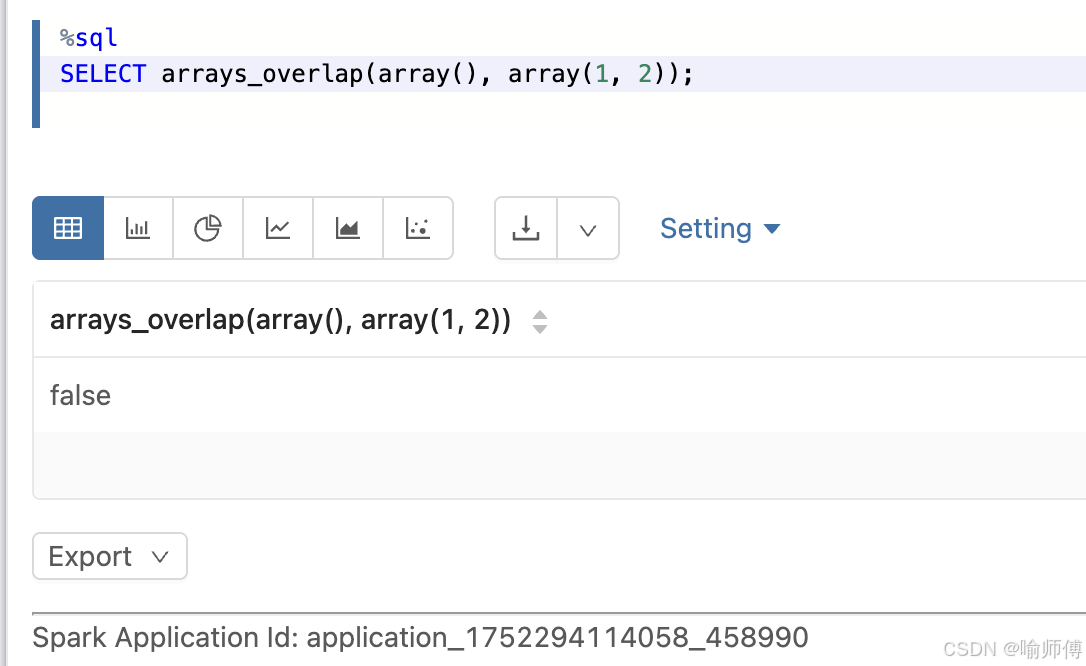
- 空数组和任何数组的交集都是
false
6:两个空数组
sql
SELECT arrays_overlap(array(), array());
-- 输出: false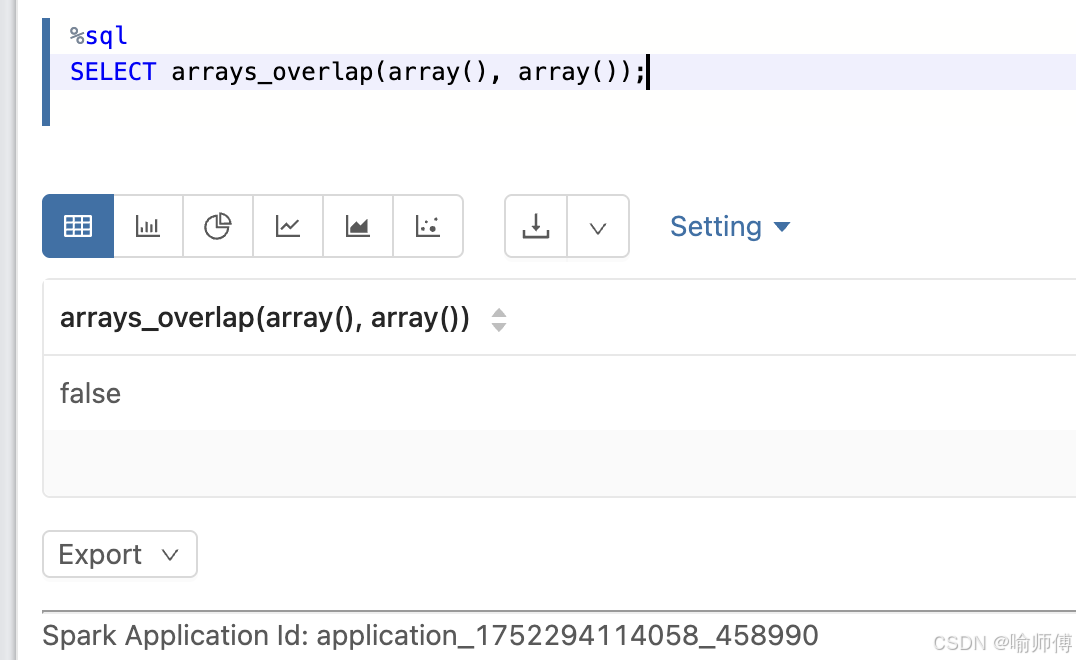
- 两个空数组没有交集,返回
false
- 判断是否有共同技能
sql
SELECT arrays_overlap(array('龟派气功', '瞬间移动'), array('龟派气功'));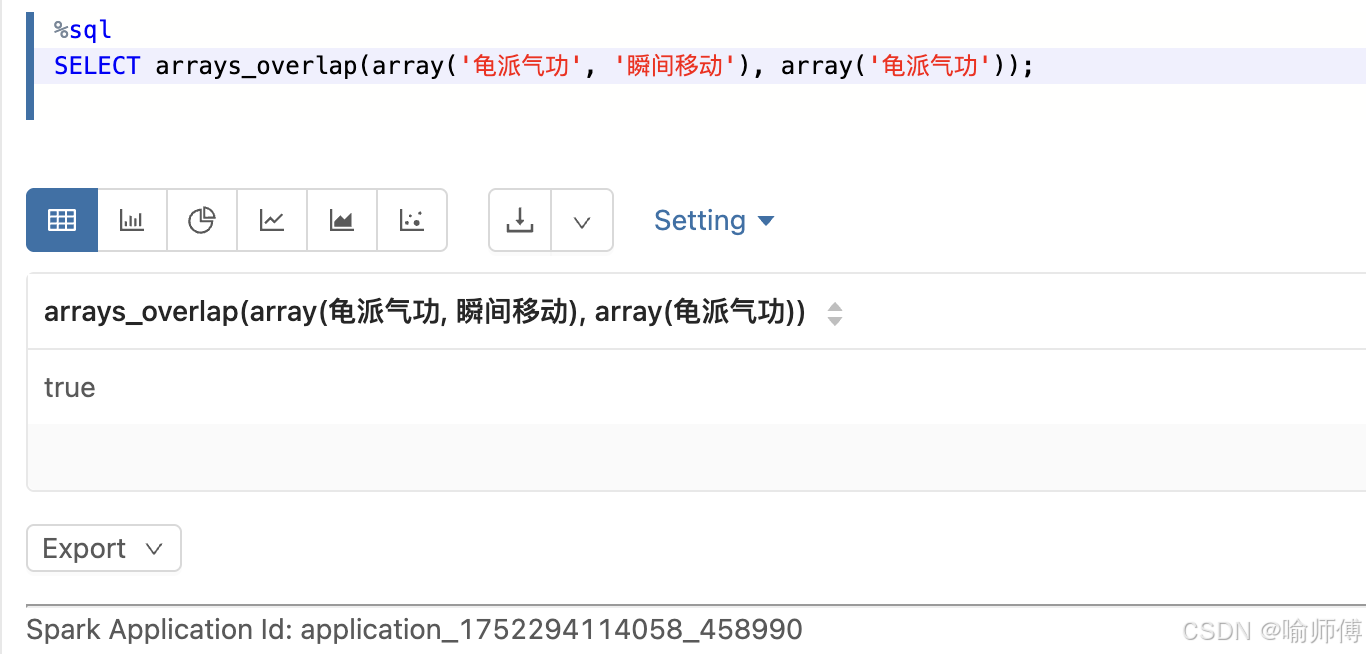
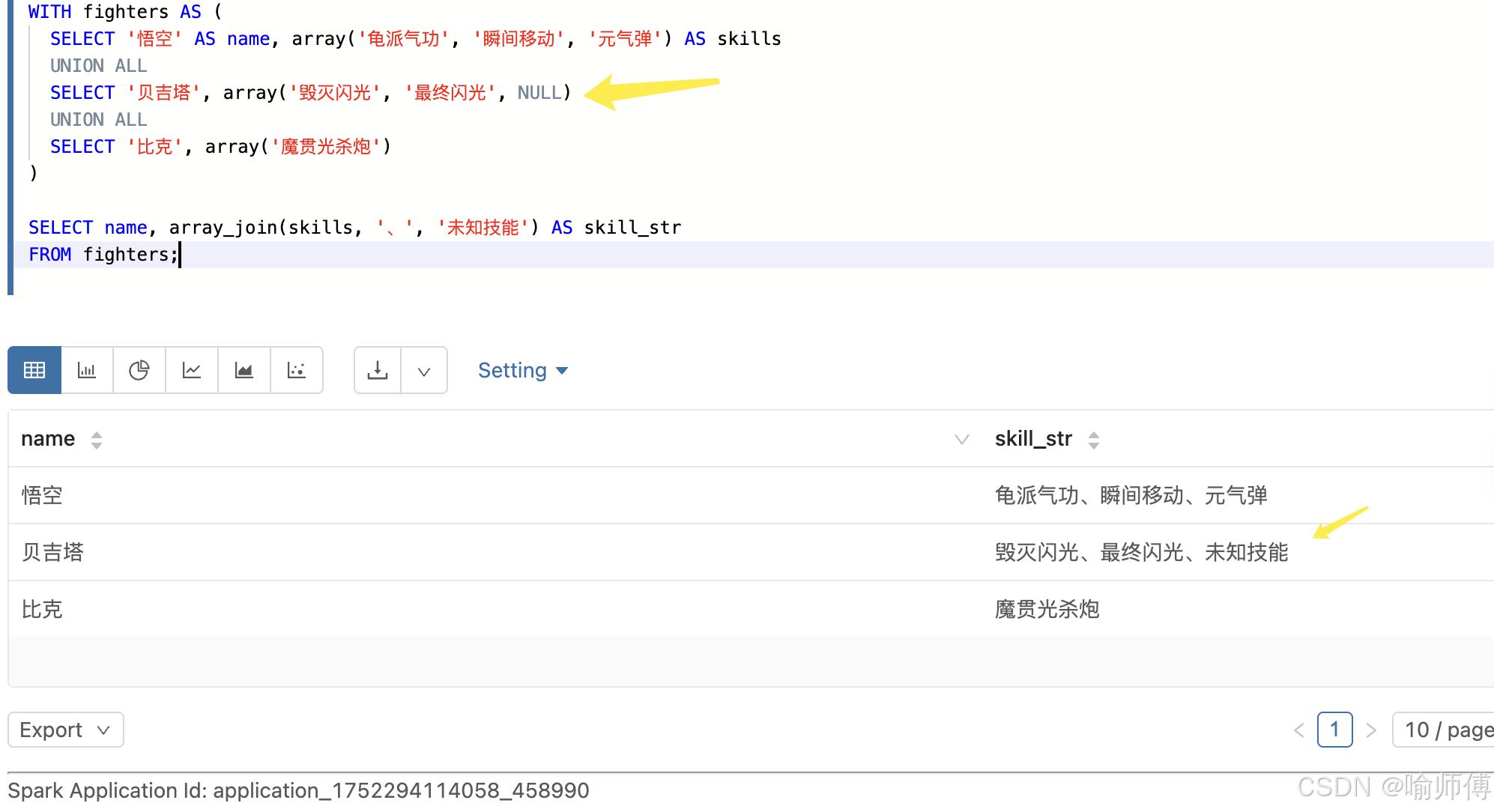
