3.3.1 创建与访问
什么是 DataFrame ?
DataFrame 是 Pandas 中的核心数据结构之一,多行多列表格数据,类似于 Excel 表格 或 SQL 查询结果 。
它是一个 二维表格结构,具有行索引(index)和列标签(columns)。
python
Python
df = pd.DataFrame({
"name": ["Alice", "Bob"],
"score": [90, 80]
})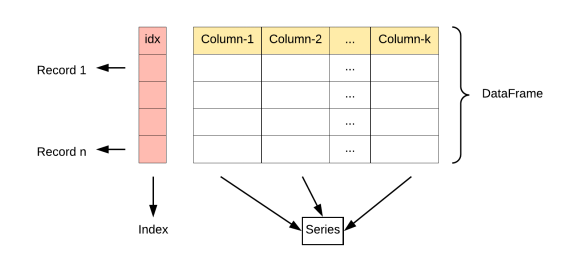
DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。它可以被看做由Series组成的字典(共同用一个索引)。提供了各种功能来进行数据访问、筛选、分割、合并、重塑、聚合以及转换等操作,广泛用于数据分析、清洗、转换、可视化等任务。
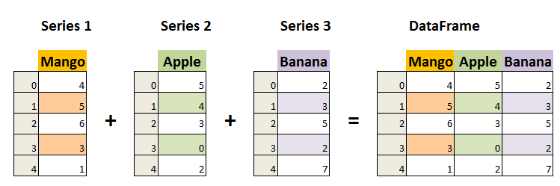
DataFrame 的创建
python
Python
# 通过series来创建
import pandas as pd
import numpy as np
np.random.seed(42)
s1 = pd.Series(np.random.randint(0,10,6))
np.random.seed(41)
s2 = pd.Series(np.random.randint(0,20,6))
df = pd.DataFrame({"s1":s1,"s2":s2})直接通过字典创建DataFrame
python
Python
import pandas as pd
df = pd.DataFrame({ "name": ["Alice", "Bob"], "score": [90, 80]})
print(df)
df = pd.DataFrame({"id": [101, 102, 103],
"name": ["张三", "李四", "王五"], "age": [20, 30, 40]})
print(df)
# id name age
# 0 101 张三 20
# 1 102 李四 30
# 2 103 王五 40通过字典创建时指定列的顺序和行索引
python
Bash
df = pd.DataFrame(
data={"age": [20, 30, 40],
"name": ["张三", "李四", "王五"]},
columns=["name", "age"], index=[101, 102, 103]
)
print(df)
# name age
# 101 张三 20
# 102 李四 30
# 103 王五 40获取 DataFrame 数据
|---------------------|-------------------------------------|--------------------------------------------------|------------------|---------------------------|
| 方法分类 | 语法示例 | 描述 | 返回值类型 | 是否支持切片 / 条件索引 |
| 列选择 | df'col' | 选择单列(返回Series) | Series | ❌ |
| | df\['col1', 'col2'] | 选择多列(返回DataFrame) | DataFrame | |
| 行选择 | df.locrow_label | 通过行标签选择单行(返回Series) | Series | ✅(标签切片) |
| | df.locstart:end | 通过标签切片选择多行(闭区间) | DataFrame | |
| | df.ilocrow_index | 通过行位置选择单行(从0开始) | Series | ✅(位置切片) |
| | df.ilocstart:end | 通过位置切片选择多行(左闭右开) | DataFrame | |
| 行列组合选择 | df.locrow_labels, col_labels | 通过标签选择行和列(如df.loc'a':'b', \['col1','col2']) | Series/DataFrame | ✅ |
| | df.ilocrow_idx, col_idx | 通过位置选择行和列(如df.iloc0:2, \[1,3]) | Series/DataFrame | |
| 条件筛选 | dfdf\['col' > 3] | 通过布尔条件筛选行 | DataFrame | ✅ |
| | df.query("col1 > 3 & col2 < 10") | 使用表达式筛选(需字符串表达式) | DataFrame | |
| 快速访问 | df.atrow_label, 'col' | 快速访问单个值(标签索引,高效) | 标量值 | ❌ |
| | df.iatrow_idx, col_idx | 快速访问单个值(位置索引,高效) | 标量值 | |
| 头部 / 尾部 | df.head(n) | 返回前n行(默认5) | DataFrame | ❌ |
| | df.tail(n) | 返回后n行(默认5) | DataFrame | |
| 样本抽样 | df.sample(n=3) | 随机抽取n行 | DataFrame | |
| 索引重置 | df.reset_index() | 重置索引(原索引变为列) | DataFrame | |
| 设置索引 | df.set_index('col') | 指定某列作为新索引 | DataFrame | |
- loc ** vs ****iloc**
- loc:基于**标签**(index/column names),切片为**闭区间**(如df.loc'a':'c'包含'c')。
- iloc:基于**整数位置**(从0开始),切片为**左闭右开**(如df.iloc0:2不包含索引2)。
- 布尔条件筛选
- 支持组合条件(需用&、|,并用括号分隔条件):
python
Python
df[(df['col1'] > 3) & (df['col2'] == 'A')]- at **/****iat**** vs ****loc****/****iloc**
- at/iat:仅用于**访问单个值**,速度更快。
- loc/iloc:支持多行/列选择,功能更灵活。
获取一列数据
python
Python
# 访问数据
print(df['name']) #访问某列数据
print(df.score)
# df["col"] / df.col
df["name"] # 返回 Series
df.name
df[["name"]] # 返回 DataFrame获取多列数据
python
Python
df[["date", "temp_max", "temp_min"]] # 获取多列数据
print(df[['name','score']]) # 访问多列数据获取行数据
loc **:**通过行标签获取数据
python
Python
df.loc[1] # 获取行标签为1的数据
df.loc[[1, 10, 100]] # 获取行标签分别为1、10、100的数据iloc **:**通过行位置获取数据
python
Python
df.iloc[0] # 获取行位置为0的数据
df.iloc[-1] # 获取行位置为最后一位的数据获取指定单元格
python
Python
df.loc[101, "name"] # 标签访问
df.iloc[0, 1] # 位置访问
df.loc[1, "precipitation"] # 获取行标签为1,列标签为precipitation的数据
df.loc[:, "precipitation"] # 获取所有行,列标签为precipitation的数据
df.iloc[:, [3, 5, -1]] # 获取所有行,列位置为3,5,最后一位的数据
df.iloc[:10, 2:6] # 获取前10行,列位置为2、3、4、5的数据
df.loc[:10, ["date", "precipitation", "temp_max", "temp_min"]] # 通过行列标签获取数据查看部分数据
通过head()、tail()获取前n行或后n行
python
Python
print(df.head())
print(df.tail(10))使用布尔索引筛选数据
python
Bash
# 条件筛选
df['score']>70
print(df[df.score>70])
print(df[(df['score']>70) & (df['age']<20)])
# 随机抽样
df.sample(2)常用属性
|--------------|-----------------|
| 属性 | 说明 |
| index | DataFrame的行索引 |
| columns | DataFrame的列标签 |
| values | DataFrame的值 |
| ndim | DataFrame的维度 |
| shape | DataFrame的形状 |
| size | DataFrame的元素个数 |
| dtypes | DataFrame的元素类型 |
| T | 行列转置 |
| loc\[\] | 显式索引,按行列标签索引或切片 |
| iloc\[\] | 隐式索引,按行列位置索引或切片 |
| at\[\] | 使用行列标签访问单个元素 |
| iat\[\] | 使用行列位置访问单个元素 |
python
Python
import pandas as pd
df = pd.DataFrame(data={"id": [101, 102, 103], "name": ["张三", "李四", "王五"], "age": [20, 30, 40]},index=["aa", "bb", "cc"])
# index DataFrame的行索引
print(df.index)
# columns DataFrame的列标签
print(df.columns)
# values DataFrame的值
print(df.values)
# ndim DataFrame的维度
print(df.ndim)
# shape DataFrame的形状
print(df.shape)
# size DataFrame的元素个数
print(df.size)
# dtypes DataFrame的元素类型
print(df.dtypes)
# T 行列转置
print(df.T)
# loc[] 显式索引,按行列标签索引或切片 逗号前是行切片规则,后是列切片规则
print(df.loc["aa":"cc"])
print(df.loc[:,["id","name"]])
# iloc[] 隐式索引,按行列位置索引或切片
print(df.iloc[0:1])
print(df.iloc[0:3,2])
print("----------")
# at[] 使用行列标签访问单个元素
print(df.at["aa","name"])
# iat[] 使用行列位置访问单个元素
print(df.iat[0,1])3.3.2 常用方法与统计
|-----------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 方法 | 说明 |
| head() | 查看前n行数据,默认5行 |
| tail() | 查看后n行数据,默认5行 |
| isin() | 元素是否包含在参数集合中 |
| isna() | 元素是否为缺失值 |
| sum() | 求和 |
| mean() | 平均值 |
| min() | 最小值 |
| max() | 最大值 |
| var() | 方差 |
| std() | 标准差 |
| median() | 中位数 |
| mode() | 众数 |
| quantile() | 指定位置的分位数,如quantile(0.5) |
| describe() | 常见统计信息 |
| info() | 基本信息 |
| value_counts() | 每个元素的个数 |
| count() | 非空元素的个数 |
| drop_duplicates() | 去重 |
| sample() | 随机采样 |
| replace() | 用指定值代替原有值 |
| equals() | 判断两个DataFrame是否相同 |
| cummax() | 累计最大值 |
| cummin() | 累计最小值 |
| cumsum() | 累计和 |
| cumprod() | 累计积 |
| diff() | 一阶差分,对序列中的元素进行差分运算,也就是用当前元素减去前一个元素得到差值,默认情况下,它会计算一阶差分,即相邻元素之间的差值。参数: periods:整数,默认为 1。表示要向前或向后移动的周期数,用于计算差值。正数表示向前移动,负数表示向后移动。 axis:指定计算的轴方向。0 或 'index' 表示按列计算,1 或 'columns' 表示按行计算,默认值为 0。 |
| sort_index() | 按行索引排序 |
| sort_values() | 按某列的值排序,可传入列表来按多列排序,并通过ascending参数设置升序或降序 |
| nlargest() | 返回某列最大的n条数据 |
| nsmallest() | 返回某列最小的n条数据 |
python
Bash
import pandas as pd
df = pd.DataFrame(data={"id": [101, 102, 103,104,105,106,101], "name": ["张三", "李四", "王五","赵六","冯七","周八","张三"], "age": [10, 20, 30, 40, None, 60,10]},index=["aa", "bb", "cc", "dd", "ee", "ff","aa"])
# head() 查看前n行数据,默认5行
print(df.head())
# tail() 查看后n行数据,默认5行
print(df.tail())
# isin() 元素是否包含在参数集合中
print(df.isin([103,106]))
# isna() 元素是否为缺失值
print(df.isna())
# sum() 求和
print(df["age"].sum())
# mean() 平均值
print(df["age"].mean())
# min() 最小值
print(df["age"].min())
# max() 最大值
print(df["age"].max())
# var() 方差
print(df["age"].var())
# std() 标准差
print(df["age"].std())
# median() 中位数
print(df["age"].median())
# mode() 众数
print(df["age"].mode())
# quantile() 指定位置的分位数,如quantile(0.5)
print(df["age"].quantile(0.5))
# describe() 常见统计信息
print(df.describe())
# info() 基本信息
print(df.info())
# value_counts() 每个元素的个数
print(df.value_counts())
