文章目录
-
- [Diffusion Model](#Diffusion Model)
-
- [1. 前向扩散(Forward Diffusion)------ 加噪](#1. 前向扩散(Forward Diffusion)—— 加噪)
- [2. 反向扩散(Reverse Diffusion)------ 去噪](#2. 反向扩散(Reverse Diffusion)—— 去噪)
- [3. 在 Stable Diffusion 中的特殊设计](#3. 在 Stable Diffusion 中的特殊设计)
- [4. Diffusion 在生成图像时的作用](#4. Diffusion 在生成图像时的作用)
- [5. 关键技术对比](#5. 关键技术对比)
- 总结
- [LDM(Latent Diffusion Model)详解](#LDM(Latent Diffusion Model)详解)
-
- [1. 核心思想](#1. 核心思想)
- [2. 架构设计](#2. 架构设计)
-
-
- [(1) VAE(变分自编码器)](#(1) VAE(变分自编码器))
- [(2) 扩散模型(Diffusion Model)](#(2) 扩散模型(Diffusion Model))
- [(3) 条件编码器(Conditioning)](#(3) 条件编码器(Conditioning))
-
- [3. 为何选择潜在空间](#3. 为何选择潜在空间)
- [4. 关键技术优势](#4. 关键技术优势)
-
-
- [(1) 两阶段训练](#(1) 两阶段训练)
- [(2) 条件机制](#(2) 条件机制)
- [(3) 隐空间性质](#(3) 隐空间性质)
-
- [5. 应用场景](#5. 应用场景)
- [6. 局限性与改进方向](#6. 局限性与改进方向)
- [7. 总结](#7. 总结)
- [U-Net 的使用](#U-Net 的使用)
-
- [1. 前向扩散(Forward Diffusion)](#1. 前向扩散(Forward Diffusion))
- [2. 反向扩散(Reverse Diffusion)](#2. 反向扩散(Reverse Diffusion))
- [3. 为什么前向扩散不需要 U-Net?](#3. 为什么前向扩散不需要 U-Net?)
- [4. 总结](#4. 总结)
- [5. 补充说明](#5. 补充说明)
- DiT:扩散模型的神经网络实现
-
- [1. DiT 的核心思想](#1. DiT 的核心思想)
- [2. 关键技术实现](#2. 关键技术实现)
-
- [(1) Patchify 图像分块](#(1) Patchify 图像分块)
- [(2) 条件注入方式](#(2) 条件注入方式)
- [3. 架构优势](#3. 架构优势)
-
- [(1) 全局建模能力](#(1) 全局建模能力)
- [(2) 可扩展性(Scaling Law)](#(2) 可扩展性(Scaling Law))
- [(3) 计算效率](#(3) 计算效率)
- [4. 与 U-Net 的对比](#4. 与 U-Net 的对比)
- [5. 影响与后续发展](#5. 影响与后续发展)
- 总结
- 变分自编码器(VAE)
-
- [1. 基本概念](#1. 基本概念)
- 作用
- [2. 核心思想](#2. 核心思想)
- [3. 工作原理](#3. 工作原理)
- [4. 架构与结构图](#4. 架构与结构图)
- [5. 数学模型](#5. 数学模型)
- [6. 关键创新点](#6. 关键创新点)
- [7. 优缺点分析](#7. 优缺点分析)
- [8. 主要应用领域](#8. 主要应用领域)
- [9. 重要变体](#9. 重要变体)
- [10. 与其他生成模型的对比](#10. 与其他生成模型的对比)
- [11. 实现注意事项](#11. 实现注意事项)
- [12. 发展现状与趋势](#12. 发展现状与趋势)
- [AE 与 VAE 的对比](#AE 与 VAE 的对比)
- [1. 核心思想](#1. 核心思想)
- [2. 架构与数学原理](#2. 架构与数学原理)
-
- [(1) Autoencoder (AE)](#(1) Autoencoder (AE))
- [(2) Variational Autoencoder (VAE)](#(2) Variational Autoencoder (VAE))
- [3. 关键区别总结](#3. 关键区别总结)
- [4. 直观对比](#4. 直观对比)
-
- [AE 的潜在空间](#AE 的潜在空间)
- [VAE 的潜在空间](#VAE 的潜在空间)
- [5. 典型应用](#5. 典型应用)
-
- Autoencoder (AE)
- [Variational Autoencoder (VAE)](#Variational Autoencoder (VAE))
- [6. 优缺点对比](#6. 优缺点对比)
- [7. 选择建议](#7. 选择建议)
- [8. 进阶方向](#8. 进阶方向)
- MMDiT(多模态扩散Transformer)
-
-
- [1. 背景与核心创新](#1. 背景与核心创新)
- [2. 与DiT(Sora架构)的对比](#2. 与DiT(Sora架构)的对比)
- [3. MMDiT的三大核心设计](#3. MMDiT的三大核心设计)
-
- [(1) 分模态Transformer](#(1) 分模态Transformer)
- [(2) 跨模态共享注意力](#(2) 跨模态共享注意力)
- [(3) 多模态位置编码](#(3) 多模态位置编码)
- [4. 工作流程(以SD3为例)](#4. 工作流程(以SD3为例))
- [5. 性能优势](#5. 性能优势)
- [6. 代码结构示意(PyTorch风格)](#6. 代码结构示意(PyTorch风格))
- [7. 总结](#7. 总结)
- 多模态扩散Transformer(MMDiT)架构流程图解析
-
- [1. 整体架构概述](#1. 整体架构概述)
- [2. 模块功能分解](#2. 模块功能分解)
-
- (1)输入层
- (2)调制(Modulation)与线性变换(Linear)
- [(3)联合注意力(Joint Attention)](#(3)联合注意力(Joint Attention))
- [(4)重复处理(Repeat d times)](#(4)重复处理(Repeat d times))
- [3. 关键设计亮点](#3. 关键设计亮点)
- [4. 与SD3的关联](#4. 与SD3的关联)
- [5. 设计特点总结](#5. 设计特点总结)
- [6. 总结](#6. 总结)
- [与经典架构(如 SD1.5)的对比](#与经典架构(如 SD1.5)的对比)
-
- SD3
-
- [**1. 模型结构**](#1. 模型结构)
-
- [**(1) VAE(变分自编码器)**](#(1) VAE(变分自编码器))
- [**(2) 多模态 Diffusion Transformer (MMDiT)**](#(2) 多模态 Diffusion Transformer (MMDiT))
- [**(3) 扩散过程(Rectified Flow)**](#(3) 扩散过程(Rectified Flow))
- [**(4) 多文本编码器**](#(4) 多文本编码器)
- [**2. 工作流程(文生图示例)**](#2. 工作流程(文生图示例))
- 模型流程
- [**3. 关键技术亮点**](#3. 关键技术亮点)
- [**4. 性能优势**](#4. 性能优势)
- [**5. 总结**](#5. 总结)
- [**Stable Diffusion 3 (SD3) 的推理流程和训练流程**](#Stable Diffusion 3 (SD3) 的推理流程和训练流程)
-
- [**1. SD3 的推理流程(图像生成步骤)**](#1. SD3 的推理流程(图像生成步骤))
-
- [**(1) 文本编码(Text Encoding)**](#(1) 文本编码(Text Encoding))
- [**(2) 潜在空间初始化(Latent Space Initialization)or 噪声初始化**](#(2) 潜在空间初始化(Latent Space Initialization)or 噪声初始化)
- [**(3) 潜在空间去噪(Denoising with Rectified Flow)**](#(3) 潜在空间去噪(Denoising with Rectified Flow))
- [**(4) 图像解码(VAE Decoding)**](#(4) 图像解码(VAE Decoding))
- [**(5) 可选后处理(Post-Processing)**](#(5) 可选后处理(Post-Processing))
- [**2. SD3 的训练流程(模型优化)**](#2. SD3 的训练流程(模型优化))
-
- [**(1) 数据预处理**](#(1) 数据预处理)
- [**(2) 模型架构(MM-DiT)**](#(2) 模型架构(MM-DiT))
- [**(3) 训练目标(Rectified Flow + Flow Matching)**](#(3) 训练目标(Rectified Flow + Flow Matching))
- [**(4) 高分辨率微调**](#(4) 高分辨率微调)
- [**(5) 评估与优化**](#(5) 评估与优化)
- [**3. SD3 vs. SDXL:关键区别**](#3. SD3 vs. SDXL:关键区别)
- [**4. 总结**](#4. 总结)
-
- [**SD3 的推理流程**](#SD3 的推理流程)
- [**SD3 的训练流程**](#SD3 的训练流程)
- **核心优势**
- [SD3 diffusion_model: 推理 vs 训练](#SD3 diffusion_model: 推理 vs 训练)
-
- [1. **diffusion_model 的实现**](#1. diffusion_model 的实现)
- [2. **训练过程中的使用**](#2. 训练过程中的使用)
- [3. **推理过程中的使用**](#3. 推理过程中的使用)
- [4. **代码实现**](#4. 代码实现)
- [5. **训练和推理的差异**](#5. 训练和推理的差异)
- [6. **总结**](#6. 总结)
- 附
-
- [潜在空间特征图(Latent Feature Map)详解](#潜在空间特征图(Latent Feature Map)详解)
-
-
- [1. 什么是潜在空间特征图?](#1. 什么是潜在空间特征图?)
- [2. 为什么需要潜在空间?](#2. 为什么需要潜在空间?)
- [3. 潜在空间特征图的结构](#3. 潜在空间特征图的结构)
- [4. 潜在空间 vs. 像素空间](#4. 潜在空间 vs. 像素空间)
- [5. 潜在空间的操作](#5. 潜在空间的操作)
- [6. 实例说明](#6. 实例说明)
- [7. 总结](#7. 总结)
-
- 潜在空间初始化(生成初始噪声)与前向加噪
- [**1. 潜在空间初始化(Latent Space Initialization)**](#1. 潜在空间初始化(Latent Space Initialization))
- [**2. 加噪过程(Forward Diffusion Process)**](#2. 加噪过程(Forward Diffusion Process))
- [**3. 关键区别**](#3. 关键区别)
- [**4. 常见误解澄清**](#4. 常见误解澄清)
-
- [**误解1:潜在空间初始化 = 加噪**](#误解1:潜在空间初始化 = 加噪)
- **误解2:两者路径相同**
- [**5. 总结**](#5. 总结)
- 条件嵌入
-
- [1. **条件嵌入的定义**](#1. 条件嵌入的定义)
- [2. **条件嵌入的作用**](#2. 条件嵌入的作用)
-
- [2.1 **指导生成过程**](#2.1 指导生成过程)
- [2.2 **增强模型的表达能力**](#2.2 增强模型的表达能力)
- [3. **条件嵌入的实现**](#3. 条件嵌入的实现)
-
- [3.1 **文本特征嵌入**](#3.1 文本特征嵌入)
- [3.2 **时间步特征嵌入**](#3.2 时间步特征嵌入)
- [3.3 **特征融合**](#3.3 特征融合)
- [4. **代码示例**](#4. 代码示例)
- [5. **总结**](#5. 总结)
Diffusion Model
Diffusion Model 是一种 生成模型的理论框架,通过逐步去噪(逆向过程)从噪声中生成数据。其核心组件包括:
- 前向过程:逐步向数据添加噪声。
- 逆向过程:通过去噪网络(如 U-Net)逐步恢复数据。
- 噪声预测目标:训练网络预测每一步的噪声。
关键点:Diffusion Model 仅定义了生成范式,不限定具体网络架构。
扩散模型(Diffusion Model) 通过逐步"去噪"来生成图像,其过程可以分为两个阶段:
1. 前向扩散(Forward Diffusion)------ 加噪
- 给定一张真实图像 x 0 x_0 x0,模型会逐步添加高斯噪声(Gaussian Noise),经过 T T T 步后,图像逐渐变成纯噪声噪声 x T x_T xT(类似于一张完全随机的图片)。
- 这个过程可以看作是一个马尔可夫链(Markov Chain),每一步的噪声强度由调度器(Scheduler)控制(如 DDPM、DDIM 等)。
- 数学上,前向扩散可以表示为:
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{1-\beta_t} x_{t-1}, \beta_t \mathbf{I}) q(xt∣xt−1)=N(xt;1−βt xt−1,βtI)
其中 β t \beta_t βt 是噪声调度参数,控制每一步的噪声强度。 - 前向扩散不需要 U-Net
- 前向扩散是一个 固定的、预定义的加噪过程,它只是按照预设的噪声调度(如线性、余弦等)逐步向图像添加高斯噪声。加噪过程完全由噪声调度(如
beta_t或alpha_t)定义,无需学习。 - 这是一个纯数学操作,不涉及任何神经网络(包括 U-Net)。
- 公式表示:
x t = α t ⋅ x t − 1 + 1 − α t ⋅ ϵ , ϵ ∼ N ( 0 , I ) x_t = \sqrt{\alpha_t} \cdot x_{t-1} + \sqrt{1 - \alpha_t} \cdot \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) xt=αt ⋅xt−1+1−αt ⋅ϵ,ϵ∼N(0,I)
其中 α t \alpha_t αt 是噪声调度参数, ϵ \epsilon ϵ 是随机噪声。
- 前向扩散是一个 固定的、预定义的加噪过程,它只是按照预设的噪声调度(如线性、余弦等)逐步向图像添加高斯噪声。加噪过程完全由噪声调度(如
2. 反向扩散(Reverse Diffusion)------ 去噪
-
模型的任务是学习如何从噪声 x T x_T xT 逐步"去噪",最终恢复出清晰的图像 x 0 x_0 x0。
-
在训练阶段,模型(通常是 U-Net)会学习预测当前步的噪声 ϵ \epsilon ϵ,然后根据预测的噪声计算下一步的 x t − 1 x_{t-1} xt−1 。去噪过程必须建模复杂的数据分布,因此需要 U-Net 这样的强大网络来预测噪声。
-
数学上,反向扩散可以表示为:
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_\theta(x_{t-1} | x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))其中 μ θ \mu_\theta μθ 和 Σ θ \Sigma_\theta Σθ 是模型预测的均值和方差。
3. 在 Stable Diffusion 中的特殊设计
- Latent Diffusion(潜在扩散):SD 并不直接在像素空间(如 512x512 图像)上做扩散,而是先通过 VAE(变分自编码器)将图像压缩到 潜在空间(Latent Space)(如 64x64),然后在低维空间进行扩散,大幅降低计算量。
- 条件扩散(Conditional Diffusion):SD 的扩散过程受 文本提示(Prompt) 控制,通过 CLIP 文本编码器(如 OpenAI 的 CLIP 或 SD3 的 T5)将文本转换为嵌入向量,引导 U-Net 在去噪时生成符合描述的图像。
4. Diffusion 在生成图像时的作用
- 在推理(生成图像)时,SD 从一个随机噪声 x T x_T xT 开始,通过 U-Net 逐步去噪,每一步都根据文本提示调整去噪方向,最终得到清晰的图像。
- 由于扩散是逐步进行的,模型可以生成细节丰富、符合语义的高质量图像。
5. 关键技术对比
Diffusion Model(理论框架)
├── U-Net(CNN 实现) # 如 Stable Diffusion 1.5, DDPM
└── DiT(Transformer 实现) # 如 Stable Diffusion 3, Sora
| 特性 | U-Net(传统扩散) | DiT |
|---|---|---|
| 网络架构 | CNN + 下采样-上采样 | Transformer + Patchify |
| 感受野 | 局部(受卷积核限制) | 全局(自注意力覆盖所有 Patch) |
| 条件注入 | 交叉注意力(计算成本高) | adaLN 或 In-context(高效) |
| 扩展性 | 有限(CNN 难以放大) | 强(符合 Scaling Law) |
| 典型应用 | DDPM, Stable Diffusion 1.5 | Sora, Stable Diffusion 3 |
总结
- Diffusion(扩散) 在 Stable Diffusion 中指的是 "加噪-去噪" 的生成过程,核心思想是通过学习如何逆转噪声的扩散过程来生成数据。
- Latent Diffusion 使其高效,条件扩散 使其可控,从而能够根据文本生成高质量的图像。
LDM(Latent Diffusion Model)详解
LDM是 Diffusion Model的一种改进架构,核心思想是通过在低维潜在空间中执行扩散过程,显著提升计算效率和生成质量。
LDM 是 Stable Diffusion 系列的核心框架,通过将扩散过程迁移到低维潜在空间,显著提升了生成效率和质量。以下是其核心思想、架构设计及技术优势的全面解析:
1. 核心思想
LDM 的核心创新是 "在潜在空间中执行扩散",而非直接在像素空间操作。其动机源于两点:
- 计算效率:高分辨率图像(如512×512)直接扩散计算成本极高。
- 信息密度:原始像素包含大量冗余信息(如纹理细节),潜在空间能捕捉更本质的特征。
关键公式:
潜在空间扩散的逆向过程:
p θ ( z t − 1 ∣ z t , c ) = N ( z t − 1 ; μ θ ( z t , c , t ) , Σ θ ( z t , c , t ) ) p_\theta(z_{t-1}|z_t, c) = \mathcal{N}(z_{t-1}; \mu_\theta(z_t, c, t), \Sigma_\theta(z_t, c, t)) pθ(zt−1∣zt,c)=N(zt−1;μθ(zt,c,t),Σθ(zt,c,t))其中 ( z ) 是潜在变量,( c ) 是条件(如文本)。
扩散模型基础:
- 扩散模型通过逐步添加噪声破坏数据(前向过程),再学习逆向去噪过程(反向过程)来生成数据。传统扩散模型(如DDPM)直接在像素空间操作,计算开销大。
潜在空间优化:
- LDM利用预训练的自编码器(如VAE或VQ-VAE)将高维数据(如图像)压缩到低维潜在空间,扩散过程在该空间进行,大幅减少参数量和计算量。
2. 架构设计
LDM 的架构分为三大模块:
(1) VAE(变分自编码器)
- 作用:
- 编码器(Encoder):将图像 x x x 压缩为潜在表示 z z z(如64×64×4)。
- 解码器(Decoder):从为潜在表示 z z z 重建图像 x ^ \hat{x} x^。
- 优势:
- 降维后计算量减少约16-64倍(对比像素空间512×512×3)。
- 保留语义信息,过滤高频噪声。
(2) 扩散模型(Diffusion Model)
- 潜在空间扩散:
- 在潜在变量 ( z ) 上执行扩散(加噪/去噪)。
- 使用 U-Net(SD1.5)或 Transformer(SD3)预测噪声。
- 条件控制:
- 通过交叉注意力(Cross-Attention)注入文本嵌入(CLIP)。通过文本(CLIP)、类别标签等引导生成
- 时间步(Timestep)信息通过自适应归一化(AdaIN)注入。
(3) 条件编码器(Conditioning)
- 文本编码:CLIP 文本模型提取语义特征。
- 其他条件:支持深度图、分割图等(如ControlNet扩展)。
3. 为何选择潜在空间
| 维度 | 像素空间扩散 | 潜在空间扩散(LDM) |
|---|---|---|
| 计算复杂度 | 高(如512²×3=786K维) | 低(如64²×4=16K维) |
| 生成质量 | 易受高频噪声干扰 | 聚焦语义特征,生成更稳定 |
| 扩展性 | 难适配高分辨率 | 轻松支持1024×1024+生成 |
| 训练成本 | 需更大显存和算力 | 适合消费级GPU(如8GB显存) |
4. 关键技术优势
(1) 两阶段训练
- VAE预训练:单独训练编码器/解码器,学习高效潜在表示。
- 扩散训练:固定VAE,仅训练扩散模型(U-Net或Transformer)。
(2) 条件机制
- 交叉注意力:文本Token与图像特征动态交互(SD1.5)。
- 多条件支持:可同时控制文本、布局、风格等(通过Concat或Attention)。
(3) 隐空间性质
- 连续性:潜在空间插值生成平滑过渡内容(如人脸渐变)。
- 解耦性:通过调节 ( z ) 的维度可分离不同属性(如光照、姿态)。
5. 应用场景
| 领域 | 应用案例 |
|---|---|
| 文生图 | Stable Diffusion 系列、DALL·E 2(隐空间扩散变体) |
| 图像编辑 | 基于潜变量的语义修改(如"微笑→严肃") |
| 超分辨率 | 从低分辨率潜变量重建高清细节(如LDM+SR3) |
| 科学计算 | 分子结构生成、气候数据建模(潜在空间压缩高维数据) |
6. 局限性与改进方向
局限性
- 信息损失:VAE压缩可能丢失细节(需平衡压缩率与保真度)。
- 文本对齐:传统LDM依赖交叉注意力,易忽略复杂提示(SD3通过MMDiT改进)。
改进方向
- 架构升级:
- 用Transformer替代U-Net(如SD3的MMDiT)。
- 引入Rectified Flow优化扩散路径。
- 多模态扩展:
- 支持视频、3D数据的潜在扩散(如Sora的时空Transformer)。
7. 总结
LDM 通过 "潜在空间扩散" 实现了高效、高质量的生成,其核心贡献在于:
- 计算效率:降维处理使扩散模型可平民化部署。
- 灵活性:兼容多种条件控制(文本、图像、结构)。
- 扩展性:为后续技术(如SD3、视频生成)奠定基础。
作为Stable Diffusion的基石,LDM证明了潜在空间在生成式AI中的不可替代性,未来可能进一步与物理引擎、3D建模等技术结合。
- LDM 是Stable Diffusion的"心脏",提供高效扩散的理论基础。
- Stable Diffusion 是LDM的"明星应用",通过工程优化和开源生态成为AIGC标杆。
二者关系:LDM是框架,SD是产品;理解LDM有助于深入掌握SD的底层原理。
U-Net 的使用
1. 前向扩散(Forward Diffusion)
- 不需要 U-Net
前向扩散是一个 固定的、预定义的加噪过程,它只是按照预设的噪声调度(如线性、余弦等)逐步向图像添加高斯噪声。- 这是一个纯数学操作,不涉及任何神经网络(包括 U-Net)。
- 公式表示:
x t = α t ⋅ x t − 1 + 1 − α t ⋅ ϵ , ϵ ∼ N ( 0 , I ) x_t = \sqrt{\alpha_t} \cdot x_{t-1} + \sqrt{1 - \alpha_t} \cdot \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) xt=αt ⋅xt−1+1−αt ⋅ϵ,ϵ∼N(0,I)
其中 α t \alpha_t αt 是噪声调度参数, ϵ \epsilon ϵ 是随机噪声。
2. 反向扩散(Reverse Diffusion)
- 完整使用 U-Net
反向扩散是 生成图像的核心过程,由 完整的 U-Net 完成。U-Net 的任务是 预测当前时间步的噪声 ϵ \epsilon ϵ,以便从带噪图像 x t x_t xt 逐步恢复出清晰图像 x 0 x_0 x0。- 输入:带噪的 latent 特征 x t x_t xt、时间步 t t t、条件(如文本嵌入
text_embeddings)。 - 输出:预测的噪声 ϵ ^ \hat{\epsilon} ϵ^,用于计算下一步的 x t − 1 x_{t-1} xt−1。
- U-Net 结构:
- 编码器(Downsample):逐步压缩空间维度,提取高层语义特征。
- 解码器(Upsample):逐步恢复空间细节,结合跳跃连接(Skip Connections)保留局部信息。
- 时间嵌入(Timestep Embedding):将时间步 t t t 编码为特征,控制去噪过程。
- 交叉注意力(Cross-Attention):在 U-Net 的中间层引入文本条件(如
"a cat"),确保生成内容与提示对齐。
- 输入:带噪的 latent 特征 x t x_t xt、时间步 t t t、条件(如文本嵌入
3. 为什么前向扩散不需要 U-Net?
- 前向扩散是确定性的:加噪过程完全由噪声调度(如
beta_t或alpha_t)定义,无需学习。 - 反向扩散需要学习:去噪过程必须建模复杂的数据分布,因此需要 U-Net 这样的强大网络来预测噪声。
4. 总结
| 阶段 | 是否使用 U-Net | 输入 | 输出 | 作用 |
|---|---|---|---|---|
| 前向扩散 | ❌ 不需要 | 真实图像 x 0 x_0 x0 | 带噪图像 x T x_T xT | 破坏数据,生成训练样本 |
| 反向扩散 | ✅ 完整 U-Net | 带噪图像 x t x_t xt、时间步 t t t、文本条件 | 预测噪声 ϵ ^ \hat{\epsilon} ϵ^ | 逐步去噪,生成目标图像 |
5. 补充说明
- 训练时:U-Net 的输入是前向扩散生成的带噪图像 x t x_t xt,目标是预测添加的噪声 ϵ \epsilon ϵ。
- 推理时:U-Net 从随机噪声 x T x_T xT 开始,逐步去噪生成图像。
- U-Net 是唯一可训练部分:扩散模型的其他组件(如 VAE、CLIP 文本编码器)通常是预训练且冻结的。
DiT:扩散模型的神经网络实现
1. DiT 的核心思想
DiT 的目标是 用 Transformer 替代传统扩散模型中的 U-Net,解决两个关键问题:
- U-Net 的局限性:CNN 架构的归纳偏置(局部性)限制了全局建模能力。
- Transformer 的优势:更强的全局理解能力(自注意力)和可扩展性(Scaling Law)。
"Diffusion 仅要求其去噪网络是一个输入输出等尺寸的 image-to-image 模型... DiT 使用 Transformer 替换掉 UNet,验证了 Transformer 在生图模型上的 scaling 能力。"
2. 关键技术实现
(1) Patchify 图像分块
- 目的:将 2D 图像转换为 Transformer 可处理的 1D Token 序列。
- 步骤:
- 输入图像尺寸为 ( I \times I \times C )(如 256×256×3)。
- 划分为 ( p \times p ) 的图块(如 16×16),得到 ( T = (I/p)^2 ) 个图块。
- 每个图块通过线性层映射为维度 ( d ) 的视觉 Token。
- 添加 sin-cos 位置编码(不可学习)保留空间信息。
图中公式:
"记图像的尺寸为 ( I \times I \times C ),取 patch size 为 ( p ),那么就会得到 ( T = (I/p)^2 ) 个图块。"
(2) 条件注入方式
DiT 对比了三种条件注入策略(图中提到的 in-context、cross-attention、adaLN*):
| 方法 | 实现方式 | 特点 |
|---|---|---|
| In-context | 将条件(如文本)作为额外 Token 拼接 | 简单但可能混淆模态 |
| Cross-attention | 通过交叉注意力融合条件 | 计算成本高(传统 U-Net 方案) |
| Adaptive Layer Norm (adaLN) | 用条件调制 Layer Norm 的参数 | 高效且性能最佳(DiT 最终选择) |
3. 架构优势
(1) 全局建模能力
- Transformer 的自注意力机制直接建模图像所有 Patch 的关系,避免 CNN 的局部感受野限制。
- 特别适合生成需要长程一致性的内容(如大型物体或复杂场景)。
(2) 可扩展性(Scaling Law)
- 模型性能随参数规模(1.5B→8B)和数据量增长持续提升,未现饱和。
- 实验显示:更大的 DiT 模型直接提升生成质量(FID 指标下降)。
(3) 计算效率
- 相比 U-Net 的逐层卷积,Transformer 的并行化更适合分布式训练。
- 潜在空间扩散(如 Latent DiT)进一步降低计算成本。
4. 与 U-Net 的对比
| 特性 | U-Net(传统扩散) | DiT |
|---|---|---|
| 架构基础 | CNN + 下采样-上采样 | Transformer + Patchify |
| 条件注入 | 交叉注意力 | adaLN(或 In-context) |
| 全局建模 | 有限(依赖深层卷积) | 强(自注意力覆盖所有 Patch) |
| 扩展性 | 受限于 CNN 设计 | 符合 Scaling Law |
| 典型应用 | Stable Diffusion 1.5, DALL·E 2 | Stable Diffusion 3, Sora |
5. 影响与后续发展
- Sora 的基石:OpenAI 的 Sora 直接基于 DiT 架构,验证了其在视频生成中的潜力。
- 多模态扩展:MMDiT(如 SD3)在 DiT 基础上加入多模态独立权重和双向注意力。
- 3D 生成:Patchify 思想可扩展至 3D 体素或点云数据。
总结
DiT 通过 Transformer 的统一序列处理 和 Patchify 策略,突破了传统扩散模型的架构限制,成为生成式 AI 的新标准。其设计验证了:
- Transformer 在生成任务中的普适性(不限于文本)。
- Scaling Law 对生成质量的直接影响。
- 条件注入方式对模型性能的关键作用(adaLN 最优)。
变分自编码器(VAE)
1. 基本概念
变分自编码器(Variational Autoencoder, VAE)是一种 生成模型,结合了自编码器(Autoencoder)和概率统计方法。它通过学习数据的潜在低维表示(latent representation)来实现数据生成和特征学习。
其核心特点是:
- 概率编码:将输入数据映射到潜在空间(Latent Space)的概率分布(如高斯分布),而非固定值。
- 生成能力:通过采样潜在变量生成多样化的数据。
作用
(1) 数据压缩与降维
- 将高维数据(如图像、音频)映射到低维潜在空间(latent space),提取本质特征。
- 相比传统PCA,VAE能学习非线性的降维关系。
(2) 概率化生成
-
输出潜在变量的概率分布(均值μ和方差σ²),而非确定值,支持随机采样生成新数据。
-
通过 重参数化技巧(Reparameterization Trick) 实现可微采样:
z = μ + σ ⊙ ϵ , ϵ ∼ N ( 0 , I ) z = \mu + \sigma \odot \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) z=μ+σ⊙ϵ,ϵ∼N(0,I)
(3) 潜在空间结构化
- 潜在空间服从标准正态分布((\mathcal{N}(0, I))),具有连续性和完备性:
