面试导航 是一个专注于前、后端技术学习和面试准备的 免费 学习平台,提供系统化的技术栈学习,深入讲解每个知识点的核心原理,帮助开发者构建全面的技术体系。平台还收录了大量真实的校招与社招面经,帮助你快速掌握面试技巧,提升求职竞争力。如果你想加入我们的交流群,欢迎通过微信联系:
yunmz777。
Playwright 是一个开源的自动化测试库,专门用于对现代 web 应用进行跨浏览器的自动化操作。它是由 Microsoft 开发的,旨在为开发者提供一种可靠、快速、简便的方式来进行端到端(E2E)测试、浏览器自动化和网页抓取等操作。Playwright 支持多种浏览器,包括 Chromium、Firefox 和 WebKit,能够很好地应对不同平台和设备的自动化需求。
Playwright 的基本功能
Playwright 是一个功能强大的现代化浏览器自动化工具,它通过多个模块帮助开发者高效地进行自动化测试和浏览器操作。其主要功能模块包括:
-
浏览器自动化:
Playwright允许开发者通过编程控制浏览器进行多种操作,类似于Selenium,但提供了更多先进的功能和更高的可靠性。开发者可以启动浏览器实例,模拟用户交互,如点击、输入、滚动和提交表单等。此外,Playwright 还支持操作复杂的单页面应用(SPA),并能自动化处理动态加载的内容,因此在处理现代 Web 应用时非常高效。 -
跨浏览器支持:
Playwright的一大亮点是其强大的跨浏览器支持,它能够在Chromium、Firefox和WebKit(Safari)浏览器上运行自动化脚本。这意味着开发者可以使用Playwright来确保其应用在不同浏览器和设备上的兼容性,从而进行全面的测试,尤其是在移动设备和不同操作系统之间的差异处理方面,Playwright的优势尤为突出。 -
自动化脚本的编写:
Playwright提供了丰富的 API,支持使用JavaScript、TypeScript、Python和C#等编程语言编写自动化脚本。这些脚本可以模拟各种浏览器行为,如点击按钮、输入文本、验证页面内容、截取截图等。开发者可以根据需求设计脚本,进行端到端的功能测试、表单验证、性能评估等,支持同步和异步执行,提升测试的效率和可靠性。 -
截图和视频录制:
Playwright提供了内置的截图和视频录制功能,开发者可以在自动化测试过程中自动截取页面截图或录制操作视频。截图可以帮助验证页面渲染效果或记录关键操作的状态,视频录制则能更直观地展示测试过程,便于开发者在调试时回放和分析失败的测试用例。这些功能在持续集成环境下尤为重要,能够帮助团队快速定位和修复问题。 -
无头模式(Headless Mode):
Playwright支持无头模式,这意味着浏览器在后台运行时不会加载图形界面,从而节省系统资源,提高测试的执行效率。无头模式特别适用于持续集成(CI)环境,因为它能在没有图形界面的服务器上快速运行测试,适合大规模的自动化测试。此外,Playwright还支持启用"慢动作"模式,帮助开发者更容易观察和调试测试过程。
通过这些功能,Playwright 提供了一个高效、跨平台、可扩展的自动化框架,帮助开发者在进行浏览器自动化测试时提高效率和准确性,确保 Web 应用在不同环境中的稳定运行。
安装 Playwright
要在 Node.js 环境中使用 Playwright,首先需要确保你有一个 Node.js 项目。如果还没有,可以通过运行以下命令来初始化一个项目:
bash
npm init -y接着,你可以通过运行以下命令来快速安装 Playwright:
bash
npm init playwright@latest这个命令不仅会安装 Playwright 库,还会自动下载 Chromium、Firefox 和 WebKit 浏览器的二进制文件,确保你的自动化脚本可以在多个浏览器中运行。
如果你已经有了一个 Node.js 项目,并且只需要安装 Playwright,可以运行以下命令来安装 Playwright 库:
bash
npm install playwright但这不会自动下载浏览器二进制文件。如果你希望下载浏览器,可以额外运行以下命令:
bash
npx playwright install除此之外,如果你只需要某个特定浏览器(如 Chromium、Firefox 或 WebKit),可以分别通过以下命令来单独安装:
-
安装 Chromium:
bashnpm install playwright-chromium -
安装 Firefox:
bashnpm install playwright-firefox -
安装 WebKit:
bashnpm install playwright-webkit
安装完成后,你可以编写自动化脚本来验证安装是否成功,启动浏览器并访问页面。如果浏览器能够成功启动并执行脚本,说明 Playwright 安装成功。
基础操作
一旦安装完成,可以开始编写自动化脚本了。以下是一个简单的示例,展示如何用 Playwright 启动浏览器、访问页面并截图:
javascript
const { chromium } = require("playwright");
(async () => {
// 启动浏览器
const browser = await chromium.launch({ headless: false });
// 创建新的浏览器上下文(类似于浏览器窗口)
const context = await browser.newContext();
// 打开一个页面
const page = await context.newPage();
// 访问页面
await page.goto("https://juejin.cn/");
// 截图
await page.screenshot({ path: "moment.png" });
// 关闭浏览器
await browser.close();
})();你可以看到它自动给我们打开了浏览器:
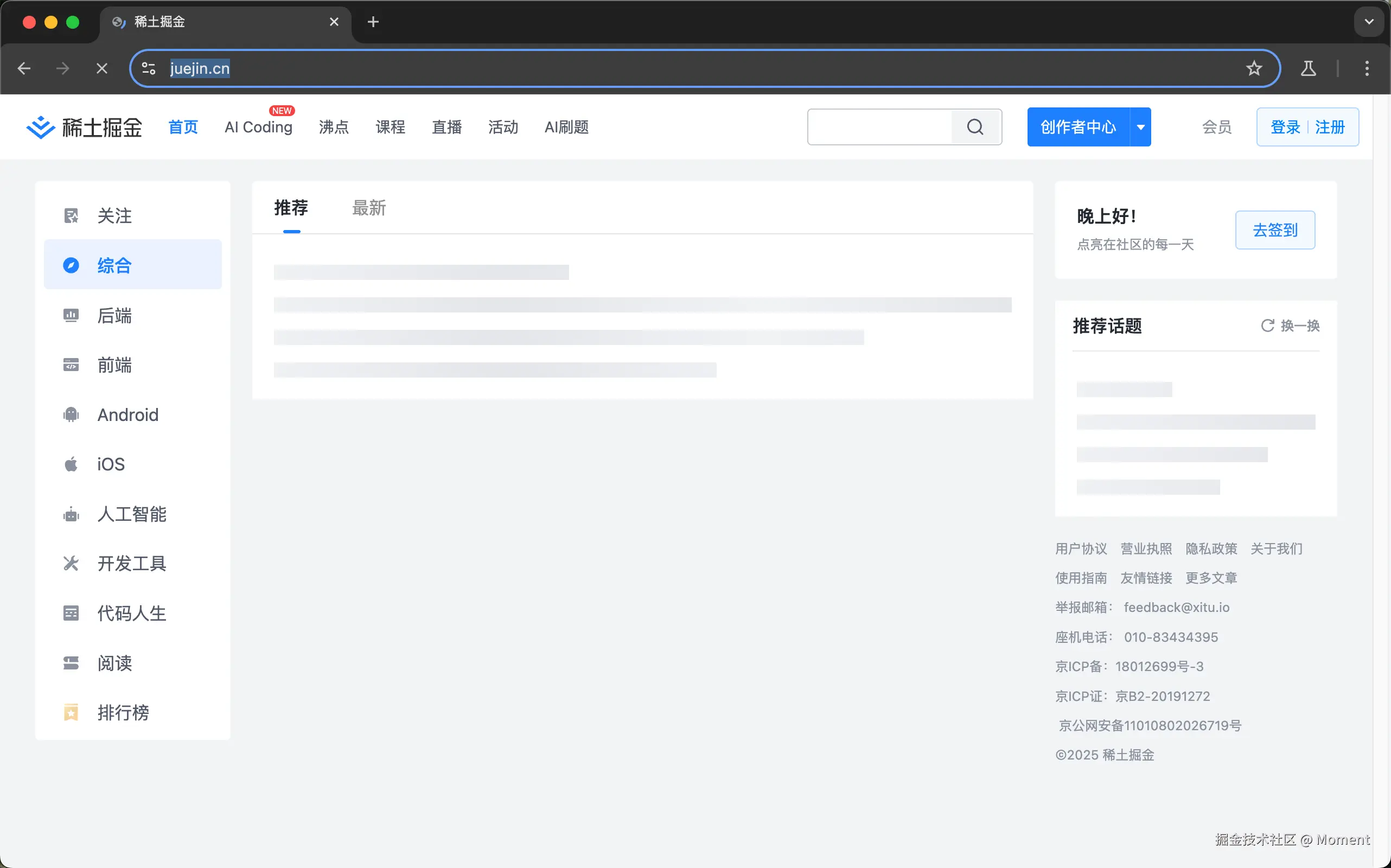
并最终在我们项目中的目录中生成了 moment.png 这个文件了:
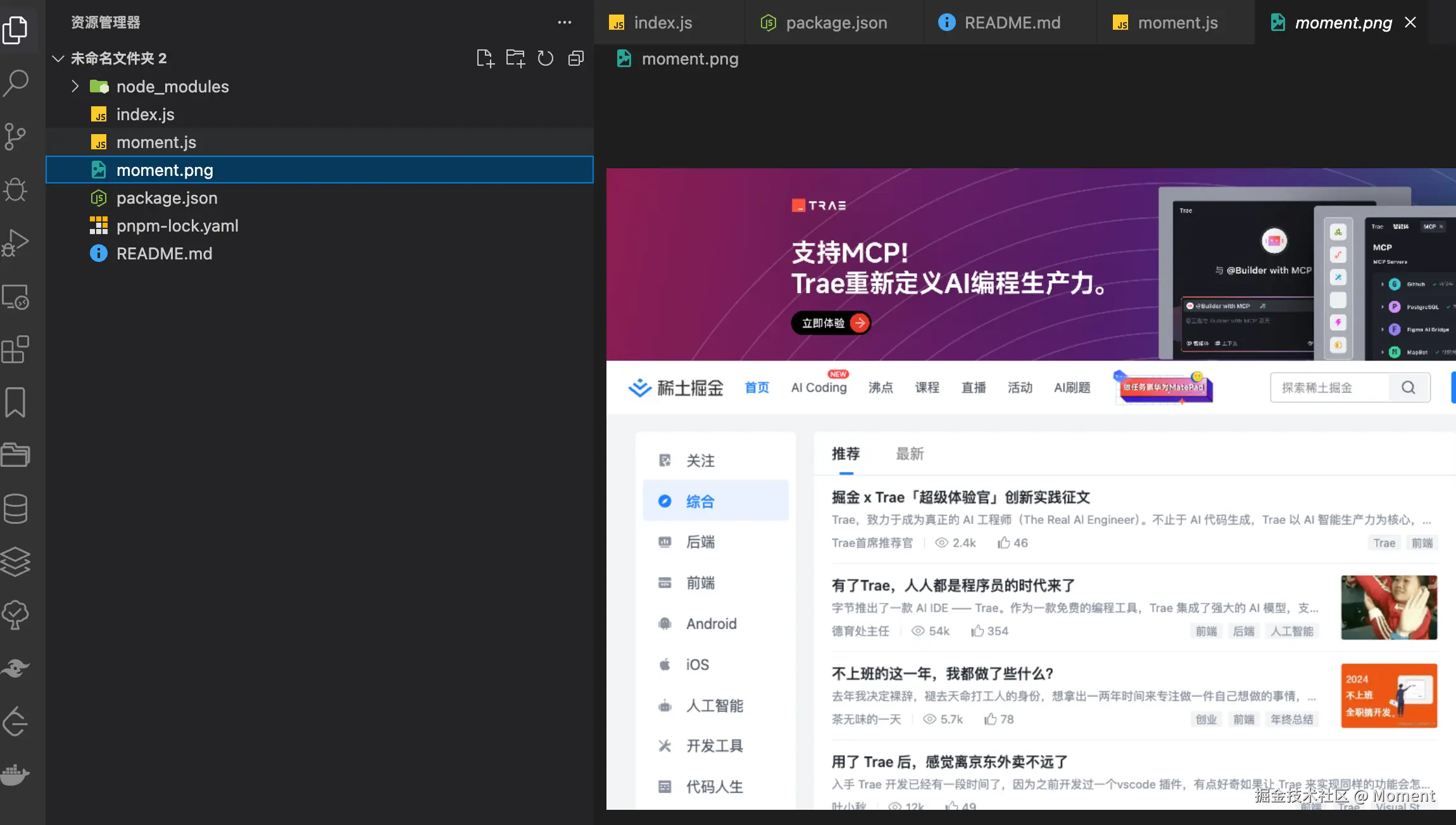
Playwright 的核心概念
浏览器(Browser)
在 Playwright 中,浏览器是进行自动化操作的基本单元。Playwright 允许你启动不同类型的浏览器实例,如 Chromium、Firefox 和 WebKit。每个浏览器实例都可以独立运行,并执行各种操作,比如加载网页、获取页面信息、模拟用户交互等。Playwright 提供了丰富的 API 来控制和操作这些浏览器实例,使得开发者可以通过脚本来模拟完整的浏览器行为。
浏览器上下文(Browser Context)
浏览器上下文是 Playwright 中用于隔离不同会话的核心概念。它类似于浏览器中的一个 "私人窗口",每个浏览器上下文都有自己的独立存储空间,包括 cookies、localStorage 和 sessionStorage。不同上下文之间的数据是隔离的,这对于模拟多个用户的场景非常有用。例如,在进行多用户登录测试时,你可以创建多个浏览器上下文,每个上下文代表一个独立的用户会话,避免数据互相干扰。
页面(Page)
页面是浏览器中的一个标签页,代表一个独立的浏览器视图。在 Playwright 中,页面是所有自动化操作的基本对象,你可以对页面执行各种操作,比如加载网页、模拟用户输入、点击按钮、获取页面内容等。每个页面都是浏览器上下文的一部分,你可以在一个浏览器上下文中同时打开多个页面,模拟多个标签页的行为。
元素选择器(Element Selector)