# count() 非空元素的个数
print(df.count())
# drop_duplicates() 去重 duplicated()判断是否为重复行
print(df.duplicated(subset="age"))
# sample() 随机采样
print(df.sample())
# replace() 用指定值代替原有值
print("----------------")
print(df.replace(20,"haha"))
# cummax() 累计最大值
df3 = pd.DataFrame({'A': [2, 5, 3, 7, 4],'B': [1, 6, 2, 8, 3]})
# 按列 等价于axis=0 默认
print(df3.cummax(axis="index"))
# 按行 等价于axis=1
print(df3.cummax(axis="columns"))
# cummin() 累计最小值
print(df3.cummin())
# cumsum() 累计和
print(df3.cumsum())
# cumprod() 累计积
print(df3.cumprod())
# diff() 一阶差分
print(df3.diff())
# sort_index() 按行索引排序
print(df.sort_index())
# sort_values() 按某列的值排序,可传入列表来按多列排序,并通过ascending参数设置升序或降序
print(df.sort_values(by="age"))
# nlargest() 返回某列最大的n条数据
print(df.nlargest(n=2,columns="age"))
# nsmallest() 返回某列最小的n条数据
print(df.nsmallest(n=1,columns="age"))在Pandas的 DataFrame 方法里,axis 是一个非常重要的参数,它用于指定操作的方向。
axis 参数可以取两个主要的值,即 0 或 'index',以及 1 或 'columns' ,其含义如下:
- axis=0 或 axis='index':表示操作沿着行的方向进行,也就是对每一列的数据进行处理。例如,当计算每列的均值时,就是对每列中的所有行数据进行计算。
- axis=1 或 axis='columns':表示操作沿着列的方向进行,也就是对每行的数据进行处理。例如,当计算每行的总和时,就是对每行中的所有列数据进行计算。
3.3.3 运算
标量运算
标量与每个元素进行计算。
python
Python
df = pd.DataFrame(data={"age": [20, 30, 40, 10], "name": ["张三", "李四", "王五", "赵六"]},
columns=["name", "age"],
index=[101, 104, 103, 102],
)
print(df * 2)
# name age
# 101 张三张三 40
# 104 李四李四 60
# 103 王五王五 80
# 102 赵六赵六 20
df1 = pd.DataFrame(
data={"age": [10, 20, 30, 40], "name": ["张三", "李四", "王五", "赵六"]},
columns=["name", "age"],
index=[101, 102, 103, 104],
)
df2 = pd.DataFrame(
data={"age": [10, 20, 30, 40], "name": ["张三", "李四", "王五", "田七"]},
columns=["name", "age"],
index=[102, 103, 104, 105],
)
print(df1 + df2)
# name age
# 101 NaN NaN
# 102 李四张三 30.0
# 103 王五李四 50.0
# 104 赵六王五 70.0
# 105 NaN NaN3.4 数据的导入与导出
导出数据
|--------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------|
| 方法 | 说明 |
| to_csv() | 将数据保存为csv格式文件,数据之间以逗号分隔,可通过sep参数设置使用其他分隔符,可通过index参数设置是否保存行标签,可通过header参数设置是否保存列标签。 |
| to_pickle() | 如要保存的对象是计算的中间结果,或者保存的对象以后会在Python中复用,可把对象保存为.pickle文件。如果保存成pickle文件,只能在python中使用。文件的扩展名可以是.p、.pkl、.pickle。 |
| to_excel() | 保存为Excel文件,需安装openpyxl包。 |
| to_clipboard() | 保存到剪切板。 |
| to_dict() | 保存为字典。 |
| to_hdf() | 保存为HDF格式,需安装tables包。 |
| to_html() | 保存为HTML格式,需安装lxml、html5lib、beautifulsoup4包。 |
| to_json() | 保存为JSON格式。 |
| to_feather() | feather是一种文件格式,用于存储二进制对象。feather对象也可以加载到R语言中使用。feather格式的主要优点是在Python和R语言之间的读写速度要比csv文件快。feather数据格式通常只用中间数据格式,用于Python和R之间传递数据,一般不用做保存最终数据。需安装pyarrow包。 |
| to_sql() | 保存到数据库。 |
python
Python
import os
import pandas as pd
os.makedirs("data", exist_ok=True)
df = pd.DataFrame({"age": [20, 30, 40, 10], "name": ["张三", "李四", "王五", "赵六"], "id": [101, 102, 103, 104]})
df.set_index("id", inplace=True)
df.to_csv("data/df.csv")
df.to_csv("data/df.tsv", sep="\t") # 设置分隔符为 \t
df.to_csv("data/df_noindex.csv", index=False) # index=False 不保存行索引
df.to_pickle("data/df.pkl")
df.to_excel("data/df.xlsx")
df.to_clipboard()
df_dict = df.to_dict()
df.to_hdf("data/df.h5", key="df")
df.to_html("data/df.html")
df.to_json("data/df.json")
df.to_feather("data/df.feather")导入数据
|----------------------|-----------------------------------------------|
| 方法 | 说明 |
| read_csv() | 加载csv格式的数据。可通过sep参数指定分隔符,可通过index_col参数指定行索引。 |
| read_pickle() | 加载pickle格式的数据。 |
| read_excel() | 加载Excel格式的数据。 |
| read_clipboard() | 加载剪切板中的数据。 |
| read_hdf() | 加载HDF格式的数据。 |
| read_html() | 加载HTML格式的数据。 |
| read_json() | 加载JSON格式的数据。 |
| read_feather() | 加载feather格式的数据。 |
| read_sql() | 加载数据库中的数据。 |
python
Python
df_csv = pd.read_csv("data/df.csv", index_col="id") # 指定行索引
df_tsv = pd.read_csv("data/df.tsv", sep="\t") # 指定分隔符
df_pkl = pd.read_pickle("data/df.pkl")
df_excel = pd.read_excel("data/df.xlsx", index_col="id")
df_clipboard = pd.read_clipboard(index_col="id")
df_from_dict = pd.DataFrame(df_dict)
df_hdf = pd.read_hdf("data/df.h5", key="df")
df_html = pd.read_html("data/df.html", index_col=0)[0]
df_json = pd.read_json("data/df.json")
df_feather = pd.read_feather("data/df.feather")
print(df_csv)
print(df_tsv)
print(df_pkl)
print(df_excel)
print(df_clipboard)
print(df_from_dict)
print(df_hdf)
print(df_html)
print(df_json)
print(df_feather)3.5 数据清洗与预处理
|---------------------|---------------------|----------------------------------------------------|
| 章节 | 核心内容 | 关键知识点 |
| 1. 缺失值处理 | 检测、删除和填充缺失值的方法 | isna(), dropna(), fillna(), 前向/后向填充, 均值/中位数填充 |
| 2. 重复数据处理 | 识别和删除重复行 | duplicated(), drop_duplicates(), 按列去重, 保留首次/最后一次出现 |
| 3. 数据类型转换 | 强制类型转换、日期/分类数据处理 | astype(), to_datetime(), 分类数据优化, 数值格式化 |
| 4. 数据重塑与变形 | 行列转置、宽表长表转换、分列操作 | T转置, melt(), pivot(), str.split()分列 |
| 5. 文本数据处理 | 字符串清洗、正则提取、大小写转换 | str.lower(), str.replace(), str.extract(), 空格处理 |
| 6. 数据分箱与离散化 | 数值分箱(等宽/等频) | pd.cut(), pd.qcut(), 离散化应用场景 |
| 7. 其他常用转换 | 重命名列、索引操作、函数应用、内存优化 | rename(), set_index(), apply(), 类型优化减少内存占用 |
- 缺失值处理
|---------------------|------------------------------|------------------------|
| 方法 / 操作 | 语法示例 | 描述 |
| 检测缺失值 | df.isna() 或 df.isnull() | 返回布尔矩阵,标记缺失值(NaN或None) |
| 统计缺失值 | df.isna().sum() | 每列缺失值数量统计 |
| 删除缺失值 | df.dropna() | 删除包含缺失值的行(默认) |
| | df.dropna(axis=1) | 删除包含缺失值的列 |
| | df.dropna(subset='col1') | 仅删除指定列的缺失值行 |
| 填充缺失值 | df.fillna(value) | 用固定值填充(如df.fillna(0) |
| | df.fillna(method='ffill') | 用前一个非缺失值填充(向前填充) |
| | df.fillna(method='bfill') | 用后一个非缺失值填充(向后填充) |
| | df.fillna(df.mean()) | 用列均值填充 |
pandas中的缺失值
- NaN (Not a Number) 是缺失值的标志
- 方法: isna(), notna()
pandas使用浮点值NaN(Not a Number)表示缺失数据,使用NA(Not Available)表示缺失值。可以通过isnull()、isna()或notnull()、notna()方法判断某个值是否为缺失值。
Nan通常表示一个无效的或未定义的数字值,是浮点数的一种特殊取值,用于表示那些不能表示为正常数字的情况,如 0/0、∞-∞等数学运算的结果。nan与任何值(包括它自身)进行比较的结果都为False。例如在 Python 中,nan == nan返回False。
NA一般用于表示数据不可用或缺失的情况,它的含义更侧重于数据在某种上下文中是缺失或不存在的,不一定特指数字类型的缺失。
na和nan都用于表示缺失值,但nan更强调是数值计算中的特殊值,而na更强调数据的可用性或存在性。
python
Plain Text
s = pd.Series([np.nan, None, pd.NA])
print(s)
# 0 NaN
# 1 None
# 2 <NA>
# dtype: object
print(s.isnull())
# 0 True
# 1 True
# 2 True
# dtype: bool加载数据中包含缺失值
python
Python
df = pd.read_csv("data/weather_withna.csv")
print(df.tail(5))
# date precipitation temp_max temp_min wind weather
# 1456 2015-12-27 NaN NaN NaN NaN NaN
# 1457 2015-12-28 NaN NaN NaN NaN NaN
# 1458 2015-12-29 NaN NaN NaN NaN NaN
# 1459 2015-12-30 NaN NaN NaN NaN NaN
# 1460 2015-12-31 20.6 12.2 5.0 3.8 rain可以通过keep_default_na参数设置是否将空白值设置为缺失值。
python
Python
df = pd.read_csv("data/weather_withna.csv", keep_default_na=False)
print(df.tail(5))
# date precipitation temp_max temp_min wind weather
# 1456 2015-12-27
# 1457 2015-12-28
# 1458 2015-12-29
# 1459 2015-12-30
# 1460 2015-12-31 20.6 12.2 5.0 3.8 rain可通过na_values参数将指定值设置为缺失值。
python
Python
df = pd.read_csv("data/weather_withna.csv", na_values=["2015-12-31"])
print(df.tail(5))
