集群搭建-Standalone
一、解压
在之前的学习中我们有了一个软件包 spark.3.1.2-bin-hadoop3.2.tgz (eg我的在 /opt/software目录下)把这个软件包解压到 /opt/module 下(也可以自己决定解压到哪里)。对应的命令是:
tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module
二、重命名
进入 /opt/module/ 把解压的内容右键重命名一下为 spark-standalone ,也可使用命令:
mv spark-3.1.1-bin-hadoop3.2/ spark-standalone
三、配置环境变量,更新spark路径
打开 /etc/profile.d/my_env.sh 加入如下代码

四、同步环境变量,并使用source命令让它生效
root@hadoop100 \~# xsync /etc/profile.d

五、修改配置文件
打开 /opt/module/spark-standalone/conf 中可看到修改文件内容前把 .template 后缀名都删掉再打开
workers.template文件 内容设置为三个主机名
hadoop100
hadoop101
hadoop102spark-env.sh.template文件
export JAVA_HOME=/opt/module/jdk1.8.0_212
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export SPARK_MASTER_IP=hadoop100
export SPARK_MASTER_PORT=7077
export SPARK_DIST_CLASSPATH=$(/opt/module/hadoop-3.1.3/bin/hadoop classpath)
export HADOOP_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
export SPARK_YARN_USER_ENV="CLASSPATH=/opt/module/hadoop-3.1.3/etc/hadoop"
export YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop100:8020/directory
-Dspark.history.retainedApplications=30
"spark-defaults.conf.****template文件****
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop100:8020/directory
spark.yarn.historyServer.address=hadoop100:18080
spark.history.ui.port=18080六、启动SPARK集群。
进入到hadoop100机器,切换目录到/opt/module/spark-standalone/sbin下,运行命令 ./start-all.sh。
使用jps命令能看到我划线的就说明运行成功
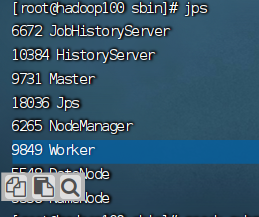
七、查看启动结果
打开浏览器,输入hadoop100:8080。看到效果如下说明成功: