安装
python
pip install locust验证是否安装成功
python
locust -V使用
网上的教程基本上是前几年的,
locust已经更新了好几个版本,有点过时了,在此做一个总结
启动
默认是使用浏览器进行设置的
python
# 使用浏览器
locust -f .\main.py其他参数
python
Usage: locust [options] [UserClass ...]
常用选项:
-h, --help 显示帮助消息并退出
-f <filename>, --locustfile <filename>
包含测试的Python文件或模块,
例如"my_test.py"。接受多个逗号分隔
.py文件、包名/目录或指向的url
远程locustfile。默认为"locustfile"。
--config <filename> 从中读取其他配置的文件。
-H <base url>, --host <base url>
主机负载测试,格式如下:
https://www.example.com
-u <int>, --users <int>
并发Locust用户的峰值数量。主要使用
与无头或自动启动一起。可以是
在测试期间通过键盘输入w、W(spawn
1,10个用户)和s,S(停止1,10用户)
-r <float>, --spawn-rate <float>
生成用户的速率为(每秒用户数)。主要是
与--headless或--autostart一起使用
-t <time string>, --run-time <time string>
在指定的时间量后停止,例如(300s,
20m、3h、1h30m等)。仅与一起使用
--headless 或 --autostart。默认为永远运行。
-l, --list 显示可能的用户类列表并退出
--config-users [CONFIG_USERS ...]
用户配置为JSON字符串或文件。列表
参数或JSON配置数组
Web UI 选项:
--web-host <ip> 将web界面绑定到的主机。默认为"*"
(所有接口)
--web-port <port number>, -P <port number>
运行web主机的端口
--headless 禁用web界面,然后立即开始测试。
使用-u和-t来控制用户数量和
运行时间
--autostart 立即开始测试(比如--headless,但是
不禁用web UI)
--autoquit <seconds> 完全退出Locust,运行后X秒
完成。仅与 --autostart一起使用。这个
默认设置是保持Locust运行,直到您按下CTRL+C关闭它
--web-login 使用登录页面保护web界面。
--tls-cert <filename>
用于提供服务的TLS证书的可选路径
HTTPS
--tls-key <filename> 用于提供服务的TLS私钥的可选路径
HTTPS
--class-picker 在web界面中启用选择框进行选择
从所有可用的用户类和形状类
主选项:
在分布式运行Locust时运行LocustMaster节点的选项。主节点需要连接到它的Worker节点,然后才能运行负载测试。
--master 将locust作为主节点启动,工作节点连接到该节点。
--master-bind-host <ip>
主机监听的IP地址,例如
'192.168.1.1'. 默认为*(全部可用接口)。
--master-bind-port <port number>
主机监听的端口。默认为5557。
--expect-workers <int>
延迟开始测试,直到达到此数量的workers
(仅与结合使用 --headless/ --autostart)。
--expect-workers-max-wait <int>
master等待workers连接时间。默认为永远等待
--enable-rebalancing 如果在测试运行期间添加或删除了新的worker,请重新分配用户。
实验。
Worker选项:
在分布式运行Locust时运行LocustWorker节点的选项。
通常只需要在workers上指定这些选项(和--locostfile),因为其他选项(-u、-r、-t、...)由主节点控制。
--worker 将locust设置为以分布式模式运行,并将此进程设置为worker。可以与设置相结合
--locustfile设置为"-",以便从master下载。
--processes <int> 分流 locust 进程的数量,以启用系统。结合--worker标志或让它自动设置--worker和--master标志,
以实现一体化解决方案。在 Windows 上不可用。
实验。
--master-host <hostname>
要连接的locust主节点的主机名。
默认值127.0.0.1。
--master-port <port number>
主节点上要连接的端口。默认值为5557。
标记选项:
Locust任务可以使用@tag装饰器进行标记。这些选项允许指定在测试期间包含或排除哪些任务。
-T [<tag> ...], --tags [<tag> ...]
测试中要包含的标签列表,只会执行至少有一个匹配标签的任务
-E [<tag> ...], --exclude-tags [<tag> ...]
