分享一篇腾讯的后端Java一面凉经,被速通了, 大家感受一下难度如何。
这次面试的考察覆盖了从 项目经验的深度挖掘(面试官非常看重 STAR 法则的应用)到 扎实的计算机基础(经典的 TCP/UDP 对比、MySQL 事务与 MVCC 原理),再到 分布式系统 的核心概念(如分布式锁的必要性与 Redis 实现),甚至还涉及了对 新兴技术趋势(如 AI 辅助编码)的看法,最后当然少不了 算法能力 的现场检验。
项目遇到过什么难点吗?你是如何解决的?
STAR 法则 是介绍项目经验的黄金法则:
- Situation (背景): "我参与的项目是 X(比如,一个电商秒杀系统/一个内容推荐平台/一个内部管理系统)。这个项目的主要目标是解决 Y 问题(比如,应对高并发抢购/提升用户点击率/提高管理效率)。"
- Task (任务): "我在其中主要负责 Z 模块(比如,订单处理模块/推荐算法实现/权限管理部分)的开发和维护。"
- Action (行动 - 重点讲难点和解决): "项目中遇到的一个主要挑战是 A(比如,秒杀场景下的库存超卖问题/推荐接口响应时间过长/复杂的权限校验逻辑)。为了解决这个问题,我/我们采取了以下措施:1.(比如,引入 Redis 分布式锁控制库存扣减的原子性);2.(比如,对推荐算法进行优化,并使用缓存减少计算量);3.(比如,设计了基于角色的访问控制模型 RBAC,并进行了细粒度的权限设计)。我具体做了 B(比如,负责锁方案的调研和编码实现/优化了部分算法逻辑/设计并实现了权限校验的核心代码)。"
- Result (结果): "通过这些努力,我们成功解决了 A 问题,最终效果是 C(比如,秒杀成功率提升了 X%,接口 RT 降低了 Y ms,系统安全性得到了保障),项目也顺利上线/达到了预期目标。通过这个项目,我深入学习了 D 技术(比如,分布式锁的应用/性能调优方法/复杂业务逻辑的设计),也提升了 E 能力(比如,解决复杂问题的能力/团队协作能力)。"
针对自己简历上的每个项目,至少准备 1-2 个有技术含量或业务复杂度的难点,想清楚解决过程和结果。不要只说功能实现,要突出技术选型、优化思路和遇到的挑战。
TCP 和 UDP 有什么区别?
- 是否面向连接 :
- TCP 是面向连接的。在传输数据之前,必须先通过"三次握手"建立连接;数据传输完成后,还需要通过"四次挥手"来释放连接。这保证了双方都准备好通信。
- UDP 是无连接的。发送数据前不需要建立任何连接,直接把数据包(数据报)扔出去。
- 是否是可靠传输 :
- TCP 提供可靠的数据传输服务。它通过序列号、确认应答 (ACK)、超时重传、流量控制、拥塞控制等一系列机制,来确保数据能够无差错、不丢失、不重复且按顺序地到达目的地。
- UDP 提供不可靠的传输。它尽最大努力交付 (best-effort delivery),但不保证数据一定能到达,也不保证到达的顺序,更不会自动重传。收到报文后,接收方也不会主动发确认。
- 是否有状态 :
- TCP 是有状态的。因为要保证可靠性,TCP 需要在连接的两端维护连接状态信息,比如序列号、窗口大小、哪些数据发出去了、哪些收到了确认等。
- UDP 是无状态的。它不维护连接状态,发送方发出数据后就不再关心它是否到达以及如何到达,因此开销更小(这很"渣男"!)。
- 传输效率 :
- TCP 因为需要建立连接、发送确认、处理重传等,其开销较大,传输效率相对较低。
- UDP 结构简单,没有复杂的控制机制,开销小,传输效率更高,速度更快。
- 传输形式 :
- TCP 是面向字节流 (Byte Stream) 的。它将应用程序交付的数据视为一连串无结构的字节流,可能会对数据进行拆分或合并。
- UDP 是面向报文 (Message Oriented) 的。应用程序交给 UDP 多大的数据块,UDP 就照样发送,既不拆分也不合并,保留了应用程序消息的边界。
- 首部开销 :
- TCP 的头部至少需要 20 字节,如果包含选项字段,最多可达 60 字节。
- UDP 的头部非常简单,固定只有 8 字节。
- 是否提供广播或多播服务 :
- TCP 只支持点对点 (Point-to-Point) 的单播通信。
- UDP 支持一对一 (单播)、一对多 (多播/Multicast) 和一对所有 (广播/Broadcast) 的通信方式。
- ......