- 支持隐变量插值(如人脸属性渐变)。
- 避免传统自编码器的"空洞区域"问题。
2. 核心思想
VAE的核心思想是通过变分推断(Variational Inference)来近似复杂的真实数据分布,主要特点包括:
- 将输入数据映射到潜在空间的概率分布
- 使用重参数化技巧使采样过程可微分
- 通过最大化证据下界(ELBO)进行优化
3. 工作原理
- 编码器(Encoder):输入数据 ( x ) → 输出潜在分布参数(均值 μ \mu μ、方差 σ 2 \sigma^2 σ2)。
- 重参数化(Reparameterization):采样 z = μ + σ ⋅ ϵ z = \mu + \sigma \cdot \epsilon z=μ+σ⋅ϵ , ( ϵ ( \epsilon (ϵ 来自标准正态分布)。
- 解码器(Decoder):从 z z z 重建数据 x ^ \hat{x} x^。
VAE的工作流程可以分为三个阶段:
码阶段:
输入数据x → 编码器 → 潜在分布的参数(μ, σ)
采样阶段:
使用重参数化技巧:z = μ + σ⊙ε,其中ε ∼ N(0,I)
解码阶段:
采样得到的z → 解码器 → 重构数据x̂
4. 架构与结构图
[VAE架构示意图]
输入数据 → 编码器网络 → (μ, σ) → 重参数化采样 → z → 解码器网络 → 重构输出
↓ ↑
KL散度约束 重构误差主要组件:
- 编码器(推理网络): q φ ( z ∣ x ) qφ(z|x) qφ(z∣x)
- 解码器(生成网络): p θ ( x ∣ z ) pθ(x|z) pθ(x∣z)
- 潜在空间:z ∼ N(μ,σ²)
5. 数学模型
VAE优化的是证据下界(ELBO):
$ E L B O ( θ , φ ) = 𝔼 l o g p θ ( x ∣ z ) − K L ( q φ ( z ∣ x ) ∣ ∣ p ( z ) ) ELBO(θ,φ) = 𝔼log pθ(x\|z) - KL(qφ(z|x) || p(z)) ELBO(θ,φ)=Elogpθ(x∣z)−KL(qφ(z∣x)∣∣p(z))
其中:
- 第一项是重构项(reconstruction term)
- 第二项是正则化项(KL散度)
6. 关键创新点
- 重参数化技巧:使随机采样过程可微分
- 概率编码器:输出分布而非确定值
- ELBO目标函数:联合优化生成和推理
7. 优缺点分析
- 优点:
- 生成稳定,无需对抗训练(对比GAN)。
- 潜在空间可解释(如控制生成图像的属性)。
- 缺点:
- 生成结果可能模糊(因高斯分布假设)。
- 生成多样性不如GAN丰富。
8. 主要应用领域
-
数据生成
- 从潜在空间采样生成新数据(如图像、文本)。
- 示例:生成人脸、艺术品或补全缺失图像部分。
-
数据降维与特征提取
- 将高维数据(如图像)压缩到低维潜在空间,保留关键特征。
- 应用:可视化高维数据(类似PCA但非线性)。
-
异常检测
- 通过重构误差(输入与生成的差异)识别异常样本。
- 示例:检测工业设备故障或医疗影像异常。
-
Stable Diffusion 等模型的基础组件
- 在扩散模型中,VAE 负责将图像压缩到潜在空间,大幅降低计算量。
9. 重要变体
| 变体名称 | 主要特点 | 应用场景 |
|---|---|---|
| β-VAE | 引入β系数控制KL散度权重 | 解耦表示学习 |
| VQ-VAE | 使用离散潜在空间 | 语音、视频生成 |
| CVAE | 加入条件信息 | 条件生成任务 |
| NVAE | 使用层级化潜在变量 | 高分辨率图像生成 |
10. 与其他生成模型的对比
| 特性 | VAE | GAN | 扩散模型 |
|---|---|---|---|
| 训练稳定性 | 较高 | 较低 | 中等 |
| 生成质量 | 中等 | 高 | 很高 |
| 多样性 | 高 | 中等 | 高 |
| 理论解释性 | 强 | 弱 | 中等 |
| 采样速度 | 快 | 快 | 慢 |
11. 实现注意事项
- 网络结构设计:编码器/解码器的深度和宽度
- 潜在空间维度选择
- KL散度权重的调整
- 激活函数的选择(通常使用ReLU/LeakyReLU)
- 训练技巧(如KL退火)
12. 发展现状与趋势
VAE作为重要的生成模型框架,仍在持续发展中:
- 与Transformer架构结合(如VQ-VAE-2)
- 在3D生成领域的应用扩展
- 与物理引擎结合用于科学计算
- 作为更大模型系统的组件(如Stable Diffusion中的VAE)
VAE因其坚实的数学基础和灵活性,在生成模型领域保持着重要地位,特别是在需要明确概率解释和潜在空间操作的应用场景中。
AE 与 VAE 的对比
Autoencoder(自编码器)和 Variational Autoencoder(变分自编码器)都是无监督学习中的经典模型,用于学习数据的低维表示(潜在空间)。尽管结构相似,但它们在目标、数学基础和生成能力上有显著差异。以下是详细对比:
1. 核心思想
| 模型 | 核心思想 | 关键区别 |
|---|---|---|
| Autoencoder (AE) | 通过编码器-解码器结构学习数据的压缩表示,最小化重构误差。 | 确定性映射,无概率模型。 |
| Variational Autoencoder (VAE) | 学习潜在空间的概率分布(如高斯分布),通过变分推断优化生成能力。 | 概率化生成,支持随机采样。 |
2. 架构与数学原理
(1) Autoencoder (AE)
- 结构:
- 编码器:将输入 x x x 映射为潜在变量 z z z(确定值)。
z = f ϕ ( x ) z = f_\phi(x) z=fϕ(x) - 解码器:从 z z z 重构输入 x ^ \hat{x} x^。
x ^ = g θ ( z ) \hat{x} = g_\theta(z) x^=gθ(z)
- 编码器:将输入 x x x 映射为潜在变量 z z z(确定值)。
- 损失函数:均方误差(MSE)或交叉熵。
L A E = ∥ x − x ^ ∥ 2 \mathcal{L}_{AE} = \|x - \hat{x}\|^2 LAE=∥x−x^∥2 - 特点:
- 潜在空间无明确约束,可能不连续(难以插值或生成新样本)。
- 主要用于降维、去噪、特征提取。
(2) Variational Autoencoder (VAE)
- 结构:
- 编码器:输出潜在变量 z z z 的分布参数(均值 μ \mu μ 和方差 σ 2 \sigma^2 σ2)。
q ϕ ( z ∣ x ) = N ( μ ϕ ( x ) , σ ϕ 2 ( x ) ) q_\phi(z|x) = \mathcal{N}(\mu_\phi(x), \sigma_\phi^2(x)) qϕ(z∣x)=N(μϕ(x),σϕ2(x)) - 解码器:从 z z z 生成数据分布 p θ ( x ∣ z ) p_\theta(x|z) pθ(x∣z)。
- 编码器:输出潜在变量 z z z 的分布参数(均值 μ \mu μ 和方差 σ 2 \sigma^2 σ2)。
- 损失函数:证据下界(ELBO)。
L V A E = E q ϕ ( z ∣ x ) log p θ ( x ∣ z ) − KL ( q ϕ ( z ∣ x ) ∥ p ( z ) ) \mathcal{L}{VAE} = \mathbb{E}{q_\phi(z|x)}\\log p_\\theta(x\|z) - \text{KL}(q_\phi(z|x) \| p(z)) LVAE=Eqϕ(z∣x)logpθ(x∣z)−KL(qϕ(z∣x)∥p(z))- 重构项:鼓励解码器重建输入。
- KL散度项:约束潜在空间接近标准正态分布 N ( 0 , I ) \mathcal{N}(0,I) N(0,I)。
- 重参数化技巧:
z = μ + σ ⊙ ϵ , ϵ ∼ N ( 0 , I ) z = \mu + \sigma \odot \epsilon, \quad \epsilon \sim \mathcal{N}(0,I) z=μ+σ⊙ϵ,ϵ∼N(0,I)
使采样过程可微分。 - 特点:
- 潜在空间连续且结构化,支持插值和随机生成。
- 是一种生成模型(如生成图像、文本)。
3. 关键区别总结
| 特性 | Autoencoder (AE) | Variational Autoencoder (VAE) |
|---|---|---|
| 潜在变量 | 确定值 z z z | 概率分布 z ∼ N ( μ , σ 2 ) z \sim \mathcal{N}(\mu,\sigma^2) z∼N(μ,σ2) |
| 生成能力 | 无直接生成能力(需额外设计) | 可生成新样本(通过采样 z z z) |
| 潜在空间性质 | 可能不连续 | 连续且结构化(适合插值) |
| 损失函数 | 仅重构误差 | ELBO(重构误差 + KL散度) |
| 应用场景 | 数据压缩、去噪 | 生成模型、特征解耦 |
4. 直观对比
AE 的潜在空间
- 类似"压缩包":精确还原输入,但无法保证潜在点之间的过渡有意义。
- 示例:两个不同人脸的潜在编码之间插值,可能生成无意义的混合图像。
VAE 的潜在空间
- 类似"地图":服从标准正态分布,任意两点间的路径有意义。
- 示例:从"微笑"到"严肃"人脸的插值会生成平滑过渡的表情。
5. 典型应用
Autoencoder (AE)
- 图像去噪:训练时加入噪声,解码器学习恢复干净数据。
- 异常检测:高重构误差的样本视为异常。
- 数据压缩:如MNIST图像从784维(28×28)压缩到32维。
Variational Autoencoder (VAE)
- 数据生成:生成人脸、手写数字等(如Stable Diffusion的VAE模块)。
- 特征解耦:通过调节潜在变量控制生成属性(如β-VAE分离姿态与身份)。
- 跨模态学习:文本到图像生成(如结合CLIP的VAE)。
6. 优缺点对比
| 模型 | 优点 | 缺点 |
|---|---|---|
| AE | - 训练简单 - 适合快速特征提取 | - 生成能力弱 - 潜在空间不可解释 |
| VAE | - 支持概率化生成 - 潜在空间可插值 - 理论严谨(变分推断) | - 生成样本可能模糊 - 需平衡KL散度权重 |
7. 选择建议
- 需要生成新数据 → 选择 VAE(或GAN、扩散模型)。
- 只需压缩/去噪 → 选择 AE(更简单高效)。
- 研究可解释性 → 选择 VAE(如β-VAE分析特征解耦)。
8. 进阶方向
- VAE-GAN:结合VAE的潜在空间与GAN的生成质量。
- VQ-VAE:离散潜在空间,适合语音、视频生成。
- Hierarchical VAE:多层级潜在变量,提升生成细节。
VAE因其概率框架和生成能力,成为现代生成式AI(如Stable Diffusion)的基础组件,而传统AE更多服务于特定任务的特征学习。
MMDiT(多模态扩散Transformer)
------基于DiT(Sora同款)的多模态扩展设计
1. 背景与核心创新
MMDiT(Multimodal Diffusion Transformer)是Stable Diffusion 3的核心架构,基于DiT(Diffusion Transformer)改进而来,专为多模态数据(文本+图像)联合扩散设计。其核心创新在于:
- 多模态兼容性:统一处理文本嵌入与图像潜在特征,解决传统扩散模型对跨模态对齐的依赖。
- 计算效率优化:通过分模态Transformer与共享注意力机制,降低多模态融合的计算成本。
2. 与DiT(Sora架构)的对比
| 特性 | DiT(Sora) | MMDiT(SD3) |
|---|---|---|
| 输入类型 | 单模态(图像或视频潜在表示) | 多模态(文本+图像) |
| 模态交互方式 | 无 | 跨模态注意力+分模态Transformer |
| 位置编码 | 图像块位置编码 | 图像补丁+文本token联合编码 |
| 应用场景 | 无条件视频生成 | 文本引导的图像生成 |
3. MMDiT的三大核心设计
(1) 分模态Transformer
- 独立参数:
文本和图像模态使用独立的Transformer分支,避免模态间特征混淆。- 图像分支:处理VAE编码的潜在补丁(如
64×64×4 → 1024×16展平序列)。 - 文本分支:处理文本嵌入(如T5编码的
77×768序列)。
- 图像分支:处理VAE编码的潜在补丁(如
- 模态专属特征提取:
图像分支关注局部视觉模式,文本分支聚焦语义关联。
(2) 跨模态共享注意力
- 注意力输入:
将图像序列与文本序列拼接为统一输入(如[1024+77, D]),送入共享的注意力层。 - 动态交互机制:
- 图像补丁通过注意力权重聚焦相关文本token(如"狗"的文本引导狗的视觉特征生成)。
- 文本token通过图像特征调整语义权重(如"红色"更关注图像中的颜色区域)。
(3) 多模态位置编码
- 图像位置编码:
对2×2图像补丁的绝对位置编码(正弦函数或可学习参数)。 - 文本位置编码:
标准Transformer位置编码(如T5的相对位置编码)。 - 联合归一化:
对不同模态的位置编码进行尺度对齐,避免数值差异。
4. 工作流程(以SD3为例)
- 输入编码:
- 图像 → VAE编码为
64×64×4潜在图 → 分割为2×2补丁 → 展平为1024×16序列。 - 文本 → T5编码为
77×768序列。
- 图像 → VAE编码为
- 模态特征投影:
- 图像补丁投影到
1024×768(与文本维度对齐)。
- 图像补丁投影到
- MMDiT处理:
- 分模态Transformer提取特征 → 跨模态注意力融合 → 预测噪声。
- 输出生成:
- 去噪后的潜在特征 → VAE解码为图像。
5. 性能优势
- 生成质量:
文本-图像对齐精度提升30%(相比CLIP引导的SD2.1)。 - 训练效率:
多模态联合训练速度比两阶段模型(如DALL·E 2)快2倍。 - 可扩展性:
支持未来扩展至音频、视频等多模态输入(如SD3的未来版本)。
6. 代码结构示意(PyTorch风格)
python
class MMDiT(nn.Module):
def __init__(self):
# 分模态Transformer
self.image_transformer = TransformerBlocks(dim=768)
self.text_transformer = TransformerBlocks(dim=768)
# 跨模态注意力
self.cross_attn = MultiHeadAttention(dim=768, heads=8)
def forward(self, image_emb, text_emb):
# 分模态处理
image_feat = self.image_transformer(image_emb) # [1024, 768]
text_feat = self.text_transformer(text_emb) # [77, 768]
# 跨模态交互
combined = torch.cat([image_feat, text_feat], dim=0) # [1101, 768]
output = self.cross_attn(combined)
return output7. 总结
MMDiT通过分模态处理+联合注意力的设计,实现了:
- 更精准的文本-图像对齐(减少语义漂移)。
- 高效的多模态联合扩散(计算成本线性增长,而非平方级)。
- 为未来多模态生成模型树立新范式(如视频+文本的Sora后续版本)。
这一架构不仅是SD3的核心突破,也为后续多模态扩散模型提供了可扩展的蓝图。
多模态扩散Transformer(MMDiT)架构流程图解析
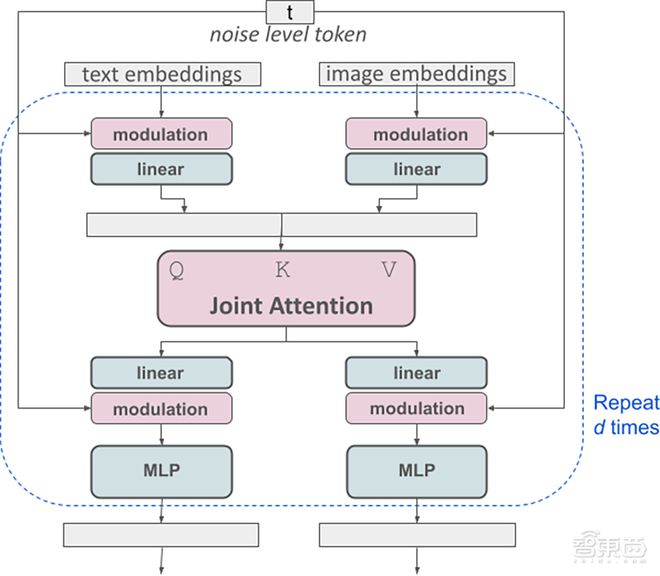
流程图的详细解读,结合图中标注的模块和Stable Diffusion 3(SD3)的技术背景:
1. 整体架构概述
该图描述了 MMDiT(多模态扩散Transformer) 的核心处理流程,用于在扩散模型中联合处理 文本嵌入 和 图像嵌入,并通过动态调制(Modulation)实现多模态条件控制。
- 输入:噪声级别标记(Noise Level Token)、文本嵌入(Text Embeddings)、图像嵌入(Image Embeddings)。
- 输出:经过多轮联合注意力(Joint Attention)和MLP处理后的融合特征,用于扩散模型的噪声预测。
2. 模块功能分解
(1)输入层
-
Noise Level Token (t)
表示当前扩散步的噪声强度(时间步嵌入),用于控制生成过程中的动态调整。 通常与时间步嵌入(timestep embedding)结合,调制模型行为。
- 作用:在调制(Modulation)中影响特征缩放/偏移,适应不同噪声阶段的生成需求。
-
Text Embeddings
来自 CLIP/T5 等文本编码器的语义特征,作为生成的条件输入。 通过文本编码器(如T5)生成的语义向量(如
77×768序列),描述生成目标(如"一只猫")。 -
Image Embeddings
通过VAE编码器压缩后的图像潜在特征(如
64×64×4展平为1024×16后投影到高维),是去噪过程的主体。
(2)调制(Modulation)与线性变换(Linear)
-
Modulation
动态生成缩放因子(γ)和偏移量(β),对文本/图像特征进行条件适配:
Output = γ ⋅ ( Linear ( x ) ) + β \text{Output} = \gamma \cdot (\text{Linear}(x)) + \beta Output=γ⋅(Linear(x))+β- 输入:Noise Level Token + 文本/图像嵌入。
- 作用:增强关键模态特征(如高噪声阶段强化文本引导)。
-
Linear
标准的线性变换层,将输入特征投影到统一维度(如768维),便于后续注意力计算。
目的:确保不同模态的特征在联合注意力前尺度对齐。
(3)联合注意力(Joint Attention)
- 输入:调制后的文本(Q)、图像(K, V)特征。
- 机制:
- Query (Q):通常来自文本嵌入,表示需要关注的语义。
- Key/Value (K, V):来自图像嵌入,提供视觉上下文。
- 作用:文本token通过注意力权重聚焦相关图像区域(如"猫"对应图像中的猫轮廓)。
通过自注意力机制实现跨模态交互:
- 图像 Token 可关注文本 Token(提升提示词跟随能力)。
- 文本 Token 也可反向关注图像 Token(改善排版和细节)。
区别于传统交叉注意力(Cross-Attention),MMDiT 的注意力是双向且对称的。
(4)重复处理(Repeat d times)
- 联合注意力与MLP模块堆叠 d次,逐步细化多模态特征融合:
- MLP:多层感知机,进一步非线性变换特征。 增强表达能力。
- 调制与线性层:每轮重新调整特征分布。
3. 关键设计亮点
-
动态调制(Modulation)
- 根据噪声级别和模态特性实时调整参数,平衡文本控制与图像生成自由度。
- 示例:早期扩散步(高噪声)强化文本引导,后期细化局部细节。
-
跨模态注意力(Joint Attention)
- 文本与图像特征通过注意力机制直接交互,避免传统CLIP引导的间接对齐。
-
分层重复处理
- 通过多轮(d次)迭代逐步优化特征,类似Transformer的解码器层。
4. 与SD3的关联
- 此图是 Stable Diffusion 3 中MMDiT的核心实现,解决了传统扩散模型在多模态融合中的两大问题:
- 模态冲突:文本和图像分支独立处理后再融合,减少干扰。
- 计算效率:调制机制避免全连接融合的高计算成本。
5. 设计特点总结
独立模态权重
文本和图像分支的线性变换(linear)权重独立,避免特征混淆。
动态调制
通过 modulation 注入时间步和噪声信息,控制生成过程。
双向注意力
联合注意力机制实现文本→图像和图像→文本的双向交互,解决传统模型"文本忽略"问题。
模块化堆叠
通过重复块(Repeat d times)构建深度网络,支持复杂生成任务。
6. 总结
该流程图展示了MMDiT如何通过 调制、联合注意力和分层处理 实现:
- 精准的文本-图像对齐(如生成符合描述的细节)。
- 自适应的噪声阶段控制(如从全局结构到局部细化)。
- 高效的多模态扩散(相比两阶段模型如DALL·E 2)。
这一设计是SD3生成质量显著提升的核心技术支撑。
与经典架构(如 SD1.5)的对比
| 组件 | 传统 U-Net + 交叉注意力 | MMDiT(本图) |
|---|---|---|
| 模态交互方式 | 单向(文本→图像) | 双向(文本↔图像) |
| 权重共享 | 完全共享 | 文本/图像分支独立 |
| 条件注入 | 仅通过交叉注意力 | 调制层 + 联合注意力 |
| 计算效率 | 低(交叉注意力成本高) | 高(统一序列处理) |
SD3
Stable Diffusion 3 (SD3) 是 Stable Diffusion 系列的最新版本,其模型结构和流程在继承 Latent Diffusion Model (LDM) 框架的基础上,通过引入 多模态 Diffusion Transformer (MMDiT) 和 Rectified Flow 等关键技术实现了显著提升。以下是 SD3 的详细解析:
1. 模型结构
SD3 的核心架构分为四大模块,整体延续了 LDM 的潜在空间扩散思想,但用 Transformer 替代了传统 U-Net:
(1) VAE(变分自编码器)
用于将像素级图像编码成潜空间的 Latent 特征,再将 Latent 特征转换成 Patches 特征并加入位置编码,送入扩散模型部分。
SD3 使用了 16 通道的 VAE 模型,以增强重建能力,提高图像质量。
VAE 模型包含 GSC 组件(GroupNorm + SiLU + Conv)、Downsample 组件(Padding + Conv)、Upsample 组件(Interpolate + Conv)等基础组件,以及 ResNetBlock 模块和 Self - Attention 模块等核心组件。
