基于 Spring AI 和 Redis 向量库的智能对话系统实践
在当前大模型技术飞速发展的背景下,构建一个功能强大、可扩展的 AI 助手系统成为许多开发者的目标。本文将分享我们基于 Spring AI 框架,结合 Redis 作为向量数据库,实现的一个多模态、支持文档检索与文件上传的智能对话系统。系统具备图片识别、文件解析、中英文翻译、深度思考等核心能力,并实现了灵活的多模型管理和切换。
界面预览
技术架构概览
整个系统采用前后端分离架构,后端基于 Spring Boot + Spring AI 构建,前端为简洁的 Web 界面。核心技术栈如下:
- 核心框架 :
Spring AI- 提供了与大语言模型(LLM)交互的标准化接口。 - 向量数据库 :
Redis(通过spring-ai-redis实现) - 用于存储和检索文档的嵌入向量(Embeddings),实现基于内容的语义搜索。 - 模型服务: 自行部署的 Qwen 大模型(通过 vLLM 推理服务),以及阿里百炼提供的视觉模型和向量模型。
- 文件处理: 使用 Apache Tika 解析多种格式的文档(PDF, Word, PPT 等),并利用 OCR 技术处理图片中的文字。
- 通信协议 : 使用
SSE (Server-Sent Events)实现流式响应,提供流畅的聊天体验。 - 状态管理: 利用 Redis 缓存会话记忆和图片识别结果,提升性能。
核心功能实现
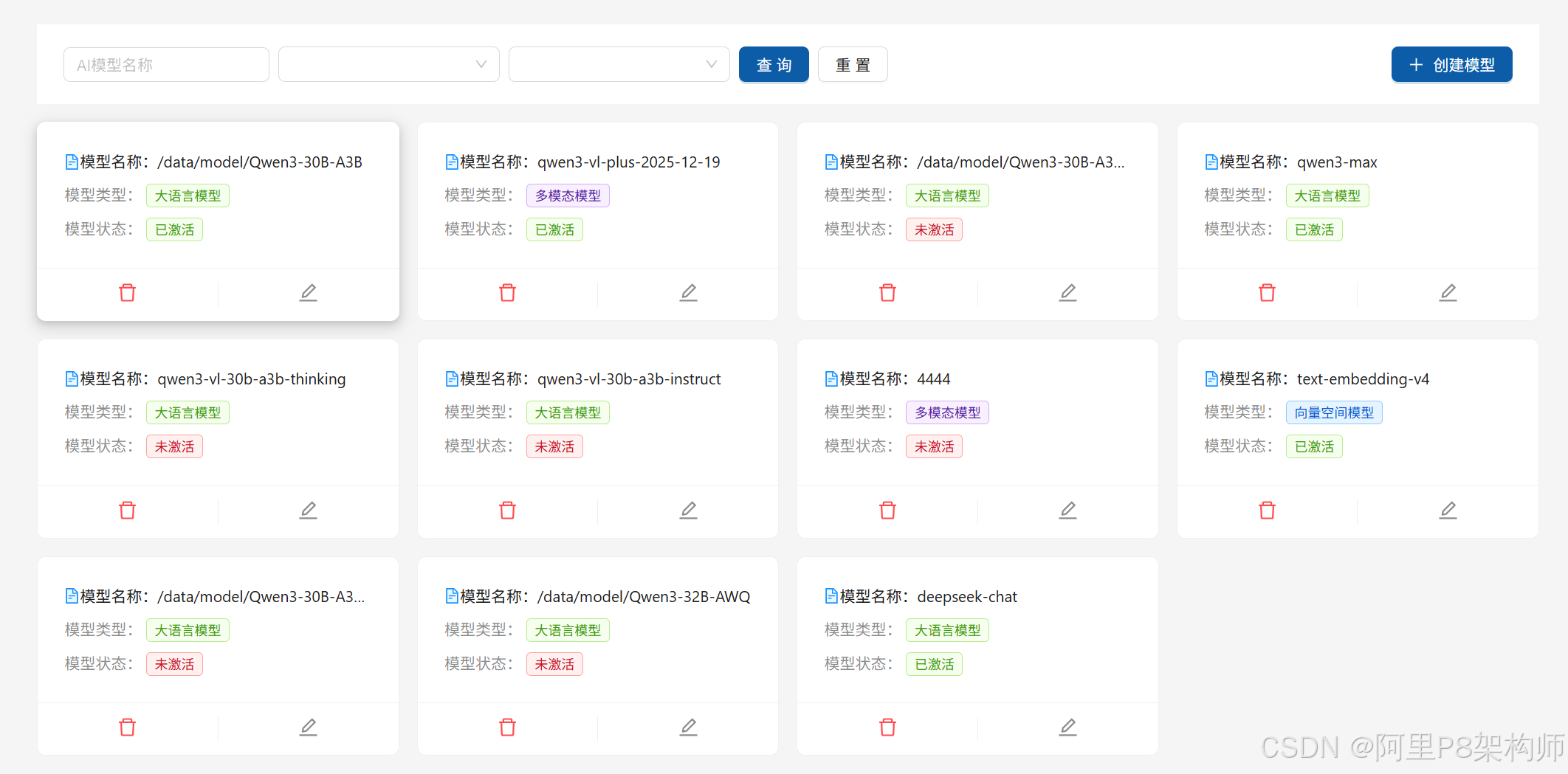
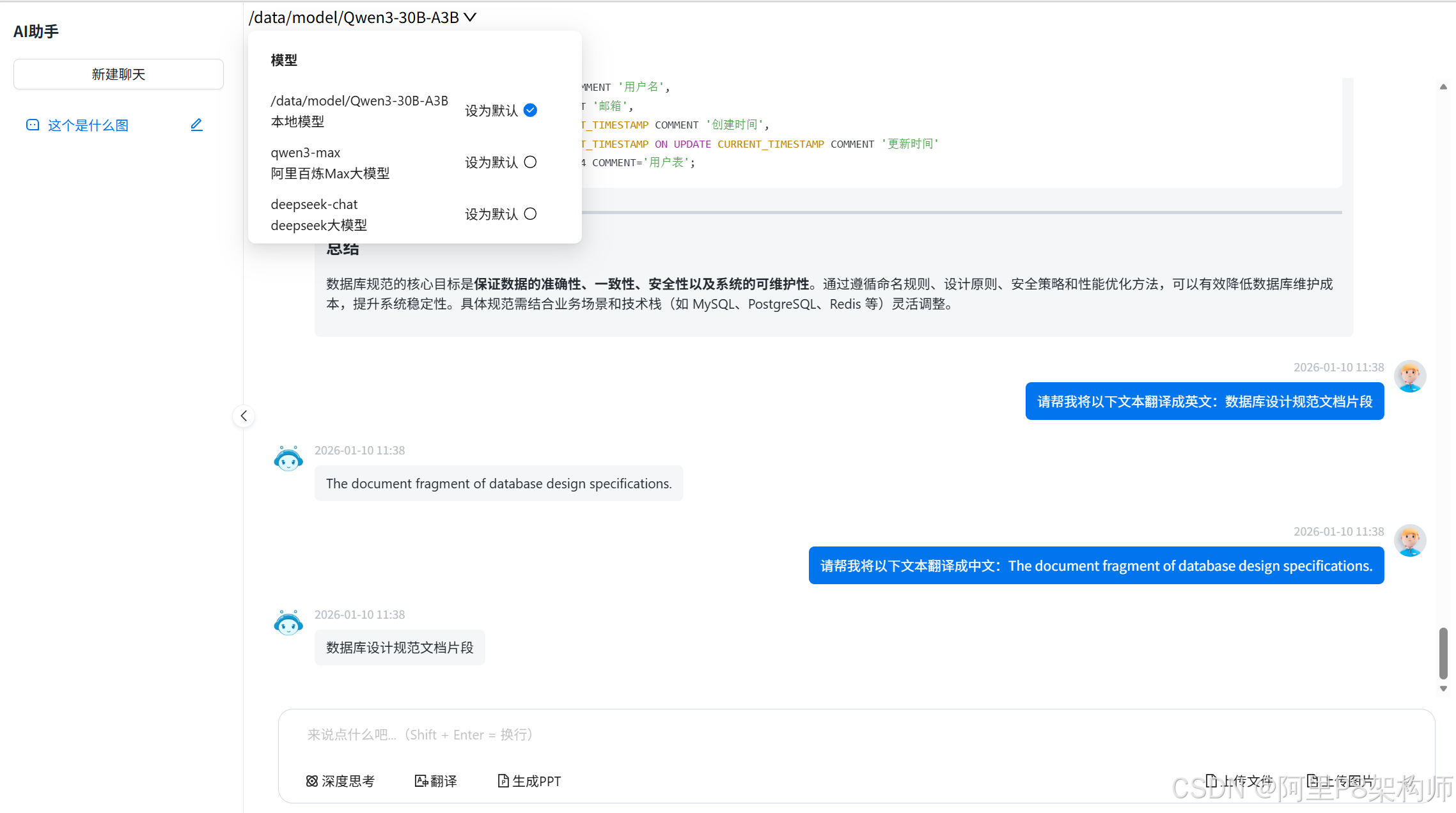
1. 多模型管理与切换
系统支持管理多个不同类型的 AI 模型,并允许用户在聊天过程中自由切换。
// 在配置界面展示所有模型
@GetMapping("/models")
public List<ModelVO> listModels() {
return modelService.listByCondition(new ModelQuery());
}用户可以通过下拉菜单选择不同的模型进行对话,如 /data/model/Qwen3-30B-A3B(本地大模型)、qwen3-max(阿里百炼Max大模型)等。
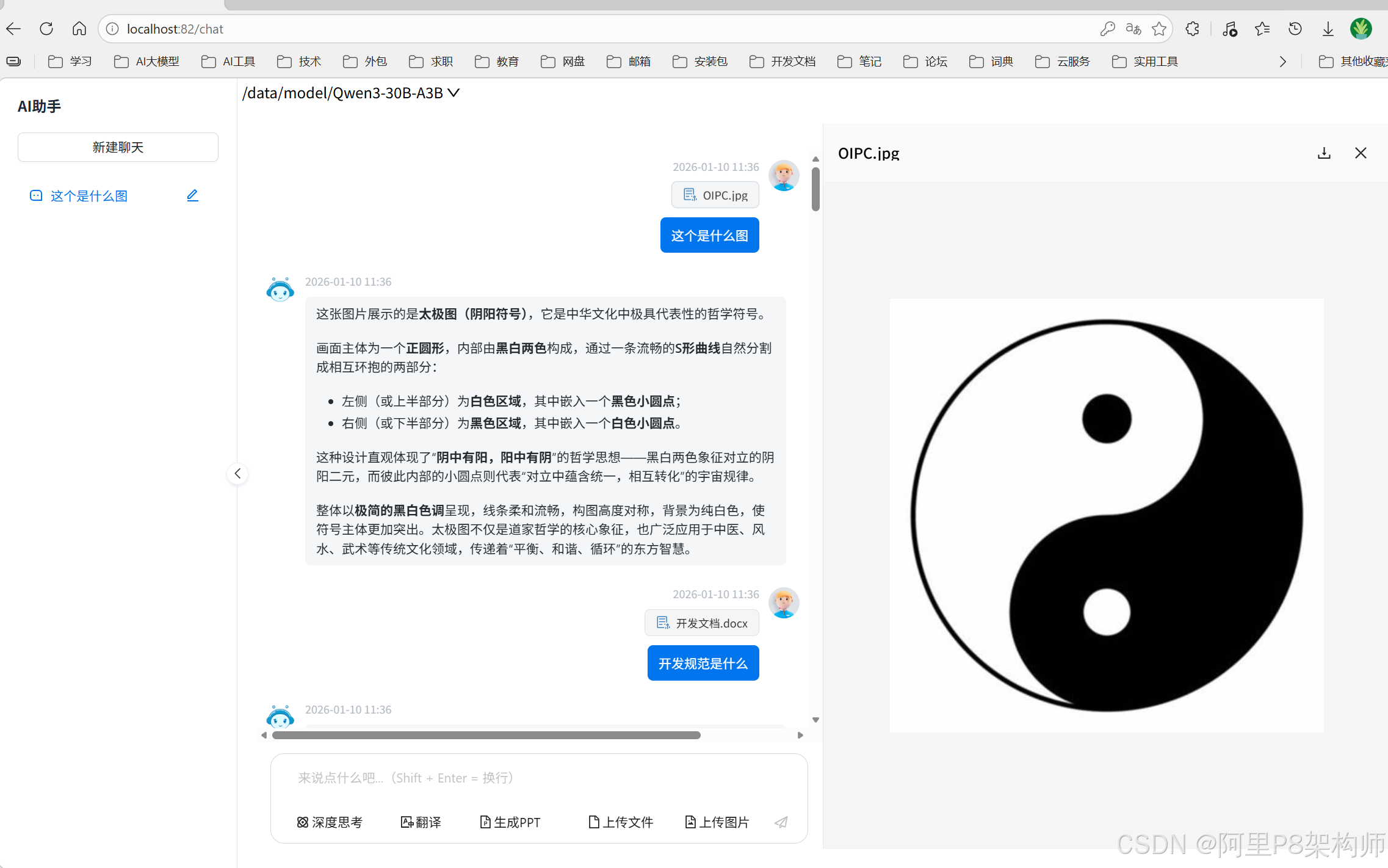
2. 图片与文件上传预览及提问
系统支持用户上传图片和文件,并能对其进行分析和问答。
图片识别
当用户上传图片时,系统会自动调用多模态模型(Multi-Modal Model)来识别图片内容,并将其描述文本作为上下文传递给主语言模型。
/**
* 处理图片:调用多模态模型识别图片内容
*/
private String processImagesWithMultiModal(List<String> fileUrls, String conversationId) {