# date precipitation temp_max temp_min wind weather
# 1456 2015-12-27 NaN NaN NaN NaN NaN
# 1457 2015-12-28 NaN NaN NaN NaN NaN
# 1458 2015-12-29 NaN NaN NaN NaN NaN
# 1459 2015-12-30 NaN NaN NaN NaN NaN
# 1460 NaN 20.6 12.2 5.0 3.8 rain查看缺失值
通过isnull()查看缺失值数量
python
Python
df = pd.read_csv("data/weather_withna.csv")
print(df.isnull().sum())
# date 0
# precipitation 303
# temp_max 303
# temp_min 303
# wind 303
# weather 303
# dtype: int64剔除缺失值
通过dropna()方法来剔除缺失值。
Series剔除缺失值
python
Python
s = pd.Series([1, pd.NA, None])
print(s)
# 0 1
# 1 <NA>
# 2 None
# dtype: object
print(s.dropna())
# 0 1
# dtype: objectDataFrame剔除缺失值
无法从DataFrame中单独剔除一个值,只能剔除缺失值所在的整行或整列。默认情况下,dropna()会剔除任何包含缺失值的整行数据。
python
Python
df = pd.DataFrame([[1, pd.NA, 2], [2, 3, 5], [pd.NA, 4, 6]])
print(df)
# 0 1 2
# 0 1 <NA> 2
# 1 2 3 5
# 2 <NA> 4 6
print(df.dropna())
# 0 1 2
# 1 2 3 5可以设置按不同的坐标轴剔除缺失值,比如axis=1(或 axis='columns')会剔除任何包含缺失值的整列数据。
python
df = pd.DataFrame([[1, pd.NA, 2], [2, 3, 5], [pd.NA, 4, 6]])
print(df)
# 0 1 2
# 0 1 <NA> 2
# 1 2 3 5
# 2 <NA> 4 6
print(df.dropna(axis=1))
# 2
# 0 2
# 1 5
# 2 6有时只需要剔除全部是缺失值的行或列,或者绝大多数是缺失值的行或列。这些需求可以通过设置how或thresh参数来满足,它们可以设置剔除行或列缺失值的数量阈值。
python
df = pd.DataFrame([[1, pd.NA, 2], [pd.NA, pd.NA, 5], [pd.NA, pd.NA, pd.NA]])
print(df)
# 0 1 2
# 0 1 <NA> 2
# 1 <NA> <NA> 5
# 2 <NA> <NA> <NA>
print(df.dropna(how="all")) # 如果所有值都是缺失值,则删除这一行
# 0 1 2
# 0 1 <NA> 2
# 1 <NA> <NA> 5
print(df.dropna(thresh=2)) # 如果至少有2个值不是缺失值,则保留这一行
# 0 1 2
# 0 1 <NA> 2可以通过设置subset参数来设置某一列有缺失值则进行剔除。
python
df = pd.DataFrame([[1, pd.NA, 2], [pd.NA, pd.NA, 5], [pd.NA, pd.NA, pd.NA]])
print(df)
# 0 1 2
# 0 1 <NA> 2
# 1 <NA> <NA> 5
# 2 <NA> <NA> <NA>
print(df.dropna(subset=[0])) # 如果0列有缺失值,则删除这一行
# 0 1 2
# 0 1 <NA> 2填充缺失值
- 使用固定值填充
通过fillna()方法,传入值或字典进行填充。
python
df = pd.read_csv("data/weather_withna.csv")
print(df.fillna(0).tail()) # 使用固定值填充
#
print(df.fillna({"temp_max": 60, "temp_min": -60}).tail()) # 使用字典来填充
# date precipitation temp_max temp_min wind weather
# 1456 2015-12-27 NaN 60.0 -60.0 NaN NaN
# 1457 2015-12-28 NaN 60.0 -60.0 NaN NaN
# 1458 2015-12-29 NaN 60.0 -60.0 NaN NaN
# 1459 2015-12-30 NaN 60.0 -60.0 NaN NaN
# 1460 2015-12-31 20.6 12.2 5.0 3.8 rain- 使用统计值填充
通过fillna()方法,传入统计后的值进行填充。
python
print(df.fillna(df[["precipitation", "temp_max", "temp_min", "wind"]].mean()).tail()) # 使用平均值填充
# date precipitation temp_max temp_min wind weather
# 1456 2015-12-27 3.052332 15.851468 7.877202 3.242055 NaN
# 1457 2015-12-28 3.052332 15.851468 7.877202 3.242055 NaN
# 1458 2015-12-29 3.052332 15.851468 7.877202 3.242055 NaN
# 1459 2015-12-30 3.052332 15.851468 7.877202 3.242055 NaN
# 1460 2015-12-31 20.600000 12.200000 5.000000 3.800000 rain- 使用前后的有效值填充
通过ffill()或bfill()方法使用前面或后面的有效值填充。
python
print(df.ffill().tail()) # 使用前面的有效值填充
# date precipitation temp_max temp_min wind weather
# 1456 2015-12-27 0.0 11.1 4.4 4.8 sun
# 1457 2015-12-28 0.0 11.1 4.4 4.8 sun
# 1458 2015-12-29 0.0 11.1 4.4 4.8 sun
# 1459 2015-12-30 0.0 11.1 4.4 4.8 sun
# 1460 2015-12-31 20.6 12.2 5.0 3.8 rain
print(df.bfill().tail()) # 使用后面的有效值填充
# date precipitation temp_max temp_min wind weather
# 1456 2015-12-27 20.6 12.2 5.0 3.8 rain
# 1457 2015-12-28 20.6 12.2 5.0 3.8 rain
# 1458 2015-12-29 20.6 12.2 5.0 3.8 rain
# 1459 2015-12-30 20.6 12.2 5.0 3.8 rain
# 1460 2015-12-31 20.6 12.2 5.0 3.8 rain通过线性插值填充
通过interpolate()方法进行线性插值填充。线性插值操作,就是用于在已知数据点之间估算未知数据点的值。interpolate 方法支持多种插值方法,可通过 method 参数指定,常见的方法有:
- 'linear':线性插值,基于两点之间的直线来估算缺失值,适用于数据呈线性变化的情况。
- 'time':适用于时间序列数据,会考虑时间间隔进行插值。
- 'polynomial':多项式插值,通过拟合多项式曲线来估算缺失值,可通过 order 参数指定多项式的阶数。
python
import pandas as pd
import numpy as np
# 创建包含缺失值的 Series
s = pd.Series([1, np.nan, 3, 4, np.nan, 6])
# 使用默认的线性插值方法填充缺失值
s_interpolated = s.interpolate()
print(s_interpolated)
# 0 1.0
# 1 2.0
# 2 3.0
# 3 4.0
# 4 5.0
# 5 6.0
# dtype: float64
python
Bash
# 缺失值
import numpy as np
# 缺失值的类型 nan na
s = pd.Series([np.nan, None, pd.NA,2,4])
df = pd.DataFrame([[1, pd.NA, 2], [2, 3, 5], [pd.NA, 4, 6]])
print(s)
print(s.isnull()) #查看是否是缺失值
print(s.isna()) #查看是否是缺失值
print(s.isna().sum()) # 缺失值的个数
# 剔除缺失值
print(s.dropna()) #series剔除缺失值
print(df.dropna()) #只要有缺失值,就剔除一整条记录
print(df.dropna(how="all")) # 如果所有值都是缺失值,则删除这一行
print(df.dropna(thresh=2)) # 如果至少有2个值不是缺失值,则保留这一行
print(df.dropna(axis=1)) #剔除一列中含缺失值的列
#可以通过设置subset参数来设置某一列有缺失值则进行剔除。
print(df.dropna(subset=[0]))# 如果0列有缺失值,则删除这一行
#填充缺失值
print('********')
df = pd.read_csv("data/weather_withna.csv")
# df = df.fillna({"temp_max": 60, "temp_min": -60}) # 使用字典来填充
print(df['temp_max'].mean())
df.fillna(df[["precipitation", "temp_max", "temp_min", "wind"]].mean()).tail() # 使用平均值填充
print(df.ffill().tail()) # 使用前面的有效值填充
print(df.bfill().tail()) # 使用后面的有效值填充
df1 = pd.read_csv("data/weather_withna.csv")
df2 = pd.read_csv("data/weather_withna.csv", keep_default_na=False)
print(df1.temp_max.count())
print(df1.isnull().sum())
print(df2.temp_max.count())
print(df2.isnull().sum())
# 将
df = pd.read_csv("data/weather_withna.csv", na_values=["2015-12-31"])
# print(df.tail(5))
print(df.isnull().sum())- 重复数据处理
|---------------------|---------------------------------------|-----------------------------|
| 方法 / 操作 | 语法示例 | 描述 |
| 检测重复行 | df.duplicated() | 返回布尔序列标记重复行(首次出现的行标记为False) |
| 删除重复行 | df.drop_duplicates() | 保留首次出现的行(默认检查所有列) |
| | df.drop_duplicates(subset='col1') | 仅根据指定列去重 |
| | df.drop_duplicates(keep='last') | 保留最后一次出现的行 |
1. 检测重复行
python
Python
import pandas as pd
# 创建包含重复数据的DataFrame
data = {
'Name': ['Alice', 'Bob', 'Alice', 'Charlie', 'Bob'],
'Age': [25, 30, 25, 35, 30],
'City': ['NY', 'LA', 'NY', 'SF', 'LA']
}
df = pd.DataFrame(data)
# 检测重复行(默认检查所有列)
print("重复行标记(False表示首次出现,True表示重复):")
print(df.duplicated())输出:
python
Plain Text
0 False
1 False
2 True
3 False
4 True
dtype: bool2. 删除重复行
python
Python
# 默认保留首次出现的行
df_unique = df.drop_duplicates()
print("去重后的DataFrame:")
print(df_unique)输出:
python
Plain Text
Name Age City
0 Alice 25 NY
1 Bob 30 LA
3 Charlie 35 SF3. 按指定列去重
python
Python
# 仅根据'Name'列去重(保留首次出现)
df_name_unique = df.drop_duplicates(subset=['Name'])
print("按Name列去重:")
print(df_name_unique)输出:
python
Plain Text
Name Age City
0 Alice 25 NY
1 Bob 30 LA
3 Charlie 35 SF4. 保留最后一次出现的重复行
python
Python
# 保留最后一次出现的行
df_last = df.drop_duplicates(keep='last')
print("保留最后一次出现的行:")
print(df_last)输出:
python
Plain Text
Name Age City
2 Alice 25 NY
4 Bob 30 LA
3 Charlie 35 SF5. 综合案例:处理真实数据
python
Python
# 加载包含重复值的数据(示例)
df_sales = pd.read_csv("sales_data.csv")
# 检查重复行数量
print("原始数据重复行数:", df_sales.duplicated().sum())
# 按'Order_ID'列去重,保留最后一次记录
df_clean = df_sales.drop_duplicates(subset=['Order_ID'], keep='last')
# 验证结果
print("去重后数据行数:", len(df_clean))注意事项
- 性能优化 :对大数据集去重时,可通过 subset 指定关键列以减少计算量。
- 逻辑一致性 :确保 keep='last' 或 keep=False(删除所有重复)符合业务需求。
- 多列去重 :subset='col1', 'col2' 可联合多列判断重复。
通过以上案例,可以灵活应对实际数据清洗中的重复值问题!