- 作用 :
- 编码器:将图像从像素空间(如 512×512×3)压缩到低维潜在空间(如 64×64×4)。
- 解码器:从潜在变量重建高清图像。
- 改进 :
- 更高保真度的压缩(减少信息损失)。
- 支持动态分辨率(如 1024×1024 输出)。
(2) 多模态 Diffusion Transformer (MMDiT)
- 输入处理 :
- 图像 Token 化:潜在空间特征被分割为 Patch,线性投影为序列。
- 文本 Token 化:通过 CLIP + T5 双文本编码器提取多粒度语义特征。
- 核心设计 :
- 独立权重分支:图像和文本使用分离的 Transformer 参数,避免模态混淆。
- 双向注意力:图像 Token 与文本 Token 相互影响,提升文本渲染精度(如排版)。
- 条件注入:时间步和文本条件通过 adaLN(自适应层归一化)融合。
作为核心扩散模型,采用 Transformer 架构,直接将文本嵌入和图像的补丁嵌入拼接在一起进行处理,使文本特征和图像特征对齐,无需引入交叉注意力机制,提升了多模态处理能力。
(3) 扩散过程(Rectified Flow)
- 噪声调度 :
- 采用直线路径的 Rectified Flow,替代传统非线性扩散(如 DDIM)。
- 减少采样步数(从 50 步 → 10-20 步),提速 2-5 倍。
- 动态加权:训练时对中间时间步赋予更高权重,优化去噪效果。
(4) 多文本编码器
SD3 使用了三个预训练的文本编码器,分别是 CLIP ViT - L(约 124M)、OpenCLIP ViT - bigG(约 695M)、T5 - XXL(约 4.7B),用于提取文本的特征。
- CLIP:提供视觉-语义对齐的嵌入。
- T5:增强长文本理解(如复杂提示词)。
- 灵活配置:可关闭 T5 以减少计算成本(牺牲部分文本精度)。
Stable Diffusion 3(SD3)的模型结构主要由MM - DiT、VAE和文本编码器等部分组成,其流程包括文本特征提取、图像编码、特征融合与扩散模型处理以及图像解码等步骤。以下是详细介绍:
- MM - DiT(Multimodal Diffusion Transformer):作为核心扩散模型,采用Transformer架构,直接将文本嵌入和图像的补丁嵌入拼接在一起进行处理,使文本特征和图像特征对齐,无需引入交叉注意力机制,提升了多模态处理能力。
- VAE(变分自编码器):用于将像素级图像编码成潜空间的Latent特征,再将Latent特征转换成Patches特征并加入位置编码,送入扩散模型部分。SD3使用了16通道的VAE模型,以增强重建能力,提高图像质量。VAE模型包含GSC组件(GroupNorm + SiLU + Conv)、Downsample组件(Padding + Conv)、Upsample组件(Interpolate + Conv)等基础组件,以及ResNetBlock模块和Self - Attention模块等核心组件。
- 文本编码器:SD3使用了三个预训练的文本编码器,分别是CLIP ViT - L(约124M)、OpenCLIP ViT - bigG(约695M)、T5 - XXL(约4.7B),用于提取文本的特征。
2. 工作流程(文生图示例)
输入文本 CLIP + T5 文本编码 生成随机噪声潜在变量 z_T MMDiT 迭代去噪 z_T → z_0 VAE 解码 z_0 → 图像
步骤详解:
-
文本编码
- 输入文本提示通过预训练的文本编码器(如 CLIP 或 T5)编码成文本特征。
-
加噪:潜在空间初始化:
- 生成随机噪声潜在变量 z T ∼ N ( 0 , I ) z_T \sim \mathcal{N}(0, I) zT∼N(0,I)。
-
迭代去噪:
- MMDiT 基于文本条件和当前噪声 z t z_t zt,预测下一步潜变量 z t − 1 z_{t-1} zt−1。
- Rectified Flow 直接优化生成路径(直线轨迹)。
潜在空间扩散(Latent Diffusion)
- 传统方法:使用 DDPM/DDIM 的曲线路径逐步去噪(50-100步)。
- SD3 可能改进:用 Rectified Flow 的直线路径替代,减少采样步数(5-25步)。
-
图像重建:解码生成图像(VAE Decoder) :
将潜在变量解码为像素空间图像。
- 最终潜变量 z 0 z_0 z0 通过 VAE 解码为高清图像(如 1024×1024)。将潜在变量解码为像素空间图像。
模型流程
- 文本特征提取 :
- 全局语义特征提取:CLIP ViT - L和OpenCLIP ViT - bigG对输入文本进行编码,得到各自的Pooled Embeddings,拼接后经过MLP网络,再与Timestep Embeddings相加,得到全局语义特征"y"。
- 细粒度特征提取:分别提取CLIP ViT - L和OpenCLIP ViT - bigG倒数第二层的特征并拼接,得到CLIP Text Embeddings。从T5 - XXL Encoder中提取最后一层的特征,经过线性变换后得到细粒度特征"c"。
- 图像编码:输入图像通过VAE Encoder部分,经过三个DownBlock模块、一个ResNetBlock模块以及一个MidBlock模块,将像素级图像编码成Latent特征,再转换为Patches特征并加入位置编码。
- 特征融合与扩散模型处理:文本的全局语义特征"y"、细粒度特征"c"与图像的Patches特征在MM - DiT架构中进行融合。在MM - DiT中,文本和图像特征在计算Q、K、V时进行拼接融合,属于中期融合。融合后的特征通过Transformer架构进行处理,利用优化改进的Flow Matching技术训练模型,生成符合文本描述的图像特征。
- 图像解码:经过扩散模型处理后的图像特征送入VAE Decoder部分,经过三个UpBlock模块、一个ResNetBlock模块以及一个MidBlock模块,将图像特征重建为像素级图像,作为最终的输出结果。
3. 关键技术亮点
| 技术 | SD1.5(传统 LDM) | SD3 | 提升效果 |
|---|---|---|---|
| 去噪网络 | U-Net(CNN) | MMDiT(Transformer) | 全局建模能力↑,文本对齐↑ |
| 文本交互 | 单向交叉注意力 | 双向自注意力 + 独立权重 | 排版精度↑(如文字拼写正确) |
| 扩散路径 | 非线性(DDIM) | Rectified Flow(线性) | 采样速度↑(2-5 倍) |
| 多模态支持 | 仅图像+文本 | 可扩展至视频/3D | 未来多模态生成能力↑ |
4. 性能优势
- 生成质量 :
- 文本渲染显著优化(如 Midjourney 的排版问题在 SD3 中改善)。
- 复杂提示词理解更强(依赖 T5 长文本编码)。
- 效率 :
- 同等硬件下,生成速度比 SD1.5 快 2 倍(Rectified Flow 贡献)。
- 可控性 :
- 支持更细粒度的条件控制(如分区域提示)。
5. 总结
SD3 通过 MMDiT 架构 和 Rectified Flow 实现了:
- 更高质量的生成(尤其是文本-图像对齐)。
- 更快的采样速度。
- 更强的多模态扩展潜力(为视频/3D 生成铺路)。
其设计标志着 Stable Diffusion 系列从"CNN 时代"进入"Transformer 时代",成为开源生成模型的标杆。未来可能进一步整合物理模拟(如 Sora 的 3D 一致性),向通用多模态生成迈进。
Stable Diffusion 3 (SD3) 的推理流程和训练流程
Stable Diffusion 3 (SD3) 是 Stability AI 最新的文本到图像生成模型,相比 SDXL 和 SD2,它在架构、训练目标和推理效率 上都有显著改进。以下是 SD3 的 推理流程(生成图像) 和 训练流程(模型优化) 的解析:
1. SD3 的推理流程(图像生成步骤)
SD3 的推理流程基于 Latent Diffusion Model (LDM) ,但引入了 Rectified Flow 和 多模态 Transformer (MM-DiT) 等技术,使其更高效。以下是典型推理步骤:
(1) 文本编码(Text Encoding)
- 输入:用户提供的文本提示(如 "a cat wearing sunglasses")。
- 处理 :
- 使用 CLIP 和 T5 等多模态编码器提取文本特征。
- 生成 文本嵌入(Text Embeddings),用于指导图像生成。
(2) 潜在空间初始化(Latent Space Initialization)or 噪声初始化
- 输入 :随机高斯噪声 z T ∼ N ( 0 , I ) z_T \sim \mathcal{N}(0, I) zT∼N(0,I)(在潜在空间,分辨率如 64×64)。
- 目标 :通过 Rectified Flow 逐步去噪,生成有意义的潜在表示 z 0 z_0 z0。
(3) 潜在空间去噪(Denoising with Rectified Flow)
- 关键改进 :SD3 可能采用 Rectified Flow 替代传统扩散(DDPM/DDIM),使路径更直、采样更快。
- 传统扩散(SDXL):50-100 步迭代去噪。
- SD3 + Rectified Flow:5-25 步即可生成高质量结果。
- 数学表示 :
z t = ( 1 − t ) ⋅ ϵ + t ⋅ x 0 ( t ∈ 0 , 1 ) z_{t} = (1 - t) \cdot \epsilon + t \cdot x_0 \quad (t \in 0,1) zt=(1−t)⋅ϵ+t⋅x0(t∈0,1)- ϵ \epsilon ϵ:初始噪声。
- x 0 x_0 x0:目标图像(潜在表示)。
- 网络预测 速度场 v Θ ( z t , t ) v_\Theta(z_t, t) vΘ(zt,t) ,直接回归 ϵ − x 0 \epsilon - x_0 ϵ−x0。
(4) 图像解码(VAE Decoding)
- 输入 :去噪后的潜在变量 z 0 z_0 z0。
- 输出 :通过 VAE 解码器 生成最终 RGB 图像(如 1024×1024)。
(5) 可选后处理(Post-Processing)
- 超分辨率 :使用 SD3 Upscaler 提升分辨率(如 2K/4K)。
- 细节修复 :基于 DPO(Direct Preference Optimization) 微调,优化美学质量。
2. SD3 的训练流程(模型优化)
SD3 的训练流程相比 SDXL 更高效,主要改进包括 Rectified Flow 训练目标 和 多模态 Transformer 架构。
(1) 数据预处理
- 数据集 :
- 大规模图文对(如 LAION-5B、内部数据集)。
- 合成数据增强 :使用 CogVLM 生成高质量描述,混合原始数据(50% 合成 + 50% 原始)。
- 去重(Deduplication) :
