你在浏览器里刚登录了某个网站,比如 xx 网盘,刷新一下页面,哎,登录状态还在,挺好。然后你手贱点了它关联的另一个产品,比如 xx 文档,发现竟然也自动登录了!但有时候,你打开另一个看似相关的网站,却又要你重新输密码。还有那个 "记住我" 的小勾勾,它背后到底藏着什么秘密?
 这些体验背后,其实都是一套关于"你是谁"以及"你能干嘛"的认证(Authentication)和授权(Authorization)机制在起作用。每次面试,这块儿知识点也基本是必考题。今天,咱们就从头捋一捋,用大白话聊聊 Session、Cookie、JWT、单点登录(SSO)以及 OAuth 2.0 这些让人既熟悉又有点模糊的概念,争取让你下次碰到类似问题或者面试官时,能自信地掰扯清楚。
这些体验背后,其实都是一套关于"你是谁"以及"你能干嘛"的认证(Authentication)和授权(Authorization)机制在起作用。每次面试,这块儿知识点也基本是必考题。今天,咱们就从头捋一捋,用大白话聊聊 Session、Cookie、JWT、单点登录(SSO)以及 OAuth 2.0 这些让人既熟悉又有点模糊的概念,争取让你下次碰到类似问题或者面试官时,能自信地掰扯清楚。
一切的起点:HTTP 的"健忘症"
咱们都知道,HTTP 协议本身是无状态的(Stateless)。啥意思呢?就是服务器记不住你上次请求是干嘛来的。你第一次请求说"你好",服务器回了"你好"。你第二次请求说"吃了没",服务器一脸懵逼:"你是谁啊?我认识你吗?"。
这在浏览网页还好,但涉及到需要登录、购物车这种场景,就抓瞎了。总不能每点一下,都让用户重新登录一次吧?体验也太差了!为了解决 HTTP 的"健忘症",大佬们想出了办法,核心思路就是:得让服务器能记住"你"。
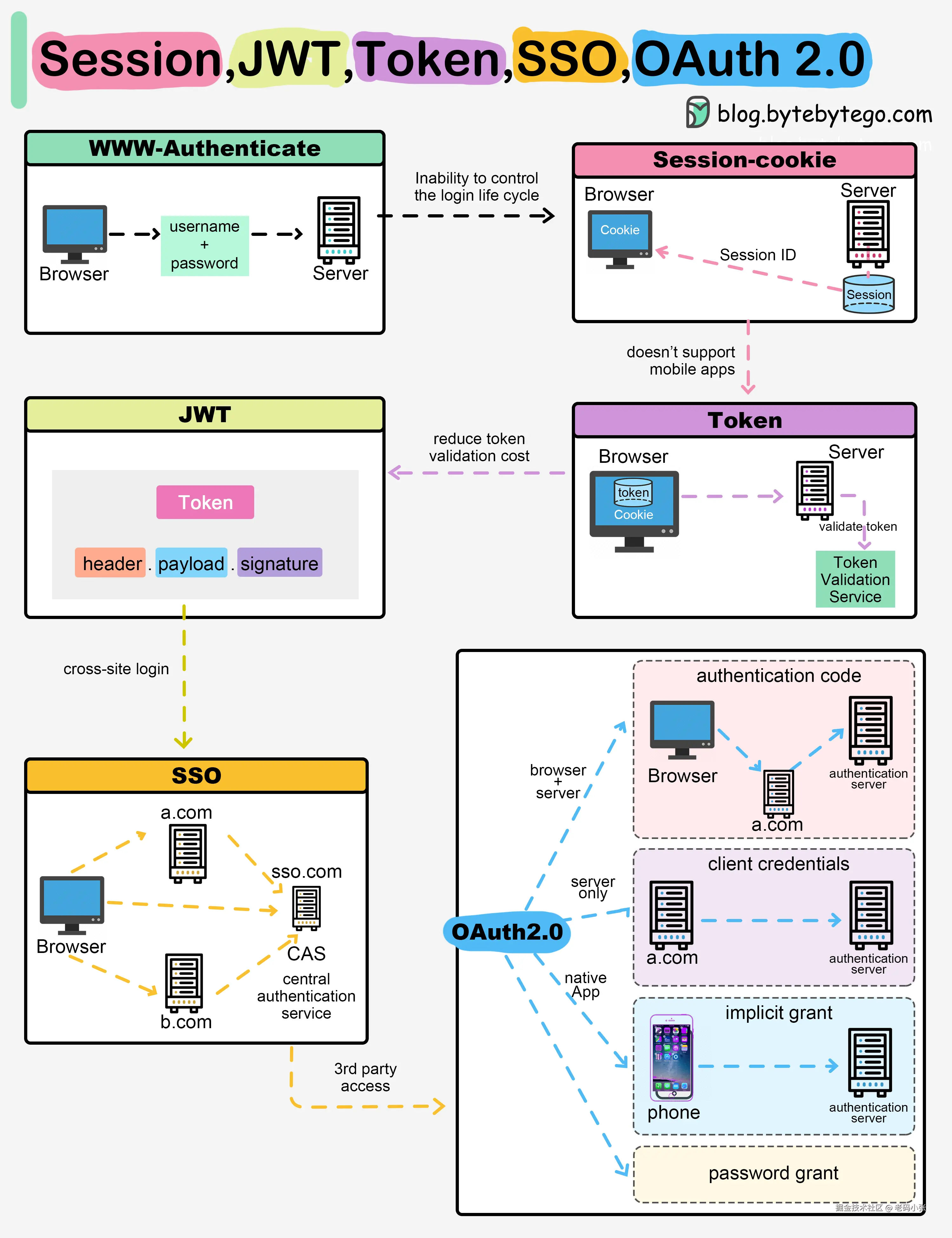
方案一:老伙计 Session + Cookie
这是最经典、最常用的方法。
运作流程大概是这样:
- 用户登录: 你输入用户名密码,提交给服务器。
- 服务器验证: 服务器验证通过,觉得"嗯,这小子是我认识的人"。
- 创建 Session: 服务器在自己这边(通常是内存或数据库里)创建一个"小本本"(Session),记录下你的信息(比如用户 ID、角色等),并给这个小本本一个唯一的编号(Session ID)。
- 发送 Cookie: 服务器把这个独一无二的 Session ID 通过 HTTP 响应头里的
Set-Cookie发送给你的浏览器。 - 浏览器存储: 浏览器乖乖地把这个 Session ID 存起来(这就是 Cookie)。
- 后续请求: 之后你每次访问这个网站,浏览器都会自动带上这个 Cookie(包含 Session ID)。
- 服务器识别: 服务器拿到请求里的 Cookie,提取 Session ID,在自己的"小本本"堆里找到对应的那个,一看:"哦,原来是你小子!",然后就知道你是谁了,可以继续操作。
用个图来表示更直观:
优劣势对比:
| 特点 | 优势 | 劣势 |
|---|---|---|
| 存储 | Session 数据存在服务端,相对安全 | 服务端需要存储大量 Session,消耗内存/存储资源 |
| 状态 | 服务端是有状态的 (Stateful) | 不利于服务器水平扩展(需要 Session 共享或粘性 Session 机制),增加复杂度 |
| 扩展性 | 扩展相对麻烦,尤其是在分布式环境下 | 依赖 Cookie,如果客户端禁用 Cookie 就失效;跨域(CORS)场景处理比较麻烦 |
| 安全 | Session ID 本身不包含敏感信息,相对不易伪造 | 存在 CSRF(跨站请求伪造)风险(需额外防护),Session 固定攻击等 |
小结: Session-Cookie 机制成熟稳定,用了很多年,对于简单应用或者服务端状态不成为瓶颈的场景,依然是个不错的选择。
方案二:新秀 JWT (JSON Web Token)
随着前后端分离、微服务架构的流行,Session 机制的劣势(主要是服务端状态和扩展性问题)越来越明显。于是,JWT 闪亮登场。
JWT 的核心思想是:服务器不存状态了,状态信息(以及校验机制)都交给客户端自己保管,每次请求带过来就行。
JWT 长啥样?
