IT社团人数的增长陷入迟滞,同时不同目标任务和不同经营模式的社团更是层出不穷。在面临内忧外患的情况下,本社团希望结合社团行业现状,分析同学和出勤的数据,挖据数据中的信息,通过对人数流失进行预测寻找到相应的对策,从而更好经营本社团。
任务分析
1、分析社团每日出勤班级与人数,明确预测分析目标。
2、了解所要用到的预测的方法。
3、熟悉社团预测的步骤和流程。
模块解析
( 一 ) 数据预处理
我们IT社在收集到的数据存在着数据不完整,数据不一致,数据异常的情况,如果用这种异常数据进行分析,那么会影响建模的执行效率,甚至能会造成分析结果出现偏差,所以我们对数据原始数据进行了预处理,通过合并数据进而实现数据清洗,检测与处理了重复值、缺失值、异常值从而提高了数据质量,为下步数据分析与可视化创造环境。
( 二 ) 数据分析与可视化
基于上一步清洗过的数据,我们对其进行二次处理,提取出有用字段分别对班级人员分布、每日出勤人数统计与人员出勤Top10进行了数据分析与可视化,一方面便于我们分析提取有用信息,另一方面也为我们下一步的构建模型打下坚实基础。
( 三 ) 基于scikit-learn构建模型
scikit-learn(以下简称sklearn)库整合了多种机器学习算法,可以帮助使用者在数据分析过程中快速建立模型,且模型接口统一,使用起来非常方便。同时, skleam拥有优秀的官方文档,该文档知识点详尽、内容丰富,是入门学习sklearn的较佳内容。 我们则使用其中的支持向量机对社团人员等级进行了评估预测
四、 项目代码
( 一 ) 数据预处理
本模块主要使用Pandas于os对原始数据进行数据清洗通过合并数据进而实现,堆叠合并主键合并和重叠合并进行数据清洗,检测与处理重复值、缺失值、异常值。清洗完毕后,在下个模块中进行数据分析与可视化。
对原始数据进行预处理
python
if os.path.exists('../File/output/汇总表.csv'):
os.remove('../File/output/汇总表.csv')
df=pd.DataFrame(data=None)
for root,dirs,files in os.walk(r"../File/import/"):
print(files)
for i in files:
data=pd.read_excel('../File/import/'+i,header=1,usecols=[1,2,5,6])
data.columns=['班级','姓名','班级2','姓名2']
data=data[['班级','姓名']].append(data[['班级2','姓名2']],ignore_index=True)
data=data[['班级','姓名']]
data['时间']=i
data['时间']=data['时间'].map(lambda x:str(x)[:-8])
df_all=df.append(data,ignore_index=True)
df_all.to_csv('../File/output/汇总表.csv',mode='a', header=False)
df1=pd.DataFrame(data=None)
for root,dirs,files in os.walk(r"../File/import/"):
for i in files:
data2=pd.read_excel('../File/import/'+i,header=1,usecols=[5,6])
data2.columns=['班级','姓名']
data2['时间']=i
data2['时间']=data2['时间'].map(lambda x:str(x)[:-8])
df_all2=df1.append(data2,ignore_index=True)
df_all2.to_csv('../File/output/汇总表.csv',mode='a', header=False)
#data2=pd.read_csv('../File/output/汇总表.csv',header=None,names=['序号','班级','姓名'])
#data=pd.concat([data,data2])
data=pd.read_csv('../File/output/汇总表.csv',header=None,names=['班级','姓名','时间'])提取时间关键词进行转换
python
date=data['时间'].astype(str).str.split('.')
list=[]
for i in date:
s=pd.Series(i)
dates='2023-'+s.str.cat(sep='-')
list.append(dates)
data['时间']=list
time=pd.to_datetime(data['时间'])
data['日期']=time
data对数据进行去重并重新分配顺序
python
data=data[['日期','班级','姓名']]
data.dropna(inplace=True)
data=data.reset_index(drop=True)
data.to_excel('../File/output/清洗完毕.xlsx')
data ( 二 ) 数据分析与可视化
( 二 ) 数据分析与可视化
1、 人员出勤Top10
本模块主要使用清洗完的数据,进去去重,对同学来的次数进行count统计,并对Top10进行可视化展示:
Pandas版wordcount
python
word=pd.DataFrame(data[['班级','姓名']])
count=word.groupby(['班级','姓名']).apply(len)
count.sort_values(ascending=False, inplace=True)
wordcount=count.reset_index(name="count")
wordcount.to_excel('../File/output/社团人员.xlsx')条形图:
python
from pyecharts import Bar
x = Top10['姓名']
y =Top10['count']
bar=Bar("出勤人员Top10","社團總體出勤人员Top10",title_color ="#2F4F4F")
title= '出勤次数'
bar.add(title,x,y,is_convert=True)
bar.render("../File/圖表/Top10条形图.html")
bar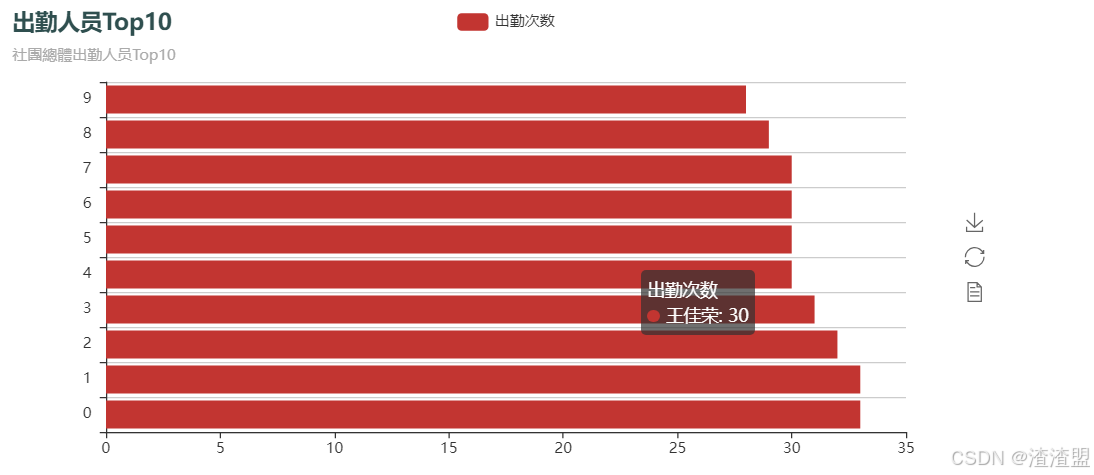 饼图:
饼图:
python
from pyecharts import Pie
attr = Top10['班级']+Top10['姓名']
v1 = Top10['count']