在 Playwright 中,与页面交互的基础是选择页面中的元素。Playwright 提供了多种方式来定位和选择元素,包括 CSS 选择器、XPath 选择器和文本选择器等。你可以通过这些选择器精确定位页面上的按钮、输入框、链接等元素,然后对它们进行操作。例如,你可以使用 page.click() 方法点击一个按钮,或者使用 page.fill() 方法输入文本。选择器的灵活性使得 Playwright 可以应对复杂的页面结构。
动作(Actions)
Playwright 支持模拟用户与页面交互的各种动作,允许开发者在自动化脚本中执行模拟点击、输入、悬停、拖拽等操作。常见的动作包括:
- 点击(
click):模拟用户点击一个页面元素。 - 输入文本(
type):模拟用户在输入框中输入文本。 - 鼠标悬停(
hover):模拟用户将鼠标悬停在一个元素上,这对于测试页面的悬浮效果或显示工具提示很有用。 - 拖拽(
dragAndDrop):模拟拖拽操作,适用于拖动元素或重新排列页面内容。
通过这些操作,Playwright 能够精确地模拟用户行为,帮助开发者实现自动化测试和网页交互的需求。
Playwright 的 API
Playwright 提供了丰富的 API,可以帮助开发者轻松控制浏览器并与页面交互。首先,启动浏览器非常简单,通过 Playwright 提供的 launch() 方法,你可以启动一个新的浏览器实例,并选择浏览器类型(如 Chromium、Firefox 或 WebKit)。如果你需要查看浏览器的操作过程,可以通过配置 headless: false 来禁用无头模式。
javascript
const { chromium } = require("playwright");
const browser = await chromium.launch();接着,你可以通过 newPage() 方法在浏览器中创建一个新的标签页,这样你就可以在这个页面中进行各种操作了。
javascript
const page = await browser.newPage();一旦你有了页面对象,就可以使用 goto() 方法访问指定的 URL。这个方法会自动等待页面加载完成。
javascript
await page.goto("https://example.com");如果需要模拟用户交互,比如点击页面上的按钮,可以使用 click() 方法。你只需要传入一个 CSS 选择器来定位按钮。
javascript
await page.click("button#submit");对于表单提交或数据输入,Playwright 提供了 fill() 方法,你可以用它将文本输入到指定的输入框中。
javascript
await page.fill('input[name="username"]', "myUser");
await page.fill('input[name="password"]', "myPassword");在页面中,如果你想获取某个元素的文本内容,可以使用 textContent() 方法,这对于验证页面显示内容特别有用。
javascript
const content = await page.textContent("h1");如果你需要捕获页面的截图,可以使用 screenshot() 方法,它会将页面的当前状态保存为图片文件。
javascript
await page.screenshot({ path: "screenshot.png" });对于动态加载的元素,Playwright 提供了 waitForSelector() 方法,它会等待指定的元素在页面中出现,这样可以确保操作不会提前执行。
javascript
await page.waitForSelector("button#submit");最后,如果你需要获取当前页面的标题,可以使用 title() 方法,它会返回页面的 <title> 内容。
javascript
const title = await page.title();这些 API 使得 Playwright 成为一个功能强大的工具,帮助开发者更轻松地进行浏览器自动化操作、测试和调试。通过这些基本操作,你可以实现与页面的互动,验证页面内容,甚至进行截图等。
