文章目录
- [1. 一些概念](#1. 一些概念)
- [2. 主动更新策略/缓存设计模式](#2. 主动更新策略/缓存设计模式)
-
- [2.1 cache-aside pattern(lazy loading)](#2.1 cache-aside pattern(lazy loading))
- [2.2 read-through pattern(针对读操作)](#2.2 read-through pattern(针对读操作))
- [2.3 write-through pattern](#2.3 write-through pattern)
- [2.4 write behind pattern(write back pattern)](#2.4 write behind pattern(write back pattern))
- [2.5 write around pattern](#2.5 write around pattern)
- [2.6 delay double delete](#2.6 delay double delete)
- [2.7 refresh ahead](#2.7 refresh ahead)
- [2.8 总结](#2.8 总结)
-
- [2.8.1 对于读场景](#2.8.1 对于读场景)
- [2.8.2 对于写场景](#2.8.2 对于写场景)
- [2.8.3 因为数据更新而引发的cache更新](#2.8.3 因为数据更新而引发的cache更新)
- [3. 一个cache系统的例子](#3. 一个cache系统的例子)
-
- [3.1 查询数据场景](#3.1 查询数据场景)
- [3.2 更新数据场景(先更新DB,再删除cache,原子操作)](#3.2 更新数据场景(先更新DB,再删除cache,原子操作))
-
- [3.2.1 更新数据库时考虑的问题:](#3.2.1 更新数据库时考虑的问题:)
- [4. 缓存面临的问题](#4. 缓存面临的问题)
-
- [4.1 缓存穿透(cache penetration)](#4.1 缓存穿透(cache penetration))
- [4.2 缓存雪崩(cache avalanche)](#4.2 缓存雪崩(cache avalanche))
- [4.3 缓存击穿(cache breakdown)](#4.3 缓存击穿(cache breakdown))
-
- [4.3.1 如何使用互斥锁来应对缓存击穿问题](#4.3.1 如何使用互斥锁来应对缓存击穿问题)
- [4.3.2 如何使用逻辑过期应对缓存击穿问题](#4.3.2 如何使用逻辑过期应对缓存击穿问题)
- [4.4 缓存系统设计的其他问题](#4.4 缓存系统设计的其他问题)
-
- [4.4.1 读扩散和写扩散问题](#4.4.1 读扩散和写扩散问题)
- [4.4.2 redis热点key问题](#4.4.2 redis热点key问题)
- [4.4.3 一致性问题](#4.4.3 一致性问题)
1. 一些概念
缓存作用:降低后端负载;提高性能,快速响应;注意点:缓存和数据库之间一致性问题;使用缓存需要额外编写代码;缓存需要额外维护。
缓存如何更新:内存淘汰;超时更新;主动更新
-
低一致性数据(不经常变动的数据):内存淘汰
-
高一致性数据(经常变动且准确性要求高的数据):主动更新+超时更新
设计一个缓存系统需要考虑的方面:工作流程的实现(应用层代码);缓存的运维(高可用);缓存层和数据库层的一致性问题;缓存的典型问题及其应对措施。
2. 主动更新策略/缓存设计模式
主动更新是指或者是应用主动更新cache,或者是db变动触发cache更新。常见主动更新的策略/缓存设计模式有:cache aside,read/write through, write back,refresh ahead。
ref: https://hazelcast.com/blog/a-hitchhikers-guide-to-caching-patterns/
2.1 cache-aside pattern(lazy loading)
工作流程:
-
读流程:读cache -> hit则返回,miss则访问DB(读穿透缓存) -> DB返回数据给app,app写cache。注意应用层要分别和cache以及DB交互。
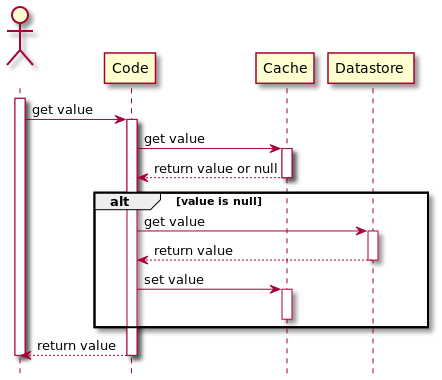
-
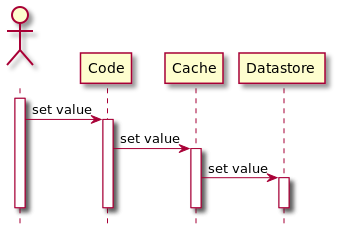