pie = Pie("出勤人员Top10", title_pos='center')
pie.add(
"",
attr,
v1,
radius=[40, 75],
label_text_color=None,
is_label_show=True,
is_more_utils=True,
legend_orient="vertical",
legend_pos="left",
center=["65%", "55%"]
)
pie.render(path="../File/圖表/Top10饼状图.html")
pie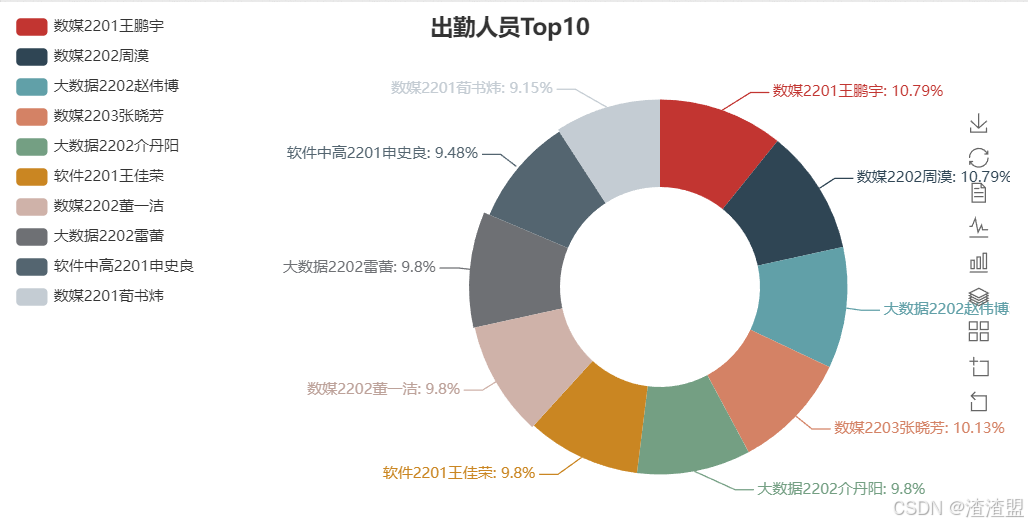
词云图:
python
from pyecharts import WordCloud
name_list = Top10['姓名']
value_list = Top10['count']
wordcloud = WordCloud(width=800, height=500)
wordcloud.add("",name_list,value_list,word_size_range=[20,100])
wordcloud.render(path="../File/圖表/Top10词云图.html")
wordcloud
2、 班级人员分布
本模块主要使用清洗完毕的数据,对其进去再次处理,提取出班级与姓名特征,并进行去重,排序去重。完毕后使用pyecharts进行折线图与饼图的绘制,最后基于班级人员分布对下步工作进行分析。
将提取的有用数据进行去重,清洗
python
data=pd.read_excel('../File/output/清洗完毕.xlsx')
data=data[['班级','姓名']]
word=pd.DataFrame(data[['班级','姓名']])
count=word.groupby(['班级','姓名']).apply(len)
count.sort_values(ascending=False, inplace=True)
wordcount=count.reset_index(name="count")
calss=wordcount[['班级','姓名']]
calss
根据count属性进行班级的排列
python
count=calss.groupby(['班级']).apply(len)
count.sort_values(ascending=False, inplace=True)
wordcount=count.reset_index(name="count")
wordcount人员分布可视化图表:
python
bar=Bar("班级人员分布","社團各班人员分布情況",title_color ="#c1392b")
bar.add("人數",wordcount['班级'],wordcount['count'],xaxis_label_textsize=8)
bar.render("../File/圖表/班级人员分布柱图.html")
bar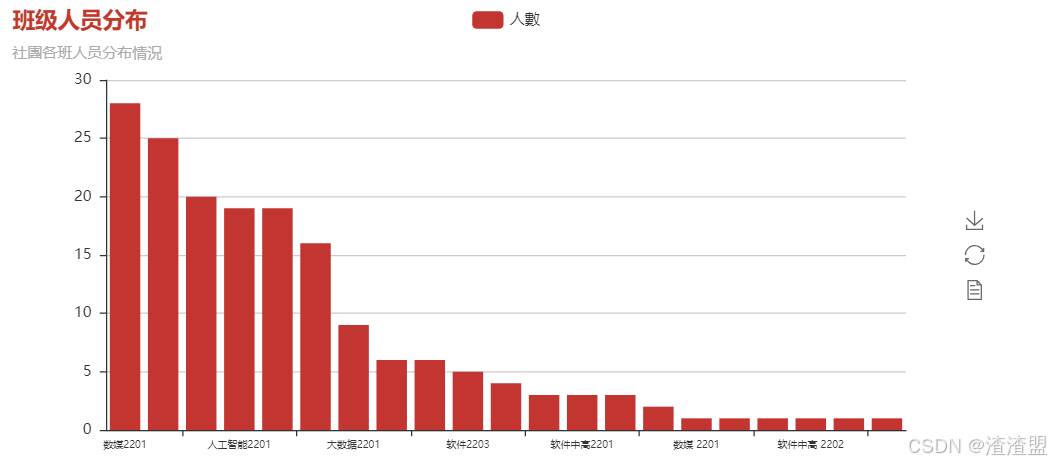
python
attr = wordcount['班级']
v1 = wordcount['count']
pie = Pie("班级人员分布", title_pos='center')
pie.add(
"",
attr,
v1,
radius=[40, 75],
label_text_color=None,
is_label_show=True,
is_more_utils=True,
legend_orient="vertical",
legend_pos="left",
center=["65%", "55%"]
)
pie.render(path="../File/圖表/班级人员分布饼图2.html")
pie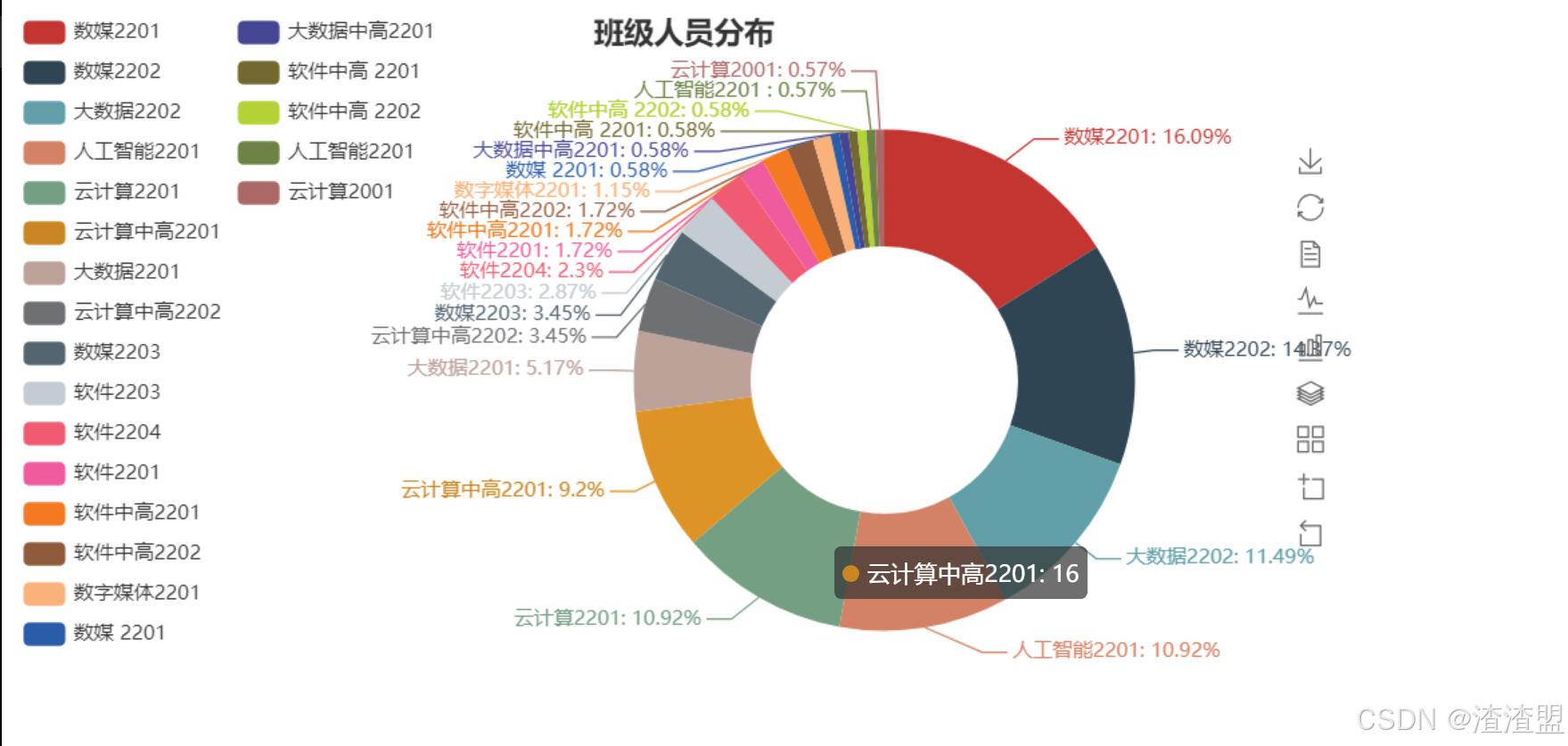
基于班级人员分布分析
从代码分析得出:
数媒2201、2202以及大数据2202、人工智能2201的同学对IT社有更大的兴趣占饼状图的百分之五十一
其次就是云计算2201和中高班的同学对IT社的兴趣仅次于上面各班占百分之二十
最后其余班级的同学对IT社的兴趣可能想简单的了解一下里面的内容占百分之三十
从这些数据上看得出来对于这些对IT社的感兴趣的同学,我们要把握住他们对网络的喜欢,让他们继续坚持下去他们对网络技术的爱好,同时带动那些想要简单了解网络技术的同学们一起努力学习。
3、 每日出勤人数统计
本模块主要使用清洗完毕的数据先提取出姓名和日期,在从日期中排序每个时间所到的人员数目,再使用pyecharts进行柱状和折线的绘制,最后基于每日出勤人数统计进行分析。
将数据进行去重,清洗
python
