kafka与其他组件的整合
kafka作为消费者
使用kafka作为消费者从bloom中获取数据,并将数据打印到控制台或传入HDFS。
ACKS机制的不同级别及其对数据可靠性和延迟的影响。
kafka作为生产者
kafka作为生产者生成数据,并使用bloom作为消费者采集数据
在kafka中创建topic,并将数据写入指定的topic中。
创建topic
kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --topic test1 --partitions 3 --replication-factor 3
数据的形式:
主题名称-分区编号。
在Kafka的数据目录下查看。
设定副本数量,不能大于broker的数量。
Spark Streaming中的Extreme转换
无状态转换操作
无状态转换操作的概念,即对每个批次的RDD进行转换。
常见的无状态转换操作,如map、flatMap、filter、reduceByKey等。
这些操作是分别应用到每个RDD上的,即使这些RDD属于不同的时间区间。
针对键值对的 DStream 转化操作(比如reduceByKey())要添加**import StreamingContext._**才能在 Scala 中使用。
Transform操作
transform操作允许对RDD进行任意转换,并扩展Spark Streaming的功能。
输出代码
java
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object Transform {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val ssc = new StreamingContext(sparkConf,Seconds(3))
val lineDStream :ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
val wordAndCountDStream :DStream[(String,Int)] = lineDStream.transform(rdd => {
val words :RDD[String] = rdd.flatMap(_.split(" "))
val wordAndOne :RDD[(String,Int)] = words.map((_,1))
val value :RDD[(String,Int)] = wordAndOne.reduceByKey(_+_)
value
})
wordAndCountDStream.print()
ssc.start()
ssc.awaitTermination()
}
}输出结果如下:
Join操作
join操作的概念,即对两个流的RDD进行关联操作。
oin操作的硬性要求,即两个流的批次大小必须一致。
实验操作步骤
配置和启动环境
配置和启动Spark Streaming环境,包括设置时间节点和端口号。

数据输入和结果输出
java
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object job {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("join")
val ssc = new StreamingContext(sparkConf,Seconds(3))
val lineDStream1 :ReceiverInputDStream[String] = ssc.
socketTextStream("node01",9999)
val lineDStream2 :ReceiverInputDStream[String] = ssc.
socketTextStream("node02",8888)
val wordToOneDStream :DStream[(String,Int)] = lineDStream1
.flatMap(_.split(" ")).map((_,1))
val wordToADstream :DStream[(String,String)] = lineDStream2
.flatMap(_.split(" ")).map((_,"a"))
val joinDStream :DStream[(String,(Int,String))]=wordToOneDStream
.join(wordToADstream)
joinDStream.print()
ssc.start()
ssc.awaitTermination()
}
}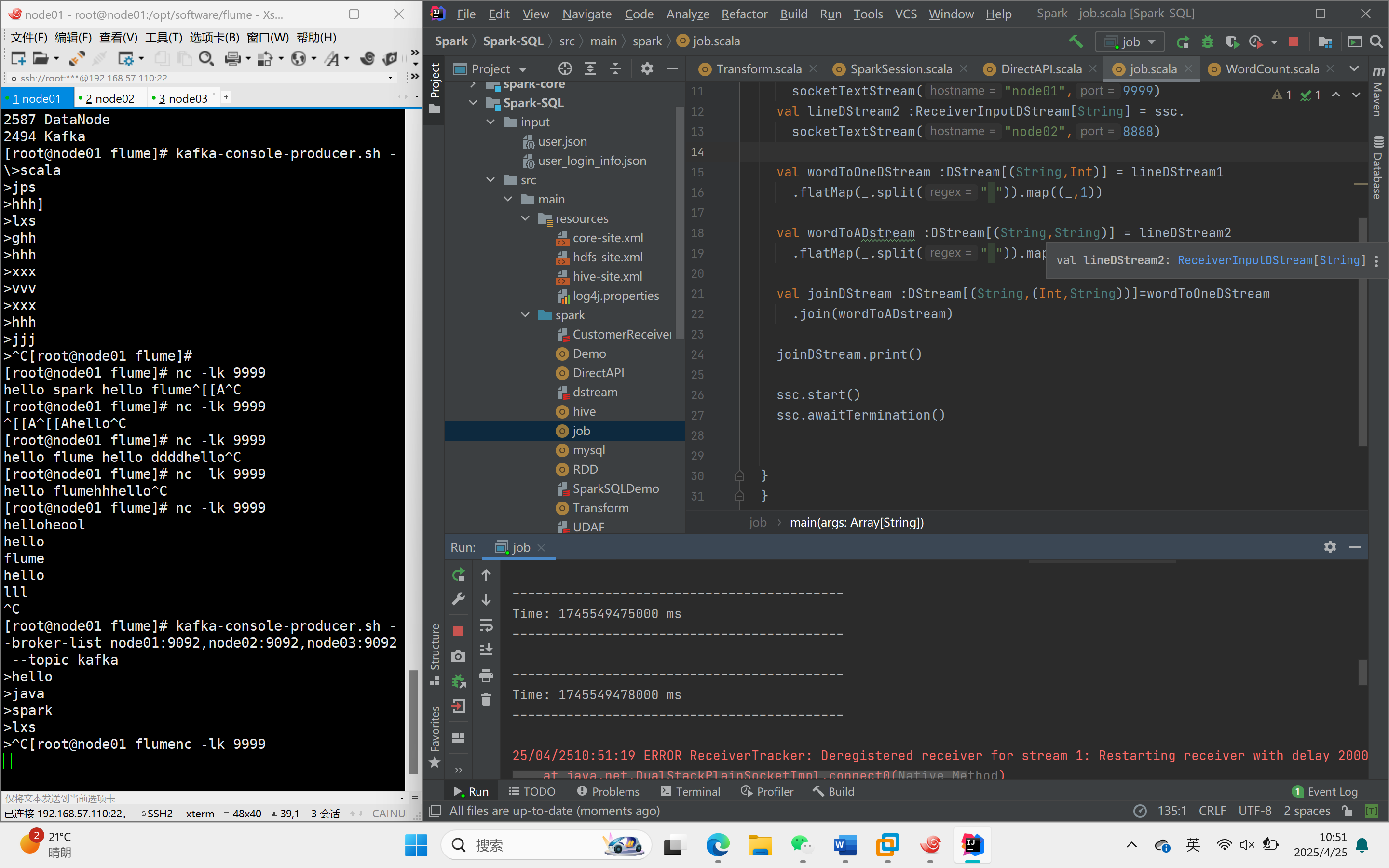
在不同的节点上输入数据,并在控制台上输出结果。
在不同窗口中启动消费者和生产者,并捕捉数据。