为了更直观地对比,可以看下面这个表格:
| 特性 | TCP | UDP |
|---|---|---|
| 连接性 | 面向连接 | 无连接 |
| 可靠性 | 可靠 | 不可靠 (尽力而为) |
| 状态维护 | 有状态 | 无状态 |
| 传输效率 | 较低 | 较高 |
| 传输形式 | 面向字节流 | 面向数据报 (报文) |
| 头部开销 | 20 - 60 字节 | 8 字节 |
| 通信模式 | 点对点 (单播) | 单播、多播、广播 |
| 常见应用 | HTTP/HTTPS, FTP, SMTP, SSH | DNS, DHCP, SNMP, TFTP, VoIP, 视频流 |
什么时候选择 TCP,什么时候选 UDP?
选择 TCP 还是 UDP,主要取决于你的应用对数据传输的可靠性要求有多高,以及对实时性和效率的要求有多高。
当数据准确性和完整性至关重要,一点都不能出错时,通常选择 TCP。因为 TCP 提供了一整套机制(三次握手、确认应答、重传、流量控制等)来保证数据能够可靠、有序地送达。典型应用场景如下:
- Web 浏览 (HTTP/HTTPS): 网页内容、图片、脚本必须完整加载才能正确显示。
- 文件传输 (FTP, SCP): 文件内容不允许有任何字节丢失或错序。
- 邮件收发 (SMTP, POP3, IMAP): 邮件内容需要完整无误地送达。
- 远程登录 (SSH, Telnet): 命令和响应需要准确传输。
- ......
当实时性、速度和效率优先,并且应用能容忍少量数据丢失或乱序时,通常选择 UDP。UDP 开销小、传输快,没有建立连接和保证可靠性的复杂过程。典型应用场景如下:
- 实时音视频通信 (VoIP, 视频会议, 直播): 偶尔丢失一两个数据包(可能导致画面或声音短暂卡顿)通常比因为等待重传(TCP 机制)导致长时间延迟更可接受。应用层可能会有自己的补偿机制。
- 在线游戏: 需要快速传输玩家位置、状态等信息,对实时性要求极高,旧的数据很快就没用了,丢失少量数据影响通常不大。
- DHCP (动态主机配置协议): 客户端在请求 IP 时自身没有 IP 地址,无法满足 TCP 建立连接的前提条件,并且 DHCP 有广播需求、交互模式简单以及自带可靠性机制。
- 物联网 (IoT) 数据上报: 某些场景下,传感器定期上报数据,丢失个别数据点可能不影响整体趋势分析。
- ......
能简单说说 TCP 的三次握手和四次挥手过程吗?