一个 JWT Token 通常是这样一长串字符串:xxxxx.yyyyy.zzzzz。它由三部分组成,用点(.)分隔:
- Header(头部): 包含类型(
typ,通常是JWT)和使用的签名算法(alg,比如HS256或RS256)。这部分会进行 Base64Url 编码。 - Payload(载荷): 包含要传递的信息(称为 Claims),比如用户 ID (
sub)、用户名 (name)、过期时间 (exp) 等。也可以自定义一些数据。注意: 这部分也是 Base64Url 编码,是透明 的,所以千万不要在 Payload 里放敏感信息(比如密码)! - Signature(签名): 把编码后的 Header 和 Payload,加上一个只有服务器知道的密钥(Secret) ,使用 Header 中指定的算法进行签名。这个签名的作用是防篡改。服务器收到 Token 后,会用同样的密钥和算法重新计算签名,跟 Token 里的签名比对,一样才说明没被动过手脚。
运作流程:
- 用户登录: 同样,提交用户名密码。
- 服务器验证: 验证通过。
- 生成 JWT: 服务器根据用户信息、密钥生成一个 JWT Token。
- 发送 JWT: 服务器把这个 Token 返回给客户端(通常放在响应体里)。
- 客户端存储: 客户端(浏览器、App)收到 Token 后自己存起来,常见的地方有 Local Storage、Session Storage,或者为了安全起见存在 HttpOnly Cookie 里。
- 后续请求: 每次请求需要认证的接口时,客户端把 Token 放在 HTTP 请求头
Authorization字段里(通常是Bearer <token>的形式)。 - 服务器验证: 服务器收到请求,拿出 Token,用自己的密钥验证签名。签名有效,就从 Payload 里获取用户信息,处理请求。签名无效或 Token 过期,就拒绝。
简单看下 Payload 解码后的样子(示例):
json
{
"sub": "1234567890", // Subject (通常是用户ID)
"name": "LaoMa XiaoZhang",
"iat": 1516239022, // Issued At (签发时间)
"exp": 1516242622 // Expiration Time (过期时间)
}流程图:
优劣势对比:
| 特点 | 优势 | 劣势 |
|---|---|---|
| 存储 | 服务端无需存储 Token 状态 (Stateless) | Token 可能比 Session ID 长,增加请求大小;Payload 透明,不能存敏感信息。 |
| 状态 | 服务端无状态,非常适合分布式、微服务架构,易于水平扩展 | Token 一旦签发,在有效期内难以强制失效(除非引入黑名单机制,又会增加复杂性);无法主动踢用户下线。 |
| 扩展性 | 天生支持跨域(CORS),因为 Token 通过 Header 传输,不受 Cookie 跨域策略限制 | 需要处理 Token 的刷新(Refresh Token)机制来平衡安全性和用户体验。 |
| 安全 | 签名机制保证了防篡改;不依赖 Cookie,可以避免部分 CSRF 问题 (但仍需注意XSS) | Token 泄露风险(需要 HTTPS 传输);需要妥善存储 Token;签发和验证 Token 消耗 CPU 资源(虽然通常可接受)。 |
小结: JWT 非常适合现代 Web 应用,尤其是前后端分离、微服务、需要跨域认证的场景。但要特别注意它的安全实践。
横向打通:SSO(单点登录)
还记得开头说的,登录了一个网站,其他关联网站也自动登录了吗?这就是单点登录(Single Sign-On, SSO)的魔力。
想象一下,一个大公司有很多内部系统:OA、邮箱、代码库、HR 系统... 如果每个系统都要单独登录,员工得疯。SSO 就是为了解决这个问题:在一个地方登录一次,就能访问所有相互信任的应用系统。
核心原理:
通常会有一个独立的认证中心(Authentication Server)。
- 用户访问应用 A(未登录)。
- 应用 A 发现用户没登录,就把用户重定向到认证中心,并带上自己的身份标识和期望的回调地址。
- 用户在认证中心输入用户名密码进行登录。
- 认证中心验证通过,生成一个"凭证"(可能是基于 Session/Cookie,也可能是 Token),记录下用户已登录的状态,然后把用户重定向回应用 A 的回调地址,并带上"用户已登录"的证明(比如一个授权码或者 Token)。
- 应用 A 收到这个证明,可能还需要跟认证中心确认一下,然后就认为用户已经登录了,放行。
- 接着用户访问应用 B。
- 应用 B 发现用户没登录,同样把用户重定向到认证中心。
- 认证中心发现:"咦,这哥们刚才不是在我这儿登过了吗?",于是直接生成一个给应用 B 的证明,重定向回应用 B。
- 应用 B 验证证明,用户成功登录应用 B,全程无需再次输入密码。
流程示意图(简化版):
SSO 的实现方案有很多,比如基于 Cookie、SAML、CAS、OpenID Connect (OIDC,基于 OAuth 2.0) 等。
专业授权:OAuth 2.0
经常看到"使用 xx 账号登录"(比如用微信、GitHub 登录某个第三方 App)?这背后大功臣就是 OAuth 2.0。
划重点:OAuth 2.0 主要解决的是授权(Authorization)问题,而不是认证(Authentication)问题。 啥意思?就是"你(用户)允许某个应用(客户端)代表你去访问你存储在另一个服务(资源服务器)上的某些受保护资源"。
比如,你允许一个"网盘备份工具"App 访问你的 Google Drive 文件。你并不会把 Google 账号密码告诉这个工具,而是通过 Google 的 OAuth 流程,授权这个工具一个有时限、有范围(比如只能读写某个文件夹)的访问令牌(Access Token)。
OAuth 2.0 中的角色:
- Resource Owner(资源所有者): 就是你,用户。
- Client(客户端): 就是请求访问你资源的第三方应用,比如那个"网盘备份工具"。
- Authorization Server(授权服务器): 负责验证你的身份,并根据你的同意,给客户端发放访问令牌。通常由资源服务器提供(比如 Google 的账号服务)。
- Resource Server(资源服务器): 存储着受保护资源的服务器,比如 Google Drive 服务器。它只认授权服务器发的有效令牌。
最常见的授权流程:授权码模式(Authorization Code Grant)
这个流程稍微复杂点,但最安全,适合有后端的 Web 应用。
- 用户在客户端 App 点击"使用 Google 账号登录/授权"。
- 客户端将用户重定向到 Google 的授权服务器,带上客户端 ID、请求的权限范围(Scope)、回调地址等信息。
- 授权服务器要求用户登录 Google 账号(如果还没登录的话),并展示客户端请求的权限列表,问用户:"你同意授权吗?"