10. array_join
https://spark.apache.org/docs/latest/api/sql/index.html#array_join
array_join会将数组中的元素用指定的分隔符连接成一个字符串。如果数组中有
NULL值:
- 没有指定
nullReplacement:NULL被跳过- 指定了
nullReplacement:NULL被替换成该字符串

sql
array_join(array, delimiter[, nullReplacement])| 参数 | 类型 | 必须 | 说明 |
|---|---|---|---|
array |
ARRAY | ✅ | 要连接的数组 |
delimiter |
STRING | ✅ | 用于连接数组元素的分隔符(如空格、逗号、顿号等) |
nullReplacement |
STRING | ❌ | 可选参数,用于替换数组中的 NULL 值。如果不传,NULL 值将被忽略(不参与拼接) |
1:基础用法(无 NULL)
sql
SELECT array_join(array('kaka', 'luote'), ' ');
-- 输出: "kaka luote"2:数组中含 NULL,不传 nullReplacement
sql
SELECT array_join(array('kaka', null, 'luote'), ' ');
-- 输出: "kaka luote"NULL被忽略,不参与拼接。
3:数组中含 NULL,传 nullReplacement
sql
SELECT array_join(array('kaka', null, 'luote'), ' ', '------');
-- 输出: "kaka ------ luote"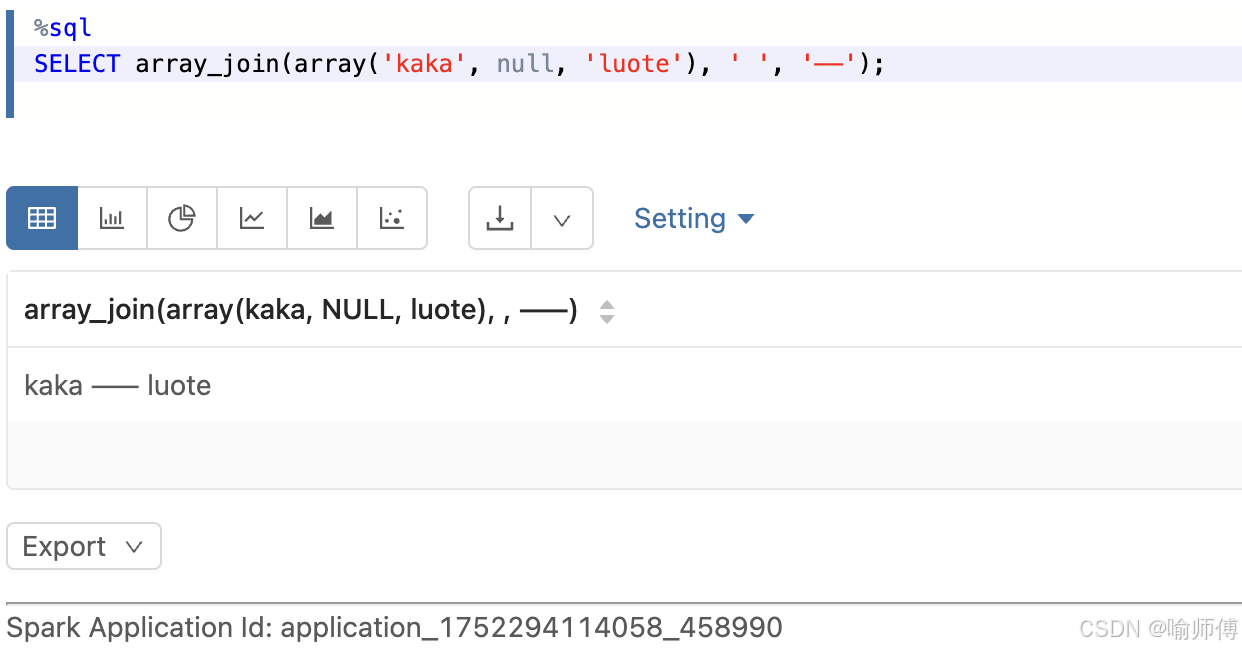
NULL被替换为------,然后参与拼接。
- 把技能转为字符串
sql
SELECT name, array_join(skills, '------') AS skill_str
FROM dragon_ball_skills;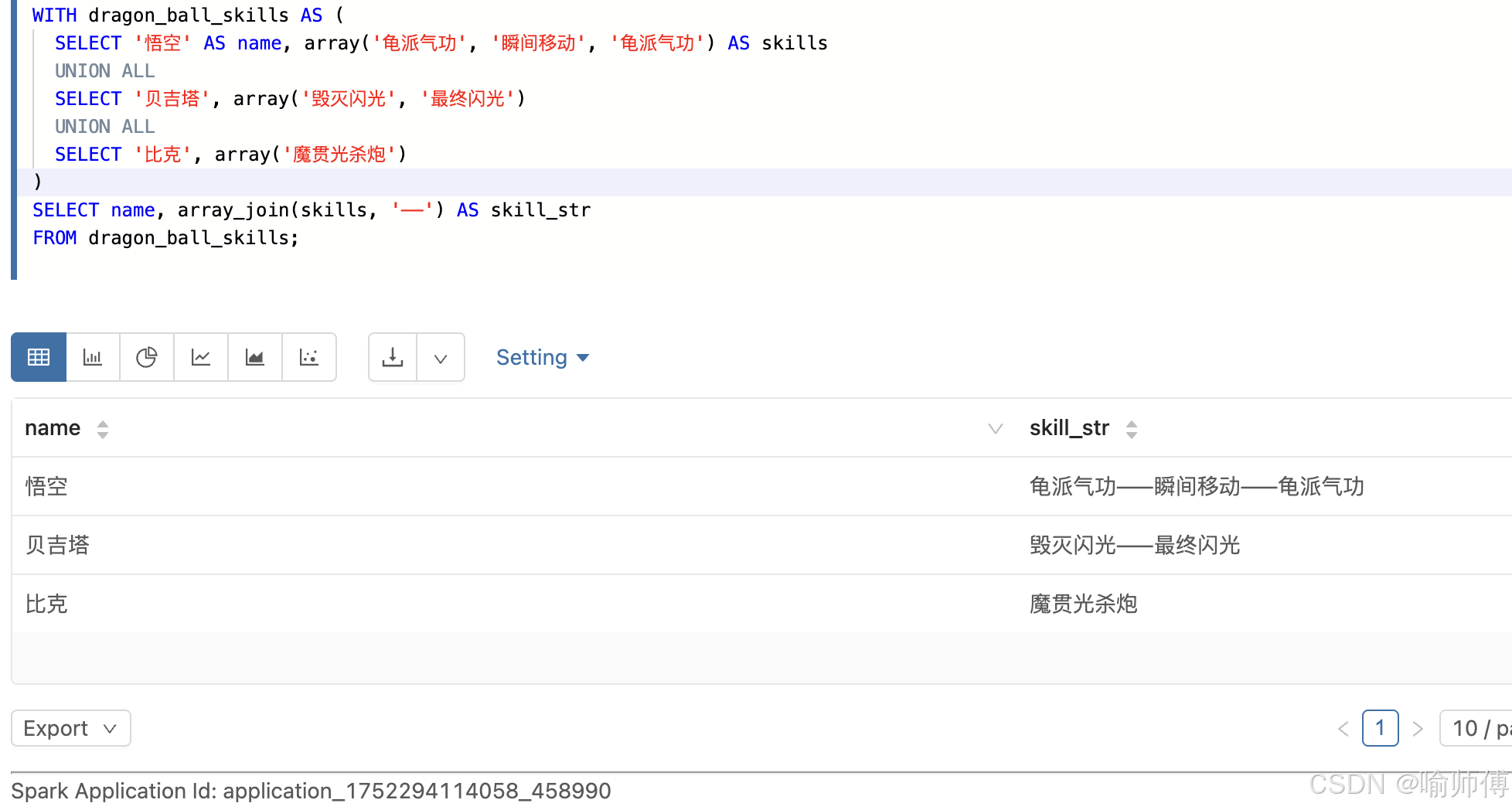
11. array_max / array_min
- 获取最大/最小值