图解如下:
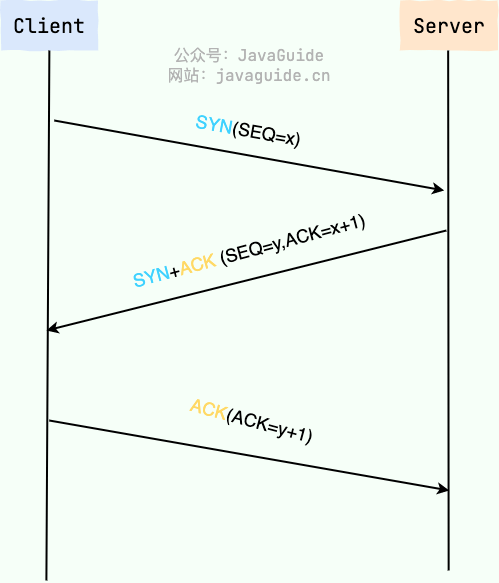
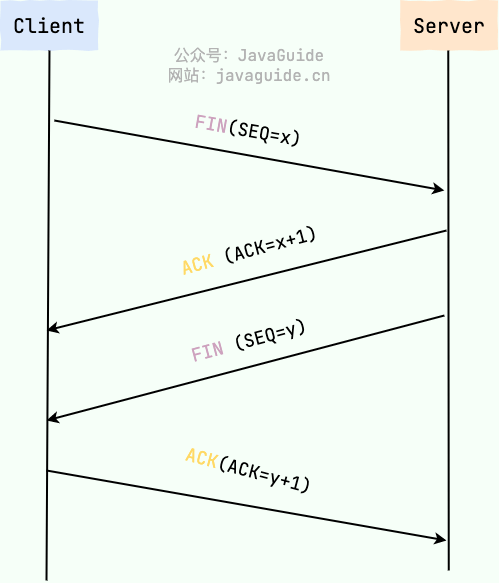
详细介绍可以参考 JavaGuide(javaguide.cn )的这篇文章:https://javaguide.cn/cs-basics/network/tcp-connection-and-disconnection.html 。
MySQL 有哪些事务隔离级别? 默认的隔离级别是什么?
SQL 标准定义了四种事务隔离级别,用来平衡事务的隔离性(Isolation)和并发性能。级别越高,数据一致性越好,但并发性能可能越低。这四个级别是:
- READ-UNCOMMITTED(读取未提交) :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。这种级别在实际应用中很少使用,因为它对数据一致性的保证太弱。
- READ-COMMITTED(读取已提交) :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。这是大多数数据库(如 Oracle, SQL Server)的默认隔离级别。
- REPEATABLE-READ(可重复读) :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。MySQL InnoDB 存储引擎的默认隔离级别正是 REPEATABLE READ。并且,InnoDB 在此级别下通过 MVCC(多版本并发控制) 和 Next-Key Locks(间隙锁+行锁) 机制,在很大程度上解决了幻读问题。
- SERIALIZABLE(可串行化) :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) |
|---|---|---|---|
| READ UNCOMMITTED | √ | √ | √ |
| READ COMMITTED | × | √ | √ |
| REPEATABLE READ | × | × | √ (标准) / ≈× (InnoDB) |
| SERIALIZABLE | × | × | × |
默认级别查询:
MySQL InnoDB 存储引擎的默认隔离级别是 REPEATABLE READ。可以通过以下命令查看:
- MySQL 8.0 之前:
SELECT @@tx_isolation; - MySQL 8.0 及之后:
SELECT @@transaction_isolation;
bash
mysql> SELECT @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| REPEATABLE-READ |
+-------------------------+InnoDB 的 REPEATABLE READ 对幻读的处理:
