HENGSHI SENSE 提供了 中心化的数据集市管理 ,即数据集市的功能:
数据集市,支持层级结构的数据集市建立,按用户,用户组,组织架构授权,将数据分配到合适的人。支持统一的计算字段,计算指标管理,在企业内部实现关键 KPI 的统计逻辑,统计算法在部门之间保持统一口径,告别数据不一致。完善的数据权限设定,支持数据连接权限,行权限的多种权限模式,满足不同的权限管理场景。
本章节以 coffee 分析 数据为例,详细描述提供了数据集市功能后,用户在数据集市中建立了数据集后的后续使用功能。
在使用本章节的文档之前,请先明确不同用户角色在数据集市可见性上的限制:
| 用户角色 | 数据集市是否可见 | 数据集市中创建文件夹 | 数据集市文件夹中创建数据集 |
|---|---|---|---|
| 系统管理 | 不可见 | ----- | ----- |
| 数据管理 | 可见 | 无法创建、无提示 | ----- |
| 数据分析 | 不可见 | ----- | ----- |
| 数据查看 | 不可见 | ----- | ----- |
| 系统管理+数据管理 | 可见 | 可创建 | 可创建任意数据集 |
| 系统管理+数据分析 | 不可见 | ----- | ----- |
| 系统管理+数据查看 | 不可见 | ----- | ----- |
| 数据管理+数据分析 | 可见 | 无法创建、无提示 | ----- |
| 数据管理+数据查看 | 可见 | 无法创建、无提示 | ----- |
| 数据分析+数据查看 | 不可见 | ----- | ----- |
| 系统管理+数据管理+数据分析 | 可见 | 可创建 | 可建任意数据集 |
| 系统管理+数据管理+数据查看 | 可见 | 可创建 | 可建任意数据集 |
| 系统管理+数据分析+数据查看 | 不可见 | ----- | ----- |
| 数据管理+数据分析+数据查看 | 可见 | 无法创建、无提示 | ----- |
| 系统管理+数据管理+数据分析+数据查看 | 可见 | 可创建 | 可建任意数据集 |
上述表格记录了任意用户对数据集市的可见性,以及在数据集市中可以进行的操作。
