论文链接:https://arxiv.org/pdf/2104.03113
《Scaling Scaling Laws with Board Games》:探索棋盘游戏中的扩展规律
摘要
如今,机器学习领域中规模最大的实验所需的资源,超出了仅有几家机构的预算。幸运的是,最近的研究表明,这些巨大实验的结果通常可以从一系列更小、更廉价实验的结果中进行外推。在这项工作中,我们表明,外推不仅可以基于模型的大小进行,还可以基于问题的大小。通过使用 AlphaZero 和 Hex 游戏开展一系列实验,我们表明,在固定计算量下,随着游戏变得更大和更难,可实现的性能会可预测地降低。除了主要结果外,我们还进一步展示了,在保持性能的同时,可以对智能体在测试时和训练时可用的计算量进行权衡。。
背景知识
扩展规律
扩展规律的研究可以追溯到 20 世纪 80 年代,但近年来才引起广泛关注。Hestness 等人表明,语言模型的性能与训练数据集的大小呈幂律关系。后续研究进一步考虑了模型大小和训练计算量等因素。然而,以往的扩展规律研究主要集中在图像和语言领域,而本文首次将扩展规律应用于多智能体强化学习领域,并同时扩展了问题和模型的规模。
AlphaZero
AlphaZero 是一种通过自我对弈教授神经网络玩两人零和游戏的算法。在训练过程中,AlphaZero 通过树搜索增强网络生成的策略,从而逐步提升网络的性能。
Hex 游戏
Hex 是一种两人策略游戏,玩家轮流在菱形棋盘上放置棋子,首个将棋盘两侧连接起来的玩家获胜。尽管规则简单,但 Hex 被认为是一种复杂的策略游戏。
研究方法
AlphaZero 实现
研究人员开发了一个快速、低资源的 AlphaZero 实现,用于在不同大小的棋盘上训练多个模型。该实现能够在单个 RTX 2080 Ti 上以大约指数级于棋盘大小的时间训练出完美策略。
模型训练
研究人员使用 AlphaZero 训练了约 200 个不同超参数的模型,涵盖棋盘大小从 3 到 9 的范围。独立变量为棋盘大小和计算量,计算量的调节通过网络深度、网络宽度和训练时长三个维度实现。
评估方法
通过让每个智能体相互对弈 1024 局棋,并根据比赛结果计算每个智能体的 Elo 评分,从而评估智能体的性能。为了固定偏移量,研究人员还让排名靠前的智能体与完美策略的 MoHex 进行对弈。
实验结果
计算前沿参数
在训练过程中,每个智能体的性能与计算量的关系呈现出近似 S 型曲线。通过对不同棋盘大小的计算前沿进行拟合,研究人员得出了以下结论:
- 斜率 :计算量每增加一个数量级,Elo 评分提高约 500 分。在性能线性增长阶段,计算量是对手两倍的智能体能赢得约 2/3 的比赛。
- 完美策略 :实现完美策略所需的最小计算量随棋盘大小的增加而呈 7 倍增长。
- 起飞点 :看到比随机策略有改进所需的最小训练计算量随棋盘大小的增加呈 4 倍增长。
- 随机策略与完美策略的距离 :棋盘大小每增加一个单位,随机策略与完美策略之间的距离增加 500 Elo 分。
预测误差
研究人员发现,基于小棋盘数据拟合的模型能够准确预测大棋盘的计算前沿。预测误差随着用于拟合的小棋盘数量增加呈指数级衰减。
训练 - 测试权衡
研究人员还发现,训练时的计算量和测试时的计算量可以相互替代。具体来说,每次训练时计算量增加 10 倍,可以抵消约 15 倍的测试时计算量,直到测试时树搜索减少到单节点搜索的下限。
讨论
计算与性能的关系
智能体的性能与计算量之间的关系类似于一个简单的玩具模型,其中每个玩家根据计算量选择随机数字,拥有最大数字的玩家获胜。这表明 Hex 游戏的复杂策略可能归结为每个智能体拥有与计算量成比例的策略池,选择更好策略的智能体获胜。
性能的平滑变化
无论计算量还是棋盘大小的变化,模型性能都呈现出平滑且可预测的变化趋势。这表明模型的性能不会因计算量或复杂性的增加而出现突发性的跳跃式变化。
训练与测试计算量的关系
研究人员最初认为测试时计算量比训练时计算量更 "廉价",但实验结果显示两者存在简单的替代关系。这可能是因为测试时的优化仅需针对一个样本,而训练时的计算量需针对整个样本分布进行优化。
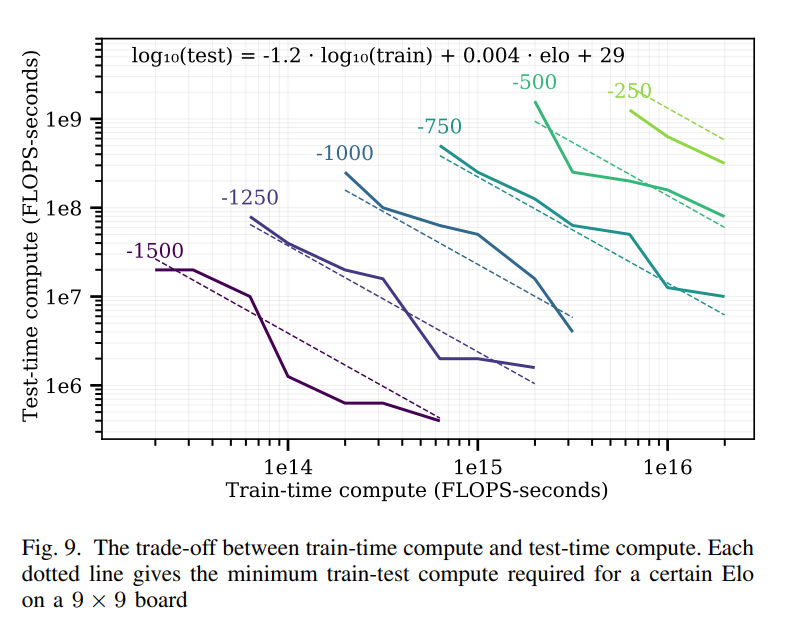
图 train-time compute 和 test-time compute之间的权衡
这个图展示了训练时计算量和测试时计算量之间的权衡关系,具体含义如下:
横轴表示训练时计算量(以 FLOPS-seconds 为单位),纵轴表示测试时计算量(同样以 FLOPS-seconds 为单位)。图中的每条虚线代表在 9×9 棋盘上达到特定 Elo 评分所需的最小训练 - 测试计算量组合。
从图中可以看出,训练时计算量和测试时计算量之间存在一种权衡关系:当训练时计算量增加时,测试时计算量可以相应减少,反之亦然。具体来说,对于每次训练时计算量增加 10 倍,可以抵消约 15 倍的测试时计算量,直到测试时树搜索减少到单节点搜索的下限。这意味着研究人员可以根据实际需求和资源限制,在训练和测试阶段的计算量分配上进行灵活权衡,以达到相同的性能水平(即相同的 Elo 评分)。
结论
本研究表明,通过在小型、廉价的问题上研究计算与性能之间的关系,可以直接推广到大规模、昂贵的问题。这一发现为未来的研究提供了一种方法,使研究人员能够在资源有限的情况下,对大型问题有更深入的理解。