标准的 SQL 隔离级别定义里,REPEATABLE READ 是无法防止幻读的。但 InnoDB 的实现通过以下机制很大程度上避免了幻读:
- 快照读 (Snapshot Read) :普通的 SELECT 语句,通过 MVCC 机制实现。事务启动时创建一个数据快照,后续的快照读都读取这个版本的数据,从而避免了看到其他事务新插入的行(幻读)或修改的行(不可重复读)。
- 当前读 (Current Read) :像
SELECT ... FOR UPDATE,SELECT ... LOCK IN SHARE MODE,INSERT,UPDATE,DELETE这些操作。InnoDB 使用 Next-Key Lock 来锁定扫描到的索引记录及其间的范围(间隙),防止其他事务在这个范围内插入新的记录,从而避免幻读。Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的组合。
值得注意的是,虽然通常认为隔离级别越高、并发性越差,但 InnoDB 存储引擎通过 MVCC 机制优化了 REPEATABLE READ 级别。对于许多常见的只读或读多写少的场景,其性能与 READ COMMITTED 相比可能没有显著差异。不过,在写密集型且并发冲突较高的场景下,RR 的间隙锁机制可能会比 RC 带来更多的锁等待。
此外,在某些特定场景下,如需要严格一致性的分布式事务(XA Transactions),InnoDB 可能要求或推荐使用 SERIALIZABLE 隔离级别来确保全局数据的一致性。
《MySQL 技术内幕:InnoDB 存储引擎(第 2 版)》7.7 章这样写到:
InnoDB 存储引擎提供了对 XA 事务的支持,并通过 XA 事务来支持分布式事务的实现。分布式事务指的是允许多个独立的事务资源(transactional resources)参与到一个全局的事务中。事务资源通常是关系型数据库系统,但也可以是其他类型的资源。全局事务要求在其中的所有参与的事务要么都提交,要么都回滚,这对于事务原有的 ACID 要求又有了提高。另外,在使用分布式事务时,InnoDB 存储引擎的事务隔离级别必须设置为 SERIALIZABLE。
讲讲 MVCC 的原理
MVCC(多版本并发控制)是一种并发控制机制。核心原理是为数据行维护多个版本:写操作(如UPDATE/DELETE)不直接覆盖旧数据,而是创建新版本,记录事务ID(DB_TRX_ID),并通过指针(DB_ROLL_PTR)指向存储在undo log中的旧版本。读操作(SELECT)基于事务启动时创建的Read View(包含活跃事务列表),通过比较行版本的事务ID和Read View,只读取对当前事务可见的版本(通常是启动前已提交或自身修改的版本),从而实现非锁定读,提升并发性能。
详细介绍可以参考 JavaGuide(javaguide.cn )的这篇文章: InnoDB 存储引擎对 MVCC 的实现。