拥有 系统管理+数据管理 的角色,可以在数据集市中创建文件夹、数据包;拥有 数据管理 角色的用户,无法在数据集市中新建文件夹、数据包,但是可以在获得授权的文件夹中创建数据集。
以下,以 coffee 分析 为例,简单介绍从应用集市中完成数据处理,至在数据可视化中使用该数据包中数据完成图表创建的整个过程。
-
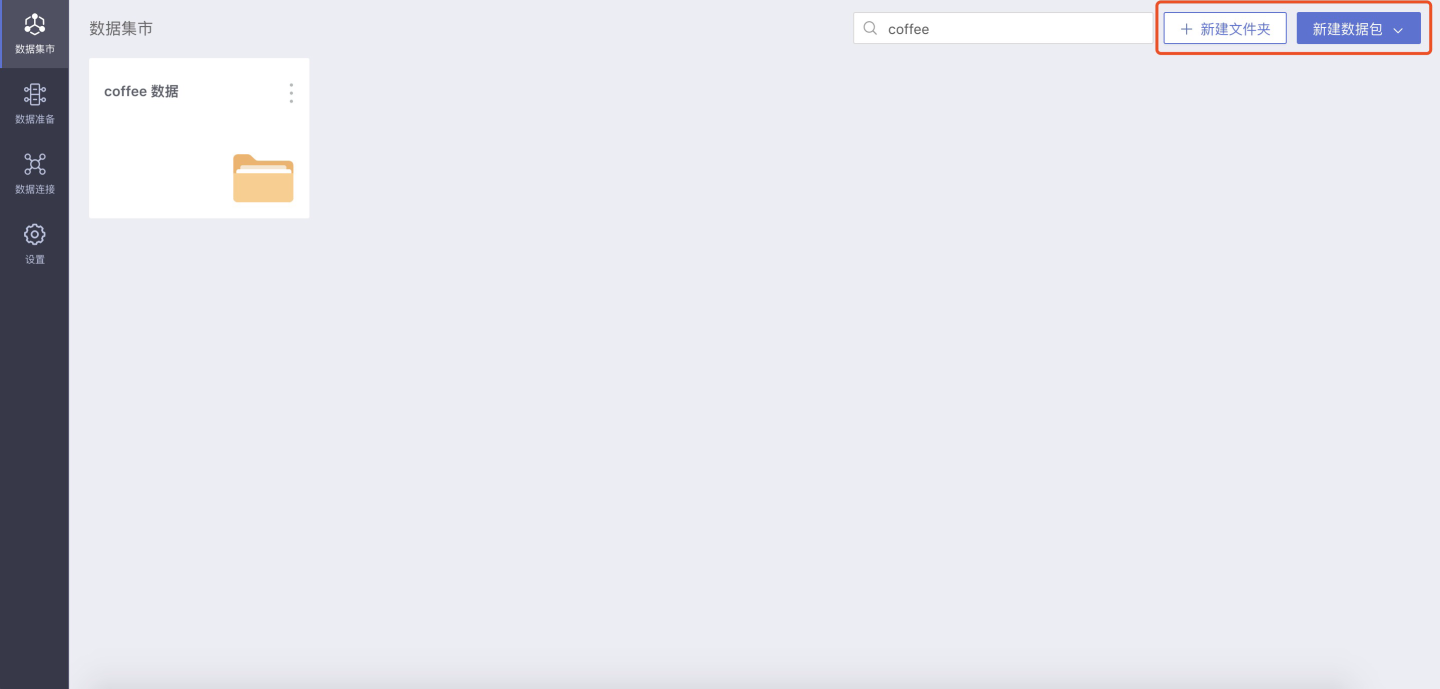
新建文件夹/数据包
拥有 系统管理+数据管理 的角色在数据集市中新建文件夹、数据包
-
设置该文件夹或数据包的权限管理
完成上述步骤后,在应用集市列表页封面上的三点菜单中,可以设置该文件夹或数据包的权限管理:
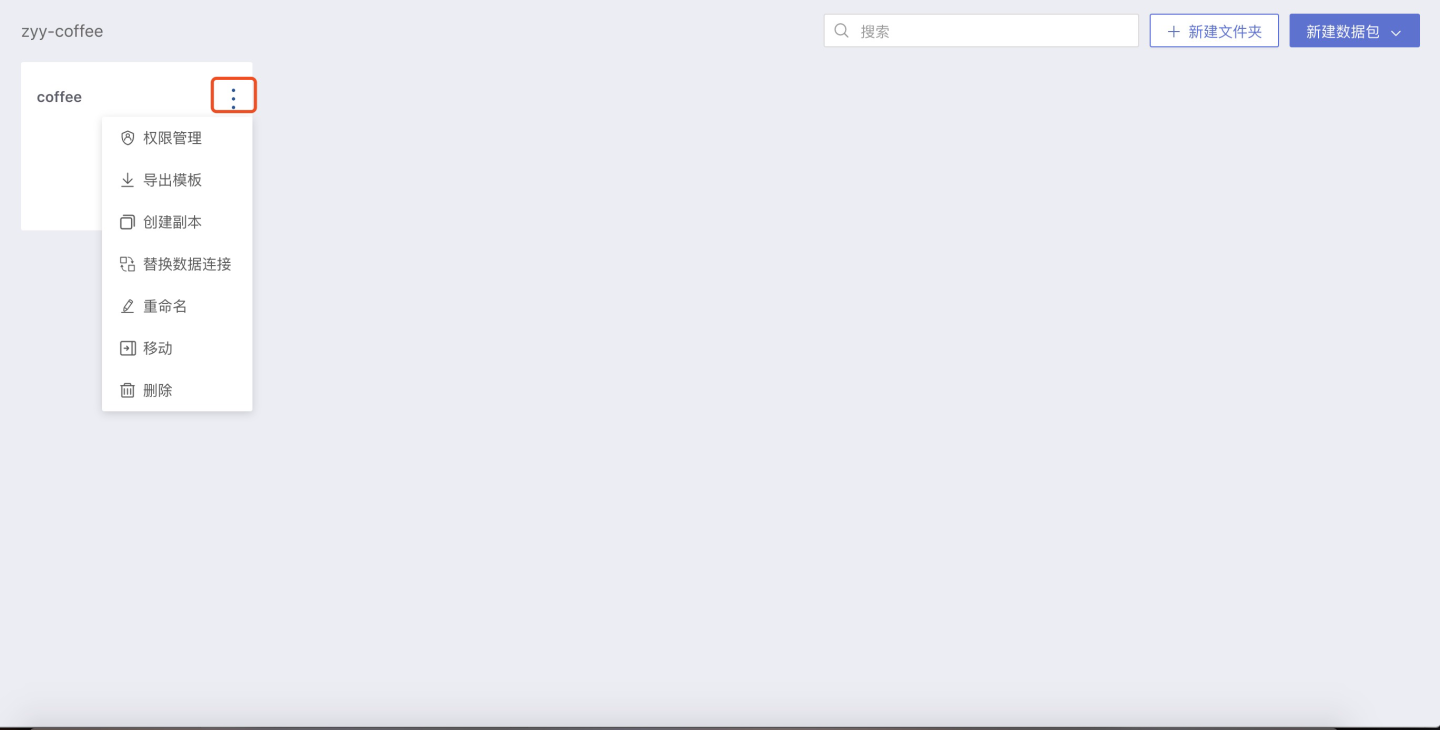
点击 权限管理 ,在弹出的窗口中设置该数据包的管理、查看权限:
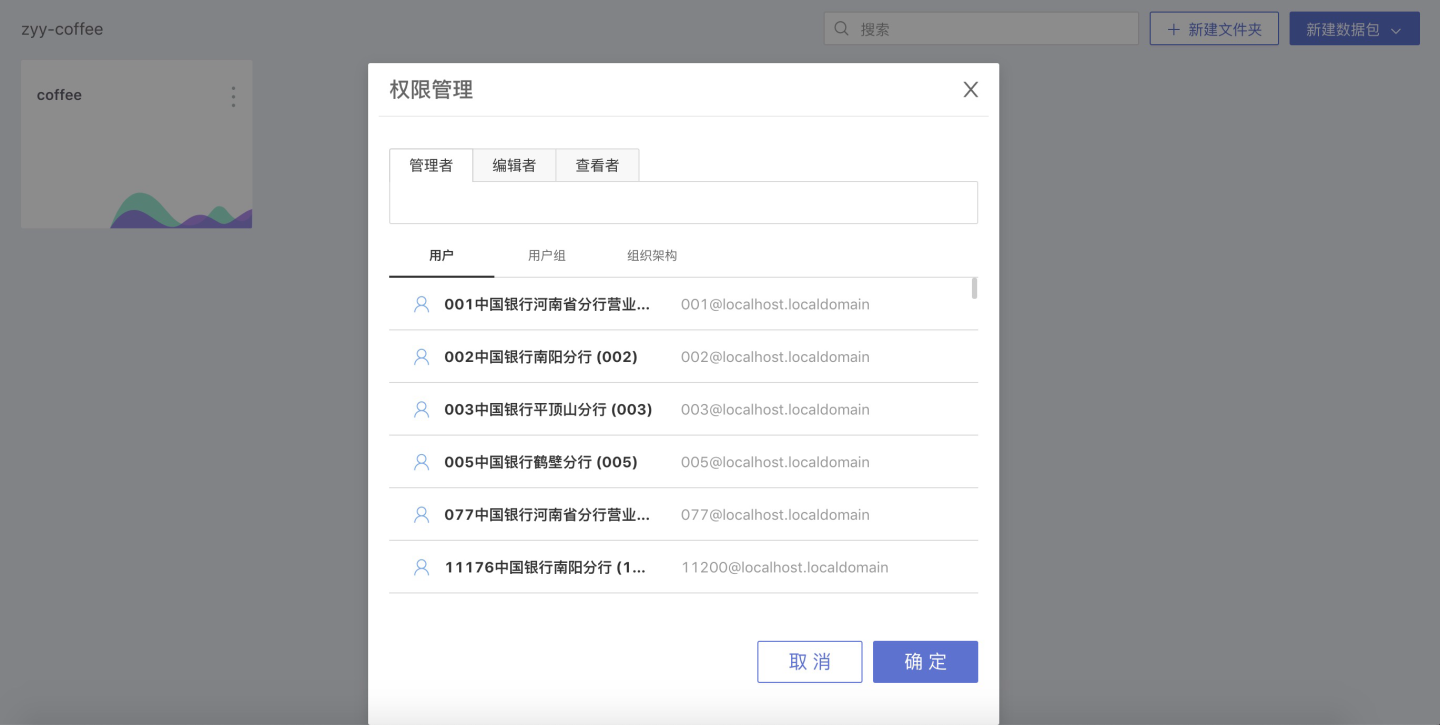
管理者:与文件夹的创建着拥有相同的权限,可以修改文件夹的访问权限、查看、使用、编辑文件夹内的数据包以及数据包内的数据集;
编辑者:只能查看、使用、编辑文件夹内的数据包以及数据包内的数据集;
查看着:只能查看、使用文件夹内的数据集以及数据包内的数据集。
按照各公司不同部门间的不同职责设置具体的权限。
-
新建文件夹或数据包
在文件夹中,可以继续新建文件夹或者新建数据包,拥有 管理者 、编辑者 权限的用户,都可以在该文件夹中创建文件夹、数据包
-
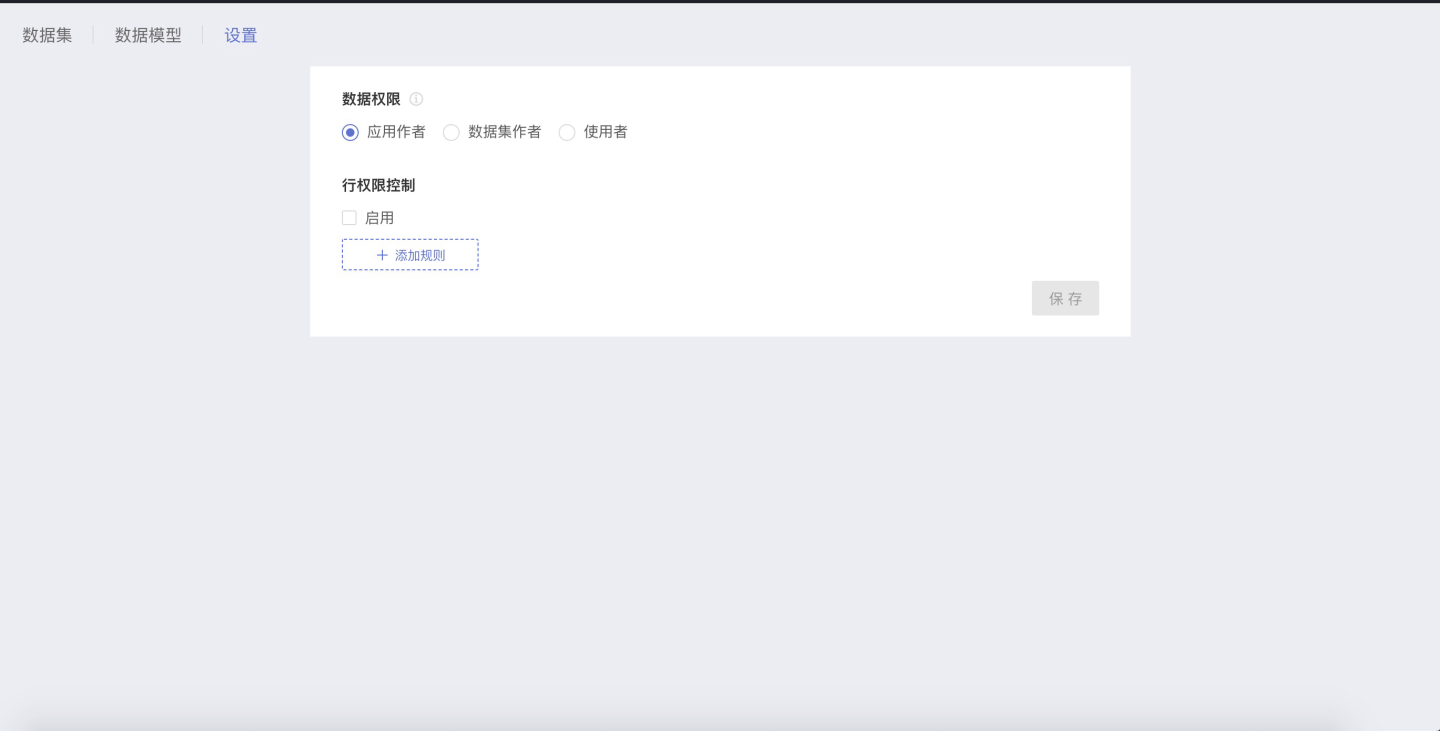
设置数据包中数据集的据权限
在数据包的 设置 页面,可以设置用户查看、使用该数据包时使用什么账户的权限查看数据集数据。拥有该数据包所在的文件夹的 管理者 、编辑者 权限的用户,都可以在数据包中设置数据权限。
-
应用作者
访问应用的人看到的应用作者的数据,可设置权限控制。
不同用户在数据包中创建数据集时,均使用应用作者在数据连接上的数据权限,与自己在数据连接上的权限无关。
-
数据集作者
访问应用的人看到的是数据集作者的数据,可设置权限控制。
