用于博主复习
Transformer
Encoder
- 输入和输出维度不变
- 输入维度: ( n , d m o d e l ) (n,d_{model}) (n,dmodel),d m o d e l d_{model} dmodel一般是512,是embedding后的维度
- 输出维度: ( n , d m o d e l ) (n,d_{model}) (n,dmodel)
自注意力层
注意力分为自注意力 和交叉注意力
Q,K,V
- Q,K,V的含义不需要特别分清楚
V在自注意力和交叉注意力中的来源不同
- Q: ( n , d m o d e l ) (n,d_{model}) (n,dmodel),
- K: ( n , d m o d e l ) (n,d_{model}) (n,dmodel)
- V: ( n , d m o d e l ) (n,d_{model}) (n,dmodel):
- 注:d_model一般都为512,三者的d_model可以不同
d k \sqrt{d_k} dk 的作用
To illustrate why the dot products get large, assume that the components of q and k are independent random variables with mean 0 and variance 1. Then their dot product, q · k has mean 0 and variance d_k.
防止过于softmax过于集中,梯度过小(本质上是因为梯度关系)
- 数学解释 :Q,K的均值为0,方差为1时,QK的均值为0,方差为 d k d_k dk
多头注意力
多头的动机:多头是为了学习不同的线性映射关系
- 假设头数h=8,会有8个K,Q,V矩阵,维度为 d m o d e l / 8 d_{model}/8 dmodel/8,这些矩阵都是相对独立的,学习到的映射也不尽相同。
本质上是对 d m o d e l d_{model} dmodel特征维度学习的拆分
- 最后拼接回来形成 ( n , d m o d e l ) (n,d_{model}) (n,dmodel)的输出即可
注意力输出
对原始token特征向量的基于上下文的一个"修正"或者新的映射
- (QK)与V的乘积反映在特征空间上的加权,特征向量的某些维度(根据注意力权重)对于形成token新的特征向量更加重要?
- 维度不变
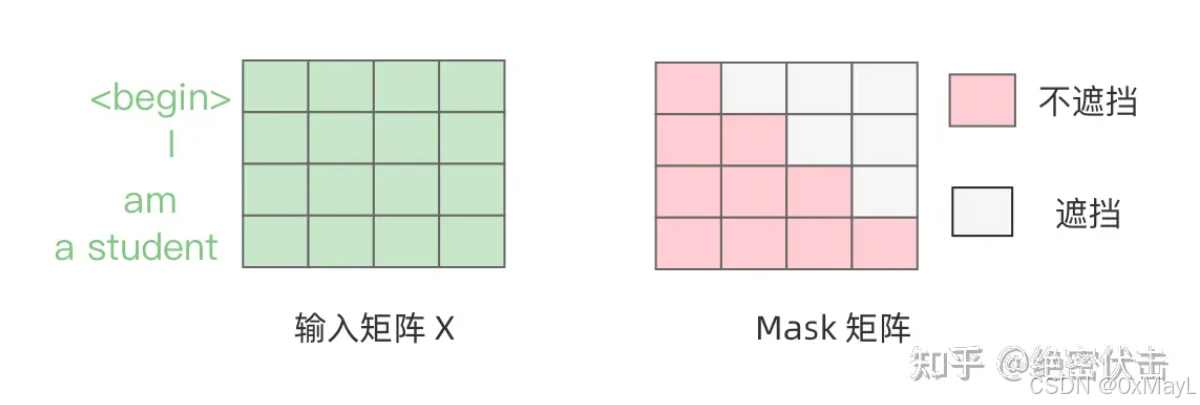
MASKED掩码
只用于decoder中,由于decoder是基于自回归的方式,所以不能让一个t-1时刻的token与t时刻以后的tokens作注意力
- Transformer掩码计算: s o f t m a x ( Q K T ∗ M A S K E D ) ∗ V softmax(QK^T*MASKED)*V softmax(QKT∗MASKED)∗V
交叉注意力
- K,V是来自encoder的信息矩阵,Q是来自Decoder的信息矩阵.