写流程:app先写cache再写DB,或者app先写DB再写cache。不过考虑直接删除缓存更好,参考第3.2节。
优劣势:pros:容易理解和实现;对被高频访问的数据友好。cons:不一致风险;交互环节多(受网络环境影响)。
场景:读密集;通用缓存设计。
2.2 read-through pattern(针对读操作)
工作流程:读cache -> hit则返回,miss则访问DB(读穿透缓存) -> 对于miss数据,由cache而不是app去查DB,DB向cache而不是app返回数据,最后由cache向app返回数据。注意cache和DB封装成一个服务,由这个服务来负责cache和DB的一致性。应用层只需要维护和这个服务的交互(这和cache aside pattern不同)。
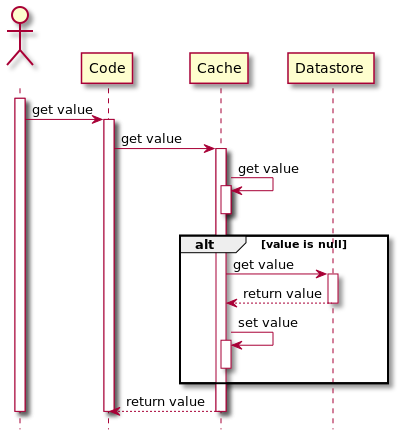
优劣势:pros: 对应用而言,只用和缓存层交互,速度快;读伸缩性好(只用和缓存层交互,缓存层应对高频读请求的良好伸缩性得以体现)。cons: 可能存在数据不一致;cache miss时速度慢。
场景:读密集;可容忍较高cache miss延时。
2.3 write-through pattern
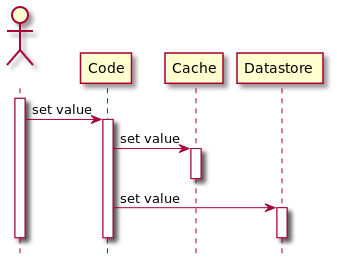
工作流程:应用写cache -> cache 同步地写数据到DB。
优劣势:pros:数据一致性好;读延时低(因为最新的数据总在cache中)。cons:写延时高;写入的数据不一定被高频读,占用cache空间;一致性风险。
场景:低频写操作;程序局部性好(写的数据很快会被访问)。
2.4 write behind pattern(write back pattern)
工作流程:应用写cache -> cache异步地写数据到DB。
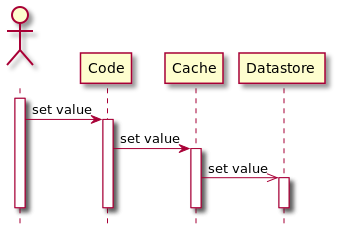
优劣势:pros:低写延时(异步,批量写DB);cons:cache数据可能在变更到DB之前而失效;实现复杂。
场景:写密集;数据改动持久化不那么重要(数据在多次改动期间没有被访问,事实上只有最后一次改动是有意义的,只需要将最后一次改动落实到数据库中);一致性风险。
2.5 write around pattern
工作流程:应用写DB -> 应用读cache,hit则直接返回,miss则读DB --> 应用写cache。注意和cache aside的区别,
优劣势:pros:应用直接写数据到DB,降低cache层数据丢失风险;cons:高读延时;高cache miss rate。
场景:没有数据更新;低频读。
2.6 delay double delete
工作流程:数据即将发生更新时,删除缓存,后续请求直接到数据库;更新数据库;延迟一段时间以便数据库完成更新操作;延迟时间过后再删除缓存(首次删除缓存后,更新数据库之前仍可能有使用数据库旧值的请求,因而旧值缓存被重新建立,需要再次删除)。
场景:读多写少;对数据一致性要求高但允许短暂(延迟时间内)不一致。
2.7 refresh ahead
在请求前将数据库最新的数据缓存起来,即数据库只要更新,不管是否访问,都会为最新的数据创建cache。
cache asdie/read through --> cache invalidation ( set expire time ) --> remove update from app, make it external --> polling db to update cache(增加DB压力) --> DB trigger (由数据库内的事件触发而执行数据库操作,如果要执行redis操作,需要额外的系统调用;没有标准实现) --> change data capture(从mysql的append-only log中提取变化事件)
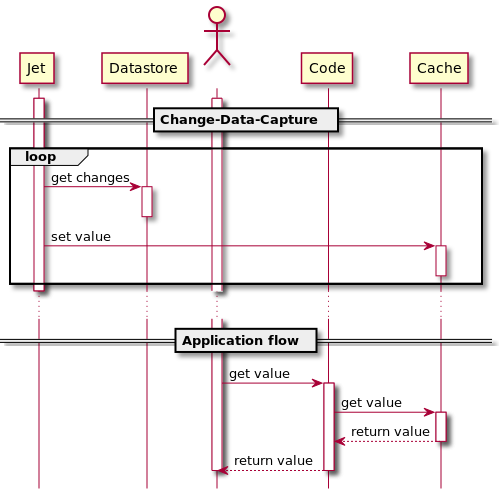
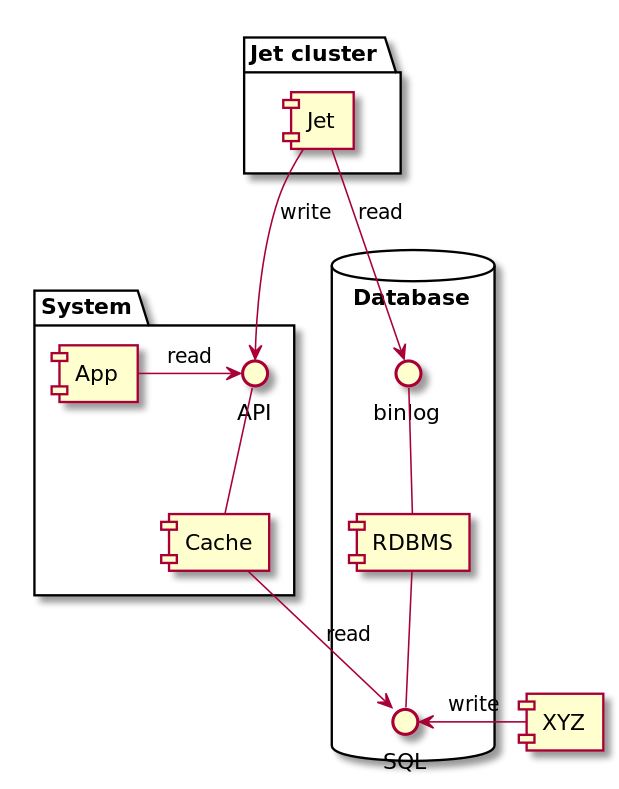
Debezium具备CDC特性,但以kafka为中转(kafka会持久化,有额外的磁盘IO;数据网络流通环节增加,有额外的网络IO),Hazelcast Jet基于Debezium,但可以直接写入cache,避免中转。Hazelcast Jet通过Debezium connector能够读取DB的event,并将其转换为kv格式写入cache。
2.8 总结
2.8.1 对于读场景