不同用户在数据包中创建数据时,均使用自己在数据连接上的数据权限,不同用户在查看、使用数据集时,按照数据集作者的权限获取数据。
-
使用者
访问应用的人看到的是自己的数据。
不同用户在数据包中创建数据集、查看、编辑数据集时,均使用自己在数据连接上的数据权限。
我们推荐用户在设置数据包的数据权限时,使用"应用作者*的数据权限。避免因为每个人的权限不同而导致的后续的数据集复制、多表联合等结果数据集无数据的情况。
数据权限使用"数据就作者"、"使用者"时,在使用的过程中,容易碰到疑惑:
A 用户创建数据集 A、B 用户创建数据集 B;
-
C 用户在做数据处理时,给 A、B 两个数据集创建了副本:
副本数据集内无数据:C 用户没有 A、B 数据集使用的数据连接的权限;
副本数据集内数据与 A、B 数据集数据完全不一致:C 用户在数据连接上的权限与 A、B 用户不一致;
-
D 用户做数据处理时,A、B 两个数据集做多表联合生成了 Fusion 数据集
Fusion 数据集无数据:D 用户对 A、B 数据集所在的数据连接中的表的权限不一致导致关联后,数据集无数据;
Fusion 数据集内数据与 A、B 数据集无任何重合:D 用户对 A、B 数据集所在的数据连接中的表的权限不一致导致关联后,数据集内数据与 A、B 数据集数据完全不重合;
-
在完成上述1~4的工作后,数据集市中文件夹的树形结构、文件夹/数据包的权限管理、数据包中数据集的数据权限已完成设置。即指定那些用户可以访问该文件夹/数据包、可以对文件夹/数据包执行什么操作、使用数据包中的那些数据
接下来则需要在数据包中完成数据处理即可
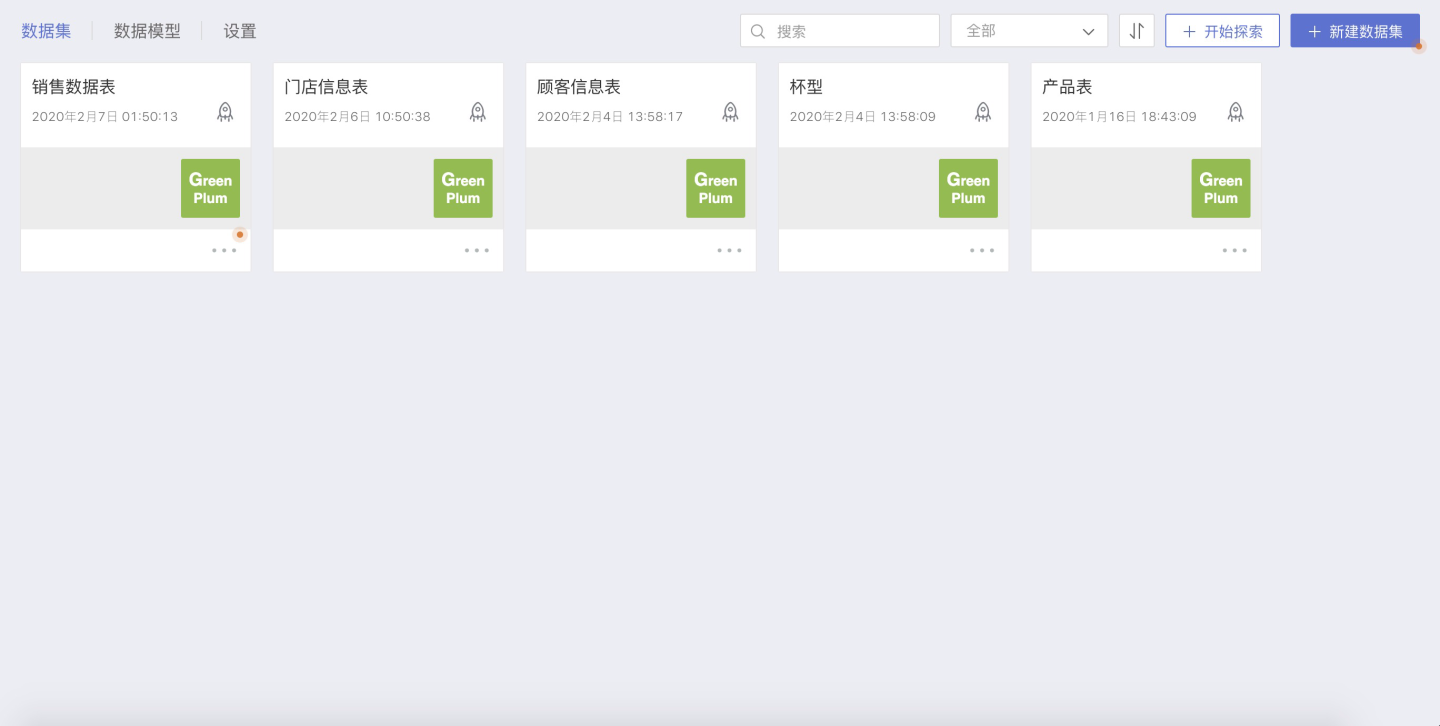
- 新建数据集
首先,在数据集市中需要创建数据集:
-
数据处理
-
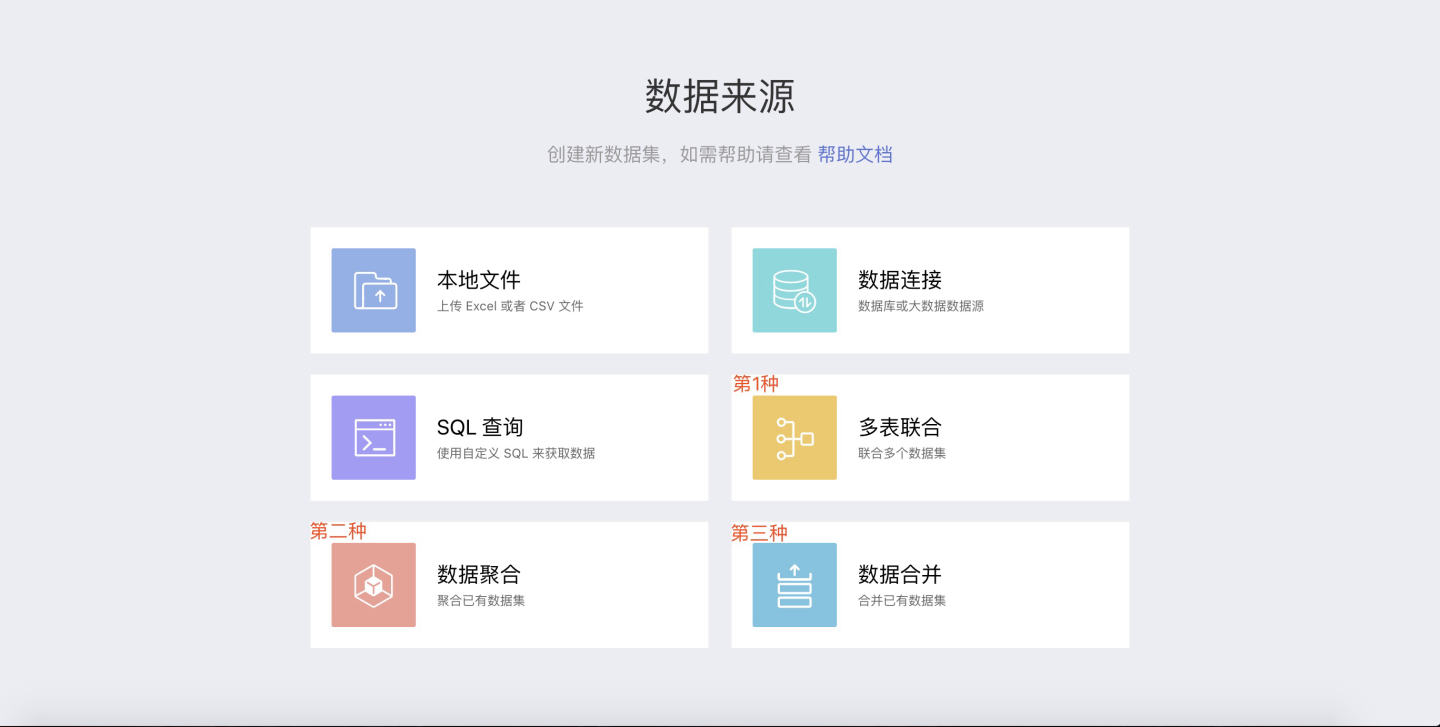
数据集的数据处理
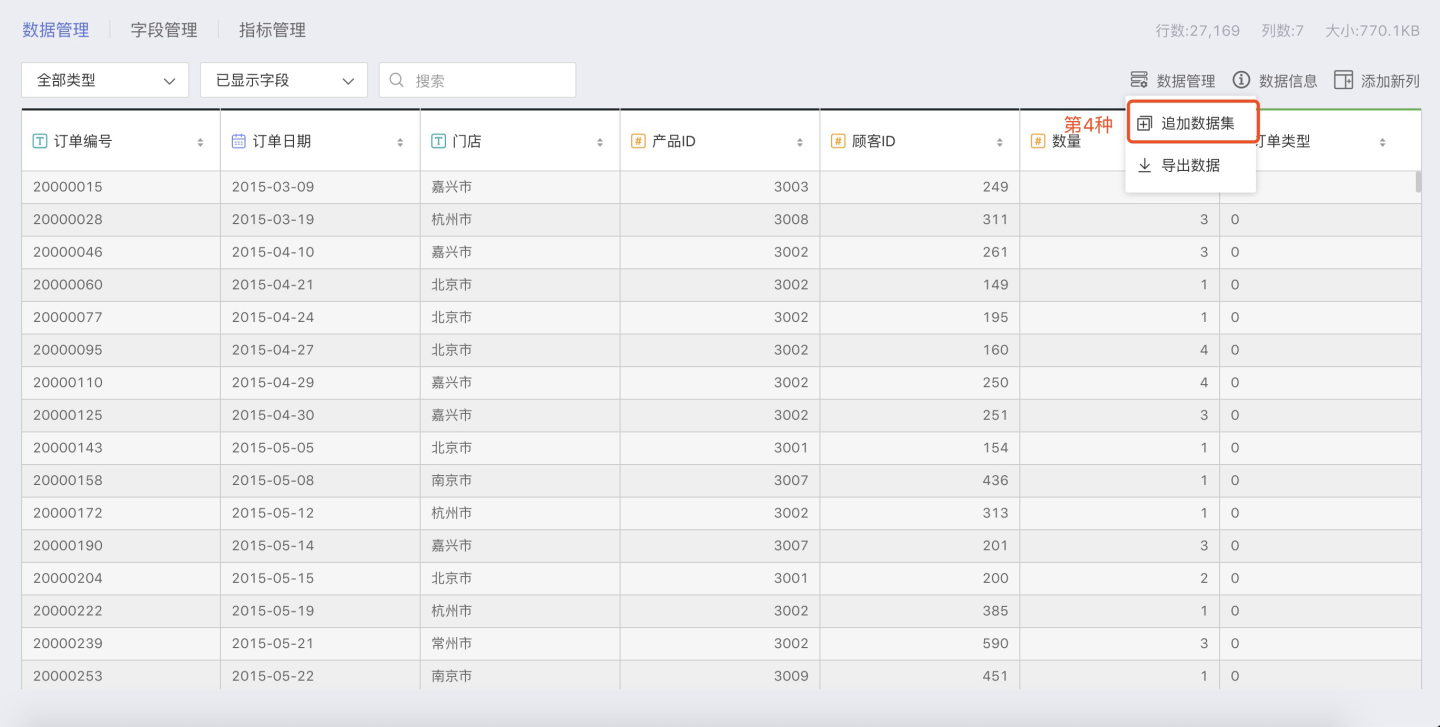
-
多表联合
SENSE 系统提供了强大的 FUSION 功能,通过数据集之间特定字段的意义对应关系。可将多个数据集通过多表联合处理后生成一张宽表。
-
-
数据聚合