if (CollectionUtils.isEmpty(fileUrls)) {
return "没有找到图片文件";
}
// 分类文件,只处理图片
FileClassificationResult classification = classifyFiles(fileUrls);
List<String> imageUrls = classification.getImageUrls();
if (imageUrls.isEmpty()) {
return "";
}
// 获取可用的多模态模型
AiModel multiModalModel = getMultiModalModel();
if (multiModalModel == null) {
log.warn("未找到可用的多模态模型,跳过图片识别");
return "未找到可用的多模态模型";
}
StringBuilder imageDescriptions = new StringBuilder();
AIParams multiModalParams = mergeParams(multiModalModel, null);
for (int i = 0; i < imageUrls.size(); i++) {
String imageUrl = imageUrls.get(i);
try {
// 使用 Redis 缓存图片识别结果,避免重复请求
String cacheKey = IMAGE_CACHE_PREFIX + conversationId + ":" + extractFileNameFromUrl(imageUrl);
String cachedDescription = stringRedisTemplate.opsForValue().get(cacheKey);
if (StrUtil.isNotBlank(cachedDescription)) {
imageDescriptions.append("图片").append(i + 1).append(": ");
imageDescriptions.append(cachedDescription);
} else {
// 调用多模态模型进行识别
byte[] imageBytes = ossService.readBytes(imageUrl);
UserMessage visionMessage = UserMessage.builder()
.text("请描述这张图片的内容。")
.media(new Media(MimeTypeUtils.IMAGE_PNG, new ByteArrayResource(imageBytes)))
.build();