- cache aside和read through的区别:cache miss时,需要从DB读数据并写cache,cache aside安排app完成这个任务,read through安排cache完成这个任务。
2.8.2 对于写场景
-
cache aside,write through, write behind,write behind,write around的区别:cache aside,write through和write behind都是将要更新的数据写入cache,在由cache同步数据到DB,write around是将要更新的数据先写入数据库,再更新cache。
-
write through, write behind的区别:对于cache数据更新到DB的任务,write through使用同步方式,write behind使用异步方式
2.8.3 因为数据更新而引发的cache更新
考虑到查询cache miss也会重建cache,因而往往考虑更新完DB就删除cache。参考3.2节。
3. 一个cache系统的例子
将以cache aside模式为例,这是实际项目中经常使用的模式。后续介绍三大缓存问题的实例都以cache aside为基础。
3.1 查询数据场景
python
def get_data(key):
result = None
# None means cache missing, {'key':'xxx', 'value': 'xxx'} means regular cache
cache_result = get_data_cache(key)
if cache_result:
result = cache_result['value']
return result
# cache missing
db_result = get_data_db(key) # db_result=None means data does not exist
if db_result:
result = db_result['value']
set_cache(key, result, ex=300)
return result3.2 更新数据场景(先更新DB,再删除cache,原子操作)
3.2.1 更新数据库时考虑的问题:
- 更新数据库时选择删除缓存还是更新缓存?(删除缓存)
- 如果多次更新数据库的期间没有查询操作,那么每次更新缓存没有意义;而采取删除缓存策略,则第一次更新数据库就删掉缓存,后续操作都不用再操作缓存,直到下一次查询才创建缓存。
- 如何保证更新数据库和删除缓存同时成功同时失败?(原子操作)
- 把更新数据库和删除缓存操作打包为原子操作。单体服务中可以使用进程级,线程级,协程级锁来实现,分布式服务则采用分布式事务方案(TCC)
- 保证更新数据库和删除缓存操作的原子性,使用锁构建临界区:多线程(线程锁 threading.Lock),多进程(锁multiprocessing.Lock,带锁的数据结构multiprocessing.Value等,信号量multiprocessing.Semaphore),协程(asyncio.Lock)。
- 先操作数据库还是先删除缓存?(先更新数据库再删除缓存)
- 先删缓存在更新数据库的不一致情形:线程1先删除缓存,并发执行的线程2查缓存不存在,用数据库旧值创建缓存,随后线程1再执行更新数据库,此时数据库中为新值而缓存中为旧值。注意线程1的更新数据库操作是相对复杂缓慢,很有可能插入线程2的操作,因此该策略下数据不一致的情形发生概率很高。
- 先更新数据库再删缓存的不一致情形:假设缓存失效,线程1查询缓存不命中而查数据库得到旧值,线程2再更新数据库为新值,然后再删除缓存(缓存本来就失效,相当于空操作),最后线程1使用旧值创建缓存。于是缓存为旧值,数据库为新值。注意线程1查询数据库再到更新缓存是相对简单高效的,在这两个操作极短的间隔内完成数据库更新操作概率很小,并且这个数据不一致情况要求事先缓存失效。
python
# cahce aside
def update_data(item, lock):
if not is_validate(item):
return False, 'fail to update data!'
with lock:
set_data_db(item)
del_data_cache(key=item['id'])
return True, 'update successfully!'4. 缓存面临的问题
4.1 缓存穿透(cache penetration)
数据既不在缓冲中也不在数据库中,请求到达数据库而增大数据库压力。