为什么需要分布式锁?
在多线程环境中,如果多个线程同时访问共享资源(例如商品库存、外卖订单),会发生数据竞争,可能会导致出现脏数据或者系统问题,威胁到程序的正常运行。
举个例子,假设现在有 100 个用户参与某个限时秒杀活动,每位用户限购 1 件商品,且商品的数量只有 3 个。如果不对共享资源进行互斥访问,就可能出现以下情况:
- 线程 1、2、3 等多个线程同时进入抢购方法,每一个线程对应一个用户。
- 线程 1 查询用户已经抢购的数量,发现当前用户尚未抢购且商品库存还有 1 个,因此认为可以继续执行抢购流程。
- 线程 2 也执行查询用户已经抢购的数量,发现当前用户尚未抢购且商品库存还有 1 个,因此认为可以继续执行抢购流程。
- 线程 1 继续执行,将库存数量减少 1 个,然后返回成功。
- 线程 2 继续执行,将库存数量减少 1 个,然后返回成功。
- 此时就发生了超卖问题,导致商品被多卖了一份。
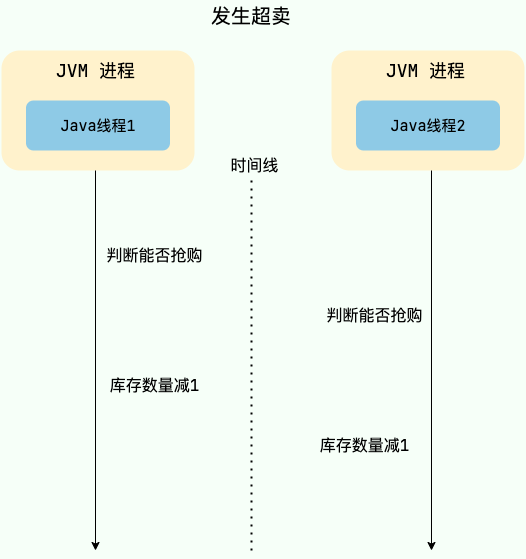
为了保证共享资源被安全地访问,我们需要使用互斥操作对共享资源进行保护,即同一时刻只允许一个线程访问共享资源,其他线程需要等待当前线程释放后才能访问。这样可以避免数据竞争和脏数据问题,保证程序的正确性和稳定性。
如何才能实现共享资源的互斥访问呢? 锁是一个比较通用的解决方案,更准确点来说是悲观锁。
悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程。
对于单机多线程来说,在 Java 中,我们通常使用 ReentrantLock 类、synchronized 关键字这类 JDK 自带的 本地锁 来控制一个 JVM 进程内的多个线程对本地共享资源的访问。
下面是我对本地锁画的一张示意图。
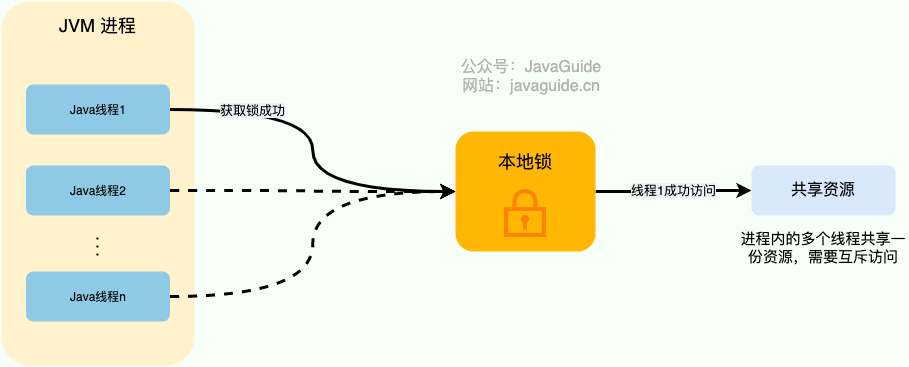
从图中可以看出,这些线程访问共享资源是互斥的,同一时刻只有一个线程可以获取到本地锁访问共享资源。
分布式系统下,不同的服务/客户端通常运行在独立的 JVM 进程上。如果多个 JVM 进程共享同一份资源的话,使用本地锁就没办法实现资源的互斥访问了。于是,分布式锁 就诞生了。
举个例子:系统的订单服务一共部署了 3 份,都对外提供服务。用户下订单之前需要检查库存,为了防止超卖,这里需要加锁以实现对检查库存操作的同步访问。由于订单服务位于不同的 JVM 进程中,本地锁在这种情况下就没办法正常工作了。我们需要用到分布式锁,这样的话,即使多个线程不在同一个 JVM 进程中也能获取到同一把锁,进而实现共享资源的互斥访问。
下面是我对分布式锁画的一张示意图。
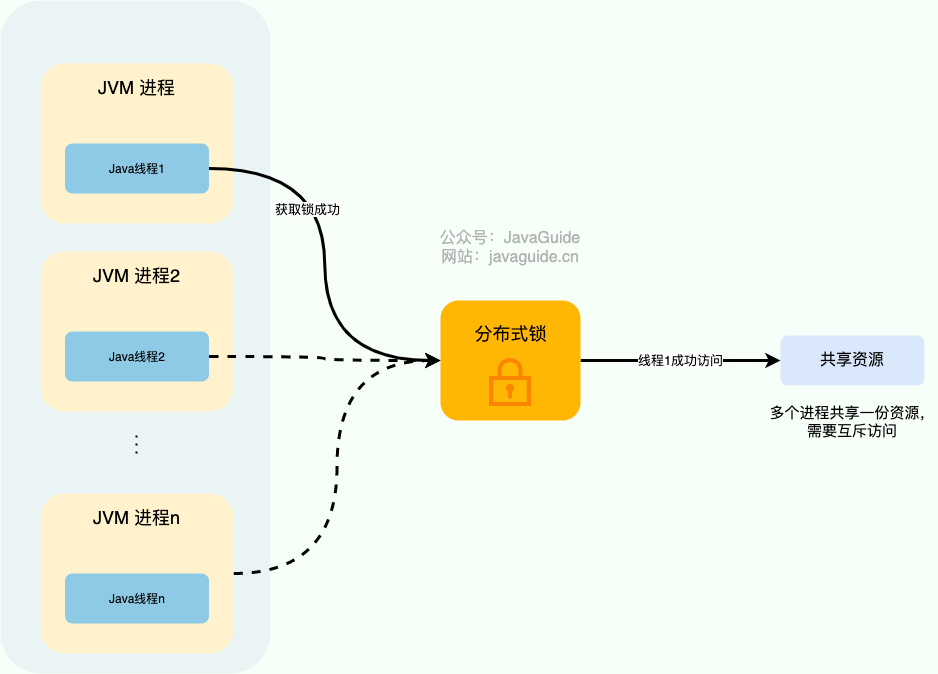
从图中可以看出,这些独立的进程中的线程访问共享资源是互斥的,同一时刻只有一个线程可以获取到分布式锁访问共享资源。
Redis 如何实现分布式锁?