如何爬取 B 站综合热门的视频
接下来我们将用一个完整的案例来演示应该如何使用 Playwright 来爬取 B 站综合热门的视频,如下代码所示:
js
const { chromium } = require("playwright");
const fs = require("fs").promises;
const path = require("path");
async function scrapeBilibiliPopular() {
const resultDir = "bilibili_popular";
try {
await fs.mkdir(resultDir, { recursive: true });
} catch (err) {
console.log("目录已存在或创建失败,继续...");
}
const browser = await chromium.launch({
headless: false,
slowMo: 100,
});
const context = await browser.newContext({
userAgent:
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
viewport: { width: 1280, height: 800 },
});
const page = await context.newPage();
try {
console.log("正在访问Bilibili热门页面...");
await page.goto(
"https://www.bilibili.com/v/popular/all?spm_id_from=333.1007.0.0",
{
waitUntil: "networkidle",
timeout: 60000,
}
);
console.log("等待页面完全加载...");
await page.waitForTimeout(5000);
await page.screenshot({
path: path.join(resultDir, "bilibili_popular_page.png"),
fullPage: true,
});
console.log("正在查找视频条目...");
const hasVideoElements = await page.evaluate(() => {
const videoContainers = document.querySelectorAll(
'[class*="video"], [class*="card"]'
);
return videoContainers.length > 0;
});
if (!hasVideoElements) {
console.log("未找到标准的视频元素,页面结构可能与预期不同。");
await page.screenshot({
path: path.join(resultDir, "debug_no_videos.png"),
fullPage: true,
});
}
console.log("正在提取视频信息...");
const videos = await page.evaluate(() => {
const videoLinks = Array.from(
document.querySelectorAll('a[href*="/video/"]')
);
const uniqueVideoLinks = [];
const seenHrefs = new Set();
for (const link of videoLinks) {
const href = link.href;
if (seenHrefs.has(href)) continue;
seenHrefs.add(href);