显然是根据encoder的信息,对decoder的特征向量进行专属修正
FFN层
原文描述:In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between
除了注意力子层之外,我们的编码器和解码器中的每个层都包含一个完全连接的前馈网络,该网络分别且相同地应用于每个位置。这包括两个线性转换,中间有一个 ReLU 激活
- 两个MLP,一个MLP负责放大维度到 4 ∗ d m o d e l 4*d_{model} 4∗dmodel,两一个负责输出回 d m o d e l d_{model} dmodel。
不要忘记:中间有一个GELU作为激活
Add&Norm
- 残差连接后 ,再归一化
位置编码
位置编码的动机:Transformer没有序列先后顺序这一概念.
位置编码对于Transformer的作用明显,不加会掉点. 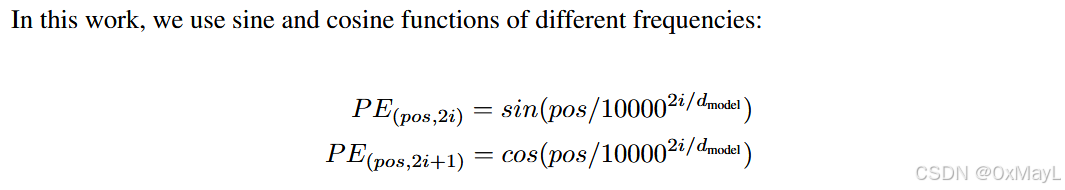
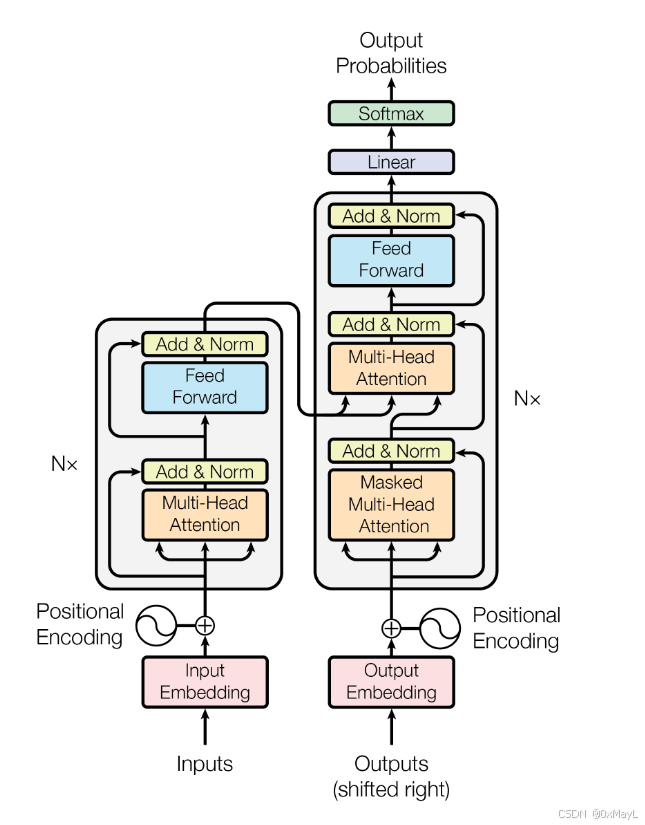
模型Workflow
- 接受两个句子作为输入
- 根据Softmax自回归输出token.
参考文献
cpp
@misc{vaswaniAttentionAllYou2023,
title = {Attention {{Is All You Need}}},
author = {Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser, Lukasz and Polosukhin, Illia},
year = {2023},
number = {arXiv:1706.03762},
eprint = {1706.03762},
primaryclass = {cs},
publisher = {arXiv},
doi = {10.48550/arXiv.1706.03762},
archiveprefix = {arXiv}
}