在已创建数据集的基础上,通过数据聚合来创建的数据集,从原本的数据集中,只选择关注的字段生成新的数据集,适合对列较多的数据集进行"数据分析"。
-
数据合并
当需要将多个数据集的数据汇总到一个数据集中,可以使用数据功能。数据合并生成新的数据集。
-
数据追加
当需要将多个数据集的数据汇总到一个数据集中,可以使用数据功能。数据追加直接改变基础数据集,不生成新的数据集。
-
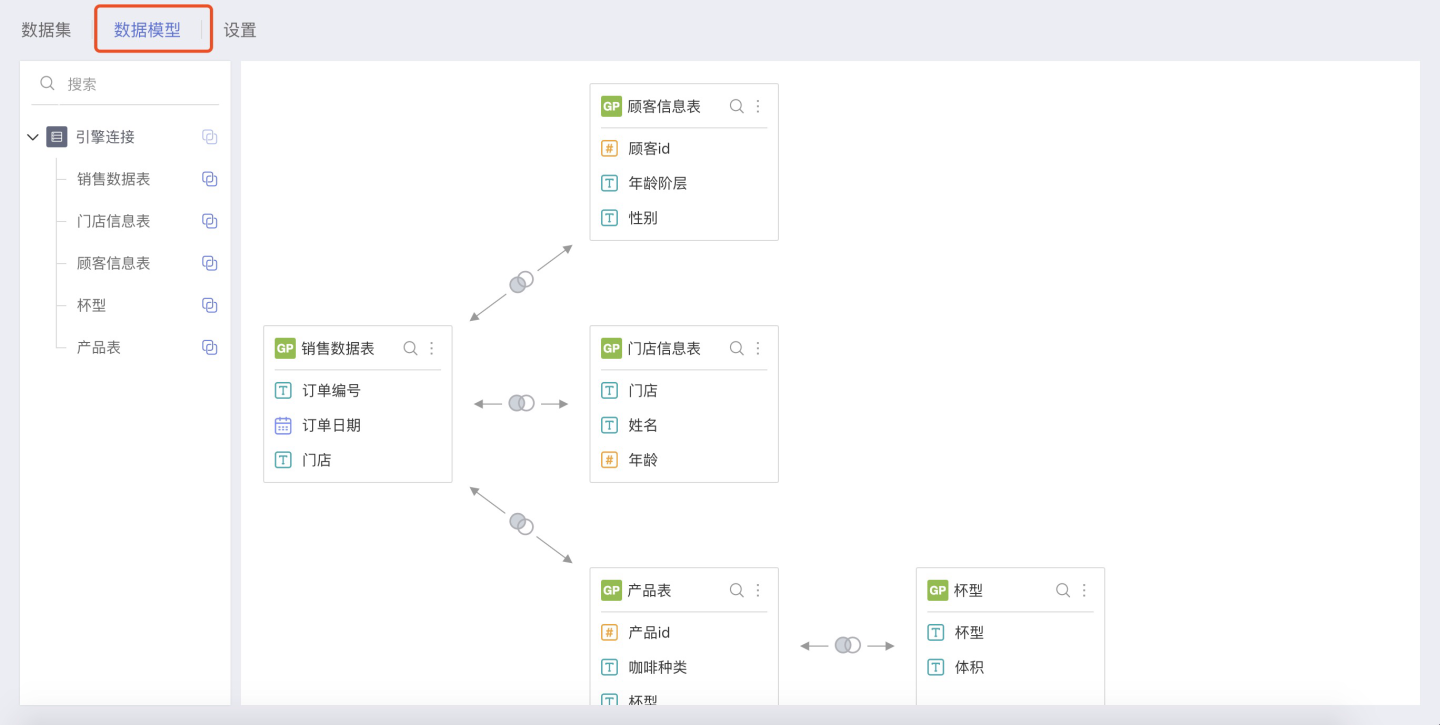
数据模型
数据模型,即关联分析模型,与为每一种关联分析建立一个数据集的方式相比,它能够提供给数据分析极大的自由度和敏捷性:随时编辑模型中的关联关系,新的模型关系能够立即影响分析结果。详解见数据模型
-
-
数据集内的数据处理
-
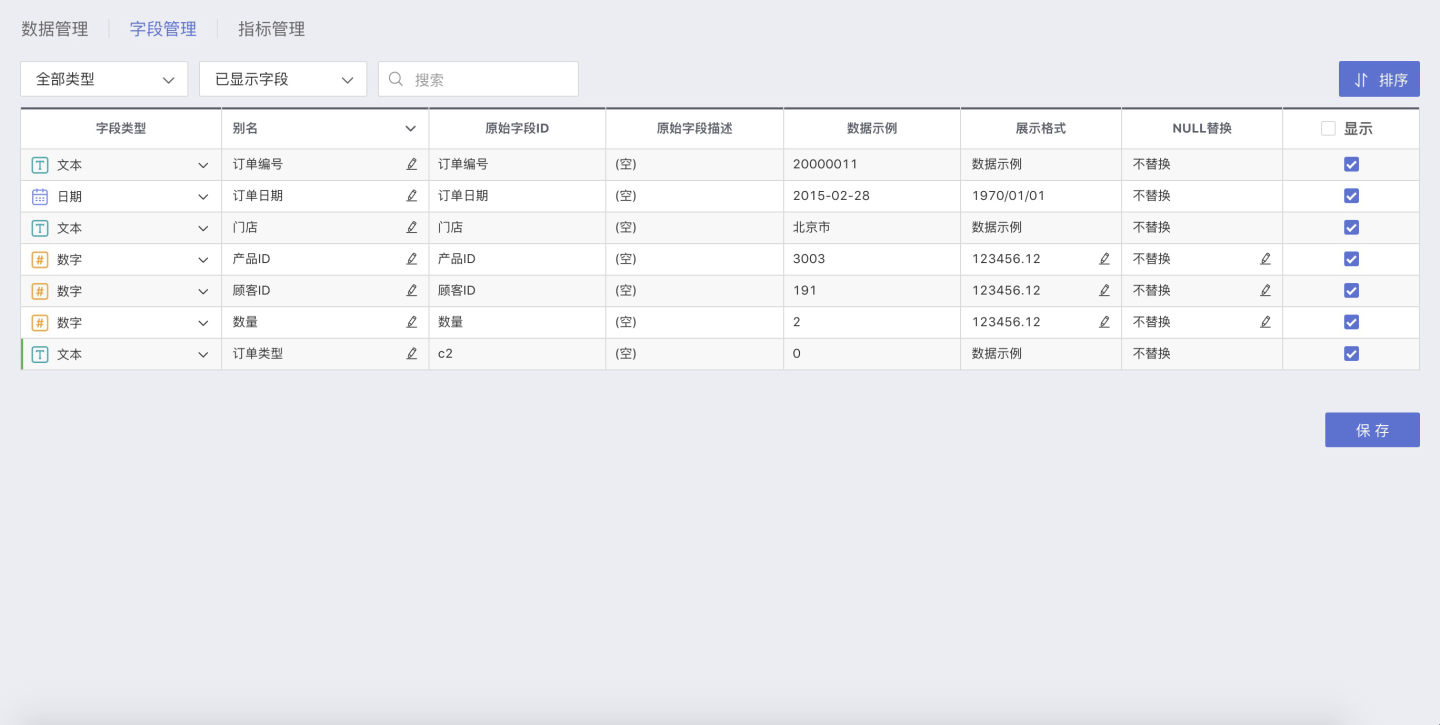
字段管理
字段管理为数据预处理的一大部分,包括:修改字段别名、批量修改字段名、修改字段类型及字段格式、设置是否显示等。
-
添加新列
添加新列为处理数据集中的原有字段,最终得到新的字段。
-
-
-