- 数据类型转换
|---------------------|--------------------------------|---------------------------------------|
| 方法 / 操作 | 语法示例 | 描述 |
| 查看数据类型 | df.dtypes | 显示每列的数据类型 |
| 强制类型转换 | df'col'.astype('int') | 将列转换为指定类型(如int, float, str, datetime) |
| 转换为日期时间 | pd.to_datetime(df'col') | 将字符串列转为datetime类型 |
| 转换为分类数据 | df'col'.astype('category') | 将列转为分类类型(节省内存,提高性能) |
| 数值格式化 | df'col'.round(2) | 保留2位小数 |
核心方法
|---------|--------------------------------|--------------------------------------|
| 操作 | 方法 / 函数 | 描述 |
| 查看数据类型 | df.dtypes | 显示每列的数据类型(如int64、float64、object等)。 |
| 强制类型转换 | df'col'.astype('type') | 将列转换为指定类型(如int、float、str、bool等)。 |
| 转换为日期时间 | pd.to_datetime(df'col') | 将字符串或数值列转为datetime类型(支持自定义格式)。 |
| 转换为分类数据 | df'col'.astype('category') | 将列转为分类类型(节省内存,提高性能,适用于有限取值的列如性别、省份)。 |
| 数值格式化 | df'col'.round(2) | 保留指定小数位数(如2位)。 |
代码案例讲解
1. 查看数据类型
python
Python
import pandas as pd
# 加载数据(以sleep.csv为例)
df = pd.read_csv("sleep.csv")
print(df.dtypes)输出示例:
python
Plain Text
person_id int64
gender object
age int64
occupation object
sleep_duration float64
sleep_quality float64
... ...|--------------------------------------|
| 说明 :object通常为字符串或混合类型,需检查是否需要转换。 |
2. 强制类型转换
将数值列转换为整数或字符串:
python
Python
# 将sleep_duration从float转为int(丢失小数部分)
df['sleep_duration_int'] = df['sleep_duration'].astype('int32')
# 将gender转为字符串
df['gender_str'] = df['gender'].astype('str')
print(df[['sleep_duration', 'sleep_duration_int', 'gender_str']].head())输出:
|--------------------------------------------------------------------------------------------------|
| Plain Text sleep_duration sleep_duration_int gender_str 0 7.4 7 Male 1 4.2 4 Female 2 6.1 6 Male |
3. 转换为日期时间
处理时间数据(假设employees.csv有日期列):
python
Python
# 示例:创建临时日期列(实际数据可能为hire_date)
df_employees = pd.read_csv("employees.csv")
df_employees['fake_date'] = '2023-01-' + df_employees['employee_id'].astype(str).str[:2]
# 转换为datetime
df_employees['fake_date'] = pd.to_datetime(df_employees['fake_date'])
print(df_employees[['employee_id', 'fake_date']].head())输出:
python
Plain Text
employee_id fake_date
0 100 2023-01-10
1 101 2023-01-10
2 102 2023-01-10|-----------------------------------------------------------------------------|
| 注意 :若原始格式非标准,需指定格式参数,如: pd.to_datetime(df'date', format='%Y/%m/%d') |
4. 转换为分类数据
优化内存和性能(适用于低基数列):
python
Python
# 将gender列转为分类类型
df['gender'] = df['gender'].astype('category')
print(df['gender'].dtypes)输出:
|-----------------------------------|
| python Plain Text category |
|-------------------------------------------------------------|
| 优势 : * 减少内存占用(尤其对重复值多的列)。 * 加速groupby、sort等操作。 |
5. 数值格式化
控制小数位数:
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| python Python # 保留sleep_quality的2位小数 df['sleep_quality_rounded'] = df['sleep_quality'].round(2) print(df[['sleep_quality', 'sleep_quality_rounded']].head()) |
输出:
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| python Plain Text sleep_quality sleep_quality_rounded 0 7.0 7.00 1 4.9 4.90 2 6.0 6.00 |
常见问题与技巧
- 处理转换错误 :使用errors='coerce'将无效值转为NaN,避免报错:
|----------------------------------------------------------------------------|
| python Python df['age'] = pd.to_numeric(df['age'], errors='coerce') |
- 内存优化 :将数值列从int64转为int32或float32:
|------------------------------------------------------------|
| python Python df['age'] = df['age'].astype('int32') |
- 布尔类型转换:将字符串(如"Yes"/"No")转为布尔值:
|------------------------------------------------------------------------------------------|
| python Python df['is_active'] = df['active_flag'].map({'Yes': True, 'No': False}) |
- 自定义格式化 :使用apply实现复杂转换(如百分比):
|-----------------------------------------------------------------------------------------|
| python Python df['score_percent'] = df['score'].apply(lambda x: f"{x*100:.1f}%") |
实战案例:处理 penguins.csv
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| python Python df_penguins = pd.read_csv("penguins.csv") # 1. 转换sex为分类类型 df_penguins['sex'] = df_penguins['sex'].astype('category') # 2. 补全缺失值后转换bill_length_mm为float32 df_penguins['bill_length_mm'] = df_penguins['bill_length_mm'].fillna(0).astype('float32') # 3. 检查并输出结果 print(df_penguins[['species', 'sex', 'bill_length_mm']].dtypes) |
输出:
|---------------------------------------------------------------|
| Plain Text species object sex category bill_length_mm float32 |
- 数据重塑与变形
|---------------------|---------------------------------------------------|------------------------------|
| 方法 / 操作 | 语法示例 | 描述 |
| 行列转置 | df.T | 转置DataFrame(行变列,列变行) |
| 宽表转长表 | pd.melt(df, id_vars='id') | 将多列合并为键值对形式(variable和value列) |
| 长表转宽表 | df.pivot(index='id', columns='var', values='val') | 将长表转换为宽表(类似Excel数据透视) |
| 分列操作 | df'col'.str.split(',', expand=True) | 按分隔符拆分字符串为多列 |
1. 行列转置( df.T )
将DataFrame的行列互换,适用于需要横向展示数据的场景。
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python import pandas as pd # 示例数据 data = { 'Name': 'Alice', 'Bob', 'Charlie', 'Age': 25, 30, 35, 'City': 'NY', 'LA', 'SF' } df = pd.DataFrame(data) # 行列转置 df_transposed = df.T print("原始数据:\n", df) print("\n转置后数据:\n", df_transposed) |
输出:
|-----------------------------------------------------------------------------------------------------------------------------------------|
| Plain Text 原始数据: Name Age City 0 Alice 25 NY 1 Bob 30 LA 2 Charlie 35 SF 转置后数据: 0 1 2 Name Alice Bob Charlie Age 25 30 35 City NY LA SF |
2. 宽表转长表( **pd.melt()** )
将多列合并为键值对形式,适合分析多指标数据。
|--------|
| Python |
输出:
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Plain Text 原始数据: ID Math English Science 0 1 90 88 95 1 2 85 92 89 转换后数据: ID Subject Score 0 1 Math 90 1 2 Math 85 2 1 English 88 3 2 English 92 4 1 Science 95 5 2 Science 89 |
3. 长表转宽表( **df.pivot()** )
将长表转换为宽表,类似Excel的数据透视表。
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python # 示例数据(长表) data = { 'ID': 1, 1, 1, 2, 2, 2, 'Subject': 'Math', 'English', 'Science', 'Math', 'English', 'Science', 'Score': 90, 88, 95, 85, 92, 89 } df = pd.DataFrame(data) # 长表转宽表(以ID为索引,Subject为列,Score为值) df_pivoted = df.pivot(index='ID', columns='Subject', values='Score') print("原始数据:\n", df) print("\n转换后数据:\n", df_pivoted) |
输出:
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Plain Text 原始数据: ID Subject Score 0 1 Math 90 1 1 English 88 2 1 Science 95 3 2 Math 85 4 2 English 92 5 2 Science 89 转换后数据: Subject English Math Science ID 1 88 90 95 2 92 85 89 |
4. 分列操作( **str.split()** )
按分隔符拆分字符串列,生成多列。
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python # 示例数据 data = { 'Full_Name': 'Alice Smith', 'Bob Johnson', 'Charlie Brown' } df = pd.DataFrame(data) # 拆分Full_Name为FirstName和LastName df\['First_Name', 'Last_Name'] = df'Full_Name'.str.split(' ', expand=True) print("原始数据:\n", df\['Full_Name']) print("\n拆分后数据:\n", df\['First_Name', 'Last_Name']) |
输出:
|------------------------------------------------------------------------------------------------------------------------------------------------|
| Plain Text 原始数据: Full_Name 0 Alice Smith 1 Bob Johnson 2 Charlie Brown 拆分后数据: First_Name Last_Name 0 Alice Smith 1 Bob Johnson 2 Charlie Brown |
注意事项
- pivot **与****pivot_table****的区别**:
- pivot要求索引和列的组合唯一,否则报错。
- pivot_table支持聚合(如均值、求和),适合非唯一组合。
- 分列操作:
- 使用expand=True将拆分结果转为多列。
- 若分隔符数量不一致,需预处理数据(如填充缺失值)。
- 内存管理:
- 宽表转长表可能增加行数,需注意内存占用。
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Bash # 数据变形 import pandas as pd data = { 'ID': 1, 2, 'name':'alice','bob', 'Math': 90, 85, 'English': 88, 92, 'Science': 95, 89 } df = pd.DataFrame(data) df df.T # 宽表转长表 df2= pd.melt(df, id_vars='ID','name', var_name='科目', value_name='分数') df2.sort_values(by='name','科目') # 长表转宽表 df3=pd.pivot(df2,index='ID','name',columns='科目',values='分数') # 分列 data = { 'ID': 1, 2, 'name':'alice smith','bob jack', 'Math': 90, 85, 'English': 88, 92, 'Science': 95, 89 } df = pd.DataFrame(data) df\['first name','last name'] = df'name'.str.split(' ',expand=True) # 加载数据 df = pd.read_csv("data/sleep.csv") df=df\['person_id','blood_pressure'] df\['high','low']=df'blood_pressure'.str.split('/',expand=True) df |