要从测试中排除的标签列表,只会执行没有匹配标签的任务
请求统计选项:
--csv <filename> 将请求统计数据以CSV格式存储到文件中。设置
此选项将生成三个文件:
<filename>_stats.csv、<filename>_stats_history.csv和
<filename>_failures.csv。前缀文件夹部分将自动创建
--csv-full-history 将每个统计条目以CSV格式存储到
_statshistory.csv文件。您还必须指定"--
csv"参数来启用此功能。
--print-stats 在UI运行中启用请求统计数据的定期打印
--only-summary 禁用请求统计信息的定期打印
--headless 运行
--reset-stats 生成完成后重置统计信息。
在分布式模式下运行时,应同时在master和worker上设置
--html <filename> 将HTML报告存储到指定的文件路径
--json 将JSON格式的最终统计数据打印到stdout。
可用于解析其他程序/脚本中的结果。
与--headless和--skip-log一起使用,仅用于json数据的输出。
日志记录选项:
--skip-log-setup 禁用Locust的日志记录设置。相反,配置是由Locust测试或Python默认值提供的。
--loglevel <level>, -L <level>
在DEBUG/INFO/WARNING/ERROR/CRITICAL之间进行选择。
默认值为INFO。
--logfile <filename> 日志文件的路径。如果未设置,日志将转到stderr
其他选项:
--show-task-ratio 打印用户类任务执行率表。
如果某些类定义了非零的fixed_count属性,请将其与非零--user选项一起使用。
--show-task-ratio-json
打印User类任务执行率的json数据。
如果某些类定义了非零的fixed_count属性,请将其与非零--user选项一起使用。
--version, -V 显示程序的版本号并退出
--exit-code-on-error <int>
设置测试结果包含任何失败或错误时使用的进程退出代码。默认为1。
-s <number>, --stop-timeout <number>
退出前等待模拟用户完成所有执行任务的秒数。
默认情况是立即终止。当运行分布式时,只需要在主服务器上指定。
--equal-weights 使用均匀分布的任务权重,覆盖locostfile中指定的权重。
User classes:
<UserClass1 UserClass2>
在命令行末尾,您可以列出要使用的User类(可用的User类可以用--list列出)。
LOCUST_USER_CLASS环境变量也可用于指定USER类。
默认设置是使用所有可用的用户类
示例:
locust -f my_test.py -H https://www.example.com
locust --headless -u 100 -t 20m --processes 4 MyHttpUser AnotherUser
有关更多详细信息,包括如何使用文件或环境变量设置选项,请参阅文档:
https://docs.locust.io/en/stable/configuration.html参数介绍在其他文章上有有很多,这里不多赘述,下面主要介绍一下项目中的应用
TaskSet
新版的
locust使用的方式与旧版有点区别,写用例时需要继承TaskSet来实现
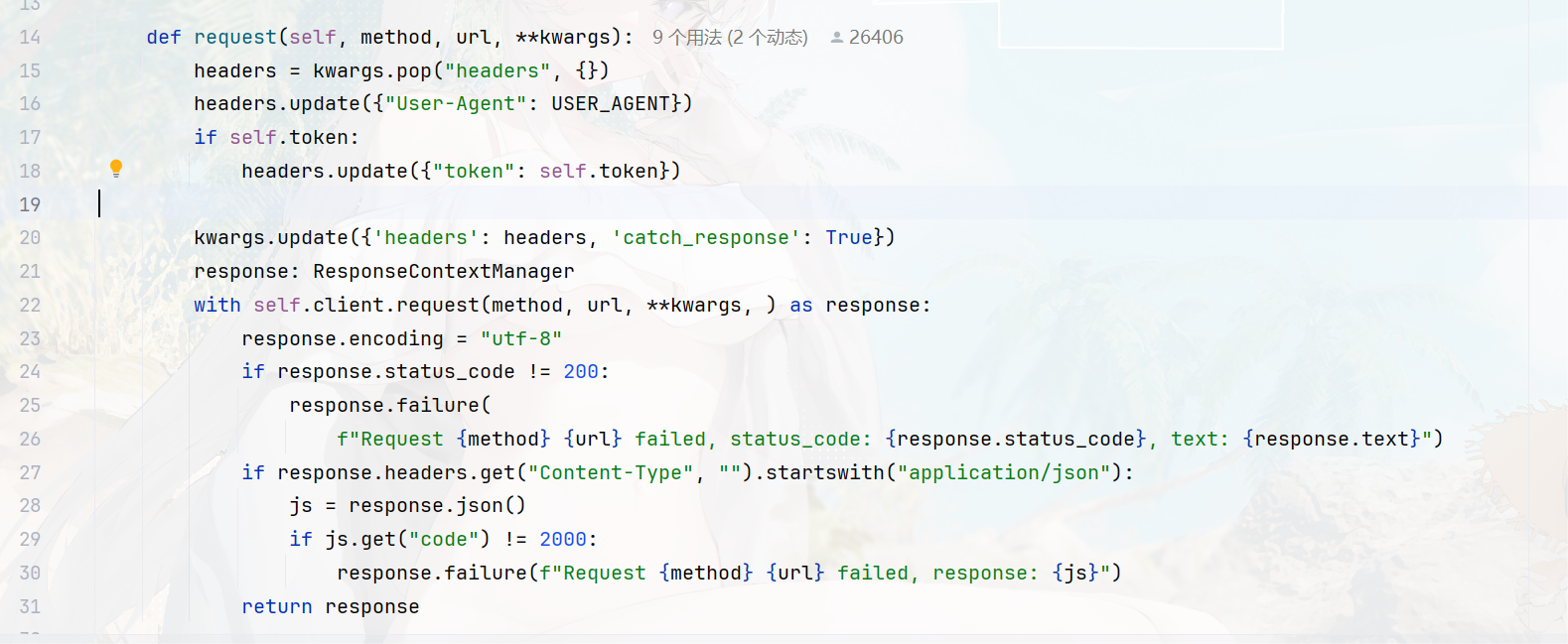
代码如下:
python
# coding: utf-8
from locust import TaskSet
from locust.clients import ResponseContextManager
from .settings import USER_AGENT
class UserBehaviorBase(TaskSet):
token = None
def setToken(self, token):
self.token = token
def request(self, method, url, **kwargs):
headers = kwargs.pop("headers", {})
headers.update({"User-Agent": USER_AGENT})
if self.token:
headers.update({"token": self.token})
kwargs.update({'headers': headers, 'catch_response': True})
response: ResponseContextManager
with self.client.request(method, url, **kwargs, ) as response:
response.encoding = "utf-8"
if response.status_code != 200:
response.failure(
f"Request {method} {url} failed, status_code: {response.status_code}, text: {response.text}")
if response.headers.get("Content-Type", "").startswith("application/json"):
js = response.json()
if js.get("code") != 2000:
response.failure(f"Request {method} {url} failed, response: {js}")