- 缓存空对象:如果访问缓存没有,数据库也没有,则创建一个空缓存(设置较短的ttl,以防大量空缓存占用内存)。实际开发中主要使用此方法。实现简单,但有一定内存开销。注意如果缓存命中,还要有判空逻辑。
- 布隆过滤:在应用和缓存之间加一层缓存,称为布隆过滤。布隆过滤判断不存在则直接返回,布隆过滤判断存在则继续访问缓存,访问数据库,尽管数据也可能在缓存和数据库中都不存在。内存占用小但是实现复杂(可以使用redis的bitmap数据结构实现)且仍可能存在缓存穿透。
- key的设计:增强key复杂度;增加key的格式校验过滤环节
- key的访问:加强用户权限校验;热点数据限流
python
# cache-aside + cache penetration prevention
def get_data(key):
result = None
# None means cache missing, {'key':'xxx', 'value': 'xxx'} means regular cache, {'key':'key', 'value': None} means null cache
cache_result = get_data_cache(key)
if cache_result:
result = cache_result['value']
return result
# cache missing
db_result = get_data_db(key)
if db_result:
result = db_result['value']
set_data_cache(key, result, ex=300)
return result4.2 缓存雪崩(cache avalanche)
同一时段大量key过期(部分key失效),或者redis服务宕机(全部key失效),则大量数据访问请求到达数据库,数据库压力增大。
- 给不同key添加随机ttl。
- 流量控制:熔断、限流策略;业务配置多级缓存截留(浏览器 -> nginx -> redis -> jvm -> DB)。
- 利用redis集群实现高可用,防止服务宕机带来缓存雪崩问题。
4.3 缓存击穿(cache breakdown)
也被称为热点key问题。热点key失效,导致并发数据请求到达数据库层,导致数据库执行缓慢甚至崩溃。
- 互斥锁确保只有一个线程重建热点key缓存:对重建这种key的缓存的操作加上互斥锁,只有拿到锁的线程才能去重建它。具体过程:查询缓存未命中 --> 申请互斥锁 --> 获得锁的线程执行key缓存重建操作 --> 释放锁,其他线程查询缓存未命中 --> 申请互斥锁失败 --> 等待一会儿重新查询缓存。该方案一致性好,实现简单,没有额外内存开销,但并发性能差。
- 逻辑过期:对于热点key不在设置过期时间,而是加上过期字段。线程1查询热点key根据过期字段发现过期,于是申请并得到互斥锁后开启线程2来独立地执行热点key更新操作(该线程更新完毕后会释放互斥锁),线程1随后返回旧的缓存值。线程2还未执行完毕,线程3访问热点key缓存,发现过期,申请互斥锁失败(说明有人在更新热点key缓存了),返回旧的缓存值。该方案并发性能好,但是实现复杂,有额外内存开销,一致性差。
- 热点key过期时间:不过期;续期。
- 多级缓存:通过本地缓存,api网关缓存来减少对服务端缓存的依赖。
4.3.1 如何使用互斥锁来应对缓存击穿问题
使用redis中setnx命令(如果key不存在才执行成功,key存在的话则执行失败),多个线程同时执行setnx,只有第一个执行的线程能够执行成功,其他线程都执行失败,这可以模拟获取互斥锁。使用del来实现释放锁。注意给互斥锁添加过期时间,避免释放锁出问题而一致不释放锁。
python
# cache-aside + cache penetration prevention + cache breakdown prevention
def request_mutex_lock(key):
# 互斥锁过期时间300s,以防持有者不释放锁导致死锁
result = redis_client.SETNX(key, 1, ex=600)
return result
def release_mutex_lock(key):
redis_client.DEL(key)
def get_data(key):
result = None
# None means cache missing, {'key':'xxx', 'value': 'xxx'} means regular cache, {'key':'key', 'value': None} means null cache
cache_result = get_data_cache(key)
