
深度解析TorchVision_Maskrcnn:基于PyTorch的实例分割实战指南
- 技术背景与核心原理
-
-
- [Mask R-CNN架构解析](#Mask R-CNN架构解析)
- 项目特点
-
- 完整实战流程
- 关键技术挑战与解决方案
-
-
- [1. GPU内存不足问题](#1. GPU内存不足问题)
- [2. 多GPU训练问题](#2. 多GPU训练问题)
- [3. COCO评估接口问题](#3. COCO评估接口问题)
-
- 性能优化技巧
- 学术研究与扩展阅读
- 项目应用与展望
实例分割是计算机视觉领域的重要任务,它不仅要检测图像中的每个目标,还要精确描绘出每个目标的轮廓。本文将全面剖析一个基于PyTorch TorchVision实现的Mask R-CNN项目------TorchVision_Maskrcnn,从原理到实战应用,为读者提供一份详尽的实例分割技术指南。
技术背景与核心原理
Mask R-CNN架构解析
Mask R-CNN是在Faster R-CNN基础上发展而来的两阶段实例分割算法,其核心创新点包括:
- RoIAlign层:解决了Faster R-CNN中RoIPooling的量化误差问题,实现了更精确的特征对齐
- 并行预测分支:在原有边界框回归和分类分支基础上,新增了掩码预测分支
- 全卷积网络设计:掩码预测采用FCN结构,保持了空间信息
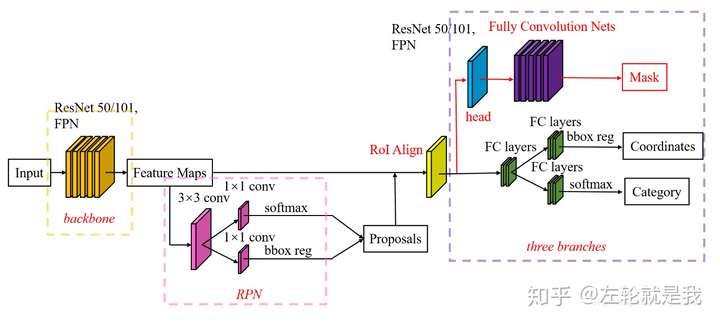
图:Mask R-CNN网络架构示意图(图片来源:知乎)
项目特点
TorchVision_Maskrcnn项目具有以下显著特点:
- 轻量级实现:基于PyTorch官方TorchVision库,无需从头实现
- 迁移学习支持:提供预训练模型微调方案
- 实战导向:包含完整的数据准备、模型训练和优化流程
- 资源友好:针对普通GPU(如GTX1660)进行了优化适配
完整实战流程
环境准备
硬件要求
- GPU:推荐NVIDIA显卡(显存≥6GB)
- CPU:支持AVX指令集
- 内存:建议≥8GB
软件依赖
bash
conda create -n maskrcnn python=3.7
conda activate maskrcnn
pip install torch torchvision opencv-python labelme pycocotools数据准备与标注
1. 图像采集
建议使用多样化场景的图像数据,每类至少200-300张样本。可使用批量下载工具:
python
# 示例:使用ImageCyborg API下载图像
import requests
url = "https://imagecyborg.com/api/download"
params = {
"query": "street cars",
"count": 100
}
response = requests.get(url, params=params)2. 数据标注
使用LabelMe进行实例级标注:
bash
labelme # 启动标注工具标注完成后,目录结构应如下:
dataset/
├── img1.jpg
├── img1.json
├── img2.jpg
└── img2.json3. 数据格式转换
项目提供了转换脚本:
python
python new_json_to_dataset.py /path/to/labelme/data
python copy.py关键修改点:
python
# 在new_json_to_dataset.py中定义类别映射
NAME_LABEL_MAP = {
'_background_': 0,
"car": 1,
"person": 2
}模型构建与训练
1. 模型初始化
python
import torchvision
from torchvision.models.detection import maskrcnn_resnet50_fpn
# 加载预训练模型
model = maskrcnn_resnet50_fpn(pretrained=True)
# 冻结骨干网络参数
for param in model.parameters():
param.requires_grad = False
# 修改预测头
num_classes = 3 # 包括背景
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
model.roi_heads.mask_predictor = MaskRCNNPredictor(in_features_mask, 256, num_classes)2. 数据加载器配置
python
from torchvision.transforms import functional as F
class CustomDataset(torch.utils.data.Dataset):
def __init__(self, root, transforms=None):
self.root = root
self.transforms = transforms
self.imgs = list(sorted(os.listdir(os.path.join(root, "PNGImages"))))
self.masks = list(sorted(os.listdir(os.path.join(root, "PedMasks"))))
def __getitem__(self, idx):
img_path = os.path.join(self.root, "PNGImages", self.imgs[idx])
mask_path = os.path.join(self.root, "PedMasks", self.masks[idx])
img = Image.open(img_path).convert("RGB")
mask = Image.open(mask_path)
mask = np.array(mask)
# 实例编码处理
obj_ids = np.unique(mask)
obj_ids = obj_ids[1:] # 去除背景
masks = mask == obj_ids[:, None, None]
# 边界框计算
boxes = []
for i in range(len(obj_ids)):
pos = np.where(masks[i])
xmin = np.min(pos[1])