return response
def get(self, url, **kwargs):
return self.request("GET", url, **kwargs)
def post(self, url, **kwargs):
return self.request("POST", url, **kwargs)
def put(self, url, **kwargs):
return self.request("PUT", url, **kwargs)
def delete(self, url, **kwargs):
return self.request("DELETE", url, **kwargs)
def options(self, url, **kwargs):
return self.request("OPTIONS", url, **kwargs)
def head(self, url, **kwargs):
return self.request("HEAD", url, **kwargs)
def patch(self, url, **kwargs):
return self.request("PATCH", url, **kwargs)自定义错误
在
locust中assert函数只能抛出错误只能在Exceptions中查看,这是错误,但是用例还是成功的
如果标记失败需要在
ResponseContextManager中进行指定,在locust中用例状态只有两种,成功,失败自定义失败需要在
ResponseContextManager中指定一个参数catch_response= True
例:
若不指定
failure,默认用例是成功的,locust中status_code小于400就是成功的用例,不满足需求常常是自定义的
task
项目中一个
task便是一个用例,用例必须要有task装饰器task有个
weight参数,若weight=2,可以简单的理解为,不指定参数的运行一次,指定参数的运行两次例:
python
# coding: utf-8
from locust import task
from common import UserBehaviorBase, operationToken, USER_MANAGE
class InsuranceUser(UserBehaviorBase):
"""
保险端用户
"""
# def on_start(self):
# insurance = Login.login(USER_MANAGE['operation'])
# token = operation.get('result', {}).get('token')
# self.setToken(token)
def on_start(self) -> None:
self.setToken(operationToken)
@task
def test01(self):
"""
承保管理 - 询价申请
"""
url = '/gateway/spli/insurance/apply/page'
payload = {
"param": {},
"page": {
"current": 1,
"size": 10
}
}
self.post(url, json=payload)on_start/on_stop
类运行前、后的函数,只运行一次,通常用于登录、清理内存
执行程序
这里只说一下单使用
locust自己写的用例运行。项目中经常需要在多个文件中写用例,官方文档中并没有明确说该怎么运行多个文件的用例。其实也比较简单
例:
python
# coding: utf-8
from locust import HttpUser, between, run_single_user
from common import HOST
# 从其他文件中引入类
from tasks import *
class WebSite(HttpUser):
# 将用例类添加到任务重
tasks = [RegulatoryUser, CustomerUser, ProjectUser, InsuranceUser]
# tasks = [InsuranceUser]
host = HOST
wait_time = between(0.5, 2)
if __name__ == '__main__':
# 调试模式下,只运行一个用户
run_single_user(WebSite)参数解析
python
class WebSite(HttpUser):
host = '' # 需要测试的主机地址 eg: http://127.0.0.1:1234
tasks: list[TaskSet | Callable] = [] # 任务列表
min_wait= 1 # 最小等待时间,已弃用,使用wait_time
max_wait = 2 # 最大等待时间,已弃用 使用 wait_time
wait_time=between(3, 25) # 等待时间,这个例子是在2-25秒中随机选择一个
wait_function=None # 自定义等待函数,已弃用
weight: float = 1 # 与`task`中相同
fixed_count: int = 0 # 如果值为> 0,则权重属性将被忽略,并且将生成'fixed_count'-实例。首先生成这些用户。如果总目标计数(由------users参数指定)不足以生成具有已定义属性的每个User类的所有实例,则每个User的最终计数是未定义的。
abstract: bool = True # 如果abstract为True,则该类将被子类化,并且在测试期间不会生成该类的用户