https://spark.apache.org/docs/latest/api/sql/index.html#array_max
 http://spark.apache.org/docs/latest/api/sql/index.html#array_min
http://spark.apache.org/docs/latest/api/sql/index.html#array_min

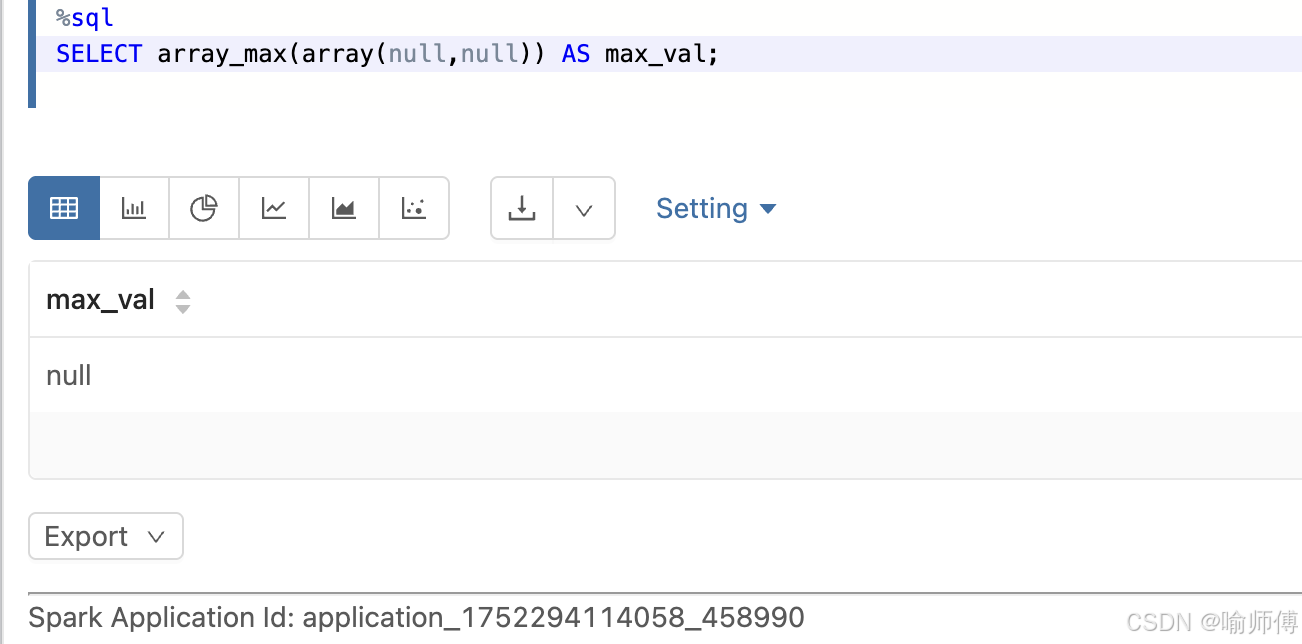
-
数组内只有null
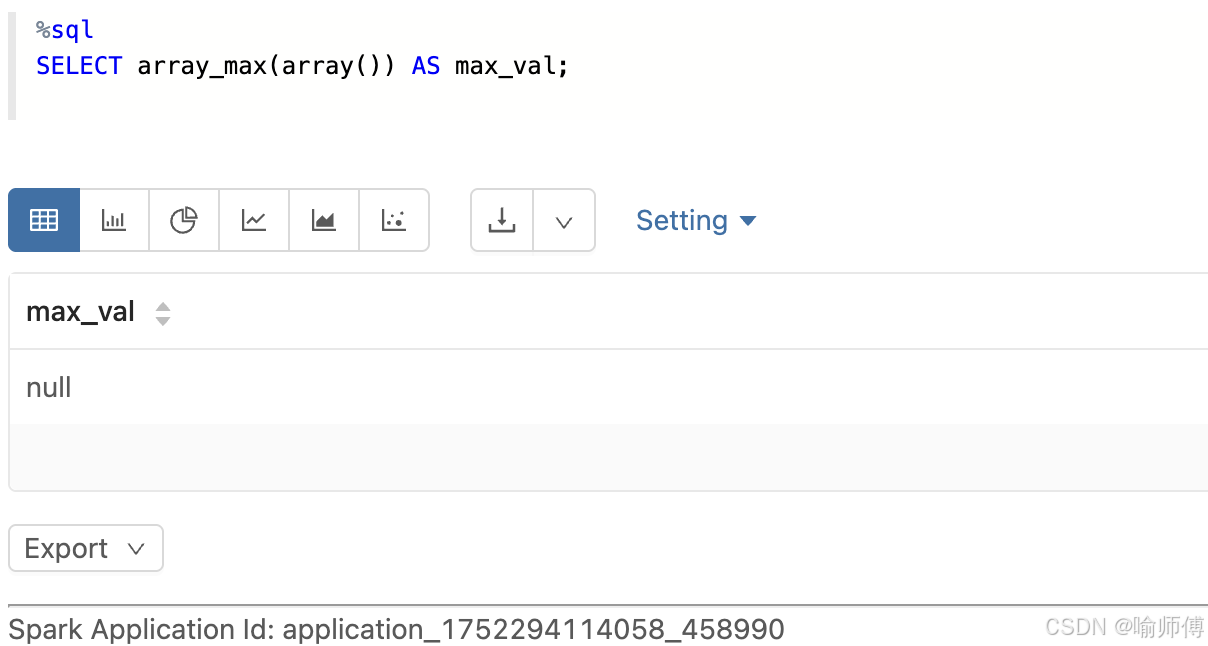
-
空数组
12. array_position
https://spark.apache.org/docs/latest/api/sql/index.html#array_position