String imageDescription = llmHandler.blockChatWithVision(visionMessage, multiModalParams);
// 将结果缓存到 Redis(5分钟有效)
stringRedisTemplate.opsForValue().set(cacheKey, imageDescription, 5, TimeUnit.HOURS);
imageDescriptions.append("图片").append(i + 1).append(": ");
imageDescriptions.append(imageDescription.trim()).append("\n");
}
} catch (Exception e) {
log.error("图片识别失败: {}", imageUrl, e);
String fileName = extractFileNameFromUrl(imageUrl);
imageDescriptions.append("图片").append(i + 1).append(": ").append(fileName).append("\n");
}
}
return imageDescriptions.toString();
}3. 文档上传与向量化
用户可以上传 PDF、Word 等文档,系统会使用 Tika 工具解析其内容,并将其分块后转换为向量,存储到 Redis 向量库中。
@PostMapping(value = "/tikaParseEmbeddingFileSse", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public SseEmitter tikaParseEmbeddingFileSse(@RequestPart("file") MultipartFile file) {
AssertUtil.notNull(file, "请上传文件");
String filename = file.getOriginalFilename();
AssertUtil.notNull(filename, "请上传文件");
// 区分图片和普通文件
String fileSuffix = filename.substring(filename.lastIndexOf(".") + 1);
if (fileSuffix.equals("jpg") || fileSuffix.equals("png") || fileSuffix.equals("jpeg")) {
return embeddingFileService.ocrImage(file); // 图片使用OCR
} else {