xmax = np.max(pos[1])
ymin = np.min(pos[0])
ymax = np.max(pos[0])
boxes.append([xmin, ymin, xmax, ymax])
# 转换为Tensor
boxes = torch.as_tensor(boxes, dtype=torch.float32)
labels = torch.ones((len(obj_ids),), dtype=torch.int64)
masks = torch.as_tensor(masks, dtype=torch.uint8)
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["masks"] = masks
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target3. 训练优化策略
python
# 优化器配置
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005)
# 学习率调度器
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)
# 训练循环
for epoch in range(10):
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)
lr_scheduler.step()
evaluate(model, data_loader_test, device=device)关键技术挑战与解决方案
1. GPU内存不足问题
现象:训练过程中出现CUDA out of memory错误
解决方案:
-
减小batch_size(建议从1开始尝试)
-
使用梯度累积:
pythonoptimizer.zero_grad() for i, (images, targets) in enumerate(data_loader): loss_dict = model(images, targets) losses = sum(loss for loss in loss_dict.values()) losses.backward() if (i+1) % 4 == 0: # 每4个batch更新一次 optimizer.step() optimizer.zero_grad() -
使用混合精度训练:
pythonfrom torch.cuda.amp import autocast, GradScaler scaler = GradScaler() with autocast(): loss_dict = model(images, targets)
2. 多GPU训练问题
现象:在Windows上多GPU训练失败
解决方案:
-
使用单GPU训练:
pythonmodel = model.to('cuda:0') -
Linux下可尝试DataParallel:
pythonmodel = torch.nn.DataParallel(model)
3. COCO评估接口问题
现象 :出现TypeError: object of type <class 'numpy.float64'> cannot be safely interpreted as an integer
解决方案 :
修改cocoeval.py文件:
python
# 原代码
self.iouThrs = np.linspace(.5, 0.95, np.round((0.95 - .5) / .05) + 1, endpoint=True)
# 修改为
self.iouThrs = np.linspace(.5, 0.95, int(np.round((0.95 - .5) / .05) + 1), endpoint=True)性能优化技巧
-
骨干网络替换:对于移动端部署,可将ResNet替换为MobileNetV2:
pythonbackbone = torchvision.models.mobilenet_v2(pretrained=True).features backbone.out_channels = 1280 model = MaskRCNN(backbone, num_classes=2) -
锚框配置优化:根据目标尺寸调整anchor生成器:
pythonanchor_sizes = ((32,), (64,), (128,), (256,), (512,)) # 针对小目标检测 aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes) -
RoIAlign参数调优:
pythonroi_pooler = MultiScaleRoIAlign( featmap_names=['0', '1', '2', '3'], # 使用更多特征层 output_size=7, sampling_ratio=4 # 提高采样率 )
学术研究与扩展阅读
关键论文
-
Faster R-CNN:
- Ren S, et al. "Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks." NeurIPS 2015
-
Mask R-CNN:
- He K, et al. "Mask R-CNN." ICCV 2017
-
RoIAlign改进:
- Dai J, et al. "Deformable Convolutional Networks." ICCV 2017
最新进展
- PointRend:将图像分割视为渲染问题,实现更精确的边缘分割
- CondInst:条件卷积实现实例分割,避免显式的RoI操作
- SOLOv2:基于实例掩码的直接预测框架
项目应用与展望
TorchVision_Maskrcnn项目可应用于多个实际场景:
- 医学影像分析:细胞实例分割
- 自动驾驶:道路场景理解
- 工业检测:缺陷定位与分割
- 增强现实:实时对象分割与替换
未来发展方向包括:
- 模型轻量化(知识蒸馏、量化)
- 实时性优化(TensorRT加速)
- 半监督学习(减少标注依赖)
通过本文的详细指南,读者可以快速掌握基于TorchVision的Mask R-CNN实现方法,并能够针对具体应用场景进行定制化开发和优化。该项目不仅提供了实例分割的完整实现,更为深度学习在实际问题中的应用提供了优秀范例。