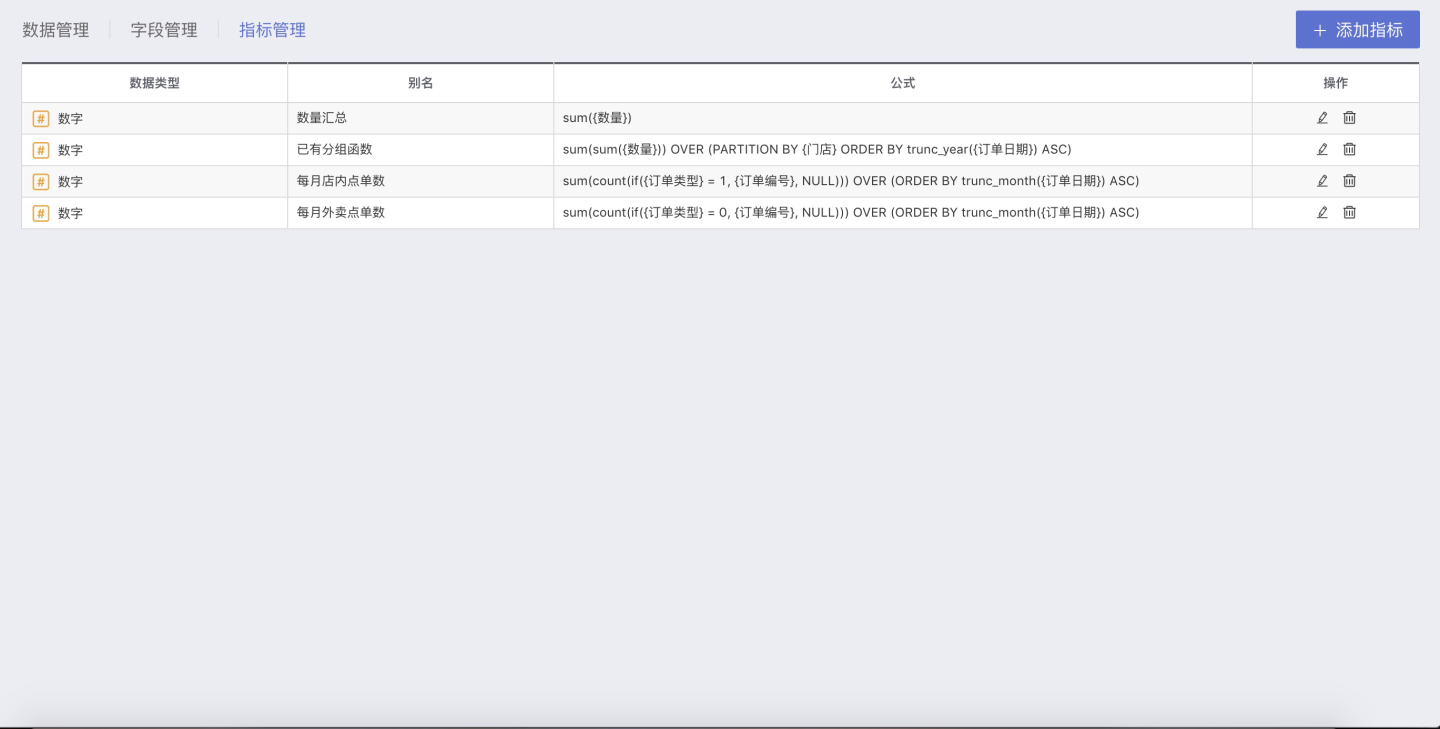
指标管理体系
完成数据处理后,HENGSHI SENSE 3.0 支持统一的计算字段,计算指标管理,及指标管理。指标管理就是在被用于数据可视化的数据集中定义了聚合指标后,所有用户使用该数据集做可视化时,都统一使用一套指标,避免概念不一致。
例如:指标 销售额 ,在指标管理中通过公式 sum({销售业绩}*{销售数量}),那大家对"销售额"这个指标的概念就是一致的,避免相同名次的不同计算方式导致的数据不一致问题。
故指标管理在企业内部实现关键 KPI 的统计逻辑,统计算法在部门之间保持统一口径,告别数据不一致.
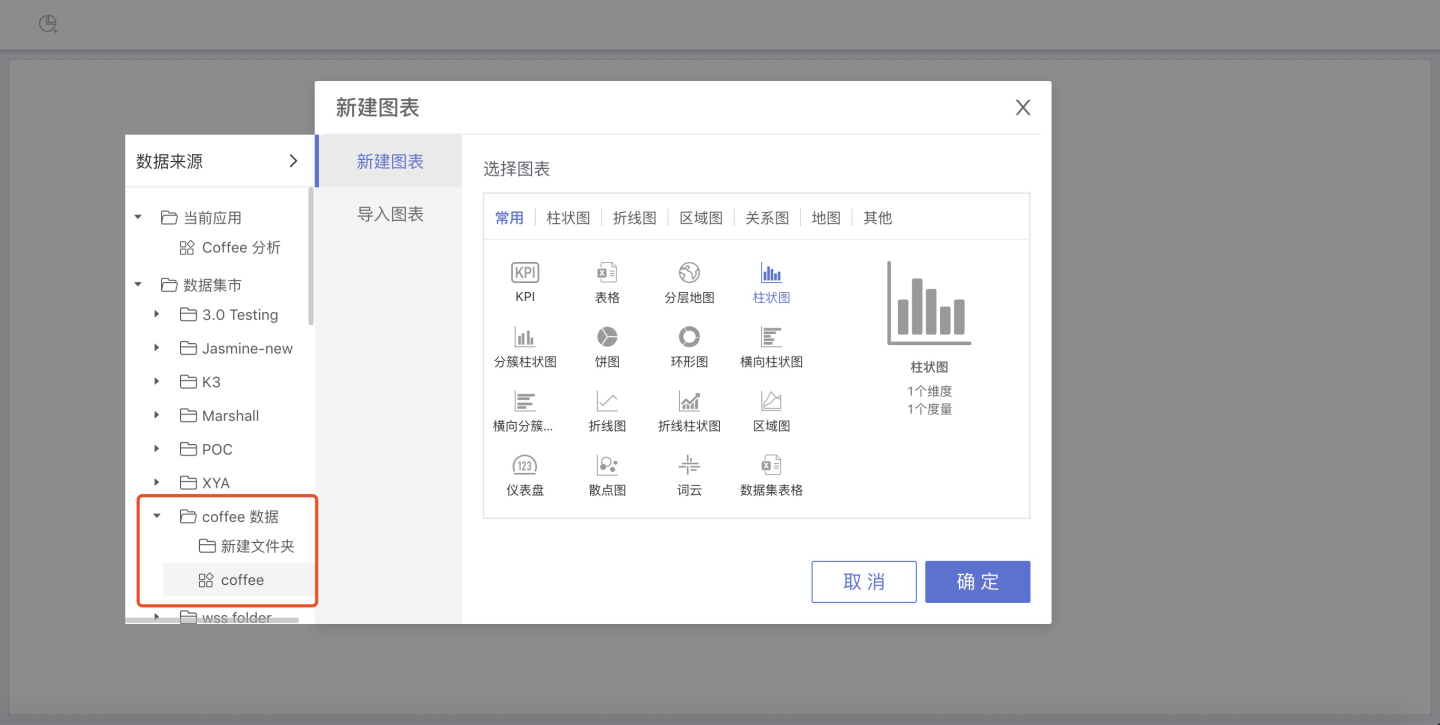
至此,数据集市中的操作全部完成,数据分析用户在 应用创作 区中可使用该数据集市的数据集做数据可视化
上述权限管理中在管理者、编辑者、查看者,任意模块下添加了的用户,在创建图表时,点击新建后,在选择图表类型左侧点击展开框,展开数据源的选择区域,可以看到该文件夹。