return embeddingFileService.tikaParseEmbeddingFileSse(file); // 其他文件使用Tika解析
}
}embeddingFileService 内部会调用 documentParseService 解析文件,并最终调用 llmHandler.vectorizeAndStore() 方法将文本内容向量化并存入 Redis。
4. 基于文档的智能问答
当用户提出问题时,系统会先从 Redis 向量库中检索与问题最相关的文档片段,然后将这些片段作为上下文,连同用户的问题一起发送给 LLM 进行回答。
/**
* 检索最相关的文档
*/
public List<Document> retrieveRelevantDocuments(String query, List<String> documentIds, AIParams params) {
RedisVectorStore vectorStore = getInitializedVectorStore(params);
// 构建过滤器,只检索指定文档ID的内容
Filter.Expression filter = null;
if (!documentIds.isEmpty()) {
filter = VectorFilterBuilder.buildDocumentIdFilter(documentIds);
}
SearchRequest request = SearchRequest.builder()
.query(query)
.topK(20) // 返回前20个最相关的文档
.similarityThreshold(0.5) // 相似度阈值
.filterExpression(filter)
.build();
List<Document> documents = vectorStore.similaritySearch(request);
// 进一步过滤确保返回的文档属于目标列表
return documents.stream()
.filter(doc -> documentIds.contains(doc.getMetadata().get("document_id")))
.collect(Collectors.toList());
}5. 流式对话与深度思考
系统使用 SSE 实现流式输出,用户可以实时看到 AI 的生成过程。同时,支持"深度思考"模式,让 AI 在回答前进行更深入的推理。
public void streamChatSse(String systemMsg, UserMessage message, String conversationId, Boolean enableThinking, AIParams params, SseEmitter emitter) {
// ... 参数校验 ...