- 文本数据处理
|---------------------|---------------------------------------|-----------------|
| 方法 / 操作 | 语法示例 | 描述 |
| 字符串大小写转换 | df'col'.str.lower() | 转为小写 |
| 去除空格 | df'col'.str.strip() | 去除两端空格 |
| 字符串替换 | df'col'.str.replace('old', 'new') | 替换文本 |
| 正则表达式提取 | df'col'.str.extract(r'(\d+)') | 提取匹配正则的文本(如数字) |
| 字符串包含检测 | df'col'.str.contains('abc') | 返回布尔序列,判断是否包含子串 |
1. 字符串大小写转换
统一文本格式,便于后续分析(如姓名、地址等)。
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python import pandas as pd # 示例数据 data = {'Name': 'ALICE', 'Bob', 'CHARLIE'} df = pd.DataFrame(data) # 转为小写 df'Name_lower' = df'Name'.str.lower() # 转为大写 df'Name_upper' = df'Name'.str.upper() print(df) |
输出:
|---------------------------------------------------------------------------------------------------|
| Plain Text Name Name_lower Name_upper 0 ALICE alice ALICE 1 Bob bob BOB 2 CHARLIE charlie CHARLIE |
2. 去除空格
处理用户输入或爬取数据中的多余空格。
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python # 示例数据(含前后空格) data = {'Text': ' Hello ', ' Pandas ', ' Data '} df = pd.DataFrame(data) # 去除两端空格 df'Text_stripped' = df'Text'.str.strip() print(df) |
输出:
|-------------------------------------------------------------------------|
| Plain Text Text Text_stripped 0 Hello Hello 1 Pandas Pandas 2 Data Data |
3. 字符串替换
替换文本中的特定字符或模式(如清理脏数据)。
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python # 示例数据(含特殊字符) data = {'Comment': 'Good!', 'Bad?', 'Okay...'} df = pd.DataFrame(data) # 替换标点符号为空字符串 df'Comment_clean' = df'Comment'.str.replace(r'!?.', '', regex=True) print(df) |
输出:
|-------------------------------------------------------------------------|
| Plain Text Comment Comment_clean 0 Good! Good 1 Bad? Bad 2 Okay... Okay |
4. 正则表达式提取
从文本中提取结构化信息(如电话号码、日期)。
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python # 示例数据(含混合文本) data = {'Info': 'Age:25', 'Height:170cm', 'Weight:65kg'} df = pd.DataFrame(data) # 提取数字 df'Value' = df'Info'.str.extract(r'(\d+)') print(df) |
输出:
|-----------------------------------------------------------------------|
| Plain Text Info Value 0 Age:25 25 1 Height:170cm 170 2 Weight:65kg 65 |
5. 字符串包含检测
筛选包含特定关键词的记录。
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python # 示例数据(产品评论) data = {'Review': 'Great product', 'Not good', 'Excellent service'} df = pd.DataFrame(data) # 检测是否包含"good"(不区分大小写) df'Is_Positive' = df'Review'.str.contains('good', case=False) print(df) |
输出:
|----------------------------------------------------------------------------------------------|
| Plain Text Review Is_Positive 0 Great product True 1 Not good True 2 Excellent service False |
实战案例:处理 employees.csv
清理员工姓名和邮箱数据:
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python # 加载数据 df_employees = pd.read_csv("employees.csv") # 1. 将first_name首字母大写,其余小写 df_employees'first_name' = df_employees'first_name'.str.capitalize() # 2. 提取邮箱域名(@后部分) df_employees'email_domain' = df_employees'email'.str.extract(r'@(.+)') print(df_employees\['first_name', 'email', 'email_domain'].head()) |
输出:
|----------------------------------------------------------------------------------------------------------------------------------------|
| Plain Text first_name email email_domain 0 Steven SKING@abc.com abc.com 1 N_ann NKOCHHAR@abc.com abc.com 2 Lex LDEHAAN@abc.com abc.com |
- 数据分箱与离散化
|---------------------|-----------------------------|----------------------|
| 方法 / 操作 | 语法示例 | 描述 |
| 等宽分箱 | pd.cut(df'col', bins=3) | 将数值列分为等宽区间(如分为低/中/高) |
| 等频分箱 | pd.qcut(df'col', q=4) | 将数值列分为等频区间(每箱数据量相同) |
cut()
pandas.cut()用于将连续数据(如数值型数据)分割成离散的区间。可以使用cut()来将数据划分为不同的类别或范围,通常用于数据的分箱处理。
cut()部分参数说明:
|------------|----------------------------------------------------------|
| 参数 | 说明 |
| x | 要分箱的数组或Series,通常是数值型数据。 |
| bins | 切分区间的数值列表或者整数。如果是整数,则表示将数据均匀地分成多少个区间。如果是列表,则需要指定每个区间的边界。 |
| right | 默认True,表示每个区间的右端点是闭区间,即包含右端点。如果设置为False,则左端点为闭区间。 |
| labels | 传入一个列表指定每个区间的标签。 |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Bash df = pd.read_csv("data/employees.csv")# 加载员工数据 df1 = df.iloc:10 print(df1"salary") salary = pd.cut(df.iloc9:16"salary", 3) print(salary) salary = pd.cut(df1"salary", 0, 10000, 20000) print(salary) df'salary_level' = pd.cut(df"salary", bins=3, labels="low", "medium", "high") print(df'salary_level') df'salary_level' = pd.cut(df"salary", bins=0, 10000, 20000,300000, labels="low", "medium", "high") print(df'salary_level') df = pd.read_csv("data/employees.csv")# 加载员工数据 salary = pd.cut(df"salary", 3) print(salary.value_counts()) salary2 = pd.qcut(df"salary", 3) print(salary2.value_counts()) #睡眠数据分箱 df_sleep = pd.read_csv("data/sleep.csv") # 将睡眠质量分为3组:差(0-4)、中(4-7)、好(7-10) bins = 0, 4, 7, 10 labels = '差', '中', '好' df_sleep'quality_level' = pd.cut( df_sleep'sleep_quality', bins=bins, labels=labels ) print(df_sleep 'quality_level') print(df_sleep 'quality_level'.value_counts()) |
- 其他常用转换
- df.rename(columns={"score": "成绩"})
- df.set_index("name")
- df.reset_index()
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python df = pd.DataFrame({"age": 20, 30, 40, 10, "name": "张三", "李四", "王五", "赵六", "id": 101, 102, 103, 104}) print(df) # age name id # 0 20 张三 101 # 1 30 李四 102 # 2 40 王五 103 # 3 10 赵六 104 #通过set_index()设置行索引 # inplace=True:这是一个布尔类型的参数。当设为 True 时,会直接在原 # DataFrame上进行修改;若设为 False(默认值),则会返回一个新的 # DataFrame,原DataFrame 保持不变 df.set_index("id", inplace=True) # 设置行索引 print(df) df.reset_index(inplace=True) # 重置索引 print(df) #修改行索引名和列名 个别修改 df.rename(index={101: "一", 102: "二", 103: "三", 104: "四"}, columns={"age": "年龄", "name": "姓名"}, inplace=True) print(df) #重新赋值 批量修改 df.index = "Ⅰ", "Ⅱ", "Ⅲ", "Ⅳ" df.columns = "年齡", "名稱" #添加列 通过 df"列名" 添加列。 df"phone" = "13333333333", "14444444444", "15555555555", "16666666666" #删除列 # 通过 df.drop("列名", axis=1) 删除,也可是删除行 axis=0 df.drop("phone", axis=1, inplace=True) # 删除phone,按列删除,inplace=True表示直接在原对象上修改 print(df) #通过 del df"列名" 删除 del df"phone" print(df) #插入列 通过 insert(loc, column, value) 插入。该方法没有inplace参数,直接在原数据上修改。 df.insert(loc=0, column="phone", value=df"age" * df.index) print(df) |
3.4 数据的导入与导出
导出数据
|--------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------|
| 方法 | 说明 |
| to_csv() | 将数据保存为csv格式文件,数据之间以逗号分隔,可通过sep参数设置使用其他分隔符,可通过index参数设置是否保存行标签,可通过header参数设置是否保存列标签。 |
| to_pickle() | 如要保存的对象是计算的中间结果,或者保存的对象以后会在Python中复用,可把对象保存为.pickle文件。如果保存成pickle文件,只能在python中使用。文件的扩展名可以是.p、.pkl、.pickle。 |
| to_excel() | 保存为Excel文件,需安装openpyxl包。 |
| to_clipboard() | 保存到剪切板。 |
| to_dict() | 保存为字典。 |
| to_hdf() | 保存为HDF格式,需安装tables包。 |
| to_html() | 保存为HTML格式,需安装lxml、html5lib、beautifulsoup4包。 |
| to_json() | 保存为JSON格式。 |
| to_feather() | feather是一种文件格式,用于存储二进制对象。feather对象也可以加载到R语言中使用。feather格式的主要优点是在Python和R语言之间的读写速度要比csv文件快。feather数据格式通常只用中间数据格式,用于Python和R之间传递数据,一般不用做保存最终数据。需安装pyarrow包。 |
| to_sql() | 保存到数据库。 |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python import os import pandas as pd os.makedirs("data", exist_ok=True) df = pd.DataFrame({"age": 20, 30, 40, 10, "name": "张三", "李四", "王五", "赵六", "id": 101, 102, 103, 104}) df.set_index("id", inplace=True) df.to_csv("data/df.csv") df.to_csv("data/df.tsv", sep="\t") # 设置分隔符为 \t df.to_csv("data/df_noindex.csv", index=False) # index=False 不保存行索引 df.to_pickle("data/df.pkl") df.to_excel("data/df.xlsx") df.to_clipboard() df_dict = df.to_dict() df.to_hdf("data/df.h5", key="df") df.to_html("data/df.html") df.to_json("data/df.json") df.to_feather("data/df.feather") |
导入数据
|----------------------|-----------------------------------------------|
| 方法 | 说明 |
| read_csv() | 加载csv格式的数据。可通过sep参数指定分隔符,可通过index_col参数指定行索引。 |
| read_pickle() | 加载pickle格式的数据。 |