if (link.offsetWidth < 100 || link.offsetHeight < 30) continue;
let container = link;
for (let i = 0; i < 5 && container; i++) {
const hasTitle = container.querySelector("[title], .title, h3, h4");
const hasAuthor = container.querySelector(
'[class*="up"], [class*="author"], .up-name'
);
if (hasTitle || hasAuthor) {
break;
}
container = container.parentElement;
}
if (!container)
container =
link.closest('div[class*="card"], div[class*="item"]') || link;
let title = "";
const titleEl = container.querySelector("[title], .title, h3, h4");
if (titleEl && titleEl.textContent.trim().length > 0) {
title = titleEl.textContent.trim();
} else if (link.getAttribute("title")) {
title = link.getAttribute("title");
} else if (container.getAttribute("title")) {
title = container.getAttribute("title");
} else {
const textNodes = [];
const walk = document.createTreeWalker(
container,
NodeFilter.SHOW_TEXT
);
let node;
while ((node = walk.nextNode())) {
if (node.textContent.trim().length > 5) {
textNodes.push(node.textContent.trim());
}
}
if (textNodes.length > 0) {
textNodes.sort((a, b) => b.length - a.length);
title = textNodes[0];
}
}
if (!title) continue;
let author = "未知作者";
const authorEl = container.querySelector(
'[class*="up-name"], [class*="author"], [class*="up"], .username'
);
if (authorEl) {
author = authorEl.textContent.trim();
}
let playCount = "未知";
const playCountEl = container.querySelector(
'[class*="play"], [class*="view"], .play-count, .view-count'
);
if (playCountEl) {
playCount = playCountEl.textContent.trim();
}
if (title && href) {
uniqueVideoLinks.push({
title,
url: href,
author,
playCount,
});
}
}
return uniqueVideoLinks;
});
if (videos.length === 0) {
console.log("未通过主要方法找到视频,尝试另一种方法...");