Redis 实现分布式锁主要利用其原子操作。
- 核心机制 :使用
SET key unique_value NX EX expire_time命令。NX 确保只有键不存在时才能设置成功(获取锁),EX 设置过期时间防止持有者宕机导致死锁,unique_value用于标识锁的持有者。 - 安全释放 :释放锁时,使用 Lua 脚本先 GET 键的值,判断是否与自己持有的
unique_value相等,确认是自己的锁后才执行 DEL,保证原子性和防止误删。 - 锁续期:为防止业务未完成锁就过期,可使用 Redisson 等库提供的"看门狗"(Watchdog)机制,它会定时检查持有锁的客户端是否活跃,并在锁即将到期前自动延长其有效期。
- 集群考量:在 Redis 集群模式下,主从复制可能导致锁问题。Redlock 算法尝试解决此问题,但实现复杂且有争议,实践中需谨慎评估。
对AI辅助编码的看法
我认为它是一个极具潜力的发展方向,并且已经成为提升开发者生产力的重要工具。
AI 辅助编码工具,例如 GitHub Copilot、Tabnine 等,正越来越多地集成到我们的开发流程中。我认为它们的主要优势体现在以下几个方面:
- 显著提升编码效率: 它们能够根据上下文快速生成样板代码(boilerplate code)、常用函数或代码片段,极大地减少了重复性劳动,让开发者能更快地完成基础编码工作。
- 辅助学习与探索: 对于不熟悉的 API、库或编程语言特性,AI 可以提供即时的代码示例和用法建议,加速开发者的学习曲线和技术探索过程。
- 代码质量改进建议: 一些工具能够识别潜在的错误模式、低效代码或不符合规范的写法,并提供优化建议,有助于提升代码的健壮性和可维护性。
- 加速测试用例生成: 在某些场景下,AI 能够根据现有代码自动生成单元测试的基本框架或测试用例,帮助提高测试覆盖率。
当然,我们也要清醒地认识到当前 AI 辅助编码工具的局限性:
- 上下文依赖性强: 生成代码的质量高度依赖于开发者提供的上下文信息(如注释、现有代码)。上下文不足或模糊时,生成的代码可能偏离预期,甚至包含逻辑错误。
- 潜在的安全风险: AI 可能生成包含安全漏洞的代码(例如,未做充分输入验证、权限控制不当等)。开发者必须对生成的代码进行严格的安全审查。
- 复杂逻辑处理能力有限: AI 目前更擅长处理模式化、通用性的编码任务。对于高度定制化、复杂的业务逻辑或创新的算法设计,其能力仍然有限,需要依赖开发者的深度思考和设计。
- 版权与合规性问题: AI 生成的代码可能源自其训练数据,这可能引发潜在的版权归属或开源协议合规性问题,需要谨慎对待。
算法
Leetcode3.无重复字符的最长子串