音频处理领域的天花板被撕开了。
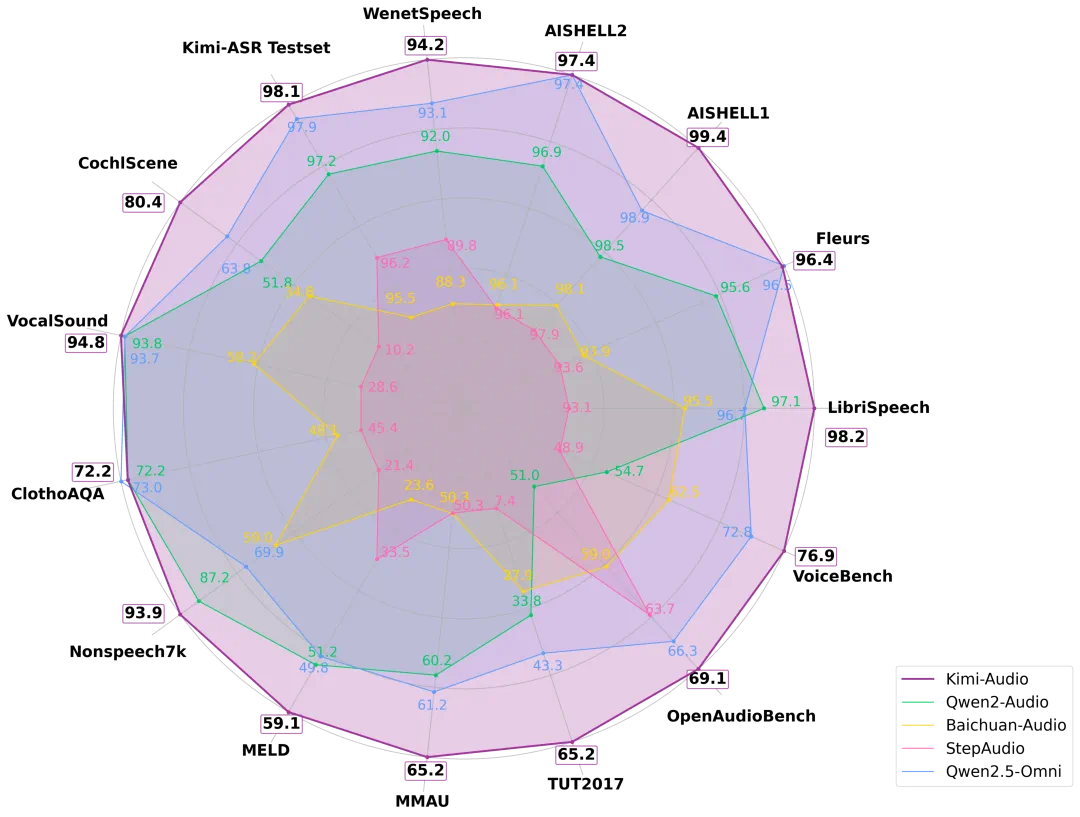
刚刚,kimi 发布全新通用音频基础模型 Kimi-Audio,这款由月之暗面(Moonshot AI)推出的开源模型,在 24 小时内收获 3.2 万星标,不仅以 1.28% 词错率刷新语音识别纪录,更在情感分析、声音事件分类等十项任务中碾压其他竞品,堪称"六边形战士"------没有短板,只有王炸。
"全能战神"Kimi-Audio
传统音频模型往往专精单一任务:语音识别、情感分析、降噪......开发者需像拼乐高般组合多个工具。而 Kimi-Audio 的颠覆性在于,它用三层架构统一了音频处理各项任务:
-
音频分词器: 将声音转化为离散语义token,保留声学细节;
-
音频大模型:基于Transformer处理多模态输入,生成文本与音频token;
-
音频去分词器:通过流匹配技术,将token转化为自然声波。
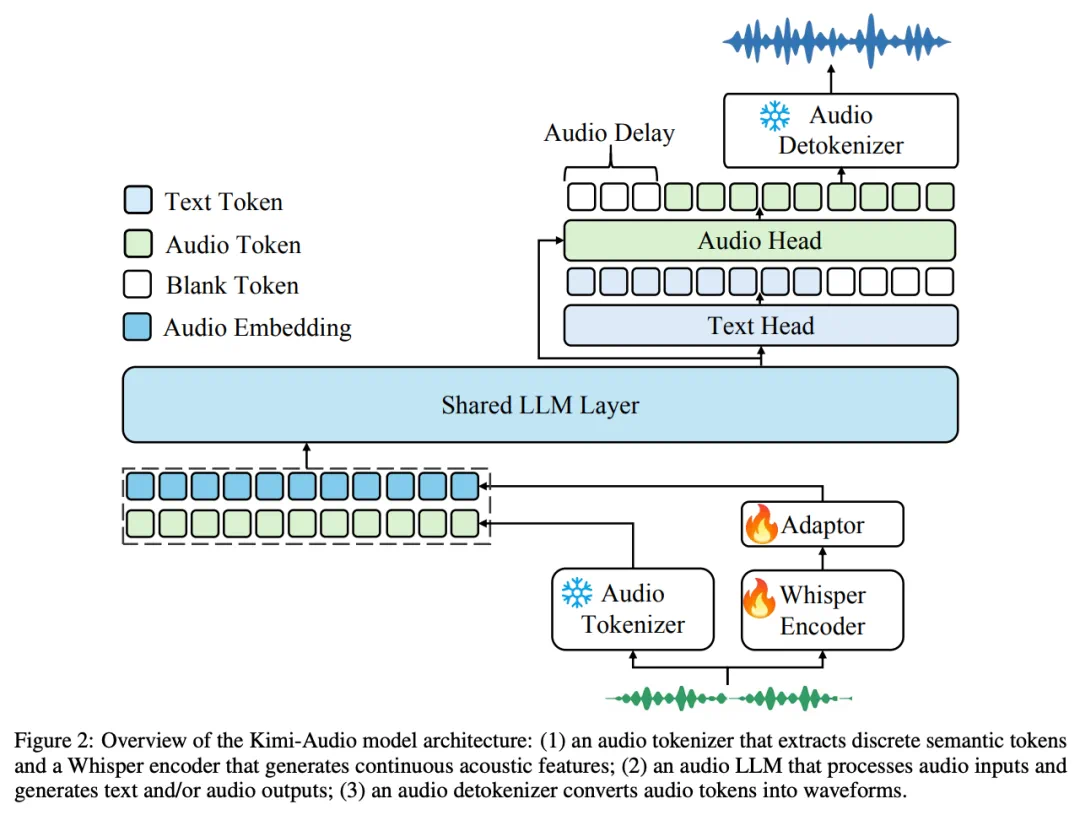
这种设计让模型能同时处理语音识别、情感分析、环境声分类等任务,完成了从音频输入到文本输出的全过程,这已经超越了工具范畴,更像是拥有听觉思维的智能体。
除了新颖的模型架构外,Kimi-Audio 在数据建构和训练方法上也下足了功夫。
在预训练阶段,Kimi-Audio 使用了约 1300 万小时覆盖多语言、音乐、环境声等多种场景的音频数据,并搭建了一条自动处理流水线来生成高质量的长音频-文本对。
这一庞大的数据集为模型的训练提供了丰富的素材和多样的场景模拟,使得模型能够更好地适应各种复杂环境下的音频处理任务。