tips:下标是从1开始的哈~。
- 查找元素位置
sql
SELECT array_position(array('龟派气功', '瞬间移动'), '瞬间移动'); -- 2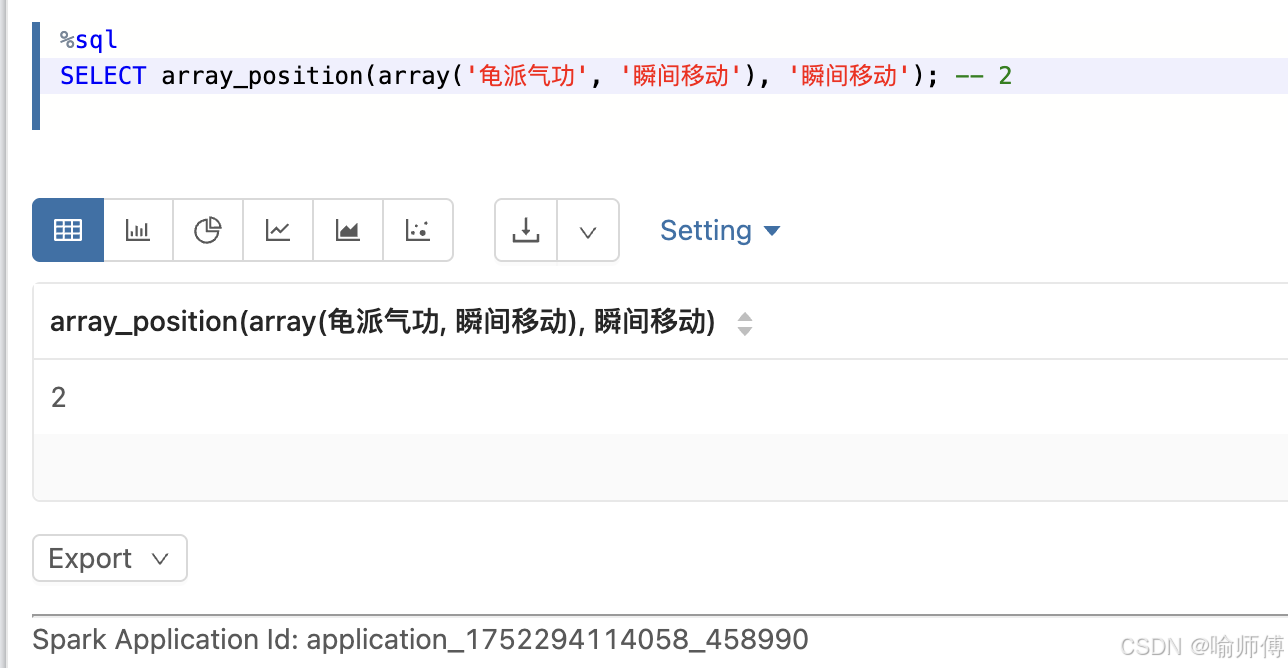
- 查找未知数据
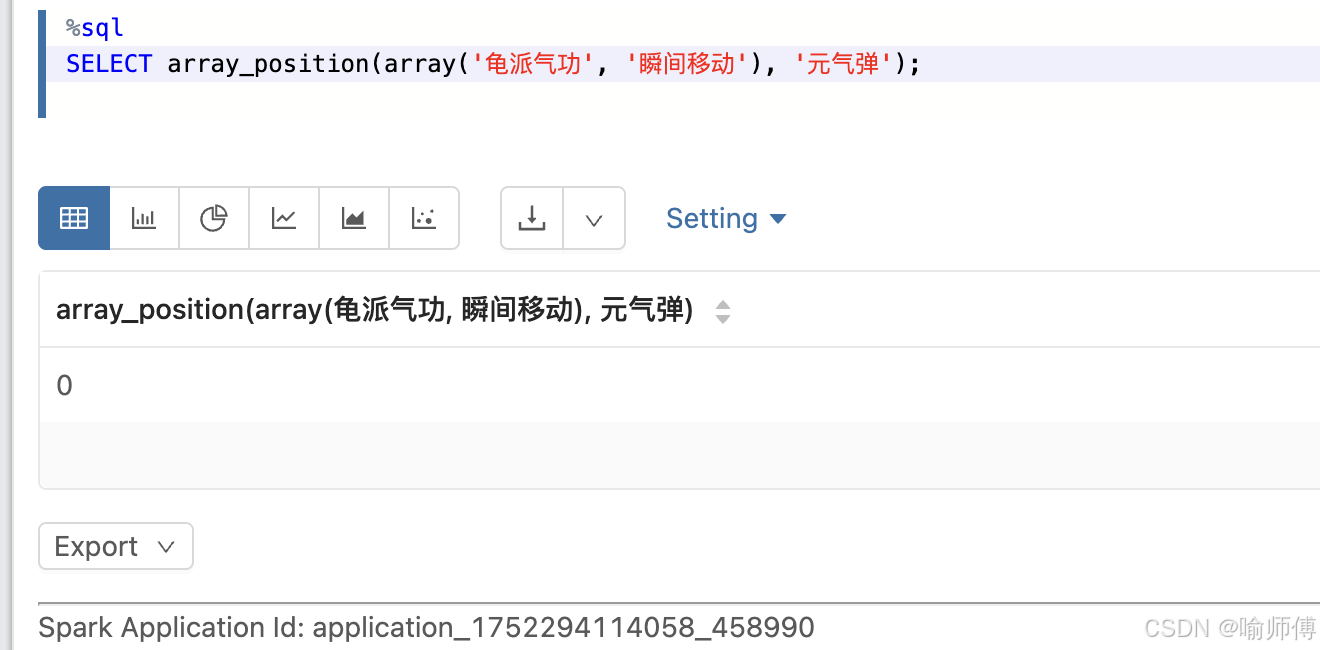
13. arrays_zip
https://spark.apache.org/docs/latest/api/sql/index.html#arrays_zip

- 合并多个数组为结构数组
sql