data=pd.read_excel('../File/output/清洗完毕.xlsx')
data=data[['日期','姓名']]
data['日期']=data['日期'].dt.date根据count数据重新排序
python
count=data.groupby(['日期']).apply(len)
count.sort_values(ascending=False, inplace=True)
date=count.reset_index(name="count")
date=date.sort_values(by='日期')
date统计出勤人数列出柱状图
python
from pyecharts import Bar
bar=Bar("出勤人數統計","社團每日出勤人员統計",title_color ="#FFA07A")
bar.add("人數",date['日期'],date['count'],xaxis_label_textsize=8)
bar.render("../File/圖表/出勤人数柱状图.html")
bar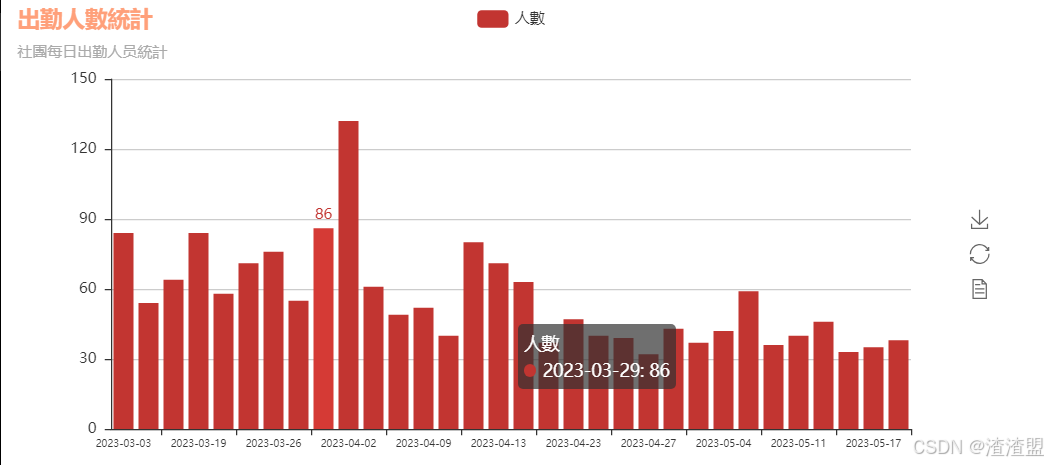 统计出勤人数列出折线图
统计出勤人数列出折线图
python
attr = date['日期']
v1 = date['count']
line = Line("社團每日出勤人數統計")
line.add("出勤人数", attr, v1, mark_point=["average"])
line.render('../File/圖表/出勤人数折线图.html')
line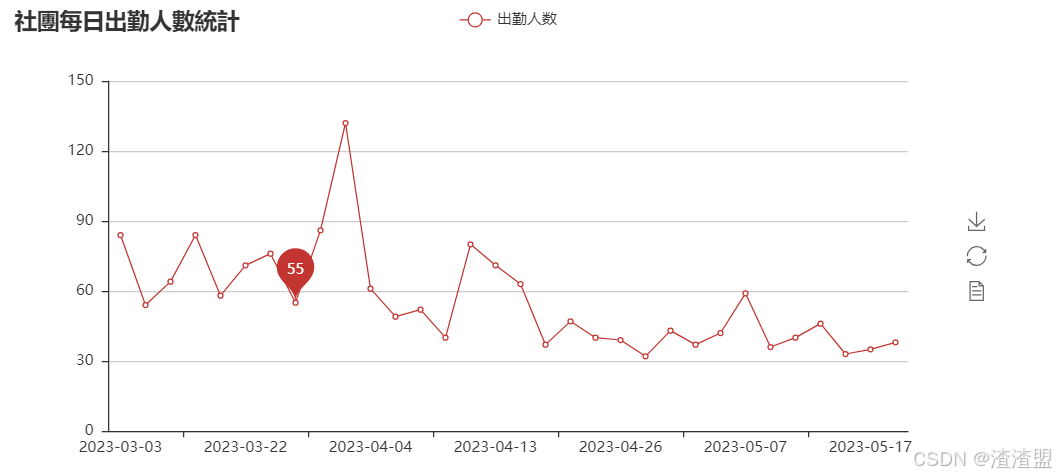
基于每日出勤人数统计的分析
从折线图中我们可以看出:
刚开始稳步提升,4月4号到达顶峰
5月17号人最少、从4月13后出勤人数一直在下滑、明显的下降趋势
5月以后,社团每日出勤趋于稳定
( 三 ) 基于scikit-learn构建模型
1、 社员等级评估
使用支持向量机算法对社员等级进行评估
python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
import warnings
warnings.filterwarnings('ignore')提取可用的数据
python