在实际应用中的表现方面,研究者们基于评估工具包对 Kimi-Audio 在一系列音频处理任务中的表现进行了详细评估,包括自动语音识别(ASR)、音频理解、音频转文本聊天和语音对话等。
在自动语音识别方面,Kimi-Audio 在多种语言和声学条件的多样化数据集上均展现出了比以往模型更优越的性能。特别是在广泛使用的LibriSpeech基准测试中,Kimi-Audio取得了最佳结果,在test-clean上达到了 1.28% 的错误率,在 test-other 上达到了 2.42%,显著超越了其他同类模型。

在音频理解方面,Kimi-Audio 也在 MMAU 基准测试中取得了高分;在 MELD 语音情感理解任务上,它以 59.13 的得分超越了其他模型。
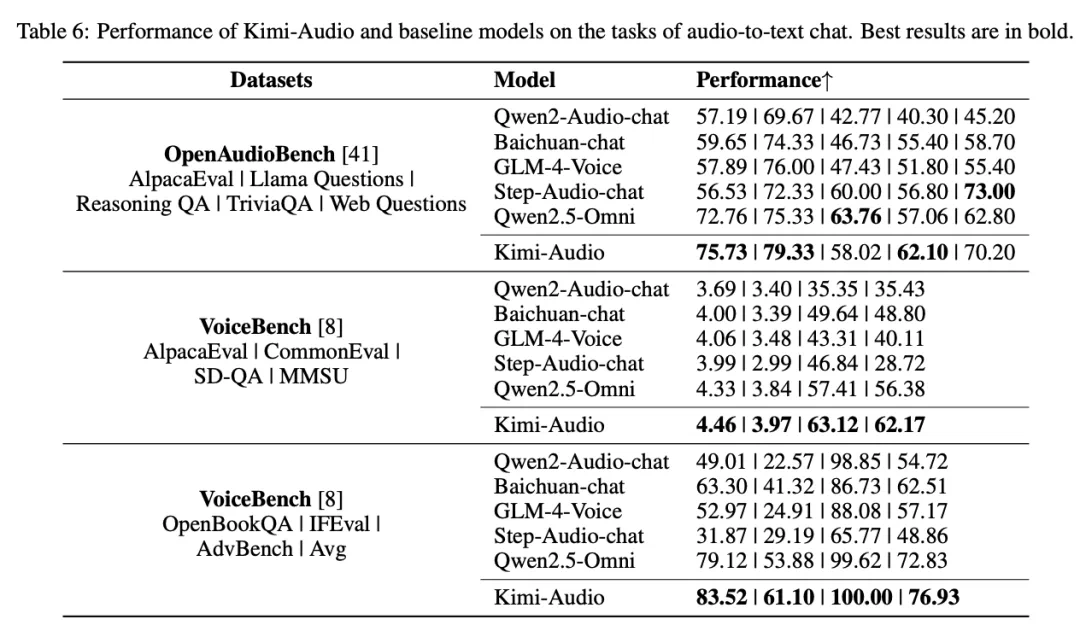
在音频转文本聊天和语音对话方面,Kimi-Audio同样表现出色。在 OpenAudioBench 和 VoiceBench 基准测试中,Kimi-Audio 在多个子任务上实现了最先进的性能。
值得一提的是,Kimi-Audio的模型代码、模型检查点以及评估工具包已经在 Github 上开源,这使得更多的研究者和开发者能够参与到音频处理领域的研究中来,共同推动这一领域的进步和发展。
Kimi-Audio 的发布,恰逢 AI 多模态革命的临界点。当 GPT-4o、Gemini 3.0 聚焦"视觉+文本"时,Kimi选择押注被低估的听觉赛道,为音频技术领域带来了新的突破和创新。
随着技术的不断进步和应用场景的不断拓展,我们有理由相信AI大模型将在未来发挥更加重要的作用,AI应用也将渗透到更多场景中。