AiModelOptions modelOptions = params.toModelOptions();
ChatModel chatModel = AiModelFactory.createStreamingChatModel(modelOptions);
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(
new SimpleLoggerAdvisor(),
new MessageChatMemoryAdvisor(chatMemory) // 记住聊天历史
).build();
// 设置会话 ID,用于在 Redis 中存储聊天记忆
Integer userId = Objects.requireNonNull(UserUtil.getUser()).getId();
String memoryIdWithUserId = userId + ":u:" + conversationId;
Prompt prompt = new Prompt(message);
prompt.setEnableThinking(enableThinking); // 开启深度思考
Disposable disposable = chatClient.prompt(prompt)
.advisors(a -> a.param(CHAT_MEMORY_CONVERSATION_ID_KEY, memoryIdWithUserId))
.system(systemMsg)
.stream()
.content()
.takeWhile(chunk -> !chatSessionHandler.isCancelled(conversationId))
.doOnNext(chunk -> {
try {
MessageData messageData = new MessageData();
messageData.setMessage(chunk);
emitter.send(SseEmitter.event().data(SseResponse.chunk(conversationId, messageData)));
} catch (IOException e) {
emitter.completeWithError(e);
}
})
.doOnComplete(() -> {
try {
emitter.send(SseEmitter.event().data(SseResponse.end()));
emitter.complete();
} catch (IOException e) {
emitter.completeWithError(e);
}
})
.doOnError(error -> {
try {
emitter.send(SseEmitter.event().data(SseResponse.error("服务端错误: " + error.getMessage())));