data=pd.read_excel('../File/output/社团人员.xlsx')
data=data[['姓名','count']]
data对数据进行标准化并根据count属性添加类别标签
python
data = pd.get_dummies(data)
data['类别']=pd.cut(data['count'],[0,5,10,20,50],labels=['D','C','B','A'])
data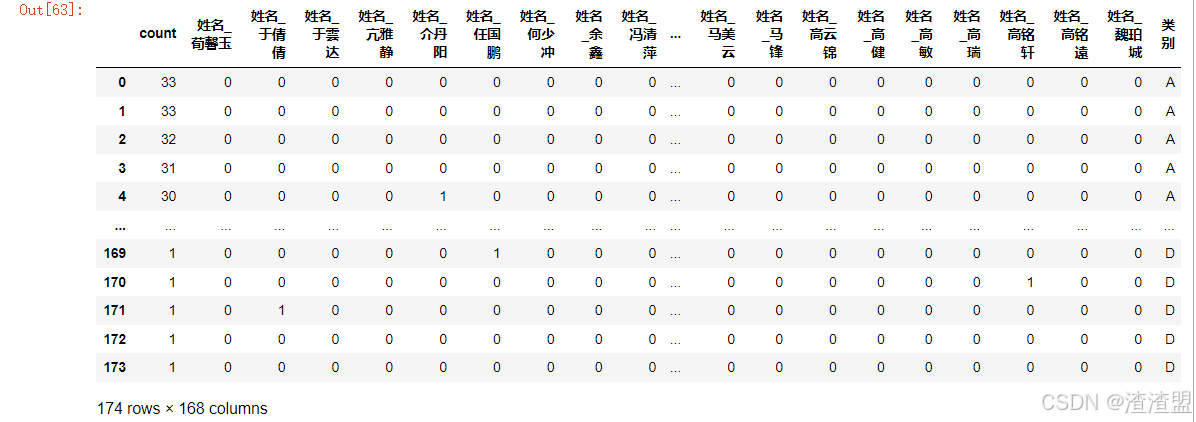 将添加的类别使用支持向量机进行评估
将添加的类别使用支持向量机进行评估
python
ry_data=data.iloc[:,:-1]
ry_target=data.iloc[:,-1]
ry_data_train,ry_data_test,ry_target_train,ry_target_test= \
train_test_split(ry_data,ry_target,test_size=0.2,random_state=15)
stdScale=StandardScaler().fit(ry_data_train)
ry_trainScaler=stdScale.transform(ry_data_train)
ry_testScaler=stdScale.transform(ry_data_test)
svm=SVC().fit(ry_trainScaler,ry_target_train)
ry_pred=svm.predict(ry_testScaler)
print('评估的前20个结果为:\n',ry_pred[:20]) 求出评估的准确率
求出评估的准确率
python
true=np.sum(ry_pred==ry_target_test)
print('评估结果的准确率为:',true/ry_target_test.shape[0])
from sklearn.metrics import accuracy_score
soure=accuracy_score(ry_pred,ry_target_test)
print('评估结果的准确率为:',soure) 用向量机评估出分类的报告
用向量机评估出分类的报告
python
from sklearn.metrics import classification_report