| read_excel() | 加载Excel格式的数据。 |
| read_clipboard() | 加载剪切板中的数据。 |
| read_hdf() | 加载HDF格式的数据。 |
| read_html() | 加载HTML格式的数据。 |
| read_json() | 加载JSON格式的数据。 |
| read_feather() | 加载feather格式的数据。 |
| read_sql() | 加载数据库中的数据。 |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python df_csv = pd.read_csv("data/df.csv", index_col="id") # 指定行索引 df_tsv = pd.read_csv("data/df.tsv", sep="\t") # 指定分隔符 df_pkl = pd.read_pickle("data/df.pkl") df_excel = pd.read_excel("data/df.xlsx", index_col="id") df_clipboard = pd.read_clipboard(index_col="id") df_from_dict = pd.DataFrame(df_dict) df_hdf = pd.read_hdf("data/df.h5", key="df") df_html = pd.read_html("data/df.html", index_col=0)0 df_json = pd.read_json("data/df.json") df_feather = pd.read_feather("data/df.feather") print(df_csv) print(df_tsv) print(df_pkl) print(df_excel) print(df_clipboard) print(df_from_dict) print(df_hdf) print(df_html) print(df_json) print(df_feather) |
3.6 时间数据的处理
Timestamp 是 pandas 对 datetime64 数据类型的一个封装。datetime64 是 NumPy 中的一种数据类型,用于表示日期和时间,而 pandas 基于 datetime64 构建了 Timestamp 类,以便更方便地在 pandas 的数据结构(如 DataFrame 和 Series)中处理日期时间数据。当 pd.to_datetime 接收单个日期时间值时,会返回 Timestamp 对象
- 时间戳 timestamp
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python d = pd.Timestamp( "2015-05-01 09:08:07.123456" ) # 属性 print('年:',d.year) print('月:',d.month) print('日:',d.day) print('小时:',d.hour) print('分钟:',d.minute) print('秒:',d.second) print('微秒:',d.microsecond) print('季度:',d.quarter) print('是否是月底:',d.is_month_end) print('是否是月初:',d.is_month_start) print('是否是年底:',d.is_year_end) print('是否是年初:',d.is_year_start) # 方法 print('星期几:',d.day_name()) print('转换为年度:',d.to_period("Y")) print('转换为季度:',d.to_period("Q")) print('转换为月度:',d.to_period("M")) print('转换为季度:',d.to_period("Q")) print('转换为周维度:',d.to_period("W")) |
to_period()获取统计周期
freq:这是 to_period() 方法最重要的参数,用于指定要转换的时间周期频率
常见的取值如下:
- "D":按天周期,例如 2024-01-01 会转换为 2024-01-01 这个天的周期。
- "W":按周周期,通常以周日作为一周的结束,比如日期落在某一周内,就会转换为该周的周期表示。
- "M":按月周期,像 2024-05-15 会转换为 2024-05。
- "Q":按季度周期,一年分为四个季度,日期会转换到对应的季度周期,例如 2024Q2 。
- "A" 或 "Y":按年周期,如 2024-07-20 会转换为 2024 。
- 日期数据转换
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Bash # 字符串字段转换为日期类型 a = pd.to_datetime('2025-07-01') a = pd.to_datetime('20250409') a = pd.to_datetime('2025/04/13') a = pd.to_datetime('2025-07') print(a) print(type(a)) # dateFrame 中的日期转换 df = pd.DataFrame({ 'sales':100,50,40, 'date':'2025-01-01','2023-03-02','2025-03-09' }) df'datetime' = pd.to_datetime(df'date') print(type(df'datetime'.dt)) df'datetime'.dt.day_name() |
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Bash # 导入数据日期的处理 df = pd . read_csv ( "data/weather.csv" ) print ( df "date" . tail ()) # 1456 2015-12-27 # 1457 2015-12-28 # 1458 2015-12-29 # 1459 2015-12-30 # 1460 2015-12-31 # Name: date, dtype: object print ( pd . to_datetime ( df "date" ). tail ()) # 1456 2015-12-27 # 1457 2015-12-28 # 1458 2015-12-29 # 1459 2015-12-30 # 1460 2015-12-31 # Name: date, dtype: datetime64ns # 在加载数据时也可以通过parse_dates参数将指定列解析为datetime64。 df = pd . read_csv ( "data/weather.csv" , parse_dates = 0 ) print ( df "date" . tail ()) |
- 将日期数据作为索引
将datetime64类型的数据设置为索引,得到的就是DatetimeIndex。
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Bash df = pd.read_csv("data/weather.csv") df"date" = pd.to_datetime(df"date") # 将date列转换为datetime64类型 df.set_index("date", inplace=True) # 将date列设置为索引,inplace=true直接修改原对象 df.info() # <class 'pandas.core.frame.DataFrame'> # DatetimeIndex: 1461 entries, 2012-01-01 to 2015-12-31 |
将时间作为索引后可以直接使用时间进行切片取值。
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Plain Text print(df.loc"2013-01":"2013-06") # 获取2013年1~6月的数据 # precipitation temp_max temp_min wind weather # date # 2013-01-01 0.0 5.0 -2.8 2.7 sun # 2013-01-02 0.0 6.1 -1.1 3.2 sun # ... ... ... ... ... ... # 2013-06-29 0.0 30.0 18.3 1.7 sun # 2013-06-30 0.0 33.9 17.2 2.5 sun print ( df . loc "2015" ) # 获取2015年所有数据 # precipitation temp_max temp_min wind weather # date # 2015-01-01 0.0 5.6 -3.2 1.2 sun # 2015-01-02 1.5 5.6 0.0 2.3 rain # ... ... ... ... ... ... # 2015-12-30 0.0 5.6 -1.0 3.4 sun # 2015-12-31 0.0 5.6 -2.1 3.5 sun |
也可以通过between_time()和at_time()获取某些时刻的数据。
|------------------------------------------------------------------------------------------------|
| Plain Text df.between_time("9:00", "11:00") # 获取9:00到11:00之间的数据 df.at_time("3:33") # 获取3:33的数据 |
- 时间间隔 timedelta
当用一个日期减去另一个日期,返回的结果是timedelta64类型。
|----------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Plain Text d1 = pd.Timestamp( "2015-05-01 09:08:07.123456" ) d2 = pd.Timestamp( "2015-05-31 09:23:07.123456" ) print(d2-d1) print(type(d1)) print(type(d2-d1)) |
TimedeltaIndex
将timedelta64类型的数据设置为索引,得到的就是TimedeltaIndex。
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Plain Text df = pd.read_csv("data/weather.csv", parse_dates=0) df_date = pd . to_datetime ( df "date" ) df "timedelta" = df_date - df_date 0 # 得到timedelta64类型的数据 df . set_index ( "timedelta" , inplace = True ) # 将timedelta列设置为索引 df . info () # <class 'pandas.core.frame.DataFrame'> # TimedeltaIndex: 1461 entries, 0 days to 1460 days |
将时间作为索引后可以直接使用时间进行切片取值。
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Plain Text print(df.loc"0 days":"5 days") # date precipitation temp_max temp_min wind weather # timedelta # 0 days 2012-01-01 0.0 12.8 5.0 4.7 drizzle # 1 days 2012-01-02 10.9 10.6 2.8 4.5 rain # 2 days 2012-01-03 0.8 11.7 7.2 2.3 rain # 3 days 2012-01-04 20.3 12.2 5.6 4.7 rain # 4 days 2012-01-05 1.3 8.9 2.8 6.1 rain # 5 days 2012-01-06 2.5 4.4 2.2 2.2 rain |
- 时间序列
生成时间序列
为了能更简便地创建有规律的时间序列,pandas提供了date_range()方法。
date_range()通过开始日期、结束日期和频率代码(可选)创建一个有规律的日期序列,默认的频率是天。
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python print(pd.date_range("2015-07-03", "2015-07-10")) # DatetimeIndex('2015-07-03', '2015-07-04', '2015-07-05', '2015-07-06', # '2015-07-07', '2015-07-08', '2015-07-09', '2015-07-10', # dtype='datetime64ns', freq='D') |
此外,日期范围不一定非是开始时间与结束时间,也可以是开始时间与周期数periods。
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Plain Text print(pd.date_range("2015-07-03", periods=5)) # DatetimeIndex('2015-07-03', '2015-07-04', '2015-07-05', '2015-07-06', # '2015-07-07', # dtype='datetime64ns', freq='D') |
可以通过freq参数设置时间频率,默认值是D。此处改为h,按小时变化的时间戳。
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Plain Text print(pd.date_range("2015-07-03", periods=5, freq="h")) # DatetimeIndex('2015-07-03 00:00:00', '2015-07-03 01:00:00', # '2015-07-03 02:00:00', '2015-07-03 03:00:00', # '2015-07-03 04:00:00', # dtype='datetime64ns', freq='h') |
下表为常见时间频率代码与说明:
|------------|----------------------------------|
| 代码 | 说明 |
| D | 天(calendar day,按日历算,含双休日) |
| B | 天(business day,仅含工作日) |
| W | 周(weekly) |
| ME / M | 月末(month end) |
| BME | 月末(business month end,仅含工作日) |
| MS | 月初(month start) |
| BMS | 月初(business month start,仅含工作日) |
| QE / Q | 季末(quarter end) |
| BQE | 季末(business quarter end,仅含工作日) |
| QS | 季初(quarter start) |
| BQS | 季初(business quarter start,仅含工作日) |
| YE / Y | 年末(year end) |
| BYE | 年末(business year end,仅含工作日) |
| YS | 年初(year start) |
| BYS | 年初(business year start,仅含工作日) |
| h | 小时(hours) |
| bh | 小时(business hours,工作时间) |
| min | 分钟(minutes) |
| s | 秒(seconds) |
| ms | 毫秒(milliseonds) |
| us | 微秒(microseconds) |
| ns | 纳秒(nanoseconds) |
偏移量
可以在频率代码后面加三位月份缩写字母来改变季、年频率的开始时间。
- QE-JAN、BQE-FEB、QS-MAR、BQS-APR等
- YE-JAN、BYE-FEB、YS-MAR、BYS-APR等
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Shell print ( pd . date_range ( "2015-07-03" , periods = 10 , freq = "QE-JAN" )) # 设置1月为季度末 # DatetimeIndex('2015-07-31', '2015-10-31', '2016-01-31', '2016-04-30', # '2016-07-31', '2016-10-31', '2017-01-31', '2017-04-30', # '2017-07-31', '2017-10-31', # dtype='datetime64ns', freq='QE-JAN') |
同理,也可以在后面加三位星期缩写字母来改变一周的开始时间。
- W-SUN、W-MON、W-TUE、W-WED等