} catch (Exception ex) {
log.error("发送错误事件失败", ex);
}
emitter.completeWithError(error);
})
.subscribe();
chatSessionHandler.registerSession(conversationId, disposable, emitter);
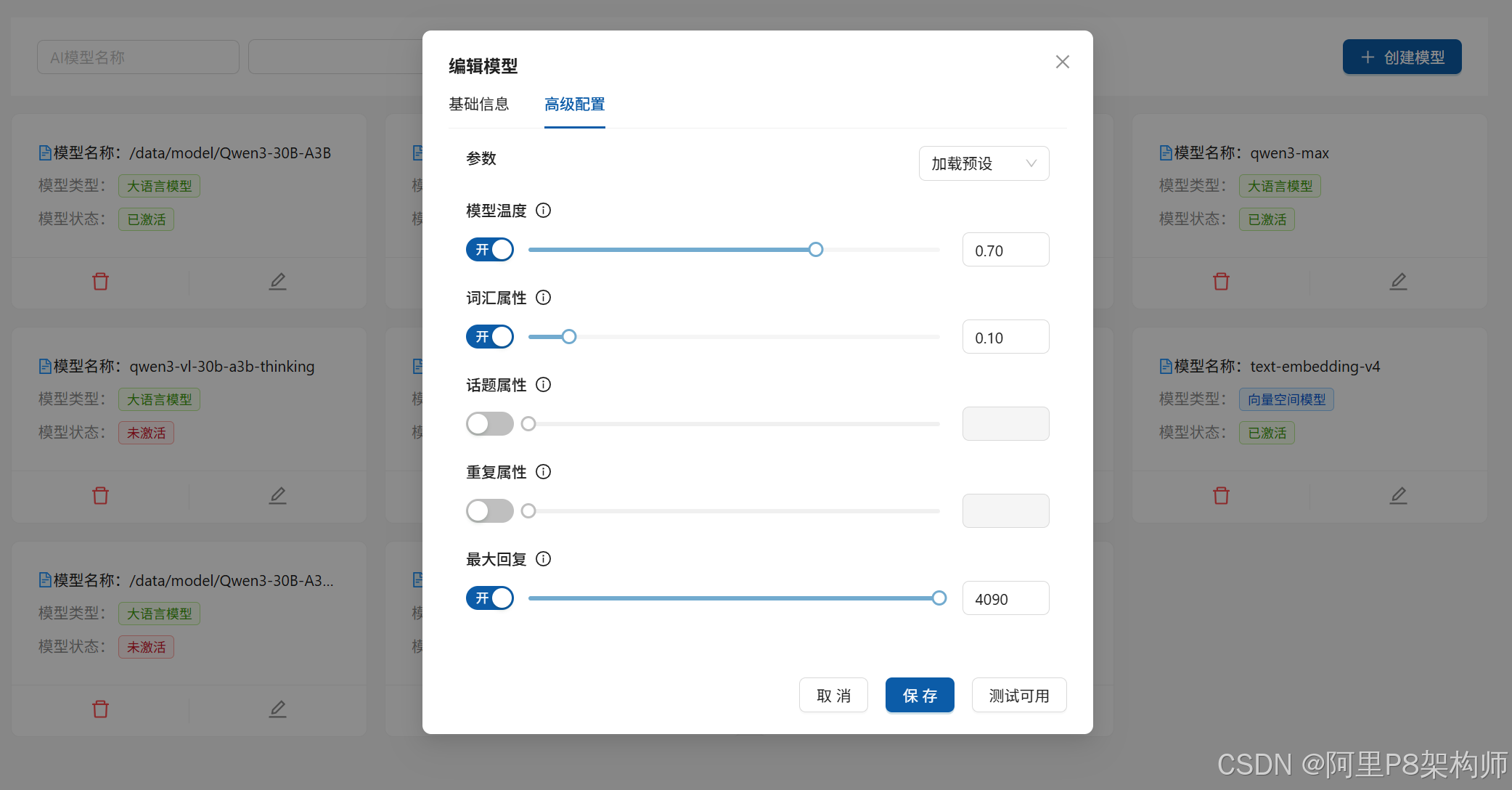
}6. 翻译与深度思考功能
系统内置了简单的翻译功能,可以快速将中文翻译成英文,反之亦然。
// 在前端页面上,用户可以选择"翻译"按钮
// 系统会调用类似以下逻辑
if (requestType.equals("translate")) {
String result = translate(text, sourceLang, targetLang);
return result;
}"深度思考"功能则通过设置 enableThinking=true 来触发,这会改变 LLM 的行为,使其在生成答案前进行更长时间的内部推理。
关键代码解析
AIChatHandler 类
AIChatHandler 是核心业务逻辑处理类,负责协调各个服务。
mergeParams: 合并全局模型参数和具体对话的参数,确保配置正确。streamChatSse: 主要的流式聊天入口,支持传入文档ID和文件URL。processImagesWithMultiModal: 调用多模态模型识别图片内容。buildDocumentContextSafely: 从向量库检索相关文档内容。buildUserMessageWithFiles: 构建包含文件信息的用户消息。
LLMHandler 类
LLMHandler 是与 Spring AI 框架交互的桥梁。
blockChat: 阻塞式调用 LLM。blockChatWithVision: 支持图片输入的阻塞式调用。streamChatSse: 实现流式对话的核心方法。vectorizeAndStore: 将文本内容向量化并存储到 Redis。retrieveRelevantDocuments: 从 Redis 向量库检索相关文档。
总结与展望
本项目成功构建了一个功能全面的智能对话系统,充分利用了 Spring AI 的强大能力和 Redis 作为向量数据库的高效性。系统不仅支持基础的文本聊天,还集成了图片识别、文档解析、语义检索等高级功能,极大地提升了用户体验。
未来可以进一步优化的方向包括:
- 引入 RAG(检索增强生成):更精细地控制检索和生成的流程。
- 增加工具调用(Tool Calling):让 AI 能够调用外部 API 完成复杂任务。
- 优化向量存储:探索更高效的向量索引算法。
- 增强安全与权限控制:对敏感数据和操作进行更严格的保护。
通过不断迭代和优化,这样的 AI 助手系统将成为企业知识管理、客户服务和个人学习的强大工具。