const altVideos = await page.evaluate(() => {
const results = [];
const cardItems = document.querySelectorAll(
'.bili-video-card, .video-card, [class*="video-card"], [class*="rank-item"]'
);
if (cardItems && cardItems.length > 0) {
cardItems.forEach((card) => {
let title = card.getAttribute("title") || "";
if (!title) {
const titleEl = card.querySelector(
"[title], .title, .info--tit, h3"
);
if (titleEl) {
title =
titleEl.getAttribute("title") || titleEl.textContent.trim();
}
}
const linkEl = card.querySelector('a[href*="/video/"]');
const url = linkEl ? linkEl.href : "";
if (!title || !url) return;
let author = "未知作者";
const authorEl = card.querySelector(
'.up-name, .up, [class*="author"]'
);
if (authorEl) {
author = authorEl.textContent.trim();
}
let playCount = "未知";
const playEl = card.querySelector(
'.play-count, .view-count, [class*="play"], [class*="view"]'
);
if (playEl) {
playCount = playEl.textContent.trim();
}
results.push({
title,
url,
author,
playCount,
});
});
}
return results;
});
if (altVideos.length > 0) {
console.log(`通过备用方法找到 ${altVideos.length} 个视频。`);
videos.push(...altVideos);
}
}
console.log(`找到 ${videos.length} 个热门视频。`);
if (videos.length === 0) {
console.log("使用直接页面提取方法...");
await page.reload();
await page.waitForTimeout(5000);
const rawVideoData = await page.evaluate(() => {
return document.documentElement.outerHTML;
});
await fs.writeFile(
path.join(resultDir, "bilibili_page.html"),
rawVideoData
);
await page.screenshot({
path: path.join(resultDir, "debug_last_resort.png"),
fullPage: true,
});
throw new Error("无法自动提取视频信息。已保存页面HTML进行手动分析。");
}
const uniqueVideos = [];
const seenUrls = new Set();
videos.forEach((video, index) => {
if (!seenUrls.has(video.url) && video.title && video.url) {