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Shell print ( pd . date_range ( "2015-07-03" , periods = 10 , freq = "W-WED" )) # 设置周三为一周的第一天 # DatetimeIndex('2015-07-08', '2015-07-15', '2015-07-22', '2015-07-29', # '2015-08-05', '2015-08-12', '2015-08-19', '2015-08-26', # '2015-09-02', '2015-09-09', # dtype='datetime64ns', freq='W-WED') |
在这些代码的基础上,还可以将频率组合起来创建的新的周期。例如,可以用小时(h)和分钟(min)的组合来实现2小时30分钟。
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Shell print ( pd . date_range ( "2015-07-03" , periods = 10 , freq = "2h30min" )) # DatetimeIndex('2015-07-03 00:00:00', '2015-07-03 02:30:00', # '2015-07-03 05:00:00', '2015-07-03 07:30:00', # '2015-07-03 10:00:00', '2015-07-03 12:30:00', # '2015-07-03 15:00:00', '2015-07-03 17:30:00', # '2015-07-03 20:00:00', '2015-07-03 22:30:00', # dtype='datetime64ns', freq='150min') |
- 重新采样
处理时间序列数据时,经常需要按照新的频率(更高频率、更低频率)对数据进行重新采样。可以通过resample()方法解决这个问题。resample()方法以数据累计为基础,会将数据按指定的时间周期进行分组,之后可以对其使用聚合函数。
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Bash df = pd . read_csv ( "data/weather.csv" ) df "date" = pd . to_datetime ( df "date" ) df . set_index ( "date" , inplace = True ) print ( df \[ "temp_max" , "temp_min" ]. resample ( "YE" ). mean ()) # 将数据按年分组,并计算每年的平均最高最低温度 # temp_max temp_min # date # 2012-12-31 15.276776 7.289617 # 2013-12-31 16.058904 8.153973 # 2014-12-31 16.995890 8.662466 # 2015-12-31 17.427945 8.835616 |
3.7 数据分析与统计
|-----------|----------------|------------------------------|---------------------------------------------------------------|
| 分类 | 依赖关系 | 协同应用场景 | 示例 |
| 描述性统计 | 所有分析的基础 | 初步了解数据分布,指导后续分组策略 | df.describe() 发现某列标准差大 → 触发分组过滤 |
| 分组聚合 | 基于描述性统计或分组过滤结果 | 按维度拆分后计算指标(如各品类销售额总和) | df.groupby('category')'sales'.sum() |
| 分组转换 | 依赖分组聚合结构 | 在保留原始行数的前提下,添加组内计算列(如标准化、排名) | df.groupby('group')'value'.transform(lambda x: x/x.max()) |
| 分组过滤 | 依赖描述性统计或分组聚合结果 | 根据组级条件筛选数据(如剔除样本量不足的组) | df.groupby('group').filter(lambda x: len(x) > 5) |
| 相关性分析 | 可结合分组聚合结果 | 分析不同分组下变量的关联性(如各地区的价格-销量相关性) | df.groupby('region')\['price','sales'].corr() |
关键交互逻辑
- 从宏观到微观
- 描述性统计(宏观) → 分组聚合(细分维度) → 分组转换/过滤(微观调整)
- 数据流闭环
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python # 示例:分析高波动品类(闭环流程) grouped = df.groupby('category') # 1. 描述性统计 → 2. 分组过滤 → 3. 分组转换 result = (grouped.filter(lambda x: x'price'.std() > 2) .groupby('category')'price' .transform(lambda x: (x - x.mean())/x.std())) |
- 功能互补性
- 聚合 vs 转换:聚合减少行数,转换保持行数。
- 过滤 vs 转*:过滤删除整组,转换修改组内值。
可视化应用场景

通过以上关系图和表格,可清晰理解如何组合这些方法解决实际问题,例如:
- 数据清洗:描述统计 → 发现异常 → 分组过滤
- 特征工程:分组聚合 → 分组转换(如生成占比特征)
-
业务分析:分组聚合 → 相关性分析(如用户分群行为关联)
-
常用聚合函数
|----------------|-------------------------|
| 方法 | 说明 |
| sum() | 求和 |
| mean() | 平均值 |
| min() | 最小值 |
| max() | 最大值 |
| var() | 方差 |
| std() | 标准差 |
| median() | 中位数 |
| quantile() | 指定位置的分位数,如quantile(0.5) |
| describe() | 常见统计信息 |
| size() | 所有元素的个数 |
| count() | 非空元素的个数 |
| first | 第一行 |
| last | 最后一行 |
| nth | 第n行 |
- 分组聚合
df.groupby("分组字段")"要聚合的字段".聚合函数()
df.groupby("分组字段", "分组字段2", ...)\["要聚合的字段", "要聚合的字段2", ...].聚合函数()
DataFrameGroupBy 对象
对DataFrame对象调用groupby()方法后,会返回DataFrameGroupBy对象。
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python df = pd.read_csv("data/employees.csv") # 读取员工数据 print(df.groupby("department_id")) # 按department_id分组,返回DataFrameGroupBy对象 # <pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000024FCBAFD700> |
这个对象可以看成是一种特殊形式的 DataFrame,里面隐藏着若干组数据,但是在没有应用累计函数之前不会计算。GroupBy对象是一种非常灵活的抽象类型。在大多数场景中,可以将它看成是DataFrame的集合。
查看分组
通过groups属性查看分组结果,返回一个字典,字典的键是分组的标签,值是属于该组的所有索引的列表。
|-------------------------------------------------------------------------------------------------------------------------------------|
| Python print(df.groupby("department_id").groups) # 查看分组结果 # {10.0: 100, 20.0: 101, 102, 30.0: 14, 15, 16, 17, 18, 19... |
通过get_group()方法获取分组。
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python print(df.groupby("department_id").get_group(50)) # 获取分组为50的数据 # employee_id first_name last_name email... # 20 120 Matthew Weiss MWEISS... # 21 121 Adam Fripp AFRIPP... # 22 122 Payam Kaufling PKAUFLIN... |
按列取值
|----------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python print(df.groupby("department_id")"salary") # 按department_id分组,取salary列 # <pandas.core.groupby.generic.SeriesGroupBy object at 0x0000022456D6F2F0> |
这里从原来的DataFrame中取某个列名作为一个Series组。与GroupBy对象一样,直到我们运行累计函数,才会开始计算。
|----------------------------------------------------------------------------------------------------------------------------------------------------|
| Python print(df.groupby("department_id")"salary".mean()) # 计算每个部门平均薪资 # department_id # 10.0 4400.000000 # 20.0 9500.000000 # 30.0 4150.000000 |
按组迭代
GroupBy对象支持直接按组进行迭代,返回的每一组都是Series或DataFrame。
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python for dept_id,group in df.groupby("department_id"): print(f"当前组为{dept_id},组里的数据情况{group.shape}:") print(group.iloc:,0:3) print("-------------------") # 当前组为10.0,组里的数据情况(1, 10): # employee_id first_name last_name # 100 200 Jennifer Whalen # ------------------- # 当前组为20.0,组里的数据情况(2, 10): # employee_id first_name last_name # 101 201 Michael Hartstein # 102 202 Pat Fay |
...
按多字段分组
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python salary_mean = df.groupby("department_id", "job_id") \["salary", "commission_pct" ].mean() # 按department_id和job_id分组 print(salary_mean.index) # 查看分组后的索引 # MultiIndex(( 10.0, 'AD_ASST'), # ( 20.0, 'MK_MAN'), # ( 20.0, 'MK_REP'), # ( 30.0, 'PU_CLERK'), # ( 30.0, 'PU_MAN'), # ... print(salary_mean.columns) # 查看分组后的列 # Index(\['salary', 'commission_pct', dtype='object') |
按多个字段分组后得到的索引为复合索引。
可通过reset_index()方法重置索引。
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python print(salary_mean.reset_index()) # department_id job_id salary commission_pct # 0 10.0 AD_ASST 4400.000000 NaN # 1 20.0 MK_MAN 13000.000000 NaN # 2 20.0 MK_REP 6000.000000 NaN # 3 30.0 PU_CLERK 2780.000000 NaN # 4 30.0 PU_MAN 11000.000000 NaN |
也可以在分组的时候通过as_index = False参数(默认是True)重置索引。
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python salary_mean = df.groupby("department_id", "job_id", as_index=False) \["salary", "commission_pct" ].mean() # 按department_id和job_id分组 print(salary_mean) # department_id job_id salary commission_pct # 0 10.0 AD_ASST 4400.000000 NaN # 1 20.0 MK_MAN 13000.000000 NaN # 2 20.0 MK_REP 6000.000000 NaN # 3 30.0 PU_CLERK 2780.000000 NaN # 4 30.0 PU_MAN 11000.000000 NaN |
将数据按月分组,并统计最大温度和最小温度的平均值
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python df"month" = pd.to_datetime(df"date").dt.to_period("M").astype(str) # 将date转换为 年-月 的格式 df_groupby_date = df.groupby("month") # 按month分组,返回一个分组对象(DataFrameGroupBy) month_temp = df_groupby_date\["temp_max", "temp_min"] # 从分组对象中选择特定的列 month_temp_mean = month_temp.mean() # 对每个列求平均值 # 以上代码可以写在一起 month_temp_mean = df.groupby("month")\["temp_max", "temp_min"].mean() # temp_max temp_min # month # 2012-01 7.054839 1.541935 # 2012-02 9.275862 3.203448 # 2012-03 9.554839 2.838710 # 2012-04 14.873333 5.993333 # 2012-05 17.661290 8.190323 |
分组后默认会将分组字段作为行索引。如果分组字段有多个,得到的是复合索引。
分组频数计算
统计每个月不同天气状况的数量。
|----------------------------------------------------------------------------------------------------------------------|
| Python df.groupby("month")"weather".nunique() # date # 2012-01 4 # 2012-02 4 # 2012-03 4 # 2012-04 4 # 2012-05 3 |
- 一次计算多个统计值
可以通过agg()或aggregate()进行更复杂的操作,如一次计算多个统计值。
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python df = pd.read_csv("data/employees.csv") # 读取员工数据 # 按department_id分组,计算salary的最小值,中位数,最大值 print(df.groupby("department_id")"salary".agg("min", "median", "max")) # min median max # department_id # 10.0 4400.0 4400.0 4400.0 # 20.0 6000.0 9500.0 13000.0 # 30.0 2500.0 2850.0 11000.0 # 40.0 6500.0 6500.0 6500.0 # 50.0 2100.0 3100.0 8200.0 |