print('使用向量机评估社团人员类别的分类报告为:','\n',classification_report(ry_target_test,ry_pred))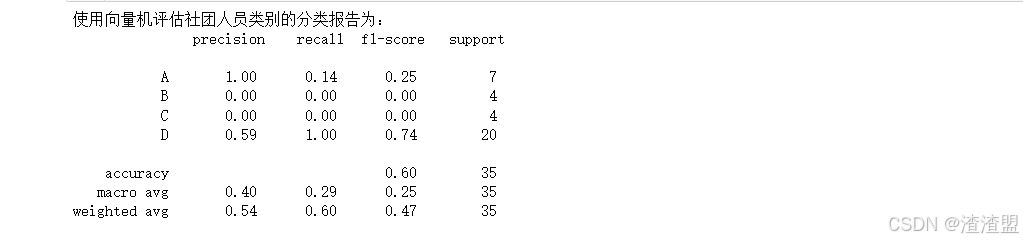 2、 人员流失预测
2、 人员流失预测
使用决策树预测人员流失状态,发现客户流失规律
python
import pandas as pd
from sklearn.metrics import confusion_matrix
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.model_selection import train_test_split定义评价函数
python
def test_pre(pred):
# 混淆矩阵
hx = confusion_matrix(y_te, pred, labels=['非流失', '准流失'])
print('混淆矩阵:\n', hx)
# 精确率
P = hx[1, 1] / (hx[0, 1] + hx[1, 1])
print('精确率:', round(P, 3))
# 召回率
R = hx[1, 1] / (hx[1, 0] + hx[1, 1])
print('召回率:', round(R, 3))
# F1值
F1 = 2 * P * R / (P + R)
print('F1值:', round(F1, 3))构建社员流失特征
python
info_user=pd.read_excel('../File/output/流失分析.xlsx')
data=info_user.iloc[:,2:]
data.drop(data[data['满意程度'].isnull()].index,inplace=True)
data 构建决策树模型
构建决策树模型
python
x_tr,x_te,y_tr,y_te=train_test_split(data.iloc[:,:-1],data['退社'],test_size=0.2,random_state=1314)
dtc=DTC(random_state=1314)
dtc.fit(x_tr,y_tr)
per=dtc.predict(x_te)
test_pre(per)