行业现状:标准工况与用户场景的割裂
全球汽车行业普遍采用WLTC工况进行能耗测试,但其与真实道路场景差异显著 。据研究,WLTC工况下车辆能耗数据比实际道路低10%-30%,导致用户对续航虚标投诉激增(数据来源:东南大学胡鸿飞,2017)。中国网约车平台调研显示,83%的司机认为现有测试工况无法反映城市拥堵场景。这种割裂倒逼车企探索基于真实用户场景的工况构建技术,以优化能量管理策略和标定流程。
引导互动:各位同行是否遇到过因工况不匹配导致的标定结果与用户反馈差异大的问题?

技术原理:从数据碎片到工况曲线
数学建模:PCA+K-means双剑合璧
- 主成分分析(PCA):将24个特征参数(如怠速比例、加速度标准差)降维至5个主成分,保留90%关键信息(论文表5数据支撑)
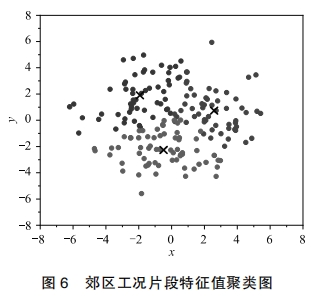
- K-means聚类:基于降维后特征将短行程片段分类,市区/郊区分别聚为2类、3类(图5-6)
数据采集→清洗→特征提取→聚类→拼接→验证
软件策略:MBD开发模式
- 基于模型的设计(MBD):MATLAB/Simulink搭建算法模型,自动生成C++代码嵌入软件
- 三大模块设计:参数输入(图14)、片段划分(图15)、工况合成(图16),支持2000+片段/秒处理速度
引导互动:在嵌入式软件开发中,您更倾向传统编码还是MBD模式?
工程挑战:数据噪声与高速困境
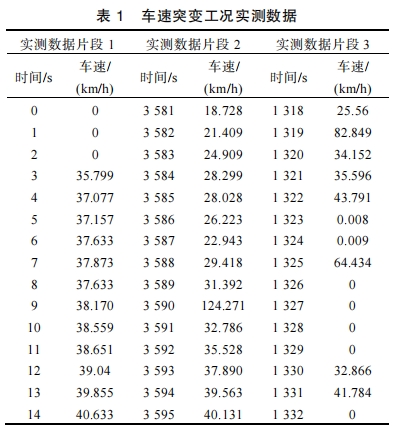
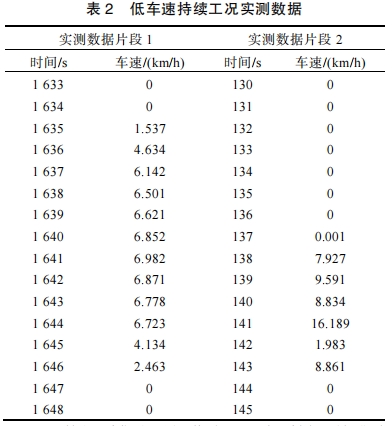
四大典型问题(论文表1-3数据支撑)
| 问题类型 | 发生率 | 影响 |
|---|---|---|
| 车速突变 | 12.7% | 特征参数失真 |
| 低速片段 | 23.4% | 聚类偏差 |
| 起止异常 | 8.9% | 片段不完整 |
| 高速超长 | 100% | 无法直接应用短行程法 |
高速段特殊挑战
- 单片段时长超800秒(图3),直接拼接导致工况占比失衡
- 加速度波动频繁,传统方法无法有效提取特征
引导互动:处理高速数据时,您是否也遇到过"一刀切"删减导致特征丢失的困境?
解决方案:场景化分段治理
技术对比表
| 方法 | 适用场景 | 优势 | 局限 |
|---|---|---|---|
| 短行程法 | 市区/郊区 | 保留微观特征 | 高速段失效 |
| 片段重组法 | 高速 | 解决超长片段 | 需要精确边界匹配 |
创新性高速处理(图9-10)
- 片段切分:按速度区间(0-30/30-60/.../120-110km/h)切割
- 智能重组:确保连接处速度差<0.05km/h,通过遗传算法优化拼接顺序
实测验证数据
| 指标 | 原始数据 | 合成工况 | 误差 |
|---|---|---|---|
| 平均车速 | 35.88km/h | 37.20km/h | 3.68% |
| 最大加速度 | 2.593m/s² | 2.496m/s² | 3.74% |
| VA分布吻合度 | - | - | <8% |
引导互动:在您的项目中,特征参数误差控制在什么范围?
未来展望:AI驱动与生态延伸
- 实时工况生成:结合5G+V2X实现动态工况构建
- 迁移学习应用:将北上广深工况快速适配到新城市
- 碳足迹追踪:基于工况数据计算车辆全生命周期碳排放
开放式讨论
当自动驾驶普及后,行驶工况构建技术会被取代还是升级?欢迎在评论区分享观点!
延伸阅读
- 《基于LSTM的实际行驶工况预测模型》(IEEE Transactions on Vehicular Technology, 2022)
- 《新能源车能耗标定中的多目标优化方法》(SAE Technical Paper, 2021)
- 《ISO 22160:2023车辆工况构建新标准解读》(CATARC白皮书, 2023)
#汽车工程 #数据驱动 #行驶工况 #机器学习 #软件开发