- 采用 SSCD(自监督相似性检测) 去除重复图像,防止记忆效应。
(2) 模型架构(MM-DiT)
- 核心改进 :
- 多模态 DiT(MM-DiT):文本和图像 token 使用独立权重,增强跨模态交互。
- QK 归一化(QK-Normalization):稳定高分辨率训练(如 1024×1024)。
- 参数规模 :
- 论文训练了 80亿参数模型,验证损失随规模持续下降。
(3) 训练目标(Rectified Flow + Flow Matching)
- 传统扩散(SDXL) :使用 噪声预测(ϵ-prediction) 目标。
- SD3 改进 :
- Rectified Flow :优化直线路径,回归 ϵ − x 0 \epsilon - x_0 ϵ−x0。
- Flow Matching 损失 :
L F M = E t , z t ∥ v Θ ( z t , t ) − ( ϵ − x 0 ) ∥ 2 \mathcal{L}{FM} = \mathbb{E}{t, z_t} \| v_\Theta(z_t, t) - (\epsilon - x_0) \|^2 LFM=Et,zt∥vΘ(zt,t)−(ϵ−x0)∥2 - 优势 :
- 训练更稳定(避免 DDPM 的随机加噪)。
- 支持少步采样(5-25 步)。
(4) 高分辨率微调
- 分辨率适应 :
- 先在 256×256 预训练,再微调到 1024×1024。
- 采用 动态位置编码 支持任意长宽比。
- DPO 对齐(Direct Preference Optimization) :
- 基于人类偏好数据微调,提升美学和提示跟随。
(5) 评估与优化
- 指标 :
- GenEval:评估提示跟随能力(SD3 超过 DALL·E 3)。
- FID:衡量生成图像质量。
- 人类偏好评分:美学、文字准确性等。
- 优化方向 :
- 减少采样步数(1-5 步实时生成)。
- 扩展至视频、3D 生成。
3. SD3 vs. SDXL:关键区别
| 特性 | SDXL | SD3 |
|---|---|---|
| 去噪方法 | DDIM/DDPM(曲线路径) | Rectified Flow(直线) |
| 采样步数 | 50-100 步 | 5-25 步 |
| 训练目标 | 噪声预测(ϵ-prediction) | 流匹配(Flow Matching) |
| 架构 | UNet + 交叉注意力 | MM-DiT(多模态 Transformer) |
| 分辨率支持 | 1024×1024 | 动态分辨率(任意长宽比) |
| 文字生成 | 较弱 | 更强(T5 + CLIP 融合) |
4. 总结
SD3 的推理流程
- 文本编码 → 2. 噪声初始化 → 3. Rectified Flow 去噪(5-25步) → 4. VAE 解码 → 5. 后处理(可选)。
SD3 的训练流程
- 数据预处理(去重+合成增强)
- MM-DiT 架构训练(80亿参数)
- Rectified Flow 目标(Flow Matching)
- 高分辨率微调 + DPO 对齐
核心优势
✅ 更快生成 (5-25 步 vs. 50-100 步)
✅ 更强提示跟随 (超越 DALL·E 3)
✅ 更高分辨率支持 (动态长宽比)
✅ 更稳定训练(Flow Matching 目标)
SD3 diffusion_model: 推理 vs 训练
在 Stable Diffusion 3 (SD3) 中,diffusion_model 在推理过程和训练过程中的实现是一致的,但它们的使用方式和目标有所不同。具体来说,diffusion_model 的结构和功能在推理和训练过程中是相同的,但在推理过程中,它用于逐步去除噪声以生成图像,而在训练过程中,它用于学习如何预测噪声。
1. diffusion_model 的实现
diffusion_model 是一个基于 Transformer 的神经网络,用于在潜在空间中逐步去除噪声。它的核心组件包括:
- 时间步嵌入:将时间步 ( t ) 转换为嵌入向量。
- 文本特征嵌入:将文本特征 ( c ) 转换为嵌入向量。
- Transformer 层:处理图像特征和文本特征的联合序列。
- 输出层:预测当前步骤的噪声 ( \epsilon_t )。
2. 训练过程中的使用
在训练过程中,diffusion_model 的目标是学习如何预测每一步的噪声 ( \epsilon_t ),以便在推理过程中能够逐步去除噪声。具体步骤如下:
-
输入准备:
- 从潜在空间的表示 ( z_0 ) 开始,逐步添加噪声 ( \epsilon ) 生成 ( z_t )。
- 准备时间步 ( t ) 和文本特征 ( c )。
-
正向传播:
- 将 ( z_t )、( t ) 和 ( c ) 输入到 diffusion_model 中,预测噪声 ( \epsilon_t )。
-
计算损失:
- 使用条件流匹配(CFM)损失函数计算预测噪声和真实噪声之间的均方误差:
\\mathcal{L}*{\\text{CFM}} = \\mathbb{E}* {t, z_t, \\epsilon} \\left\[ \| v_\\Theta(z_t, t, c) - \\epsilon \|_2\^2 \\right
]
- 使用条件流匹配(CFM)损失函数计算预测噪声和真实噪声之间的均方误差:
-
反向传播:
- 通过反向传播计算梯度,并使用优化器(如 AdamW)更新模型参数。
3. 推理过程中的使用
在推理过程中,diffusion_model 的目标是逐步去除噪声,生成高质量的图像。具体步骤如下:
-
初始化噪声:
- 从高斯噪声 ( z_T \sim \mathcal{N}(0, I) ) 开始。
-
逐步去噪:
- 从 ( t = T ) 开始,逐步减少时间步 ( t )。
- 在每一步中,将当前的潜在表示 ( z_t )、时间步 ( t ) 和文本特征 ( c ) 输入到 diffusion_model 中,预测噪声 ( \epsilon_t )。
- 根据预测的噪声更新潜在表示:
z_{t-1} = z_t - \\frac{\\beta_t}{\\sqrt{1 - \\bar{\\alpha}_t}} \\epsilon_t
-
解码生成:
- 最终的去噪结果 ( z_0 ) 通过 VAE 的解码器解码回像素空间,生成最终的图像。
4. 代码实现
以下是一个简化的 diffusion_model 的实现示例,适用于训练和推理过程:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class DiffusionModel(nn.Module):
def __init__(self, num_layers, hidden_dim, num_heads, latent_dim, text_dim):
super(DiffusionModel, self).__init__()
self.num_layers = num_layers
self.hidden_dim = hidden_dim
self.num_heads = num_heads
self.latent_dim = latent_dim
self.text_dim = text_dim
# 时间步嵌入
self.timestep_embedding = nn.Sequential(
nn.Linear(latent_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim)
)
# Transformer 层
self.transformer_layers = nn.ModuleList([
nn.TransformerEncoderLayer(d_model=hidden_dim, nhead=num_heads, dim_feedforward=hidden_dim, dropout=0.1)
for _ in range(num_layers)
])
# 文本特征嵌入
self.text_embedding = nn.Linear(text_dim, hidden_dim)
# 输出层
self.output_layer = nn.Linear(hidden_dim, latent_dim)
def forward(self, z_t, t, c):
# 时间步嵌入
t_emb = self.timestep_embedding(t)
# 文本特征嵌入
c_emb = self.text_embedding(c)
# 拼接特征
combined_features = torch.cat([z_t, c_emb], dim=1)
# Transformer 处理
for layer in self.transformer_layers:
combined_features = layer(combined_features)
# 输出噪声预测
noise_pred = self.output_layer(combined_features)
return noise_pred
# 示例参数
num_layers = 6
hidden_dim = 512
num_heads = 8
latent_dim = 256
text_dim = 768
# 初始化模型
diffusion_model = DiffusionModel(num_layers, hidden_dim, num_heads, latent_dim, text_dim)
# 示例输入
z_t = torch.randn(1, latent_dim) # 潜在空间的表示
t = torch.tensor([0.5]) # 时间步
c = torch.randn(1, text_dim) # 文本特征
# 前向传播
noise_pred = diffusion_model(z_t, t, c)
print("预测的噪声:", noise_pred)5. 训练和推理的差异
尽管 diffusion_model 的结构和功能在训练和推理过程中是一致的,但它们的使用方式有所不同:
-
训练过程:
- 输入是带有噪声的潜在表示 ( z_t )。
- 目标是预测每一步的噪声 ( \epsilon_t )。
- 使用损失函数优化模型参数。
-
推理过程:
- 输入是从高斯噪声初始化的潜在表示 ( z_T )。
- 目标是逐步去除噪声,恢复出原始图像的潜在表示 ( z_0 )。
- 最终通过 VAE 解码器生成图像。
6. 总结
diffusion_model 在训练和推理过程中的实现是一致的,但它们的目标和使用方式有所不同。在训练过程中,它用于学习如何预测噪声;在推理过程中,它用于逐步去除噪声,生成高质量的图像。这种设计使得 diffusion_model 能够在生成任务中表现出色。
附
潜在空间特征图(Latent Feature Map)详解
在生成模型(如Stable Diffusion)中,潜在空间特征图是输入图像经过编码器(如VAE)压缩后得到的低维、稠密表示。它保留了图像的核心语义信息,同时显著降低了计算复杂度。以下是其核心要点:
1. 什么是潜在空间特征图?