多个列计算不同的统计值
也可以在agg()中传入字典,对多个列计算不同的统计值。
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python df = pd.read_csv("data/employees.csv") # 读取员工数据 # 按department_id分组,统计job_id的种类数,commission_pct的平均值 print(df.groupby("department_id").agg({"job_id": "nunique", "commission_pct": "mean"})) # job_id commission_pct # department_id # 10.0 1 NaN # 20.0 2 NaN # 30.0 2 NaN # 40.0 1 NaN # 50.0 3 NaN |
重命名统计值
可以在agg()后通过rename()对统计后的列重命名。
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python df = pd.read_csv("data/employees.csv") # 读取员工数据 # 按department_id分组,统计job_id的种类数,commission_pct的平均值 print( df.groupby("department_id") .agg( {"job_id": "nunique", "commission_pct": "mean"}, ) .rename( columns={"job_id": "工种数", "commission_pct": "佣金比例平均值"}, ) ) # 工种数 佣金比例平均值 # department_id # 10.0 1 NaN # 20.0 2 NaN # 30.0 2 NaN # 40.0 1 NaN # 50.0 3 NaN |
自定义函数
可以向agg()中传入自定义函数进行计算。
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python df = pd.read_csv("data/employees.csv") # 读取员工数据 def f(x): """统计每个部门员工last_name的首字母""" result = set() for i in x: result.add(i0) return result print(df.groupby("department_id")"last_name".agg(f)) # department_id # 10.0 {W} # 20.0 {F, H} # 30.0 {B, T, R, C, K, H} # 40.0 {M} # 50.0 {O, E, K, S, W, L, P, D, C, V, B, T, M, J, F, ... |
- 分组转换
聚合操作返回的是对组内全量数据缩减过的结果,而转换操作会返回一个新的全量数据。数据经过转换之后,其形状与原来的输入数据是一样的。
通过transform()将每一组的样本数据减去各组的均值,实现数据标准化
df = pd.read_csv("data/employees.csv") # 读取员工数据
print(df.groupby("department_id")"salary".transform(lambda x: x - x.mean()))
通过transform()按分组使用平均值填充缺失值
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python df = pd.read_csv("data/employees.csv") # 读取员工数据 na_index = pd.Series(df.index.tolist()).sample(30) # 随机挑选30条数据 df.locna_index, "salary" = pd.NA # 将这30条数据的salary设置为缺失值 print(df.groupby("department_id")"salary".agg("size", "count")) # 查看每组数据总数与非空数据数 def fill_missing(x): # 使用平均值填充,如果平均值也为NaN,用0填充 if np.isnan(x.mean()): return 0 return x.fillna(x.mean()) df"salary" = df.groupby("department_id")"salary".transform(fill_missing) print(df.groupby("department_id")"salary".agg("size", "count")) # 查看每组数据总数与非空数据数 |
- 分组过滤
过滤操作可以让我们按照分组的属性丢弃若干数据。
例如,我们可能只需要保留commission_pct不包含空值的分组的数据。
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python commission_pct_filter = df.groupby("department_id").filter( lambda x: x"commission_pct".notnull().all() ) # 按department_id分组,过滤掉commission_pct包含空值的分组 print(commission_pct_filter) |
3 .8 案例讲解
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python # 导入必要的库 import pandas as pd import numpy as np # 1. 数据加载与初步探索 # 读取企鹅数据集,注意解析日期列(虽然这个数据集没有日期列,但展示 parse_dates 参数的用法) penguins = pd.read_csv('data/penguins.csv') print("数据集前5行:") display(penguins.head()) print("\n数据集信息:") display(penguins.info()) # 2. 数据清洗 # 检查缺失值 print("\n每列的缺失值数量:") print(penguins.isnull().sum()) # 处理缺失值 - 删除含有缺失值的行 penguins_clean = penguins.dropna() print("\n清洗后数据集形状:", penguins_clean.shape) # 3. 数据转换与特征工程 # 将性别列转换为类别类型 penguins_clean'sex' = penguins_clean'sex'.astype('category') print("\n性别列数据类型:", penguins_clean'sex'.dtype) # 创建新特征:喙长与喙深的比值 penguins_clean'bill_ratio' = penguins_clean'bill_length_mm' / penguins_clean'bill_depth_mm' # 4. 数据分析 # 按物种分组计算平均特征值 species_stats = penguins_clean.groupby('species').agg({ 'bill_length_mm': 'mean', 'bill_depth_mm': 'mean', 'flipper_length_mm': 'mean', 'body_mass_g': 'mean', 'bill_ratio': 'mean' }).round(2) print("\n不同物种的平均特征值:") display(species_stats) # 5. 数据分箱 - 将体重分为低、中、高三个等级 labels = '低', '中', '高' penguins_clean'mass_category' = pd.cut(penguins_clean'body_mass_g', bins=3, labels=labels) print("\n体重分箱结果:") display(penguins_clean'mass_category'.value_counts()) # 6. 按岛屿和性别分组分析 island_sex_stats = penguins_clean.groupby('sex').agg({ 'body_mass_g': 'mean', 'count' }) print("\n按性别分组的统计数据:") print(island_sex_stats) |
python
Python
# 导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 设置可视化风格
plt.style.use('seaborn')
sns.set_palette("husl")
# 1. 数据加载与初步探索
# 读取睡眠数据集
sleep_data = pd.read_csv('sleep.csv')
# 显示前5行数据
print("数据集前5行:")
print(sleep_data.head())
# 显示数据集基本信息
print("\n数据集信息:")
print(sleep_data.info())
# 2. 数据清洗与预处理
# 检查缺失值
print("\n每列的缺失值数量:")
print(sleep_data.isnull().sum())
# 如果有缺失值,可以删除或填充
# 这里假设数据已经完整,直接复制
sleep_clean = sleep_data.copy()
# 3. 数据转换与特征工程
# 将性别列转换为类别类型
sleep_clean['gender'] = sleep_clean['gender'].astype('category')
# 分离血压为收缩压和舒张压
sleep_clean[['systolic_bp', 'diastolic_bp']] = sleep_clean['blood_pressure'].str.split('/', expand=True).astype(int)
# 创建睡眠质量分类列
bins = [0, 4, 7, 10]
labels = ['差', '中', '优']
sleep_clean['sleep_quality_category'] = pd.cut(sleep_clean['sleep_quality'], bins=bins, labels=labels)
# 创建年龄分段列
age_bins = [0, 30, 45, 60, 100]
age_labels = ['18-30', '31-45', '46-60', '60+']
sleep_clean['age_group'] = pd.cut(sleep_clean['age'], bins=age_bins, labels=age_labels)
# 4. 基本统计分析
# 描述性统计
print("\n数值变量的描述性统计:")
print(sleep_clean.describe())
# 分类变量统计
print("\n分类变量统计:")
print(sleep_clean['gender'].value_counts())
print("\nBMI类别分布:")
print(sleep_clean['bmi_category'].value_counts())
print("\n睡眠障碍分布:")
print(sleep_clean['sleep_disorder'].value_counts())
# 5. 睡眠质量分析
# 按性别分析平均睡眠时间和质量
gender_stats = sleep_clean.groupby('gender').agg({
'sleep_duration': 'mean',
'sleep_quality': 'mean',
'stress_level': 'mean'
}).round(2)
print("\n按性别分组的睡眠统计:")
print(gender_stats)
# 按BMI类别分析
bmi_stats = sleep_clean.groupby('bmi_category').agg({
'sleep_duration': 'mean',
'sleep_quality': 'mean',
'physical_activity_level': 'mean'
}).round(2)
print("\n按BMI类别分组的睡眠统计:")
print(bmi_stats)
# 6. 睡眠障碍分析
# 有睡眠障碍和无睡眠障碍的比较
disorder_stats = sleep_clean.groupby('sleep_disorder').agg({
'sleep_duration': ['mean', 'count'],
'sleep_quality': 'mean',
'age': 'mean',
'stress_level': 'mean'
}).round(2)
print("\n按睡眠障碍分组的统计:")
print(disorder_stats)
# 7. 相关性分析
# 计算数值变量之间的相关性
correlation = sleep_clean[['sleep_duration', 'sleep_quality', 'age', 'physical_activity_level',
'stress_level', 'heart_rate', 'daily_steps', 'systolic_bp', 'diastolic_bp']].corr()
print("\n变量间相关性矩阵:")
print(correlation)
# 8. 高级分析 - 多因素分组
# 按性别和年龄组分析
gender_age_stats = sleep_clean.groupby(['gender', 'age_group']).agg({
'sleep_duration': 'mean',
'sleep_quality': 'mean',
'stress_level': 'mean'
}).round(2)
print("\n按性别和年龄组分组的统计:")
print(gender_age_stats)
# 按职业和BMI类别分析
occupation_bmi_stats = sleep_clean.groupby(['occupation', 'bmi_category']).agg({
'sleep_duration': 'mean',
'sleep_quality': 'mean'
}).round(2)
print("\n按职业和BMI类别分组的统计:")
print(occupation_bmi_stats)
# 9. 数据可视化
# 设置图形大小
plt.figure(figsize=(15, 10))
# 睡眠质量分布
plt.subplot(2, 2, 1)
sns.histplot(sleep_clean['sleep_quality'], bins=10, kde=True)
plt.title('睡眠质量分布')
plt.xlabel('睡眠质量评分')
plt.ylabel('人数')
# 睡眠持续时间分布
plt.subplot(2, 2, 2)
sns.histplot(sleep_clean['sleep_duration'], bins=10, kde=True)
plt.title('睡眠持续时间分布')
plt.xlabel('睡眠时间(小时)')
plt.ylabel('人数')
# 睡眠质量与压力水平的关系
plt.subplot(2, 2, 3)
sns.scatterplot(x='stress_level', y='sleep_quality', hue='gender', data=sleep_clean)
plt.title('睡眠质量与压力水平的关系')
plt.xlabel('压力水平')
plt.ylabel('睡眠质量')
# 不同BMI类别的平均睡眠质量
plt.subplot(2, 2, 4)
sns.barplot(x='bmi_category', y='sleep_quality', data=sleep_clean, ci=None)
plt.title('不同BMI类别的平均睡眠质量')
plt.xlabel('BMI类别')
plt.ylabel('平均睡眠质量')
plt.tight_layout()
plt.show()
# 10. 更多可视化
plt.figure(figsize=(15, 5))
# 按年龄组的睡眠质量
plt.subplot(1, 2, 1)
sns.boxplot(x='age_group', y='sleep_quality', hue='gender', data=sleep_clean)
plt.title('不同年龄组的睡眠质量')
plt.xlabel('年龄组')
plt.ylabel('睡眠质量')
# 睡眠障碍与睡眠质量的关系
plt.subplot(1, 2, 2)
sns.boxplot(x='sleep_disorder', y='sleep_quality', data=sleep_clean)
plt.title('睡眠障碍与睡眠质量的关系')
plt.xlabel('睡眠障碍类型')
plt.ylabel('睡眠质量')
plt.tight_layout()
plt.show()
# 11. 保存处理后的数据
sleep_clean.to_csv('cleaned_sleep_data.csv', index=False)
print("\n处理后的数据已保存为 cleaned_sleep_data.csv")