video.rank = uniqueVideos.length + 1;
seenUrls.add(video.url);
uniqueVideos.push(video);
}
});
console.log(`处理后:找到 ${uniqueVideos.length} 个独立视频。`);
let markdownContent = "# Bilibili 热门视频\n\n";
markdownContent += `*爬取时间:${new Date().toLocaleString()}*\n\n`;
uniqueVideos.forEach((video) => {
markdownContent += `## ${video.rank}. [${video.title}](${video.url})\n\n`;
markdownContent += `**作者:** ${video.author}\n\n`;
markdownContent += `**播放量:** ${video.playCount}\n\n`;
markdownContent += `**链接:** [${video.url}](${video.url})\n\n`;
markdownContent += "---\n\n";
});
const outputPath = path.join(resultDir, "bilibili_popular_videos.md");
await fs.writeFile(outputPath, markdownContent);
console.log(`结果已保存至 ${outputPath}`);
await page.screenshot({
path: path.join(resultDir, "bilibili_final.png"),
fullPage: false,
});
} catch (error) {
console.error("抓取Bilibili时发生错误:", error);
await page.screenshot({
path: path.join(resultDir, "bilibili_error.png"),
fullPage: true,
});
console.log("错误截图已保存至 bilibili_popular/bilibili_error.png");
} finally {
await browser.close();
}
}
scrapeBilibiliPopular().catch((error) => {
console.error("抓取器错误:", error);
});当我们执行该文件的时候,它会自动给我们打开 URL 对应的页面:
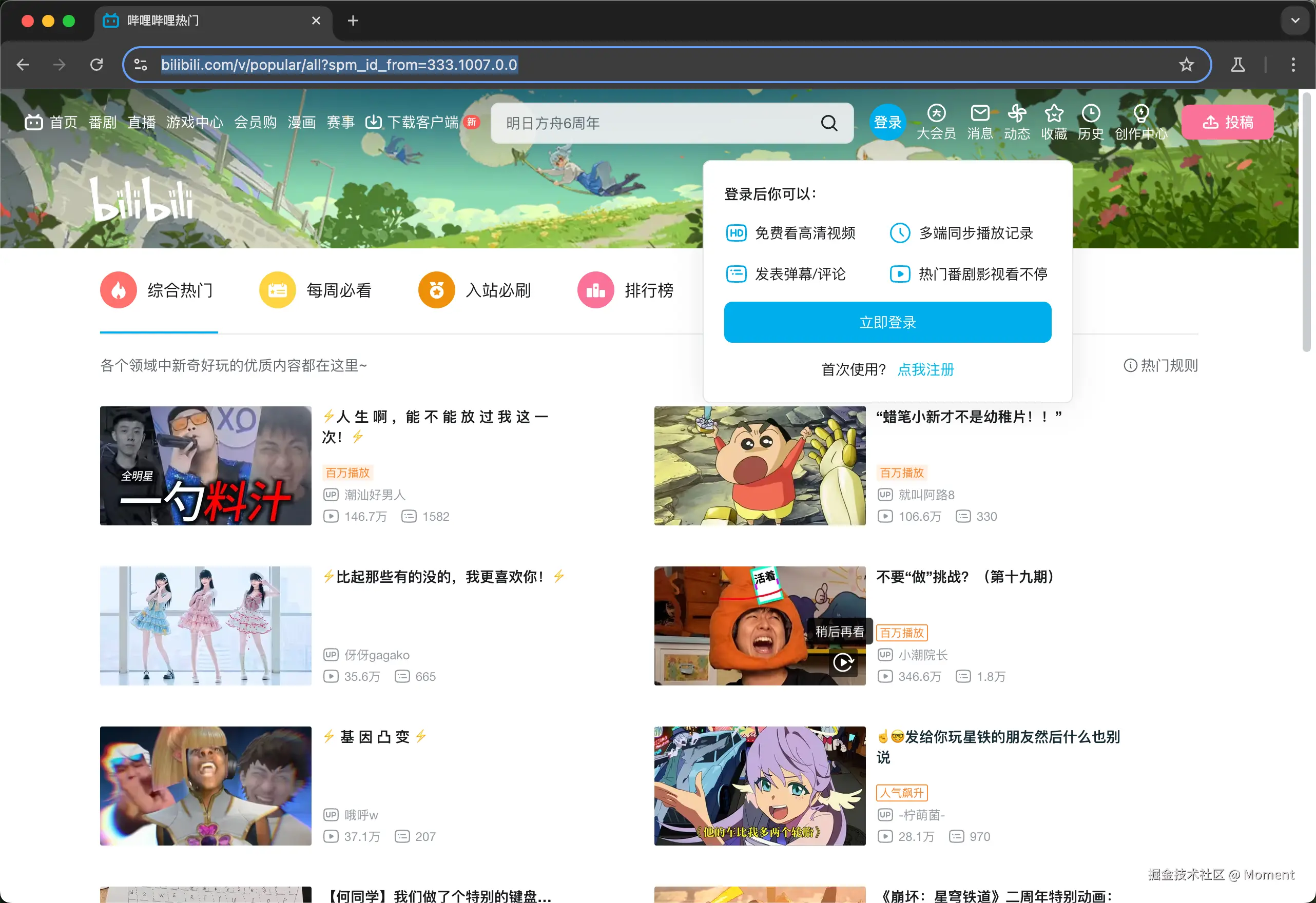
最终输出结果如下图所示:
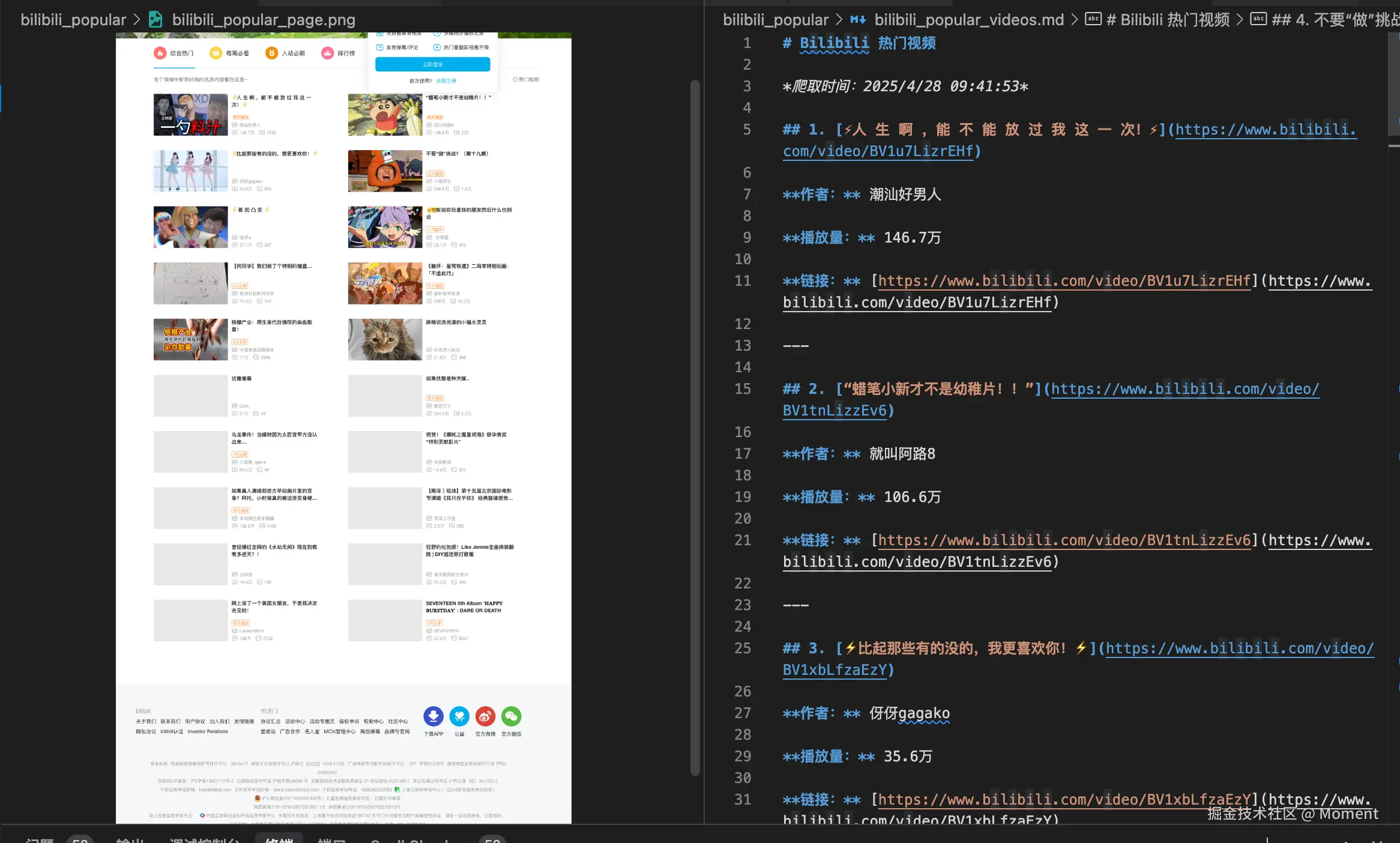
在上面的代码中,首先启动了一个 Chromium 浏览器实例,并通过 chromium.launch() 创建了一个新的浏览器上下文和页面。在启动浏览器后,脚本访问了 Bilibili 热门页面,使用 page.goto() 方法加载页面,并通过 page.waitForTimeout() 等待页面完全加载,确保所有的资源都被加载完毕。之后,脚本会截图整个页面,保存为 bilibili_popular_page.png。
js
const browser = await chromium.launch({ headless: false, slowMo: 100 });
const context = await browser.newContext({ userAgent: "..." });
const page = await context.newPage();