- 用户点击"同意"。
- 授权服务器把用户重定向回客户端预设的回调地址,并附带一个一次性的授权码(Authorization Code)。
- 客户端收到授权码,在后端 偷偷地用这个授权码,加上自己的客户端 ID 和密钥,向授权服务器请求访问令牌(Access Token)(可能还有刷新令牌 Refresh Token)。
- 授权服务器验证授权码和客户端信息,发放访问令牌。
- 客户端拿到访问令牌后,就可以用它去访问资源服务器(比如 Google Drive API)获取用户信息或操作资源了。
流程图示意:
OAuth 2.0 还有其他授权模式,比如隐式模式(Implicit Grant,适合纯前端应用,安全性稍低)、密码模式(Resource Owner Password Credentials Grant,不推荐)、客户端凭证模式(Client Credentials Grant,适合机器间通信)等,根据不同场景选用。
注意: OpenID Connect (OIDC) 是在 OAuth 2.0 基础上构建的一个身份认证层。它提供了获取用户身份信息(比如你是谁)的标准方法,而 OAuth 2.0 本身只关心授权(你能干什么)。很多"使用 xx 登录"其实是 OIDC 在发挥作用。
实践干货小贴士
聊了这么多原理,落地时有啥要注意的?
- JWT 安全:
- 必须用 HTTPS! 防止 Token 在传输中被截获。
- 设置合理的过期时间 (
exp),不要太长。 - 使用 Refresh Token 机制: Access Token 过期时间短(比如几分钟到几小时),Refresh Token 过期时间长(比如几天或几周)。Access Token 过期后,用 Refresh Token 静默获取新的 Access Token,用户体验更好。Refresh Token 要安全存储,一旦泄露要能作废。
- 密钥(Secret)要保密,且足够复杂。考虑使用非对称加密(RS256 等),更安全,但性能开销稍大。
- 选择合适的存储位置:
- Web 端:推荐存在
HttpOnly、Secure、SameSite=Lax或Strict的 Cookie 里,能有效防范 XSS 攻击获取 Token。Local Storage/Session Storage 容易被 XSS 攻击读取。 - 移动端:使用 Keychain (iOS) 或 Keystore (Android) 等安全存储。
- Web 端:推荐存在
- 考虑 Token 黑名单机制: 如果需要强制用户下线或作废某个 Token,需要额外实现一套机制(比如 Redis 存失效 Token 列表),但这又有点违背 JWT 无状态的初衷了。
- Session 安全:
- 登录成功后重新生成 Session ID,防止会话固定攻击。
- Cookie 设置
HttpOnly、Secure、SameSite属性。 - Session 数据服务端存储也要注意安全。
- OAuth/SSO:
- 优先选择成熟的库或服务(比如 Okta, Auth0, Keycloak,或者云厂商提供的身份服务),自己完全实现一套复杂且易出错。
- 仔细理解不同 OAuth Grant Type 的适用场景和安全风险。
- 严格校验
redirect_uri,防止开放重定向漏洞。 - 正确处理
state参数,防止 CSRF 攻击。
好了,今天咱们从 HTTP 的无状态聊起,一路走过了 Session/Cookie、JWT,再到更宏观的 SSO 和专业的 OAuth 2.0。希望能帮你把这些概念串起来,理解它们各自解决的问题和应用场景。
技术选型没有绝对的银弹,关键是理解原理,根据你的具体业务场景、团队能力、安全需求来做权衡。
我是老码小张,一个在技术原理的海洋里遨游,同时也在实践的大坑里摸爬滚打的技术人。如果你觉得这篇文章对你有帮助,或者有什么想法想交流,欢迎留言讨论!咱们下次再见!