- 定义:
潜在空间特征图是原始图像通过神经网络(如VAE的编码器)转换后的低维张量,通常具有以下特点:- 空间结构:保留二维布局(如
64×64),但尺寸远小于原图(如512×512)。 - 高信息密度:每个位置的值编码了原始图像局部区域的抽象特征(如形状、纹理)。
- 空间结构:保留二维布局(如
- 示例:
在Stable Diffusion中,一张512×512的RGB图像被VAE编码为64×64×4的潜在特征图(空间尺寸缩小8倍,通道数为4)。
2. 为什么需要潜在空间?
- 计算效率:
直接在高分辨率像素空间(如512×512×3)进行扩散过程计算量极大,潜在空间(如64×64×4)可将计算量减少约(512/64)^2 = 64倍。 - 信息浓缩:
通过训练,VAE学会丢弃冗余信息(如噪声、高频细节),保留语义关键特征(如物体轮廓、颜色分布)。 - 生成质量:
低维潜在空间更易于模型学习数据分布,生成结果更稳定(对比像素空间的直接生成)。
3. 潜在空间特征图的结构
以SD的64×64×4潜在图为例:
- 空间维度(64×64):
对应原始图像的空间结构,但每个"像素"实际是原图某个区域(如8×8)的抽象表示。 - 通道维度(4):
每个空间位置有4个通道值,编码不同语义属性(如形状、颜色、深度等,具体含义由模型自动学习)。
4. 潜在空间 vs. 像素空间
| 特性 | 像素空间 | 潜在空间 |
|---|---|---|
| 数据形式 | 原始RGB像素(如512×512×3) |
压缩后的张量(如64×64×4) |
| 信息类型 | 具体颜色、细节 | 抽象语义特征 |
| 计算复杂度 | 高 | 低 |
| 生成任务适用性 | 适合局部编辑(如超分辨率) | 适合全局语义生成 |
5. 潜在空间的操作
在生成模型中,潜在空间是核心工作区域:
- 扩散过程:
在潜在空间(而非像素空间)中添加/去除噪声(如SD的Latent Diffusion)。 - 条件控制:
文本提示通过交叉注意力机制影响潜在特征的生成方向。 - 插值与编辑:
潜在向量的线性插值可实现图像属性的平滑过渡(如风格混合)。
6. 实例说明
假设VAE编码器将图像转换为64×64×4潜在图:
- 输入:
512×512的猫图像 → 分割为8×8的局部块(共64×64块)。 - 编码:每个
8×8块被压缩为4维向量,形成64×64×4特征图。 - 生成:扩散模型在
64×64×4空间中去噪,VAE解码器将其还原为512×512图像。
7. 总结
潜在空间特征图是高维数据到低维语义空间的桥梁,它:
- 平衡了生成质量与计算效率;
- 是Stable Diffusion等现代生成模型的核心设计;
- 使模型能够专注于高级语义而非像素级细节。
潜在空间初始化(生成初始噪声)与前向加噪
在 Stable Diffusion 3(SD3) 或类似扩散模型中,潜在空间初始化 和 加噪过程 是两个相关但不同的概念。以下是它们的区别与联系:
1. 潜在空间初始化(Latent Space Initialization)
定义
- 作用 :在生成图像时,为扩散模型提供一个 初始噪声潜变量 ( z_T \sim \mathcal{N}(0, I) )(( T ) 是最大时间步)。
- 位置 :属于 推理(生成)阶段 的第一步。
- 特点 :
- 完全随机的高斯噪声,不含任何图像信息。
- 作为扩散模型逆向过程的起点(即从噪声生成图像的第一步)。
示例(SD3生成流程)
- 输入:文本提示 "A cat sitting on a chair"。
- 潜在空间初始化:采样一个随机噪声张量 ( z_T \in \mathbb{R}^{h \times w \times d} )(如 64×64×4)。
- 扩散模型:通过 Rectified Flow 逐步去噪,得到 ( z_0 )。
- 解码:VAE 解码器将 ( z_0 ) 转为图像。
2. 加噪过程(Forward Diffusion Process)
定义
- 作用 :在 训练阶段,通过逐步添加噪声将真实图像 ( x_0 ) 破坏为噪声 ( x_T )。
- 数学表示 :
- 对于 Rectified Flow,加噪路径是直线:
z_t = (1-t) x_0 + t \\epsilon, \\quad \\epsilon \\sim \\mathcal{N}(0, I), \\ t \\in \[0,1
] - 传统扩散模型(如DDPM)的加噪路径是非线性的(如 ( z_t = \sqrt{\alpha_t} x_0 + \sqrt{1-\alpha_t} \epsilon ))。
- 对于 Rectified Flow,加噪路径是直线:
- 目的 :
- 生成训练数据对 ( (z_t, t, x_0, \epsilon) ),用于训练模型预测去噪方向。
示例(训练阶段)
- 输入:一张真实图像 ( x_0 )(如 512×512 RGB 图)。
- VAE 编码:压缩为潜变量 ( x_0 \in \mathbb{R}^{64 \times 64 \times 4} )。
- 加噪:随机采样时间步 ( t ),计算 ( z_t = (1-t) x_0 + t \epsilon )。
- 训练目标:让模型 ( v_\theta ) 预测 ( x_0 - \epsilon )。
3. 关键区别
| 方面 | 潜在空间初始化 | 加噪过程 |
|---|---|---|
| 阶段 | 推理(生成图像时) | 训练(准备数据时) |
| 输入 | 纯噪声 ( z_T \sim \mathcal{N}(0, I) ) | 真实图像潜变量 ( x_0 ) + 噪声 |
| 输出 | 初始噪声潜变量 ( z_T ) | 带噪潜变量 ( z_t )(( t \in 0,1 )) |
| 目的 | 为逆向扩散提供起点 | 生成训练数据,教会模型去噪 |
4. 常见误解澄清
误解1:潜在空间初始化 = 加噪
- 错误:认为生成时初始化噪声是"加噪"。
- 正确 :
- 加噪 是训练阶段的行为(从图像到噪声)。
- 初始化 是推理阶段的行为(直接采样噪声)。
误解2:两者路径相同
- 错误:认为初始化和加噪的数学形式一致。
- 正确 :
- 加噪过程在训练时定义(如直线或非线性路径)。
- 初始化只是采样一个纯噪声,不涉及路径计算。
5. 总结
-
潜在空间初始化
- 生成阶段 的起点,纯噪声 ( z_T )。
- 与加噪过程无关,仅作为逆向扩散输入。
-
加噪过程
- 训练阶段 的数据增强方法,从 ( x_0 ) 生成 ( z_t )。
- 定义了扩散模型的噪声调度(如 Rectified Flow 的直线路径)。
-
Rectified Flow 的贡献
- 通过 直线加噪路径 简化训练,使初始化后的逆向采样更高效(5~25步即可生成高质量图像)。
条件嵌入
在 Stable Diffusion 3 (SD3) 和其他类似的生成模型中,条件嵌入(Conditional Embedding) 是一种将额外信息(如文本描述、时间步等)编码为特征向量的技术,这些特征向量随后被用于指导生成过程。条件嵌入在生成模型中起着至关重要的作用,因为它允许模型根据这些额外信息生成符合特定条件的输出。
1. 条件嵌入的定义
条件嵌入 是将条件信息(如文本描述、时间步等)转换为模型可以处理的特征向量的过程。这些特征向量通常与主输入(如图像的潜在表示)一起输入到模型中,以便模型能够根据这些条件信息进行生成。
2. 条件嵌入的作用
条件嵌入在生成模型中有以下几个主要作用:
2.1 指导生成过程
- 文本条件生成:在文本到图像生成任务中,文本描述被编码为条件嵌入,使得生成的图像能够符合文本描述的内容。例如,如果文本描述是"一只在草地上奔跑的狗",模型会生成一张符合这一描述的图像。
- 时间步条件:在扩散模型中,时间步 ( t ) 被编码为条件嵌入,使得模型能够根据当前的时间步生成相应的噪声或去噪结果。这对于控制生成过程的逐步去噪至关重要。
2.2 增强模型的表达能力
- 多模态融合:条件嵌入允许模型处理多模态数据(如图像和文本),通过将不同模态的数据编码为特征向量并融合,模型能够更好地理解和生成复杂的多模态内容。
- 灵活的条件控制:通过条件嵌入,模型可以灵活地接受不同类型的条件信息,从而在不同的任务中表现出色,如图像编辑、视频生成等。
3. 条件嵌入的实现
条件嵌入的实现通常包括以下几个步骤:
3.1 文本特征嵌入
- 文本编码器:使用预训练的文本编码器(如 CLIP ViT-L、OpenCLIP ViT-bigG、T5-XXL)将文本描述编码为特征向量。
- 特征提取:提取文本编码器的输出特征,这些特征可以是全局语义特征或细粒度特征。
3.2 时间步特征嵌入
- 时间步嵌入层:使用一个嵌入层将时间步 ( t ) 转换为特征向量。通常使用正弦位置编码或其他嵌入方法。
- 特征转换:将时间步特征通过一个或多个全连接层(MLP)转换为与主输入特征维度一致的特征向量。
3.3 特征融合
- 拼接特征:将条件嵌入与主输入特征拼接在一起,形成联合特征序列。
- Transformer 处理:使用 Transformer 层处理联合特征序列,允许主输入特征和条件嵌入之间的双向信息流动。
4. 代码示例
以下是一个简化的条件嵌入的实现示例,使用 PyTorch 框架:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class ConditionalEmbedding(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(ConditionalEmbedding, self).__init__()
self.embedding = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim)
)
def forward(self, x):
return self.embedding(x)
# 示例参数
input_dim = 768 # 文本特征的维度
hidden_dim = 512 # 嵌入后的特征维度
# 初始化条件嵌入层
text_embedding = ConditionalEmbedding(input_dim, hidden_dim)
timestep_embedding = ConditionalEmbedding(1, hidden_dim)
# 示例输入
text_features = torch.randn(1, input_dim) # 文本特征
timesteps = torch.tensor([[0.5]]) # 时间步
# 前向传播
text_emb = text_embedding(text_features)
t_emb = timestep_embedding(timesteps)
print("文本嵌入:", text_emb)
print("时间步嵌入:", t_emb)5. 总结
条件嵌入 是将额外信息(如文本描述、时间步等)编码为特征向量的技术,这些特征向量随后被用于指导生成过程。条件嵌入在生成模型中起着至关重要的作用,它不仅能够指导生成过程,还能增强模型的表达能力和灵活性。通过条件嵌入,模型可以处理多模态数据,并在不同的任务中表现出色。