SELECT arrays_zip(array('Math', 'English'), array(90, 85));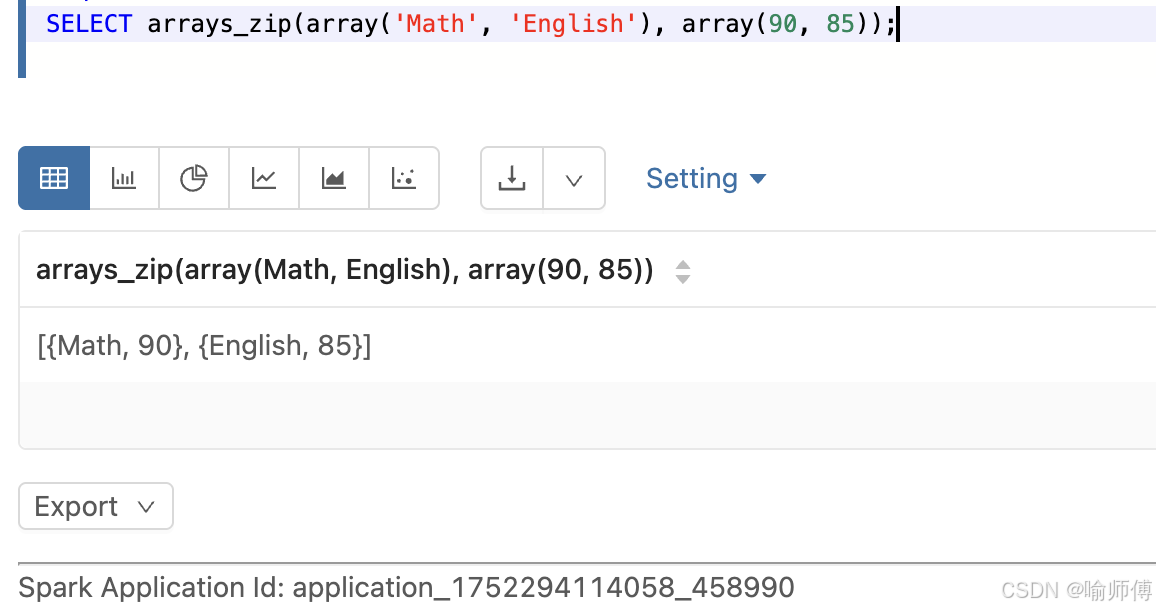
14. array_compact
https://spark.apache.org/docs/latest/api/sql/index.html#array_compact

- 删除数组中的 NULL 值
sql
SELECT array_compact(array(NULL, '龟派气功', NULL, '瞬间移动'));
-- ["龟派气功", "瞬间移动"]15. array_repeat
https://spark.apache.org/docs/latest/api/sql/index.html#array_repeat
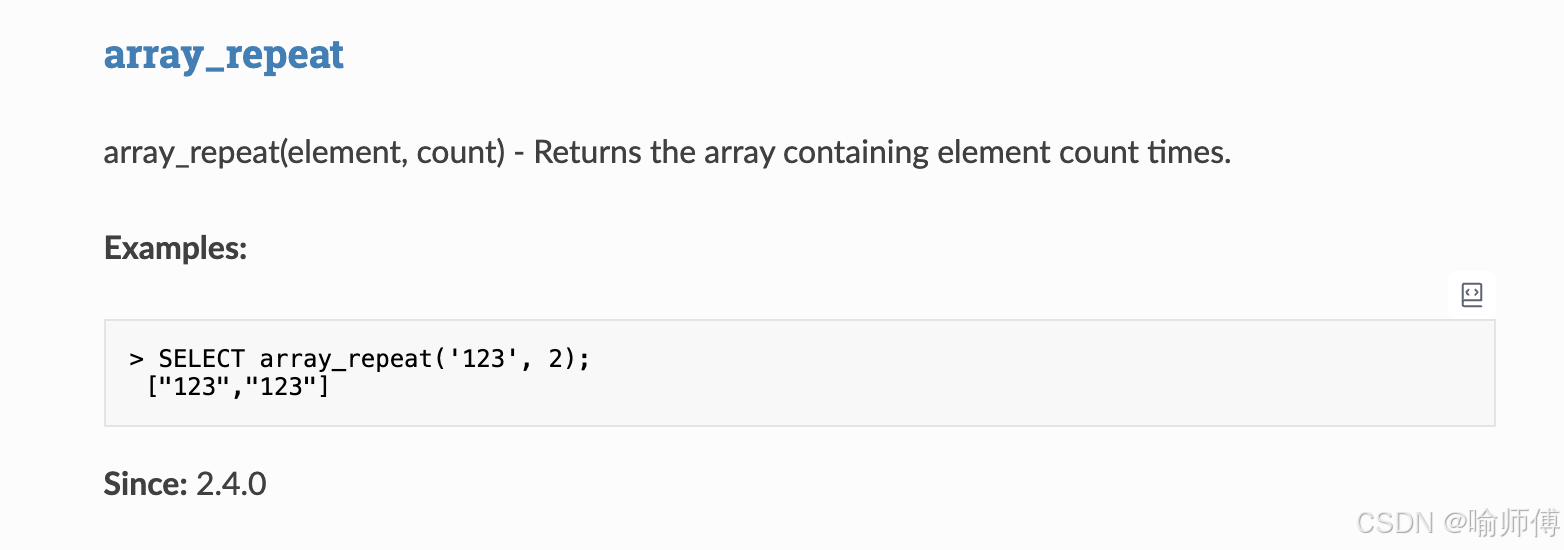