await page.goto("https://www.bilibili.com/v/popular/all", {
waitUntil: "networkidle",
timeout: 60000,
});
await page.waitForTimeout(5000);
await page.screenshot({ path: "bilibili_popular_page.png", fullPage: true });接下来,脚本会使用 page.evaluate() 提取页面中的视频信息。它遍历页面中的视频链接,并从每个视频元素中提取标题、作者和播放量等信息。如果视频提取成功,脚本将这些信息存储在一个数组中。如果第一次提取失败,脚本会尝试使用备用方法来获取视频数据,这时候它会查询不同的页面元素(如 .video-card 或 .bili-video-card)来提取视频信息。
js
const videos = await page.evaluate(() => {
const videoLinks = Array.from(
document.querySelectorAll('a[href*="/video/"]')
);
// 提取标题、作者、播放量等信息
});如果即使通过备用方法也没有成功提取到视频,脚本会重新加载页面并保存页面的 HTML 内容,以供后续手动分析。同时,它还会截图页面并保存错误信息,以帮助调试。
js
await page.reload();
const rawVideoData = await page.evaluate(() => {
return document.documentElement.outerHTML;
});
await fs.writeFile("bilibili_page.html", rawVideoData);
await page.screenshot({ path: "bilibili_error.png", fullPage: true });在成功提取到视频信息后,脚本会去重并按顺序排列视频数据,生成一个 Markdown 格式的报告,并将其保存为 bilibili_popular_videos.md 文件。每个视频的标题、作者、播放量以及链接都会以特定格式写入报告。
js
let markdownContent = "# Bilibili 热门视频\n\n";
uniqueVideos.forEach((video, index) => {
markdownContent += `## ${index + 1}. [${video.title}](${video.url})\n`;
markdownContent += `**作者:** ${video.author}\n`;
markdownContent += `**播放量:** ${video.playCount}\n`;
});
await fs.writeFile("bilibili_popular_videos.md", markdownContent);最后,无论操作是否成功,脚本都会关闭浏览器并保存错误截图(如果有错误发生)。这段代码的目的是自动化抓取 Bilibili 热门视频的基本信息,并生成一个易于查看和分享的报告。
js
await browser.close();整个过程确保了即使在提取信息失败的情况下,脚本也能通过保存页面 HTML 和错误截图进行调试,并最终输出一个包含视频信息的报告。
总结
Playwright 是一个由 Microsoft 开发的现代化浏览器自动化框架,支持跨浏览器操作,包括 Chromium、Firefox 和 WebKit。它提供了强大的 API,可以帮助开发者模拟用户交互、进行端到端测试、抓取网页内容等。Playwright 的设计兼顾了性能和灵活性,支持无头模式(Headless Mode)以及多浏览器支持,适用于自动化测试和抓取任务。通过简洁的脚本,Playwright 可以在多个平台和设备上高效执行,确保 Web 应用的兼容性和稳定性。