if cache_result:
result = cache_result['value']
return result
# cache missing
mutex_lock = request_mutex_lock(key) # rebuild key needing lock first
if mutex_lock == 0:
# fail to get mutex lock, wait a while and retry
time.sleep(0.1)
return get_data(key)
# rebuild cache
db_result = get_data_db(key)
if db_result:
result = db_result['value']
set_data_cache(key, result, ex=300)
release_mutext_lock(key)
return result4.3.2 如何使用逻辑过期应对缓存击穿问题
创建key时不用设置过期时间,依赖value中中ex字段来判断是否过期。
python
# cache-aside + cache penetration prevention + cache breakdown prevention
def request_mutex_lock(key):
# 互斥锁过期时间300s,以防持有者不释放锁导致死锁
result = redis_client.SETNX(key, 1, ex=600)
return result
def release_mutex_lock(key):
redis_client.DEL(key)
def rebuild_cache(key):
db_result = get_data_db(key)
if db_result:
result = db_result['value']
set_data_cache(key, result) # 不再设置key的ex,依赖逻辑ex
release_mutext_lock(key)
def get_data(key):
result = None
# None means cache missing, {'key':'xxx', 'value': 'xxx'} means regular cache, {'key':'key', 'value': None} means null cache
cache_result = get_data_cache(key)
result = cache_result['value']
ex = cache_result['ex']
if ex <= time.now():
return result
# cache missing
mutex_lock = request_mutex_lock(key) # rebuild key needing lock first
if mutex_lock == 0:
# fail to get mutex lock, wait a while and retry
return result
# rebuild cache
thread_pool.submit(rebuild_cache(key))
return result4.4 缓存系统设计的其他问题
4.4.1 读扩散和写扩散问题
- 读扩散:数据更新后还没同步到其他结点,读出来的是旧值。本质是数据复制延迟带来不一致。
- 写扩散:数据更新后同步到其他结点的过程。本质是通过冗余写换取读性能提升。
4.4.2 redis热点key问题
- 识别:INFO命令;redis 监控工具
- 解决:让hot key使用更合适的数据结构(hot key有序存多个元素,考虑使用sorted set而不是list);压缩值降低网络带宽压力;使用客户端侧缓存;服务端使用redis + mencached;
- ref: https://abhivendrasingh.medium.com/understanding-and-solving-hotkey-and-bigkey-and-issues-in-redis-1198f98b17a5
4.4.3 一致性问题
单体架构下cache和DB一致性问题: 传统缓存设计模式无法保证一致性。要保证一致性只能加锁(做成读者-写者模型)。
分布式架构下cache和DB一致性问题:分布式锁;CDC