- 构造重复数组
sql
SELECT array_repeat('龟派气功', 3); -- ["龟派气功", "龟派气功", "龟派气功"]
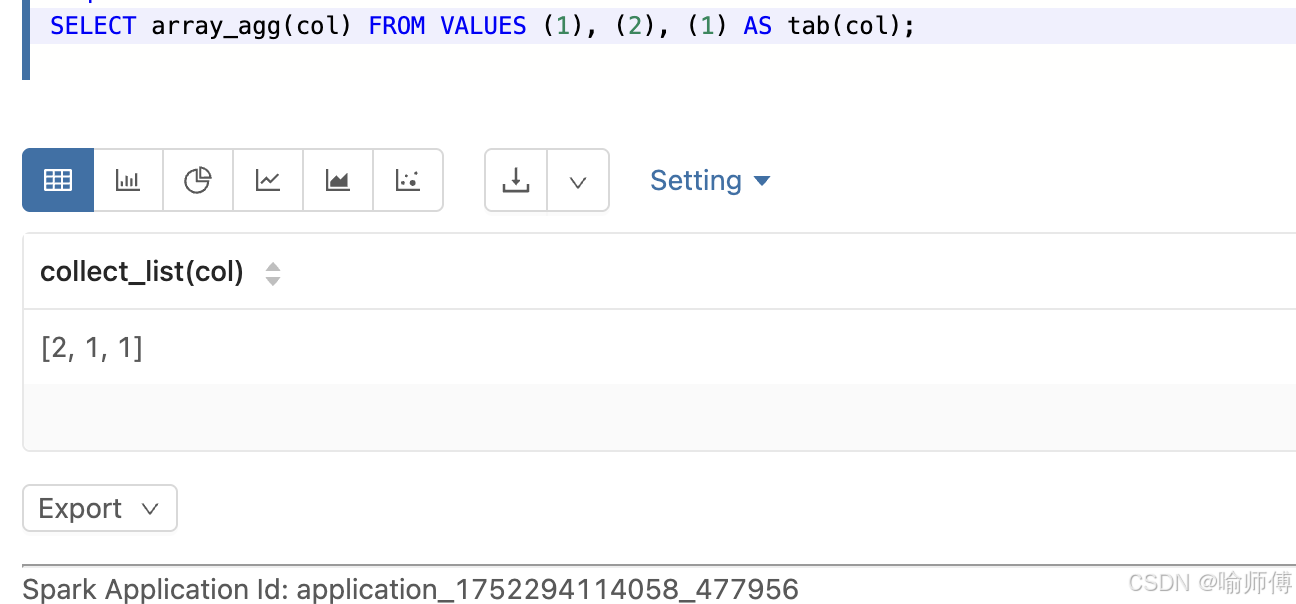
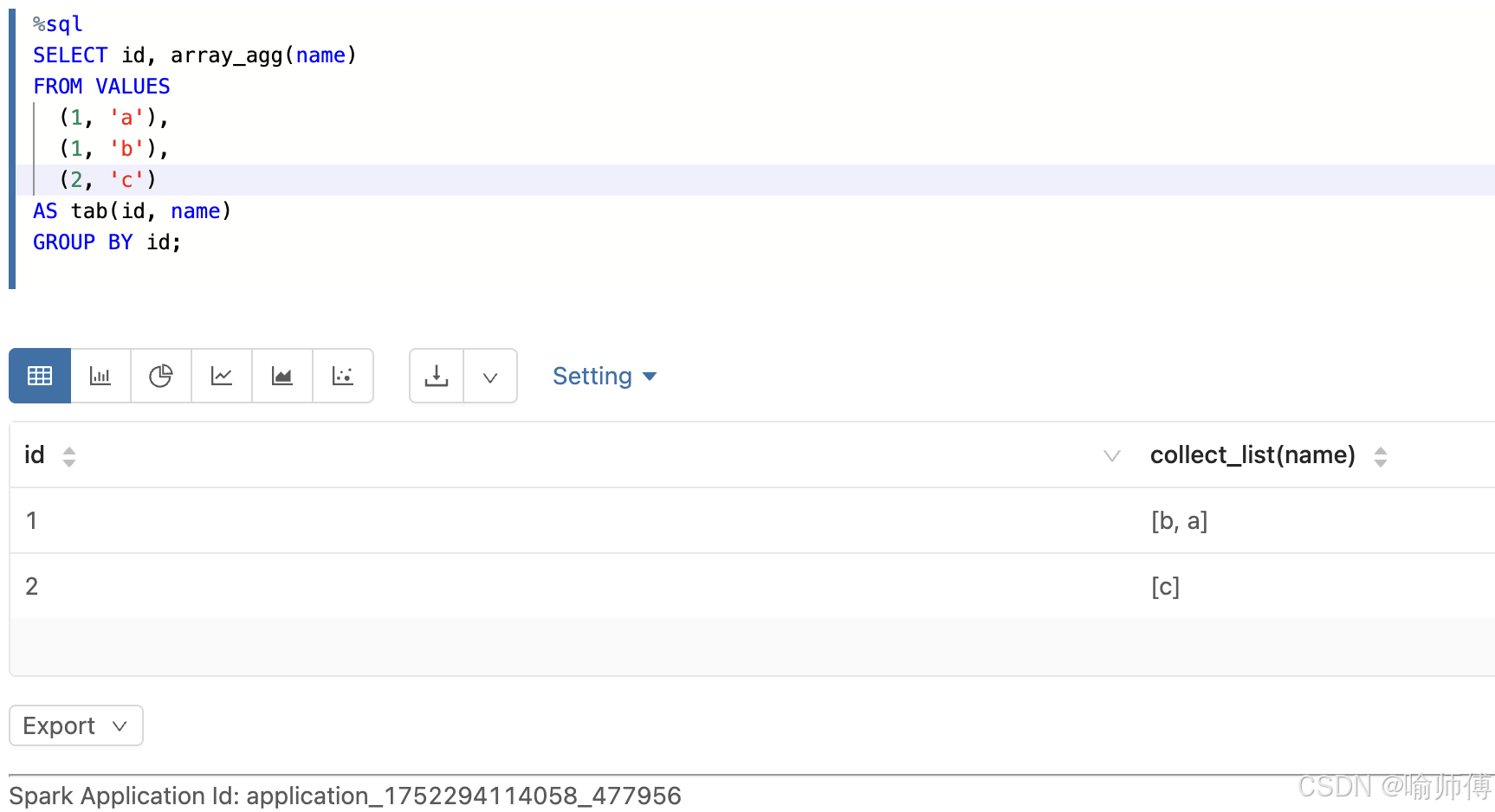
16.array_agg
https://spark.apache.org/docs/latest/api/sql/index.html#array_agg
把某一列的多个值收集起来,合并成一个数组(保留重复值),结果顺序不确定。

- 顺序依赖数据的物理顺序,shuffle 后顺序可能变化------ 每次运行结果可能不同(因为顺序不确定)。